
联邦学习公平性研究综述*
2022-11-04 02:23:06王文鑫张健毅
北京电子科技学院学报 2022年2期
王文鑫 张健毅
北京电子科技学院,北京市 100070
引言
近年来,随着互联网与大数据时代的来临,深度学习越来越受到社会各界的广泛关注[1],数据分析师可以通过整合各种零碎数据来进行对某件事或某个人的信息分析,进而预测潜在结果发生概率。 如淘宝、京东等大企业的应用程序经常会精确地把一些符合消费者偏好的商品推荐给用户,这其中的推送方式或通过购物者的日常消费记录,或凭借其他APP 获取购物者自身相关信息(如消费者的性别、到访地、接触人群等)。 虽然两种方式有着些许的差异,但是大致都是通过深度学习把消费者日常相关信息进行大量训练分析来形成数据预测[2]。
不过深度学习是先构建中心服务器,然后将多个客户端数据进行整合与训练,这样可能导致各方数据安全不能得到充分保障,比如在医疗、金融等重要行业,企业无法将己方数据信息传递给潜在的竞争对手,而且同一单位的不同部门相互之间信息也无法完全共享。 随着2018 年欧盟史上最严隐私法规——《通用数据保护条例》(GDPR)的颁布[3],越来越多的企业和单位对于个人敏感信息提起高度重视,例如2019 年英国航空公司由于违反《一般数据保护条例》被英国信息监管局罚款1.8339 亿英镑。 而我国在2020 年颁布《信息安全技术个人信息安全规范》和《个人信息保护法》,这些法规的制定旨在保护用户个人隐私和规整行业数据的处理规范,且对如今普遍采用数据驱动的发展提出了新挑战。为了解决数据安全问题和实现信息孤岛全面共享,谷歌2016 年提出联邦学习(Federated Learning,FL)的理论概念,其主要是通过将用户端数据存储和模型训练阶段转移至本地用户,而仅与中心服务器交互模型更新的方式有效保障用户隐私安全[4]。
公平性指系统开发过程不偏袒于任何一方。在实际生活中,所有公共和私有行为者都必须防止和减轻机器学习的设计、开发和应用中的歧视风险。 随着联邦学习技术[5,6,7]的逐渐兴起,公平性问题成为制约其发展的一个短板一般来说,训练的数据和数据集并非客观存在,而是人类主观设计的产物。 从数据收集到算法推演,从程序运行到结果初步评估,再到最后分析师得出满意的预测结果,各种各样的操作都参与到深度学习的训练中,难免其中一些步骤存在偏差。 例如机器学习开发人员在对数据进行预处理时,由于没有意识到数据集中可能的偏差,训练之后便会得出与事实相背的结果。 尽管公平性问题对于个人实验结果影响或许微乎其微,不过在工业界细小差异可能造成不可预估的损失[8],由此联邦学习公平性是如今急需探究的话题。
