
基于注意力机制的业务过程异常检测方法
2022-11-07 04:26孙晋永周博文闻立杰邓文伟孙志刚
计算机集成制造系统 2022年10期
孙晋永,周博文,闻立杰,许 乾,邓文伟,孙志刚
(1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004;2. 清华大学 软件学院,北京 100084;3.广西师范大学 计算机科学与工程学院,广西 桂林 541004)
0 引言
过程感知信息系统(Process Aware Information System, PAIS)被广泛应用于各行各业来处理大量业务过程,在其运行过程中,业务过程可能发生异常,包括可预期异常(如资源缺失、业务过程超时等)和不可预期异常[1]。异常会使业务过程偏离预定目标,给用户带来不可预料的损失,例如对未核查征信信息的用户放贷、已发货的网购订单被退款等,尽早发现异常并及时采取措施可以减少或避免损失。业务过程异常检测技术能够帮助管理者及时发现业务过程中潜在的执行风险,进而采取相应的处理措施,因此业务过程异常检测是PAIS必须支持的功能。
不确定性和多变性是现代企业业务过程的内在特点,传统的基于过程模型和规则约束的异常检测方法已无法满足柔性业务过程管理技术的需要[2]。DELIMABEZERRA等[3-4]采用过程挖掘算法从事件日志中挖掘出过程模型,进而通过检查过程模型与事件日志的一致性来检测业务过程是否异常。该方法可以检测业务过程控制流的异常,但因为没有利用事件的属性信息,所以不能检测事件属性的异常,而且挖掘高质量的过程模型依赖一个无噪声的事件日志,其维护成本高且较难实现。
通常业务过程异常发生的实际原因是事件单个属性值异常[5],例如用户未经许可执行了某项活动,这种异常表现为该事件用户属性值异常。业务过程的异常检测方法必须能够检测事件属性级别的异常才能发现上述异常,因此检测业务过程中事件属性级别的异常非常重要。
CHANDOLA等[6]将离散序列的异常检测方法分为基于概率、基于距离、基于重构、基于领域和基于信息论方法5类。并提出实际的业务过程实例事件包含多个属性,如何处理这种事件的序列是一个亟需解决的问题;BÖHMER等[7]采用业务过程的状态概率图进行异常检测,状态概率图中的顶点表示事件或属性,有向边表示业务过程的状态转移,采用统计方法对边赋予权值以表示该状态转移的概率,并根据状态概率图对业务过程进行端到端地分析,小概率的事件或事件属性的状态转移被认为异常,该方法适用于有噪声的事件日志,可以检测事件属性异常,不足之处是因使用固定的顺序检测事件属性,而引入了对某些事件属性的偏好。
NOLLE等[8]提出基于重构事件序列的业务过程异常检测方法,通过将业务过程的事件序列作为输入数据训练一个自编码器来重构该序列,自编码器对正常事件序列和异常事件序列的重构误差不同,采用重构误差的平均值作为异常阈值,大于阈值的序列被认定为异常序列,该方法能成功检测出业务过程事件日志中的控制流异常,不足之处是只能检测业务过程案例级别的异常;在此基础上,NOLLE等[9]在自编码器的输入中加入数据流,可以检测业务过程中数据流的异常和检测业务过程属性级别的异常,提高了异常检测的准确性,但没有考虑事件的时间属性。为了解决以上问题,NOLLE等[10]提出基于深度神经网络并考虑事件时间属性的多变量异常检测方法BINet,该方法采用长短期记忆神经网络(Long Short Term Memory,LSTM)构建预测过程实例的下一事件概率模型,采用预测误差[11]进行异常检测,并采用“肘方法”确定异常检测阈值,进一步提高了异常检测的准确性,不足之处是无法处理事件序列的长距离依赖。
目前LSTM已被用于不同领域时间序列的异常检测,如声学异常检测和视频异常检测。JOERG等[12]和TAX等[13]采用LSTM预测当前业务过程实例的下一个事件,在较复杂的业务过程中取得了较好的准确率,但无法捕获事件序列的长距离依赖,影响下一个事件预测的准确率;孙笑笑等[2]提出基于上下文感知的多角度业务流程在线异常检测方法,采用Split Miner算法挖掘[14]过程模型,在过程模型上用重演技术生成行为上下文,以其他事件属性为数据上下文,从行为、时间和属性3个角度进行异常检测,该方法的优点是从多个视角检测业务流程执行的异常,其异常检测全面,不足是只能确定异常类型,无法定位引发异常的具体事件属性。
