
基于主成分分析和支持向量机的鲁棒稀疏线性判别分析方法
2022-11-01 06:34:00鞠厦轶吕开云龚循强鲁铁定
科学技术与工程 2022年26期
鞠厦轶, 吕开云,2*, 龚循强,2, 鲁铁定,2
(1.东华理工大学测绘工程学院, 南昌 330013; 2.自然资源部环鄱阳湖区域矿山环境监测与治理重点实验室, 南昌 330013)
特征选择是从原始高维图像中提取有用信息,通过低维特征高效地表示图像的主要信息,在人脸识别、基因检测、图像检索以及文本分类等领域中应用广泛[1-2]。在线性判别分析中,输入端需将高度相关的图像矩阵变为图像向量进行识别,在量化过程中会造成数据冗余性,直接对高维图像向量提取特征,既耗时又降低识别率。因此如何从高维图像中提取具有代表性的特征成为当下研究的热点[3]。
最近几十年,中外学者针对特征提取提出了各种各样的方法,其中线性判别分析(linear discriminant analysis,LDA)被广泛使用。LDA的基本原理是通过建立最小化类内散度矩阵同时最大化类间散度矩阵模型来获得投影矩阵,基于LDA的模型多种多样[3-5]。Li等[6]提出的鲁棒线性判别分析(robust linear discriminant analysis,RLDA)通过使用L1范数在解决小样本的同时对受污染的图像具有鲁棒性。Li等[7]提出的基于L1范数和巴氏距离的鲁棒线性判别分析(robust linear discriminant analysis based on the bhattacharyya error bound and L1-norm,L1BLDA)通过使用巴氏距离能够避免类内散度矩阵出现奇异值并且采用L1范数能提高对异常值的鲁棒性。Guo等[8]提出的鲁棒自适应线性判别分析(robust adaptive linear discriminant analysis,RALDA)通过使用L21范数正则化来选择更佳的特征矩阵。Wen等[9]提出了鲁棒稀疏线性判别分析(robust sparse linear discriminant analysis,RSLDA)通过正交矩阵保留高维图像的主要特征,利用稀疏矩阵拟合噪声所引起负面影响,提高LDA的鲁棒性。
然而上述涉及的方法通常是直接对高维图像向量直接处理,考虑到基于LDA模型的方法提取特征时需将图像矩阵变为图像向量,这样做既会耗时,增加电脑算力,降低识别效率,同时在向量化过程中,噪声图像会降低识别率。为此,现提出一种基于主成分分析(principal component analysis,PCA)和支持向量机(support vector machine,SVM)的鲁棒稀疏线性判别分析方法。利用PCA对高维图像向量进行降维处理,这样做不但能够提高识别率而且能够提高方法的鲁棒性,采用RSLDA对降维后的图像向量提取特征,RSLDA可以看作是将PCA和LDA联合到一个框架中,该方法不但可以提取最具代表性的特征,而且可以保留降维后图像特征的主要特征,最后利用SVM对提取后的图像进行分类。通过ORL人脸库、YaleB人脸库、COIL20物体库和UCI机器学习库中的部分图像集,将本文方法与LDA、RLDA、L1BLDA、RALDA和RSLDA进行比较。
1 基本原理