本文通过调研发现大部分文献侧重于局部公平探讨,缺乏系统总体的公平性研究。 比如为使各客户端资源分配更具公平的准确性,文献[9]提出高效通信方法q-FFL,但却缺少数据不公与权值分配差异的分析;为使数据和模型遭受中毒攻击时保持稳健性和公平性,文献[10]提出个性化联合学习框架Ditto,但却缺少存在偏见对于系统公平的影响;为使数据异质性下联合模型训练偏差减少,文献[11]讨论FL 偏差存在的原因以及提出削弱偏差的方案,但却缺少对于偏差类别的形式化分类[12,13]。 在先前一系列文章的基础上,本文进行详细的归纳,并对偏差的出现、偏差的解决和公平性的分类方式等提出自己的见解。 本文脉络如下:第1 章节总体介绍联邦学习公平性架构,第2、3、4 章节分别阐释偏差分类、公平机制和公平性系统应用,第5 章说明未来发展方向,第6 章进行全篇结论。
1 联邦学习介绍
主要介绍传统联邦学习迭代过程和公平联邦学习系统设计思路,并对公平性展开数学定义,之后根据实际迭代过程梳理系统整体层次结构,将公平联邦学习分为公平认知表征、公平算法建模和公平评估决策三个阶段分别讨论[14]。本节使用符号及其意义说明详见表1。

表1 本节符号表
1.1 传统联邦学习
与集中式机器学习所不同,传统联邦学习是基于分布式机器学习技术。 各客户端(PC、移动终端等)不再将自身数据直接传送给中心服务器统一训练,而是在本地训练后形成模型参数传送给中心服务端,中心服务器把各个传送的模型加权集合形成全局模型再传输给各个客户端,如此反复迭代直至全局模型收敛,中心服务端函数可表示如下:

1.2 公平联邦学习
公平联邦学习[15]是在传统联邦学习基础上,考虑系统模型训练时认知表征、算法建模和评估决策的公平性对于聚合梯度的影响,减少三阶段偏见的生成,从而使得系统设计更大程度满足于各参与方需求,并符合国家相关法律标准和伦理规范。 比如文献[16]提出新型鲁棒公平联邦学习(RFFL)框架,通过声誉机制实现系统协作公平和对抗鲁棒性,本文公平联邦学习表示如下:

由图1 可知X,Y,Z,L,H阶段可能存在偏差歧视的现象。 比如认知表征阶段(X), 数据收集、数据集输入可能由于采样者不同而引入不同的采样行为偏差;算法建模阶段(Y,Z,H),程序实现、模型训练可能由于算法设计存在偏见而使得整体系统歧视的产生;评估决策阶段(L), 实验评估、结论归纳可能由于研究者自身认知局限性导致实验数据与真实结果因果关系存在差异。由此可知,联邦学习系统迭代过程或多或少存在不公的风险。
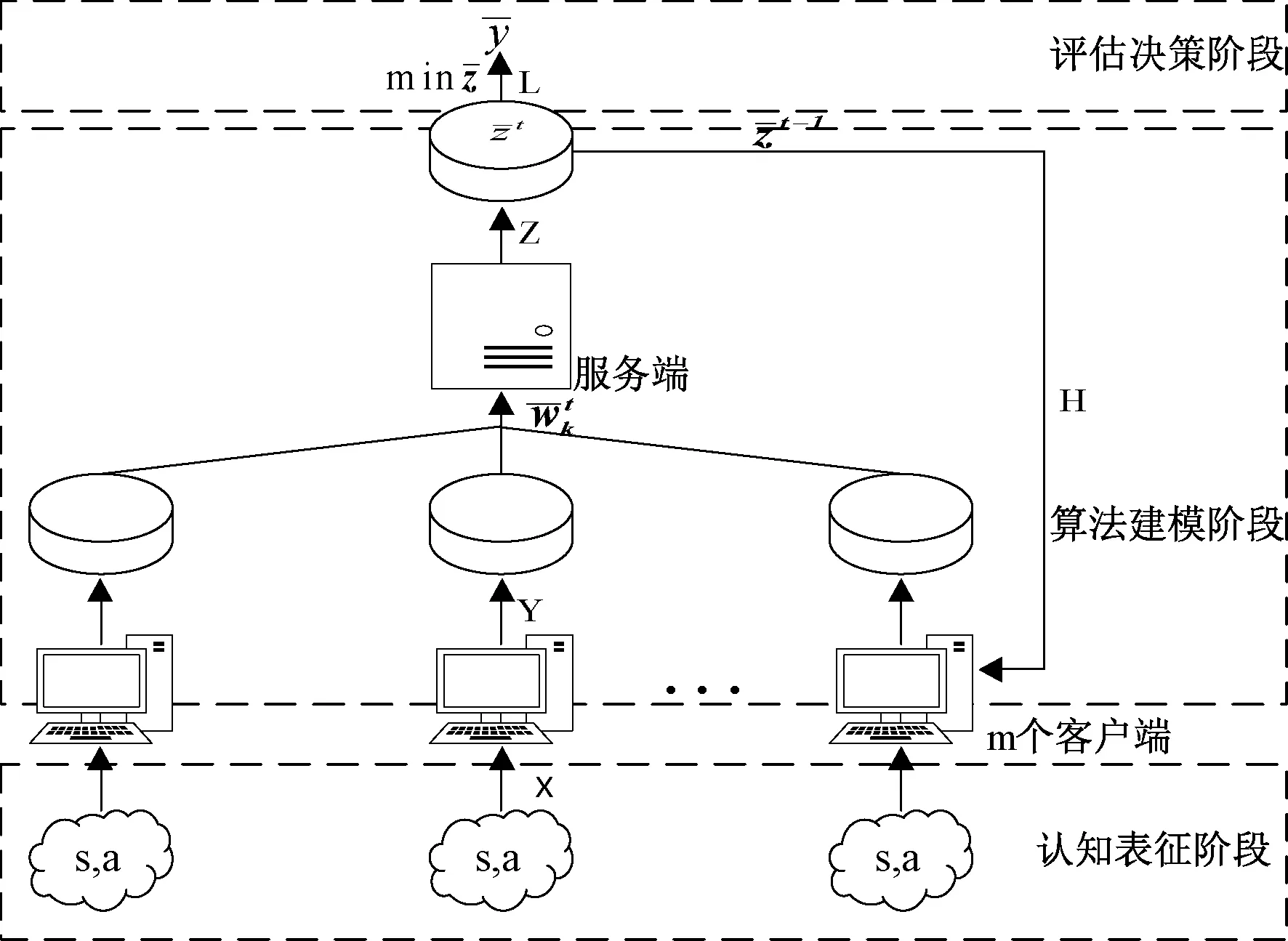
图1 联邦学习迭代架构图
若实现整体系统架构公平性,那么必须要认知表征、算法建模和校准决策三阶段分别公平(如图1)。 由此联邦学习公平性系统可以根据数据处理阶段划分为三部分:公平认知表征、公平算法建模和公平评估决策。 公平认知表征存在于数据输入阶段,其主要包含数据收集、数据集输入和特征提取等公平;公平算法建模存在于模型训练阶段,其主要包括算法设计、程序实现、模型建立和聚合等公平;公平评估决策存在于评估决策阶段,其主要包括数据校准、实验评估和结论归纳等公平。