近年来,Transformer神经网络模型在自然语言处理(Nature Language Processing, NLP)任务有优秀的表现。自然语言和业务过程都是一种离散的序列数据,不同的是,自然语言由不同语义的字和词组成,而业务过程的事件序列由不同语义的事件组成,事件具有属性,而且不同事件的属性集可能不同。
鉴于Transformer模型的注意力机制能够捕获长距离端到端的依赖关系,具有很强的特征提取能力,本文选用Transformer模型从事件日志中提取业务过程特征。基于此,本文提出一种无需挖掘业务过程模型、无需领域知识和自定义约束的业务过程异常预测方法,通过挖掘事件日志中的控制流和数据流信息构造过程特征数据集,基于Transformer模型构建预测模型,由预测模型预测当前过程实例的下一事件及其属性的概率分布,通过实际发生的事件和该事件的预测结果计算该事件各属性的异常评分,采用异常评分阈值判定事件属性异常,并定位异常来源为发生异常的事件属性。
本文将所提异常检测方法与现有的7种业务过程异常检测方法进行比较,在真实事件日志的数据集上进行评估。实验结果表明,相比于现有的7种方法,本文异常检测方法有效提高了异常检测的准确性,不但可以检测出业务过程事件及其属性异常,而且可以定位异常来源。本文的主要贡献如下:
(1)提出一种无需从事件日志中挖掘过程模型,无需领域知识,也无需对事件日志数据进行手动标记的业务过程异常检测方法。
(2)设计一种采用异常比率的梯度自适应计算异常评分阈值的方法,以应对不同场景下的业务过程异常检测。
(3)设计3种不同的注意力策略,从业务过程的不同视角预测业务过程实例的下一事件。
(4)提出一种可以检测业务过程的事件属性级别异常并能定位引发异常的具体事件属性的方法。
1 预备知识
1.1 事件日志
事件日志是PAIS记录业务过程的执行过程的信息集合,一般由业务过程的执行轨迹组成。为了便于下文的准确表述,本文定义事件、属性、案例和事件日志。
定义1事件、属性、案例[1]。事件是描述业务过程实例运行时的活动及其相关信息的最小单位;属性是描述事件中活动的相关信息的特征;案例是业务过程实例运行时的一个事件序列,对应业务过程的一条执行轨迹。事件常用元组e=(case_id,event_id,attrname,attrstart_time,…,attr…)表示,其中case_id为该事件所属案例的id属性,event_id为该事件的id属性,attrname为该事件的活动名,attrstart_time为该事件开始执行的时间,attr…为事件的其他属性。
典型的事件属性有事件执行角色、组织资源、开始时间和执行时长等,这些属性是事件的必需属性,本文拟采用事件必需的离散属性进行异常检测,如执行角色、组织资源等。
定义2事件日志[1]。事件日志L是案例的集合且L⊆C,可以表示为一个三阶张量L=R|C|×|E|×|A|,其中C为案例的集合,E为事件的集合,A为业务过程事件属性的集合。
按照从低到高的建模层次,业务过程涉及的异常可以分为基础结构异常、工作流异常和运行实例异常,本文提出的业务过程异常检测方法适用于检测业务过程的运行实例异常。
定义3运行实例异常[15]。运行实例异常指业务过程实例中不符合业务流程定义、违反过程约束或不合常理的行为或属性。在事件日志中大多数过程实例能够正常完成的前提下,运行实例异常表现为事件日志中离群的事件和属性值。
需要说明的是,按照对系统产生的影响,运行实例异常可以分为噪音(可容忍或忽略)、特殊异常(只出现在某个工作流实例中)和演变异常(随业务过程的变化而产生的行为变化)3类,本文不分别讨论这3类异常,而主要研究业务过程的运行实例异常检测方法。
1.2 Transformer和注意力机制
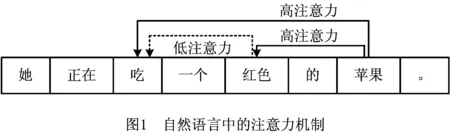
机器学习中的注意力机制是模拟人类对注意力焦点投入更多注意力资源,以达到关注焦点信息,忽略其他无用信息的机制,其核心是在大量信息中筛选出高价值信息,找到当前任务的关键信息。注意力机制广泛应用于自然语言处理领域,如自然语言中语义的注意力机制。
