
基于多频谱特征的音频对抗样本检测方法
2022-11-02 03:20:02马健罗达
东莞理工学院学报 2022年5期
马健 罗达
(1.东莞理工学院 计算机科学与技术学院,广东东莞 523808;2. 东莞理工学院 网络空间安全学院,广东东莞 523808)
近年来,对抗样本[1]的研究在语音识别领域发展迅速。作为对抗样本技术在语音识别中的特殊应用,可通过添加特定的对抗扰动噪音,使语音识别系统的识别结果发生改变,甚至变成攻击者指定的句子。虽然如今端到端语音识别系统在性能上十分优秀,但存在音频对抗样本技术使语音识别系统的安全受到了严重的威胁,因此有必要对音频对抗样本进行深入的研究。
自动语音识别系统(ASR)的任务是语音到文本的转换。许多现代的自动语音识别系统都是基于深度神经网络(DNNs)模式,性能突出,如Deep-Speech[3]、Lingvo[4]和Amazon Transcribe。在端到端的语音识别的背景下,有可能向一段音频片段注入对抗扰动噪音,以此篡改语音识别的结果。比如:
原始识别结果:The password has given to Alice;
Key-word篡改:The password has given to Bob;
Sentence篡改:I do not have the password.
在第一种情况下,对抗样本只将句子中的关键词从Alice改为Bob,被称为关键词篡改。在第二种情况整个文本被替换,被称为句子篡改。
语音识别领域的对抗样本研究分为攻击方面和防御方面[2]。在攻击方面的研究,文献中展示了几种ASR对抗样本攻击方法[5-8]。其中一些关键的技术是共通于图像领域的,如使用梯度下降法来对扰动噪点进行更新。与对抗样本攻击方法不同,音频对抗样本检测与图像领域的对抗样本检测方法相比,更具挑战性。首先,由于序列的依赖性,基于递归神经网络(RNN)[9]生成音频对抗性样本更慢、更复杂,导致训练二进制分类器作为音频对抗样本检测器的训练样本更少。此外,音频输入转换对对抗样本攻击的抵抗效果并不明显[10],主要是因为语音数据具有一定时序的依赖性。在现有ASR对抗样本防御研究中,Zeng等人[11]提出以音频文件在不同架构和不同参数下的语音识别系统中的识别结果相似度作为检测音频对抗样本的指标。Yang等人[10]利用音频数据中固有的时间依赖性进行检测,音频切帧前后的识别结果差异被用作检测的指标。此方法将作为对比方法在实验中部分使用。Jayashankar等人[12]在语音识别的神经网络推理中使用了dropout机制[13],dropout机制是指在神经网络训练的过程中使部分的神经元权重为0,增强模型的泛化性。