
融合特征金字塔与可变形卷积的高密度群养猪计数方法
2022-11-03 10:42高荣华李奇峰马为红
农业机械学报 2022年10期
王 荣 高荣华 李奇峰 冯 璐 白 强 马为红
(1.北京市农林科学院信息技术研究中心, 北京 100097;2.西北农林科技大学信息工程学院, 陕西杨凌 712100;3.国家农业信息化工程技术研究中心, 北京 100097)
0 引言
随着智慧农业和信息化养殖技术的发展,大规模集成化养殖进程明显加快,视觉与人工智能技术在养殖中的应用逐渐成为新的发展趋势[1]。生猪在不同生长阶段转栏时需要对舍内猪只重新盘点计数,现有人工巡检方式费时费力,还会因为猪只跑动造成计数不准确,利用信息化技术精确检测生猪群体数量能够提升养殖效率。但舍内猪只数量较多,粘连、遮挡等客观因素给群体盘点计数带来较大挑战,因此,迫切需要一种适合高密度养殖模式下的非接触式生猪群体精准盘点计数方法,实现高效智慧养殖[2-3]。
传统非接触式盘点计数方法以传统图像处理方法为主。首先利用光学方法确定目标猪只典型颜色,再结合形态学和区域生长方法统计生猪群体数量[4]。除颜色外,研究者还利用目标猪只纹理特征,实现视觉范围内猪只数量远程统计[5]。然而这些方法均需要人工选择猪只颜色和纹理等特征,在高密度养殖模式下造成特征提取不充分,使得群体计数准确率降低。
随着深度学习与计算机视觉技术发展,卷积神经网络(Convolutional neural network,CNN)表现出较强的特征提取能力[6-7],被很多研究者应用到盘点计数领域[8-16]。高云等[17]通过感知多尺度特征获取预测密度图,并分析密度图积分实现猪只数量估计,改进后的模型平均绝对误差和均方根误差分别为1.74和2.28。TIAN等[18]提出新的CNN学习图像特征到密度图的映射关系,将盘点误差降为1.67。然而密度图积分估计群体数量的方法无法精准识别猪只区域,造成盘点计数误差较高。为准确获取猪只区域,研究者利用目标检测网络YOLO(You only look once)检测目标猪只,再结合深度相机Kinect对其进行分割,实现实时的猪体分割[19]。利用Faster R-CNN(Faster regions with CNN feature)和神经网络结构搜索算法(Neural architecture search,NAS)检测群养猪图像中的猪只位置并识别猪只姿态[20]。然而基于目标检测算法得到的猪只区域,对高密度的粘连猪只的检测误差较大,无法获取猪只边缘信息。为解决此问题,SARWAR等[21]使用全卷积网络(Fully convolution network,FCN)在无人机(UAV)捕获的航空图像中分割牲畜个体,实现了牲畜边缘信息的提取,将整个系统的召回率从90%提高到98%。