
基于信息融合描述子的机器人复杂场景位姿估计算法
2022-11-03 11:12齐咏生姚辰武刘利强董朝轶李永亭
农业机械学报 2022年10期
齐咏生 姚辰武 刘利强 董朝轶 李永亭
(1.内蒙古工业大学电力学院, 呼和浩特 010080; 2.内蒙古自治区机电控制重点实验室, 呼和浩特 010051)
0 引言
为实现自主移动和导航,移动机器人需要解决3个关键问题:位姿估计、建图、路径规划[1-3]。其中移动机器人位姿估计是建图与路径规划的重要前提和关键环节。
目前常见的信息提取渠道主要分为激光雷达传感器和相机传感器。而相机传感器相比激光雷达传感器,具有成本低廉、质量轻、功耗低、采集信息丰富等优点,因而相机传感器用于机器人位姿估计已成为一个重要的发展方向。
即时定位与地图构建(Simultaneous localization and mapping,SLAM),主要解决移动机器人在未知环境中定位与地图构建的问题。而SLAM前端作为其重要环节是一个求解运动变换的过程,并为后端提供初始的数据,SLAM前端可以分为特征提取、特征匹配、数据关联[4-6]。迄今为止已经有一些经典的视觉SLAM算法,其算法的前端部分都是采用视觉定位。MonoSLAM[7]是第一个基于单目相机运行的SLAM方案,其前端采取稀疏的特征点进行匹配估计位姿,能够实现实时的无漂移运动恢复结构。但该方案的前端特征点跟踪鲁棒性较差,很容易丢失;PTAM[8]采用了Tracking和Mapping双线程的结构,在Tracking线程中其前端采取FAST提取特征点进行匹配,其优点是提取速度快,但也存在鲁棒性差的缺陷,而且它会提取出大量的FAST特征,需要使用各种约束剔除误匹配,耗时耗力。为了降低前端计算工作量,以直接法为代表的LSD-SLAM[9]在帧与帧之间实现跟踪以构建光度误差,降低特征匹配的计算量,但该算法对纹理缺乏的场景效果较差。ORB-SLAM2[10]在PTAM架构的基础上,增加了地图初始化和闭环监测功能,可实现全局约束优化。但ORB-SALM2前端在复杂场景下(噪声引入、运动模糊、光线明亮变化)特征点的提取抗干扰能力较差,而且其描述子Brief[11]利用的是图像局部信息,缺乏全局性描述,会对提取的特征点造成较多误匹配,影响定位精度。
为进一步提高ORB-SLAM2定位精度,MA等[12]从提高特征点描述子区分度的角度出发提出了ASD-SLAM,针对视点变化和高度重复的场景,使用深度学习的方法提高特征点描述子的区分度。所提出的Adaptive Scale Triplet损失函数应用于Triplet Network获得自适应尺度描述子(ASD),替换传统视觉SLAM框架的前端,提高了特征的匹配精度。然而该算法也存在特征点提取抗干扰能力差,在复杂环境下提取点数变少甚至无法求解位姿的问题。LI等[13]将深度学习目标检测方法融入SLAM前端中,提出一种PO-SLAM方案,该方法是对ORB-SLAM2的改进,对输入的图像从目标检测网络中提取对象的语义信息,使用bundle adjustment构建对目标的映射,可有效提高定位精度。不过,当环境中目标信息减少和缺失时,仍会出现目标检测失效、定位精度下降的问题。
为克服上述问题,提出基于多级深度网络提取图像特征点和输出描述子[14-17]。在面对复杂场景提取特征点时具有很好的抗干扰性,输出的描述子匹配精度也有较大提高。但上述网络对特征点提取和描述子输出分别采用不同网络,网络结构庞大复杂,当面对较大场景、输入图像较大时,网络的计算时间成本陡然增加,降低了SLAM系统的实时性,此外该类方法对移植系统的资源要求很高。
