
基于XY双变量特征提取策略的秸秆炭热值LIBS定量分析
2022-11-07 07:56段宏伟朱荣光牛其建
光谱学与光谱分析 2022年11期
段宏伟,郭 梅,朱荣光,牛其建
1. 江苏大学农业工程学院,江苏 镇江 212013 2. 江苏大学现代农业装备与技术教育部重点实验室,江苏 镇江 212013 3. 石河子大学机械电气工程学院,新疆 石河子 832003
引 言
随着化石能源价格不断攀升,生物质能利用价值愈发受到各国能源部门关注。生物质炭化成型燃料因清洁卫生、 灰渣可回收利用等优点已成为我国主推清洁能源之一。热值(CV)是热效率、 燃烧设备热平衡、 燃料品质计算的重要指标,主要通过氧弹量热仪测量反应物与生成物的焓差计算得到,然而该方法难以满足工业生产实时监测要求。
激光诱导击穿光谱(LIBS)是一种利用激光在焦平面直接烧蚀样品表面产生等离子体时发射的原子或离子光谱进行检测的新兴技术[1]。该技术在农业原料等生物质复杂基体特性精确定量分析方面仍面临挑战。Song等[2]研究结果表明X自变量特征提取法可以去除复杂基体LIBS谱线中大量无信息变量和多重共线性变量,从而提升定量模型预测性能。
目前常规特征变量提取方法为X(光谱)自变量特征提取类型法,如竞争性自适应重加权算采样法、 遗传算法和回归系数法等[2-4],上述方法主要依据不同采样光谱波段组合构建模型的交互验证均方根误差(RMSECV)进行特征光谱提取。由于该类方法所对应回归模型主要为线性偏最小二乘回归(PLSR),而秸秆炭中主要包含金属元素原子/离子谱线和非金属元素原子/分子谱线,因此X自变量特征提取法仅能筛选出符合朗伯比尔线性定律的大部分金属元素LIBS特征光谱。
为提取与秸秆炭CV紧密相关的非金属元素LIBS特征谱线,本研究提出一种Y(浓度∶热值)因变量特征提取法,主要对秸秆炭CV与元素浓度进行相关性分析,通过相关性显著分析获取大部分非金属元素最佳组合谱线。研究基于XY双变量特征提取策略精确获取秸秆炭CV敏感特征元素变量,采用遗传算法优化及自适应增强的人工神经网络算法(GA-BP-Adaboost)构建秸秆炭CV非线性LIBS定量分析模型,为秸秆炭燃料品质评价以及工业现场过程分析提供一种可靠的分析策略。
1 实验部分
1.1 LIBS装置
LIBS系统烧蚀源为一台调Q的Nd∶YAG固体激光器,激发波长为1 064 nm,最大频率为2 Hz,脉冲延迟为10 ns,最大激发能量为100 mJ。激光聚焦后法线入射到样品表面并引发等离子体,相对于水平方向呈45°的准直镜接收等离子体信号至光纤传输通道。光纤出口连接7通道电荷耦合光谱仪,光谱仪分辨率为0.05 nm,检测波长范围为187~980 nm。
在本研究中,针对激光脉冲能量波动对谱线强度影响问题,将激光能量设为30 mJ,单点激光重复烧蚀次数设为3,单点光斑大小设为200 μm。为了避免轫致辐射,探测器相对于激光脉冲的延迟时间设为0.7 μs。
