
面向日志完备性的事件日志采样方法
2022-11-07 04:27张帅鹏曾庆田李彩虹
计算机集成制造系统 2022年10期
苏 轩,刘 聪+,张帅鹏,曾庆田,李彩虹
(1.山东理工大学 计算机科学与技术学院,山东 淄博 255000;2.山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引言
流程挖掘[1-3]是连接数据科学和业务流程管理领域的新颖学科,其目的是从事件日志中提取业务流程的有效信息,发现、监控和改进真实的业务流程[4]。人们对流程挖掘日益增长的兴趣主要有两个驱动因素:①越来越多被记录下来的事件提供了流程历史的详细信息;②需要在竞争激烈且瞬息万变的环境中改进和支持业务流程。流程挖掘还包括流程预测[5-6]和业务流程自动化[7]等子领域,流程发现是最具挑战性的流程挖掘任务之一,其可以在不使用任何先验信息的情况下从事件日志中发现流程模型,近年来受到了外界的广泛关注。在过去的20年中,国内外学者已经提出各种流程发现方法,如Alpha Miner[8],Heuristics Miner[9],Inductive Miner[10],Tsinghua-Alpha[11],Split Miner[12]等,然而由于I/O和内存等硬件限制,大多数发现方法不再适用于使用一台机器处理整个大型数据集的模型发现。若依靠当前的分布式平台重新实现现有的流程发现算法,如著名的MapReduce框架[13-14],则流程将非常耗时,而且这些方法不具有普适化,需要开发人员对底层发现方法有广泛的了解,因此迫切需要一种新方法来解决这些问题。
事件日志采样技术为上述问题提供了一种可行性方案,其将原始事件日志作为输入,返回一个样本日志。事件日志采样技术不是要求重新实现现有发现方法,而是希望能够提供一种提高发现效率的替代方法。目前已经提出许多事件日志采样技术,以LogRank日志采样技术[15-16]为例,该技术实现了一个基于图的排序算法,所得样本日志比原始日志小得多,处理效率也更高。在此基础上提出的一种基于轨迹相似度的事件日志采样技术LogRank+[17],虽然能够确保采样质量,缩短采样时间,提高采样效率,但是其性能仍然不能满足实际应用的需求,例如得到的模型质量不够理想,而且随着原始日志规模的增大,原始日志采样时间与样本日志挖掘时间之和与原始日志挖掘时间之间的差异愈发明显。
受传统集合覆盖等相关问题的启发,借助传统算法如动态规划、贪心算法、排序算法等,本文提出面向日志完备性的事件日志采样方法,包括完全遍历采样法(BF-Sampling)、集合覆盖采样法(SC-Sampling)、基于轨迹长度的采样方法(TL-Sampling)和基于轨迹频次的采样方法(TF-Sampling)4种,该方法保留了原始日志更多的信息,能够更有效地支持日志采样,而且与已有采样方法相比,4种采样方法可以得到更简单、更高质量的流程模型。为了验证这种保证日志完备性的事件日志采样方法的可行性与高效性,从模型质量评估和时间性能分析两方面进行实验,比较4种采样方法得到的样本日志与原始日志的质量,最终说明本文所提4种新的采样方法可以在保证模型挖掘质量的前提下,大幅提高模型挖掘效率,具备可行性与高效性。
1 基础知识
