
基于注意力和角度间隔损失的高光谱目标跟踪
2022-11-03 14:05施宗晗赵海涛
应用光学 2022年5期
施宗晗,赵海涛
(华东理工大学信息科学与工程学院,上海200237)
引言
近年来随着人工智能等技术的兴起,目标跟踪在机器人导航、无人驾驶、人机交互、智能交通和体育赛事转播等领域具有广泛的应用,涉及到国防建设、航空航天、安全保障等众多方面。目标跟踪根据给定视频序列初始帧的目标大小与位置来预测后续帧中该目标的大小与位置[1],是计算机视觉中重要的研究方向之一。由于跟踪目标和场景的复杂多变,且训练样本匮乏,能在有限的训练样本中克服运动模糊、快速移动、光照变化、尺度变化、旋转、遮挡等这些极具挑战性的问题[2],这考验着算法的速度、鲁棒性和准确性。早期的目标跟踪算法大多使用传统方法,包括基于滤波理论的算法[3-5]、基于核方法的算法[6-7]以及基于相关滤波的算法[8-11]。随着卷积神经网络(convolutional neural network,CNN)的发展,目标跟踪的性能得到了很大提升,深度学习在该领域的实际应用也在不断地改进和创新。
2013年,深度学习方法被首次应用到目标跟踪领域。随后,Ma 等人[12]提出的HCF(hierarchical convolutional features)算法将深度学习与相关滤波结合起来,使用核相关滤波(kernel correlation filter,KCF)算法[9],并将其中使用的多通道梯度直方图(histogram of oriented gradients,HOG)特征替换为深度卷积特征。而深度学习的功能十分强大,研究人员并不满足于将深度特征仅用在目标跟踪中。Bertinetto 等人[13]提出的全卷积孪生网络模型(fully-convolutional siamese networks,Siamese FC)实现了模型端到端的训练,使用大型数据集在孪生网络框架上进行离线预训练,提取目标模板特征与候选区域特征并进行卷积操作,得到的响应图中响应最大的区域即为估计目标位置。随后,Danelljan 等人[14]又提出了一种训练连续卷积滤波器(continuous convolution operator tracker,C-COT)的新方法,通过创建在时域内相关的连续卷积滤波器,有效地整合了多分辨率深度特征图。对于跟踪问题,使用视频跟踪序列作为训练数据更为合理,而且从目标检测、分类任务中迁移来的网络需要分出很多类别的目标,建成的网络很大,增加了计算的复杂度,但在跟踪问题中只需分两类,即目标和背景。于是2015年VOT的冠军算法,即多域卷积神经网络模型[15](multi-domain convolutional neural networks,MDNet)做出了一个示范,通过建立多域学习的网络结构来学习目标的通用表示特征。随后有研究人员提出MANet(multi-adapter convolutional networks,MANet)算法[16],将可见光图像和红外图像进行融合,并分别设计了共享卷积核和特定卷积核,同时延续MDNet的思想,跟踪效果和现有其他现有算法相比又有一定的提升。
虽然MANet 网络跟踪效果较好,但在一些场景较为复杂的情况下,例如目标与背景纹理相似或颜色相近时,跟踪算法很容易出现漂移。CNN模型在处理数据时,对每一个特征图和特征子空间进行等价处理,没有重点关注的对象,当目标尺度变化或颜色与背景相近时,缺乏对应的响应机制,限制了模型的性能。此外多域网络训练过程中,每一个域都对应一个不同的视频序列,一个视频中的目标可能是另一个视频中的背景。网络使用的Softmax 损失的决策边界是两类预测概率相等,这样就存在边界判断模糊的情况,在目标与背景颜色相近时,无法准确跟踪到目标,影响模型效果。
因此本文针对高光谱数据提出了基于注意力机制和加性角度间隔损失[17]的跟踪模型(multiadaptor convolutional neural network based on attention mechanism and AAML,AANet)。首先在卷积层后加入融合的注意力模型,该模型能够有效整合两路输入中不同波段的信息,对全局特征和局部特征进行处理,使得网络的注意力集中在目标上,在相似特征之间进行整合和强化;其次为了使得目标和背景更易区分,网络引入了加性角度间隔损失,通过最大化角度分类间隔,提高了不同类之间的可分性和差异性,同时加强了类内紧实度;最后整个网络通过端到端的训练,使得跟踪结果得到显著提升,同时验证了模型的有效性。
1 基于注意力和角度间隔的跟踪网络结构
本章首先介绍基于注意力机制和加性角度间隔损失的高光谱图像目标跟踪算法,整体网络受到MANet 的启发,采用融合的多域神经网络,同时使用注意力机制来获得更多的上下文信息,并采用加性角度间隔损失来增大正负类样本的类间距离,缩短其类内距离,使得网络输出的结果更为精确和鲁棒。
1.1 融合多域神经网络
高光谱图像的不同波段反映目标物体不同的光谱特性,但其中仍有一些共有信息,如物体的边界等。为了保留这些信息,网络采用共享卷积核来提取图像的共有特征,并针对不同波段通过特定卷积核来提取特有特征,构成一个并行的网络结构。整体网络结构由共享层和特定域层的多个分支组成,如图1所示。图中C 表示特征图的拼接。