通过PCA对高维图像向量降维,利用RSLDA对降维后的图像提取特征,利用SVM进行分类。因此,了解一下PCA的基本原理。
1.1 主成分分析方法
主成分分析(PCA)是使用较为广泛的降维方法[10-12]。其基本原理是依按照特征值从大到小的顺序,选择前K个特征值对应的特征向量,组成低维子空间,不但减少样本间的相关性,而且最大程度地保留高维图像的主要特征信息。
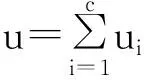
(1)
第i类的样本标准差σi为
(2)

(3)
协方差矩阵M为
(4)
计算协方差矩阵的特征值和特征向量,将特征值按照从大到小的顺序排列,选择前K个特征值对应的特征向量组成降维矩阵W=[w1,w2,…,wr]∈RK×r,从而降维后的图像为
(5)
1.2 本文方法
LDA是利用标签信息,最大化类间距离的同时最小化类内距离,获得投影向量g为
(6)
式(6)中:Sw和Sb分别为类内散度矩阵和类间散度矩阵,表示为
(7)
(8)

(9)
式(9)中:β为很小的正调谐参数,本文取β=10-5。
考虑到同类别间差异较小,不同类别间差别较大,为了获得更具有鉴定性的特征矩阵,同类间使用L2范数,不同类别间使用L1范数,称为L21范数,计算公式为
(10)
(11)
式(11)中:Tr(·)为矩阵的迹;G∈Rr×l
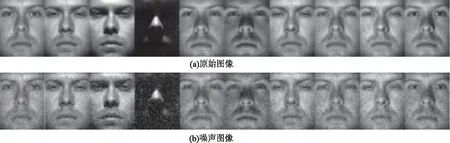
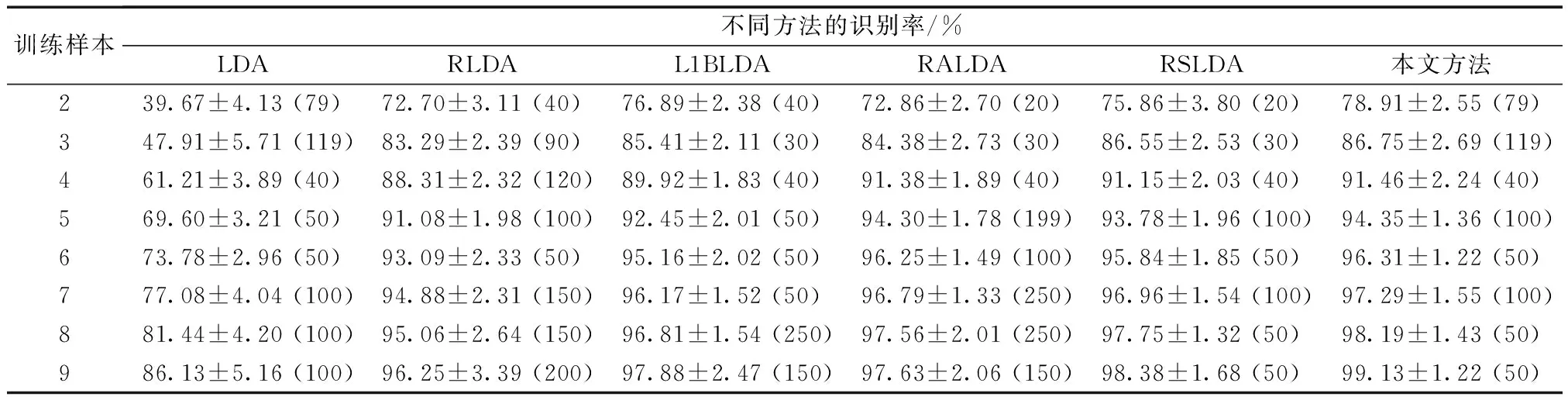
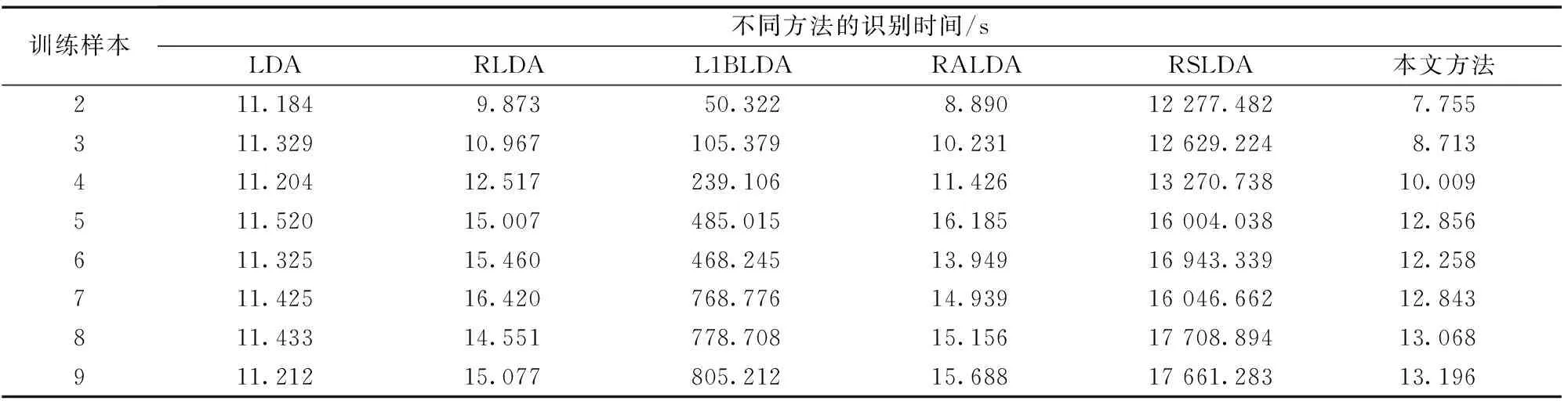
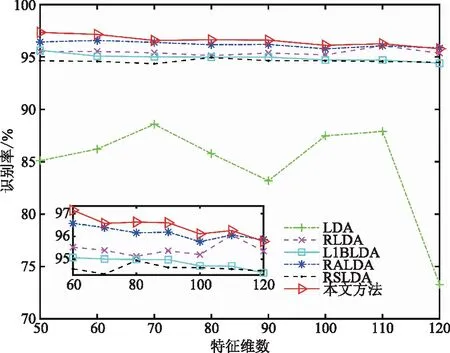
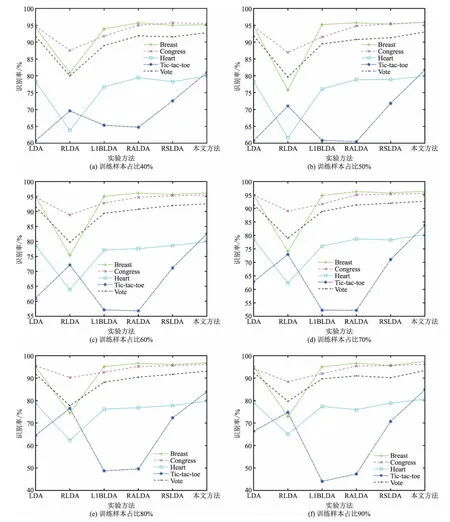
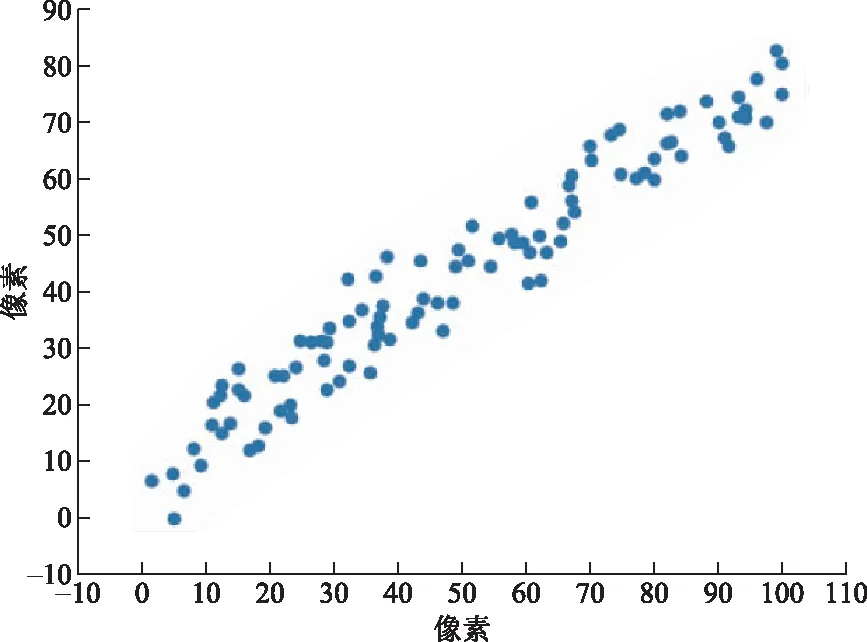
(l (12) 式(12)中:Q∈Rr×l为正交重构矩阵,根据文献[14],通过奇异值分解可以获得。在现实世界中,图像很容易受光照条件、传输通道以及传感器等噪声的影响,会影响识别率,引入稀疏矩阵来减少噪声的负面影响,因此,式(12)改进为 (13) 基于主成分分析和支持向量机的鲁棒稀疏线性判别分析方法在处理高维图像时,通过PCA对高维图像向量进行降维处理,采用RSLDA对降维后的图像提取特征,使用SVM进行分类,基本实现步骤如下。 (2)对训练集利用PCA进行降维,通过训练集获得降维矩阵W,则有Xpca=WTX,其中Xpca表示降维后的训练集,对训练集进行归一化,利用PCA对测试集进行降维,有Ypca=WTY,其中Ypca表示降维后的测试集,对测试集进行归一化。 (3)利用降维后测试集相关信息,通过RSLDA提取有效信息,获得特征矩阵G,使用交替方向乘子法(alternating direction method of multipliers,ADMM)让变量在每一次迭代中逐步收敛,使子空间矩阵G达到最优解。 (4)通过特征矩阵G和降维后的训练集Xpca,有Xlow=GTXpca,其中Xlow表示特征提取后的训练集,并对其进行归一化处理。利用特征矩阵G和降维后的测试集Ypca,有Ylow=GTYpca,其中Ylow表示特征提取后的测试样本,并对其进行归一化处理。 (5)利用Xlow和Ylow的相关信息,利用SVM进行分类。 ORL人脸库是由40位受试者,每位受试者有10张图像组成。每张图像像素大小为112×92,其中人脸图像是拍摄于不同的时期,改变了灯光、面部表情和面部细节。所有图像都是在黑暗均匀背景下拍摄的,受试者一般处于正面位置[9]。图1展示了ORL人脸库中部分图像。 图1 ORL人脸库中部分图像Fig.1 Some images of the ORL face database COIL20物体库有20个物体对象,这20个物体抛弃了背景信息,每个物体在水平上旋转360°,每隔5°拍摄一张照片,有72张图像,每张图像像素大小为32×32[9]。图2展示了COIL20物体库中部分图像。 图2 COIL20物体库中部分图像Fig.2 Some images of the COIL20 object database 在UCI机器学习库中选择Breast、Congress、Heart、Tic-tac-toe、Vote 5个数据集中的子集。 YaleB人脸库包含了28岁以下,9种姿态,64种光照条件下的16 128张人脸图像。本次实验中,从YaleB人脸库选择一个子集,子集库中受试者38位,每位受试者有64张图像,每张图像像素大小为32×32[9]。图3分别展示了YaleB人脸库中原始图像和加入噪声密度为5%的椒盐噪声部分对比图像。 图3 YaleB人脸库部分原始图像和噪声图像Fig.3 Some original and image samples with noise of the YaleB face database 为验证本方法的识别率、识别效率以及鲁棒性,利用ORL人脸库、YaleB人脸库、COIL20物体库和UCI机器学习库中的部分图像集对LDA、RLDA、L1BLDA、RALDA、RSLDA和本文方法进行比较。在本次实验中,考虑到是随机选择的训练样本和测试样本组成训练集和测试集,存在随机性和差异性,使得识别率存在偏差,因此,在本次实验中,每种方法对每个图像集重复实验20次,取实验的平均值和标准差作为最终的结果,使结果更为合理,更有说服性[16]。所有实验都是在软件MATLAB2020a上实现的,采用i7-10875H处理器,内存为16 GB。 在ORL人脸库中有40位受试者,每位受试者10张样本。训练样本从2~9进行均匀变化,剩余的图像为相应的测试样本。考虑到在使用PCA时,维数不同,保留的主要信息也是不一样的,识别率也会不同,因此,在本次实验中,尽可能选择最佳维数下对应的识别率均值和标准差作为结果。LDA、RLDA、L1BLDA、RALDA、RSLDA和本文方法在ORL人脸库中的结果如图4所示。分析可知,这6种方法随着训练样本的增加识别率也在不断地提高,但不管训练样本为多少,本文方法的识别率在这6种方法中是最高的,充分说明本文方法的稳定性。 图4 ORL人脸库识别率随训练样本增减的变化Fig.4 Classification accuracy versus the training samples on the ORL face database 具体分析,当训练样本从2到9均匀增加时,本文方法的识别率依次为78.91%、86.75%、91.46%、94.35%、96.31%、97.29%、98.19%和99.13%,均值为92.80%。