
基于残差注意力生成网络的机械臂抓取位姿估计算法
2022-11-05 08:30:58洪倩倩杨亮曾碧
电子设计工程 2022年21期
洪倩倩,杨亮,曾碧
(1.广东工业大学,广东 广州 510006;2.电子科技大学 中山学院,广东 中山 528402)
近些年来,伴机器人在各个领域得到广泛应用,例如精密医疗[1-3]、社会服务[4-5]、工业制造[6-7]、航空航天[8-9]等,抓取技术作为机器人控制核心之一也获得了大量关注,但是在实际应用环境中,机器人对未见过的新物体实时地决定一个合适的抓取位姿仍是一个较大的挑战。
在先前的研究工作中,许多抓取方法基于手工特征[10]进行抓取位姿推理,这些方法有工序繁重、耗时、对新物体泛化性弱等缺点。而随着近年来深度学习技术的发展,基于深度学习的方法[11-15]在抓取领域上取得了显著的进展,其中包括基于分类的抓取检测方法[16-18],此类方法在抓取位姿方面上取得一定改进,但是存在计算耗时长并要求较多计算资源的劣势;还有基于回归的检测方法[19-20],该方法在抓取位姿检测上有不错的精度表现,但是此类方法通常基于潜在可能的抓取位姿平均值预测实际的抓取位姿,有时会出现不合理的位姿推断偏差。
为了解决上述问题,文中提出一种基于残差注意力生成网络的抓取位姿生成方法,通过在康奈尔公开抓取检测数据集上进行算法对比及消融实验,比较不同方法对位姿生成精度的影响,进而验证文中方法的有效性。
1 网络结构
文中提出的残差注意力生成网络主要由三个部分组成,分别是编码器、聚合层、解码器。残差注意力生成网络及生成结果图如图1 所示。
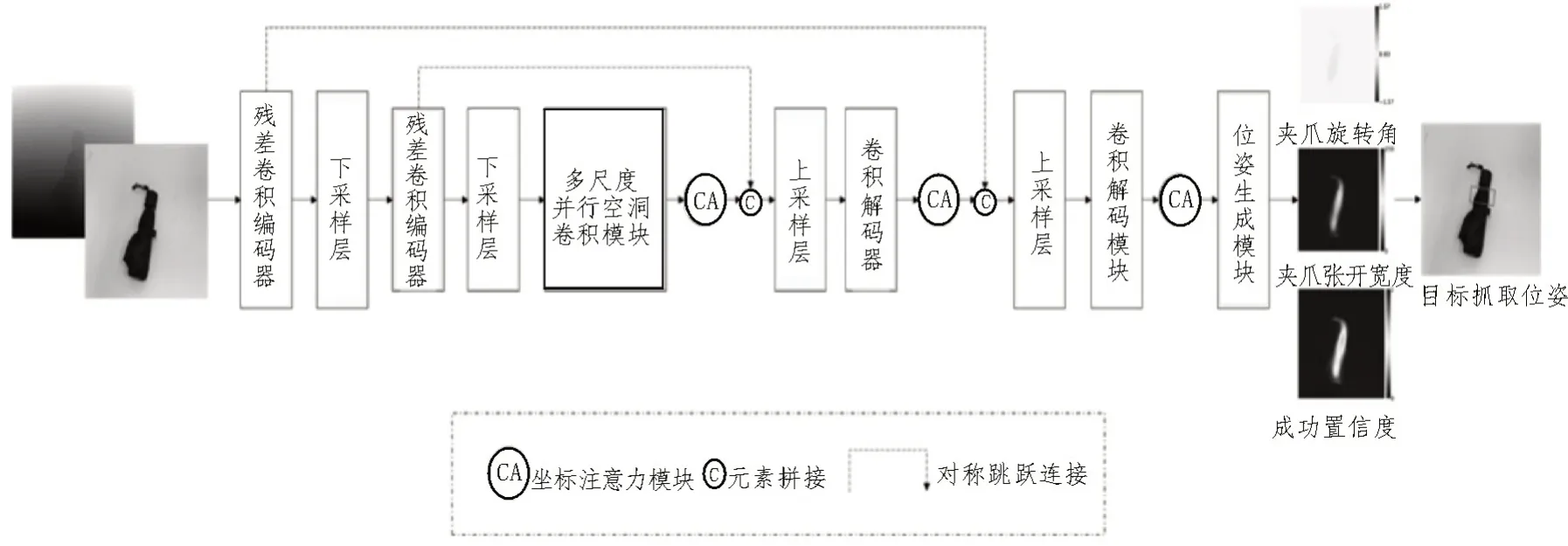
图1 残差注意力生成网络及生成结果图
1.1 编码器
相比原有抓取位姿生成研究,为了进一步增强网络的特征提取能力,编码器部分采用残差卷积模块获取更丰富的特征表示,通过特征向量的跨层传递,在训练中加速了网络的收敛,避免出现梯度消失的问题。残差卷积模块采用较大的卷积核设定,进而获得更大的感受野。
1.2 聚合层
为了解决残差注意力生成网络面对不同目标尺寸波动时的检测鲁棒性问题,文中在聚合层引入了多尺度并行空洞卷积模块。多尺度并行空洞卷积模块采用瀑布结构,通过空洞卷积在保留图像分辨率的情况下扩张图像的感受野。文中方法针对每个分支,分别设置了不同的卷积核大小与扩张率,以有效获取不同尺度下的上下文语义信息,强化残差注意力生成网络在面对不同尺寸大小目标时的检测鲁棒性。另外,有针对性地在聚合层使用多尺度并行空洞卷积模块策略,使文中方法在少量增加网络训练量与模型参数的同时有效改善了网络鲁棒性与精度表现。多尺度并行空洞卷积模块如图2 所示。