在模型推理过程中使用dropout机制会使神经网络的参数信息异动,进而使音频对抗样本的攻击失效,但使用此方法会在一定程度上导致模型的性能下降。Zhu等人[14]提出了使用对抗训练的方法来训练模型,是在训练模型的过程中,同时对模型进行对抗样本攻击,使模型在对抗样本的攻击下继续进行正确的推理,增强模型的鲁棒性。上文提及的音频对抗样本检测方法的检测准确率还存在提升空间,且现有的音频对抗样本防御检测工作缺乏对音频对抗样本分布特征的分析,因此笔者从对音频对抗样本分布特征的分析入手,提出准确率更高的音频对抗样本检测方法。
文中在时域和频域上对音频对抗样本的扰动噪音的分布特点进行了分析,发现扰动噪音在时域和频域上的分布特征:在时域上,音频对抗样本的扰动噪音会广泛分布于整段原始音频;在频域上,音频对抗样本扰动噪音会集中在中高频部分。据此,笔者提出一种基于多频谱的音频对抗样本检测方法,实验结果表明,所提出的方法可以显著提高音频对抗样本检测的准确率,在公共语音数据集上,与基线方法和最先进的方法相比,该方法的检测准确率提升超过30%。
1 基于多频谱的检测方法
1.1 音频对抗样本攻击
考虑用两种有代表性的攻击方法来生成音频对抗样本:C&W攻击[5]和Taori攻击[8]。前者是基于梯度下降优化的白盒攻击,后者是最先进的黑盒攻击。C&W攻击部署在DeepSpeech v0.4.1上,而Taori攻击部署在DeepSpeech v0.1.1上。
1) C&W攻击方法:Carlini和Wagner提出了通过一个优化函数来生成对抗性扰动。该方法需要获取目标的参数信息。具体来说,DeepSpeech使用连接主义时间分类(CTC)损失函数[15],因此,C&W攻击的目标函数表示为:
suchthatdB(δ)≤τ,
(1)
(2)
2)Taori攻击方法:Taori攻击是一种针对ASR系统的黑盒攻击方法,黑盒攻击不需要访问受害模型的内部信息。攻击有两个步骤组:首先,使用带有动量突变的遗传算法来获得一个近似的解决方案,再使用梯度估计方法来完善对抗扰动噪音。与C&W攻击相比,Taori攻击是以较慢的速度产生音频对抗样本,并带来相对大的扰动噪音。
1.2 扰动噪音特征分析
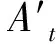
At=h(Utxt+WtAt-1) ,
(3)
模型的输出计算方式为:
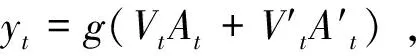
(4)
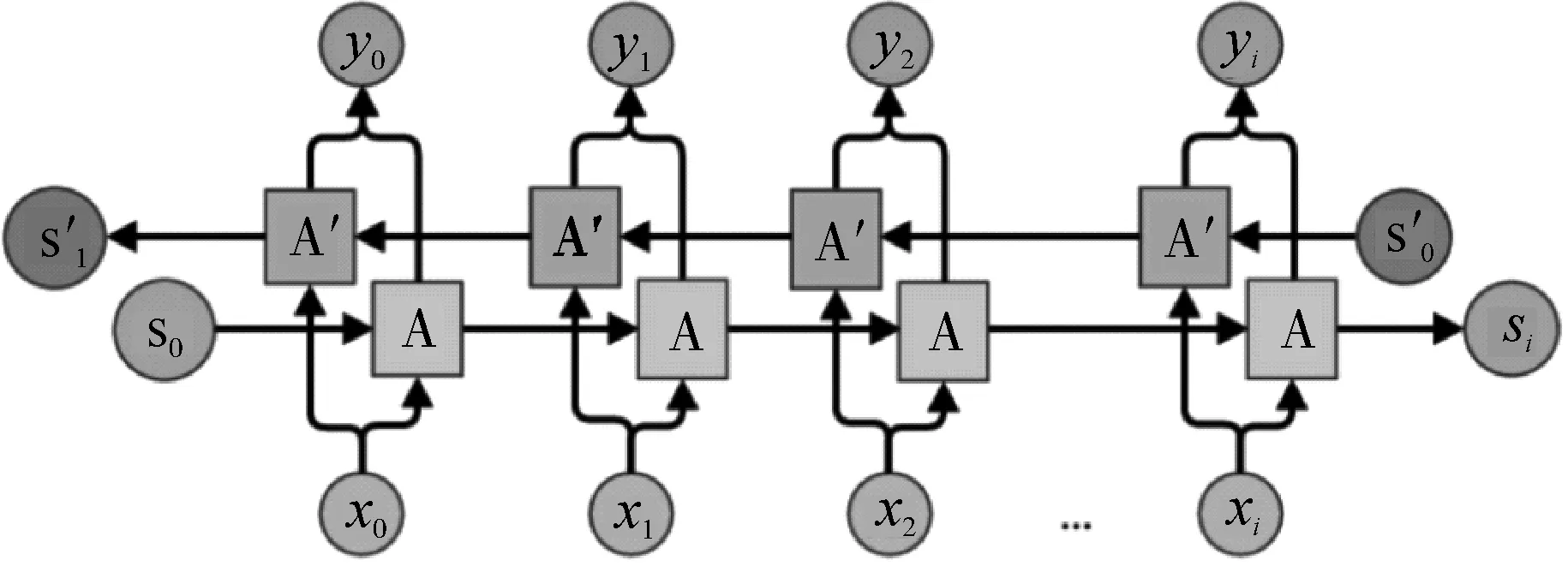
图1 idirectional-RNN 网络结构示意图