XU等[22]利用Mask R-CNN(Mask regions with CNN feature)分割无人机拍摄的牛羊图像并进行盘点计数,准确率达92%。同时利用特征金字塔和非极大值抑制等方法优化Mask R-CNN并将其应用于猪只盘点,取得较好的盘点效果,但对高密度养殖模式下生猪群体盘点计数准确率只有86%[23]。上述研究成果证明实例分割算法可获取猪只边缘信息,对稀疏生猪盘点计数的误差较小,但在猪只互相粘连、严重遮挡等高密度养殖模式下,猪只边缘分割精度仍有待提高,影响盘点计数精度。
WANG等[24]提出的SOLO v2(Segmenting objects by locations)可以精准快速地分割高密度下实例物体,成为主流的实例分割网络。因此本文以SOLO v2为基础,融合多尺度特征金字塔网络(Feature pyramid network,FPN)和二代可变形卷积[25](Deformable convolutional networks version 2,DCN v2),提出一种高密度养殖模式下的生猪群体盘点计数模型,解决猪只之间粘连、遮挡等问题,并根据分割结果计算单个猪圈内猪只数量,同时优化模型结构,降低其对计算资源的依赖,为生猪群体盘点计数在线监测提供技术支撑。
1 计数模型构建
1.1 数据来源
本文试验数据采用科大讯飞公开的生猪盘点数据集,如表1所示。数据采集时间为2019年5月1日到6月30日,分别在两个群养的育肥猪舍中安装俯视摄像头,选取早中晚差异较大的图像,每幅图像包括18~31头数量不等的猪只,共700幅,图像分辨率为2 048像素×1 563像素和1 920像素×1 080像素,保存为.jpg格式,24位彩色图像。本文利用200幅图像作为猪只分割数据集,并按照比例8∶2将其划分为训练集和验证集,然后利用剩余500幅图像作为猪只盘点测试集测试模型盘点生猪数量的效果,将猪只分割数据集中50%的图像进行随机翻转,增加数据集的多样性。

表1 生猪盘点数据集Tab.1 Analysis of pig inventory data set
图1为群养猪俯视图像,每幅图像猪只数量在18~31头之间,由于育肥猪较为活跃,群养时容易聚集,因此每幅图像中均存在高密度区域。加之猪场环境脏乱,拍摄的盘点图像受环境和猪群姿态影响较大,这些高密度区域出现较多的模糊、脏乱、严重遮挡、重叠和粘连等情况,因此增加了生猪个体分割的难度,也为盘点计数带来挑战。

图1 自然场景下群养猪俯视图像Fig.1 Top view images of group pigs in natural scene
1.2 生猪群体盘点计数模型
1.2.1模型网络结构
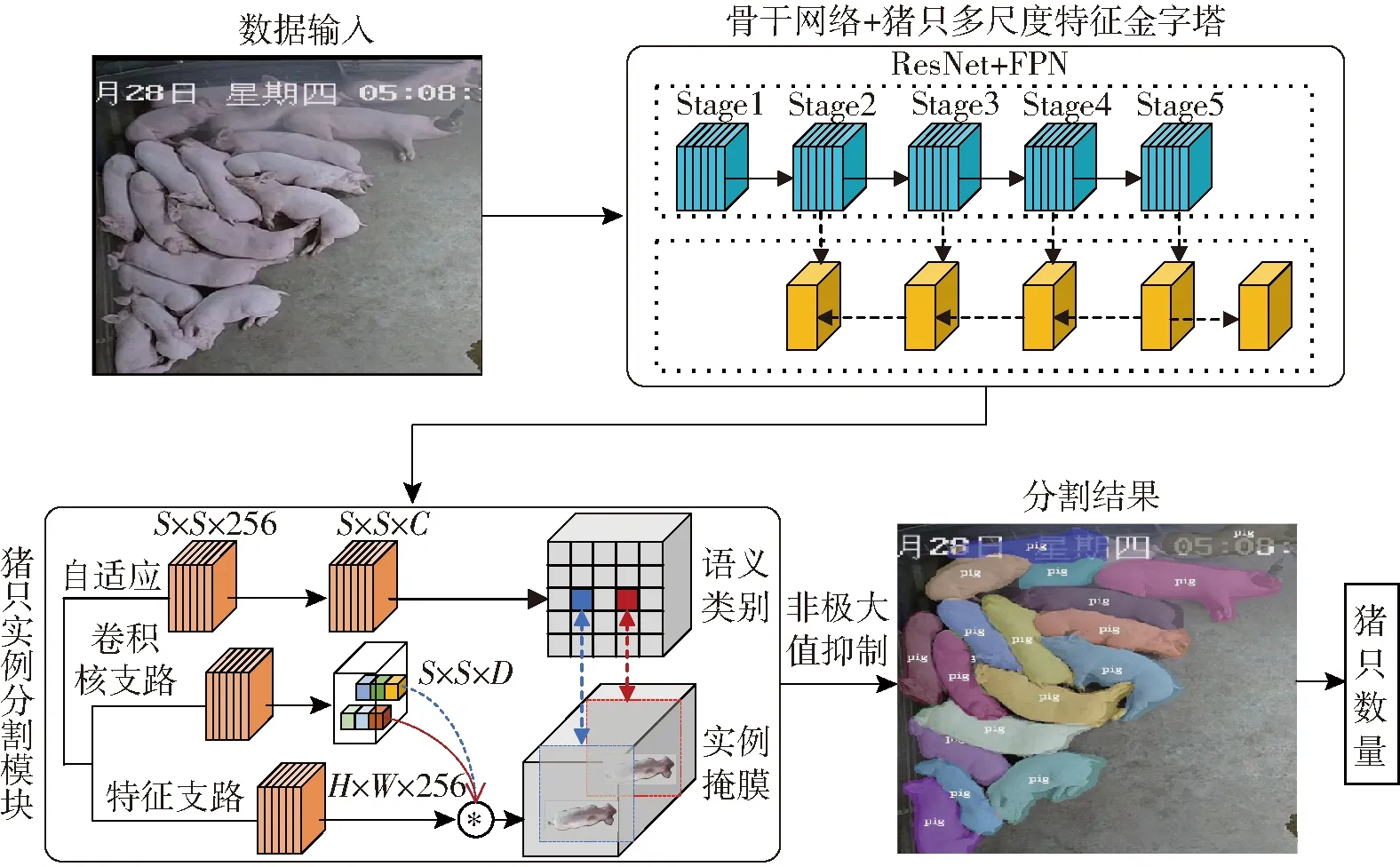
图2 高密度生猪群体盘点计数模型结构Fig.2 Structure of high-density pig population inventory count model
