
人像自动提取与处理软件设计与实现*
2022-11-04 02:22:34刘清雨
北京电子科技学院学报 2022年2期
刘清雨 蒋 翔 金 鑫
北京电子科技学院,北京市 100070
引言
图像提取是将照片中的目标前景部分从背景图像中分割出来的一种技术,在图像融合、图像增强复原等图像编辑技术中具有重要地位。
20 世纪90 年代,学者首次提出了图像背景移除的数学定义,引入透明(alpha)通道的概念,用于控制前景和背景融合时的线性插值比例。随着数字图像领域逐渐走向成熟,图像提取技术在日常生活已经普遍适用,尤其在媒体制作领域[1]。 传统图像提取算法通常根据颜色、纹理等低级特征从已知确定像素部分推测不确定像素部分,而没有利用高级语义信息,此类方法并不适用于前景颜色相似或者纹理复杂的图片;传统图像提取算法利用逐像素的处理方式扣取前景,耗时较长,此类方法并不适用于实际应用中对前景高质量和高速度处理的需求。 随着深度学习被多方关注研究,其理论不断完善,李飞飞等人建立了ImageNet[2]大型数据集,依赖于大数据集的卷积神经网络在计算机视觉、自然语言处理等领域爆发了强大生命力,图像提取与深度学习的结合也顺理成章,通过深度卷积神经网络的强大拟合能力,能有效提取前景与背景之间的结构信息、语义信息,因而不完全依赖于简单的颜色信息实现抠图效果。 基于深度学习的人像自动提取和处理算法相比于传统算法在生成图质量上有了很大的提升,使得最终网络输出的图在细节上有更好的预测结果。
目前市面上已经存在多款集成抠图功能的APP 应用[3],主流的有:Photoshop、美图秀秀、美颜相机、轻颜相机等,但它们用到的原理大多都不涉及深度学习。 Photoshop 软件用的是通道抠图,它的本质是利用通道保存颜色这一特性,通过亮度差异来确定选区;美图秀秀等美颜相机用的是grabcut[4]等传统算法,它需要用户进行一些交互式操作,手动将要提取的部分画出来,才能进行抠图。
本文针对人像,实现了自动化提取并处理人像,提取的人像部分边缘分割清晰,信噪比高,有效地优化了人像提取的准确度。 主要贡献如下:
(1)提出了BiSeGAN 网络,以GAN 网络框架为基础,采用BiSeNet 结构作为生成器网络进行训练,可以很好地分离人像和背景,提高了模型的识别速度和精度。
(2)分配混合损失函数以不同的权重,共同优化网络参数,有助于模型快速收敛,使生成器生成更真实的目标图像。
(3)利用百度飞浆这一深度学习平台将训练好的BiSeGAN 模型部署到Andriod 手机上,并基于OpenCV 研发出一款能够实现背景替换和美颜滤镜功能的APP,致力于移动端的AI 化,以满足人们制作证件照和趣味图片等实际需求。
1 人像提取与处理实现方法
1.1 实现方法概述
人像提取领域的关键问题就是求解以下公式[5]:

