
使用共指消解增强多轮任务型对话生成
2022-11-07 10:12张诗安熊德意
中文信息学报 2022年9期
张诗安,熊德意
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
任务型对话系统(Task-oriented Dialogue System)是自然语言处理领域一个重要的研究方向,其主要目的是通过对话交互完成特定任务[1],如寻找商品、预订酒店等。由于其广阔的应用前景和巨大的发展潜力,受到了学术界和产业界的广泛关注。
根据对话轮数的不同,任务型对话系统可以分为单轮对话和多轮对话。近些年,单轮对话生成任务取得了丰富的研究成果,然而在多轮对话生成任务上,模型的效果仍然不尽如人意。
单轮对话由于其一问一答的特性,问句的语意完整,意图清晰,几乎不使用省略和指代,模型回答起来相对容易;而多轮对话间的意图较为复杂,需要考虑对话上下文信息,语句中还存在大量的省略和指代现象。如图1所示,对话中的代词给模型理解说话者的真实意图造成了很大的困难,这是多轮对话模型性能达不到预期的一大原因[2-3]。

图1 含有指代的多轮任务型对话示例
本文主要关注代词对模型语言理解的影响,提出将共指消解任务结合到任务型对话上,消除代词的歧义,提升任务型对话生成模型的性能。
为了减轻省略和指代对多轮任务型对话生成模型的影响,Quan等[2]提出了一个生成式省略指代恢复模型GECOR,它把省略指代的消解任务简单地看作一个端到端的生成任务:根据上下文信息,将含有代词及省略的不完整句子直接转写为语义成分完整的句子,使对话模型可以更好地生成回复。这种方法可以取得一定的消歧效果,但训练消解模型需要标注额外的<不完整语句,完整语句>数据对,缺乏扩展性;同时,以端到端的方式恢复句子的完整语义,中间过程不可见,也不可控,因而在实际使用中缺乏灵活性。
不同于之前的方法,本文提出先借助共指消解模型识别出对话上下文中存在的指代簇,然后利用两种不同的方法将指代簇引入到对话模型中:①利用指代簇信息将语句中的代词恢复为代词所指代的实体,恢复句子的完整语义,降低对话理解的难度;②使用图卷积神经网络(Graph Convolutional Networks,GCN)对指代簇编码,作为额外信息引入到任务型对话生成模型中,增强机器理解对话的能力,帮助模型生成更合理的回复。
本文提出的方法在大规模多领域任务型对话数据集RiSAWOZ[4]上进行了实验,实验结果表明,本文提出的两个方法均比基线模型的性能有显著提升,证明本文方法的有效性。
本文的组织架构为:第1节介绍消解代词增强对话生成的相关工作;第2节介绍任务型对话和共指消解相关的背景知识;第3节介绍使用指代簇恢复对话完整语义的工作;第4节介绍将指代簇信息结构化编码引入对话模型的相关工作;第5节介绍了实验设置及实验结果;第6节对实验结果进行分析;最后,总结全文,并对下一步的工作进行展望。
1 相关工作
本节主要介绍消解代词以增强对话生成任务的相关工作。
Zheng等[5]利用单轮短文本对话数据构建了一个指代省略消解数据集,其数据形如<不完整语句,完整语句>,然后使用Seq2Seq的神经网络模型执行省略补全及代词消解。此方法的局限在于模型仅在单轮对话语句上处理,忽略了对话历史对代词消解省略补全的作用。
Su等[3]提出把代词消解和省略补全作为预处理任务,帮助多轮对话建模,其方法是先将对话历史及当前对话一同输入句子重写模型,恢复所有代词,补全所有省略信息,然后用重写完的句子执行下一个对话处理步骤,降低对话理解的难度。他们构建了含有2万段中文多轮对话的数据集,其数据形式与Zheng等类似,但把任务扩展到了多轮对话。该方法使用结合指针网络[6](Pointer Network)的Transformer[7]模型作为句子重写模型,在现有的多个聊天机器人上进行实验,都能有效提升聊天机器人的回复质量。
Quan等[2]则将多轮任务型对话和句子重写进行了结合,提出了一个生成式省略指代恢复模型GECOR。同样的,他们在Cam Rest676数据集上进行了扩展标注,每句话都额外地标注了<不完整语句,完整语句>语句对,然后将结合了拷贝网络[8](Copy Network)的Seq2seq模型与任务型对话生成模型Sequicity[9]进行多任务联合训练,该方法也取得了较好的提升效果。
与之前的工作相比,本文主要关注多轮对话生成中的指代问题,借助共指消解模型得到对话历史中的指代簇信息,通过两种不同的方式增强对话模型。在数据上,本文提出的方法不需要额外标注<不完整语句,完整语句>数据对,具有更好的适应性。同时,先抽取指代簇,再使用指代信息的方式,过程可见、可控,更适合工业中的实际运用。
2 背景知识
本节介绍与文章相关的背景知识,主要包括两部分:共指消解及任务型对话模型。
2.1 共指消解
共指消解是自然语言处理中的一个基本任务,其目的是找出文本中描述同一个实体的所有表述(mentions,包括代词和名词短语),构成一个指代簇(coreference cluster)[10]。如图2中,“通用电气”和“该公司”表述的都是同一个实体“通用电气”,所以这两个表述构成了一条指代簇。