在攻击过程中,将对抗样本扰动噪音信号定义为语音篡改前后的音频样本之差,即,其中,为了篡改,必须改变时间序列中的整个话语序列。不失一般性地,用表示篡改后的输出。因此,在范数攻击中,关于的目标函数是,再使用梯度下降法来优化这个目标函数。由以上的推断可知,无论是篡改整段语句还是篡改关键词,对抗样本扰动的噪音都会影响整段音频信号。
C&W方法产生的音频对抗样本数据被作为挖掘音频对抗样本频域特征的研究对象。攻击的方法分为关键词篡改与句子篡改两种情形。在音频对抗样本频域特征的研究中,首先将干净的音频与该音频对应音频的对抗样本波形图进行比较,从图2中的上部分可见波形图,分别为干净音频的关键词篡改情况下的音频对抗样本与句子篡改情况下的音频对抗样本。在波形图上难以察觉出差异,这符合音频对抗样本难以被人耳察觉的特性。由于在波形图上难以观测到音频对抗样本的特征,因此使用短时傅立叶变换(Short-time Fourier Transform, STFT)将音频转换为频谱图,再使用功率谱图研究音频在各个频率上的能量分布,功率信号在某一时间段的平均功率可以表示为:
(5)
若式(5)中的f(t)在有限时间段内用fT(t)表示,fT(t)的傅立叶变换表达式为FT(ω)=F[fT(t)],则平均功率谱的计算公式为:
(6)
(7)
通过计算干净音频与音频对抗样本的功率谱图,可以发现音频对抗样本在频域上的分布特点,从图2的下部分功率谱图可以看出,音频对抗样本的功率谱图比起干净音频的功率谱图在6 000至7 000 Hz的能量更大,且该现象在句子篡改情况的音频对抗样本上更为明显。
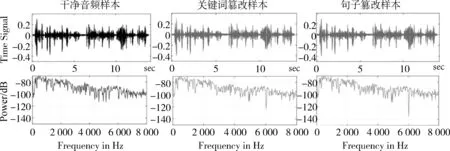
图2 音频对抗样本的波形图与功率谱图分析
单独对一段干净音频及其对应的关键词篡改情况的音频对抗样本进行分析,使用Welch方法[17]计算二者之间的相关性,结果如图3上图,干净音频与其对应的音频对抗样本在0至4 000 Hz范围内的相似度达0.9以上,它们的主要区别集中于5 000 Hz以上的频率范围。为进一步验证干净音频与其对应的音频对抗样本在频域上的分布特点,笔者进一步进行交叉功率谱相位(Cross-Spectrum Phase)分析,音频功率谱密度由式(8)计算:
Pxy(ω)=∑Rxy(m)e-jωm,
(8)
其中互相关系数序列(cross-correlation sequence)定义为:
Rxy(m)=Ex[n+m]y=Ex[n]y[n-m] ,
(9)
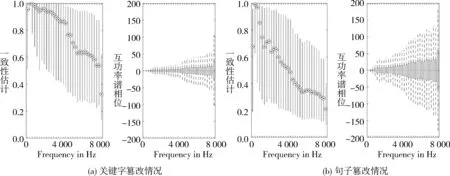
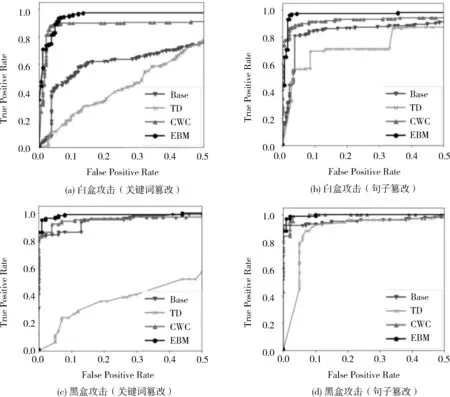
