
基于孪生网络和字词向量结合的文本相似度匹配①
2022-11-07 09:08李奕霖周艳平
计算机系统应用 2022年10期
李奕霖,周艳平
(青岛科技大学 信息科学技术学院,青岛 266061)
计算文本语义相似度是在考虑自然语言表达的可变性和模糊性的同时,确定句子在语义上是否等价,它是自然语言处理领域的一个挑战性问题,也是智能问答[1,2]、信息检索[3]、文档聚类[4]、机器翻译[5]、简答评分[6]等任务的重要组成部分.
传统的机器学习模型进行相似度计算时,可以解决在词汇层面上文本之间的匹配,但忽略了前后单词之间所具有的语义关联以及文本蕴含的语法信息.例如,基于词袋模型[7]的TF-IDF,把句子作为一个长向量,以词为单位分开,每一维代表一个词,对应的权重代表这个词在文本中的重要程度.但这种方法只能反应字面上的重要程度,词之间各自独立,无法反映序列信息和语义信息; Hofmann[8]提出的PLSA 模型引入了主题层,采用期望最大化算法训练主题,在训练到不同主题的情况下,避免了同义词和多义词对相似度的影响,在一定程度上考虑到了语义问题.
基于深度学习模型的文本相似度计算方法进一步关注到了文本语义层.CNN 和RNN 通过对文本信息进行深层卷积,使模型可以关注到文本的整体信息,相比传统机器学习模型对文本的语义建模能力更强.
近年来,Transformer 模型[9]因强大的语义建模能力被广泛应用于NLP 领域,其全局自注意力机制的运用使模型对文本特征的提取更加准确.Google 提出的BERT (bidirectional encoder representations from Transformer)模型[10]在只保留encoder 部分的前提下使用双向Transformer,这种模型对语境的理解比单向的语言模型更深刻.BERT 模型中每个隐藏层都对应着不同抽象层次的特征,用来提取多维度特征,独特的相对位置编码方法使得建模能力更强,可以更准确地把握文本真实语义.
2020年,苏剑林[11]在BRET 模型的基础上开源了以词为单位的中文 WoBERT 模型,基于词提取文本句向量,相比字义能更好地对文本语义进行整体表达,但是单纯的以词为单位存在一定的稀疏性,会存在有未登录词出现的现象,对于未登录词能否做到正确的语义理解具有不确定性.Reimers 等基于孪生网络(Siamese network)和BERT 模型提出了SBERT 模型[12],沿用了孪生网络的结构,将不同的英文文本输入到两个BERT 模型中,这两个BERT 模型参数共享,获取到每个句子的表征向量,之后再做分类目标和回归目标.SBERT 在文本语义相似度匹配任务上明显优于BERT模型.虽然SBERT 提高了运算效率,但在本质上还是基于表示的BERT 方法,即通过基于字的方法来提取句子表征向量,而且句子的特征交互只在网络顶层进行,将其运用到语义复杂度高的中文文本中仍会出现语义理解不充分的问题.
