
基于多级别特征感知网络的中文命名实体识别
2022-11-07 10:12:08周俊昊
中文信息学报 2022年9期
宋 威,周俊昊
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122)
0 引言
如何从海量的非结构化文本数据中,准确识别其中的各种各样的实体,成为当下的研究热点和难点。命名实体识别(Named Entity Recognitior,NER)作为自然语言处理领域的一项基础任务,主要是识别文本中有一些特定含义的实体,例如,人名、地名、时间及专有名词等。目前,命名实体识别作为其他自然语言处理任务的上游任务,已广泛应用于自动摘要[1]、情感分析[2]和机器翻译[3]等多种自然语言处理任务中。
从早期的基于规则和字典的方法到基于传统的统计机器学习方法,再到现在主流的基于深度学习的方法,研究人员不断地将新的技术应用到命名实体识别中。其中,基于规则和字典的方法的可扩展性较差,一种规则或字典只能应用在一种领域中。随着统计机器学习的发展,隐马尔科夫链[4]、最大熵[5]和条件随机场(Conditional Randm Field,CRF)[6]等方法逐渐取代了早期的基于规则和字典的方法,进一步推动了命名实体识别朝着智能化的方向发展。基于统计机器学习的方法,一方面较依赖于本领域的专家,造成大量的人力耗费;另一方面,特征标注的质量直接影响实体识别的好坏。现在基于神经网络的命名实体识别方法既不需要定制规则和字典,也不需要进行大量的人工标注,因此逐渐成为主流的方法。命名实体识别是一种典型的序列标注问题,而循环神经网络(Recurrent Neural Network,RNN)非常擅长处理具有时序特征的数据。但是RNN 在实际使用的过程中,存在记忆信息有限、保留信息不完全的问题,同时存在梯度爆炸的情况。RNN 和长短期记忆网络(Long Short-Term Memony,LSTM)都是从前往后传递信息,这在很多任务中都有局限性,比如词性标注任务,一个词的词性不仅和前面的词有关还和后面的词有关。因此提出了双向长短期记忆网络(Bi-derectional Long Short Term Memory,BiLSTM),将同一个输入序列分别接入向前和后的两个LSTM 中,然后将两个LSTM 的隐含层连在一起,共同接入到输入层进行预测。Huang[7]等人提出了该方法在词性标注和命名实体识别任务中均取得了不俗的效果。
目前中文命名实体识别方法主要分为基于字和基于词的两种方法。其中,基于字的中文命名实体识别方法用来获取字级别特征。例如,Jin[8]等人引入了一种带有门控滤波机制的混合卷积神经网络来捕获局部上下文信息,并用一个High Way网络来选择感兴趣的特征。另外,门控自注意力机制可用于捕获来自不同的多个子空间和任意相邻字符的全局依赖关系,如Zhang[9]等人利用注意机制和一个信息门来融合字符级和词级特征。该方法应用反向堆叠的LSTM 层来获得一个序列的深度语义信息。