式(8)中的x和y为要进行对比的两个音频信号,-∞ 图3 音频对抗样本相关性分析与音频交叉功率谱相位(Cross-Spectrum Phase)分析 进一步在Common Voice语音数据集[18]上进行信号相似度的统计分析。每个样本的持续时间为3 ~ 4 s,每隔0.1 s切成帧,总共产生了3 890对从100对干净的和敌对的样本中切分出来的帧。图4以箱线图的形式总结了关键词和句子篡改的结果。总的来说,与关键词修改相比,句子修改的对抗性扰动在信号的能量和相位方面造成更大干扰。这种影响在高频段尤为显著。如相似度分析中在5 kH之后急剧下降,关键词篡改的均值降至0.7以下,句子篡改均值降至0.4以下。大量数据支持下的分析结果符合上文的推测,音频对抗样本的扰动噪音主要活跃在高频部分,这与人耳的听力敏感范围主要在相对低频部分,而对高频部分的声音不敏感相关。并且,该现象在句子篡改的音频对抗样本的扰动噪音分布中更加明显。 在以上实验中,音频对抗样本在时域和频域的分布特征得到了挖掘。在频域上,音频对抗样本的扰动噪音主要在高频部分拥有较高的能量。在时域上,由于语音识别系统模型架构的特性,音频对抗样本的扰动噪音会散布在整段干净音频序列中。基于以上分析可知,音频对抗样本的扰动噪音在频域上更易被察觉,在频域上捕捉音频对抗样本扰动噪音更容易,并且基于音频对抗样本扰动噪音在时域的分布特点,检测方法以音频的帧作为检测单位效果更好。据此笔者提出一种基于多频谱的音频对抗样本检测方法。 图5为笔者提出检测方法的流程图,先将待检测音频切成帧,每一帧的时长为100 ms,记每一帧音频数据为。通过离散傅立叶变换(Discrete Fourier Trans- form, DFT)将每帧音频数据转换到频域,转换形式为: 图4 通过(a)关键字篡改情况和(b)句子篡改情况从100对干净和对抗样本中音频中切出的3890对帧之间的一致性估计(coherence estimatesy)和互功率谱相位(cross-spectrum phase)的箱线图 图5 基于多频谱的音频对抗样本检测方法流程图 (10) 式(10)中的ω[m],序列长度为L,m=0,1,…,L,N是用来进行DFT转换的数据长度。在本文实验中,使用常见的分窗方法——汉宁窗(Hanning Window),长度L为512。输入音频切片信号通过汉宁窗后利用傅立叶变换转换到频域,这里用到了两个时域上的参数和。转换后的二维频谱图作为检测器的输入样本。由于在频域上的频谱图特征较复杂,笔者使用端到端的学习方法来训练一个二分类器来提取频谱的特征后进行检测。