通过前期研究和深入分析,发现目前所研究的ORB-SLAM2的前端定位算法主要缺陷为:特征点的提取是基于人工设定的规则,在复杂场景[18-21]中,特征点提取会失效,或点数变少甚至于无法求解位姿,容易跟踪失败。通过使用深度学习可有效改善这些问题,然而引入深度学习在特征点提取和描述子输出时会带来网络庞大、复杂场景环境下计算成本过高,实时性难以保证的问题。ORB-SLAM2使用Brief描述子利用的是图像的局部信息进行特征点匹配,而图像中纹理信息较为丰富,当特征点距离较远时局部信息描述子可能非常相似,很容易产生误匹配现象,影响定位精度。为此,从不影响V-SLAM实时性同时又保证具有较强抗干扰性角度出发,提出一种概率p-SuperPoint网络实现特征点提取,提高提取特征点的鲁棒性;并在其中引入一种带有反馈特征点p概率控制策略,实现特征点的输出质量控制,提高前端位姿估计的准确性。提出在描述子输出部分引入一种自适应K-means聚类算法融合Brief描述子,提高特征点的匹配精度和鲁棒性。最后,引入一种Ransac的随机抽样方法对估计的位姿进行检验,增强算法的可靠性。
综上,本文提出一种信息融合描述子位姿估计前端算法(SuperPoint Brief and K-means visual cocation,SBK-VL)。该算法综合考虑ORB-SLAM2和深度学习方法2种思路的优缺点,给出一种均衡方案,用更小的计算成本得到最佳的估计精度;将该算法与经典ORB-SLAM2算法、GCNv2-SLAM算法进行比较,以验证算法的有效性。
1 理论基础
1.1 SuperPoint特征点提取框架
SuperPoint网络是基于自监督学习用于训练特征点检测器和描述子,适用于计算机视觉中大多数视点几何问题[14]。它能够有效检测图像中的特征点和输出特征点对应的描述子,其中SuperPoint网络中的特征点提取网络在复杂环境下具有较好的抗干扰能力。SuperPoint特征点提取网络框架如图1所示。
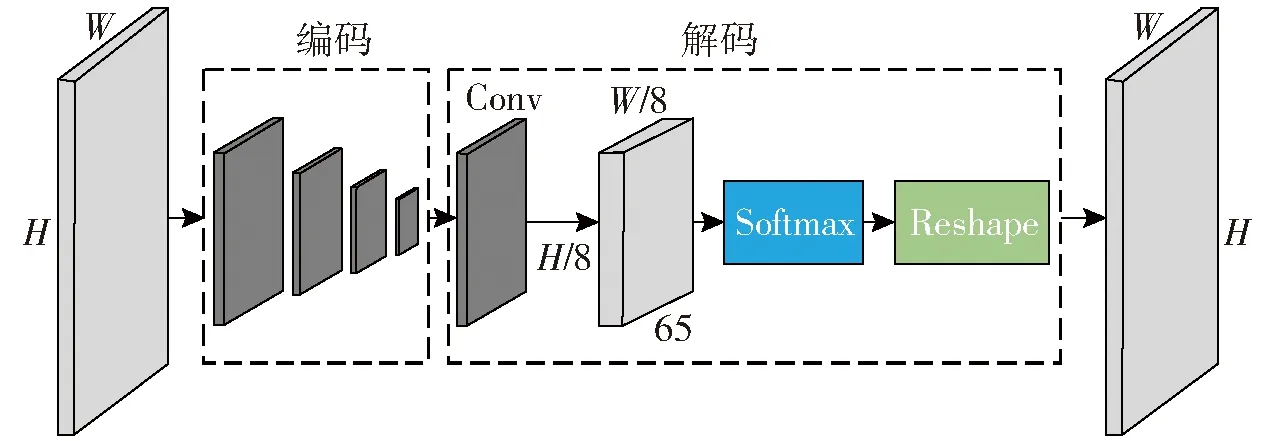
图1 SuperPoint特征点提取网络框架图Fig.1 SuperPoint feature point extraction network
该网络输入尺寸W×H图像,经过类似于VGG-net编码形式的卷积,对图像实施降维,提取特征,图中的解码部分经过Softmax,计算图像的每个像素成为特征点的概率,最后在Reshape中采用子像素卷积的方法将其重组为与原来图像尺寸相同并带有特征点位置的图像。该网络输出图像中的像素带有一个0-1的数值概率表示该像素点成为特征点的概率[14]。该网络结构简单,参数组成较少,网络运算时间短,因此可以将其应用到V-SLAM算法中,来提取复杂环境下的特征点。
1.2 多视图几何技术
多视图几何中已知2D的像素坐标估计相机的运动使用的是对极几何。
如图2中p1和p2是一对在第1帧和第2帧中匹配好的特征点,设第1帧到第2帧的运动为旋转和平移,旋转和平移运动前后的2个相机的中心分别为O1、O2。设P的空间位置为P=(X,Y,Z)。
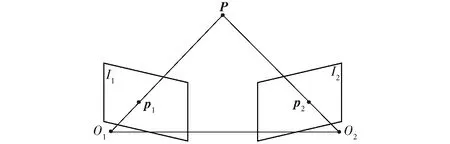
图2 对极几何约束Fig.2 Polar geometric constraints
根据针孔相机原理,2个像素点p1和p2的像素位置为
s1p1=KP
(1)
s2p2=K(RP+t)
(2)
式中K——相机内参矩阵
R——相机旋转矩阵
t——相机平移向量
s1、s2——尺度
上述2个投影关系可以写为
p1≅KP
(3)
p2≅K(RP+t)
(4)
式中≅表示尺度意义下的相等,现取
x1=K-1p1
(5)
x2=K-1p2
(6)
式中x1、x2——2个像素归一化平面的坐标
于是有
x2≅Rx1+t
(7)
(8)
化简后,得到用对极几何计算相机的位姿,计算式化简为
(9)
式(9)的中间部分记作2个矩阵:基础矩阵F和本质矩阵E。
F=K-TEK-1
(10)
E=R
(11)