数据集中实体识别的F1达到91.09%。冯艳红[10]等人提出了一种基于双向LSTM 的中文命名实体识别方法,该方法不直接依赖于人工特征,它利用标签之间的相关性,增强模型的识别能力,在1998年《人民日报》数据集中人名、地名和机构名实体识别的F1值分别达到93.66%、90.77%和93.25%。Tang[11]等人构建一种新的字符图卷积网络,该网络使用交叉图卷识网络(Graph Convolational Netnwork,GCN)块同时处理两个方向的字符有向无环图。其次,为了提高长距离依赖的捕获,引入了全局注意力机制来学习基于全局上下文的节点表示。在这两个模块中,单词和字符被平等地视为图中的节点。
在电力系统安全生产的过程中,员工的安全保障意识还有待提升,许多安全事故的发生大多是由于工作人员没有足够的安全生产意识。这不仅为工作人员带来了许多安全隐患,也不利于电力公司的发展。所以,我国的电力公司必须建立一个科学合理、安全性强的安全生产制度,并且加强对员工进行安全教育和安全培训。同时还要对电力系统中的生产工具进行严格的检修与管理,避免因工具有缺陷而造成的安全生产事故、
即将到来的各种节日,不仅是奢侈腕表,更是几乎所有奢侈品牌争夺的营销主战场。想要从中分一杯羹,创新的营销形式、精准的渠道选择以及电商导入能力,在品牌营销中更加至关重要了。
由于中文中汉字在不同的场景有着不同的含义,但是字级别特征仅考虑字本身,忽视了字在在具体语境中的含义,没有考虑到词级别特征。为此,Wang[12]等提出了一种基于多粒度语义字典和多模态树的中文命名实体识别方法,该方法包括以下步骤。首先,利用多模态树提取不同的语义词级别特征,然后再提取边界信息,最后进行多粒度特征融合。Hu[13]等人将词典信息融合进词特征中,最终利用条件随机场加入一些约束来保证预测结果,其中词级别特征的方法和分词工具最终的结果起着至关重要的作用。
其中,Ti,yi表示字符xi的标签概率,A是转移矩阵。实际输出标签序列y的条件概率如式(15)所示。
由于传统的卷积神经网络更偏向于获取数据的局部特征,不能很好的获取全局信息。因此Strubell[21]等人利用空洞卷积网络(Dilated CNN,DCNN)获取更远距离的关系,通过扩大感受野的方式改善效果,但其缺点是容易造成局部信息丢失。为了综合考虑远距离和相邻字符之间的信息,同时受到Dauphin[22]等人提出的门控机制启发,本文采用一种双通道门控卷积神经网络,利用门控机制动态加权地获取两个部分卷积网络之间的信息流动。如图2所示。具体的,首先利用DCNN 和CNN 分别获取远近距离字级别特征。其次利用门控机制,加权获取远距离和相邻字符的特征。式(3)和式(4)为本文定义的DCGCN。
(1)构建了一种双通道门控卷积网络,获取字级别特征,以表示单字所包含字的字形信息。
(2)获取词语的词义信息,在词级别的特征中嵌入对应位置信息,同时为了赋予实体更大权重,利用自注意力机制感知带有位置信息的词级别特征。