1.2 样品制备
79个秸秆炭样品采购于南京智融联科技有限公司,包含水稻秸秆炭和玉米秸秆炭。样品经过45 ℃烘箱干燥后,利用刀片式粉碎机粉碎过75 μm筛后放入自封袋备用。样品中N,C,S,H和O采用元素分析仪测定[5],K,Na,Ca,Mg,Pb,Cr,Cu,Zn和P元素含量采用ICP-MS测定[6],CV采用氧弹量热仪测定[7],实验结果如表1所示。
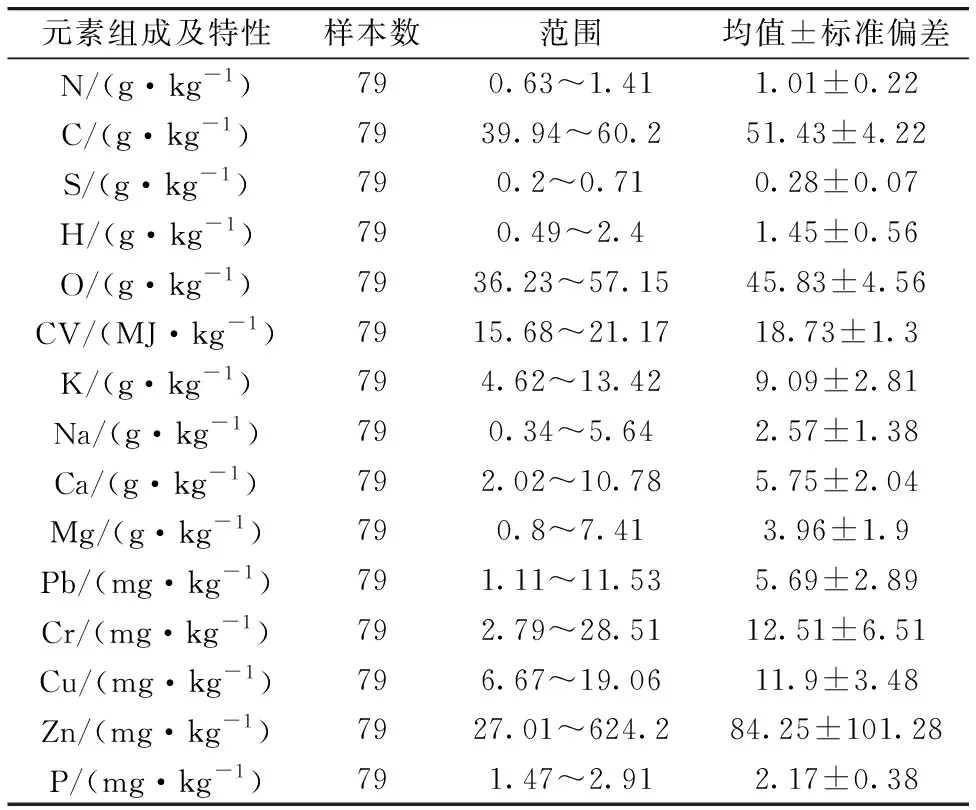
表1 CV和主要元素含量统计结果Table 1 Statistical results of CV and main element content
1.3 XY双变量特征提取
定量分析模型一般形式为Y=KX+B,其中X和Y分别为自变量和因变量,所对应特征变量提取方法可以分类为X自变量特征提取法和Y因变量特征提取法。本研究所采用的XY双变量特征提取法流程如图1所示。
首先采用Y因变量特征提取法获取与秸秆炭CV相关的C和O等非金属元素谱峰波段组合,通过CV与秸秆炭元素浓度之间相关性分析,选取相关性极显著(p<0.01)元素分析线展宽波段作为特征变量。采用回归系数法(RC)作为X自变量特征提取法,通过设定不同回归系数阈值筛选特征变量,并构建不同特征变量组合的线性偏最小二乘回归(PLSR)模型,依据模型RMSECV(交互验证均方根误差)值选取最优金属元素谱线组合作为提取结果。由于所提取特征包含线性和非线性变量,最终构建秸秆炭CV的非线性精确定量分析模型。

图1 XY双变量特征提取策略Fig.1 XY bivariate feature extraction strategy
1.4 模型构建及效果评价
遗传算法优化及自适应增强的人工神经网络算法(GA-BP-Adaboost)[8]是一种非线性人工神经网络改进模型,一方面采用遗传算法(GA)优化边界函数参数w和b值,另一方面采用多个弱预测器对数据集中每个样本进行训练并不断调整样本权重D,同时为每个弱预测器分配权重alpha以计算最终强预测器结果。相关计算公式分别为式(1)—式(3)
(1)
(2)
Errori=Errori+(0,Di, j)
(3)
式中,i和j分别为弱预测器和样本序号,Error为每个弱预测器所有样本权重总和。若某个样本被准确预测(小于相对误差率阈值),则该样本权重降低,式(2)中alpha符号取负,所对应Error值不变(+0);若某个样本未能准确预测(大于相对误差率阈值),则该样本权重升高,式(2)中alpha符号取正,所对应Error值变大(+Di, j)。
模型效果主要由均方根误差(RMSE)、 平均相对误差(ARE)和相对标准误差(RSD)来评价[9-10],计算公式如式(4)—式(6)所示。RMSECV越小,则建模效果越好;RSDP和AREP越小,则模型预测精度越高。