本文针对中文文本相似度匹配任务,提出了一种基于孪生网络和字词向量结合的文本相似度匹配方法.本文整体框架采用孪生网络模型,对匹配的两段文本采用同样的编码器和预训练模型.首先通过BERT 和WoBERT 模型分别获取字级和词级的句向量,在字词向量表示层采用向量并联的方式得到融合特征向量,BERT+WoBERT 的句向量表征方法改变了仅基于BERT 的表示方法,通过联合WoBERT 模型基于词的句向量表征方法,让句子转换为具有充分语义信息的高维向量; 其次,将得到的特征向量送入特征信息整合层,得到复杂但富含充分语义信息的文本向量.针对孪生网络整合过程出现的维度过高的问题,使用PCA 算法压缩数据空间,将高维数据的特征映射到低维空间,实现对特征向量的降维降噪.通过这种计算方法使模型更有效的关注到文本的深层语义特征,解决了中文数据集中出现的字词模糊性和差异性问题,提高了文本相似度匹配的准确率.
1 基础模型
1.1 BERT 预训练模型
Google 提出的BERT 是一个预训练的语言表征模型,将文本中无法直接计算的字转变为可计算的向量形式,这些向量能够更好地反映出字在句子中的含义.
BERT 模型使用两个无监督预训练任务.
(1)遮蔽语言模型: 随机选择句子15%的词用于预测,其中80%的词用[MASK]替换,10%的被随机换掉,剩下的10%保持不变.
(2)下一句预测: 判断两句话是否为前后句关系,选择训练集里的句子 A 和 B 时,句子B 有 50% 几率是 A 的下一句,50%是随机选择的句子.
BERT 模型的编码层通过联合调节所有层中的双向Transformer 来训练,使模型能够充分提取输入文本的语义信息.图1 为BERT 模型的结构图,Trm 为Transformer 编码器,E1,E2,…,En为模型的输入向量,T1,T2,…,Tn为输出向量,经过计算得到句子seq_A的特征向量表示f(seq_A).
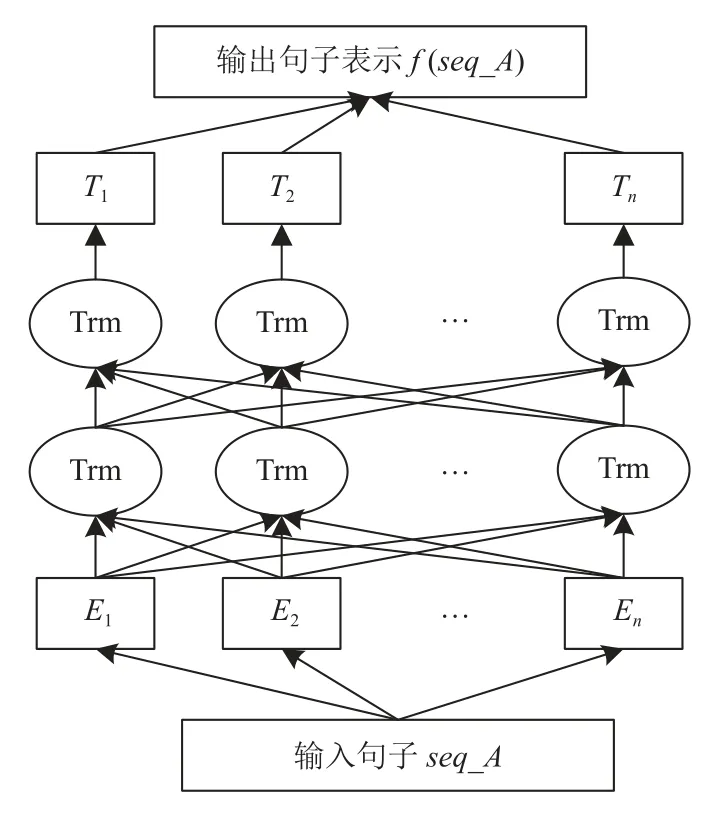
图1 BERT 模型结构图