(3)在MSRA、Resume、《人民日报》和Literature数据集中进行广泛的实验,所提出的方法总体上优于近几年提出的主流方法,验证了本文所提出的方法的有效性。
1 相关工作
近年来,神经网络已成为主流的命名实体识别方法。Lin[15]等人受到象形字的启发,将汉字分解为不同的偏旁部首,同时将这些偏旁部首融入到字级别特征中,进而作为BiLSTM 的输入,但是仅考虑偏旁部首,却没有考虑位置关系,无法表示每个汉字中偏旁部首的位置,因此这种字级别特征无法表示完整的字形信息。针对此问题,Jia[16]等人在此基础之上融入卷积神经网络(Convolutional Neural Network,CNN)提取字的形态和结构等字级别特征。
标准允许使用的刀具有:单刃刀具和多刃刀具。由于多刃刀具只适用于漆膜厚度小于120μm的漆膜[1],且使用时因受力点多,容易出现施力不匀的现象,很难达到全部划透漆膜。因此,推荐优先使用单刃刀具。
其中,Wg和Wh分别表示转换门和输入层权重,bg和bh分别为上述权重的偏置。tg是转换门,控制信息的流动,保留更多有用的信息。
由于词语在不同的语境中可以表达不同的含义,为有效地区分一字多义的问题,Peters[17]首先利用大量的未标注的数据进行正反向语言模型的训练,得到两个预训练的RNN 网络,同时对于句子中的每个单词,经过第一层RNN 得到隐层表示,此时该句子经过预训练的两个RNN,并与之前的网络隐层进行拼接,进行序列标注。BiLSTM 擅长处理时序信息,但无法获取词语的局部特征。针对此问题,盛剑等人[18]在BiLSTM 基础上,借助卷积神经网络进一步提取词语的局部特征,提出细粒度的命名实体识别方法,首先利用网络词典标注一些数据,获取一批粒度比较粗糙的文本数据。为了减少噪声和冗余信息对结果造成的影响,先获取实体的大类标签,然后确定命名实体的细粒度标签。然而,上述两种方法无法动态地为句子的每个词分配权重,因此无法体现更重要的实体,忽略了句子中词语之间的相关性信息。Zhu[19]等提出一种基于注意力机制的卷积神经网络(Convolutional Attention Network,CAN),该方法利用全局和局部的注意力机制,从相邻的字符和句子上下文中获取信息。此外,与其他方法不同的是,CAN 不依赖于任何外部资源,字符嵌入使得CAN 在实际场景中更加实用。
针对仅采用字级别或词级别特征网络进行识别,不能兼顾二者优点,难以获取足够的特征信息这一问题,本文提出了一种基于多级别特征感知网络的中文命名实体识别方法MFPN。首先为了获取单字的字形信息,构建一种双通道门控卷积神经网络获取字级别特征信息。由于词在不同位置有着不同的含义,本文利用自注意力机制感知嵌入位置信息的词级别特征,同时考虑了词语间的相关性。进一步地,将字和词级别特征拼接,从而有效结合了字和词级别的特征,以全面表示词的语义信息。