(4)
(5)
(6)
2 结果与讨论
2.1 LIBS光谱分析


图2 LIBS谱线Fig.2 LIBS spectral analysis
与非金属元素和重金属元素相比较,营养型金属元素K,Ca,Na和Mg发射线强度较大。原因可能是营养型金属元素的电离能较小,更容易发生能级跃迁至激发态,单位体积内处于激发态的原子数更多,谱线强度更大。又由于K,Na,Ca,Mg和Cr参与农作物生理生长作用过程,其LIBS分析线可能会对秸秆炭CV表现出更高敏感性。
2.2 XY双变量特征提取
首先采用Y因变量特征提取法获取与CV具有显著相关性的特征元素谱峰波段,结果如表2所示。CV与C,O,H和Na元素浓度相关性较大且相关系数呈现极显著性(p<0.01);与Ca,K和Cr元素浓度相关性相对较低且相关系数呈现显著性(p<0.05);而与S,Mg,Zn,Pb,N,Cu和P元素浓度无相关性。由于秸秆炭中C,O和H主要以碳单质、 芳香环、 羧基、 醚键和硅氧键等形式存在[13],能够显著提升秸秆炭CV。因此,选取C,O,H和Na元素的LIBS谱峰波段作为Y因变量特征提取结果。
采用X自变量特征提取法获取全波段PLSR模型回归系数较大值作为CV特征变量,结果如图3(a)所示。当回归系数阈值分别设为15×10-5,10×10-5,5×10-5,4×10-5,3×10-5,2×10-5和1×10-5时,其所构建PLSR模型的RMSECV结果如图3(b)所示。结果表明:随着阈值逐渐减小,RMSECV值先减小后增大。原因可能是:当RMSECV降低时,CV模型中线性相关性元素Ca,Cr,Mg和K的分析线光谱逐渐被选中;当RMSECV升高时,CV模型中非线性相关性元素光谱和噪声信息逐渐被选中。当阈值为4×10-5时RMSECV降至最小值0.61,所选取49个特征变量数为X自变量特征提取结果。

表2 CV与元素相关性分析Table 2 Correlation analysis between CV and elements

图3 回归系数法阈值选取 (a): 全波段PLSR模型回归系数;(b): 不同回归系数阈值模型结果Fig.3 Threshold selection of regression coefficient method (a): Full band PLSR model regression coefficient; (b): Model results with different regression coefficient thresholds