为适应高密度养殖模型下的多姿态猪只盘点计数,以ResNet为基础建立盘点计数骨干网络,利用猪只特征金字塔提取多尺度盘点特征图,再整合特征图分批输入至猪只实例分割模块,根据分割结果实现生猪群体盘点计数,模型结构如图2所示。
盘点数据集被输入到高密度生猪群体盘点计数模型后,被划分为S×S网格,经过骨干网络和猪只特征金字塔得到不同层次特征图,输入到猪只实例分割模块的不同支路进行多任务学习,最终输出不同位置的语义类别和实例掩膜。利用矩阵非极大值抑制算法(Matrix non-maximum suppression,Matrix NMS)去除得分较低的实例掩膜,输出最终的群养猪实例分割结果,实现生猪群体盘点计数。为适用于粘连、密集和遮挡等情况下的群体精准计数,本文选取ResNet18、ResNet34、ResNet50和ResNet101共4种骨干网络寻找适用于生猪群体盘点的最优模型,减少训练中的过拟合现象,骨干网络具体结构见表2。

表2 骨干网络结构Tab.2 Backbone network structure
1.2.2猪只特征金字塔构建
单一视角下获取的大视野生猪盘点数据集,往往存在不同尺度猪只个体,因此,融合ResNet骨干网络和猪只特征金字塔提取不同层级语义信息,解决图像中多尺度猪只分割问题,达到提高模型分割精度的目的,具体结构如图3所示,图中括号内数值
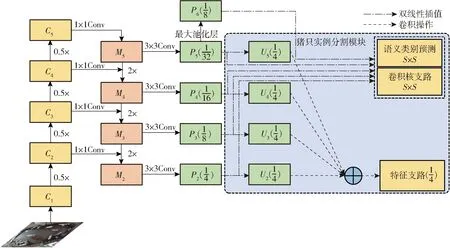
图3 猪只特征金字塔结构图Fig.3 Pyramid structure diagram of pig characteristics
表示特征图尺寸占原图尺寸的比例。
高层特征包含的语义信息较多,低层特征的特征损失较少,因此抽取包含高层语义信息的特征图C5,经过1×1卷积操作得到通道数为256的特征图M5,抽取特征图C2~C4,分别与上一层上采样后的特征图相加,得到256通道的融合特征图M2~M4。M2~M5经过3×3卷积操作之后得到包含语义类别和位置信息的4种不同尺度特征图P2~P5,其中,P5经过最大池化层后得到P6。利用双线性插值将P2~P6缩放至S×S大小(其中S为12、16、24、36、40),作为卷积核支路和语义类别预测支路的输入。利用重复卷积和双线性插值将U2~U5缩放至相同尺度后进行特征融合,输入至特征支路预测猪只掩膜。
1.2.3猪只实例分割模块
猪只实例分割模块包含语义类别预测和实例掩膜预测两个分支,猪只特征金字塔输出的特征图F被输入到实例掩膜预测分支后,利用特征支路和卷积核支路获取最终的群养猪掩膜预测结果M,计算公式为
Mi,j=Gi,j*F
(1)
式中Mi,j——群养猪的掩膜预测结果
Gi,j——中心位置为(i,j)的掩膜内核