图2 指代簇样例
传统的共指消解方法[11-14]都是采用管道式结构(pipeline),即先通过句法解析识别出文本中所有的代词和实体,然后通过手工构造的特征对它们进行打分聚类。这类方法的局限在于其依赖大量复杂精细的特征,易导致级联错误。Clark 和Manning等人[15-16]将神经网络应用到共指消解任务上,减少了执行共指消解所需要语义特征的数量。Lee等[10]提出了一个端到端的共指消解模型e2e-coref,它完全不需要任何的句法解析和手工构造特征,减少了句法解析导致级联错误的发生概率,同时,其性能超过了之前的所有模型。
Lee把共指消解任务简化:先将含有T个词的文本D=(x1,x2,…,xT)切分成N=个文本片段(span),然后通过模型计算得分,为每一个文本片段寻找最可能是其先行词(antecedent)的片段。
本文使用e2e-coref执行共指消解任务,其模型主要分为两个部分。第一部分如图3所示,模型的输入为分词后的单词,先映射成词嵌入向量表示,再使用Bi-LSTM 根据上下文进行编码,得到词的表示x*t,最后加权求和得到文本片段的表示g。第二部分如图4所示,模型的输入为第一部分输出的片段嵌入表示g,先计算可能是代词或先行词的概率,将概率过低的去除,以减少计算复杂度;然后将剪枝后的片段两两配对,计算两个表述间存在指代关系的概率,通过加权计算得到最终的概率,抽取得分高的构成最终的指代簇。
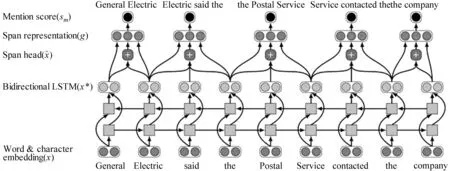
图3 e2e-coref第一部分

图4 e2e-coref第二部分
本文中的共指消解任务利用了改进后的e2e-coref模型,使用fast Text[17]中文预训练词向量,以适应中文共指消解任务。
2.2 任务型对话
任务型对话的目的是通过对话完成特定的任务。早期的任务型对话[18-20]是由语言理解(NLU)、对话管理(DM)、语言生成(NLG)等多个功能部分组合而成的模块化系统;随着深度学习的发展,任务型对话系统也逐渐开始引入神经网络[21-22]。
Zhang等[23]提出的DAMD 模型,使用端到端的方式,减少了各个模块单独训练的性能损耗;同时能够有效捕捉问句与答句间一对多的映射关系,是目前性能最优的端到端生成式任务型对话模型。因此,本文把DAMD 作为基线对话模型,并在此基础上提出改进方法。
DAMD由1个编码器和3个解码器组成,如图5所示。

