
几种典型机器学习算法在短临降雨预报分析研究
2022-11-07 10:41:04池钦赵兴旺陈健
全球定位系统 2022年4期
池钦,赵兴旺,陈健
(安徽理工大学 空间信息与测绘工程学院,安徽 淮南 232001)
0 引言
大气可降水量(PWV)是监控气候变化的重要一环.以全球卫星导航系统(GNSS)技术为代表的水汽反演PWV 方法在时间、空间、速度上占有优势,在气象学领域中逐渐发挥作用[1].而降雨情况与PWV 的动态特征变化关系,让不少学者开始利用机器学习模型对降雨进行预报.
降雨预报模型包括降雨信息录入和气象参数因子获取、测试训练集规划确定、降雨预报模型的选择、模型参数的确定、降雨模型训练和建模结果分析等步骤[2].在获取准确的降雨信息和气象参数因子等关键数据后,模型的选择问题是影响降雨预报结果的一个重要因素.适用的预报模型能够模拟降雨与气象参数因子的数据关系,利用线性或非线性函数构建两者之间的联系,这种方法不需要再深入了解降雨发生背后的物理规律,只需要通过挖掘历史数据(气象参数、降水信息等)的变化规律[3].
机器学习模型在降雨预报中表现出了良好的效果[4-5].LIU 等[6]基于一种新的空间框架,将改进的K近邻(KNN)算法在遥感影像上分析了强降雨下影像的范围.HUANG 等[7]利用改进的KNN,在降雨数据分布不均匀的情况下,在降雨预报中取得了不错的效果.BOJANG 等[8]将奇异谱分析与最小二乘支持向量机和随机森林(RF)结合,可用于月降雨量的研究.SHI 等[9]利用长短期记忆神经网络(LSTM)模型引入卫星遥感云图以时间序列建立降雨预报模型,也取得不错的效果.然而,这些研究主要把机器学习算法应用在遥感影像和雷达图像.因此,另一批学者在GNSS PWV 与机器学习的融合应用上进行探索,尝试利用GNSS 解算出来的天顶对流层延迟(ZTD)通过机器学习算法建立降雨预报模型.周永江等[10]利用BP 神经网络融合气象参数、PWV 和PM2.5 数据建立时间序列和回归的雾霾预测模型,时效性达到3 h.刘洋等[11]利用反向传播神经网络结合多种气象参数和PWV 进行短临降雨预报,比BP 神经网络拥有更好的性能,赵庆志等[12]利用最小二乘支持向量机(SVM)对短临降雨进行预测,相对传统降雨预测算法具有显著提升.
为了验证机器学习算法在降雨预报中的可靠性能,本文在上述研究的基础上,以几种典型机器学习算法构建短临降雨预报模型,融合PWV 和气象参数数据,定量分析和比较这些机器学习算法在相同背景下的降雨预测性能,研究和评价模型的可行性.
1 理论和数据
1.1 GNSS 获取PWV
GNSS 信号在传播过程中会受到对流层延迟的干扰,利用对流层延迟不仅可以改进GNSS 定位的精度,同时对水汽的研究有着重要作用.ZTD 可由斜路径方向上的对流层延迟通过映射函数投影在天顶方向上得到.GAMIT 解算的对流层延迟与国际GNSS服务(IGS)提供的对流层延迟产品具有很好的一致性[13].本文使用IGS ZTD 产品代替GAMIT 处理的ZTD 延迟.
ZTD 由天顶对流层静力延迟(ZHD)和天顶对流层湿延迟(ZWD)两部分组成,前者是ZTD 中的主要成分,可以通过Saastamoinen 公式求得;后者通过ZTD 与ZHD 之间作差求得.PWV 与ZWD 之间的转换系数(π)由Bevis 提出,通过ZWD 和π 的乘积可以得到PWV.综上,PWV 的计算公式为

1.2 模型和算法
1.2.1 KNN 算法
KNN 算法是一种通过特征空间中的输入样本寻找k个距离最近邻的样本并依据所属类别投票表决的方法[14].距离的计算函数有欧几里得距离、巴氏距离和马氏距离等.常用的欧几里得距离计算的是两个点距离之间的平方差之和的平方根,计算公式为

式中,i表示点x和y的第i个坐标.通过KNN 算法对目标进行分类,输出值是k个最近邻样本类别中占比最大的一类.可以通过手动设置或使用交叉验证结果较为准确的k值.
1.2.2 随机森林
随机森林(RF)在Bagging 算法的基础上,随机选取部分特征向量组成CART (classification and regression tree)决策树,流程如图1 所示,重复m次建立m个决策树模型,通过多颗决策树联合对结果进行预测.