苏州市于1997年年底着手农村河道疏浚5年规划,经过1998—2002年5年的艰苦努力,投资超过6亿元,完成了第一轮河道疏浚。但由于“重建轻管”观念未彻底扭转,河道整治后疏于管理,再次造成河道屡疏屡堵,引、排、蓄功能削弱等情况。2002年,在总结经验教训的基础上,确立了农村河道 “疏浚整治和坚持长效管理”两手抓的方针。至2006年,借助江苏省委发出“关于动员农村党员集中开展村庄河道疏浚整治的要求”的东风,苏州市又提出了“加快河道综合整治和坚持长效管理全覆盖”的第三轮河道整治,真正做到了“疏好一条河道,复垦一块土地,增加一片林地,整治一村环境,盘活一方水系”。
2 基于多级别特征感知网络的中文命名实体识别方法
本节具体介绍MFPN,整体框架如图1所示。多级别特征感知网络主要包括以下几个部分:字级别特征感知网络(Character-level Feature Perception Network,CFPN)、词级别特征感知网络(Wordlevel Feature Perception Network,WFPN)、Highway网以及CRF层。
然而,中文中汉字在不同的场景有着不同的含义,字级别特征仅考虑字的本身,忽视了字在在具体语境中的含义,即仅基于字级别的方法无法解决中文命名实体识别方法中字的多义性问题。例如“小明去朋友家做客,盛情难却,多盛了一碗饭吃”第一个“盛”表示多,第二个“盛”是动词,表示动作,两个“盛”在不同的语境中表达不同的含义。
随着我国全社会经济和信息化进程的不断发展,各类刑事犯罪高发,社会矛盾日趋激化,影响社会稳定的不确定因素增多,难以预料的挑战和风险明显加大,在这些维护社会和谐稳定的巨大挑战面前,传统的被动反应型警务模式已经无法适应社会发展的需要,公安信息化被赋予了重大的时代意义。
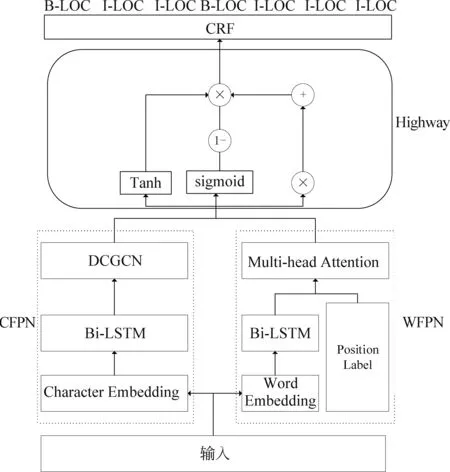
图1 MFPN 结构
2.1 字级别特征感知网络
假设句子X={x1,x2,...,xn},其中xi表示X中的第i个字符,字符xi的字级别特征表示如式(1)所示。

由于传统的RNN 网络在训练的过程中存在梯度消失的问题,Hochreiter[20]等人利用LSTM 解决梯度消失问题,但是LSTM 仅考虑文本中字符前向序列信息。因此本文利用双向LSTM 获取文本中字符的上下文信息。
她被妈妈骂的时候,会噘起小嘴巴,眼睛向下看。有时,还会带一点点眼泪。被骂得很凶的时候,她放声哇哇大哭,眼泪就像泉水一样涌出来。
这里把式(1)中的字级别特征作为双向LSTM的输入,从而得到字符xi的隐层表示,如式(2)所示。

本文贡献主要包含以下三点:

图2 DCGCN 的网络结构
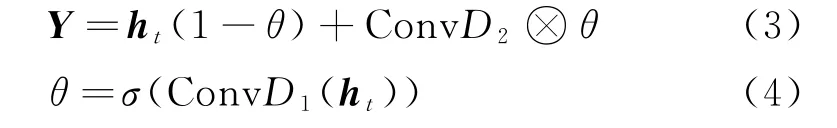
其中ht用以获取字符序列前向和后向特征,ConvD1和ConvD2分别表示CNN 和DCNN 两个不同的卷积输出信息,分别用以获取相邻字符和远距离字符特征,σ为Sigmoid激活函数。
2.2 词级别特征感知网络(WFPN)
假设有一个句子W={w1,w2,...,wn},其中wi代表第i个词语。句子中的词向量表示如式(5)表示。