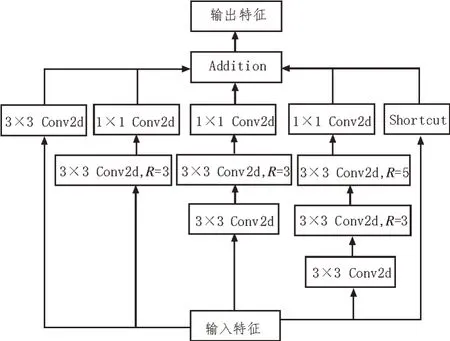
图2 多尺度并行空洞卷积模块
1.3 解码器
不同于编码器与聚合层主要关注于提升网络的特征提取能力,解码器部分更多聚焦于从已提取的特征中发掘更多有效信息。因此文中在解码器部分融合了注意力模块与对称跳跃连接策略,其中对称跳跃连接策略以将对应编码器模块特征传递到对应解码器模块中的连接方式,保留了不同层次的细粒度特征细节,而注意力模块通过将位置信息嵌入到通道注意力中,沿两个不同空间方向进行特征聚合,生成一对位置敏感与方向敏感的注意力参数Ch、Cw,并将这对参数互补地应用于输入特征,进而增强对关注目标的特征表示。注意力模块的输入输出关系为:
2 抓取位姿定义
文中研究对象为给出多模态图像数据的新物体抓取位姿,采用已有研究提出的矩形度量方法[16-17]评估网络生成的抓取位姿生成结果。文中将多模态图像中的新物体抓取位姿定义为:

其中,pi代表了末端夹爪抓取中心点的二维坐标(u,v),wi代表末端夹爪的张开宽度,θi代表末端夹爪旋转角,范围为[-2/π,2/π]。而qi代表基于像素级层面的末端抓取位姿的成功概率预测常量。图3所示为抓取位姿示意图。

图3 抓取位姿示意图
3 实验及结果分析
3.1 实验环境
文中硬件环境使用的显卡为Nvidia GeForce RTX 2080ti,实验平台与系统是Ubuntu16.04、Pytorch深度学习框架。
3.2 实验数据
文中实验基于公开的康奈尔抓取位姿检测数据集展开,此数据集共包含240 种不同物体的885 张RGB-D 图像与对应图像中物体的基准夹取位置描述文件。
由于康奈尔数据集样本量相对较小,因此在实验中采用了随机裁剪、随机缩放和随机旋转等数据增强操作对康奈尔数据集进行数据样本数量的扩充。在实验的训练与评估阶段,将数据集按照9∶1的比例划分为训练集与验证集。
3.3 模型训练策略

文中提出的残差注意力生成网络使用Xavier 正态分布作为网络参数的初始化方法,使用Adam 方法作为网络优化算法,其中Adam 初始学习率设为0.000 1,文中提出的网络结构采用Huber Loss 作为损失函数。
3.4 结果评价标准
为了验证文中方法的有效性,选取了与已有研究方法相同的评测标准,即当网络生成的抓取位姿符合下述两个条件时视为一次成功的机械波末端抓取位姿,具体评价标准为:
1)文中方法的预测末端抓取框与数据集基准抓取框的夹角小于或等于30°。
2)文中方法的预测末端抓取框与数据集基准抓取框的交并比指数大于25%。
3.5 实验结果
为验证文中提出的残差注意力生成网络在新目标抓取位姿生成问题上的有效性,在康奈尔抓取检测数据集上进行了实验验证,并设置了消融实验用于评估不同模块对于网络检测能力的影响。