而LDA识别率的均值为67.10%,RLDA识别率的均值为89.33%,L1BLDA识别率的均值为91.34%,RALDA识别率的均值为91.43%,RSLDA识别率的均值为92.03%,本文方法识别率的均值是最高的,其中本文方法识别率的均值比LDA识别率的均值高25.00%以上,实验具体结果如表1所示。究其原因,建模过程中,LDA使用的是L2范数,RLDA和L1BLDA使用的是L1范数,RSLDA和RALDA使用的是L21范数。相比于L1范数和L2范数,本文方法利用L21范数使得同类样本的距离尽可能近而不同类别样本的距离尽可能远,因此,RSLDA、RALDA和本文方法的识别率明显高于LDA、RLDA和L1BLDA的识别率。利用稀疏矩阵N弥补噪声带来的影响,而RALDA方法中并没有该模块,因此,整体上RSLDA和本文方法的识别率高于RALDA。相比于RSLDA直接对高维图像向量进行特征提取,然后利用K最近邻(K-nearest neighbor, KNN)进行分类,本文方法通过PCA对高维图像向量进行降维,从高维图像中保留样本的主要特征信息,然后利用RSLDA对降维后的图像向量提取特征,最后通过SVM进行分类,本文方法先对高维图像向量通过PCA进行预处理,SVM的分类效果一般要好于KNN,因此,本文方法的识别率要高于RSLDA的识别率。从识别效率即识别所需时间分析,以秒作为计量单位,识别所需时间如表2所示。对比前提以识别率为主要参考因素,识别效率为次要因素。分析可知,相比于其他5种方法,LDA的识别效率虽然很快,但是根据表1所示,LDA的识别率相对较差,因此,不做比较。与余下的4种方法相比,本文方法的识别率和识别效率都提高不少,特别是与RSLDA的识别效率相比,本文方法的识别所需时间为其所需时间的1/1 000左右,更能说明本文方法的实用性。究其缘由,本文方法通过PCA对高维人脸图像进行降维处理,将高维图像投影到低维子空间中,在尽可能保留高维图像向量主要特征信息的同时减少计算的复杂程度,极大提高了识别效率。 表1 ORL人脸库中原始图像的识别率Table 1 The recognition rate of the original image on the ORL face database 表2 ORL人脸库中识别时间Table 2 Time of recognition on the ORL face database 在COIL20物体库中,每个物体对象有72张图像,训练样本从9均匀变化到54,间隔为9,剩余的样本为测试样本。本文方法识别率的均值为97.76%。LDA识别率的均值为89.91%,RLDA识别率的均值为96.96%,L1BLDA识别率的均值为96.84%,RALDA识别率的均值为97.54%,RSLDA识别率的均值为96.48%。具体实验结果如表3所示。当训练样本为18,维数从50均匀变化到120,间隔为10时,排除LDA,剩余5种方法识别率整体呈缓慢下降趋势,相比于其他4种方法,本文方法识别率受到维数变化的影响相对有限,识别率仍是最高的,6种方法识别率随维数变化情况如图5所示。本文方法通过PCA进行降维保留了高维图像的主要特征信息,同时RSLDA模型中又利用了PCA的变体即正交矩阵Q保留了降维后图像的主要特征信息,因此,本文方法受维数的影响不大。