BERT 模型只使用了Transformer 架构中的encoder模块,弃用了decoder 模块.其中,encoder 模块的多头自注意力机制可以从多个维度准确提取文本语义特征,其主要运算过程如下: 首先进行自注意力的计算,将输入向量E1,E2,…,En与给定的权重矩阵WQ、WK、WV相乘得到向量Q、K、V.Q表示与这个单词相匹配单词的属性,K表示这个单词本身的属性,V表示这个单词所包含的信息本身.
通过attention 计算得到自注意力值:
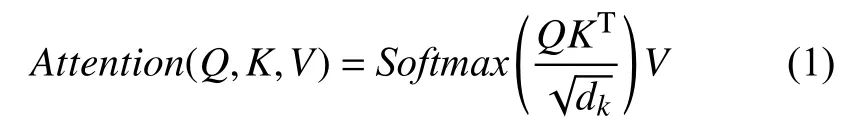
其中,dk为向量K的维度.将Q、K、V通过线性映射的方式分为n份,对每一份分别进行自注意力的计算,最后通过并联的方式将n个自注意力模块结合起来,然后通过左乘权重矩阵的线性映射方法得到最终输出,完成整个多头注意力模块的计算,计算如下:
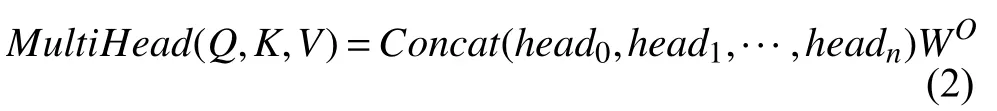
其中,
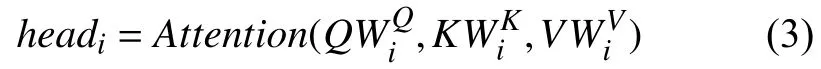
1.2 WoBERT 预训练模型
WoBERT 是以词为单位的中文预训练模型,让序列变短,处理速度变快,语义更明确.
WoBERT 模型相对BERT 模型做出了如下改进:
(1)加入前分词操作,进行中文分词.
(2)使用动态的Mask 操作,将训练数据重复10次,使得每轮训练的Mask 的位置不同.
(3)学习任务只有遮蔽语言模型,取消了下一句预测任务.
(4)batch size 从256 扩大为8k.
(5)删除了BERT 模型自带词汇表的中文冗余部分,比如带##的中文字词,将结巴分词自带的词汇表中词频最高的两万个加入词汇表,减少了未登录词的出现概率,最终词汇表规模为33 586.
1.3 孪生网络
孪生网络定义两个网络结构分别表征对应的输入内容,分为孪生网络和伪孪生网络.孪生网络中的两个网络结构相同且共享参数,当两个句子来自同一领域且在结构上有很大的相似度时可选择孪生网络; 伪孪生网络可以是不同结构的网络或不共享参数的同结构网络,计算两个不同领域的句子相似度时可以选择伪孪生网络.本文研究两个文本的相似度,采用两个网络结构相同且共享参数的孪生网络模型.其模型基础结构如图2 所示,孪生网络结构简单,训练稳定,以两个样本input1 和input2 为输入,其两个子网络各自接收一个输入,子网共享权重使得训练需要更少的参数,这意味着需要更少的数据并且不容易过拟合.
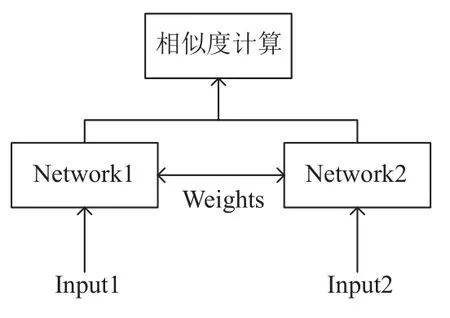
图2 孪生网络基础结构
2 模型和方法
本文提出的基于孪生网络和字词向量结合的文本相似度匹配模型结构如图3 所示,主要分为4 层: 输入层、字词向量表示层、特征信息整合层、输出层.