其中,I(Image)是当前用户输入的图像,α是透明度,F(Foreground) 是照片的前景,B(Background)是照片的背景。 由于,从一张输入图片不能较好地区分前景像素和背景像素,所以α、F、B这三个变量是未知的[6]。
这个公式提供了一种思路,它提出原始图像是由若干个不同对象组合形成的图片,系数α控制着这些对象的归属,决定对象属于前景还是背景。 当α=1,说明它是不透明的,属于图像中的前景;当α=0 时,说明它是透明的,属于图像中的背景。 但在实际情况里,我们不能完全确认哪个像素归属于前景,哪个像素归属于背景,它们没有明确的界限,α不仅仅是0 和1 这两个数值,而是在0 ~1 区间的任意一个数[7]。 由此看来,研究改进人像提取算法就是考虑如何能让计算机更好的分辨像素归属,从而更加快速的得到更准确地人像提取结果。 在得到每个对象的α值后,就会生成一张蒙版图,从图1 可以看到它将原图像的前景与背景划分出来,黑色部分是前景,白色部分是背景。 最后,结合蒙版图和原图,就能实现人像提取。

图1 人像提取的蒙版图
本系统基于深度学习的深度卷积神经网络,建立一种全自动人像及其各部分的精细分割技术算法,捕捉图像的高层次特征,并根据肖像的特定特征,生成高质量的蒙版图,更加快速、准确地提取出人像及其各部分,减少用户后期修正与图像处理时间,提升图像处理效率与质量。 本软件通过PaddlePaddle 将深度学习的模型部署到Andriod 手机上,完成Andriod APP 的制作。
1.2 BiSeGAN 网络架构
本文提出了一种BiSeGAN 的网络结构,包括两个模块:生成器和判别器。 本方法以生成对抗网络(GAN)框架为基础,采用BiSeNet 结构作为生成器网络以更好地实现语义分割,如图2 所示。 生成器的输入是真实人像数据集,经过生成器后得到人像提取解析图。 将标签人像图和人像提取解析图作为判别器的输入,由判别器辨别输入的数据是一个真实数据还是来自生成器生成的虚假数据,如果判别器判定输入的图像为虚假数据,生成器和判别器则会交替训练,两者在竞争中学习优化网络参数,直至达到纳什均衡状态,此时生成器生成的数据接近真实数据的样本分布,判别器也无法区分样本是否来自生成器。

图2 BiSeGAN 网络结构图
实际应用中,对语义分割的速度和精度有着很高的要求。 从已有的实时性语义分割算法来看,实施模型加速方法都是以牺牲一定图像精度的基础上来实现推理速度的增加。 针对上述问题,生成器网络采用BiSeNet 结构,此结构是一个实时、快速的语义分割框架,能够在确保图片质量的情况下保证提取速度,很好地平衡了精度与速度,同时它也是一个轻量级语义分割架构,便于部署到本地手机上。 BiSeNet 网络结构拥有两个部分:空间路径和上下文路径。 空间路径(SP)用来处理空间信息缺失,以保留更多丰富的空间信息,上下文路径(CP)用来针对感受野缩小的问题,以保证有更大的感受野。 同时,为了在保持良好的速度的情况下,拥有更高的精度,本软件提出将空间路径和上下文路径相融合,得到特征融合模块(FFM)和精细化后的注意力优化模块(ARM)。