本文通过预处理、处理中和后处理三种方式解决认知表征、算法建模和决策评估的公平,从而使得传统联邦学习系统转变为公平联邦学习系统。 其中预处理机制包括数据重采样和寻找特征函数,处理中机制包括重新加权和增加约束项,后处理机制包括调整预期阈值、使用去偏工具和增加风险评估等方式。
2 偏差类别
在联邦学习系统中,研发者主观上无意造成偏见,不过往往有些偏见是无意识产生,从而导致系统开发存在偏差。 结合Suresh 等人对不同类型偏差分析,本节将常见偏差分类为认知表征偏差、算法建模偏差和评估决策偏差。

图2 公平联邦学习架构图
2.1 认知表征偏差
认知表征偏差主要存在于数据收集、数据集输入阶段,本小节将认知表征偏差划分为:历史偏差[17]、抽样偏差[18]、测量偏差[19]、标签偏差[20]和行为偏差[21]。
历史偏差:指一些模型通过当时数据训练得到的结果与当今社会数据训练得出的结果存在差异。 如2018 年浏览器图片搜索关键词“女性CEO”时会减少女性CEO 图片出现的情况,究其原因是因为当时世界500 强中女性CEO 只占5%。
抽样偏差:选取样本没有使用随机采样导致数据样本失去评估总体的能力。 可具体分为:偏见偏差[22]、链接偏差[23]、代表性偏差[24]等。 偏见偏差指研究人员无意识情况下将自身期望映射到抽样阶段从而产生偏差,如根据种族、性别、地域等相关信息来评价某种事物,这是带有偏见色彩的。 链接偏差指受访者通过网络链接向调研者收集数据,由于匿名化和网络化导致信息收集可能与真实用户信息存在差异。 代表性偏差指研究者对某个事件判断过度注重某个特征,反而忽视其他具有影响力的特征。
测量偏差:指测量值与真实值之间存在的误差。 美国累犯风险预测工具涉嫌歧视案中有这样一个结论:由于来自少数族人群的逮捕率较高,所以他们更有可能犯罪。 研究发现逮捕率较高的原因是少数族裔社区相比于白人种受到政府更频繁的控制和监管,这种在评估群体存在差异的方式属于测量偏差。
标签偏差:标注者为某一实验样本分配带有歧视的标签从而产生偏差。 Jiang H 等人研究标签偏差并证实在不改变标签的情况下通过重新加权数据集方式可以纠正标签谬误导致的偏差,从而设想无偏机器学习分类器的生成[25]。
行为偏差:行为偏差是指不同平台面对不同用户产生不同影响。 如不同网络平台之间表情符号表现形式差异可能导致用户反应和行为存在不同,甚至出现沟通错误的情况。
2.2 算法建模偏差