图5 DAMD 模型
第t轮的问句和回复分别可以形式化为Ut和Rt,在第t轮时,首先使用Context Encoder将上一轮的回复Rt-1和这一轮的问句Ut进行编码,得到相应的句子表示。然后使用Belief Span Decoder解析出对话的意图,根据上一轮的Belief Span和句子表示解码得到第t轮的Belief Span,记为Bt,计算如式(1)所示。

得到当前轮问句的意图后,进行数据库检索,获取相应信息DBt,并与问句拼接后,使用Action Span Decoder解码得到接下来要执行的动作Action Span,记为At,如式(2)所示。

最后利用Response Decoder,生成最终的回复Rt,如式(3)所示。

3 使用指代簇恢复对话的完整语义
本节主要介绍第一个改进方法。在Zhang等人[23]的工作上进行扩展,在对话模型前加入了一个语义恢复模块(Semantic Recovery,SR),把代词消解作为一个对话的预处理步骤,使用指代簇恢复问句的完整语义,降低句子理解的难度,以增强对话生成任务,如图6所示。

图6 DAMD+SR 模型
在经过了e2e-coref模型后,可以从对话上下文中得到一个最终的指代簇Ct,但并不能知道指代簇中的文本片段是代词还是实体,这给替换代词恢复语义的工作造成了一定的困难。
在英语中,代词有复指(anaphora)和预指(cataphora)两种用法,复指为代词在其所指代的词之后,预指则为代词出现在其指代的词之前。但在中文中,代词一般只用于复指,而极少为预指形式[24]。
因此,本文将此方法简化:把指代簇中出现的第一个表述都看作实体,后面的表述无论是实体还是代词表示的都是第一个实体。在语义恢复时,直接把指代簇中第二个及其之后的所有表述全部替换为第一个实体,以达到消解代词的作用。在共指消解准确率较高的情况下,此方法能有效恢复语义。
4 融合指代簇到对话生成模型
本节介绍第二个改进方法,将指代簇作为额外信息融入对话模型,增强对话模型的编码能力。
根据指代簇恢复句子完整语义的方法虽然取得了一定的消解效果,但此方法仍然存在一定的局限:①在执行共指消解前要预先进行分词处理,然而中文分词存在一定的误差,会导致解析出的指代簇含有部分错误,如图7中例1所示;②虽然端到端共指消解模型取得了不错的效果,超过了所有传统方法,但准确率依然只能达到84%左右。在执行代词替换时,错误的指代簇可能反而会引入一些原本没有的错误,如图7中例2所示。

图7 语义恢复错误样例
针对上述问题,本文在模型上进行改进,将指代簇信息先编码,再引入对话模型,由模型自主选择指代簇中信息进行利用,增强模型的建模理解能力。
指代簇表示的是文本中词与词之间的关系。从形式上看,其并不是简单的一维序列结构,而是一种类似于图的结构化信息。本文利用图卷积网络[25]擅于对结构化信息建模的特点,将问句和指代簇构建成一张图(Graph),如图8所示。

图8 GCN 编码所使用的Graph
使用GCN 对构建的图进行编码,如式(4)和式(5)所示。其中,h(l)i为节点i在第l层的特征,N(i)为节点i相邻节点的集合,cij为归一化因子。

Gt为各个节点表示的拼接,如式(5)所示。

把GCN 输出的信息Gt与DAMD 中的Context Encoder 的输出进行融合,经过Belief Span Decoder得到第t轮的Belief Span,即问句的意图,记为Bt,如式(6)所示。

然后使用Action Span Decoder解码得到第t轮的Action Span,即要执行的Action,记为At,如式(7)所示。

最后,根据先前得到的Bt和At等信息,生成最后的回复语句Rt,如式(8)所示。

模型结构如图9所示。通过这种方式,把指代簇信息间接地引入到了对话模型,增强了对话模型的语言理解能力,又不影响原先句子的流畅度。这种方法还不用考虑指代簇中词的关系,具有更好的扩展性。