对于语义分割来讲,空间分辨率和感受野大小这两个关键因素不能兼得。 针对于此,本软件的SP 保留了原始输入图像的空间尺寸并编码丰富的空间信息。 如图3 所示,空间分支主要包含三层,每一层包括一个步长为2 的3*3 卷积、bn 层和relu 激活层。 最终空间路径得到的特征图是原图的1/8,包含了丰富的位置信息。 语义分割性能的好坏是由感受野来决定的。 为了兼顾感受野的大小和实时性两个因素,上下文路径采用轻量级模型和全局平均池化去提供更大的感受野。 轻量级模型可以快速的下采样特征图从而获得更大的感受野,来编码高层语义语境信息(特征的上下文信息),接着,在轻量级模型末端使用全局平均池化提供一个具有全局上下文信息的最大感受野。 最后将全局池化上采样输出的特征图和轻量级模型的输出特征图相融合。

图3 BiSeNet 网络结构
上下文路径(CP)中,使用注意力优化模块来调整我们所采集的特征,使其更加精细。 通过应用全局平均池化(global pool)来捕获全局语境并计算出注意力向量,从而让其指导特征学习。通过这个过程操作,上下文路径中各个阶段采集到的特征可以被进一步优化,使特征图更加精细。 此外整个过程无需任何其他操作,简单快捷。 因此,由其造成的额外计算成本微乎其微,基本可以忽略不计。 注意力优化模块结构图如图4 所示。

图4 注意力优化模块结构图
特征融合模块是用以融合空间和上下文这两种路径输出的特征。 由SP 捕获的空间信息编码了绝大多数的丰富细节信息,所输出的特征是低层级的(8x down)。 而CP 的输出特征主要编码语境信息,所输出的特征是高层级的(32x down)。 由于这两种路径所形成的特征级别并不相同,所以不能将它们直接进行叠加,它首先连接(concatenate)两条路径的特征,然后通过Batch Normalization(bn)层进行批量归一化来平衡特征,接着通过global pool 进行池化从而得到一个特征向量,同时计算出一个权重向量,这个权重向量可以调整特征的权重,起到特征选择和融合的作用。 特征融合模块结构图如图5 所示。
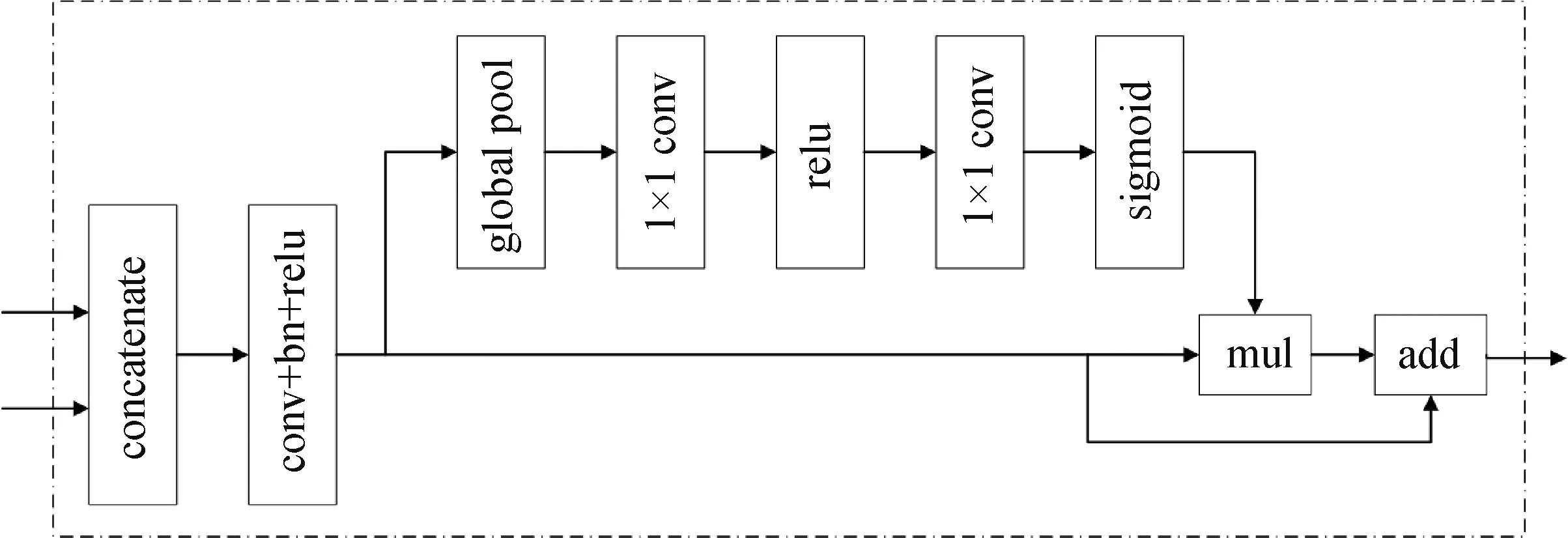
图5 特征融合模块结构图
1.3 损失函数
损失函数包括三个部分:对抗损失函数、Softmax 损失函数以及感知损失函数。 对抗损失函数是生成对抗网络框架下的基本损失函数,控制生成器和判别器对抗训练。 BiSeNet 结构使用Softmax loss 作为损失函数,有助于快速收敛。感知损失函数可以帮助生成器生成更真实的目标图像。
(1)对抗损失函数
网络结构中包含一个生成器和一个判别器,将带人像的图像x输入生成器G,得到人像提取解析图G(x),判别器需要将人像提取解析图G(x)作为负样本,将标签人像图y作为正样本。生成器和判别器交替训练,该损失函数可表示为:
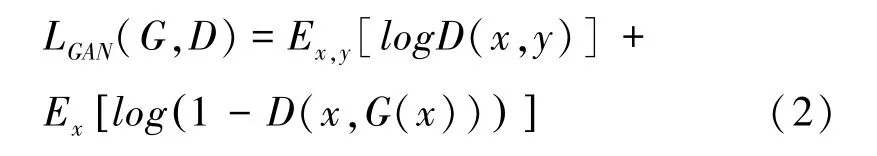
(2)Softmax 损失函数
在BiSeNet 结构Context Path 分支上添加了一个特殊辅助损失函数,如公式(3)所示,用来监督Context Path 的输出,其与网络输出损失函数整合得到全局损失,见公式(4)。 其中,K=3;lp为主损失函数,用来监督整个BiSeNet 网络的输出;li为辅助损失函数,用来监督模型的训练;借助参数来平衡主损失函数与辅助损失函数的权重。 两个loss 同时传播,辅助loss 有助于优化学习过程,主loss 仍是主要的优化方向,两者使用不同的权重共同优化参数,有利于快速收敛。

(3)感知损失函数
使用VGG16 网络对人像提取解析图G(x)和标签人像图y 进行特征提取,经过卷积层得到特征图,分别记为F和P,F和P的Gram 矩阵可以表示人像提取解析图和标签人像图间的纹理差异,所以分别对F 和P 求Gram 矩阵差的Frobenius 范数,最终生成风格纹理较为相近的图像。 感知损失函数表示如下:
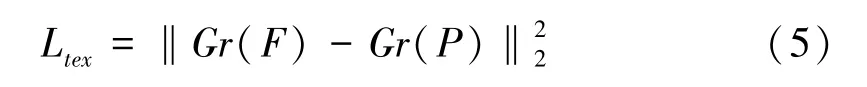
总损失函数表示为:

1.4 模型部署
本软件采用Paddle Lite 框架,将已训练好的深度学习模型部署到手机上,Lite 架构完整实现了相应的能力:多硬件支持,高性能,量化支持,强大的图分析和优化能力,轻量级部署,可支持任意硬件的混合调度。 Lite 框架为包括手机在内的端侧场景的AI 应用提供高效轻量的推理能力,有效解决手机计算力和内存限制等问题,推动AI 应用更广泛的落地。
2 总体框架设计
2.1 系统目标
本软件以在移动设备上实现人像提取、背景替换和美颜滤镜功能为目标,利用基于深度学习的BiSeGAN 网络进行语义分割,实现人像提取和背景替换的功能[8],利用OpenCV 实现磨皮美白算法,利用百度飞浆深度学习平台将训练好的模型部署到移动端。 人像自动提取与处理软件首先从手机本地存储中读取图片,然后经过人像提取模块或美颜滤镜模块处理图片,最后将处理好的图片返回给用户。 由于移动端设备算力相对于PC 端较低,所以对于移动端设备而言,部署深度学习模型时,需要慎重地考虑模型的大小和运行速度这两个因素。 模型的大小将直接影响APP 所占存储的大小和APP 运行时所占内存的多少,模型的运行速度将直接关系到APP用户体验的好坏,模型推理速度快,相应的功能响应也会快,如此用户在与APP 进行交互式才会有比较好的体验。
2.2 系统框架结构
本软件实现了基于深度学习的人像提取、背景替换和美颜滤镜两个功能,系统流程图如图6所示。 本软件在主界面中声明了人像提取和美颜滤镜两个控件,并对这两个控件进行监听。 当后台获取到人像提取控件的ID 时,会从当前的主界面跳转到人像提取界面;当后台获取到美颜滤镜控件的ID 时,会从当前的主界面跳转到美颜滤镜界面。

图6 系统流程图