算法建模偏差主要存在算法设计和数据训练阶段,可以根据层次结构将模型偏差划分为客户端偏差和服务端偏差两大类:其一客户端偏差是指当多个客户端通过模型参数与本地数据训练时由于算法不合理导致客户端偏差的存在。其二是服务端偏差,当多个客户端将更新权值传输给中心服务器时,根据伯克森悖论[26](多个通常独立的事物会在特定场合下形成关联带来偏差)可知中心服务器聚合后的模型可能与实际模型相差甚远。 算法建模偏差也可根据机制差异分为混杂偏差[27]、资源分配偏差[28]、激励机制偏差[29]和省略可变偏差[30]四部分。 混杂偏差指模型算法没考虑对象全部信息,或没考虑特征和目标输出之间关联,从而学习错误的关系造成偏差;资源分配偏差是指中心服务器通过降低最小损失函数导致训练时对各个客户端造成偏差,显然各个客户端获得相同的模型参数对于提供数据资源较多的客户端是不公平的;激励机制偏差是FL 技术与区块链技术结合时存在的情况,当整个联邦学习系统获得外部贡献时,客户端通过制定利益分配方案获取各自利益时存在一定偏差;省略可变偏差是指当模型遗漏一个或多个重要变量时产生的偏差。 例如某商家设计较高准确度模型来预测客户喜爱产品程度,由于出现新的竞争对手导致很多客户选择其他商家产品,而模型却并没有根据实际情况更改导致出现偏差。
2.3 评估决策偏差
评估决策偏差主要存在于数据校准、实验评估和结论归纳阶段,此阶段可能由于研究者自身局限性(知识存储量不足或认知谬误),导致实验结论与真实原理存在差异。 此类偏差根据实验处理过程可分为:评估偏差[31]、因果偏差[32]、汇总偏差[33]、验证性偏差[34]和辛普森驳论[35]。
评估偏差:是指模型评估阶段存在的一种偏差。 例如一些基准(IJB-A)在具有种族或性别歧视的人脸识别系统评价管理中应用,如果使用这类不相称的基准来评估实验最终模型,可能导致实验结果无意识的歧视产生。
因果偏差:是指研究者没有正确把握问题隐含因果关系,当只通过表面现象主观臆断时,可能导致相关性谬误出现,从而使得因果偏见生成。 因果关系是研究者认知归纳常用方法,只有正确把握问题的因果结构,才能确立正确思维,得出正确实验结论。
汇总偏差:汇总偏差又称作整理偏差,指训练数据在汇总整理阶段所形成的误差。 训练聚合数据需经过层层汇总才能形成为反映评估实验的结论信息。 由于汇总方式的不同,统计整理时此类偏差可分为手工汇总偏差(手工整理偏差)和机器汇总偏差(机器整理偏差)。
验证性偏差:是指研究者对某一观点或信念形成意识形态后,在分析信息和实验评估时,若真实结果与理论原理存在差异,可能为了自身信念反复质疑甚至全盘否定真实结果。 文献[35]表述当研究者个人信念影响研究问题和方法的选择时便会产生偏见,并举例一制药公司研究人员可选择支持制造药物有用性的研究问题。
辛普森驳论:当实验者研究两种变量关联性问题时,一般采用分组比较法观测,然而在分组比较占优一方可能在总评处于劣势地位。 如加州大学伯克利分校大学因不同学院女性新生比男性新生录取率更少而被诉讼一案,调研者对各个学院新生分组剖析时却发现女性申请人具有平等性,且在某些学院中录取人数女性比男性更多。

表2 偏差类别
3 不公平案例
如今FL 技术在越来越多领域展开应用,为了更直观介绍偏差对于FL 的危害,本节通过两个不公平案例简单说明。