图1 网络模型结构图Fig.1 Structure diagram of network model
为了最大化注意力矩阵信息的丰富性,将注意力机制模块加载到卷积层通道数最多的conv3 之后,将提取的特征经过融合的注意力机制得到加权特征,输入到接下来的两个全连接层中,网络末端是K个权值分支(W1-WK),这些分支对应K个域,也就是K个不同的视频训练序列。对应不同的视频序列,需要分别训练一个单独的权值W,每一个分支通过AAML 损失来求取正负类样本和其类别中心夹角,并通过类别样本夹角余弦值来判断跟踪是否成功。整个网络的输入层为107×107像素的图像,每个输入均来自3 个不同波段的图像,输入的图像区域需经裁剪统一为1 07×107像素大小,由于VGG-M 网络[18]结构简洁,并采用了较小的卷积核来降低参数量,因此共享的卷积核采用VGG-M 网络作为骨干网络。
1.2 融合注意力机制
注意力机制源自于对人体和视觉学的研究。当人类在观察一件事物时,由于信息处理能力有限,人类会将有限的注意力集中在重点信息上,即视觉的注意力焦点,同时忽略其他不相关或无用的信息,从而节省资源,快速获取最有效地信息。注意力机制包含source、query 和attention value 3 个要素,其中:source 表示需要处理的原始信息;query 代表给定的条件;attention value 则表示在给定query 下,原始数据通过注意力机制提取到的信息。通常source 中的信息是通过键(key)和值(value)来表示的[19]。
本文构建的注意力模型如图2所示。模型输入是通过卷积层提取到的不同波段组合的特征图1和特征图2,给定的query 通过特征图1 重构得到,key 则是通过特征图2 重构得到。相比于query 和key 均来自同一特征图的注意力模型来说,这样通过点乘操作后得到的attention value 可以融合不同波段组合的关联信息,同时有效地将这些上下文信息进行整合和强化。
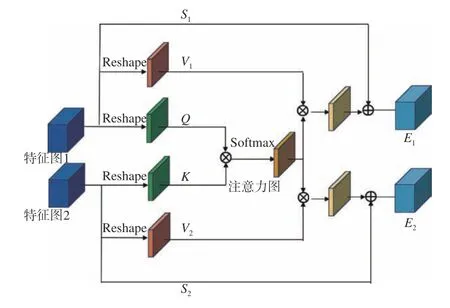
图2 注意力机制模型Fig.2 Structure diagram of attention mechanism
输入为经过卷积层提取到的特征矩阵A和B,且{A,B}∈RC×H×W,其中上标C、H、W分别表特征图的通道数、特征图的高度和宽度。对特征图1 进行重构,可得到对特征图2 进行重构,可得到其中CQ=CK=C,N=H×W。将Q转 置后与K进行矩阵相乘的操作,其结果利用Softmax 归一化为概率分布,得到注意力矩阵T=RN×N,aj,i是T在 (j,i)位置的元素,其计算的方式如(1)式:
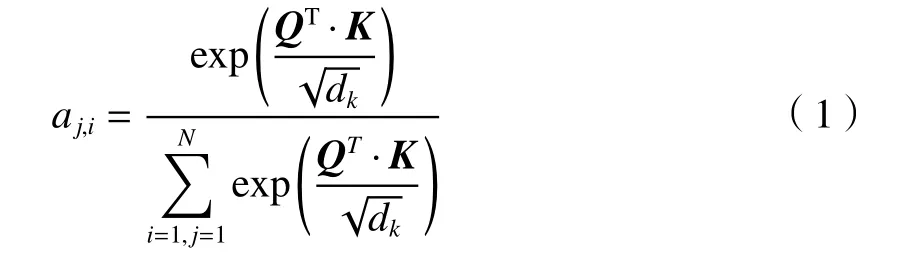
式中:aj,i是用来衡量位置j和位置i像素的相似度,aj,i的值越大,说明两个元素之间的关联程度越高,同时代表两个位置的信息也越相近;是一个尺度标尺,用来避免点乘之后的结果过大而影响计算过程。将转换和重构得到的矩阵V1和V2分别与注意力矩阵T相乘,得到的结果再分别与原特征图相加,最后注意力模块的输出为E1和E2,计算方式如(2)~(3)式:

将特征图E1和E2进行拼接后作为网络组件的输入,此时特征图中的各个位置信息均来自各路输入中所有位置全部的特征和经过注意力机制进行特征加权之和,这样能够有效捕捉到上下文信息,同时相似的特征之间会互相强化,对跟踪过程中对目标的分类和定位效果都有一定的提升,得到更鲁棒的目标表示。
1.3 加性角度间隔损失
由于高光谱图像的目标和背景在颜色相近或出现背景干扰时容易错分,因此网络在使用注意力机制的基础上又改进了损失函数。AAML 损失是基于余弦距离的间隔损失,该损失函数是对Softmax 损失函数的改进,Softmax 虽然可以进行分类,但它只有一个决策边界,如果类别中心向量之间的夹角较小,特征就容易混淆在两类之间,而AAML 实现了在角度空间内的最大化分类界限,通过给决策边界增加间隔,使得类内距离减小、类间距离增大,这意味着正负类样本错分的概率会减小。
假设样本xi对应的标签为yi,批量个数为N,类别数为n,那么Softmax 交叉熵损失函数定义为


同时为了增强特征的鉴别性,使特征向量的分布更加集中于权重中心,在角度空间内加上角度间隔m,可得到:
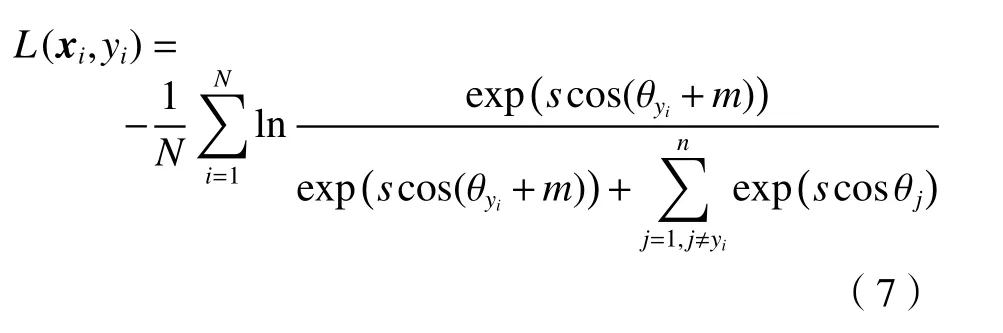
在跟踪问题中,首先为正负类样本设置中心类别向量,随后计算样本特征和类别中心的余弦距离并代入Softmax 函数,最后通过分类任务来训练模型。其中s和m是超参数,s=31.0,m=0.5。损失计算的伪代码如表1所示。

表1 AAML 损失计算Table 1 Loss calculation of AAML
2 网络训练
2.1 高光谱图像波段选择
高光谱图像波段众多,数据量大且冗余度高,直接进行分析计算对分类精度和效果都有一定影响,同时也增加了计算量。因此在进行跟踪实验之前需要先对原始数进行降维预处理,去除冗余波段以减少计算负担,从而获得相关性小、维数低、信息量大且冗余度小的波段。本文通过图像熵和OIF 指数相结合的方式来进行波段的选择。
图像熵是一种特征统计形式,反映了一张图像中平均信息量的多少。图像的一维熵表示图像中灰度分布的特征所包含的信息量,一元灰度熵计算公式为