图9 DAMD+GCN 模型
5 实验设置及实验结果
本节介绍了实验的相关设置、评价指标,并给出了相应的实验结果。
5.1 实验设置
本文提出的方法在RiSAWOZ 数据集[4]上进行了实验,这是迄今为止规模最大的中文任务型对话公开数据集,同时还标注了大量的对话语言特征,包括指代簇、省略补全信息等。
首先使用RiSAWOZ数据集中的共指消解任务数据训练了共指消解模型。由于本文中的任务在中文对话上运行,我们对e2e-coref模型做了修改,使用fast Text[17]中文预训练词向量增强模型。
在得到共指消解模型e2e-coref 后,本文在RiSAWOZ数据集上进行了对话生成的实验,本文使用了10 000段对话作为训练集,开发集和测试集各使用600段。其中,平均每段对话含有1.77条指代簇,数据的详细信息见表1。

表1 RiSAWOZ数据集
本文使用DAMD 模型作为基准系统,其中词向量维度设为50,编码器的隐层大小设置为100,随机初始化模型参数,并在训练过程中更新这部分参数。实验采用了Adam 模型[26]更新参数,其中β1=0.9,β2=0.999。在使用第4 节提出的GCN 方法时,GCN 的层数设置为1层。其余与Zhang等[23]的实验设置保持一致。
由于GCN模型使用的依赖与DAMD 模型存在兼容问题,本文使用了Py Torch-1.5 版本和dgl-0.5库,并重新评测了基线模型性能。
5.2 评价指标
本文借鉴了Zhang等[23]的实验,使用Inform、Success、BLEU 和Combine作为本实验的评价指标。其中,Inform 是Belief Span的准确率,Success是Action Span的准确率,BLEU 是评价生成回复与参考回复的相似度;Combine是上述三个指标的加权得分,其计算如式(9)所示。
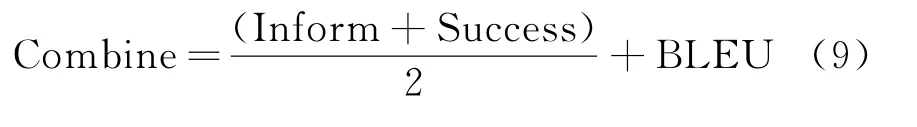
5.3 实验结果
表2展示了本文提出的改进方法和基线模型在RiSAWOZ数据集上的性能。同时,相关实验还按对话涉及的领域数量进行划分,计算了在单领域、多领域和全领域数据下的模型性能。

表2 实验结果

续表
从不同模型在全领域数据上的性能表现可以发现,与基线模型相比,本文提出的语义恢复方法(+SR)在全部3 个指标上均能有提升,在综合的Combine Score上提升了2.56个百分点;使用指代簇增强对话模型的方法(+GCN)则在所有指标上都超过了基线模型,在Inform 指标上提升2.72;在Success指标上提升4.03;在BLEU 上提升1.3个百分点;在Combine Score上,相比SR 方法进一步提升了2.115个百分点,相比基线模型则提升了4.675个百分点。实验结果表明,本文提出的方法能够更准确地识别Belief Span,进而生成出更优的回复。
从模型在不同领域数据上的性能表现来看,多领域数据上的模型性能比单领域的有不小差距,与Quan等人[4]实验中的描述一致。在单领域和多领域数据上,基线模型、+SR、+GCN 方法的性能依次增强,与全领域数据上的模型性能表现一致。
6 实验分析
本节对实验结果进行分析,分析了指代簇对生成式对话模型的性能提升的有效性,比较了本文提出的两个方法间的差异,验证了方法的有效性。
6.1 指代簇数量对对话模型性能的影响
本文提出的方法是通过不同方式利用指代簇信息增强对话模型的性能,本节通过实验分析验证指代簇对生成式对话模型的提升的有效性。
在5.3节的实验结果中,先使用e2e-coref模型在对话上下文中抽取出所有的指代簇,然后继续做相应的处理。为了验证指代簇对对话模型的提升有效性,本文做了进一步的实验,在解码过程中,将共指消解中解析出的指代簇按比例随机掩去,保留20%、40%、60%、80%、100%的指代簇用作比较,模拟不同召回率情况下的对话模型各指标提升效果。实验的性能如图10所示。
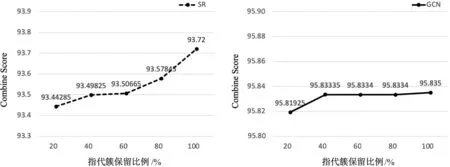
图10 使用不同数量指代簇的模型性能对比
从图10可以看出,随着指代簇数量的增多,模型的性能缓慢提升,指代簇的召回率越高,对生成式对话模型的帮助越大。与基线模型相比,两个方法在Combine Score指标上都更强。这表明,引入指代簇的信息,确实能够有效提升对话模型的生成性能。
6.2 指代簇质量对对话模型的影响
本文提出的两个增强方法,区别主要在于利用指代簇信息的方式不同,第3节提出的方法是使用指代簇恢复对话源端语句的完整语义,降低句子的理解难度;第4节提出的方法则是将指代簇作为额外信息编码,整合进对话生成模型,增强对话模型的语言理解能力。本节探究了这两个方法的区别,主要是指代簇质量的高低对这两个方法性能的影响,分析两个方法的鲁棒性。
为了验证两个方法对指代簇质量的敏感程度,在训练对话模型时,给训练数据中的指代簇随机添加噪声,噪声的比例按10%递增,模拟不同消解准确率下对话模型的性能表现。
如图11所示,在不添加任何噪声的情况下,两个方法都达到了最高性能,随着噪声的增多,两个方法的性能都开始逐渐下降。这说明继续提高共指消解模型的性能,提高指代簇准确率,能够进一步提升对话模型的性能。