3.1 COMPAS
COMPAS(Correctional Offender Management Profiling for Alternative Sanctions)是越多越多美国的法官、缓刑和假释官使用的累犯风险预测工具[36],其主要用于被告保释评估阶段,算法可定义为:S= (Y-W) + (Yf-W) + (C*W) +(E*W) + (I*W),其中S表示累犯风险预测分数,W表示权值系数,Y表示被告年龄,Yf表示首次被捕年龄,C表示历史暴力情况,E表示教育水平,I表示违法历史,从中不难观测分数与种族并无联系。 然而ProPublica 团队发现预测工具隐含偏见:黑人被告被错误归类为高暴力累犯风险是白人可能性的两倍。 COMPAS 出现种族偏见的主要原因是:“历史暴力情况”、“教育水平”等在不同种族间存在显著差距。 在违法历史的讨论上,相同犯罪在白人、亚裔、非裔黑人等种族之间存在明显差异,进而导致某种程度上偏向或不利于某个种族,从而使得累犯风险预测工具COMPAS 不公平的产生。
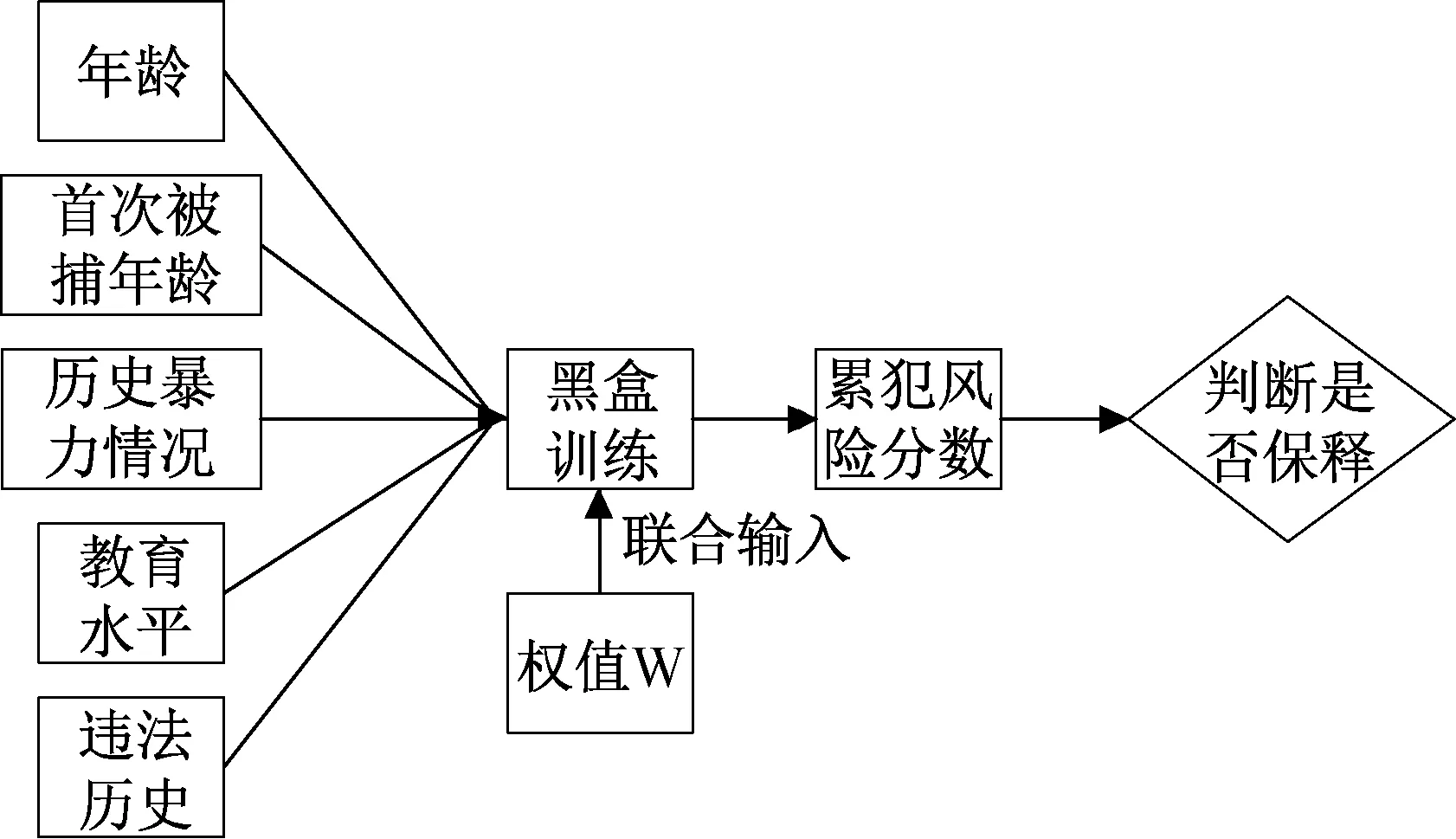
图3 COMPAS 预测算法过程图
3.2 保险定价
如文献[37]一出租车公司B希望为全体司机上保而与保险公司A合作。 这时单一训练出租车公司历史数据不足以清晰评估司机出险情况,所以保险公司采用多方联合方式更精确预测保险个性化定价。 假设X表示司机历史出险概率,Y表示乘客满意度等其他敏感特征信息,此外由于各保险公司间存在合作,保险公司A一定程度能获取其他保险公司C的司机投保特征数据,此部分属性可设定为Z,以上数据以聚合模型传输。 令X1= (ID,x,y),X2= (ID,z), 可用逻辑回归模型预测:L=sigmoid(W;X1,X2),W表示联邦学习中模型多轮迭代聚合收敛的最优参数。 若此过程中B、C公司数据标签存在差异,或公司C的数据量Z过小且不具代表性等,将可能导致回归模型预测保险定价与实际本应定价存在差异。

图4 保险定价流程
4 公平性探讨
近年来,由于工业界对于数据集精度要求与日俱增以及避免偏差对于经济损失造成重大影响,许多研究团队致力于探讨公平性问题。 比如刘文炎团队[14]提出可以把公平性类别分为感知公平性、统计公平性和因果公平性三部分,感知公平性主要关注于处理敏感属性和一般属性的平衡,或使用减少敏感属性输入以达到减少偏差的目的,或通过差分隐私使得敏感特征加权实现与一般特征的公平;统计公平性主要关注于数据和算法的公平,使得受保护群体和非保护群体的预期结果与真实结果保持一致;因果公平性通过干预实验的因果模型、实验者意识的因果关系来研究受保护属性对于实验结果的影响。 文献[38]中提出基于FL 的一种实时算法以实现贡献公平、遗憾分布公平和期望公平三种公平性指标,由于FL 基于多方合作传输梯度模型以实现资源共享,所以需要各方利益分配合理才能使得整个系统持续运转。 本章节根据Gajane 和Pechenizkiy 等人系统化研究将公平性分为群体公平、个体公平、无意识公平、反事实公平、基于偏好公平五种类型[12,13],并通过预处理、处理中、后处理三阶段对FL 公平性机制开展探讨。