式中:pi是某个灰度在图像中出现的概率。
最佳指数法(optimum index factor,OIF)将单波段图像的信息量和波段之间的相关性考虑在内,选择出信息量较大、冗余度较小的波段组合。计算公式如(9)式:

式中:Si为第i个 波段的标准差;Ri j为i、j两波段的相关系数。本文通过使用图像信息熵和OIF 指数相结合的方式进行波段选择,具体算法流程如表2所示。

表2 波段选择Table 2 Bands selection
首先计算高光谱图像各波段的图像熵,如图3所示,按照光谱波段图像熵由大及小进行排序后,选择前16 个信息量比较大的波段。
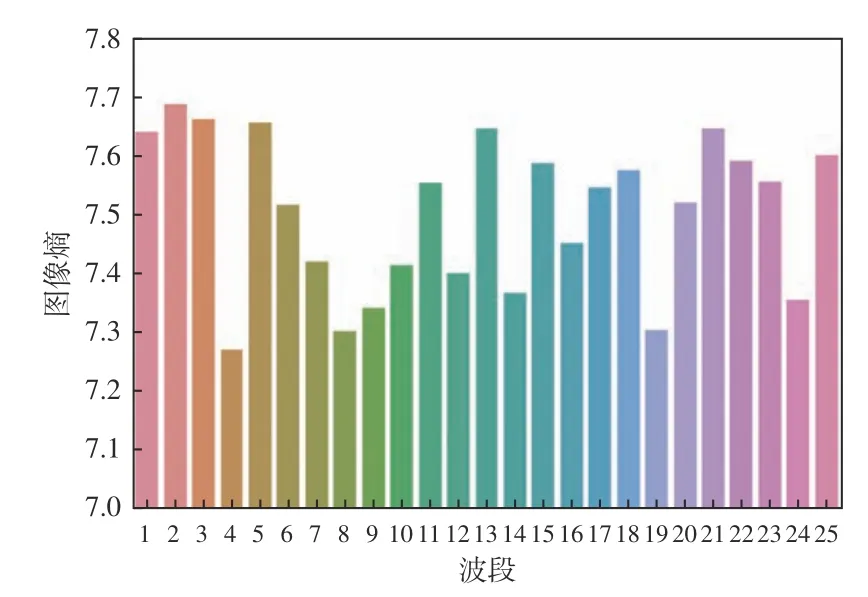
图3 原始高光谱图像各波段图像熵Fig.3 Image entropy of each band of original hyperspectral images
随后选择两组相关系数较小的波段作为算法的初始化波段,根据计算结果选出B1= {B15,B17},B2= {B11,B25},分别计算两组波段和剩余每个波段的OIF 指数,选择OIF 指数最大的波段加入到当前波段子集中,作为每路输入的波段组合。图4 展示了根据B1和B2进行初始化后的OIF 指数曲线,从中选出OIF 指数最大的加入到当前波段组合中,从图4(a)中可以看出初始化为B1后,需要选择波段16加入到当前波段组合中,为了保证波段多样性,减少冗余性,选择OIF 指数较大的波段20 加入到B2波段组合中。因此从图4(b)选出波段B1= {B15,B16,B17}和B2= {B11,B20,B25}进行后续实验。76 个视频,其中共包含17 846 帧高光谱图像。数据集按照6∶1 的比例划分为训练集与测试集,训练集共包含65 个视频,共包含15 047 帧高光谱图像,测试集共包含11 个视频,共包含2 799 帧高光谱图像。每个视频包含从几十帧到几百帧不等的高光谱图像,采集到的原始图像分辨率为2 048×1 088像素,经过解析后每一帧图像包含25 个通道,空间分辨率为409×217 像素。这些波段分布是不均匀的,波段响应范围为600 mm~975 mm,除了包含一部分可见光波段(380 mm~780 mm)外,还覆盖了一部分近红外短波光谱(780 mm~1 100 mm),极大丰富了图像的光谱信息。图像真实目标框需要人工进行标注,通过标记边界框的左上角和右下角来确定目标边界框的位置和大小。图5 为高光谱图像数据集各波段展示。图6 展示了本文数据集中目标特征的光谱曲线,横坐标为各波段标号,纵坐标为目标特征像元的灰度值,红色曲线代表飞机目标的光谱,蓝色曲线代表背景的光谱。图中标注的4 种线形分别表示飞机机身、飞机机尾、