本章介绍后期研究4种事件日志采样方法和两种实验评估方法需要用到的基本知识。假设S为一个集合,∅表示空集,B(S)为集合S所有多集的集合;f:X→Y是一个函数,其中dom(f)为其定义域,cod(f)={f(x)|x∈dom(f)}为函数的值域;在集合S上长度为n的序列为一个函数σ{1,2,…,n}→S。若σ(1)=a1,σ(2)=a2,…,σ(n)=an,则σ=a1,a2,…,an;S*为定义在集合S上所有任意长度有限序列的集合。
定义1事件、轨迹、事件日志。给定A是一个活动的集合,一个轨迹σ∈A*是一系列的活动。对于1≤i≤|σ|,σ(i)表示轨迹σ中的第i个事件,L∈B(A*)是一个事件日志。一个事件日志记录了某个潜在业务流程的执行情况,该业务流程对应的业务流程模型即为流程挖掘的任务目标,因此并未在事件日志的定义中显式地出现。业务流程实例的执行情况由相应的轨迹表示,轨迹中的事件记录在事件日志中。
定义2流程发现。设UM是所有流程模型的集合,一个流程发现方法指从一个事件日志L∈B(A*)映射到一个流程模型pm∈UM的函数γ,即γ(L)=pm。一般来说,流程发现方法能够将事件日志转换为有标记的Petri网、业务流程建模标注(Business Process Modeling Notation,BPMN)、流程树等表示的流程模型。无论流程模型采用什么表示方法,输入事件日志中的每个轨迹都对应发现的流程模型中的一个可能的执行序列。
定义3直接跟随活动关系。假设事件日志L中的一条轨迹为a,b,c,e,f,则a,b,c,e,f是σ的5个活动,如果活动b紧紧跟随在活动a之后,则称在轨迹σ中从a到b存在直接跟随活动关系,记作a,b。因此轨迹σ的直接跟随活动关系有4对,分别为a,b,b,c,c,e,e,f。
2 方法概述
本章提出两个研究目标:①寻找一种事件日志采样方法,使样本日志不仅具有足够的代表性,还能覆盖原始事件日志中的所有行为,而且相比已有采样方法更加高效;②分别从时间性能分析和模型质量评估两方面衡量样本日志相对于原始事件日志的质量。
目标①的解决方案提供了一种方法,即相比已有事件日志采样方法,将大规模事件日志更快更准确地采样为较小的样本日志,以便更高效地进行分析;目标②的答案用于验证事件日志采样方法的有效性和评估样本日志的质量,以证明事件日志采样方法的可行性。
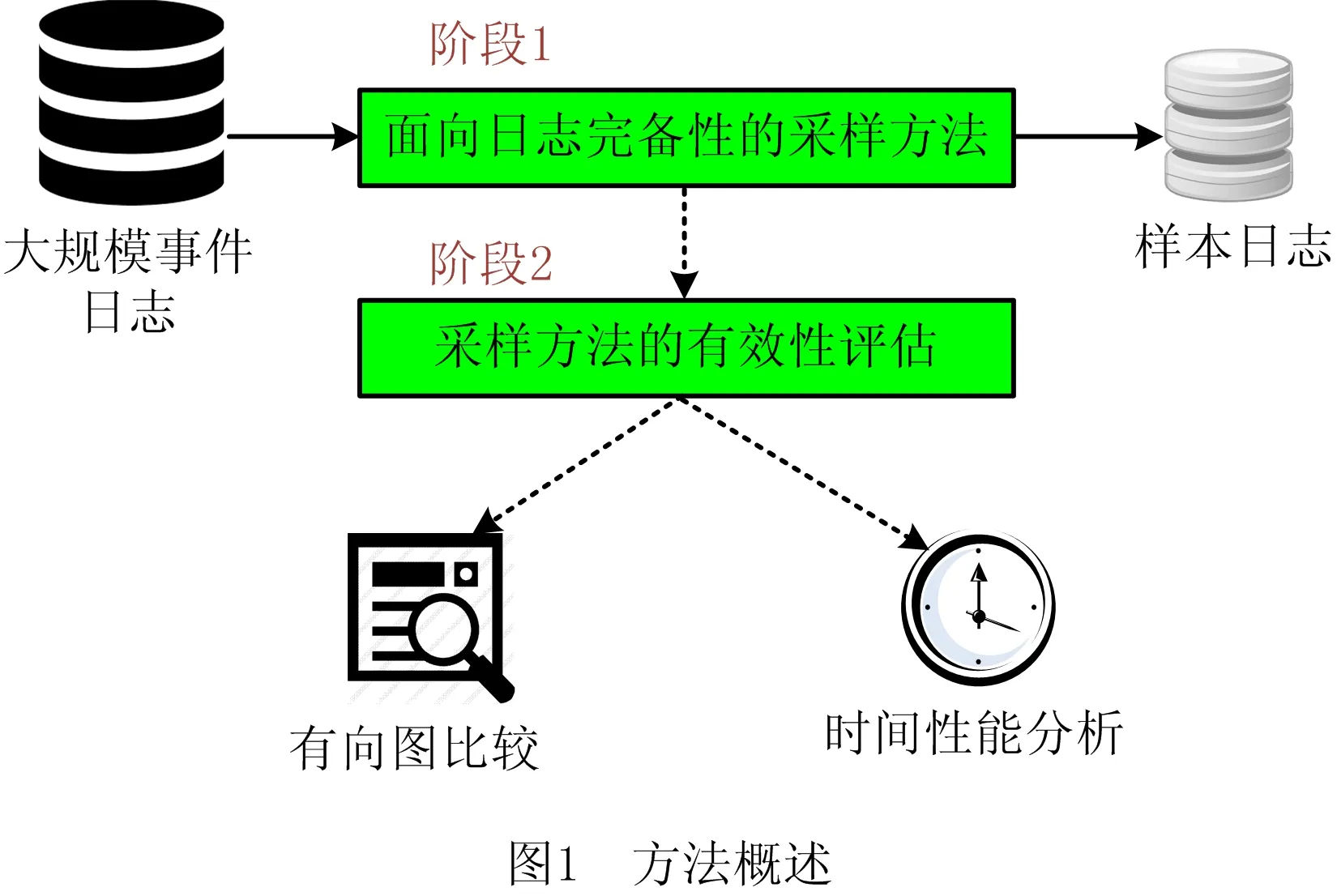
为了实现这些研究目标,图1展示了所用方法的概述,包括以下两个阶段:
(1)阶段1——事件日志采样
事件日志采样技术将一个事件日志L∈B(A*)映射到另一个事件日志L′∈B(A*)中,其中L′⊆L,L为原始事件日志,L′为L的一个样本日志,与原始事件日志L相比,L′小得多,而且可以准确地代表L。
本文提出的面向日志完备性的4种事件日志采样方法分别为完全遍历采样法、集合覆盖采样法、基于轨迹长度的采样方法、基于轨迹频次的采样方法。
(2)阶段2——采样技术的有效性评估
为验证4种事件日志采样方法的有效性,提出两种评估方法:
1)模型质量评估 首先通过比较原始日志和样本日志的有向图是否相同,间接地说明样本日志中的行为与原始事件日志中的代表性行为是否相同,若比较结果相同,则将原始日志与从样本日志中挖掘的模型进行拟合度计算[19],拟合度值为1表示样本模型可以重新生成原始日志中的所有轨迹,低拟合度表明原始日志中的大部分行为不能被样本模型重演。此外,通过准确度[20]指标量化样本日志相对于原始日志的质量,准确度值为1表示样本模型生成的所有轨迹都包含在原始日志中,低精确度则表明样本模型允许原始日志外更多的行为。最后,通过拟合度和准确度的调和平均值F-measure[18]来评价模型的优劣。