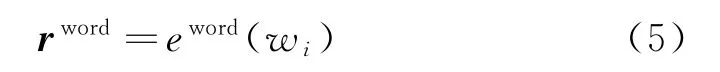
本文利用双向LSTM 获取词语的上下文信息。同时为了给词语嵌入不同的位置,给定一组位置标签L={l1,l2,...,ln},第i个位置标签li的表示如式(6)所示。

将词向量特征和位置特征组合,获取融合特征,表示如式(7)所示。

自注意力机制通过接收n个输入,然后返回n个输出,让每个输入都会彼此交互,然后找到应该更加关注的输入。具体地,通过某种运算来直接计算得到句子在编码过程中每个位置上的注意力权重;然后再以权重和的形式来计算得到整个句子的隐含向量,从而获取词语的相关词义信息。自注意力机制主要包括点乘和多头注意力两个部分。点乘注意力如式(8)所示。

多头注意力就是在多个不同的投影空间中建立不同的投影信息,将输入矩阵进行不同的投影,得到许多输出矩阵后,将其拼接在一起。实现方式如式(9)、式(10)所示。
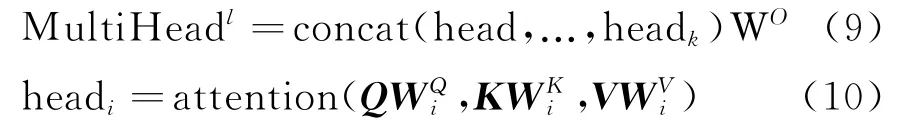
其中,WQi、WKi和WVi分别为Q、K和V的参数,WO为可学习的权重。对于序列G,本文利用自注意力机制获取带有位置信息的词级别特征向量C=SAM(G)。
3.罪犯教育方法人性化。要充分考虑人性发展的要求,采用引导,激励等方式,尽最大可能去调动和发挥罪犯的积极性、主动性与创造性。要给予罪犯一定的自由宣泄手段。要认真考虑给予罪犯个体适当的自由空间和时间。同时,对一些过去明令禁止的,但又有助于罪犯心理自我调整的行为要认真加以研究,给予罪犯自由的情感宣泄手段。如,建立供给罪犯释放情绪的倾诉室、拳击室、静思室等等。
中心机房是计算机网络信息系统的核心组织结构,完善中心机房安全管理策略可以从技术与角度两个入手,从而提升中心机房安全管理质量。
2.3 字词特征融合
由于字级别特征无法解决一词多义的问题,但是分词的好坏又直接影响到基于词级别特征方法的识别实体的准确性。因此,我们将字-词特征融合,如式(11)所示。
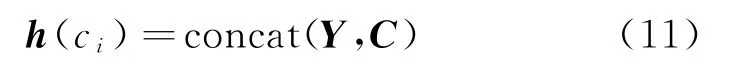
2.4 Highway网络
Highway网络主要利用门控机制,将一部分数据过滤,控制信息的流动,过滤掉重复语义信息的同时,尽可能地将有用信息保留下来。最终的输出如式(12)、式(13)所示。
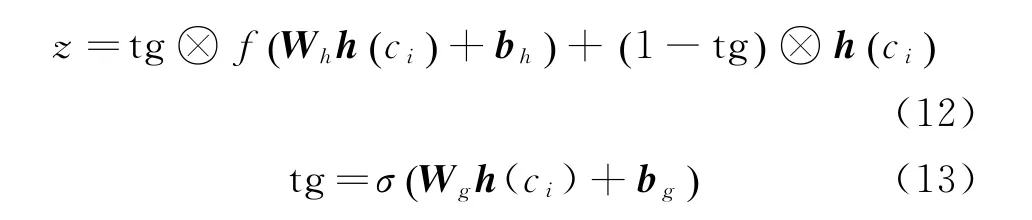
清查表中每项数据中都需要填写联系电话,按规定固定电话在区号和号码之间使用连字符“-”,手机号码位11位数字,数据量很大,常出现漏区号、位数错、非数字的情况,在这些列的后面增加一列并填上公式“=LEN(SUBSTITUTE(M2,“-”,“”))”,如图 1,同时为此整列设置条件格式,可以明显判断左侧的电话号码是否有输入错误。
莫西沙星组临床总有效率显著高于左氧氟沙星组,不良反应发生率显著低于左氧氟沙星组,差异具有统计学意义(P<0.05)。莫西沙星与左氧氟沙星相比,细菌不易产生耐药性,患者对莫西沙星的耐受性也较好,出现的不良反应和副作用少。