综上所述,XY双变量特征提取法获取的CV特征变量结果如图4(a)所示。Y因变量特征提取法主要包括C,O,H和Na元素分析线展宽波段,X自变量特征提取法主要包括Ca,Cr,Mg和K元素分析线光谱,并且二者无交集。分别构建X单变量、Y单变量和XY双变量特征PLSR模型,由图4(b)得出双变量特征模型的RMSECV值最小,表明XY双变量特征提取法能够成功获取CV特征变量。然而由于该方法获取了大量非线性特征变量,有必要构建非线性多元回归模型以提升模型预测性能。

图4 XY双变量特征提取结果 (a): XY双变量特征提取结果;(b): 三种特征变量模型效果比较Fig.4 XY bivariate feature extraction results (a): XY bivariate feature extraction results; (b): Comparison of three feature variable model
2.3 非线性特征模型构建及预测
在构建GA-BP-Adaboost特征模型前,需要提前采用GA和Adaboost对BP-ANN模型参数进行寻优以构建较为稳健的非线性特征模型。相关参数设置:GA参数中迭代次数为20,种群规模为20;Adaboost参数中弱预测器个数设为20,双隐含层数均为1,输入层、 隐含层和输出层传递函数分别为tansig,tansig和purelin; 训练函数为trainbr,学习速率和学习目标均设为0.01。
对于GA-BP部分,当交叉概率设为0.8~0.95,步长为0.05,变异概率设为0.05~0.5,步长为0.05时,所对应平均适应度值如图5(a)所示。当变异概率逐渐减小,交叉概率逐渐增大时,平均适应度值呈现降低趋势。当变异概率和交叉概率分别为0.1和0.95时,平均适应度降至最小值80.98。又由于适应度函数为预测绝对误差和,适应度越小表明模型预测越准确。对于BP-Adaboost部分,由于20个弱预测器模型对每个训练样本的相对误差率(RE)范围为0~7.15%,将RE阈值设为0.05~0.30,步长为0.05,结果如图5(b)所示。观察得出,随着RE值增大,AREP和RSDP值总体呈现先减小后增大趋势。因此,将变异概率、 交叉概率和RE值分别设为0.1,0.95和0.01用于进一步的GA-BP-Adaboost模型构建。
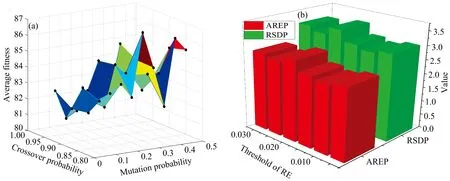
图5 GA和Adaboost参数优化 (a): GA参数优化;(b): Adaboost参数优化Fig.5 Optimization of GA and Adaboost parameters (a): GA parameter optimization; (b): Adaboost parameter optimization