可以进一步化简对极约束,根据特征点的配对坐标求出E或F,根据E或F求出R、t。
2 SBP-VL算法框架
2.1 算法架构
SBP-VL算法架构如图3所示。由图3可知,算法框架主要包括3部分:基于位姿反馈输出的深度学习特征点提取网络、特征点匹配和位姿估计。
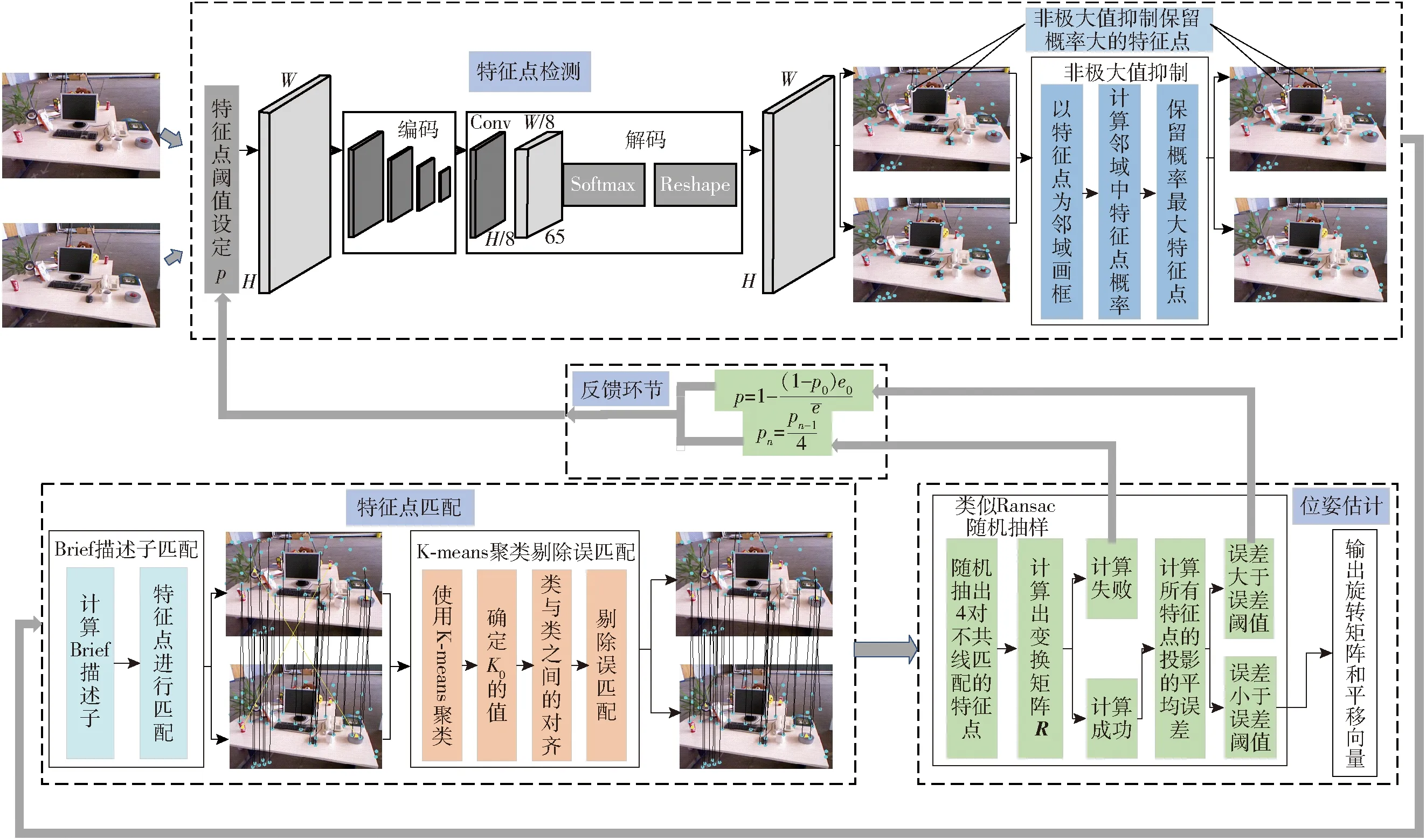
图3 SBK-VL算法框架Fig.3 SBK-VL algorithm framework
(1)基于概率p-SuperPoint网络的特征点提取。如前所述,SuperPoint网络编码器具有类似VGG-net的架构,其网络结构简单、参数少、运算时间短,非常适合应用到V-SLAM算法中实现复杂环境下特征点提取。但在应用中该网络需要提前设定一个固定的阈值来判定图中像素点是否为特征点。实验中发现,固定的阈值对于不同场景(如运动模糊场景)会导致连续丢帧,甚至是位姿估算失败进入重定模式等。为此,引入一种概率阈值p控制方法,即由特征点的概率阈值p自适应控制该网络生成特征点的质量,当位姿估算超出误差范围或位姿估算失败时特征点的概率阈值p会被重置,以适应场景的变化实现准确位姿估计。另外,由于网络输出的特征点可能会有稠密现象,给后续特征点匹配带来一定难度,因此,在本文算法中加入了非极大值抑制环节,将多余特征点去除。
(2)特征点匹配。该部分由Brief描述子匹配和特征点K-means聚类组成。考虑到传统Brief描述子主要反映的是局部特征,会造成误匹配。为此,基于相邻帧结构相似性原理,引入自适应K-means聚类剔除出现的误匹配,同时采用欧氏距离平均法自适应确定聚类类数K0。
(3)位姿估计。引入Ransac随机抽样对估计出的位姿进行准确性检验,设置误差检验范围并加入反馈环节。若估计的位姿结果超出该范围或位姿估计失败,则进行反馈重新设置概率阈值p,重新产生特征点;否则,输出估计准确的旋转矩阵和平移向量。
2.2 特征点检测
SuperPoint网络是一个能够检测特征点和描述子的双网络。但当输入图像变大、场景变大,该网络的计算成本增加、运算量变大。因此,在特征点检测中只使用SuperPoint网络中的特征点检测网络,这样可以减少该网络的计算时间。该特征点检测网络能够对图像中的像素点生成一个概率值的标记,表示该像素点成为特征点的概率,因此将SuperPoint网络输出的图像中像素点概率作为衡量特征点质量的标准。通过设定概率阈值p便可以控制特征点的输出。概率阈值p设置的越高表示网络提取到的特征点质量越高,输出数量越少。特征点输出质量越高表示特征点在不同场景下的不变性与稳定性越强。而前端的位姿估计面临的2个风险分别为由特征点误匹配造成的位姿估计误差太大和由特征提取数目太少而造成的位姿估计失败。而这2个问题可以通过控制特征点的输出来解决。
(1)位姿估计误差太大。该情况大多是由于特征匹配出现误差,而位姿估计时使用了错误的特征匹配数据,对于前端位姿估计误差太大,解决办法为提高特征点的输出质量,减少特征点的输出数量,即提高概率阈值p,一方面阈值p的提高使得特征点数量减少,复杂环境下特征点的描述子相似性很高的点多数会消失,降低匹配难度,且在特征点匹配的过程中进一步减少了时间;另一方面特征点输出质量高、稳定性强,在不同场景下处于前一帧图像的特征点很大概率也会存在后一帧图像中,在特征点匹配的过程中更加容易精确寻找到匹配的特征点,使得点与点匹配后的精度提高。对于前端位姿估计误差太大情况,本文提出概率阈值p的控制策略公式
(12)
式中p0——初始设定阈值

e0——所有特征点映射误差阈值
误差阈值是以真实投影特征点为圆心,半径为e0的圆,该误差阈值与图像的尺寸有一定的比例关系,即
(13)
式中W——输入图像的宽
H——输入图像的高