2.5 CRF层
由于CRF层可以加入一些约束来保证最终预测结果是有效的。因此本文利用CRF获得全局最优序列。对于一个句子来说,其概率表示如式(14)所示。
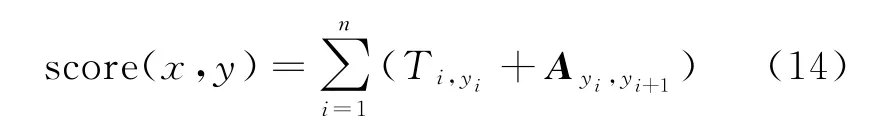
针对上述问题,本文提出了一种基于多级别特征感知网络(Multi-level Feature Perception Network,MFPN)的命名实体识别方法[14]。首先提出一种双通道门控卷积神经网络,用于感知字级别特征,以表示字形信息。其次,在词级别特征中嵌入对应的位置信息,以表示词语的语义信息。本文利用自注意力机制感知带有位置信息的词级别特征。进一步地将上述得到的字级别和词级别信息融合,以此全面表示句子的语义信息。在此基础上,本文设计一种带有门控机制的网络来过滤重叠的冗余信息。最后结合CRF学习到句子中的约束条件,实现中文的命名实体识别。

其中,λ表示L2正则化的超参数,θ表示可训练参数。
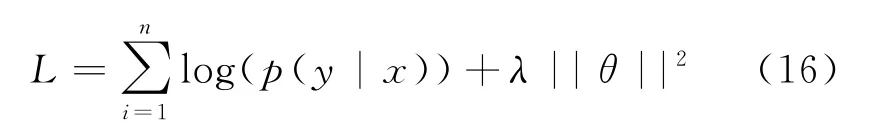
最后我们通过维特比算法[23]来求解最优序列。目标损失函数如式(16)所示。
3 实验
3.1 数据集介绍、评价指标及参数设置
本文在如下四个数据集上验证多级别特征感知网络的有效性,分别是Resume、MSRA、Literature和1998年的《人民日报》(以下简称《人民日报》)。表1是对这四个数据集的训练集和测试集情况的一个统计详情。其中Resume主要包括上市公司一些管理人员的国籍、学历、工作地点、姓名、职业及职称等简历实体信息。MSRA主要是简体中文的新闻,其中主要包括任命、地名和机构名等三种实体信息。Literature主要包括任务、地点、时间、组织和摘要等文学实体。《人民日报》主要是由中文文章组成的。其次,本文利用F1值来评价命名实体识别的有效性。
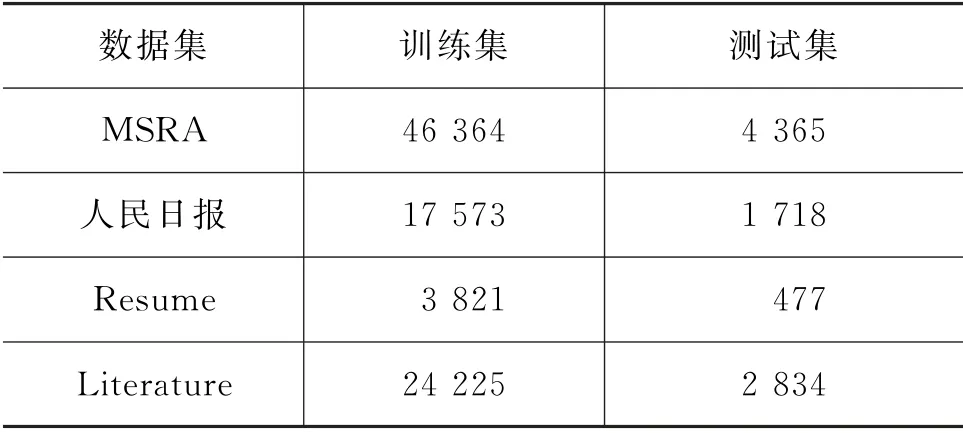
表1 数据集介绍
本文使用Word2vec对MSRA、1998年《人民日报》、Resume和Literature数据集进行词向量训练。通十折交叉验证法,获取多级别特征感知网络的最优参数。具体参数情况,其中学习率为0.001,隐藏层的节点数为300,向量的维度为300,Dropout设置为0.5。
3.2 实验结果和分析
本文在3.1节介绍的四个数据集上进行实验,以此对所提的方法进行验证。同时本文做了消融实验。具体的,将多级别特征感知网络拆分成以下三个部分,仅基于字级别特征(CFPN)、仅基于词级别特征(WFPN),以及本文所提出的基于多级别特征感知网络(MFPN)的中文命名实体识别方法。图3~图6分别展示了上述三种方法(MFPN、CFPN 和WFPN)在MSRA、《人民日报》、Resume和Literature数据集上的训练过程。
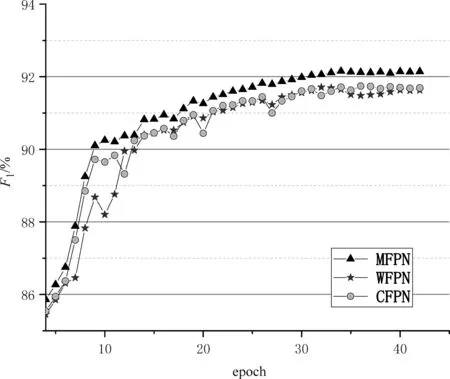
图3 MSRA 数据集训练过程