实例掩膜预测支路有两个分支,因此需要两个输入F和两个掩膜内核G生成猪只掩膜M。被输入到卷积核支路的特征图F尺寸为S×S×256,经过4个3×3卷积和一个3×3×D的操作后生成最终掩膜内核Gi,j,对于每个网格,卷积核分支预测输出维度为D,当卷积操作为1×1时,D与F的通道数相同,卷积操作为3×3时,D为F通道数的9倍。
特征支路利用重复的3×3卷积操作、组归一化[26]、ReLU和上采样等操作,将猪只特征金字塔输出的特征图P2~P5进行特征融合,融合之后的特征图再次经过1×1卷积操作、组归一化以及ReLU激活函数得到最终的掩膜特征图。
1.2.4卷积结构优化
传统卷积使用固定大小的卷积核作为滑动窗口对特征图F进行采样,然后点乘ω求和,卷积公式为
(2)
式中y(P0)——输出的卷积结果
Rk——感受野的大小和扩张,取值为{(-1,-1),(-1,0),…,(0,1),(1,1)}
Pn——以P0为中心卷积核范围内的所有采样点
ω(Pn)——卷积核的权重矩阵
F(P0+Pn)——以P0为中心卷积核范围内的图像特征
卷积操作中固定的感受野对多尺度目标的鲁棒性较差,易造成较大的特征损失。为进一步提高模型对多尺度猪只的鲁棒性,本文引入第2代的可变形卷积(Deformable convolutional,DCN v2)。在传统卷积感知输入特征时加入调整偏移量,调整来自不同空间位置和单元的特征调制振幅。当调制振幅为0时,该位置的特征信号不被接收,实现模型对空间位置特征的自主学习和选择。y(P0)计算公式为
(3)
式中 ΔPn、Δmn——调整偏移量
仅加入调整偏移量ΔPn后得到可变形卷积DCN[27],加入Δmn后得到DCN v2,提高了模型对群养猪图像的特征提取能力和对多尺度猪只的鲁棒性。
1.2.5模型结构优化
为减少模型对计算资源的消耗,对模型冗余通道剪枝,实现较轻量猪只实例分割模块。将模块支路中的4个卷积块减少为3个,生成的掩膜图通道维数由512降为256,同时将尺度范围修改为[(1,64),(32,128),(64,256),(128,512),(256,2 048)],降低冗余的模型参数量。输入较大尺寸的图像虽然能提高模型准确率,但仍会降低模型推理速度,增加模型对计算资源的消耗,因此,在保证模型准确率基础上,本文降低多尺度训练和测试时输入图像分辨率,将多尺度训练时图像分辨率设为[(852像素,512像素),(852像素,480像素),(852像素,448像素),(852像素,416像素),(852像素,384像素),(852像素,352像素)],测试时由(1 333像素,800像素)降为(852像素,512像素),实现对生猪群体盘点计数模型结构优化。
1.2.6损失函数和评价指标
生猪群体盘点计数模型的损失函数由Focal语义类别预测损失函数Lcate和Dice掩膜预测损失函数Lmask组成,利用猪只个体分类误差和猪只掩膜预测误差,共同判定模型收敛程度。