4.1 公平性分类
群体公平[39]:特定属性在不同的群体间通过FL 算法应呈现相同的概率。 假设a= 1 表示受保护属性,Y表示实际输出结果,现有B、C两个群体,则可根据定义表示为:
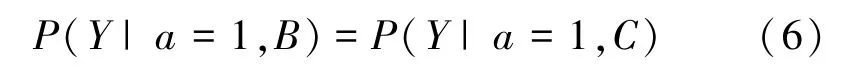
群体公平可依照度量形式不同分为统计公平、精度公平、均等公平。
个体公平[39]:如果一对个体具有相似的属性,FL 算法应该输入相似的概率。 若b1,b2 分别为群体B中的个体,a=1 表示受保护属性,Y表示实际输出结果,那么可表示为:

无意识公平[12,13]:FL 过程中,如果个体的同类型属性(受保护属性和一般属性)出现相似的决策,换言之受保护属性不影响系统输出结果,那么预测器被称为通过无意识实现公平。 假设a= 1 表示敏感属性,a= 0 表示一般属性,Y表示实际输出结果,A为一个个体,则根据定义可表示为:
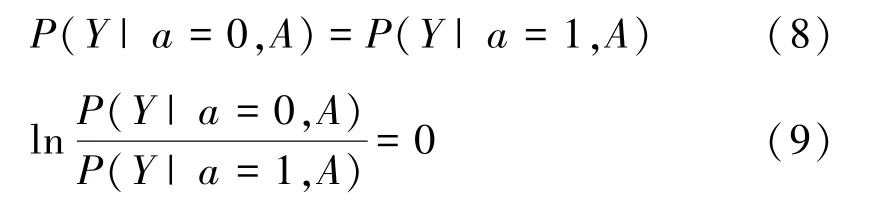
基于偏好的公平[40]:Zafar 等人[41]从经济学和博弈论角度出发得到基于偏好公平的概念,当在不同群体间给定多种选择时,群体中的个体往往自发选择有利于自身发展的决策执行。 假如分类器X对种族B提供不低于分类器Y的益处,那么当决策选择时种族B根据基于偏好的公平更容易选择分类器X,可表示为:

反事实公平[42]:Kusner 等人[42]描述受保护属性和数据之间关系时提出一种反事实公平。定义如下,假定现实世界带有受保护属性的数据集训练得出的结果与在反事实世界运算得出的结果一致,则说明遵从反事实公平,这种对公平性的衡量也提供了一种解释偏见原因的机制。

表3 公平性分类
4.2 公平性处理
4.2.1 预处理机制
预处理机制是指采取数据层面去偏方式以实现FL 系统输入时的认知表征公平,其主要采用数据重采样技术[43]。 数据重采样技术表示重新选取样本数据以减少预期结果和真实结果之间的偏差。 比如当研究者发现样本属性带有偏见时,可以选择减少带有偏见的采样数据或去除受保护属性的信息,不过直接去除特征中的敏感属性可能会造成实验结果出现误差。 又如当采样数据的不同属性采样比例不一致时,根据马太效应占比更大的属性会在模型训练中比例越来越多、占比更少的属性会在模型训练中越来越少,从而出现两极分化的局面,这时可以使用重复采样少比例样本来实现数据采集的公平。 还可以通过寻找合适的特征函数,将原来带有受保护属性的函数X转换为一般属性的函数Y,但是函数Y仍然具有很强的特征表达能力,从而使得FL 系统输入时具有公平性。