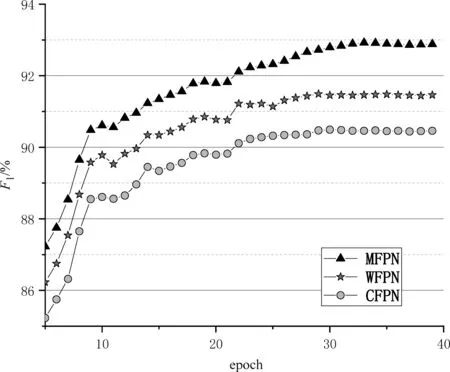
图4 1998年《人民日报》数据集训练过程
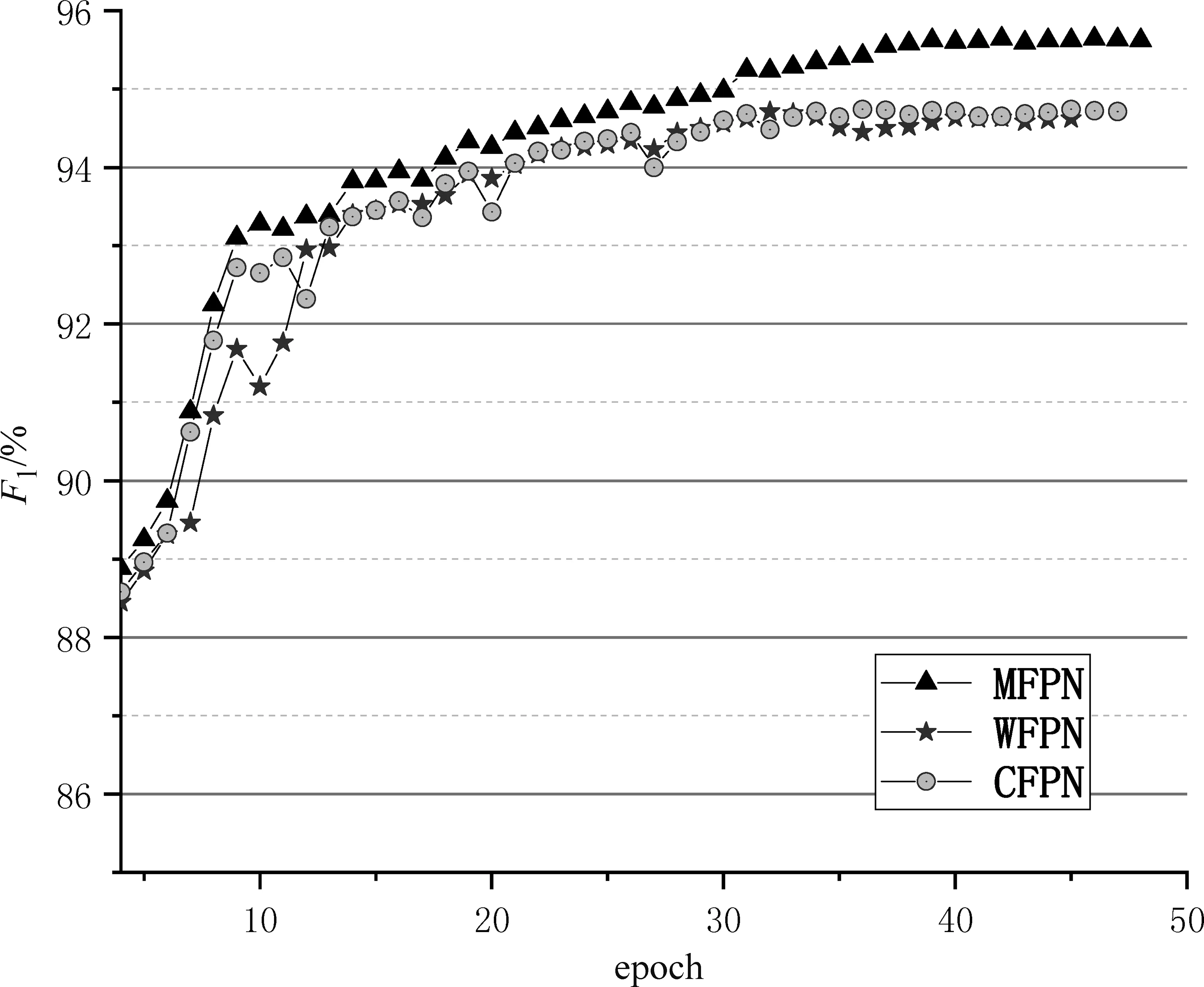
图5 Resume数据集训练过程

图6 Literature数据集训练过程
从训练过程图中可以发现,在训练之初的前若干次迭代中,迭代次数和F1值呈现出正相关的关系。之后F1的上升趋势逐渐放缓,并且伴随着小幅度波动。但是在四个数据集上的F1值最终都趋于稳定。
此外在上述的四个数据集上,本文所提的多级别特征感知网络均优于单一模型CFPN 和WFPN的识别效果。这主要是因为本文所提的多级别特征感知网络既考虑了字级别的字形信息,又考虑了词级别的语义信息,以此全面表示句子的语义信息,因此拥有最高的F1值。
为了展示上述消融实验中的三种方法在所选取的数据集的效果,分别在MSRA 和《人民日报》数据集上展示了三种方法的最高F1值。同时,为了展示本文所提出的方法在时间开销上的成本也相对较低,在上述两个数据集上做了时间开销实验。表2和表3展示了在MSRA 和《人民日报》的最高F1值与时间开销。从表中可以发现,本文所提出的MFPN 拥有最高的F1值。这主要是由于本文所提出的方法同时考虑了字和词级别的优点,同时又过滤掉了二者的冗余信息对网络的影响。
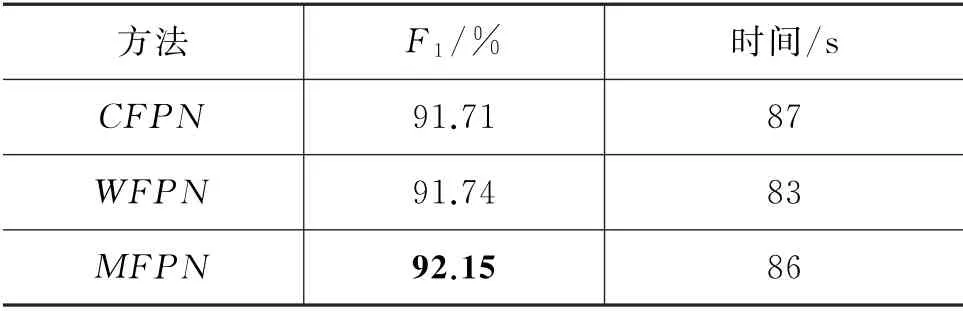
表2 MSRA数据集上3种方法F1 值
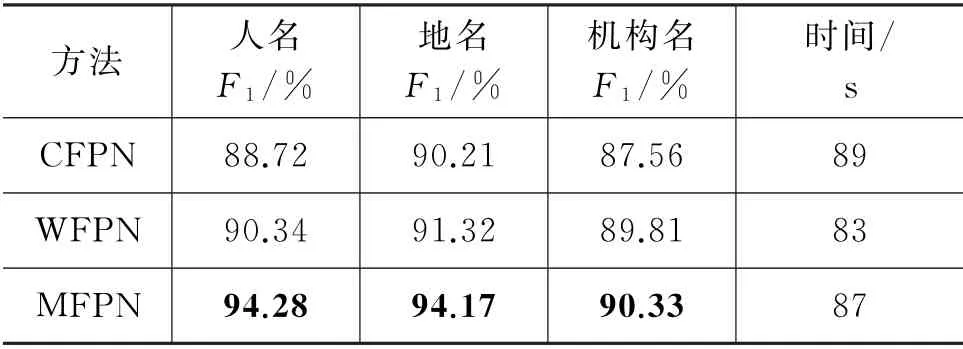
表3 《人民日报》数据集上3种方法F1 值
另外,在《人民日报》数据集上的结果普遍优于MSRA,主要是因为《人民日报》没有采用自动分词工具去分词,每个词都是手工标注,分词很准确。另一方面,我们还发现在时间成本上,本文提出的方法优于CFPN,仅比WPFN 效果差一点,主要是因为本文采用字词结合的方法,故在时间成本上会稍微差点。
3.3 与主流方法的比较
表5至表7分别展示了本文所提的MFPN 和当前主流的中文命名实体识别方法的最高F1,以体现本文所提出方法的优越性。在MSRA 数据集上,对MFPN、Ensemble-SVM[24]、BiLSTM+CRF+adversarial+self-attention[25]、MIFM[9]、DEM-attention[26]和Bi-LSTMpre2+ext[27]等五种近年来主流的中文命名实体识别方法进行比较。在《人民日报》数据集上对MFPN、CRF、BLSTM[10]、Emsemble-SVM 和DCW[28]进行比较。在Resume数据集上,对MFPN、lattice LSTM[29]、CAN-NER[19]、IDCHSAN[30]和GCRA[8]进行比较。在Literature 数据集上,对MFPN、GCRA 和DEM-attention 进行比较。
坐在宝马车副驾驶位置上的欧阳锋收到妻子发来的一条短信:老公,别喝太多,记得早点回来。欧阳锋盯着手机屏幕傻傻地笑了笑,回复了两个字:放心!