2)时间性能分析 首先计算原始日志采样时间与样本日志挖掘时间之和,再将其与原始日志挖掘时间进行比较,原始日志采样时间与样本日志挖掘时间之和越短,采样效率越高,事件日志采样方法越高效。
3 业务流程事件日志采样
本章首先给出4种事件日志采样方法的具体思路,其次介绍两种实验评估方法。下面给出一个示例日志(表示为L),用于介绍面向事件日志完备性的采样方法。该日志包括5条轨迹,共有5个变体和6个事件,记σ(1)=a,d,e,σ(2)=a,b,c,e,σ(3)=b,c,e,f,σ(4)=b,d,f,σ(5)=c,d,L=[a,d,e,a,b,c,e,b,c,e,f,b,d,f,c,d]。示例日志L的轨迹的初始点集合StartSet、结束点集合EndSet、日志直接跟随关系集合dfrSetLog和轨迹直接跟随关系集合traceIDToDFRSet分别为:
StartSet=[a,b,c];
EndSet=[e,f,d];
dfrSetLog=[a,d,d,e,a,b,b,c,
traceIDToDFRSet=[{a,d,d,e},{a,b,
3.1 日志完备性采样方法
3.1.1 完全遍历采样法
完全遍历采样法的思路如下:从原始事件日志第一条轨迹开始依次遍历,若轨迹的直接跟随关系集合与日志直接跟随关系集合有交集,且满足轨迹的开始点与开始点集合有交集或轨迹的结束点与结束点集合有交集,则将该条轨迹加入样本日志,并删除以下3部分:①日志直接跟随关系集合与新轨迹的直接跟随关系集合的交集;②开始点集合与新轨迹开始点的交集;③结束点集合与新轨迹结束点的交集。直到日志直接跟随关系集合、开始点集合、结束点集合均为空,停止轨迹遍历。完全遍历采样法的伪代码如算法1所示。
算法1完全遍历采样法。
输入:原始日志。
输出:样本日志。
1: Initialization(算法开始)
2: N∈ |L|
3: For i∈1 To N Step 1
4: StartSet1 {σ(0)}
5: EndSet1 {σ(|σ |-1)}
6: If(dfrSetLog∩traceIDToDFRSet !=∅)∨(StartSet1 ∩StartSet !=∅)∨(EndSet1 ∩ EndSet !=∅) Then
7: SampleLog L(i)
8: dfrSetLog dfrSetLog-(dfrSetLog∩traceIDToDFRSet)
9: StartSet StartSet-(StartSet1∩StartSet)
10: EndSet EndSet-(EndSet1∩EndSet)
11: Else break;
12:End(算法结束)
3.1.2 集合覆盖采样法
本文给出集合覆盖采样法的伪代码,如算法2所示。集合覆盖采样法主要借助集合覆盖问题的贪婪算法求解思想,具体思路如下:首先遍历所有轨迹的直接跟随活动关系,选择一条覆盖了最多未覆盖直接跟随活动关系的轨迹(即与日志直接跟随活动关系集合拥有最大交集的轨迹);然后将所选轨迹加入样本日志,删除其覆盖的日志直接跟随活动关系、开始点与开始点集合的交集、结束点与结束点集合的交集;最后重复前两步,直到日志直接跟随活动关系集合、开始点集合、结束点集合3个集合均为空集时结束遍历。