表4为6种方法在COIL20物体库中的识别所需时间,分析可知,LDA虽然识别效率高,但是识别率差,因此不做比较,相比于剩余4种方法识别效率,本文方法识别效率是最高的。 表3 COIL20库中原始图像的识别率Table 3 The recognition rate of the original image on the COIL20 database 表4 COIL20人脸库中识别时间Table 4 Time of recognition on the COIL20 database 图5 COIL20中识别率随着维数的变化Fig.5 Classification accuracy versus the number of dimensions on the COIL20 object database 在UCI机器学习库中选择Breast、Congress、Heart、Tic-tac-toe、Vote 5个数据集,由于所选择的类别为2个,数据量相对较少,且每一类别样本相对相似,不同类别的样本差异较大,因此,训练样本占总样本的比例对最终实验结果影响相对较低,实验具体结果如图6所示。 图6 Breast、Congress、Heart、Tic-tac-toe、Vote 5个库中识别率随着训练样本占比的变化Fig.6 Classification accuracy of Breast、Congress、Heart database changes with the proportion of training samples 在本实验中,将训练样本占总样本的比例从40%提高到90%的识别率作为实验结果。在Breast数据集中,本文方法的识别率为96.31%,高于其他五种方法,在Congress数据集中,本文方法的识别率为95.71%,比RSLDA高0.24%,在Heart数据集中,本文方法的识别率为80.08%,比LDA高1.48%,在Tic-tac-toe数据集中,本文方法的识别率为82.95%,比RLDA高10.1%,在Vote数据集中,本文方法的识别率为92.91%,比LDA高1.06%,实验结果如表5所示。 表5 Breast、Congress、Heart Tictac-toe和Vote 5个库中原始图像的识别率Table 5 The recognition rate of the original image on the Breast、Congress、Heart Tictac-toe and Vote database 在YaleB子集人脸库中,受试者38人,每位受试者有64个样本,随机选择8、16、24、32、40、48和56作为训练样本,剩余的样本作为测试样本,加入密度为5%的椒盐噪声的结果如表6所示。当训练样本从8均匀地变化到56时,本文方法的识别率依次为59.54%、75.92%、82.06%、85.25%、87.24%、89.08%和89.95%,均值为81.35%。比LDA识别率的均值高38.43%,比RLDA识别率的均值高26.83%,比L1BLDA识别率的均值高21.70%,比RALDA识别率1.37%,比RSLDA识别率的均值高15.32%,本文方法识别率的均值是唯一超过80%的。