在图1所示的自然语言中注意力机制的句子中,并非每个词都和“苹果”强相关。机器学习中的注意力机制能够发现句子中词与词之间的依赖关系,在训练模型时借助注意力权重关注关键信息,从而提高训练效率和模型质量。注意力的这一特征可以在业务过程的场景下挖掘活动与活动、活动与属性的依赖关系。
Transformer是一种基于编码器—解码器(encoder-decoder)结构的神经网络模型架构,其核心是注意力机制。其中,编码器可以多层堆叠,每层包括多头自注意层和前馈网络层两个子层。多头自注意力层的核心是对两个序列进行按比例缩放的点积注意力运算。对于两个序列SA,SB,点积注意力运算表示为对查询矩阵Q、键—值矩阵K,V进行如下操作:
(1)
式中,若序列SA,SB的长度分别为N,M,则输入变量Q为N×dk维,K为M×dk维,V为M×dv维。在自注意力中(如图2),序列SA,SB为同一个序列H,有dk=dv,N=M。

首先,将Q和K进行点积注意力运算得到维度为N×M的注意力权重矩阵Wa,为序列A到序列B的注意力分布。为了防止点积运算后结果数值过大而导致注意力分布过度集中,用矩阵K的维度dk对注意力权重进行缩放,然后采用Softmax函数计算权重矩阵Wa得到注意力分布,最后将概率分布与矩阵V进行点积计算,得到维度为N×dV的结果,即为由矩阵V根据SA到SB的注意力分布来表示SA序列的各元素。式(1)的作用是根据输入矩阵Q和矩阵K来计算序列SA对序列SB的注意力分布,再由注意力分布与矩阵V计算的结果捕获序列SA和SB之间的依赖关系。
自注意力机制是注意力机制的一个改进(如图2),其将输入数据H投影到3个不同空间得到Q,K,V,即Q=HWQ,K=HWK,V=HWV。函数self_Attention(H,dh)将输入H分别投影到3个不同空间来计算自注意力,从而捕获序列的内部依赖关系:
self_Attention(H,dh)=dot_Attention
(HWQ,HWK,HWV)。
(2)
式中:dh为多头注意力将输入数据根据注意力头数h进行划分得到的维度;WQ∈Rdh×dk,WK∈Rdh×dk和WV∈Rdh×dv。
首先,多头自注意力将输入的编码序列按维度划分成多个子编码序列,并将这些子编码序列映射到不同的向量空间;然后,多头自注意力在每个划分得到的子编码序列上进行自注意力运算;最后,将自注意力运算的结果聚合。如式(2)所示,设输入数据维度为dmodel,h为注意力头数,则每个自注意力头的输入维度为dmodel/h,即dh=dmodel/h。多头注意力的计算方法如下:
head=self_Attention(H,dmodel/h);
(3)
mh_Self_Attention(H,h,s)=
Concate(head1;…;headh)W0。
(4)
式中W0用于将拼接后的矩阵维度压缩为dmodel维,使多头自注意力的输入和输出维度相同,达到可堆叠的目的。式(4)的作用是将输入数据分为h个子空间进行自注意力运算[16],从不同子空间捕获序列的内部依赖关系。
与编码器类似,解码器的每一层包括多头自注意力层和前馈网络层两个子层并附加一个多头编码—解码注意力(encoder-decoder attention)子层,该附加层接收编码器的输出作为其矩阵K和V。关于Transformer模型的注意力机制的更多细节,请参见文献[17]。
2 基于注意力机制的业务过程异常检测方法
基于Transformer模型的注意力机制,本文提出业务过程异常检测方法TransNet(transformer network),方法的总体框架如图3所示。

首先,从控制流和数据流视角在业务过程的事件日志中挖掘出控制流和数据流特征,构造过程特征数据集;然后,基于注意力机制构建预测模型,将以上数据集作为输入数据训练预测模型,根据输入数据预测当前业务过程实例的下一事件及其属性的概率分布;接着,根据实际执行的事件与预测结果的偏差计算事件各属性的异常评分,基于该评分进行异常判断,大于异常评分阈值的事件属性判定为异常属性,并定位该事件属性为异常来源。由于不同业务过程的异常评分阈值不同,本文还设计了一种基于异常比率的、梯度自适应计算事件属性的较优异常评分阈值方法,该方法的两个核心任务是基于注意力机制构建预测模型和基于预测模型结果判定异常。
2.1 事件日志的预处理方法