算法2集合覆盖采样法。
输入:原始日志。
输出:样本日志。
1:Initialization(算法开始)
2:N |L|
3:For i 1 To N Step 1
4: StartSet2 {σ(0)}
5: EndSet2 {σ(|σ|-1)}
6: If Max (dfrSetLog∩traceIDToDFRSet(i)) Then
7: SampleLog L(i)
8: dfrSetLog dfrSetLog-(dfrSetLog∩traceIDToDFRSet(i))
9: StartSet StartSet-(StartSet2∩StartSet)
10: EndSet EndSet-(EndSet2∩EndSet)
11: Else break;
12:End(算法结束)
3.1.3 基于轨迹长度的采样方法
定义4轨迹长度。轨迹σ的长度记为|σ|。日志中的所有事件是全序的,即整个日志可以看作为一个事件序列,然而整个日志的长度通常并不是该序列的长度,而是日志中所包含的轨迹数,因为轨迹是一个相对完整的逻辑单位。假设一条轨迹σ=a,b,c,e,f,a,b,c,e,f是σ的5个事件,则称L中σ的轨迹长度为5,即|σ|=5。日志L中第i条轨迹长度表示为|L(i)|。
根据定义4,基于轨迹长度的采样方法思想如下:首先统计原始事件日志中每条轨迹的长度,将轨迹和其对应的长度存储到一个集合中;然后按照轨迹长度降序排列,从最长的轨迹开始依次向下遍历,筛选样本日志轨迹的方法与完全遍历采样法相同。基于轨迹长度的采样方法伪代码如算法3所示。
算法3基于轨迹长度的采样方法。
输入:原始日志。
输出:样本日志。
1:Initialization(算法开始)
2:N |L|
3:For i 1 To N Step 1
4: TraceLength(i) |σ(i)|
6:For j MaxLength To MinLength Step 1
7: StartSet3 {σ(0)}
8: EndSet3 {σ(|σ|-1)}
9: If(dfrSetLog ∩ traceIDToDFRSet(j)!=∅)∨(StartSet3∩StartSet!=∅)∨(EndSet3∩EndSet!=∅)Then
10: SampleLog L(i)
11: dfrSetLog dfrSetLog-(dfrSetLog∩traceIDToDFRSet(j))
12: StartSet StartSet-(StartSet3∩StartSet)
13: EndSet EndSet-(EndSet3∩EndSet)
14: Else break;
15:End(算法结束)
3.1.4 基于轨迹频次的采样方法

根据定义5,基于轨迹频次的采样方法思想如下:从原始事件日志的第1条轨迹开始,依次统计每条轨迹出现的次数,同时将轨迹和其对应的频次存储到一个集合中;统计完成后进行去重操作,只保留相同轨迹的频次最大值;最后按照轨迹频次降序排列,从频次最大的轨迹开始依次向下遍历,筛选样本日志轨迹的方法与完全遍历采样法相同。基于轨迹频次的采样方法伪代码如算法4所示。