在人像提取功能中,软件首先从本地存储中读取人像图片和背景图片,然后采用目标检测判断人像图片中是否含有人像,如果没有,需要重新选择人像图片,如果确是人像图,则需加载Bi-SeGAN 深度学习模型,利用此模型对图像数据进行预测,获取到语义分割的结果,实现人像和背景的分离,合并人像和背景图,形成新图,最后判断是否保存新图,如果不保存,需要从本地存储中重新读取图片,如果保存,则完成本次背景替换[9]。
在美颜滤镜功能中,软件首先从本地存储中读取人像图片,然后采用目标检测判断人像图片中是否含有人像,如果没有,需要重新选择人像图片,如果确是人像图,则采用双边滤波和高斯模糊来进行图片像素点的模糊处理,在图像去噪的同时保留图片细节,从而达到磨皮美白效果,并设置进度条控件选择磨皮美白的程度,最后判断是否保存新图,如果不保存,需要从本地存储中重新读取图片,如果保存,则完成本次美颜滤镜。
3 系统设计与实现
3.1 人像提取
本软件在人像抠图界面中设置了三个按钮,分别是选择人物图片、选择背景以及保存图片。当点击选择人物图片的按钮后,会跳转进行访问手机相册,并让用户从中选择想处理的图片,点击选择背景也会跳转访问手机相册进行背景图片的选择,但是,如果在没有选择人物图片的情况下,就直接选择背景按钮时,会弹出一条提示,提示显示“您需先进行人物图片选择”。 同样的,如果没有选择任何图片时,点击保存图片也会提示“图片保存失败”。
本软件实现了人像提取功能。 将原模型部署到手机端后,选择一张包含人像的图片,对图片进行预测。 首先,对输入的数据进行预处理,目标输入的数据是一个浮点数组,实际输入的是一个Bitmap 的图片,所以需要把Bitmap 转换为浮点数组,在转换过程中需要对图像做相应的预处理,如:乘比例,减均值,除方差。 为了避免输入的图像过大,图像预处理变慢,通常在元数据预处理之前,对图像进行压缩。 待到处理完成后,输入预测图像数据,通过本模型对输入的数据进行预测并得到预测结果,最后通过解析获取到语义分割的结果[10]。
本软件实现了背景替换功能,将原模型部署到手机端后,选择一张背景图片,语义分割得到的前景图为人像,将人像与背景图片融合,实现自动换景功能,最后可以选择是否保存图片到相册,背景替换功能流程图如图7 所示。
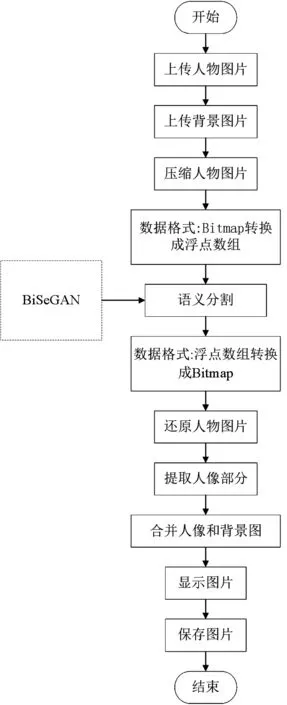
图7 背景替换功能流程图
3.2 美颜滤镜
本软件的美颜滤镜有两个界面,第一个界面就是提示用户从相册进行图片选择,点击图标后,选择完图片就跳转到第二个界面,也就是图片处理界面。 本软件基于OpenCV 实现了一个磨皮美白功能,通过设置SeekBar,拖动进度条控件选择磨皮美白的程度,让用户自行选择满意的美颜效果,效果图可以通过ImageView 显示,最后可以选择是否保存图片到相册。