图3 本文模型结构图
2.1 输入层
BERT 模型的输入是将字向量(tokening embeddings)、文本向量(segment embeddings)和位置向量(position embeddings)拼接得到Eci作为模型输入.如图4 所示.
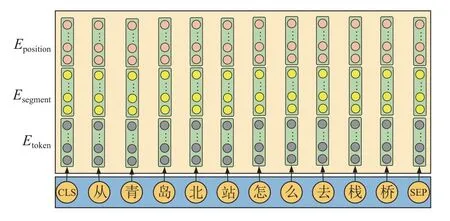
图4 BERT 模型输入层
由于以字为单位的建模方法在处理中文数据集时存在语义确定性不高的问题,模型往往难以对文本中重复出现的字准确提取真实语义特征.本文引入WoBERT模型,输入向量用Ewj表示,此模型与BERT 模型建模形式不同的地方在于tokenize 为了分出中文单词在BERT模型的tokenize 中加入了一个前分词操作.WoBERT模型的tokenize 方法流程如图5 所示.

图5 WoBERT 模型的tokenize 流程图
对“从青岛北站怎么去栈桥”这句话,token embeddings 通过词汇表使用WordPiece 嵌入,用Etoken表示;字的位置向量用Eposition表示; 由于模型中只有一个输入句子,所以每一个字所处的某个句子信息是一样的Esegment.输入向量的计算公式如下:
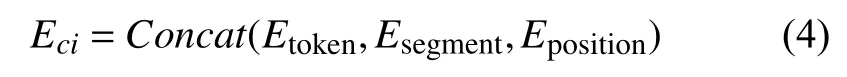
经过WoBERT 的tokenize 方法处理之后为[‘[CLS]’,‘从’,‘青岛’,‘北站’,‘怎么’,‘去’,‘栈桥’,‘[SEP]’].
使用孪生网络训练时的输入形式为:
[CLS]seq_A[SEP] [CLS]seq_B[SEP]
由于模型运行过程中,内存占用率与输入模型句子长度l成平方增长,但batch 增加只略微影响到训练时间,采用孪生网络的训练方式可以缩短模型的训练时间.
2.2 字词向量表示层
采用BERT 和WoBERT 模型分别获取句子的字向量和词向量表示,最终得到一个句子的两种表达方式.
具体步骤如下:
(1)通过BERT 模型在LCQMC 数据集上训练得到对应文本x的句向量表达.每个句子得到一个二维矩阵chari,行数为文本中字的个数Ci,列数为768 维.
(2)通过WoEBRT 模型在LCQMC 数据集上训练得到对应文本x的句向量表达.每个句子得到一个二维矩阵wordj,行数为文本中词的个数Wj,列数为768 维.
(3)对得到的Ci×768 和Wj×768 维度的文本向量分别进行归一化,对所有特征向量按行取平均作为最终向量f(x)、g(x),维度均为1×768.
(4)对得到的基于字词级别的文本向量f(x)、g(x)进行并联操作,得到基于字词向量结合的文本向量s(x):
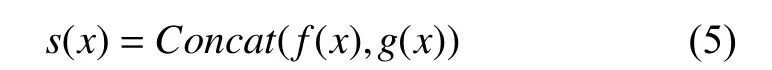
2.3 特征信息整合层
降低向量维数会损失原始数据中具有可变性的一些特征向量,但也会带来一些积极作用,例如减少计算时间、避免过拟合、去除噪声等.PCA 算法(principal component analysis)是流行的线性降维算法之一,它将一组相关变量(P)转换为较小的K(K<P)个特征子空间,同时尽可能多地保留原始文本的主要特征.
Su 等人[13]提出,在处理相似度匹配任务时,对BERT模型进行降维操作可以有效去除数据噪声,提高模型准确率的同时降低计算复杂度.BERT 模型输出维度为768,在特征信息整合层,并联组合会使输出的向量维度达到上千维,冗余信息多且占用内存大.本文用PCA算法对字词向量结合后的输出向量进行降维处理:
(1)对输入的特征向量进行归一化.
(2)计算输入样本特征向量的协方差矩阵.
(3)计算协方差矩阵的特征值和特征向量.
(4)选取协方差矩阵前K列作为降维矩阵.
(5)降维矩阵映射到低维空间完成降维计算.
本文将融合后的向量S(seq_A)、S(seq_B)维度降为384 维,得到两个输入句子的特征向量u和v.去除文本噪声的同时降低模型的整体建模难度,提高了模型的灵活性和准确率.
本文探索了不同的特征整合方式对实验结果的影响,采用通过字词向量结合并进行向量降维后得到向量u、v、两个向量差的绝对值|u-v|和两个向量乘积的绝对值|u×v|做并联的整合策略作为最终实验方案.
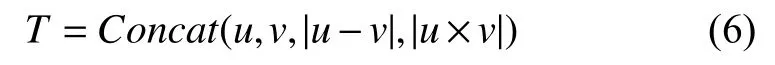
2.4 输出层
Softmax 函数在进行二分类任务时使用二项分布的计算方法,相对于Sigmoid 函数的单一建模方法,它可以对两个类别进行建模,得到两个相加为1 的概率预测结果.
本文通过Softmax 函数对输出的文本向量进行训练,损失函数采用交叉熵损失.最终输出结果为0 和1,0 表示进行匹配的两段文本不相似,1 表示相似.
3 实验及分析
3.1 数据集
本文使用的数据集LCQMC 是一个大规模的中文问答数据集,侧重于语义匹配而不是简单的复述,要求模型能够深度挖掘文本的高层语义信息.语料库由两个问题和一个标签组成,标签是0 和1 两种形式,0 表示不相似,1 表示相似.数据集共有260 068 对句子对,其中训练集238 766,验证集8 802,测试集12 500.部分数据集样例如表1 所示.