为了充分利用事件日志中的控制流特征和数据流特征,本文从事件属性粒度提取过程信息,采用事件的离散属性进行异常检测,如执行用户、组织部门等属性。对事件的离散属性采用独热编码方式(one-hotencoding)进行编码,来构造过程特征数据集。
用事件的活动名作为事件的第一个属性代表业务过程的控制流特征,用其他离散属性作为数据流特征。由于每个案例事件序列的长度可能不同,为了保证数据集中各案例的长度相等,在较短的案例末尾添加pad进行填充。例如,某个案例的事件序列为case=e1,e2,e3,e4,其中事件为为案例事件序列中的第i个事件,ci为第i个事件的活动名属性,为第i个事件的其他属性,i=1,2,3,4。该案例的事件序列长度为4,假设数据集中事件序列最大的长度为5,在案例末尾添加pad进行填充,则该案例表示为
(5)
2.2 业务过程预测模型
事件日志中的事件序列具有长度不确定、可能存在并发和循环结构的事件序列、事件及其属性存在长距离依赖等特点。基于深度学习的业务过程实例的下一事件预测大多采用基于循环神经网络(Recurrent Neural Network, RNN)的方法[12-13]。与基于RNN的方法不同,Transformer模型能够关注输入特征序列中的任何一个元素,且不考虑元素之间的距离,这一优势使其更适合处理具有长距离依赖、存在重复出现子序列的业务过程的事件序列[18]。鉴于Transformer模型的注意力机制能够捕捉长期和短期的事件或事件属性的依赖关系,本文采用Transformer模型构建业务过程实例的下一事件预测模型,而且不同的Transformer注意力头可以关注事件编码的不同子空间,从而更加灵活地调整预测模型的注意力策略,使Transformer成为预测业务过程实例下一事件的良好选择。
本文提出的TransNet方法采用编码器—解码器结构的预测模型,事件的每个属性都单独使用编码器进行特征提取,而且每个属性使用单独的解码器预测下一事件该属性的概率分布,编码器和解码器都使用可堆叠的注意力层和全连接层。活动名属性预测模型的结构示例如图4所示。

在训练阶段,为了避免当前流程实例中未发生事件出现“信息泄露”,对编码器和解码器的注意力层均使用掩码(mask),以确保注意力仅应用于当前过程实例已发生的事件特征。例如,解码器在预测活动名属性c3的概率分布时,用[c1,c2]的自注意力和[c1,c2]与[e1,e2]的注意力。
图4所示为预测下一事件活动名属性的预测模型结构的示例,而预测下一事件非活动名属性的模型结构与其不同。本文所提预测模型有控制流预测模块和数据流预测模块两个模块,分别用于预测活动名属性和非活动名属性,如图5所示。为方便描述,本文事件仅使用活动名、用户和时间3个属性。


在图5中,fact为活动名属性特征,fuser和fday分别为用户属性特征和开始执行时间属性特征,t为离散时间步,表示当前过程实例第t个事件的发生时间。

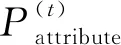
2.3 事件属性的异常评分
考虑到实际的业务过程可能存在并发或循环结构,当前过程实例的下一事件及其属性可能有多个值是合理的。例如,在并发结构中,并发执行的活动有多个可能的后继活动,因此过程实例的下一事件有多个合理的活动名属性。
定义4异常评分[5]。异常评分是一个用于判断业务过程实例的、某事件属性值是否异常的、[0,1]内的实数,用函数fscore(P,pt)表示为
(vi,pi)∈P,(vt,pt)∈P。
(6)
式中:P为所预测事件属性值的概率分布;t为在P中事件属性实际值的下标;vt为事件属性的实际值;pt为在P中事件属性实际值vt的发生概率;pi为在P中事件属性取值的发生概率大于pt的概率;vi为在P中发生概率大于pt的属性值。
由定义4可得,事件属性实际值的发生概率越低,其异常评分越高,越有可能为异常;反之亦然。例如,某个属性有4个可能的离散值{v1,v2,v3,v4},设其概率分布P={(v1,0.1),(v2,0.2),(v3,0.3),(v4,0.4)},若实际发生的属性值为v1,则异常分数fscore(P,0.1)=0.2+0.3+0.4=0.9;若实际发生的属性值为v3,则异常评分fscore(P,0.3)=0.4。
2.4 业务过程异常的判定方法
根据上述方法可以计算出实际发生事件的属性对应的异常评分s,为了判定该事件或属性是否异常,本文采用判定函数