采用平均精度(Average precision,AP)评价模型性能,使用交并比(Intersection over union,IoU)在0.50~0.95的联合阈值上取平均值,并利用IoU取0.50或0.75时的AP来判断模型精度,评价指标值越高,证明模型分割猪只精度越高。
2 实验结果与分析
2.1 实验设置
实验采用1块GeForce GTX 2080Ti 型GPU进行训练,显存为11 GB,基于Windows 10操作系统和Pytorch框架搭建深度学习算法网络训练平台,其中Python版本为3.7.1,Pytorch版本为1.10.0,Keras版本为2.2.4,CUDA API版本为10.2,cuDNN版本为8.0.5。
2.2 基础模型选择
ResNet骨干网络包含多种不同层数的特征提取网络,使用相同的生猪盘点数据集和多尺度训练方法训练具有不同骨干网络的SOLO v2模型,获得适用于生猪群体盘点计数的ResNet骨干网络,实验结果如表3所示。
由表3可知,基于ResNet50和ResNet101的SOLO v2模型效果最好。在IoU为0.50~0.95、0.75时基于ResNet101的SOLO v2的AP最高,IoU为0.50时SOLO v2+ResNet101比SOLO v2+ResNet50的AP低1.1个百分点,且内存占用量比其高145 MB。为确保模型轻量化和精确性,本文选择ResNet50作为骨干网络改进SOLO v2,使其适用于生猪盘点在线计数。
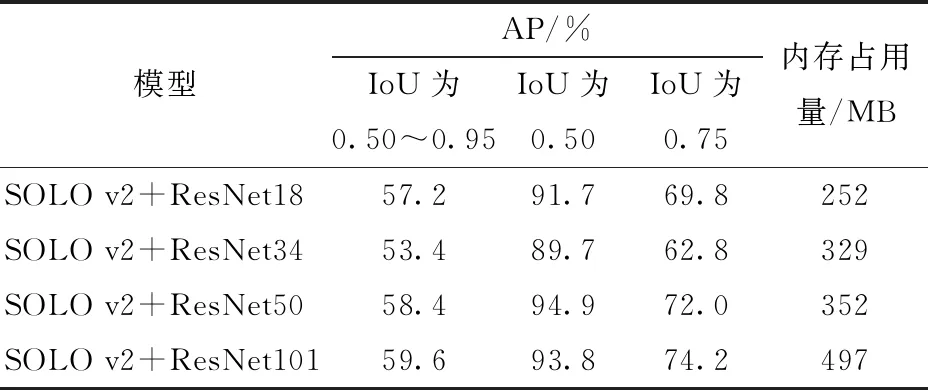
表3 不同骨干网络的SOLO v2模型猪只分割结果Tab.3 Pig segmentation results of SOLO v2 model with different backbone networks
2.3 模型训练结果
模型训练过程中采用梯度下降法(Stochastic gradient descent,SGD)优化模型权重,设置初始学习率为0.01,动态衰减因子为0.9,正则化权值衰减系数为0.000 1,在150轮和250轮时降低学习率,总训练轮数为400轮,训练时每次输入GPU的图像数量为10。利用多尺度分辨率图像训练本文模型,训练结果如图4所示。

图4 高密度生猪群体盘点计数模型的训练结果Fig.4 Training results of high-density pig population inventory counting model