表1 部分数据集样例
3.2 评价指标
为验证本文方法的效果,采用准确率、召回率、精确率、F1 值的评价指标来验证算法的有效性.
(1)准确率(accuracy),表示预测结果预测正确的比率.

(2)召回率(recall),衡量检索文本相似度的查全率.

(3)精确率(precision),衡量检索文本相似度的查准率.

(4)F1 值,对精确率和召回率的整体评价.F1 值越大,说明精确率和召回率更均衡.

3.3 实验环境配置和参数说明
本文实验环境如表2.

表2 实验环境配置信息
选用BERT 预训练模型为BERT-Base-Chinese,最大序列长度为128,训练批次为8,学习率为2E-5,共训练5 轮.选用WoBERT 预训练模型为苏剑林等[11]以RoBERTa-wwm-ext 模型为基础训练得到的WoBERT模型,最大序列长度为128,训练批次为16,学习率为5E-6.
训练Softmax 分类器时,选用交叉熵损失函数,训练批次为100,训练轮数为1 000,学习率为0.01.
3.4 实验结果及分析
在LCQMC 数据集上进行了如下4 组对比实验:
(1)将字词向量结合生成句向量的文本相似度计算方法,与单一字向量和单一词向量生成句向量的方法进行了性能比较.
(2)使用PCA 算法对特征向量降至不同维度对模型性能的影响.
(3)不同的特征向量融合方式对模型性能的影响.
(4)将本文模型与已发表的方法进行性能比较.
在文本句向量表达模块中,使用如下3 种方法提取文本句向量:
(1)使用BERT 得到基于字级别的句向量表示.
(2)使用WoBERT 得到基于词级别的句向量表示.
(3)使用BERT+WoBERT 得到基于字词向量结合的句向量表示.
在分别得到两个句向量表示之后,通过并联操作进行特征向量融合然后输入Softmax 分类器进行实验验证,实验结果如表3 所示.
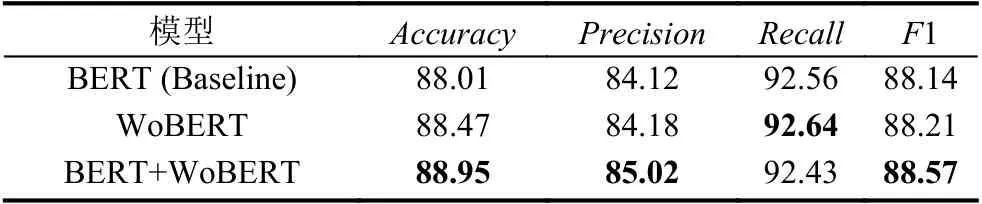
表3 字词向量结合方法(%)
由表3 可见,尽管字词向量结合的文本句向量提取方法在召回率上稍低,但在准确率、精确率和F1 值上较BERT 和WoBERT 模型都有所提升,证明了字词向量结合方法的语义表征能力.
为了对BERT 及WoBERT 模型进行评估,绘制了两种模型在数据集上训练过程中的loss 变化以及验证集的准确率曲线,如图6-图8.从图中可见,BERT 模型相对WoBERT收敛更快,虽然两个模型单次训练时输入网络的数据量不同,但WoBERT 模型最终loss 值更低,且在验证集上的最高准确率值优于BERT 模型.