(7)
式中τ为评分阈值。fthre(s,τ)=0表示该事件属性正常,fthre(s,τ)=1表示该事件属性异常。因为不同属性的取值个数|Ba|可能不同,且每种属性的预测难度不同,所以需要为每个属性设定独立的阈值,该阈值的确定方法见2.5节。
2.5 基于异常比率梯度的自适应异常评分阈值确定方法
大多数业务过程异常检测算法的异常阈值为用户根据经验手动设定的某个常数。在不同业务场景下,业务过程异常有较大区别,例如在医疗领域,与正常情况有很小的偏差就被认为异常(如病人的体温);在证券交易领域,证券价格的大幅波动被认为异常。本文提出一种自适应确定事件属性异常评分阈值的方法,以应对过程感知系统中业务过程的不同场景。
首先,根据事件属性的异常评分s确定异常评分阈值的范围,从而确定其最小值τmin和最大值τmax。若评分阈值为τmax,则所有属性值都会被判定为正常;若评分阈值为τmin,则所有属性值都会被判定为异常。于是,将异常评分阈值的取值区间设为[τmin,τmax],在其中构造一个大小为k的候选异常评分阈值集合T,本文方法取k=50。
(8)
事件属性的异常比率为:当异常评分阈值为τi∈T时,在训练数据集中某个事件属性被判定为异常的属性值个数与该事件属性全部属性值个数的比值,即
(9)
式中:D为数据集中非填充事件的个数;C为案例的集合;F为案例的最大事件序列长度;sjk为异常评分集S中第j个案例的第k个事件中该属性值的异常评分。特别地,设定r(s,τmin)=1,r(s,τmax)=0。
受基于方向梯度直方图进行目标检测[19]的启发,本文提出一种基于异常比率梯度的自适应评分阈值确定方法,采用差分法计算得到异常比率梯度的近似值。若异常评分阈值τi∈T,则设异常比率梯度数值的近似值本文提出的基于异常比率梯度的自适应阈值确定方法的具体实现如算法1所示。
(10)
算法1基于异常比率梯度的自适应阈值。
输入:异常评分集合S。
输出:自适应阈值t。
1:V=S.key;P=S.value //S.key为属性值集合,S.value为各属性值对应的概率值集合
2:τmin=min(P);τmax=max(P);k=50
3:T=get_range(τmin,τmax,k) //式(8)
4:R′=r′(S,T) //式(9)
5:ε=mean(R′)/2
6:sum=0;n=0
7:FOREACH r′,τ in R′,T DO
8:IF r′≤ε DO
9:sum=sum+τ;n=n+1
10:ELSE DO
11:t=sum/n
12:sum=0;n=0
13:END IF
14:END FOREACH
15:RETURN t
该方法的示例如图6所示,图中横轴为阈值τ,纵轴为不同阈值下的异常比率r′、召回率Recall、准确率Precision,竖线h与横轴相交的点为最终确定的阈值。具体步骤如下:
(1)确定异常比率r变化很小的一段区间,即异常比率梯度趋近于0的区间(|r′(s,τ)|<ε),ε是一个很小的值,本文设ε为异常比率r的平均值的一半(算法1第5行),从而得到3个评分阈值区间,即图6中3个灰色区域覆盖的横轴区间。
(2)选择异常评分阈值τ最大的区间作为候选阈值区间,即横轴0.8附近的区间。
(3)选择候选阈值区间的平均值作为所确定的自适应阈值,即τ=0.78。
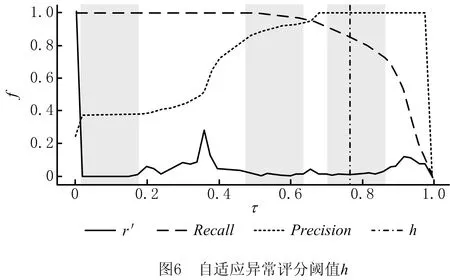
本文异常检测算法的异常评分阈值刻画了算法对小概率事件或属性值的敏感程度。异常评分阈值越高,异常检测算法对小概率事件或其属性值的异常越不敏感,反之亦然。对于不同的业务流程场景和事件属性,本文的异常评分阈值确定方法能够自适应地调整阈值大小,避免误报小概率发生的正常事件和事件属性值。
3 实验与结果分析
3.1 数据集与设置
本文采用来自BPIC (business process intelligence challenge)的事件日志数据BPIC12(http://www.win.tue.nl/bpi/2012/challenge),BPIC13(http://www.win.tue.nl/bpi/2012/challenge),BPIC15(http://www.win.tue.nl/bpi/2012/challenge),BPIC17(http://www.win.tue.nl/bpi/2012/challenge)作为数据集,4个数据集的具体信息如表1所示。