本软件实现了磨皮美白功能,对于图像来说,本质就是让像素点模糊,提高亮度。 图像去噪的方法很多,如:中值滤波,高斯滤波,维纳滤波等,但使用这些方法进行图像去噪容易使图片的边缘细节被模糊,从而导致图片的一些高频细节的保护效果并不明显。 相比而言,双边滤波是一种非线性的滤波方法,是结合图像的空间邻近度和像素值相似度的一种折衷处理,它同时考虑空域信息和灰度相似性,可以很好对图像边缘细节进行保护,达到保边去噪的目的。 因此,本软件采用双边滤波和高斯模糊来进行图片像素点的模糊处理,在图像去噪的同时保留图片细节,从而达到磨皮美白效果。
OpenCV 处理图片数据的类型是Mat(矩阵),而Andriod Studio 处理图片数据的类型是Bitmap,所以在通过Andriod Studio 将图片交给OpenCV 处理之前,必须先将Bitmap 转化成Mat。 图片数据转换为Mat 后就进行双边滤波处理,而后,进行高斯模糊处理,图片数据经由双边滤波和高斯模糊的处理后,再将图片从Mat 转化为Bitmap,使得Andriod Studio 可以成功将图片进行显示。 美颜滤镜功能流程图如图8 所示。
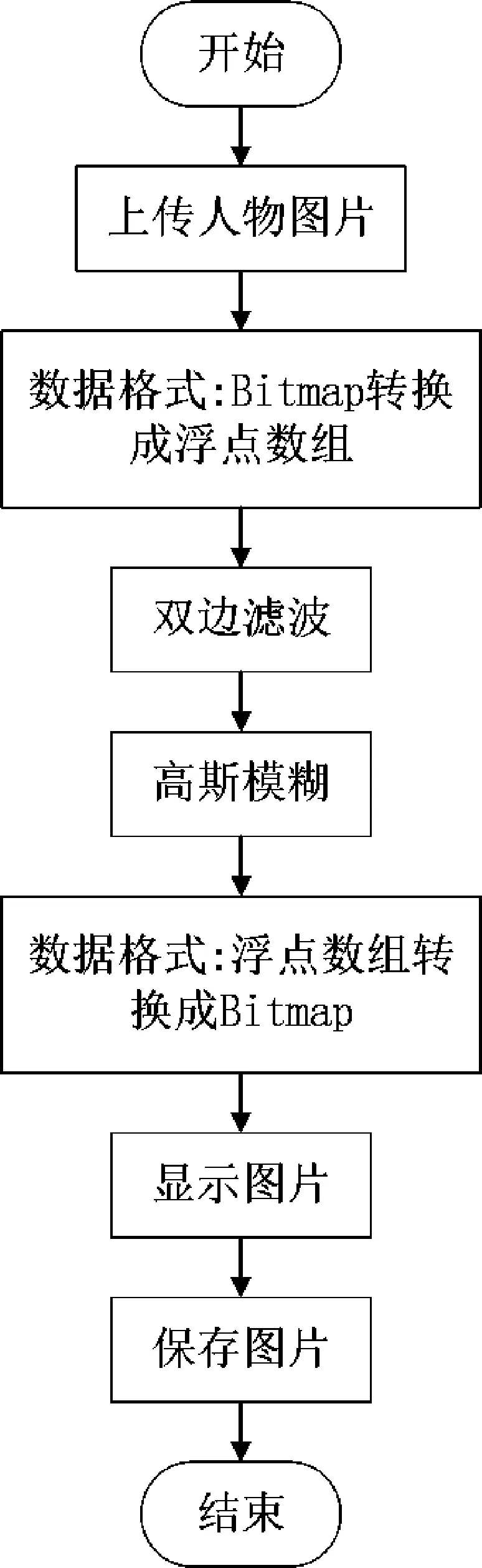
图8 美颜滤镜功能流程图
4 系统运行与测试
4.1 软件设计环境及工具
本软件的移动终端开发环境为Andriod Studio,SDK 选用了API28:Andriod 9.0,手机机型:VKY-AL00。
4.2 人像提取模块测试
用户从手机相册中选取人像图片和背景图片,实现从人像图片中提取人像部分并实现背景替换,形成新的图片效果,可以选择是否保存新的效果图。 本软件与多款应用对比,比较各应用之间的性能优越性,各应用的背景替换效果对比图如图9 所示。 本软件与Andriod AI 抠图软件做背景替换效果对比[11],如:AI 抠图精灵、AI 修图抠图工具、Ai 智能抠图软件;与AI 抠图小程序做背景替换效果对比,如:AI 抠图换背景、AI自动抠图、易飞AI 抠图、抠图AI。
与Andriod 软件比较:如果天天P 图软件提取没有正脸的人物图像,则无法自动识别人像区域,需要手动选择,且图像的边缘手动调整很困难;如图9 所示,当背景色和头发颜色相近时,无法识别头发。 AI 抠图精灵可以较好地将人像与背景分离,但无法从本地自定义选择背景图片,只能选软件中预设的几张背景图,且背景图大小和原图大小不一致;在人像提取时,人像的大小被改变,只能通过“缩放”功能放大人像,但也无法保证与原图中的人像大小一致。 AI 修图抠图工具无法完整地分离人像和背景,原图中的“出口”路标牌应归属于背景,却被智能AI 识别成前景部分。 Ai 智能抠图软件只能提取人像部分,不能实现背景替换;人像提取时并未保留原图大小,只截取了人像的最小矩形外边框;可从图9 中看出鞋子边缘处的噪声大。