由图4可知,随着训练轮数的增加,3个损失函数总体呈下降趋势,趋于稳定后,在固定区间内波动。其中掩膜预测损失函数在0.06~0.08区间波动,语义类别预测损失函数在0.01~0.02区间波动,总体损失函数在0.2~0.25区间震荡,掩膜损失函数收敛区间略高于语义类别预测损失函数收敛区间,其原因是掩膜损失函数计算依赖于猪只分割区域像素值矩阵,计算得到的损失函数值偏高。因此总体收敛趋势表明本文模型分割猪只效果较好。
2.4 不同模型之间测试结果对比
为验证本文模型对高密度生猪群体的分割精度,设计了多组消融对比实验。使用相同骨干网络、训练方式、训练集和测试集,对比SOLO v2、模型结构优化后的SOLO v2、引入DCN的结构优化SOLO v2及本文模型的猪只分割效果,SOLO v2优化模型的测试结果对比如表4所示。
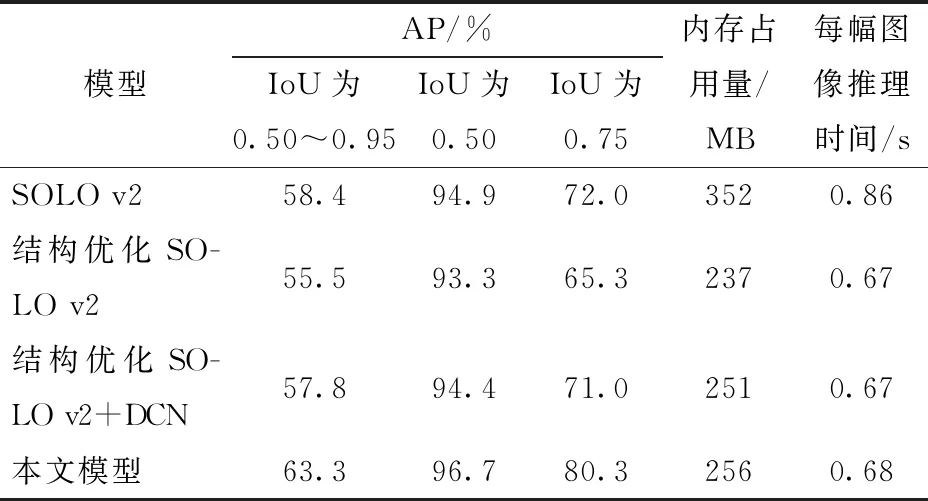
表4 不同模型的测试结果对比Tab.4 Comparison of test results between different models
以ResNet50为基础骨干网络的SOLO v2模型在IoU为0.50时分割的准确率达到了94.9%,保存的内存占用量为352 MB,对SOLO v2结构进行优化,模型内存占用量为237 MB,减少115 MB,证明模型结构优化方法的有效性。但结构优化后的模型在IoU为0.50时准确率下降1.6个百分点,IoU为0.50~0.95和IoU为0.75时的AP也出现一定程度下降,因此,分别引入DCN和DCN v2,提升模型准确率。在结构优化后的SOLO v2模型中引入DCN,AP(IoU为0.50)提高1.1个百分点,IoU为0.50~0.95和0.75时AP分别提高了2.3、5.7个百分点。而本文模型进行结构优化并引入DCN v2后,相较于仅优化模型结构的SOLO v2的AP(IoU为0.50)提高3.4个百分点,IoU为0.50~0.95和IoU为0.75时的AP分别提高7.8、15个百分点,因此,本文模型提高了生猪群体分割准确率,且模型内存占用量为256 MB,较SOLO v2模型降低1/3,适用于真实养殖场内生猪群体的在线盘点计数。
表4证明了本文模型对生猪群体分割准确率最高,鲁棒性最好。因此,对不同模型分割生猪群体结果进行可视化分析,如图5所示,图像中重叠、粘连的区域使用红色虚线框标出。由图5可知,SOLO v2模型对稀疏猪群分割效果较好,红色虚线标记的猪只粘连、堆叠区域,SOLO v2优化模型存在将粘连猪只视为同一头猪或将一头猪只分割为多头的错分现象。而本文模型对严重重叠、粘连区域的分割错误较少。因此,图5进一步验证了本文模型对重叠、粘连生猪群体有较好的分割效果,同时,本文模型推理每幅图像时间仅为0.68 s,能够实现生猪群体实时盘点。

图5 不同模型分割生猪个体的可视化结果Fig.5 Visual analysis of results of segmentation of individual pigs by different models