图1 随机森林示意图
1.2.3 朴素贝叶斯分类器
朴素贝叶斯分类器(NBC)是贝叶斯分类器中常用的模型之一.这种分类器假设特征向量之间独立,降低了运算的逻辑性和复杂性.在特征向量为x的情况下,对目标进行归类时,计算公式为

对于特征向量的属性是连续性分布的二分类问题,计算出变量正态分布的均值和方差,可将公式转换为

式中:Z表示归归一化因子;µj表示第j个特征向量的均值;σj表示第j个特征向量的标准差;y=+1 表示样本归为正类的标签.
1.2.4 SVM
SVM 的目的通过寻找一个最具鲁棒性的超平面来将样本进行分类.这个超平面让不同的样本类别分布在平面两侧,同时让两侧距离决策边界最近的样本类别有一个极大值.这个超平面用下面的式子表示:

式中:x为特征向量;w表示超平面的归一化方向向量;b表示阈值.
SVM 可以利用核函数将原始特征向量映射到新空间.常用的核函数有线性核函数、多项式核函数和高斯核函数等.在本次实验中,使用了高斯核函数[15],如下式所示:

1.3 数据资料
数据选取位于北京(BJFS)和武汉(WUH2) 2 个GNSS 测站,其中ZTD 数据来自IGS 提供的对流层延迟产品,PWV 由式(1)计算得到.气象数据来自气象网站rp5.ru,由英国气象局制作并根据相关资质发布在该网站上,提供的气象数据有温度(T)、气压(P)、相对湿度(U)、露点温度(Td)、每3 h 降雨量.
2 气象参数特征分析
降雨的发生往往伴随着复杂参数的变化,研究降水形成过程中PWV 和多尺度气象参数时间序列的周期性、敏感性等特征,挖掘降雨的形成机理是有必要的.图2~3 分别为BJFS 站和WUH2 站降雨及相关其气象参数的时间序列变化.由图可知,降雨的发生与PWV 及其气象参数的变化基本是一致的,有比较强的相关性.从全年的数据变化看,在PWV 的峰值到来时,会伴随着降雨的发生;结合气象资料选择降雨较为集中的180—210 天,在降雨发生前,通常伴随着PWV、Td及U的上升,T的下降,P的陡峭上升;在降雨发生时,通常伴随着PWV、P、Td及U的下降,T的上升.

图2 BJFS 站2020 年降雨量与PWV 关系以及7 月(年积日第180—210 天)降雨量与相关气象参数关系

图3 WHU2 站2020 年降雨量与PWV 关系以及7 月(年积日第180—210 天)降雨量与相关气象参数关系
3 基于机器学习的预报模型构建
3.1 预报流程设计
图4 展示了区域短临降雨的一般预报框架.

图4 降雨预报模型流程
以BJFS 站2020 年的实验数据为例,首先对PWV 和气象参数进行归一化处理.模型的参数对预报的精度起到重要作用,RF 模型的参数有树的数目和深度,KNN 的参数有权重和距离,SVM 的参数有正则化参数和惩罚参数,本文利用网格搜索法和交叉验证的方式来确定模型的最优参数.接着将预报因子(PWV、T、P、Td、U)与降雨情况作为数据集输入模型中,分别随机将数据集中的70%和80%作为训练集进行模型训练,剩下的数据作为测试集进行模型验证,得到BJFS 站2020 年的降雨预报模拟结果.WUH2 站的模拟实验流程与上述流程基本一致.
3.2 结果评价
本文使用准确性(Accuracy)、精确率(Precision)和假负率(FNR)来评价降雨预报模型的精度
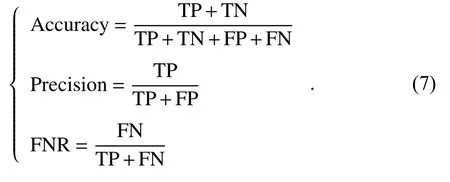
式中:将降雨预报的分类情况表示为混淆距阵,具体如表1 所示.TP 为实际情况降雨,预报情况为降雨的样本数;TN 为实际情况不降雨,预报情况为不降雨的样本数;FP 为实际情况不降雨,预报情况为降雨的样本数;FN 为实际情况降雨,预报情况为不降雨的样本数.