4.2.2 处理中机制

图5 预处理机制过程图


图6 处理中机制过程图
4.2.3 后处理机制
后处理机制是指决策层面去偏方式以实现FL 系统输出时的后验评估公平,其方法形式也多种多样。 首先当分类器聚合各参与方传输的权重多次迭代形成最终收敛时,研究者可以通过调整预测阈值对模型进行后处理或直接修改联邦学习的输出结果以满足验证决策的公平;其次研究者可以使用一个有效去偏工具[44],根据可解释技术生成特征向量,然后对特征向量进行分析,去除其中的偏见结果以实现公平;最后还可以在训练完成的模型后增加风险评估算法,通过再训练模型来评估偏见,以预测数据的偏差程度,如果结果偏差较大,则需要改进实验、重新训练,如果偏差较小,则可以修改数据以满足公平性。 例如Galhotra 团队开发出一种基于测试的方法Themis 来识别模型训练时存在的歧视以及歧视程度。

图7 后处理机制过程图
5 公平性系统
5.1 公平性数据集
COMPAS 数据集[45]:COMPAS 数据集包含2013、2014 年美国佛罗里达州布劳沃德县11757名被告人的姓名、性别、年龄、种族等相关信息,其任务是通过计算累犯风险预测分数,进而来预测被告人的累犯概率和累犯高风险概率。 该数据集可以研究种族和性别对于被告再次犯罪的影响。
Adult 数据集[46]:Adult 数据集包含1994 年美国人口普查中48842 条居民信息,囊括年龄、种族、工作性质、教育程度、婚姻状况、国籍和收入等14 项属性,其任务是根据教育、每周工作时间等属性预测给定的成人是否年收入超过50000 美元,该数据集可以研究国籍、种族和教育程度等对于年薪收入的影响。
German Credit 数据集[47]:German Credit 数据集包含1000 名贷款申请人的20 种特征属性,比如现有支票账户状态、信用记录、贷款目的等,其任务是通过训练来预测借贷人信用风险好坏分类,从而实现银行贷款的风险最小化和利益最大化。
WQDB 数据库[48]:WQDB 数据库是由美国地质调查局与密苏里州哥伦比亚市和密苏里州环境保护部合作收集1998 年到2005 年地下水和地表水位数据等形成的研究,包括900 个联邦、州等超过3.8 亿条水质数据记录,物理特性、化学成分、营养物质等多种属性,其主要用于研究水质情况的预测。
5.2 去偏平台
TensorFlow 是由谷歌公司开发的第二代数字计算软件库开源系统,可便捷应用于PC、服务器和移动终端。 其工作模式如下:TensorFlow 系统先调用TensorFlow 约束优化库,然后根据不同指标(如种族、性别等)来配置联邦学习系统环境,最后为用户提供最小化和约束指标任意组合的功能,由此解决系统公平性问题。