2.5 不同模型生猪盘点效果对比分析
为进一步验证本文模型泛化性,采用500幅带有高密度区域的猪群盘点测试数据集,如图6所示,500幅测试图像中每幅图像的猪只数量在18~29头不等。利用SOLO v2及不同优化模型盘点图像生猪数量,分析不同模型群体盘点计数结果,如表5所示。
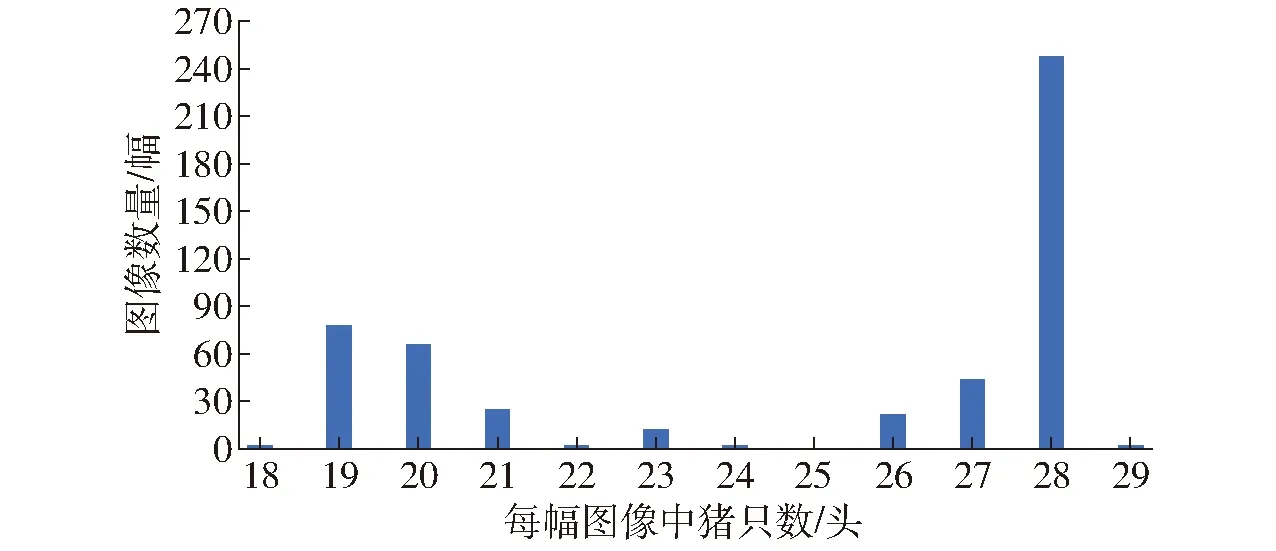
图6 500幅盘点测试图像中的猪只数量分布Fig.6 Distribution of pig numbers in 500 inventory test images
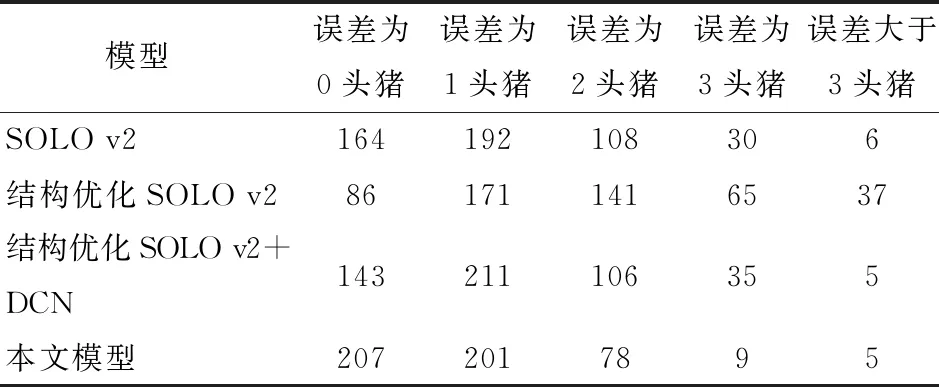
表5 不同模型群体盘点计数结果对比Tab.5 Comparison of population count results of different models 幅
实验过程中,设置得分阈值为0.5,由表5可知,本文模型盘点误差为0头猪的图像数量为207幅,远高于其他模型,相较于改进前的SOLO v2,盘点误差为0头猪的图像数量增加了26%。其中,盘点计数误差为0或1头猪的图像数量占总体测试图像的81.6%,而SOLO v2仅占71.2%;误差为2头猪以内的图像数量占整体测试图像的97.2%,误差大于3头猪的图像仅5幅,占整体测试图像的1%,相较于表5中的SOLO v2优化模型,本文模型实现了高密度养殖模式下的高精度盘点计数。
2.6 分析与讨论
目前基于深度学习的猪只计数研究中常使用目标检测算法检测图像中的猪只个体,然后根据检测结果计算猪只数量。这种方法对于稀疏离散分布的猪只图像中检测效果较好,当图像中存在高密度区域时,猪只粘连、遮挡、重叠等问题使得目标检测模型准确率降低,而基于实例分割算法的猪只计数可减少高密度猪群的干扰。因此,本文复现了目前性能较好的YOLO v5模型对群养猪进行计数的准确率,并和本文基于实例分割模型的猪只计数算法进行对比,结果如表6所示。
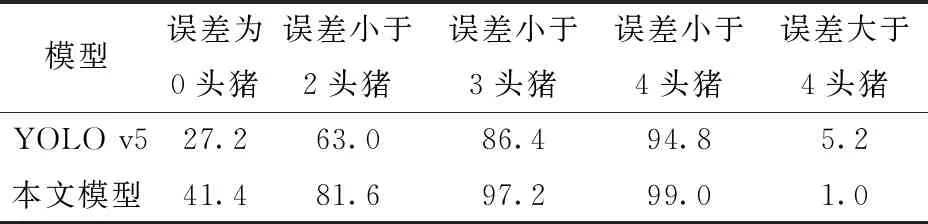
表6 不同方法对猪群计数准确率对比结果Tab.6 Comparison results of pig herd counting by different methods %
对YOLO v5模型进行200轮训练后,IoU为0.50时,模型目标检测的准确率达到了99.2%,在猪只盘点测试集测试猪只计数效果,不同方法对猪群计数的对比结果如表6所示。本文模型计数正确的猪群图像数量约为YOLO v5的两倍,且本文模型计数误差小于3头猪时准确率为97.2%,比YOLO v5模型提高10.8个百分点;而YOLO v5模型计数误差大于3头猪的图像数量是本文模型的5倍。综上所述,YOLO v5作为目前性能最优的目标检测模型,经训练之后,虽然检测准确率较高,但其应用在猪只计数时准确率远低于本文模型,验证了本文选择实例分割算法用于猪只计数优于基于目标检测的猪只计数方法。