与小程序比较:AI 抠图换背景小程序在人像提取时,缩放了人像大小,放大人像框也极难操作,经常会出现翻转等问题;在选择背景图时,多次出现已选择好背景图,但在可视化界面中无法看见的情况。 AI 自动抠图的用户体验感差,响应时间非常长,且无法生成结果图。 易飞AI抠图在提取人像时遇见了同“AI 修图抠图工具”一致的问题,而且,无论选择的背景图是横板还是竖版,都会被压缩成横板图片,如图9 所示。抠图AI 小程序在提取人像时也遇见了同“AI 修图抠图工具”一致的问题,不过,此小程序可以实现背景替换,如图9 所示。

图9 各应用的背景替换效果对比图
针对以上应用提到的问题,本软件最大程度地满足了用户的实际需求,可做到操作简单、使用方便、响应时间短、处理速度快。 人像提取的默认大小为原图的人物大小,用户也可以自行调整。 用户不仅可以选择软件预设的背景图,还可以从本地自定义选择背景图片,且本软件在选择背景图时并不会改变长宽比。 本软件可以很好地分离人像和背景,头发与背景,不需要用户手动分割。
4.3 美颜滤镜模块测试
用户从手机相册中选取图片后,可以拖动进度条控件,用户选择自己满意的美颜效果,测试磨皮美白效果,形成新的美颜效果图。 选择美图秀秀、天天P 图、轻颜相机等APP 与本软件的美颜滤镜效果作对比,各软件的美颜效果对比图如图10 所示,可以看出,本软件的美颜效果与主流软件的美颜效果没有明显的区别。
5 结论
本文提出了一种BiSeGAN 网络结构,在生成对抗网络框架的基础上,采用BiSeNet 结构作为生成器网络,并加入了对抗损失函数、Softmax损失函数和感知损失函数,有助于优化学习过程,快速达到收敛状态,较好地完成了语义分割。本软件在Andriod Studio 的环境下开发并测试了该方案,通过功能测试完成了人像自动提取与处理软件的设计与实现,研发一款能够实现背景替换和美颜滤镜功能Andriod App。 本软件利用百度飞浆深度学习平台将训练好的深度学习模型进行移动端本地部署,通过本模型对图像数据进行预测,通过解析获取到语义分割的结果,通过语义分割分离前景和背景,提取人像,实现自动换景功能。 通过OpenCV 实现了一个简单的磨皮美白算法,采用双边滤波和高斯模糊对图片像素点进行模糊处理,在图像去噪的同时保留图片边缘细节,从而达到磨皮美白的效果。
猜你喜欢
今日农业(2022年14期)2022-09-15 01:45:12
加油站服务指南(2022年6期)2022-07-28 06:07:18
作文成功之路·教育前言(2022年12期)2022-03-06 19:42:13
开放教育研究(2020年2期)2020-03-31 01:54:14
当代陕西(2019年6期)2019-04-17 05:04:16
海峡姐妹(2018年11期)2018-12-19 05:18:32
华人时刊(2018年15期)2018-11-10 03:25:34
摄影之友(影像视觉)(2017年12期)2017-02-08 02:10:04
三月三(2016年8期)2016-09-29 09:24:39
现代语文(2016年21期)2016-05-25 13:13:44