将所提取特征变量数据经主成分分析(阈值参数设为99.93%),并基于优化后的参数构建GA-BP-Adaboost模型,将模型结果与线性PLSR模型效果相比较,结果如图6所示。与PLSR特征模型相比较,GA-BP-Adaboost特征模型中大部分样本(1~3,5,7~17,19,20)的预测值与测定值更为接近,AREP和RSDP分别降低了0.82%和0.91%。结果表明:非线性GA-BP-Adaboost模型效果较优,原因可能是XY双变量特征提取法获取了大量非线性特征变量,而神经网络模型通过多个神经元的深度训练能够较好地实现非线性特征变量的拟合。与Song等[2]所构建CV特征模型结果相比较,本研究所构建PLSR和GA-BP-Adaboost模型的RSDP值分别下降了0.34%和1.25%。原因可能是:Song等采用了一种集成变量选择法,即将回归系数法、 套索法、 竞争性自适应重加权算采样法、 递归加权偏最小二乘法、 显著性多元相关法、 最小冗余最大相关性选取的6个变量子集分别构建PLSR模型,根据RMSECV值选取前3个变量子集合并作为最终集成变量特征提取结果。然而该方法所选用的特征提取方法均属于X自变量特征提取法,仅能提取符合朗伯比尔线性定律的金属元素谱线,无法提取与CV相关的C和O等非金属元素特征谱线。因此,将XY双变量特征提取法与GA-BP-Adaboost非线性多元回归模型相结合能够显著提升传统X自变量特征模型效果,可以用于秸秆炭CV精准预测。
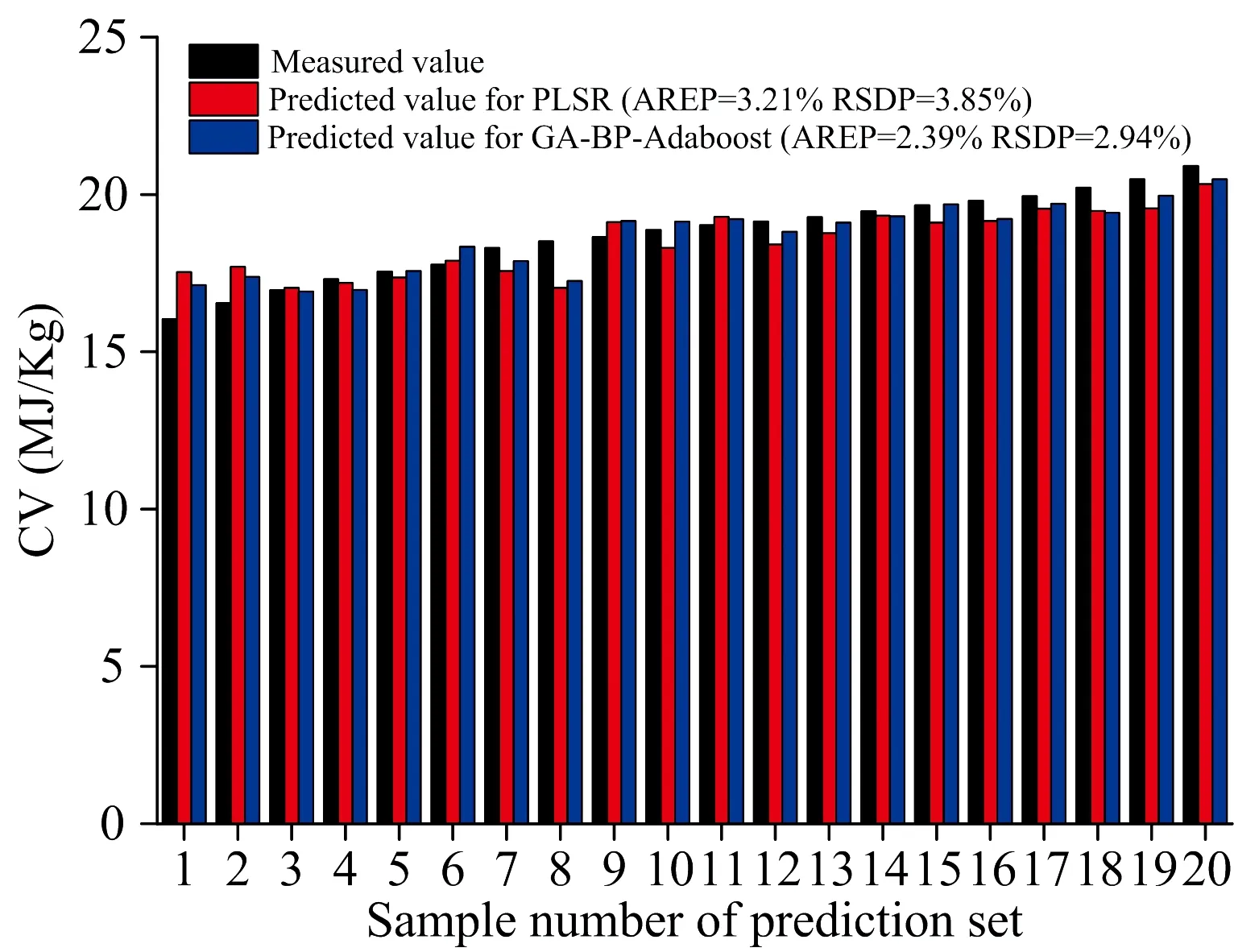
图6 模型预测结果Fig.6 Model prediction results
3 结 论
针对传统X自变量特征提取方法在LIBS定量分析秸秆炭CV过程中缺陷问题,提出了一种XY双变量特征提取法。首先分析了秸秆炭CV与各元素含量之间相关性,基于相关性显著性分析结果选取与CV相关的Y型特征变量,主要包含C,O,H和Na元素分析线展宽波段;同时通过筛选多变量线性模型回归系数阈值获取与CV相关的X型特征变量,主要包含Ca,Cr,Mg和K元素分析线光谱。进一步采用所提取特征变量构建秸秆炭CV非线性神经网络模型,其AREP和RSDP值明显低于相关文献报道的特征模型结果。结果表明:XY双变量特征提取法结合GA-BP-Adaboost模型可以用于秸秆炭CV精确定量预测分析。
猜你喜欢
中国科技财富(2022年8期)2022-12-18
物理学报(2022年10期)2022-06-04
天津诗人(2021年1期)2021-11-12
科技视界(2019年23期)2019-09-28
现代商贸工业(2017年30期)2018-01-22
江苏农业科学(2017年10期)2017-07-21
江苏农业科学(2017年10期)2017-07-21
试题与研究·高考理综化学(2016年3期)2017-03-28
科技与创新(2014年3期)2014-04-14
试题与研究·高考理综化学(2009年1期)2009-03-02