特别地,在分类器中先使用卷积神经网络[19](Convolutional Neural Networks, CNN)进行特征提取,再使用交叉熵[20](Cross-Entropy, CE)损失函数对网络进行建模。频谱图被标记为干净样本或音频对抗样本后被送入神经网络,以此来训练检测器神经网络。 为提高检测精度,在CNN基础上采用能量模型的训练方法,最近的研究发现,基于能量的模型(EBM)[21]可以帮助改善自我监督学习的判别式模型。EBM依赖于这样一个认识:x∈D的任何观测概率密度p(x)均可用所谓的能量函数表示,即Eθ:D←,将输入的x映射成一个标量。在二分类器的情况下,能量函数可以定义为: Eθ(Y,x)=-Y·Fθ(x) , (11) 其中,CNN的logit被重新用于fθ(x),Y是x的类别标签,表示是干净的数据还是对抗样本的数据,即Y∈{-1,1}。当预测正确且置信度高时,能量值Eθ(Y,x)会降低。通过应用极大似然估计与Gibbs分布的准则进行训练,使能量模型的能量值尽可能小,遵循的损失函数遵循极大似然估计的损失(Negative Log-likelihood, NLL)[22]函数设计,定义为: LNLL(Y,x;θ)= (12) 损失函数中的对数项是对所有可能的输出标签{E(y,x),y属于Y}的对数概率之和,记为free energy。由于模型的输出结果的改变,对比项会根据模型输出正确值时而变大,以此来制衡能量损失函数的更新,以免模型过度学习某一个输入样本的特征,该项起到对比学习的作用,能让模型在学习过程带有自监督的效果,从而提升了模型的泛化性能,以此提升模型的性能。参数β是一个正常数,用来控制损失函数中的对比项的工作强度,实验中将β设置为常见的0.5。 根据上文分析,笔者提出的在频谱域中设计音频对抗样本检测器有三个优点:1)在帧的功率谱中,对抗扰动噪音的特征更为显著;2)如上文分析,在频谱上可以更好地利用时空信息处理高度而非平稳的扰动噪音信号,特别是当扰动噪音的分布位置遍布在整段音频信号中时;3)通过将语音段切成多个频谱帧,有更多的对抗样本数据用来训练一个有效的检测器,从而缓解了第一节中讨论的音频对抗样本检测训练中训练数据较少的问题。 实验在两个公共语音数据集即LibriSpeech[23]和Mozilla Common Voice数据集[17]上评估了本文所提出方法对音频对抗样本的检测准确性。LibriSpeech是包含有声读物的录音,这些录音被切割并组织成文本注释的音频文件,每个文件约15 s。Common Voice数据集包含短的音频片段,每个片段约4 s。实验中使用LibriSpeech数据集中的57个音频片段和Common Voice数据集中的60个音频片段作为训练数据集。