WhiteNoise:WhiteNoise 是由微软与哈佛研究所联合开发的工具包,其可通过差分隐私方式保证各参与方的隐私安全和统计公平性。 例如多家医院科室协同搭建一个实行重症治疗的预测模型,依靠差分隐私技术能够使得各参与方不用直接通过数据进行信息的传输,从而减少个人信息被泄漏的风险以及增加各参与方数据采集的正确性。
6 未来研究方向
(1)资源分配更趋近公平
联邦学习系统中,当中心服务器将聚合后的模型参数分配给各客户端时,每个客户端从中心服务器获取相同模型或者平均分配模型参数(Fed-Avg)对于向服务端提供更多数据模型的参与方显然不公平,所以如何更合理资源分配使得各参与方认为己方公平是值得后续学者认真考虑的问题。
(2)公平性与准确性的界定
在公平性解决方案中,研究者可以通过差分隐私技术实现联邦学习算法的公平,不过差分隐私的引入可能导致噪声过大,从而降低模型训练的准确性[49]。 所以如何更合理控制噪声大小使得公平性与准确性达到一个临值也是需要后续进一步讨论。
(3)联邦学习与区块链结合的公平
近几年随着区块链技术的兴起,联邦学习与区块链结合引发激励机制问题[50]成为学术界热衷的新热点,不过如何合理分配各方利益也是一个关键的难题。 若给予某些参与方的利益没有达到心理预期,可能这些参与方擅自退出整个联邦学习系统,若给予某些参与方利益过高使得其他参与方感到不满,可能其他参与方也会离开此系统,从而导致整体模型数量级减少和利润总和降低,甚至产生不可预想的蝴蝶效应,所以联邦学习与区块链关于激励机制分配公平也需要加深探讨。
7 结束语
目前,公平性定义衡量标准在世界范围内没有统一确立,且系统研发多数情况下偏差的出现是由于设计者无意识行为导致,所以仅仅依靠技术算法层面去偏不能真正实现联邦学习公平性问题,还需要进一步完善相关机制,形成社会、法律、道德等联合一体化整治规范。 不过随着社会的不断发展和人们对于网络信息安全意识不断增强,相信在不久的将来,联邦学习公平性相关问题在社会各界的共同重视下得到进一步解决和完善,相关项目产品研发也将减少无意识偏差引入带来的危害。
猜你喜欢
家庭影院技术(2020年10期)2020-12-14 07:54:16
学生天地(2020年6期)2020-08-25 09:10:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:36
家庭影院技术(2019年7期)2019-08-27 02:42:06
电脑与电信(2018年12期)2018-03-23 02:37:36
高中生学习·高二版(2016年11期)2016-12-01 20:00:48
系统医学(2016年8期)2016-02-20 02:55:08
中国卫生(2015年3期)2015-11-19 02:53:16
华东理工大学学报(自然科学版)(2014年1期)2014-02-27 13:48:36
俄罗斯问题研究(2013年1期)2013-03-11 15:43:59