式(13)表示以真实投影特征点为圆心,半径为e0的圆与输入图像的面积占比为0.002,根据实际输入图像的尺寸可以确定e0。在实际场景中可以根据实际情况对e0进行微调。
图4表示实际投影的2种情况:I1图像中的点u1、u2,经过三维空间中点P1、P2映射到图像I2中点u′1、u′2,图像I2中的虚线方框表示实际投影位置,实线方框为真实投影点,圆圈表示投影误差范围,该图展示了实际投影在误差范围内和超出误差范围的2种情况。
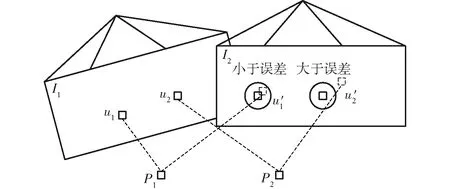
图4 特征点投影示意图Fig.4 Projection of feature points
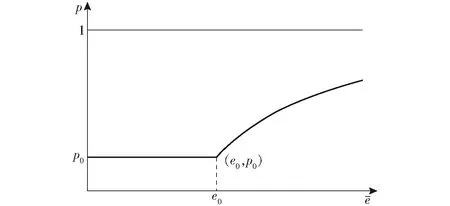
图5 控制策略示意图Fig.5 Schematic of control strategy
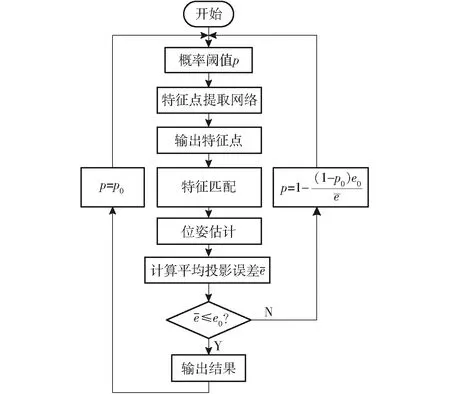
图6 阈值重设流程图Fig.6 Threshold reset flow chart
(2)位姿估计失败。当复杂场景中提取到的特征点数目太少(如运动模糊)而无法满足位姿方程的求解条件,往往会造成位姿估计失败,针对这种情况,解决办法为降低概率阈值p、提高特征点数量、降低质量以满足位姿求解方程。对于位姿估计失败时该概率阈值p的控制策略公式为
(14)
式中pn-1——n-1次设置的概率阈值
pn——n次设置的概率阈值
该控制策略采用比例函数,当n-1次设置的概率阈值pn-1使得提取的特征点数量不足造成位姿求解失败时,为保证降低后概率阈值所提取出的特征点数能够满足式(11)的求解(式(11)的求解需要至少4对匹配的特征点),所以降低后的概率阈值所提取出的特征点数应至少为原来的4倍,于是概率阈值设置降低为原来的1/4,重新提取特征点求解位姿。该控制策略流程如图7所示。
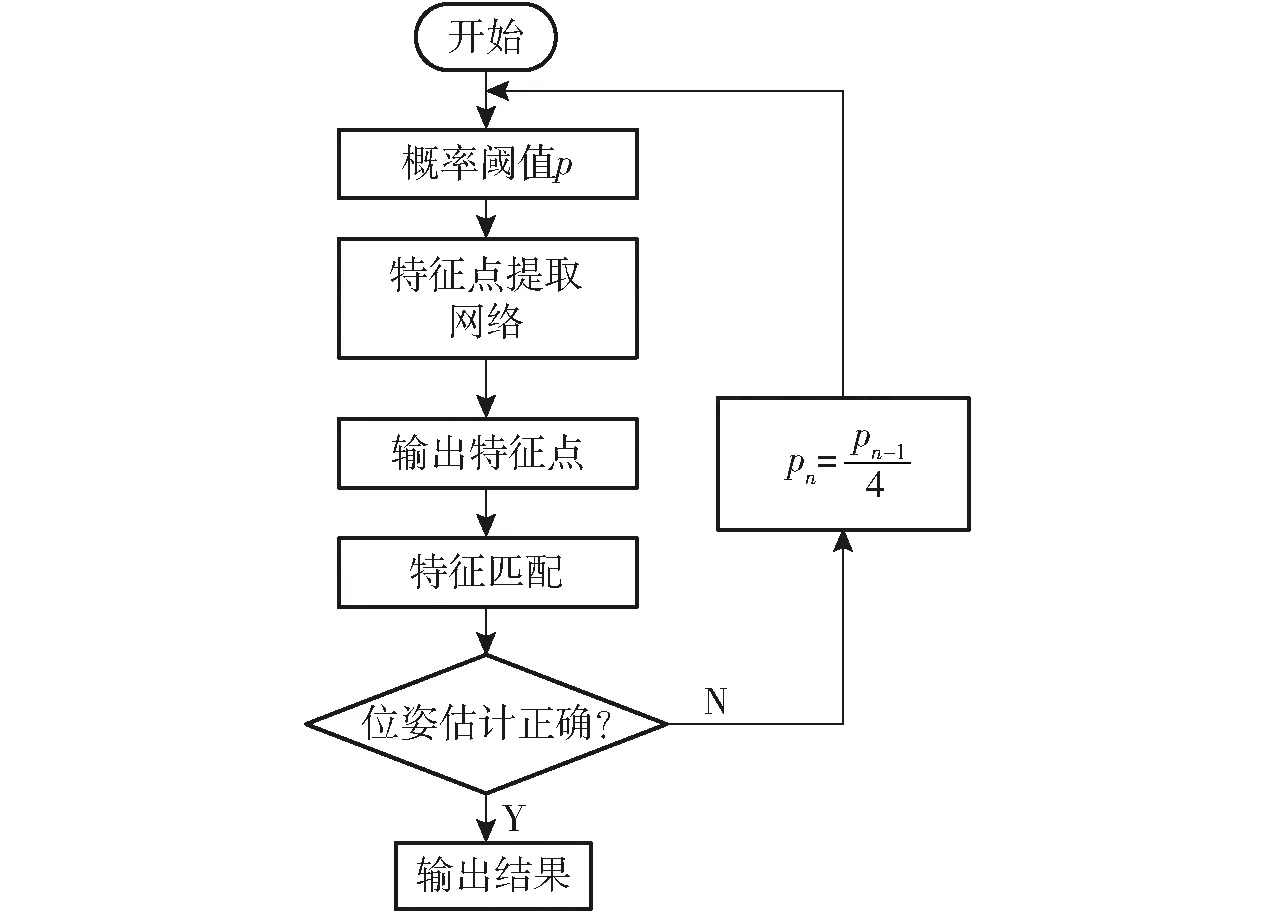
图7 位姿估计失败时阈值重设流程图Fig.7 Threshold reset flow chart when pose estimation failed
2.3 特征点匹配
特征点匹配如图8所示,包括特征点预匹配、匹配特征点的自适应K-means聚类、类与类之间的对齐剔除误匹配3部分。
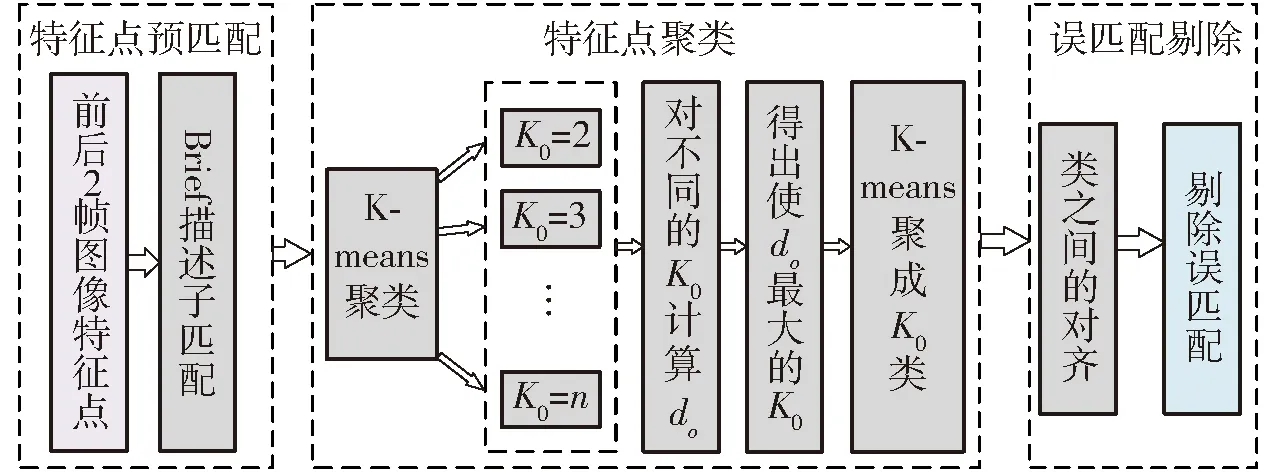
图8 特征点匹配算法流程图Fig.8 Feature point matching algorithm flow
2.3.1特征点预匹配
将前后2帧检测的特征点使用Brief描述子进行预匹配。由于Brief描述子是一种利用图像局部信息产生的描述子,且采用二进制描述,因此会造成特征点误匹配现象。此时即使降低阈值也不能消除误匹配,这是因为图像中的纹理信息丰富,使得特征点的局部信息很容易产生相似性,而阈值的下降会造成点数减小,导致方程求解条件缺失无法求解。因此必须进行进一步误匹配消除。
2.3.2特征点聚类
在特征点进行预匹配的过程中,发现经过预匹配的特征点在结构上具有相似性,因此当对参与预匹配的特征点进行聚类时,前后2帧图像的特征点能够有很好的聚类性能,可充分利用前后2帧类的相似性剔除误匹配。基于此,提出K-means聚类的误匹配剔除思路。使用K-means聚类主要是因为该方法计算简单、直观,不过传统K-means聚类算法需要人为设定聚类系数K0,实际应用中很难满足,为此,提出一种自适应的改进措施。
首先定义距离
(15)
式中i、j——图像中特征点聚类数
(x,y)——聚类的中心点坐标
d0——类间的平均欧氏距离
当该距离越大时,其一帧图像中类与类之间距离越远,在进行类与类的对齐时越易于匹配。
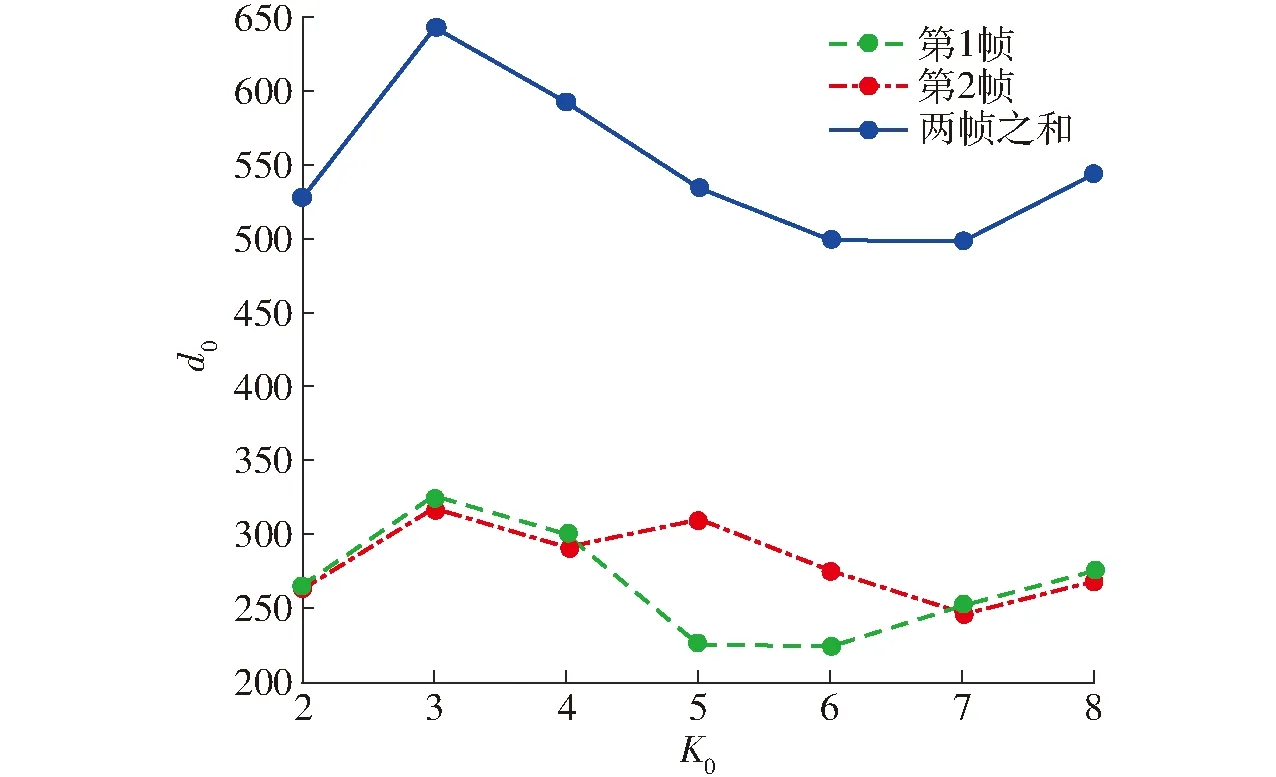