图11 添加不同数量噪声的模型性能对比
在两个方法的比较上,在0%和50%噪声情况下做对比,SR方法性能下降了1.07%,而GCN 方法性能下降了1.02%,表明GCN 方法的性能损失更少,鲁棒性更佳,确实优于基线模型和SR方法。
6.3 实例分析
表3中展示的是对话的一个生成示例,可以看到在对话的问句中存在代词“这部片子”,这给作为基线模型的DAMD 模型造成了一定的影响,使得模型错误地认为当前谈论的是电视剧领域,造成后续一系列问题。

表3 回复样例比较
SR 和GCN 方法则先对上下文做共指消解,抽取出对话文本中的指代簇,降低代词对语言理解模型的影响。结合了SR 方法的模型,将问句恢复为“最后我想问问武状元苏乞儿还有哪些主演?”后,模型能够准确地识别出对话意图为询问电影领域的主演名单和片长两个槽,但直接替换破坏了语句的流畅度,造成回复生成质量一般。结合了GCN 方法的模型,将指代簇作为辅助信息编码进对话模型,解析的act span准确,生成的回复完整且质量高,显示出了更好的性能。这表明,借助指代簇的信息,能够有效提升含有代词语句的语言理解能力;另一方面,GCN 方法相比SR 方法能够在保证共指消解的情况下,取得更好的生成质量。
7 总结
本文提出了两种使用指代簇信息增强任务型对话生成模型的方法。与之前的方法不同,本文提出的方法都是先通过共指消解模型抽取出对话上下文中的指代簇,然后使用指代簇来增强对话模型。进一步的,使用指代簇恢复出含有代词问句的完整语义,以降低句子的语言理解难度;使用GCN 将指代簇作为额外信息编码,增强对话模型的语言编码能力,在引入指代信息的同时,保留了对话的自然特征,进一步提高了对话的生成质量。与之前的方法相比,本文提出的方法过程更可控,使用更灵活,且取得了显著的性能提升。
未来工作中,我们会进一步探索如何在对话生成模型中更加有效地融合指代信息。
猜你喜欢
科学咨询(2022年19期)2022-11-24
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
考试与评价·八年级版(2020年1期)2020-10-26
家庭影院技术(2019年8期)2019-08-27
高中生·天天向上(2018年1期)2018-04-14
自动化学报(2017年11期)2017-04-04
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
火炸药学报(2014年1期)2014-03-20