C&W攻击方法和Taori攻击方法将在本实验中用作生成音频对抗样本数据的攻击方法。特别的,C&W攻击方法为白盒攻击,Taori攻击方法为黑盒攻击。为了在有限的时间内完成黑盒攻击,将LibriSpeech数据集中的音频片段分成10 s的片段和5 s的片段,来生成黑盒攻击的音频对抗样本。实验中使用LibriSpeech和Common Voice数据集生成了187个白盒攻击音频对抗样本和100个黑盒攻击音频对抗样本,分别作为用于测试关键词和句子的篡改的数据集。DeepSpeech[3]被用作受害的语音识别模型,其中白盒攻击部署在DeepSpeech v0.4.1模型上,黑盒攻击部署在DeepSpeech v0.1.1模型上。 对音频对抗样本检测效果实验,使用真阳性率 (True Positive Rate, TPR)和假阳性率(False Positive Rate, FPR) 作为检测的评价指标。在检测过程中,将检测结果为真阳性的个数记为TP,检测结果为假阴性的个数记为FN,检测结果为假阳性的个数为FP,检测结果为真阴性的个数为FN,则有: 1)真阳性率 TPR: (13) 2)假阳性率 FPR: (14) 实验使用了四种不同方法对数据进行检测并对检测效果进行比较。1)基线方法使用语音识别常用的手工提取特征作为RBF-SVM[24]的输入,而不是使用端到端方法。在基线方法中使用广泛用于语音识别和音频检测系统的手工提取特征的 Mel Frequency Cepstral Coefficients(MFCCs)[25];2)最先进的音频对抗样本检测方案,通过利用音频中固有的时间依赖性(TD)[10],在时间序列域中分辨出音频对抗样本;3)在本文提出的多帧频谱检测框架下,使用CNN模型进行特征提取和分类器学习,具体来说,CNN架构依次包括5层(3个卷积层和2个max-pooling层),3个卷积层的核大小分别为9×9、5×5和5×5,通道外大小为24、36和60,2个max-pooling层的核大小分别为5×5和3×3,训练epoch设置为15;4)在CNN logits的基础上使用的EBM进行模型训练的方法。表1显示了TPR在5%FPR下对关键词和句子篡改的检测精度。 表1 在白盒和黑盒攻击下对关键词和句子篡改情况下的音频对抗样本检测精度(TPR @5% FPR) 由表1的数据可以看出,EBM在所有攻击下表现最好,其中,在LibriSpeech的长音频数据上产生的句子篡改的黑盒攻击对抗样本较少,且成功的黑盒攻击有较大的扰动强度,这导致所有四种方法都相对容易进行检测。实验通过用LibriSpeech上产生的音频对抗样本数据本来训练检测器,并用Common Voice上产生的音频对抗样本数据来测试。