表1 降雨预报混淆矩阵
图5~7 为BJFS 站和WUH2 站2020 年100 次的降雨模拟结果,由图可见,2 个测站的降雨预报模拟都有不错的效果.BJFS 站4 种模型不同百分比训练集准确性的平均值均约为0.96,精确率的平均值约为80%,假负率的平均值约为21%;WUH2 站4 种模型不同百分比训练集准确性的平均值约为0.92,精确率的平均值约为86%,假负率的平均值约为13%.而在4 种模型中,RF 的模型在准确性和精确率上比其他3 种模型更优一点,SVM 的模型在假负率上比其他3 种模型更低一点.

图5 4 种预报模型的准确性箱图
传统的阈值方法利用降雨前的PWV 的变化量和变化率进行短临降雨预报[16],表2 对BJFS 站和WUH2 站的PWV 变化量和变化率进行分析并确定合适的阈值,模拟2 个测站的降雨预报效果.

表2 BJFS 站和WUH2 站降雨预报的统计结果

图6 4 种预报模型的精确率箱图

图7 4 种预报模型的假负率箱图
由表2 可以看出,选择合适的PWV 变化量和变化率并利用阈值方法对降雨进行预报,其精确率和假负率约在80%和60%,说明该方法在一定程度上能对未来短时间进行降雨预报,但却有着不低的假负率,对预报的应用存在一定的影响.
综上所述,4 种模型在BJFS 站和WUH2 站的降雨预报都起到了不错的效果,且漏报率低于传统的阈值方法判断降雨模型.
3.3 预报实验
以BJFS 站为例,按时间序列的方式选取年积日为第150—200 天的数据作为训练集数据,对数据集进行归一化处理输入预报模型中进行训练,以200—250 天的数据作为测试集数据,预报下一时间段的短临降雨情况.利用接收器操作特性(ROC)曲线和查准率一查全齐(PR)曲线对结果进行评估.WUH2 站的预报流程与上述流程基本一致.
图8~11 为BJFS 站和WUH2 站的降雨预报结果.由图可见,2 个测站的降雨预报都取得不错的效果,BJFS 站的ROC 曲线下与坐标轴围成的面积(AUC)值最好的是SVM 模型的0.923 80,平均准确率(AP)值最好的是SVM 模型的0.790 92;WUH2 站的AUC 值最好的是SVM 模型的0.924 30,AP 值最好的是RF 模型的0.821 86.综上所述,SVM 模型的分类器性能略优于RF 模型,而KNN 模型和NBC 模型也能取得不错的效果.因此,本文基于机器学习的短临降雨预报模型对未来3 h 的降雨预报能达到一个不错的效果,可以达到80%以上的降雨情况,而假负率在20%以下.相对于传统的阈值预报模型,在正确率相当的情况下(其正确率约为为80%),假负率降低了50%左右(其假负率约为70%).

图8 BJFS 站的ROC 和AUC 曲线

图9 WUH2 站 的ROC 和AUC 曲线

图10 BJFS 站的PR 和AP 曲线

图11 WUH2 站的PR 和AP 曲线
4 结论
1)通过分析降雨发生前后与PWV 和多种气象参数(T、P、Td、U)的一种非线性变化关系得出,在降雨发生前,会有PWV、Td、U和P的上升过程,T的下降,而在降雨发生时,这些参数发生相反的态势.
2)利用不同的机器学习算法,分别对测站整年的降雨数据划分不同的训练集构建短临降雨预报模型,结果表明4 种模型均能取得不错的效果,准确性在0.9 以上,精确率在80%以上,假负率在25%以下,而RF 模型在准确性和精确率上更优,SVM 的模型在假负率上更优.
3)以时间序列构建的短临降雨预报模型的结果表明,4 种模型对未来3 h 的80%以上降雨情况可以很好的预报,假负率在20%以下,相较传统的阈值方法,假负率降低了约50%,有了很大的改进.其中SVM 模型的综合性能略优,在BJFS 和WUH2 测站上的AUC 最好,BJFS 的AP 最好,其次是RF 模型,最后KNN 模型和NBC 模型也能取得不错的效果.综上,4 种典型机器学习构建的短临降雨预报模型具有不错的可行性.
致谢:感谢IGS 提供的GNSS 数据,感谢rp5.ru网站提供的气象数据.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
区域治理(2021年14期)2021-08-11 08:57:30
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
水利科技与经济(2017年6期)2017-04-28 08:30:36
载人航天(2016年4期)2016-12-01 06:56:24
成都信息工程大学学报(2016年6期)2016-06-01 12:10:06
水利科技与经济(2016年5期)2016-04-22 03:43:46
发明与创新(2015年29期)2015-02-27 10:39:44