图6 LCQMC 数据集上BERT 模型训练的loss 曲线
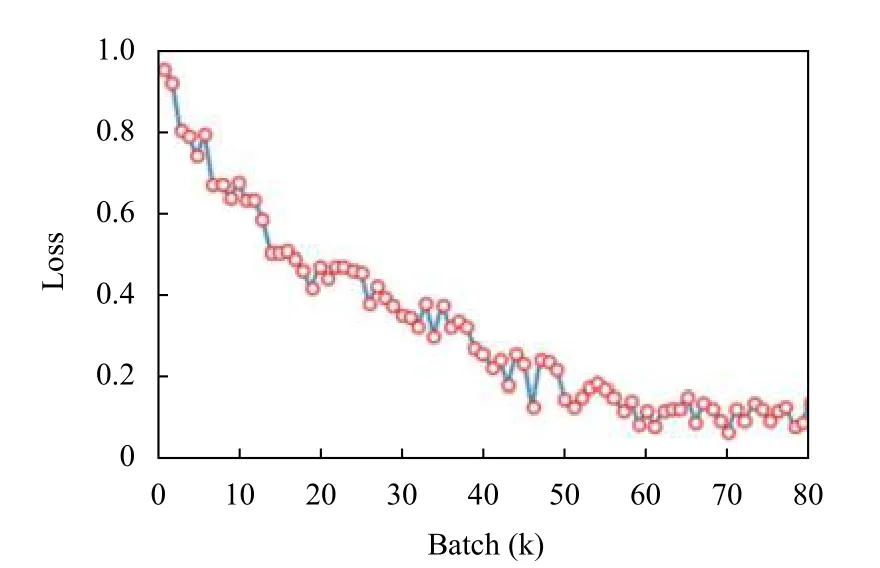
图7 LCQMC 数据集上WoBERT 模型训练的loss 曲线
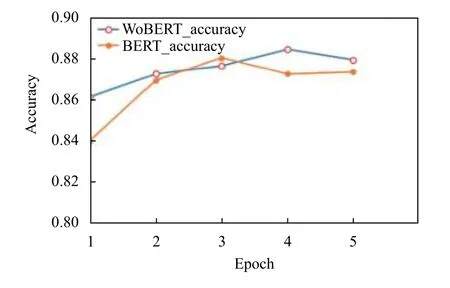
图8 LCQMC 数据集上验证的 accuracy 值变化图
孪生网络在进行相似度计算时,将两段文本分为两个batch 分别提取句向量,需要对两段特征向量进行融合.本文对不同特征融合方法进行了对比实验,经过BERT+WoBERT 字词向量结合方法得到的两个输入文本的特征向量u、v,采用如下多种方式进行实验:
(1)向量相加:

(2)向量相乘:

(3)向量并联:

(4)向量并联组合1:

(5)向量并联组合2:
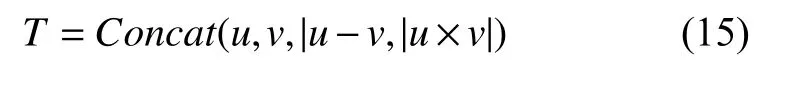
本文针对不同向量融合方式进行了5 组实验,由表4 可见,u+v的融合方式较(u,v)方法准确率提高了0.28%,而u×v融合方式的实验效果不佳.当采用(u,v,|u-v|,|u×v|)的融合方式时,准确率和F1 值分别达到了88.86%和88.42%,有着不错的匹配效果.
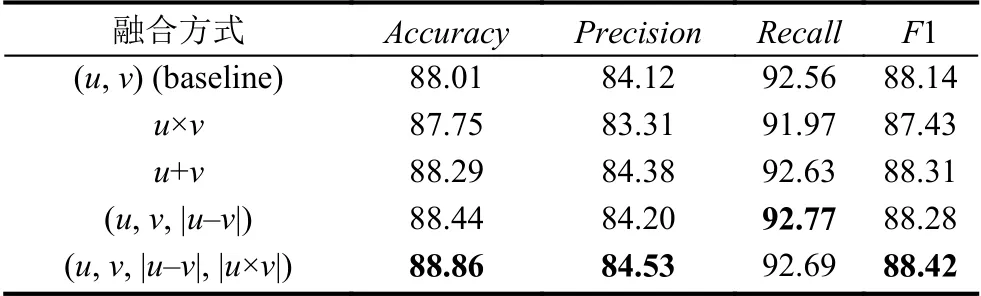
表4 不同向量融合方式实验结果(%)
为证明采用PCA 算法进行适当降维操作可以有效去除数据噪声,提高模型的识别准确率且加快训练速度,本文以BERT 模型作为baseline 在LCQMC 数据集上进行了对比实验,指定PCA 的n_components 参数也就是主成分分别为整数384、256 和100,求得对应的贡献率,实验如下:
由表5 可见,将BERT 输出的768 维向量降至384 维使得输入Softmax 的向量维度由1 536 降至原来一半,模型识别准确率达到最高.再降至256 维会损失一些特征值,导致准确率降低.说明在输入分类器的向量维度较高时,使用PCA 算法降维降噪的有效性.