算法4基于轨迹频次的采样方法。
输入:原始日志。
输出:样本日志。
1:Initialization(算法开始)
2:N |L|
3:For i 1 To N Step 1
5:For i 1 To N Step 1
6: If TraceFrequency(i) HasNextSameTrace Then
7: TraceFrequency (TraceFrequency-TraceFrequency(i))
9:For j MaxFrequency To MinFrequency Step 1
10: StartSet4 {σ(0)}
11: EndSet4 {σ(|σ|-1)}
12: If(dfrSetLog∩traceIDToDFRSet(j)!=∅)∨(StartSet4∩StartSet!=∅)∨(EndSet4∩EndSet!=∅)Then
13: SampleLog L(i)
14: dfrSetLog dfrSetLog-(dfrSetLog∩traceIDToDFRSet(j))
15: StartSet StartSet-(StartSet4∩StartSet)
16: EndSet EndSet-(EndSet4∩EndSet)
17: Else break;
18:End(算法结束)
3.2 采样方法的有效性评估
为了系统地评估4种采样方法得到的样本日志相比原始日志的质量,同时与之前的采样方法进行比较,本文采用模型质量评估和时间性能分析两种评估方法。
3.2.1 模型质量评估
为了评估模型质量,先引入直接跟随活动关系集合和样本日志完备性定义:


图2直观地展示了定义7中样本日志完备性的概念,图中I.M表示对日志采用Inductive Miner流程发现方法,PN1=PN2表示原始日志Petri网和样本日志Petri网在保证样本日志完备性时需满足的条件。

因为有向图可分别对比样本日志和原始日志对应的直接跟随图、边集(即直接跟随活动关系集合)和顶点集(即活动集合),所以模型质量评估实验通过比较原始日志和样本日志的有向图是否相同,来间接验证样本日志相比原始日志的质量,从而判断采样方法是否保证了样本日志的完备性。进而,为了量化事件日志采样方法所得样本日志的质量,将样本日志采用Inductive Miner方法发现一个流程模型,与原始日志进行一致性检查,通过拟合度指标来量化原始日志中轨迹可以被样本模型从头到尾重演的比例。
最后,通过比较4种事件日志采样方法针对同一业务流程事件日志得到的准确度指标和F-measure值,判断其是否均有效可用。
3.2.2 时间性能分析
时间性能分析实验通过比较原始日志挖掘时间和采样挖掘时间(包括原始事件日志采样时间、样本日志挖掘时间)的大小来验证4种事件日志采样方法的采样效率,若原始日志挖掘时间比采样挖掘时间大,则证明采样方法提高了采样效率。另外,还对4种采样方法进行相互比较,从而找出其中最快的采样方法。
4 工具实现
在开源流程挖掘工具平台ProM 6中为流程挖掘提供了一个完全可插拔的实验环境,其可通过添加插件进行扩展,目前包括1 600多个插件,该工具和所有插件都是开源的。本文所提4种事件日志采样技术已作为插件(称为Business Process Event Log Sampling Plugin)在ProM中实现,该工具的快照如图3和图4所示,其以一个事件日志作为输入,选择采样方法后输出一个样本日志。