图4 波段选择OIF 指数曲线Fig.4 Optimum index factor curves of band selection

图5 高光谱图像样本各波段展示Fig.5 Display of each band of hyperspectral image samples
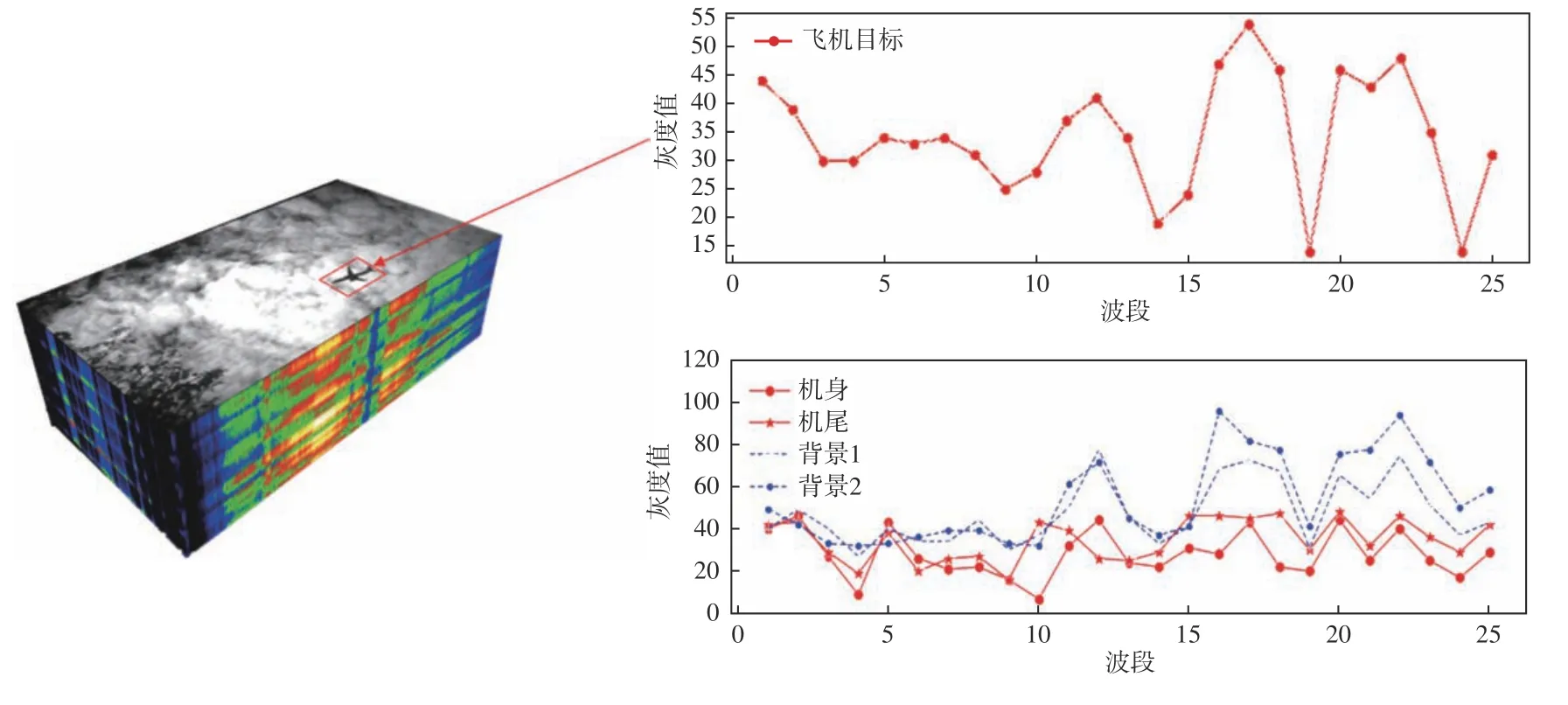
图6 高光谱图像目标特征的光谱曲线Fig.6 Spectral curves of target features in hyperspectral images
2.2 实验平台与数据集
本文所提出的模型均使用PyTorch 深度学习框架实现,通过Python 语言进行编程,使用NVIDIA RTX 2060 进行模型训练和测试。
本文所采用的实验数据集是自制的高光谱飞机数据集,由高光谱摄像机进行对空拍摄,共计背景样例1 和背景样例2。可以看出虽然飞机机身和天空、地面等背景颜色纹理相近,但在某些特定波段其光谱差异明显,使得飞机目标和背景相比是可区分的。
2.3 训练过程
该学习算法的目标是训练一个多域的卷积神经网络,能够辨别不同视频序列中的目标和背景,并通过不同高光谱图像不同波段融合的方式增加算法的鲁棒性和准确性。但不同域中的目标和背景具有不同的定义,为了将某一特定域与其他域分离开,采用多域学习的框架来提取目标的共有特征。