选取不同的K0则会对应不同d0,d0越大,其类与类之间的差距越大则特征点的结构信息越明确,2帧图像类与类之间的匹配范围就越清晰,因此K0的确定就转换为最大化距离d0问题。通过实验发现大部分的K0取3和4时d0能够取得最大,但K0的选取范围不能太大,过大的K0会使得K-means在聚类时花费更多的时间,因此,将K0的合理范围划分在2~9之间,能够满足特征点类的划分和适当的计算成本。由此得到具体算法流程如图9所示。
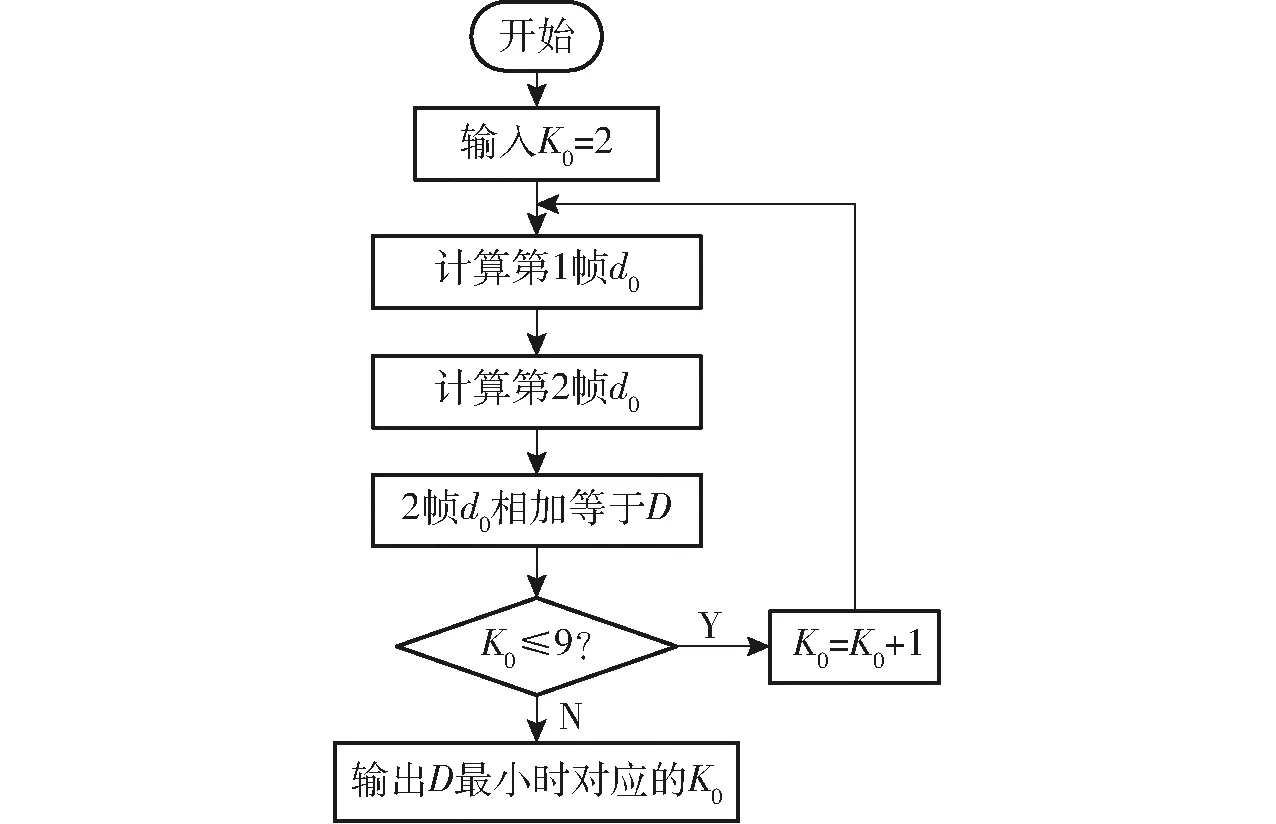
图9 确定K0流程图Fig.9 Flow chart for determining K0 value
2.3.3误匹配剔除
误匹配剔除的关键在于2帧图像中第1帧图像的类与第2帧图像类的对齐,而类的中心点可以表示一类特征点的范围,因此类与类的对齐就转换为中心点匹配问题。首先,对输入的前后2帧图像根据图9流程图所确定的K0分别聚成K0类;其次计算前后2帧K0类的中心点坐标;在类的中心点周围以9×9的方格取81位像素值作为该中心点的描述子,具体示意图如图10所示。
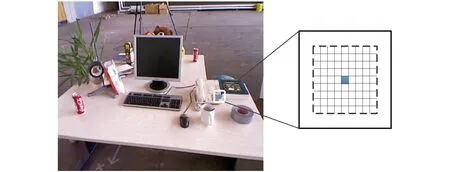
图10 类中心点的描述方式Fig.10 Description of class center point
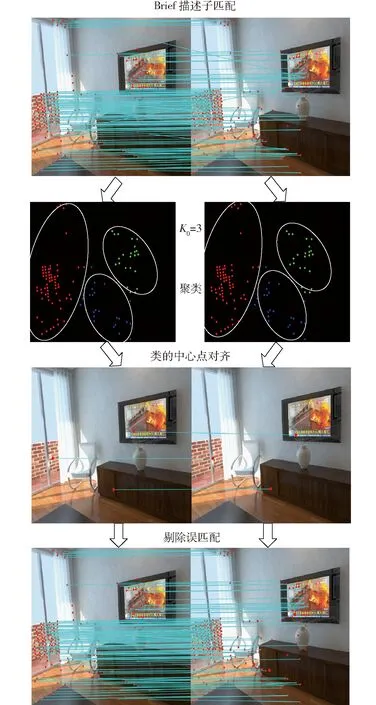
图10中的实心点表示类中心点,网格表示类中心点周围像素值。对每个中心点分别取上述描述方式,并在2帧之间进行匹配,与预匹配结果进行比较,最终剔除误匹配。显然类的中心点的对齐代表的是2类特征点结构的相似性和全局匹配性,可从整体范围内剔除特征点的误匹配,充分利用了全局信息。为了更好地说明误匹配剔除过程,示例如图11所示。
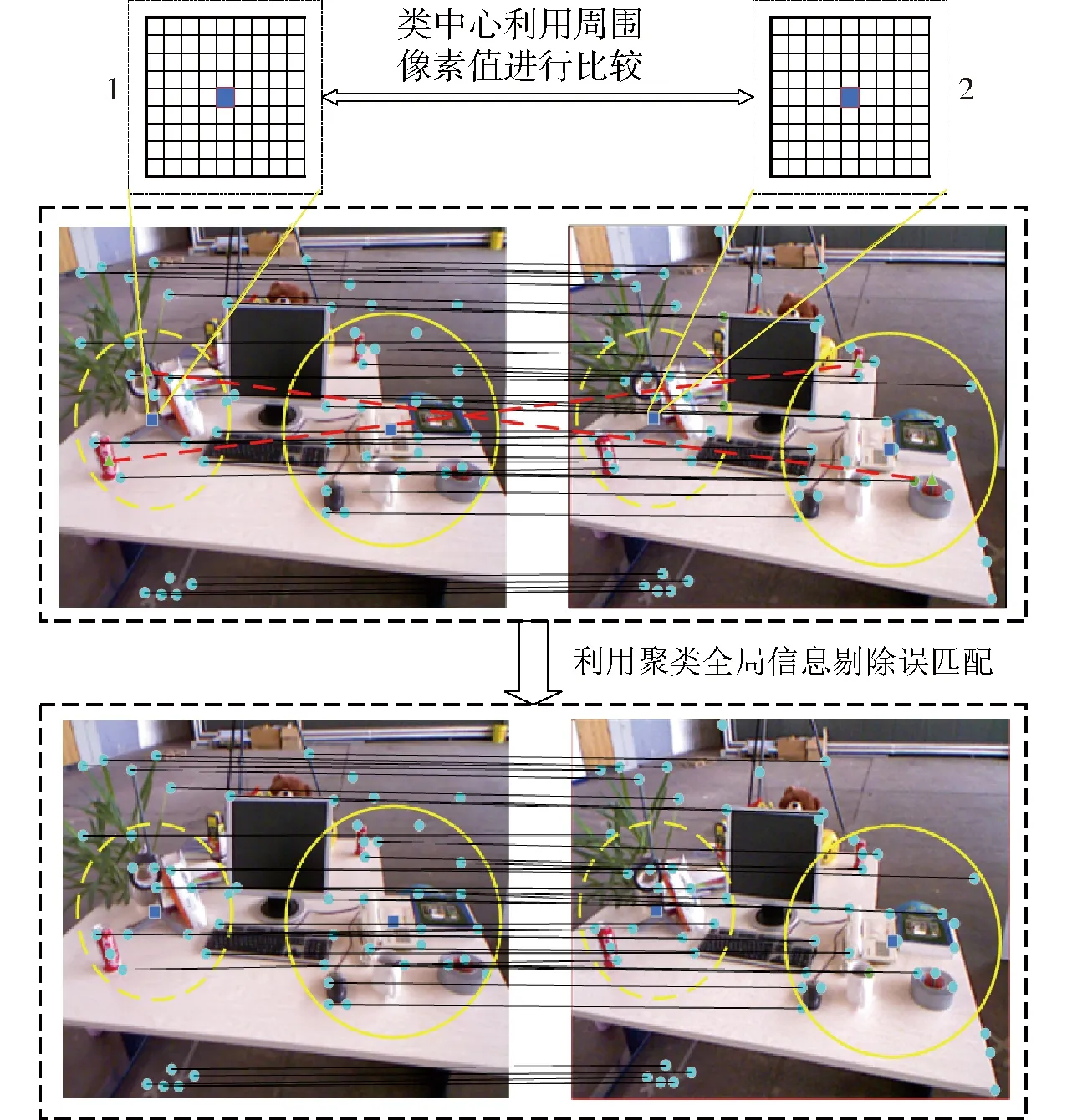
图11 类的匹配示意图Fig.11 Schematic of matching
图11中实心圆点表示Brief描述子匹配后的特征点;三角形的点和虚直线表示使用Brief所产生的误匹配;正方形点表示聚类的中心点,虚线圆圈表示特征点聚类Ⅰ的范围,实线圆圈表示特征点聚类Ⅱ的范围。由图11可以看出,本该在类Ⅰ的特征点被Brief描述子匹配到了类Ⅱ的范围里,发生误匹配,为此采用聚类中心匹配方法,利用前后2帧图像类Ⅰ和类Ⅱ的划分和对齐可以有效地将误匹配结果剔除。
2.4 位姿估计
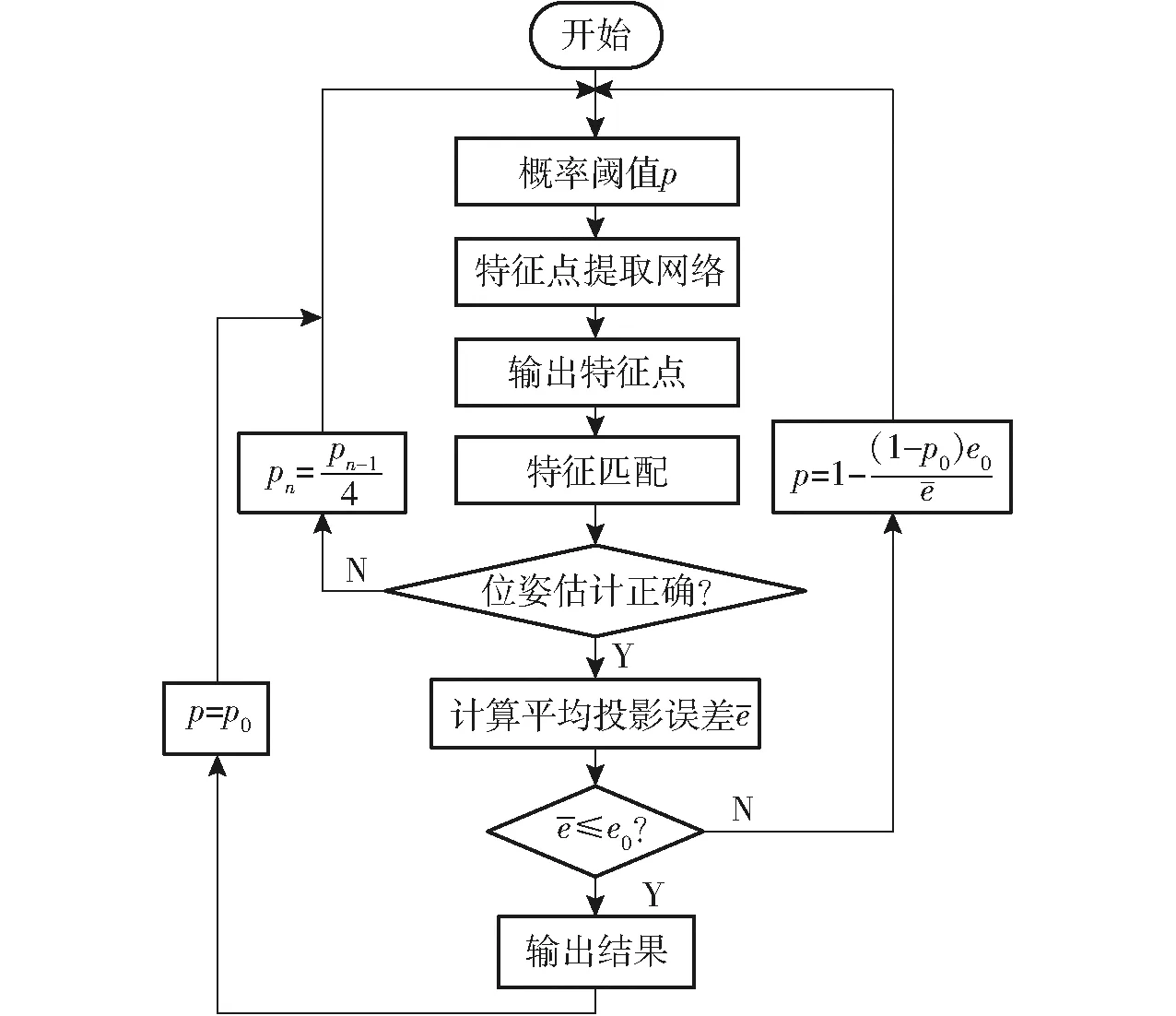
图12 位姿检验流程图Fig.12 Flow chart of pose estimation
3 实验
为了验证本文算法的有效性,分别比较了SuperPoint与FAST特征点的场景适应性、概率阈值p控制策略正确性、提高概率阈值p对特征点匹配准确率的影响、Brief描述子与K-means结合对特征点误匹配剔除的有效性等,最后,将本文方法与经典ORB-SLAM2算法[10]、GCNv2-SLAM算法[16]进行了比较,验证算法的有效性和优越性。
3.1 SuperPoint与Fast特征点的场景适应性
分别在明亮变化场景、运动模糊场景、引入高斯噪声和椒盐噪声场景,通过SuperPoint网络和FAST提取特征点,对比2种特征提取器的效果,实验结果如图13所示。

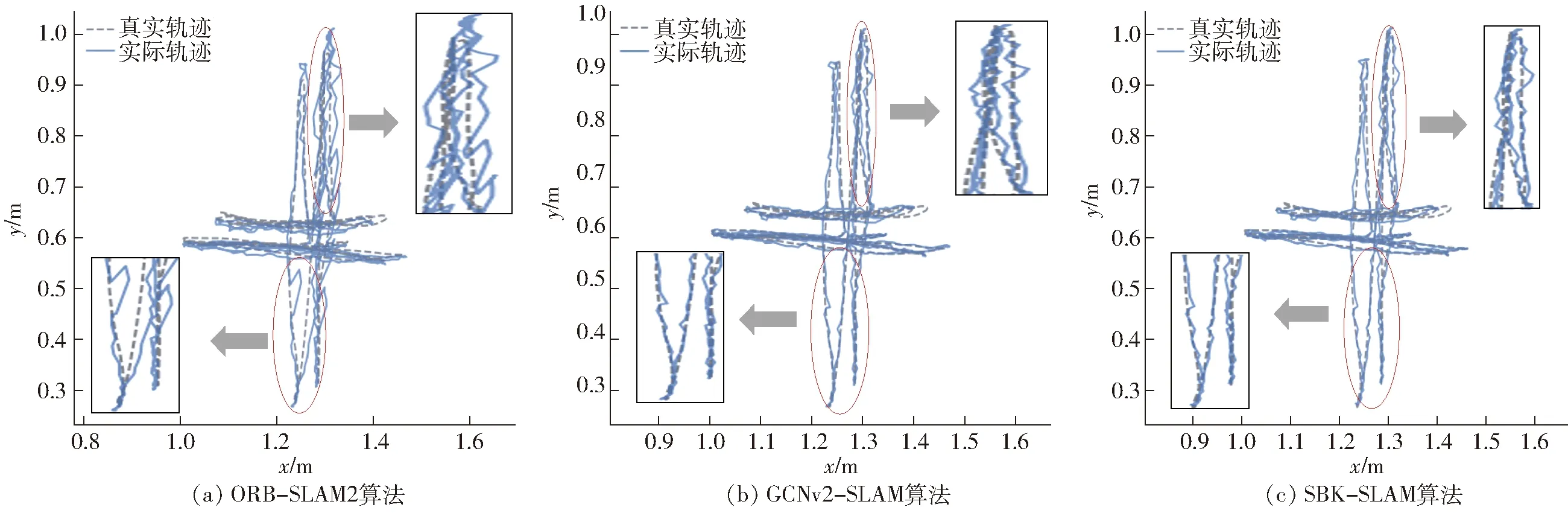
图13 不同场景中两种算法对比结果Fig.13 Comparison results of two algorithms in different scenarios