在验证面向日志完备性的4种事件日志采样方法的模型质量评估实验中,采用图5所示的在ProM平台中实现的Compare two event log dfg sampling Plugin插件与原始日志和样本日志的边集(即直接跟随活动关系集合)、顶点集(即活动集合)进行比较,该插件以原始事件日志和样本日志为输入,直接输出比较结果。

5 实验评估
本章介绍对面向日志完备性的事件日志采样方法进行实验时使用的事件日志数据集,然后分析模型质量评估和时间性能评估两个实验的结果。本次实验评估采用一台2.70 GHz CPU、Windows 10专业版、Java SE 1.8.0_281(64位)和Python 3.7.6(64位)的笔记本电脑,并分配有12 GB RAM。
5.1 实验数据集
实验共使用9个公开事件日志数据集(https://figshare.com/articles/dataset/Event_Log_Sampling_Datasets/20354505),分别对所提4种事件日志采样方法进行实验评估。表1所示为这些事件日志的部分主要统计数据,包括轨迹数、变体数、事件数、活动数,以及轨迹长度的一些信息。
(1)exercise数据集 该数据集是由论文评审流程模型生成的仿真日志,每条轨迹均详细清晰地描述了评审论文的流程。
(2)training_log_1/3/8数据集 这3个数据集是人工训练的用于2016年流程发现竞赛(PDC 2016)的仿真日志,每条轨迹由事件所引用的流程模型活动的名称和事件所属案例的标识符两个值组成。
(3)Production数据集 该数据集包括生产流程中的流程数据,每条轨迹包括案例、活动、资源、时间戳和更多数据字段的数据。
(4)BPIC_2012_A/O/W数据集 该数据集源自荷兰一家金融机构的个人贷款申请流程,事件日志中表示的流程是全球融资组织中个人贷款或透支的申请流程,每条轨迹描述了不同客户申请个人贷款的流程。
(5)CrossHospital数据集 该数据集包括医院急诊病人的治疗流程数据,每条轨迹表示医院里一位急症患者的治疗流程。

表1 实验日志概述

续表1
5.2 模型质量评估结果
模型质量评估实验得到的有向图比较结果如图6所示,示例日志采用BPIC_2012_W数据集,示例方法为完全遍历采样法,因为其他3种采样方法与该方法结果相同,所以不再赘述。采用Python方式比较原始日志直接跟随图和样本日志直接跟随图,得到的比较结果相同,表明从样本日志中发现的流程模型可有效替代从原始日志中发现的流程模型。通过对9个公开事件日志数据集进行实验,并比较返回的结果可知,原始事件日志与样本日志的边集和顶点集均相同,证明了4种事件日志采样方法能够保证日志的完备性。
首先根据原始事件日志和4种事件日志采样方法对应的样本日志得到的Petri网[2]进行拟合度测量,测出的拟合度均为1(如图7),证明4种事件日志采样方法能够保证从样本日志中发现的模型可以完全代表原始日志中的行为,即100%拟合,有力地证明了所提采样方法能够保证日志采样质量。