EBM训练的检测性能显示了显著的适用性,这表明该模型在不同的攻击下的检测性能更可靠。为考察本文提出的方法在面对跨数据集场景时的可行性,实验中使用长音频数据集LibriSpeech作为训练数据集来训练模型,并在短音频数据集Common Voice上进行测试(如表1),本文提出的方法在跨数据集也可行。图 6为白盒攻击与黑盒攻击下的关键词篡改情况与句子篡改情况的四种检测方法ROC曲线图。ROC曲线图是由真阳性率TPR和假阳性率FPR共同决定,FPR越小TPR越高,代表检测方法的性能越好,即检测方法的ROC曲线包围的面积越大代表检测性能越好,从图6中可以看出本文提出的多频谱检测方法CWC和EBM在关键词篡改情况下的检测成功率要好于基线方法和TD方法。 图6 白盒攻击与黑盒攻击下的关键词篡改情况与句子篡改情况的检测器 ROC 曲线图 文中先对音频对抗样本在时域和频域的分布特征进行分析,发现了音频对抗样本在时域和频域上的分布特点,根据分析得到的音频对抗样本特点,提出了一种基于多频谱的音频对抗样本的检测方法,并提出了利用音频对抗样本的扰动噪音会分散在干净的音频以及扰动噪音主要分布于高频段的特点,以帧为检测单位在频域上进行检测,利用能量模型的训练方法对检测模型进行训练。实验结果显示提出的方法在白盒攻击与黑盒攻击上都取得了更好的实验结果,且在关键词篡改情况下的音频对抗样本检测的效果上提升更为明显。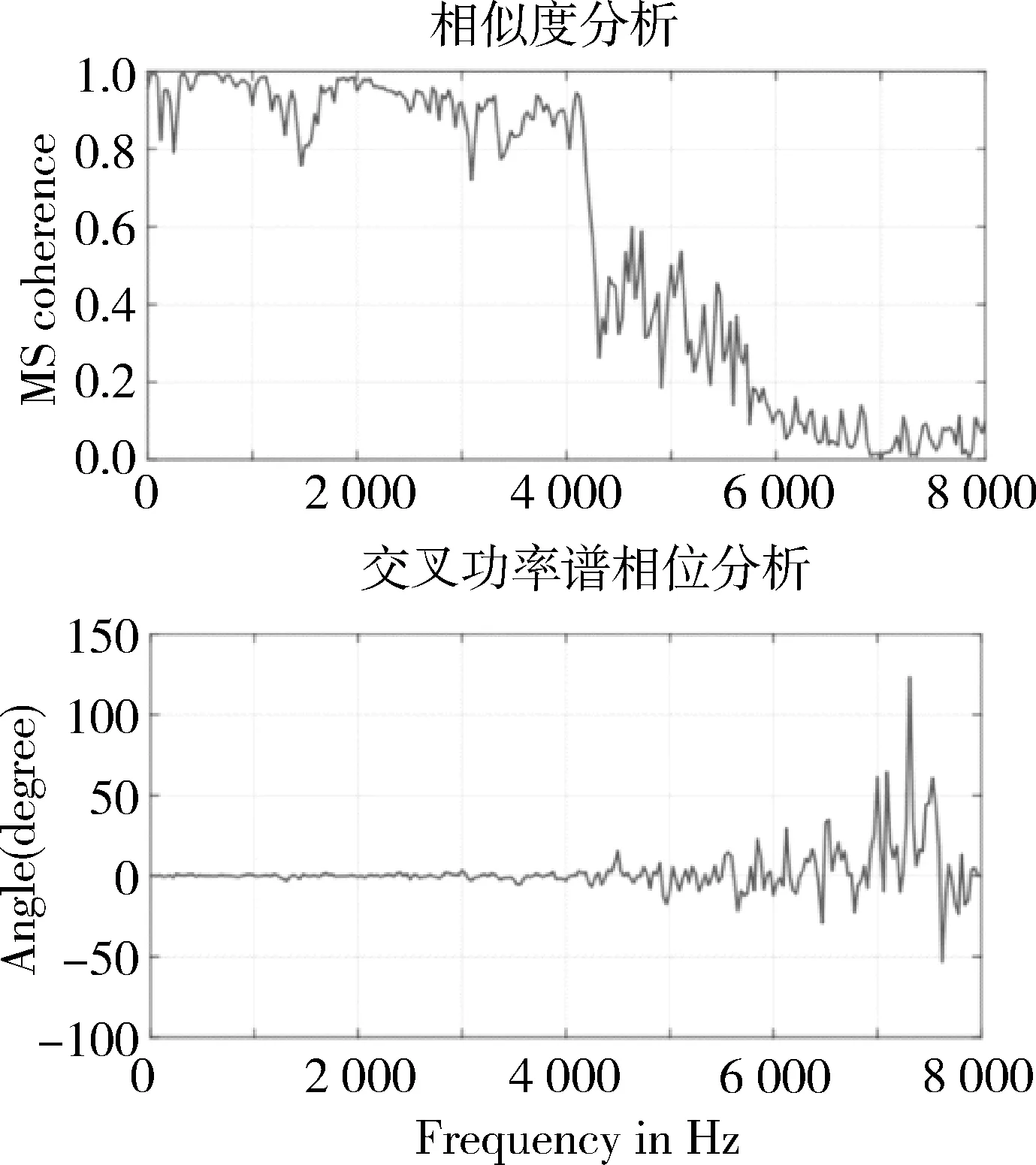
1.3 基于多频谱的检测框架
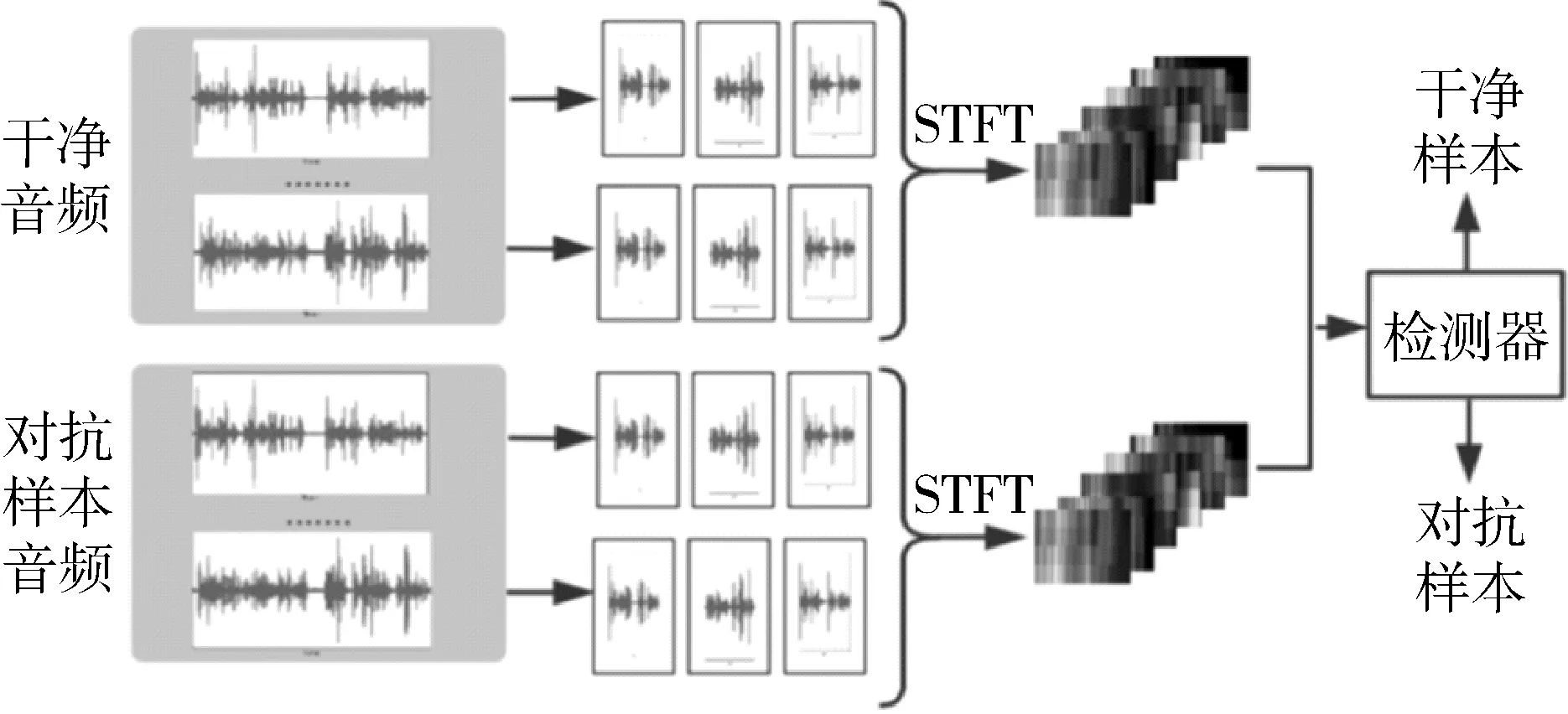

2 实验以及结果分析
2.1 实验环境
2.2 评价指标
2.3 实验结果分析

3 结语
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:06:36
小学科学(学生版)(2020年10期)2020-10-28 07:52:12
疯狂英语·新悦读(2019年10期)2019-12-13 09:02:32
数学物理学报(2019年4期)2019-10-10 02:38:56
雷达学报(2018年3期)2018-07-18 02:41:34
小火炬·阅读作文(2017年8期)2017-09-26 06:30:48
Coco薇(2017年9期)2017-09-07 22:09:28
贵州师范学院学报(2016年3期)2016-12-01 03:53:52
火控雷达技术(2016年1期)2016-02-06 02:17:55
无线电通信技术(2015年3期)2015-12-23 11:37:02