图像中实心圆点表示提取到的特征点,由上述实验结果可以看出:在亮度减小时(夜间场景)SuperPoint提取结果明显优于FAST,FAST提取点数不足以求解方程;在亮度增加时SuperPoint提取的特征点分布性较FAST好。在运动模糊场景下,SuperPoint提取结果明显优于FAST,FAST提取点数仅有4点。在对图像引入噪声后,发现FAST对噪声很敏感,而SuperPoint对噪声有抗干扰作用。综上,SuperPoint的提取效果明显优于FAST,对场景的适应能力更强。
3.2 概率阈值p的控制策略实验
SuperPoint网络输出图像中的像素带有一个0-1的概率阈值标记,表示该像素点成为特征点的概率[14]。该概率阈值越高表示该特征点响应越高。如果设置一个概率阈值p,使得网络输出的特征点大于概率阈值p的特征点,输出便筛选出了具有高概率的特征点。对前后2帧采用不同的概率阈值p进行特征点的提取,实验结果发现,带有高概率标记的特征点能够同时出现在前后2帧图像中,在帧与帧的变化过程中表现相对稳定,比带有低概率特征点稳定,不容易丢失,即带有高概率标记的特征点在应对环境变化时表现稳定,特征点质量高。图14为前后2帧带有概率标记的特征点图像。
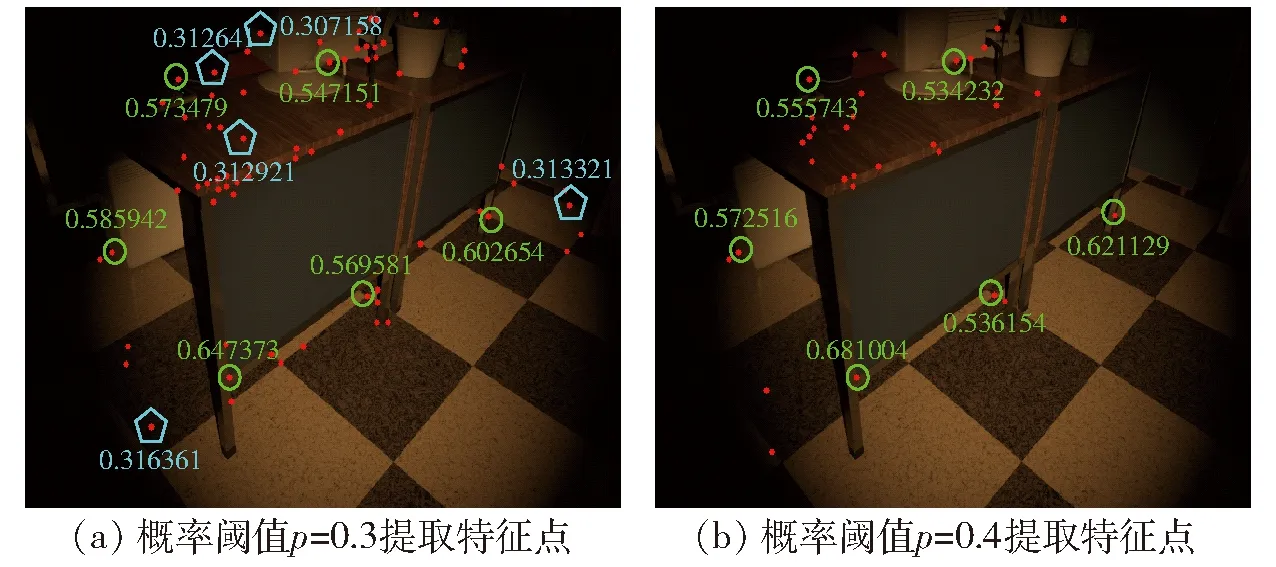
图14 前后2帧带有概率标记的特征点图像Fig.14 Feature point images with probability markers in two frames before and after
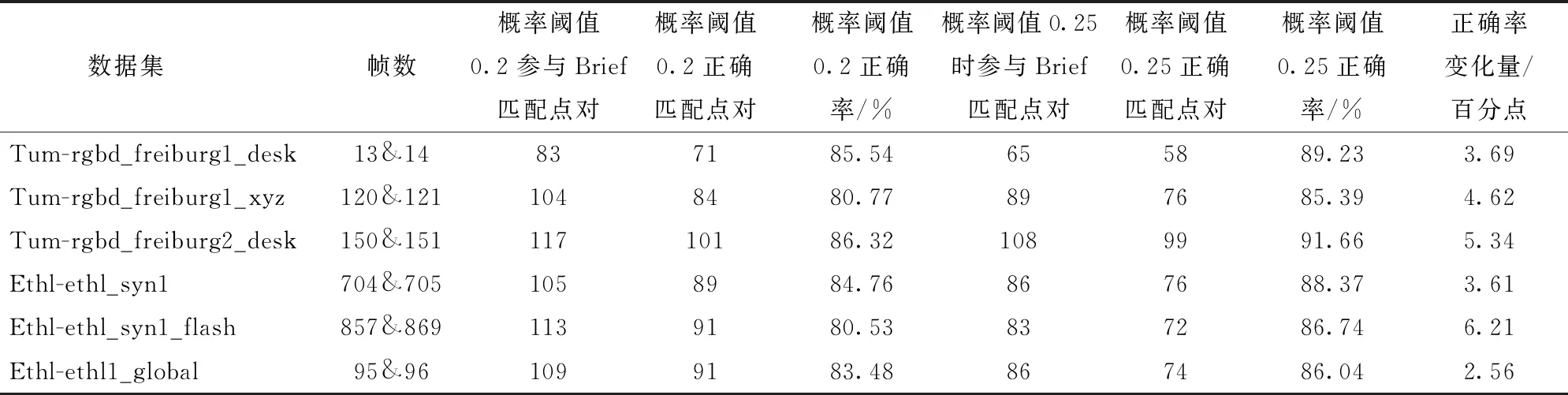
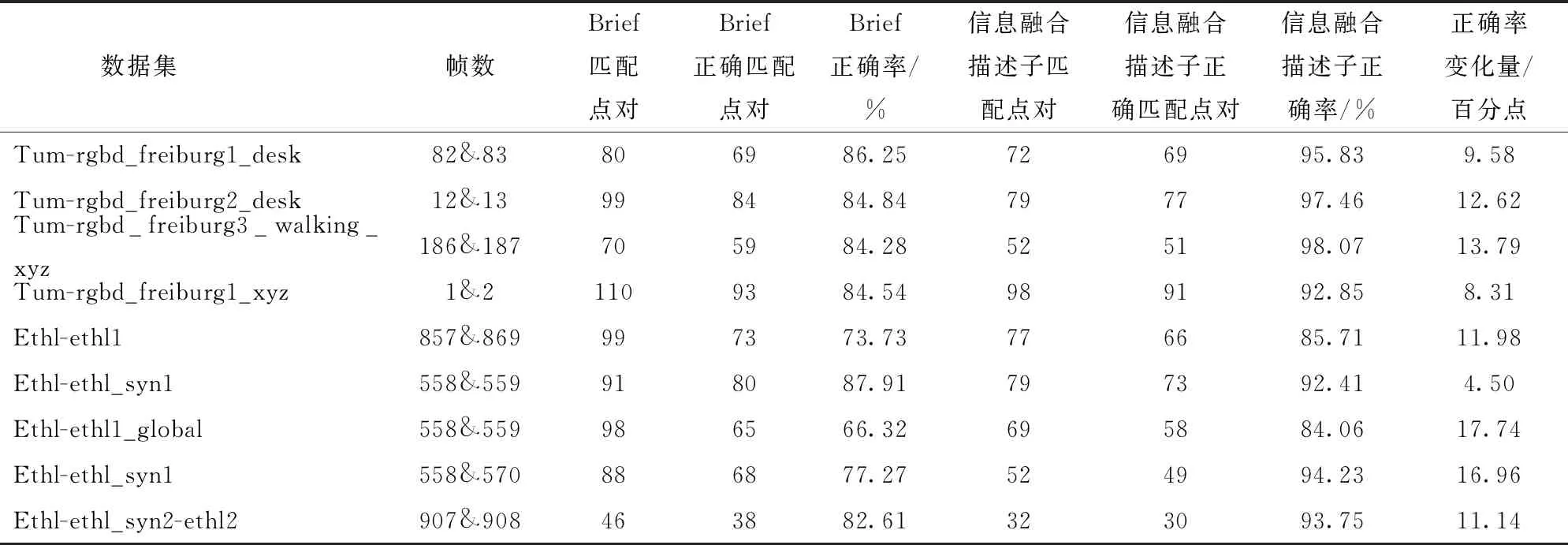
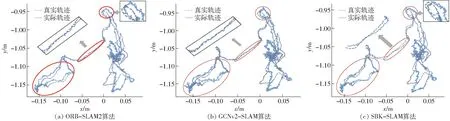
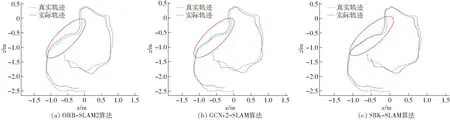
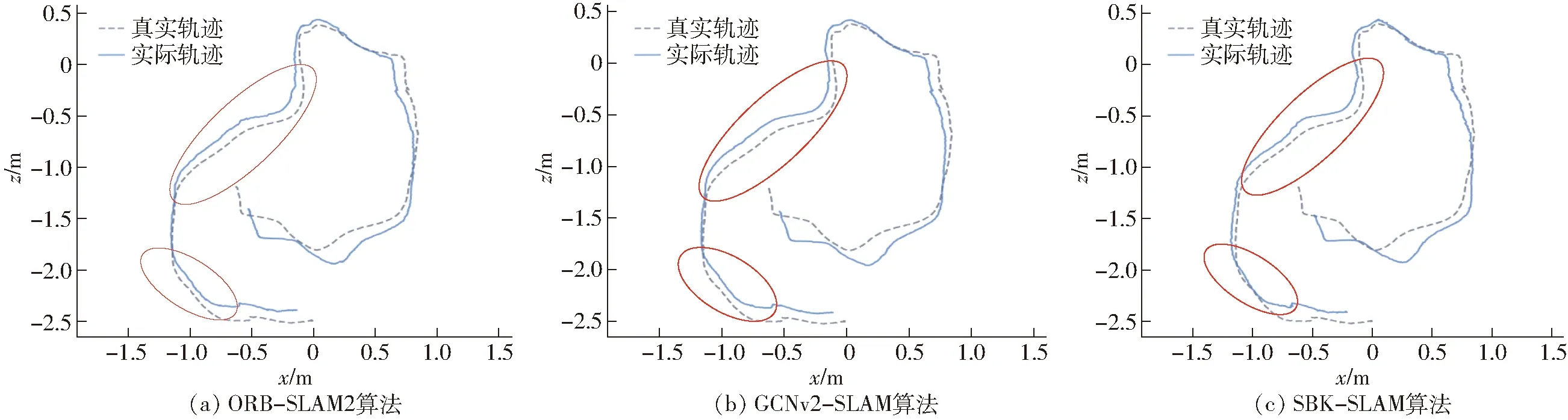
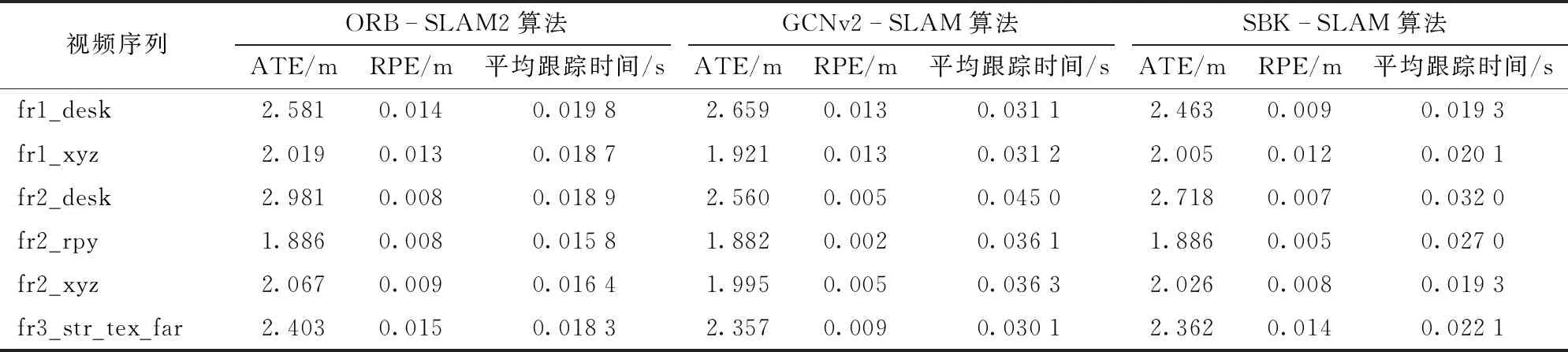
图像第1帧采用概率阈值p=0.3进行特征点的提取,第2帧图像采用概率阈值p=0.4进行提取。其中使用圆圈标记的特征点显示有较高的概率标记值,也都存留在了第2帧中,而带有五边形标记的特征点显示有相对较低的概率标记值,在后一帧中没有保留。从上述结果可以发现,带有高概率标记的特征点在前后2帧中表现稳定。因此,采用SuperPoint网络提取特征点的输出响应值(概率阈值)Pi作为衡量该特征点质量,输出响应值Pi越大表明质量越高,输出响应值Pi越小表明质量越低。设定p为概率阈值,则集合A表示特征点质量相对高的集合,为A={Pi|Pi>p,0 对于位姿估计失败情况,在复杂环境中往往由于运动模糊产生的特征点输出较少,不满足位姿求解方程,针对这种情况,应当降低概率阈值产生更多的特征点,因此根据式(14)将初始阈值重置为原来的1/4,即0.05重新提取特征点进行位姿估计,由图15可以看出概率阈值改变后特征点数明显增加,可进行位姿估计。 图15 模糊场景下特征点提取匹配结果Fig.15 Feature point extraction and matching results when in fuzzy scene 图16 特征点提取匹配映射结果Fig.16 Feature point extraction matching mapping results 图16a为p=0.2时特征点的特征提取匹配情况,根据其特征匹配计算出R,当图I1用R进行映射时并不能恢复图I2。对于图16a由于产生错误的位姿估计导致图像的映射结果错误,在图16b中将p重置为0.37,减少特征点数量提高特征点质量,计算出R能够很好地使其恢复至原图I2。 为了验证提高特征点质量(即提高概率阈值)对特征点匹配准确率的影响,进行如表1所示实验,实验以概率阈值从0.2提升到0.25时特征点的匹配情况为例,并分别针对TUM和ETHl数据集进行测试,具体实验结果见表1,图17为其中1组对比图结果。 