该CNN 网络通过随机梯度下降法(stochastic gradient descent,SGD)来训练,其中卷积层的学习率为0.000 1,全连接层学习率为0.000 2,动量和权值衰减设定为0.9 和0.000 5。在第K次迭代中,小批量中只包含来自第K个视频的样本,K个特定域层也只激活第K支。每个小批量从第K个视频任意8 帧中提取,共包含N+=32 个 正样本和N-=96个负样本,其中正样本 IoU ≥0.7,负样本 IoU ≤0.5。一直重复到网络收敛或达到预定义的迭代次数。通过这样的训练过程,学习到的通用特征就会被保存在共享层中,这些信息会被作为非常有效的泛化特征表示。
2.4 网络在线跟踪
预训练完成后,权值分支W1-WK会被去掉并直接替换为一个新的权值W,训练好的模型中只需保留共享层的参数,并根据跟踪序列的第1 帧信息对新的特定域层和共享层中的全连接层进行在线微调。
在训练一个分类器时,若训练样本类别不均衡,对训练无帮助的易分负样本会使得模型整体的学习方向跑偏,产生无效学习的现象,即智能分辨出不包含目标物体的背景信息,从而无法准确地分辨真正的目标。为了避免网络的预测值向负样本的方向靠拢,取正、负样本数比约为1∶3来进行网络训练,在训练过程中采用难负例挖掘的思想,找到难分的负样本,尤其是被错分为正样本的负样本,这样不仅可以减少训练的样本数,还能提升模型的准确性。参数更新过程中,全连接层的权重采用在线更新的方式,而卷积层的权重一直是固定的,这样的策略不仅能够提升计算效率,还能避免获取通用表示特征时出现的过拟合现象。同时在首帧训练时采用了边框回归技术来改善目标定位的准确度,通过均匀分布的方式在测试视频第1 帧时周围生成1 000 个正样本,其IoU ≥0.6,通过对这些样本使用conv3 特征进行训练,得到一个简单的线性回归模型来对目标的位置进行一定修正,提升预测的精度。