表1 数据集特征
本文采用人工方法将异常插入以上数据集的事件日志中。需要注意的是,BPIC系列的事件日志可能已包含少量异常,对这些异常进行标记比较困难。为了验证本文方法在真实案例上的可行性,人工将异常插入事件日志中,插入异常的案例被标记为异常。此时事件日志包含原本就存在的未标记的异常和已标记的人工异常,增加了异常检测的难度。在实际业务中,异常情况的类型是多样的,仿真实验中难以模拟所有异常情况,本文尽可能多地模拟不同类型的异常。人工插入的异常类型比事件日志生成软件PLG[20]模拟的异常类型丰富,可以使实验环境更贴近真实环境,具体为从事件日志中随机选取30%的案例,将7种异常插入数据集。7种类型异常描述如下:
(1)Rework在案例中的随机位置插入来自该案例的n个事件。
(2)Skip跳过n个事件。
(3)Insert在案例中添加n个随机事件。
(4)Switch将两个事件交换位置。
(5)Replace将m个事件中的n个属性用错误的值替换,或将m个事件用随机事件替换。
(6)Delay将n个事件的发生时间延后d个事件。
(7)Earl将n个事件的发生时间提前d个事件。
为了方便开展实验,本文取n∈{2,3},m=2,d∈{2,3}。采用TransNet方法预测模型构建无需对数据集进行人工标记,上述标记用于验证实验结果。
本文实验配置如下:操作系统为Window 10,处理器为Intel(R)Core(TM)i7-7700CPU@3.60 GHz;图像处理器为NVIDIAQuadroP600;TensorFlow版本为2.1.0。
本文用以上数据集中的9个事件日志对TransNet方法进行评估,并将其与t-stide[21]、支持向量机(Support Vector Machine,SVM)[6]、Naive[22]、Likelihood[7]、Sampling[22]、DAE[9]和BINet[10]各方法进行比较。
本文采用Scikit-learn库中的模块编程实现SVM模型,并选用径向基核函数(Radial Basis Function,RBF)。分别参照原文献用Python编程语言3.7版本实现了Naive[22],Sampling[22],Likelihood[7],DAE[9]和BINet[10]等方法,其中Naive[22],DAE[9],BINet[10]需要设定异常评分阈值,并采用自适应的异常评分阈值方法确定阈值;DAE[9],BINet[10],TransNet方法采用默认参数的Adam梯度下降方法更新网络参数,并采用交叉熵(crossentropy)作为损失函数。TansNet方法在编码器和解码器的最后一层用BatchNormalization层进行批归一化操作,并用提前停止技术缓解过拟合。
3.2 实验结果分析
3.2.1 3种注意力策略
为了研究不同注意力策略对业务过程异常判定结果的影响,本文提出3种注意力策略:策略1在预测下一事件属性时,只关注当前过程实例的控制流;策略2在预测下一事件属性时,同时关注当前过程实例的控制流和数据流;策略3在预测非活动名属性时,同时关注控制流、数据流和目标事件的活动名。
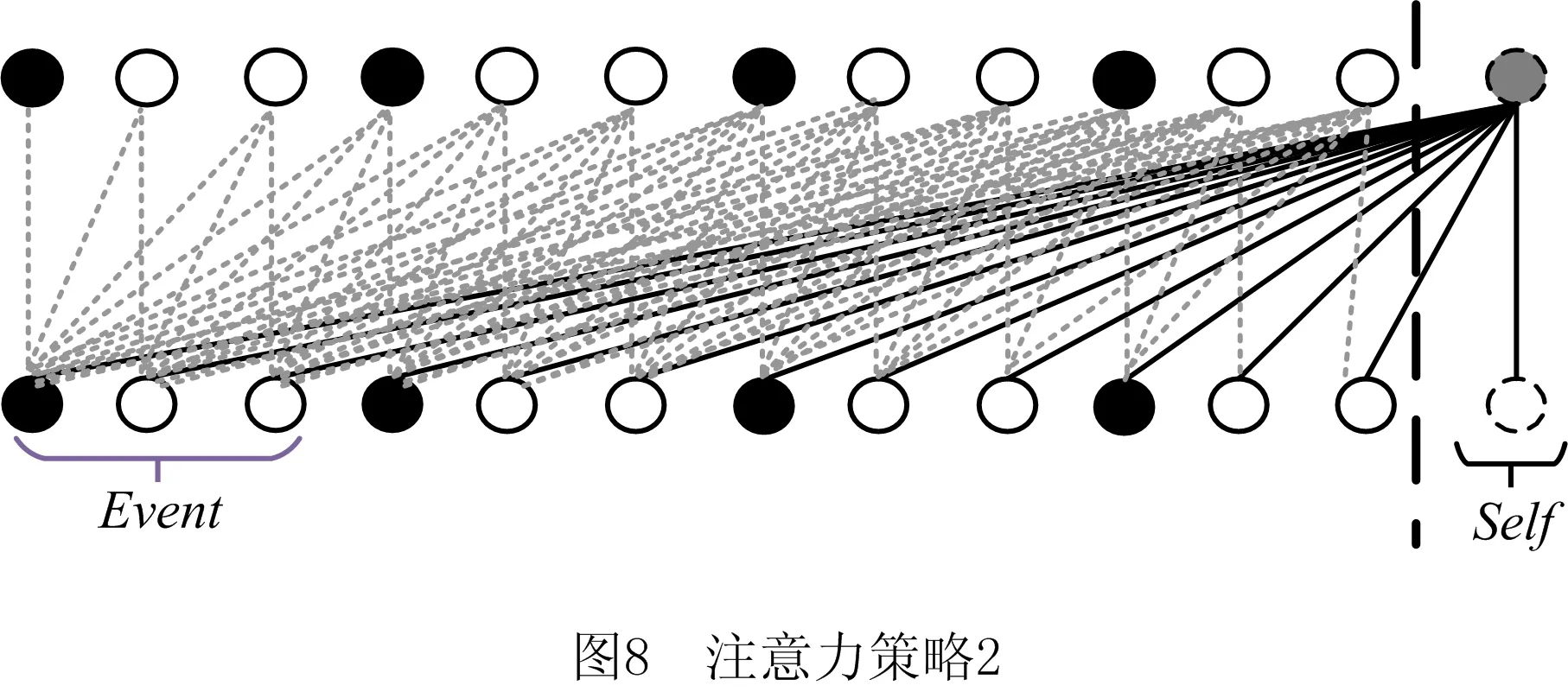
策略1记为TansNetv1,如图7所示。其中,实心圆圈表示当前过程实例的控制流特征(事件活动名),空心圆圈表示数据流特征(活动名以外的其他事件属性),虚线表示已完成预测的属性的注意力,实线表示待预测属性的注意力,连线的方向为从下到上;黑色粗虚线的左侧,上半部分表示由预测模型预测得到的、当前过程实例已完成的事件属性,下半部分为当前过程实例中实际已发生的事件属性;黑色粗虚线右侧的灰色圆圈表示待预测的事件属性,虚线圆圈表示当前过程实例中已完成事件的属性;Event表示已完成事件,有3个属性,分别为一个活动名属性和两个非活动名属性;Self表示待预测属性对自身的注意力,即自注意力。

在预测当前实例的下一事件属性时,TansNetv1只关注当前过程实例中已发生事件的控制流特征,即图7中左下部的实心圆圈。