如表4所示,相较于本文所选的当前主流的中文命名实体识别方法,本文提出的MFPN 具有最高的F1。如表5所示,在《人民日报》数据集上,本文提出的MFPN 的平均F1值优于其他四种方法,达到了92.93%。如表6所示,本文所提出的MFPN具有最高的F1,这是由于Resume数据集中不仅包括人名、地名和机构名等常规实体,同时也包括了学历、国籍等其他实体,MFPN 在获取语义信息时,不仅考虑到了字和词的特征,同时又兼容了二者之间的联系,因此更能全面表示句子的语义信息,从而提升其命名实体识别的准确性。如表7所示,MFPN在Literature数据集上取得最好的表现,其F1值为74.54%。同时可以发现,几种方法在该数据集上的效果均不如前三个数据集的效果好,这是由于Literature数据集由包含多种复杂修辞手法的中国文学作品组成,导致其实体难以识别。尽管如此,本文提出的MFPN 相对于其他两种方法仍取得较高的F1值。
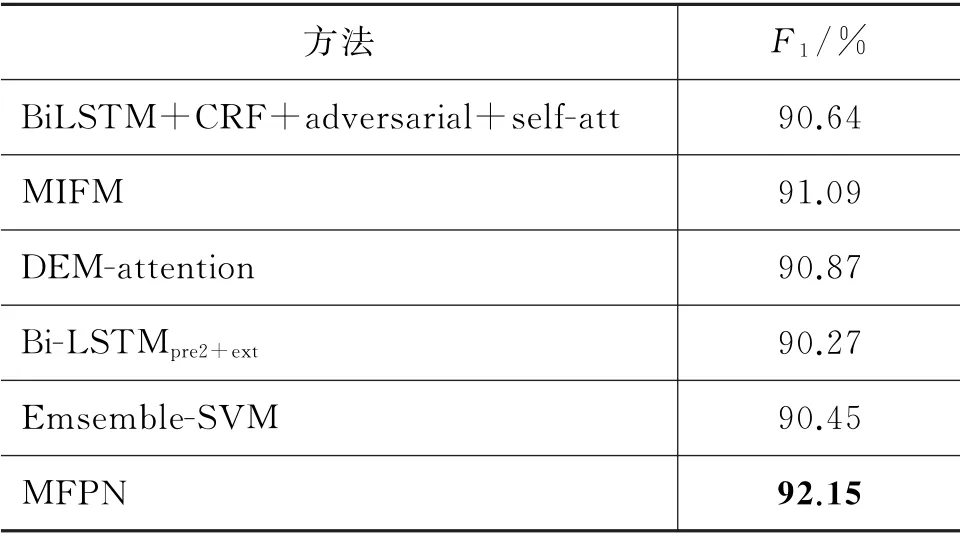
表4 MSRA数据集上最高F1
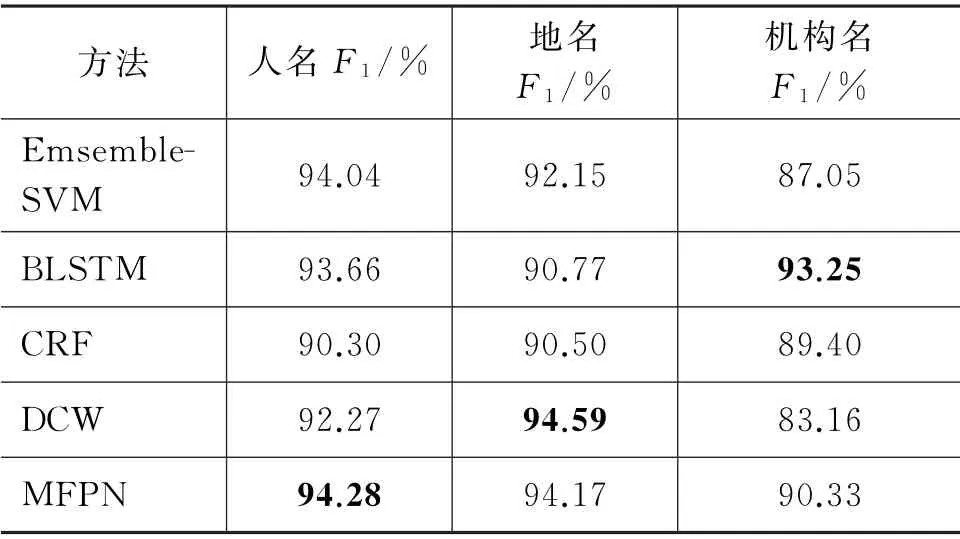
表5 《人民日报》数据集上最高F1
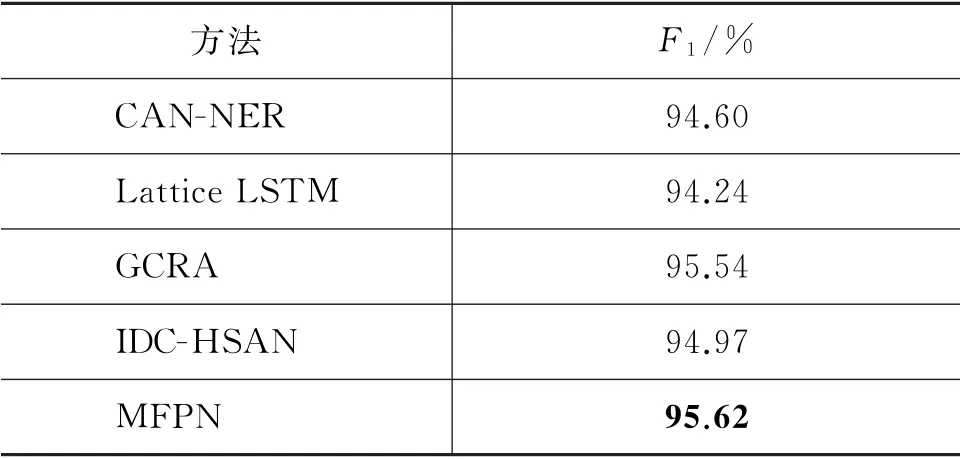
表6 Resume数据集上最高F1

表7 Literature数据集最高F1
4 总结与展望
本文提出一种基于多级别特征感知网络的中文命名实体识别方法,解决了单一字级别或词级别网络难以获得取足够特征信息的问题。首先提出一种双通道门控卷积神经网络,通过感知字级别特征,在减少了未登录词数量的同时,也表示了字形信息。同时,为了获取词语的词义信息,本文在词级别的特征中嵌入对应位置信息。为了赋予实体更大的权重,本文利用自注意力机制感知带有位置信息的词级别特征。进一步,将上述得到的字级别和词级别两种信息融合,表示句子的语义信息。由于采用字词结合的方法,容易产生冗余信息。因此本文设计了一种门控机制网络,过滤冗余信息,从而减少冗余信息对命名实体识别的影响。再结合条件随机场学习到句子中的约束条件从而识别子中的实体。最后在MSRA、《人民日报》、Literature和Resume数据集上开展消融实验。验证了本文所提出的多级别特征感知网络比仅基于字或仅基于词的部分效果好。同时与目前的主流方法做对比,总体上优于近几年的主流命名实体识别方法。下一步工作中,我们将尝试将本文方法运用到其他场景的中文数据集中,同时将探索在细粒度中文命名实体中的识别方法,从而为海量数据的数据挖掘提供支撑。
猜你喜欢
基层中医药(2021年8期)2021-11-02 06:25:02
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
数学物理学报(2017年5期)2017-11-23 07:51:31
中学生(2017年13期)2017-06-15 12:57:48