为了在每一帧中生成候选目标框,根据上一帧的位置采用多维高斯分布的形式在大小和尺度两个维度上采样256 个候选目标X1,···,XN,通过前向传播计算每个目标特征和正负类的类别中心向量夹角余弦值取余弦值最大的前5个样本目标框均值作为当前帧的跟踪位置,若余弦值在设定阈值范围内,则视为跟踪成功,通过训练好的回归模型调整估计出的目标位置,作为当前帧最终的跟踪位置。同时在跟踪过程中采用长期和短期更新两种策略来实现网络的鲁棒性和适应性。跟踪流程如图7所示。
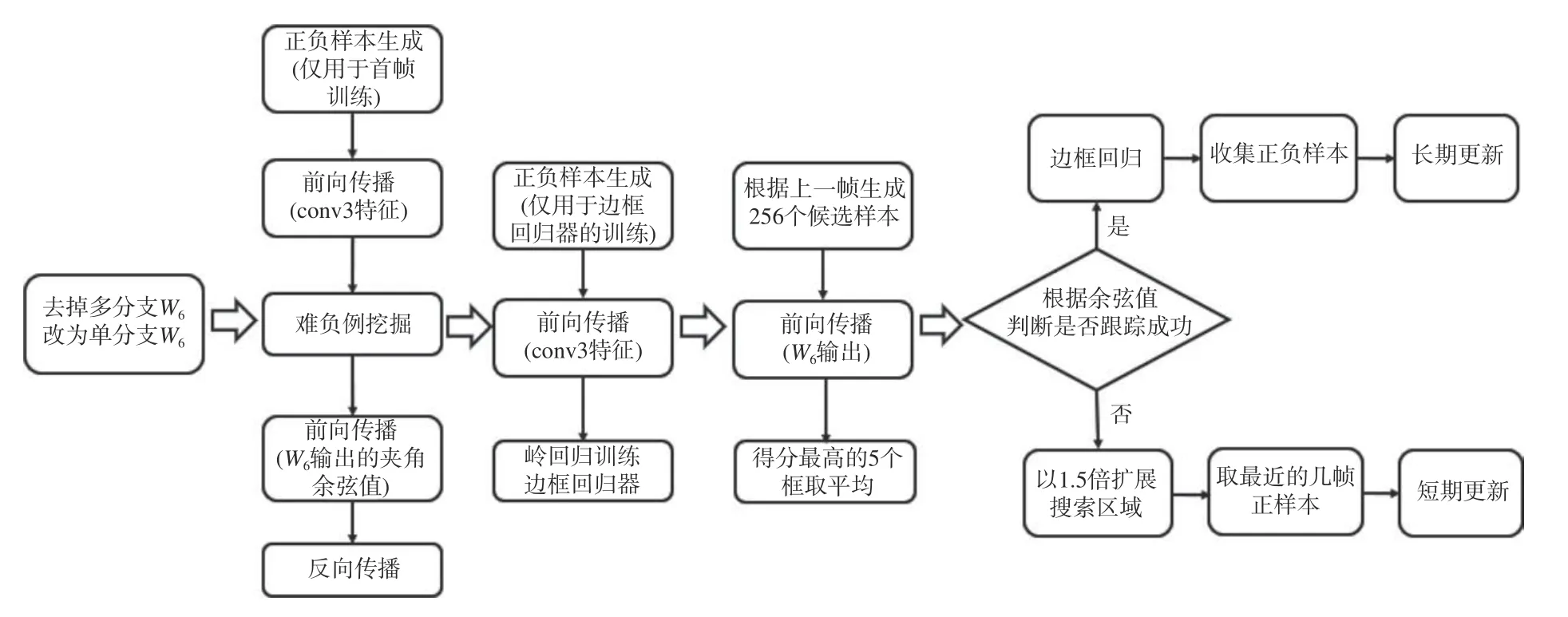
图7 在线跟踪算法流程Fig.7 Flow chart of online tracking algorithm
3 实验结果与分析
3.1 模型评价指标
针对目标跟踪问题,为了更直观地分析跟踪结果,一般通过精确率图(precision plot)和成功率图(success plot)进行衡量。精确率计算模型估计的目标位置中心点与人工标注目标中心点之间的距离,即:
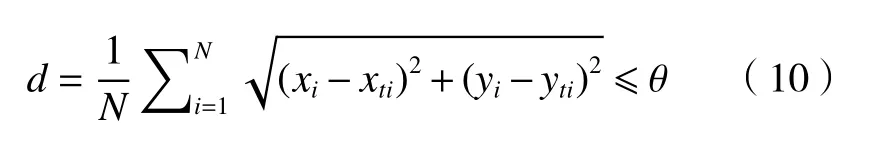
式中:xi和yi表示预测的目标框中心点位置;xti和yti表示预测的目标框的中心位置坐标,两者距离小于给定距离阈值 θ的视频帧百分比曲线即为精确率图。
成功率衡量的是目标位置和真实标注框的交并比(intersection over union,IoU),重叠率高于阈值的矩形框被认为成功跟踪到目标,反之则被认为未跟踪到目标,即:

式中:Ai表示跟踪到的目标框;AGi表示真实的目标框。大于给定交并比阈值δ 的视频帧的百分比曲线即为成功率图。
3.2 注意力机制可视化
注意力机制可以有效整合两路输入中不同波段的信息,使得网络的注意力集中在目标上。本节将把输入图片与注意力矩阵进行可视化展示,来说明注意力模型在跟踪过程中的作用。
图8(a)图展示注意力矩阵的可视化结果,8(b)图展示注意力矩阵和原图叠加的可视化结果。从图中可以看出注意力机制可以使模型更多的将注意力集中到目标上,尤其是飞机的机身,进而更利于后续的跟踪。


图8 注意力机制可视化Fig.8 Visualization of attention mechanism
为了更进一步展示注意力机制在跟踪过程中的作用,将目标和背景的特征图和注意力图进行可视化,如图9所示。图中特征图的可视化是将所有通道对应像素点的值取平均来进行的。根据结果可以看出,目标的注意力矩阵集中在机头和机身部分,背景的注意力矩阵则相对比较平滑,注意力分布比较均匀,因此网络对于这类输入不会产生较强的注意力,使得网络对正类和负类的区分更为准确。

图9 目标与背景的特征图和注意力图对比Fig.9 Comparison of feature maps and attention maps of target and backgrounds
3.3 目标跟踪结果可视化
本节将从直观和客观两个角度对本文模型结果进行展示。图10 是本文提出的算法对目标的跟踪轨迹图。由于视频均是由手持高光谱设备拍摄,因此视频中的目标存在一定抖动。从跟踪结果来看,本文提出的模型可以较好地跟踪到目标。

图10 本文算法跟踪结果图Fig.10 Tracking results of proposed algorithm
图11 展示了本文与其他算法在不同测试视频中的跟踪结果对比。从实验结果可以看出,本文提出的算法相比其他算法具有一定的优势。在测试数据集中,作为目标的飞机与作为背景的天空、云朵及地面汽车的颜色和纹理较为相近,一些算法容易出现跟踪失败的情况。例如在测试视频1、2 中,一些对比算法出现了漂移,开始跟踪天空中的云与地面的汽车,而本文算法由于改进了损失函数,使得网络对正负类的区分更为准确,因此能够一直跟踪到目标。同时,由于网络使用了注意力机制,不仅能够使模型将更多的关注集中到目标上,还能够获得更精确的位置表示,例如在测试视频3 中,在跟踪初期,所有算法均能准确跟踪到目标,而在跟踪后期,只有本文算法能完整地跟踪到目标,其他算法只能跟踪到一部分目标。因此整个模型在引入注意力机制后,跟踪结果更为精确,加入AAML 损失后整个模型的学习性能增强,对正负样本的区分也更为鲁棒。

图11 不同算法跟踪结果对比Fig.11 Comparison of results with different tracking algorithms
接着以定量的角度对目标跟踪的结果以及两种指标方面进行对比分析,进一步佐证了上述直观结果。从图12 中可以看出本文所提出的方法在成功率和精确率上相较于其他方法均有提升,分别提升了1.3%和0.3%。

图12 不同网络精确率和成功率对比图Fig.12 Comparison curves of accurate rate and success rate of different networks
3.4 消融实验
为了进一步验证本文提出模型中各模块的有效性,设计了如表3所示的消融实验,本文的模型框架基于MANet,因此以其为基准。Ours-AAML(without margin)表示在MANet算法基础上使用AAML 损失且不设角度间隔,Ours-AAML 表示在MANet 算法基础上加入AAML 损失,Ours-Attention表示在MANet 算法基础上加入注意力机制。由表3 可以看出,本文所设计的各个模块对算法的提升都有着积极作用,相比于原始MANet 算法,在精确率和成功率上分别提升1.3%和2.7%,最佳的表现来自于3 个模块的共同作用。

表3 消融实验Table 3 Ablation experiment
4 结论
本文提出了一种基于注意力机制和加性角度间隔损失的融合高光谱图像目标跟踪方法。利用注意力机制来获取融合的加权特征,减少模型的漂移问题,获得更鲁棒的位置表示,同时采用AAML 损失提升了模型对具有相似语义的目标分判别能力。实验结果显示,本文算法在自制高光谱数据集上获得了优于经典目标跟踪算法的结果,精确率和成功率分别提升了1.1% 和0.3%。(代码地址:https://github.com/Blueyonder00/AANet)但该算法在运动目标突然发生尺度变化或快速移动时,追踪效果仍不理想,在之后的工作中,将针对这个问题进行专门的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
航天返回与遥感(2022年2期)2022-05-12
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2021年1期)2021-05-22
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