策略2记为TansNetv2,如图8所示,图中各图形符号的意义与图7相同。在预测当前过程实例的下一个事件属性时,TansNetv2关注当前实例中已发生事件的控制流特征和数据流特征。
策略3记为TansNetv3,如9所示,图中各图形符号的意义与图7相同,其中Present所包括的元素表示待预测的下一事件。在策略2的基础上,策略3在预测非活动名属性时,额外关注预测目标事件的控制流特征。

3.2.2 异常检测方法的有效性验证
为了验证本文方法在多视角进行业务过程异常检测的有效性,分别从业务过程的控制流视角、数据流视角和多视角(控制流+数据流)开展异常检测实验,并比较结果的F1分数。F1分数是查准率Precision和查全率Recall的调和平均值,具体计算式为
(11)
在本实验中,F1分数值越大,表示某方法异常检测实验的总体性能越好。在BPIC17数据集上进行案例级别的异常检测,实验结果的F1分数如表2所示。
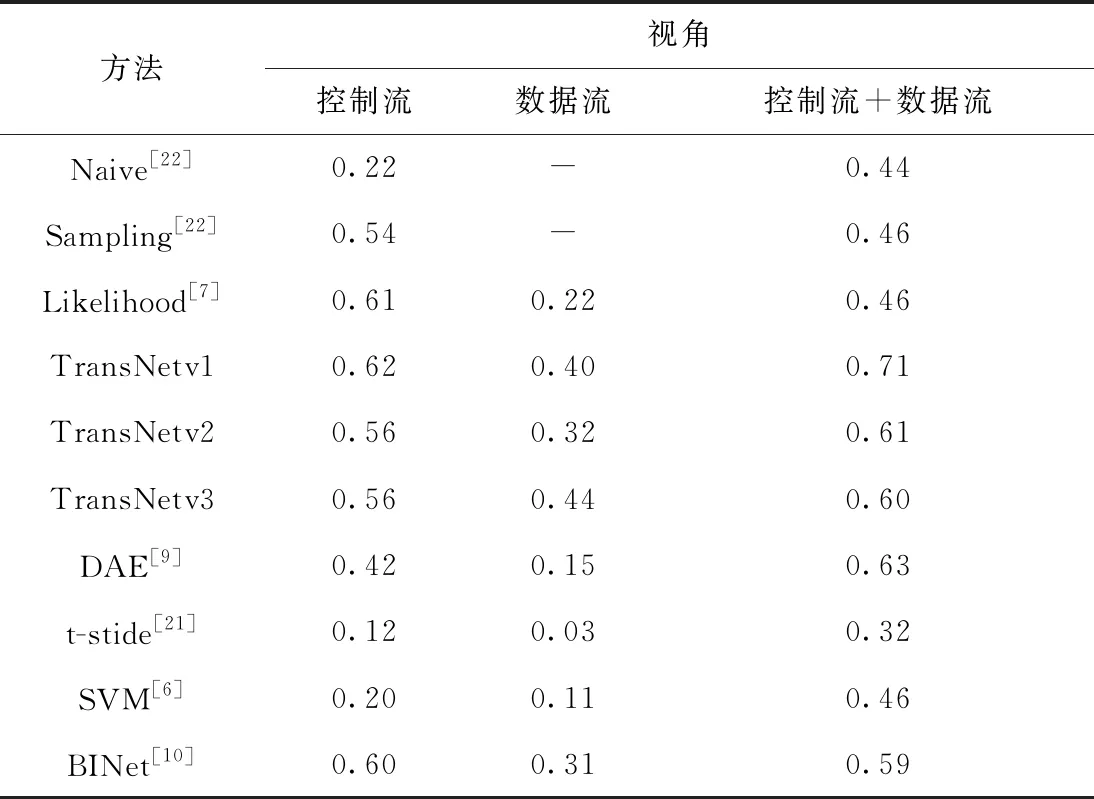
表2 基于不同视角的实验F1分数对比
由表2可见,从多视角进行异常检测实验的F1分数,普遍好于单独从控制流视角或数据流视角开展的实验结果。在业务过程中,事件的属性通常强依赖于事件的活动名,如果缺少控制流信息,单纯从数据流视角出发进行业务过程异常检测,则效果较差;而单独从控制流出发,缺少数据流信息,异常检测也不够全面,因此F1分数较小。以上分析表明,从多视角进行业务异常检测能够更准确地发现异常。
对比3种注意力策略,TransNetv1获得了最好的F1分数0.71,说明在BPIC17数据集上关注控制流、从多视角进行业务异常检测最有效。因此,本文方法可以有效地从多视角开展异常检测,即本方法是有效的。
为了验证本文异常检测方法能够在不同检测级别检测异常,并有效定位异常来源,在4个数据集上分别开展3个异常检测级别的异常检测实验。3种检测级别如图10所示。
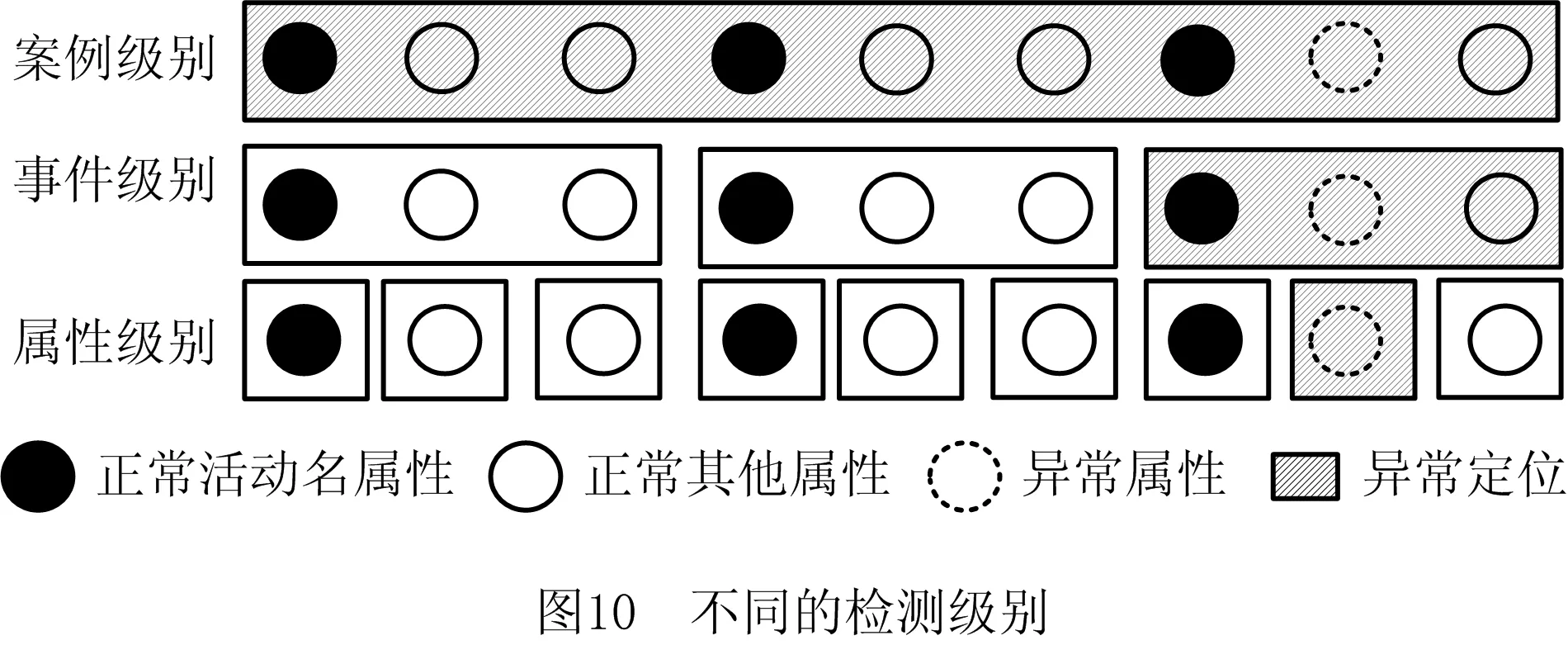
在图10中,实心圆圈表示控制流特征(事件活动名)、空心圆圈表示数据流特征(除活动名外的其他事件属性);虚线圆圈表示发生异常的事件属性。斜线填充方框表示不同检测级别对异常来源定位的范围,无填充方框表示不同检测级别下正常的事件或其属性。图中检测级别从案例级别到属性级别,级别越低,异常检测方法定位异常来源的准确度越高,异常检测的难度越高。虽然属性级别异常的检测难度较大,但是可以准确定位异常来源,因此属性级别的异常检测是必要的。由于案例由多个事件组成,事件由多个属性组成,根据以下规则,属性级别的异常检测可以用于事件级别和案例级别[9]:
(1)若一个事件的任意属性是异常的,则该事件是异常的。
(2)若一个案例的任意事件是异常的,则该案例是异常的。
在训练预测模型阶段,设定参数epochs=20,batch_size=100,dropout_rate=0.2;在异常检测阶段,采用本文自适应阈值确定方法确定异常评分阈值。本文对所有非确定性方法,如SVM[6],BINet[10],DAE[9]和TransNet进行10次实验,取指标的平均值作为最终结果,用F1分数作为综合评价指标。实验结果如表3所示。

表3 不同异常检测级别的实验F1分数对比
由表3可见,对于所有参与比较的方法,检测属性级别异常的F1分数比检测案例级别异常的F1分数小,说明检测属性级别异常比检测案例级别异常更困难,而检测事件级别异常的难度介于前两者之间,但属性级别的异常检测可以准确定位异常发生的具体事件属性。相比其他方法,TransNet方法在属性级别异常检测中取得的F1分数最高,而Naive[22],Sampling[22],Likelihood[6]等方法在检测属性级别异常时已经失效。在BPIC12数据集中,BINet方法[10]在检测属性级异常上的效果最好,其F1分数达到0.48,但在其他数据集上并未得到最好的效果,这是因为BPIC12事件日志是4个数据集中唯一没有数据流的数据集。
对比3种注意力策略,TransNetv1策略在BPIC15,BPIC17数据上取获得最好的F1分数,而TansNetv2策略在BPIC12,BPIC13数据集上获得最好的F1分数。TransNetv3策略作为TransNetv2策略的扩展,在单独数据流视角异常检测和BPIC13案例级别异常检测中的表现优于TransNetv2策略,但是TransNetv2在属性级别异常检测的效果优于TransNetv3。