图17对应实验5(表1第5行),采用ETHl数据集进行验证结果。从对比图中可清晰地看出,在提高概率阈值后,原本在前一帧中存在的特征点(图中黄色圆圈标记)在下一帧中发生部分消失,此时由表1统计数据可知,消失的特征点中,误匹配点消失的比率更高。如实验5中,删除特征点总数为30个,其中误匹配特征点为11个,占比36.7%,明显高于概率阈值提升之前的19.5%。分析原因可知,误匹配的特征点质量偏低,当适当提升概率阈值后首先被剔除的特征点是这些低质量的特征点,因此本文算法相当于起到一个滤除作用,可以有效提升匹配的正确率。从表1也可以看出,对于给出的6个实验中,均实现了正确率的提升,平均提升率为4.34个百分点。由此,可以进一步表明,提高概率阈值有利于提升特征点的匹配正确率。 首先使用特征点提取器对前后2帧图像进行特征点提取,之后使用Brief描述子进行匹配,在前后2帧中分别求d0,求出使2帧d0之和最大的值所对应的K0,确定聚类类数K0。由图18可以看出,当K0=3时取得最大值。将前后2帧图像分别分成3类,对分成3类的中心点进行对齐,剔除产生的误匹配。 实验结果如图19所示,在Brief预匹配后特征点之间产生了误匹配,对参与匹配的特征点经过K0=3的聚类,因参与匹配的特征点在结构上具有相似性,利用其结构分布相似性对聚类后的特征点类进行中心点对齐,将帧与帧之间的类进行对齐。实验结果最后显示误匹配的特征点被剔除。 表1 概率阈值提高后匹配情况Tab.1 Improved probability threshold matching 为了验证该匹配方法的准确程度,分别在TUM数据集和ETHI数据集中选取了几对图像帧进行了特征匹配实验,实验结果表明信息融合描述子的平均匹配正确率为92.71%,Brief描述子进行匹配的平均正确率为80.86%。使用信息融合描述子对比使用Brief描述子的匹配正确率平均提高11.87个百分点。表2为该方法的匹配结果。 图17 Brief的匹配结果(Eth1-ethl_syn1_flash)Fig.17 Brief matching results 图18 K0值的选定Fig.18 Selection of K0 value 图19 Brief与K-means结合的结果Fig.19 Result of combination of Brief and K-means 表2 特征点匹配精度比较结果Tab.2 Feature point matching accuracy comparison 为验证本文前端算法替换ORB-SLAM2前端能够提高定位精度,分别使用TUM RGB-D和ETHl[22]公共数据集的多个典型视频序列对该算法进行测试,与ORB-SLAM2[10]、GCNv2-SLAM算法[16]在绝对轨迹误差(ATE)、相对轨迹误差(RPE)、平均跟踪时间等指标进行了比较。实验平台的硬件环境CPU为AMD Ryzen 5 3600 CPU 3.60 GHz,GPU为NVIDIA GTX 1650 SUPER 4 GB,运行内存为16 GB。实验结果表明该算法能以每个序列的帧速率实时运行。基于TUM和ETHl的视频序列的实验结果如图20~23所示。 图20 视频序列fr1_xyz不同算法仿真结果Fig.20 Simulation diagrams of different algorithms of video sequence fr1_xyz 图21 视频序列fr2_rpy不同算法仿真结果Fig.21 Simulation diagrams of different algorithms of video sequence fr2_rpy 图22 视频序列Ethl_flash不同算法仿真结果Fig.22 Simulation diagrams of different algorithms of video sequence Ethl_flash 图20~23实验结果展示了3种算法在TUM视频序列fr1_xyz、fr2_rpy和ETHl视频序列Ethl_flash、Ethi_local的测试结果,表3、4显示了ETHl和TUM视频序列在3种算法下的测试结果。 