为进一步验证基于实例分割的猪只计数效果优于基于目标检测算法的猪只计数方法,对猪只计数测试集的分割结果和检测结果进行可视化分析,如图7所示。对于稀疏分散的群养猪图像,图像分割和检测均可以较为准确地找到猪只位置,但当猪体形状不是规则的矩形时,目标检测方法会出现误检的情况,而本文模型没有出现,如图7a所示。夜间群养猪图像为红外图像,对本文模型的影响较小,而YOLO v5会将背景检测为猪只个体,导致计数不准确,如图7b所示。对于群养猪图像的高密度区域,猪只粘连、重叠现象较多,本文模型误分割的现象相对较少,而由于猪体不是规则的矩形形状,且互相粘连,YOLO v5的检测框中常常包含多头猪,不同猪只之间相互影响,造成YOLO v5对高密度区域内的猪群计数准确率较低。综上,育肥猪较为活跃,喜好群居,在猪只计数测试集中出现了大量的高密度区域,而本文模型的准确率远高于YOLO v5模型,可视化效果也优于目标检测结果,因此,本文提出的基于实例分割模型的猪只计数方法更适用于高密度下的群养猪盘点计数。

图7 不同方法检测猪只可视化效果Fig.7 Visualization of pig detection by different methods
3 结束语
本文模型利用猪只特征金字塔和DCN v2提高对多尺度目标的特征提取能力和分割能力,同时优化模型结构,减少对计算资源的消耗和占用,并与目前使用最多的目标检测模型YOLO v5进行了对比。实验结果表明,本文模型在高密度养殖模式下分割生猪群体准确率达到96.7%,且本文模型内存占用量较SOLO v2减少96 MB,降低1/3,达到较好的猪群分割效果。盘点计数预测误差为0的图像数量为207幅,较SOLO v2增加26%,其中盘点计数误差为0头猪或1头猪的图像数量占整体测试图像的81.6%,较SOLO v2提高10.4个百分点,本文盘点误差在2头猪以内的图像数量占比为97.2%,误差大于3头猪的图像仅占1%。且本文模型计数正确的猪群图像数量约为YOLO v5的1.52倍,计数误差大于3头猪的图像数量是基于YOLO v5模型的1/5。
猜你喜欢
猪业科学(2022年11期)2022-12-17
导航定位学报(2022年5期)2022-10-13
电子技术与软件工程(2021年5期)2021-06-16
中国畜禽种业(2020年4期)2020-12-16
动漫星空(2020年10期)2020-10-29
动漫星空(2020年2期)2020-10-10
中外文摘(2020年8期)2020-05-05
河南畜牧兽医(2020年21期)2020-01-10
猪业科学(2018年5期)2018-07-17
电子技术与软件工程(2018年5期)2018-04-09