3.5.1 康奈尔抓取检测数据集结果
将文中提出方法的残差注意力生成网络与已有研究从两个维度进行比较,分别是检测精度与检测时间,在多模态数据下分别进行了测试,如表1 所示。从表1中结果可发现,得益于更丰富的特征信息,文中方法使用RGB-D 图像在康奈尔数据集上获得了96.6%的检测精度与18 ms 的实时检测时间,优于其他相关研究方法的实验结果,证明了文中所提方法的有效性。
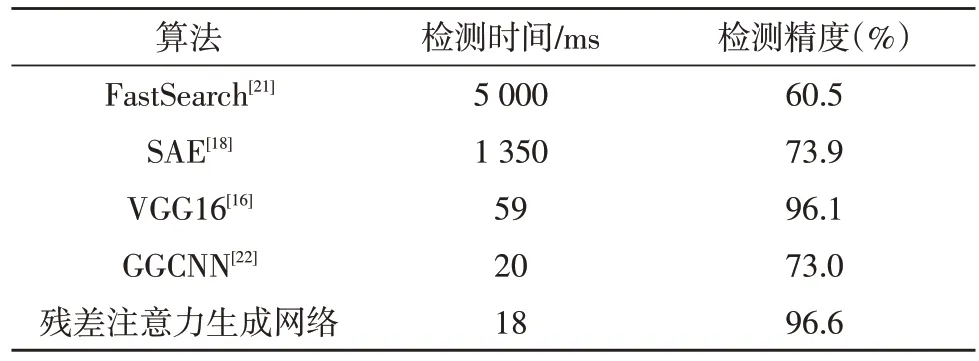
表1 康奈尔抓取检测数据集结果
3.5.2 消融实验
为了增强残差注意力生成面对新物体的泛化能力,文中提出的网络结构不仅采用残差卷积模块、多尺度并行空洞卷积模块用于增强网络的特征提取与表达,还融合了对称跳跃连接策略、注意力机制以强化目标特征细节。因此文中基于康奈尔数据集的RGB-D 图像数据进行了消融对比实验,以研究残差注意力生成网络结构中使用不同模块策略对检测精度带来的影响。实验结果如表2 所示,其中实验一采用了包含残差卷积模块与跳跃连接策略的基础残差注意力生成网络结构,实验二添加了多尺度并行空洞卷积模块,实验三添结构加了注意力模块,实验四采用综合所有策略的残差注意力生成网络结构。

表2 消融实验结果
实验结果表明,文中所提出的融合注意力机制与对称跳跃连接策略的基础网络结构得到了92.1%的精度表现,证明了文中所提基础网络结构的可行性。随后,基于基础网络分别评估了添加多尺度并行空洞卷积模块与注意力模块对网络精度表现的增益,实验结果显示,受益于特征信息丰富度的增加,使用这两种策略分别令基础网络结构取得了2.2%与0.9%的精度提升,而最后通过融合所有策略,文中最终提出的残差注意力生成网络结构在康奈尔抓取检测数据集上得到了96.6%的精度表现。
4 结论
为了解决机器人面对未见过的新物体时实时有效地生成目标抓取位姿的问题,文中创新地提出了一种残差注意力生成神经网络结构,这种结构融合了位置注意力机制、多尺度并行空洞卷积模块与对称跳跃连接策略,在抓取位姿生成问题的速度与精度上取得了一个较好平衡。实验结果表明,在康奈尔数据集上,文中提出的方法在实时生成速度下获得了不错的抓取位姿生成精度,验证了文中所提出方法的有效性。在后续的工作中,将主要着力于针对难样本的检测精度改善。
猜你喜欢
延河(2019年6期)2019-06-28 02:37:38
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
微型小说选刊(2015年33期)2015-11-17 11:41:24
中学生(2015年12期)2015-03-01 03:43:52