测得的准确度如图8所示。通过柱状图可以发现,对于同一业务流程事件日志,即使选择的采样方法不同,得到的准确度值也完全相同,证明4种事件日志采样方法相互之间的结果没有偏差,均可在保证日志完备性的前提下进行采样。最后根据准确度和拟合度计算出的F-measure值如图9所示,可见虽然不同业务流程事件日志的F-measure值不同,但是相同事件日志使用不同采样方法得到的结果完全相同,进一步印证了4种事件日志采样方法的可行性与高效性,是符合预期的。
5.3 时间性能分析结果
实验共测量并记录了3种类型的时间:①原始日志挖掘时间;②使用4种采样方法的采样时间;③样本日志挖掘时间。由于每次实验时电脑内部环境可能存在差异,且每次测出的时间与上次相比不可能完全相同,为了保证实验结果的准确性,对9个事件日志应用4种采样方法的3个时间分别测量5次取平均值,最后将4种采样方法各自的采样时间与样本日志挖掘时间求和,再与原始日志挖掘时间比较。
时间性能分析结果如图10所示,图中纵坐标为实验使用的采样方法,分别为本文所提的4种采样方法和未使用采样方法(Non-Sampling)。


实验得到如下3个结论:
(1)将样本日志与原始日志比较,当日志规模较大时,样本日志挖掘时间远小于原始日志挖掘时间,证明使用样本日志替代原始日志进行相应操作可以极大提高操作效率。
(2)执行时间和质量通常会随日志规模的减小而缩减,不同的是,执行时间随日志规模的减小而急剧缩短,事件日志的规模越大,原始日志采样时间与样本日志挖掘时间之和小于原始日志挖掘时间越多。因此,在实际应用时,可以考虑根据具体需求在发现效率和样本日志质量之间寻找平衡点,通过选择合适的采样方法对原始日志进行处理,从而优化流程挖掘流程,加快操作速度,提高准确度。
(3)通过比较4种采样方法的结果可见,随着原始事件日志规模的增大,虽然4种采样方法得到的样本日志挖掘时间相差无几,但是采样时间之间的差异呈递增趋势。相比其他3种采样方法,在保证样本日志质量的前提下,基于轨迹长度的采样方法的采样时间最短。
6 结束语
给定一个大规模事件日志,为了高效地从中选择能够保证日志完备性的代表性样本日志,本文提出完全遍历采样法、集合覆盖采样法、基于轨迹长度的采样方法和基于轨迹频次的采样方法4种事件日志采样方法,并从时间性能分析和模型质量评估两方面评估样本日志相对原始日志的质量。所提4种采样方法已作为插件在开源流程挖掘工具平台ProM6中实现。在9个公开事件日志数据集上的实验结果表明,相比已有采样方法,所提4种采样方法不仅能够大幅提高日志采样效率,还能保证模型的完整性。

未来将从3个方面进行深入研究:①本文在探讨4种事件日志采样方法的有效性时只针对普通事件日志,未来将研究包含生命周期信息的事件日志采样方法;②在分布式系统[22]上部署4种事件日志采样方法,以便处理现实生活中其他信息系统收集的超大规模事件日志;③将本文所提事件日志采样方法应用于面向特定领域的事件日志,如教育、医疗、金融、制造业等。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
华人时刊(2021年13期)2021-11-27
今日农业(2021年10期)2021-07-28
心声歌刊(2020年4期)2020-09-07
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
劳动保护(2018年5期)2018-06-05
高校招生(2017年7期)2017-06-30