当图像存在噪声时,本文方法识别率的均值高于RSLDA识别率的均值,主要原因是RSLDA是直接对存在噪声的图像向量提取特征,而本文方法通过PCA对高维数据进行降维,在降维过程中利用PCA处理丢弃了大部分噪声信息,具体分析结果如图7和图8所示。图7模拟的是有噪声的图像,图8展示了经过PCA降维再回到原始图像。分析图8可知,在降维的过程中舍弃了大部分的噪声信息同时又保留了图像的主要特征。与LDA、RLDA、L1BLDA和RALDA相比,本文方法在每一次迭代中利用ADMM使得变量逐渐收敛,达到同类样本之间的距离较近,不同种类别之间的样本距离较远的目的,通过正交重构矩阵Q可以保留经过PCA预处理后的图像的主要有效信息,同时稀疏矩阵N拟合经过PCA降噪后少量噪声所带来的误差。 图7 噪声图像Fig.7 Noise image 图8 经PCA处理后的图像Fig.8 The image after PCA processing 表6 YaleB人脸库加椒盐噪声5%的识别率Table 6 The recognition rate of YaleB database with 5% salt-and-pepper noise 在图像识别中,本文方法使用PCA对高维图像进行降维。在特征提取过程中,使用L21范数使得同类样本之间的距离尽可能近,不同类别样本之间的距离尽可能远,使用正交矩阵Q保留降维后图像的主要特征信息,通过稀疏矩阵N弥补噪声造成的误差,最后利用SVM进行分类。将本文的方法和LDA、RLDA、L1BLDA、RALDA和RSLDA进行比较,得出如下结论。 (1)在ORL人脸库中,当训练样本从2到9均匀变化时,本文方法识别率的均值为92.80%,在COIL20库中,当训练样本从8到56均匀变化时,本文方法识别率的均值在91.83%以上,不管是人脸图像还是物体图像,本文方法识别率都高于其他5种方法识别率。 (2)在YaleB人脸库中添加5%的椒盐噪声时,本文方法识别率的均值为81.35%,本文方法的识别率均高于其他5种方法,说明本文方法的鲁棒性优于其他5种方法。 然而在复杂环境下获取的图像,但训练样本占总样本比例较少的情况下,本文方法的识别率较低,因此,后期考虑使用更好去噪的方法,这是以后研究的一个方向。
1.3 本文方法步骤
2 实验数据
2.1 原始图像


2.2 添加噪声的图像
3 实验结果与分析
3.1 原始图像的结果与分析




3.2 添加椒盐噪声图像的结果与分析

4 结论
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
科普童话·学霸日记(2022年1期)2022-05-30 10:48:04
海峡姐妹(2019年12期)2020-01-14 03:24:40
测控技术(2018年4期)2018-11-25 09:46:48
电信科学(2017年6期)2017-07-01 15:44:37
物流技术与应用(2017年3期)2017-05-17 05:29:04
数学年刊A辑(中文版)(2015年3期)2015-10-30 01:56:52
应用数学与计算数学学报(2014年3期)2014-09-26 12:03:56
计算物理(2014年1期)2014-03-11 17:00:18