相比案例级别和事件级别的异常检测,属性级别异常检测更重要,因为业务过程异常往往由单个事件属性值表现,所以检测属性级的异常十分关键。通过实验可知,在属性级别业务过程异常检测上,TransNet方法在各个数据集上都获得了较好的结果。
3.2.3 TransNet方法的时间效率分析
本文进行对比的8种异常检测方法的主要运行时间是模型建立时间,而实质的业务过程异常检测时间都在毫秒级。为了检验本文TransNet方法的时间效率,在3.2.2节实验中统计了8种异常检测方法在所有事件日志上运行10次的平均模型建立时间,如图11所示。
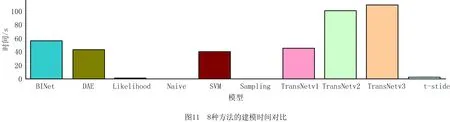
由图11可见,基于机器学习的方法,如SVM[6],BINet[10],DAE[9]和TransNet方法的模型建立时间远高于其他方法,如Naive[22],Sampling[22],Likelihood[7]和t-stide[21]。在基于机器学习的方法中,SVM方法[6]的运行时间最短,TansNetv3方法的运行时间最长,因为SVM方法的模型需要训练的参数较少,损失函数可以更快地收敛,而TransNetv3需要额外训练目标事件的控制流和数据流特征的编码器,所以训练时间最长。
在TansNet方法中,TansNetv1策略只需训练控制流特征的编码器,训练时间较快;TransNetv2策略和TransNetv3策略同时关注控制流和数据流特征,需要对每个数据流特征单独训练编码器,因此相对于TransNetv1策略训练时间较长。从整体来看,TansNet方法的建模时间比其他方法长,原因是注意力机制在计算点对点的依赖关系时计算量较大,比较耗时,今后可以设计并行算法计算注意力,以降低TansNet方法的建模时间。
从以上3个实验可知,本文所提业务过程异常方法TansNet可以有效地从多视角检测业务过程异常,虽然建模时间较长,但是比其他方法能够更准确地检测业务过程实例的事件属性异常,同时定位业务过程异常发生的来源,对提高业务过程异常检测效率有重要意义。
4 结束语
业务过程实例发生的异常通常由事件的单个属性值异常引起。针对现有的大多数业务过程异常检测方法可以检测出业务过程运行实例、事件或事件属性类型的异常,但无法定位引发异常的事件的具体属性的问题,本文提出一种基于注意力机制的业务过程异常检测方法。首先,从业务过程的事件日志中挖掘控制流和数据流视角的过程特征,构造过程特征数据集;然后,基于Transformer模型的注意力机制构建业务过程预测模型,采用该预测模型捕获过程特征数据集中事件及其属性间的长距离端到端的依赖关系,由此预测当前业务过程实例的下一事件及其属性的概率分布,通过实际发生的事件和该事件的预测结果计算该事件各属性的异常评分。为应对业务过程的多变性和不确定性,本文提出一种基于异常比率梯度的、自适应的异常评分阈值确定方法,采用异常评分阈值判定事件属性异常,其异常评分大于设定的异常评分阈值的事件属性被认为是异常属性,并定位该事件属性为异常来源。仿真实验表明,本文所提业务过程异常检测方法不但能够更准确地检测业务过程实例、事件及其属性的异常,而且可以定位业务过程异常发生的事件属性,对提高业务过程异常的检测效率和过程感知信息系统的运行平稳性有重要意义。
目前本文方法只能处理事件的离散型属性。如果某个事件属性值是在训练期间未遇到的值,则在独热编码中不会给该值分配维度。一个简单的解决方案是向编码向量添加一个额外维度,用于编码所有未知的属性值。本文的异常检测方法可用于离线检测异常,也可以部署在过程感知信息系统中在线检测异常。
未来将致力于以下研究:①改进确定事件属性异常评分阈值的方法;②研究处理事件连续型属性的异常检测与定位方法;③尝试将本文的异常检测方法应用于实际的过程感知信息系统的在线过程异常检测。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
临床骨科杂志(2020年1期)2020-12-12
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