表5 不同向量维度的对比实验(%)
将本文方法在LCQMC 数据集上与已发表的方法在准确率、精确率、召回率和F1 值上做了对比实验,实验结果如表6 所示.

表6 不同方法的测试结果(%)
本文的对比模型如下.
(1)BiLSTM-char: 以字向量作为输入的双向LSTM文本相似度匹配模型.
(2)BiLSTM-word: 以词向量作为输入的双向LSTM文本相似度匹配模型.
(3)BiMPM-char: 以字向量作为输入,基于 BiLSTM的双边多角度文本相似度匹配模型.
(4)BiMPM-word: 以词向量作为输入,基于 BiLSTM的双边多角度文本相似度匹配模型.
(5)MSEM: 结合文本编码模型和近似最近邻搜索技术的通用语义检索框架.
(6)Siamese- LSTM[14]: 基于孪生网络和双层双向LSTM 的文本相似度匹配模型.
(7)BERT: 以字为单位的预训练模型,可以完成适用于文本匹配的下游任务.
(8)SBERT[15]: 基于孪生网络和BERT 的文本相似度匹配模型.
(9)WoBERT: 以词为单位的中文预训练模型,可以完成适用于文本匹配的下游任务.
从表6 的结果可见,BiLSTM 和BiMPM 只使用字或词单粒度下的特征提取方法,不足以充分捕获中文文本的特征信息.MSEM 考虑词和字嵌入到一起作为文本表示,准确率相对之前方法有所提高,但没有捕捉不同粒度之间的相关特征,表达能力仍然有限.BERT模型凭借强大的建模能力相对之前方法取得了较大提升.SBERT 模型使用了最大池化和全连接层的Siamese-BERT 模型,在LCQMC 数据集上的准确率与BERT模型相当,验证了基于BERT 的孪生网络模型的有效性.WoBERT 模型较BERT 模型在准确度上有所提高,说明以中文文本为基础的基于词粒度的预训练语言模型能更充分的理解中文语义.本文在孪生网络的基础上,基于字粒度和词粒度融合特征对文本进行建模,解决了只使用BERT 模型或WoBERT 模型提取句子特征向量表达单一的问题,验证了多角度获取文本特征信息方法的有效性,进一步提高模型性能,在LCQMC 数据集上通过与其他模型的对比实验证明了本文模型在文本相似度匹配任务上的有效性.
4 结论与展望
本文提出了一种基于孪生网络和字词向量结合的文本相似度匹配方法,采用字词向量结合的BERTWoBERT 模型解决了传统模型难以关注到中文文本语义语法信息的问题,通过孪生网络和PCA 算法探索多种融合方式以及降维降噪对相似度匹配结果的影响,然后通过Softmax 分类器进行二分类,最终在LCQMC数据集上取得了不错的相似度匹配结果.
然而本文模型存在参数量过大,计算时间复杂度过高的缺点,下一步尝试将预训练模型进行知识蒸馏,在不降低准确率的前提下加快模型速度,解决资源占用率较大的问题.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生理科应试(2021年11期)2021-12-09
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
数学学习与研究(2018年15期)2018-11-12
电脑知识与技术(2016年22期)2016-10-31
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