其中在TUM数据集下,在绝对误差和相对误差方面总体上GCNv2-SLAM最小,SBK-SLAM次之,ORB-SLAM2最大;而在ETHl数据集下,总体上SBK-SLAM最小,GCNv2-SLAM与ORB-SLAM2相当。分析可知,当使用TUM数据集时GCNv2-SLAM的深度网络作用精度强使得误差最小,精度总体上均高于SBK-SLAM、ORB-SLAM2。而当使用有干扰的数据集ETHl进行实验时,SBK-SLAM精度总体上均高于GCNv2-SLAM和ORB-SLAM2,分析可知主要在于SBK-SLAM在特征点匹配期间除了计算Brief描述子外加入了K-means聚类算法,从而降低了误匹配使得最后的定位精度提高。 图23 视频序列Ethl_local不同算法仿真结果Fig.23 Simulation diagrams of different algorithms of video sequence Ethl_local 表3 ETHl数据集下SLAM算法比较结果Tab.3 Comparison results of SLAM algorithms under ETHl dataset 表4 TUM数据集下SLAM算法比较结果Tab.4 Comparison results of SLAM algorithms under TUM dataset 但在平均跟踪时间总体上GCNv2-SLAM用时最长、SBK-SLAM次之、ORB-SLAM2最小。主要原因在于GCNv2-SLAM特征点提取阶段和特征点匹配阶段使用了深度网络,SBK-SLAM只在特征点提取阶段使用了深度网络,匹配阶段没有引入深度网络计算。 从总体看,SBK-SLAM在匹配中增加了聚类算法,相比ORB-SLAM2提高了定位精度,在深度学习网络中只提取特征点适应场景复杂性,相比GCNv2-SLAM减少了运算时间。 (1)在特征点提取阶段给出一种概率p-SuperPoint深度学习算法,相比于ORB-SLAM2的FAST特征提取器能更好地适应场景的复杂性,具有更高的鲁棒性。 (2)在特征点匹配阶段提出一种基于Brief描述子与自适应K-means聚类复合算法,实现局部细节和全局描述信息融合,可有效减少特征点的误匹配。 (3)在位姿估计阶段,使用一种Ransac随机抽样对估计位姿进行准确性检验,通过设置误差检验范围并加入反馈环节,提升位姿估计的准确性,增强算法的可靠性。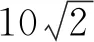


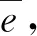
3.3 提高概率阈值对特征点匹配准确率的影响
3.4 描述子与K-means结合对特征点误匹配剔除

3.5 位姿精度性能评价

4 结论
猜你喜欢
光学精密工程(2022年22期)2022-11-28
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
铁道通信信号(2019年6期)2019-10-08
制造技术与机床(2019年9期)2019-09-10
成都信息工程大学学报(2019年5期)2019-05-21
电子技术与软件工程(2019年6期)2019-04-26
西南交通大学学报(2018年6期)2018-12-18
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
