
提升电网调度中人工智能可用性的混合增强智能知识演化技术
2022-10-31 06:30姚建国杨胜春潘振宁李亚平张孝顺
电力系统自动化 2022年20期
姚建国,余 涛,杨胜春,潘振宁,李亚平,张孝顺
(1. 中国电力科学研究院有限公司(南京),江苏省南京市 210003;2. 华南理工大学电力学院,广东省广州市 510640;3. 东北大学佛山研究生院,广东省佛山市 528311)
0 引言
能源变革新形势下,中国电网的结构形态和商业模式正在经历深刻变化,电网调度运行面临的挑战愈发严峻:1)以风、光为代表的新能源和海量柔性负荷渗透率不断增加,调控对象发生变化,电网运行不确定性日益增加[1-2];2)气象、市场和社会因素对新能源和负荷预测误差影响愈发明显,电网实际运行与传统预测方法适用的运行条件偏差显著扩大[3-4];3)“源-网-荷-储”协同运行导致各层级电网调度数量呈指数级增加,监控信息爆发性增长,传统基于优化建模方法的计算实时性压力大,且可能难以得出结果,调度人员决策压力剧增[5-7];4)电力市场下多方主体利益博弈显著加剧了电网运行的不确定性[8],多方利益平衡和电力平衡交集空间变小,电力系统最优调度决策的复杂度急剧增加。传统电网调度模式难以适应上述挑战,电力行业对智能调度的需求愈加迫切。
人工智能(artificial intelligence,AI)技术为提升能源新变革下的智能化调控水平提供了新手段[9]。自20 世纪80 年代起,AI 技术已经历了第1 代和第2代2 个研究高潮。近10 年来,随着基础理论和算力的不断提升,以深度学习、强化学习为代表的AI 技术再次引起了广泛关注,尤其是在DeepMind 开发出AlphaGo 系列围棋机器人之后[10],更是掀起了不同科学领域的研究热潮,在电网调度,特别是智能决策领域也受到广泛关注。然而,在AI 技术应用于各时间尺度调度决策的研究如火如荼开展的同时,却鲜有在实际工程中应用的案例,距离实现具有完全自主决策能力的智能调度依然任重道远。造成AI技术在实际中“不敢用”的根本原因包括泛化性不足、解释性缺失、复杂约束下的决策可行性存疑、收敛性不佳等问题。
作为中国新一代AI 规划五大技术方向之一,混合增强智能(hybrid-augmented intelligence,HI)被视为解决当前AI 技术缺陷的重要方法。混合增强智能的关键特性是将人的作用或人的认知模型引入AI 系统中,与机器智能共同形成混合增强智能的形态,这种形态是AI 或机器智能可行的、重要的成长模式[11]。混合增强智能具有数据与知识的双重驱动特征,能充分利用人类大脑与机器智能之间互补关系实现机器知识的演化增强,可有效解决传统AI解释性差、泛化性弱等问题[12]。混合增强智能调度是将混合增强智能应用至电网调度领域而形成的一个新的调度模式。其关键特征是要充分融合“人”和“机”两者的知识,从第2 代AI 的“数据驱动”为主提升到新一代AI 的“数据+知识双驱动”。但是,目前各领域对于混合增强智能的研究仍处于起步阶段。文献[13]通过引入人在回路的混合增强智能,提升了Sawyer 机器人在非结构化环境下决策性能。文献[14]从人机交互模式、态势感知、人机协同决策等角度阐述了面向集群自主系统的人机混合增强智能研究进展,明确了通过人机混合增强智能可以显著提升AI 认知能力,减轻基于AI 的控制决策技术不成熟带来的风险。文献[15]提出基于混合增强智能的知识图谱推理方法,结果证实了人的知识可以有效地指导模型的优化,从而提升大规模知识图谱的推理效率。但是,在电力调度领域,关于混合增强智能的研究还很少,未见有研究剖析实现混合增强智能调度决策的关键技术。
基于此,本文将首先分析当前AI 技术在电网调度决策中应用的现状;其次,研究实现混合增强智能的关键理论,将其归纳为“人机知识协同演化”;再次,分析实现混合增强智能调度人机知识演化解决的关键问题,并尝试提出求解思路和实现方法。
1 AI 技术在电网调度决策中应用的现状分析
传统的数学解析方法因其收敛性强、计算结果稳定、求解过程与结果可解释的优点,近几十年来已在电网调度决策中得到深度应用。对于常规的确定性调度优化问题,没必要应用AI 技术替代传统解析化方法,例如,常规的机组组合、经济调度、最优潮流等问题。这类问题的特点是模型明确、机理明晰、决策变量维数大且须满足运行约束,可采用成熟的凸优化算法或混合整数优化算法轻松求解,而AI 方法即使大费周章也难以获得与之媲美的计算结果。但是,在能源变革背景下,风光强随机性、信息物理社会因素的复杂交互[8]、能源网络的紧密耦合将给常规电网调度问题引入大量不确定性和机理不清晰的部分。此时,依赖于精确模型和参数的传统解析方法并不能很好地适应上述转变。同时,调控变量维度的增加、非线性非凸目标函数/约束的加入,导致传统方法的决策实时性存疑。
作为一种基于历史经验学习而不依赖于模型的数据驱动方法,以强化学习为代表的AI 决策技术更加适合求解机理不清晰、系统状态变化不确定、具有非凸目标函数/约束的决策问题的最优策略。近年来,AI 技术已应用在新形势下的机组组合[16]、经济调度[17]、最优潮流[18]、自动发电控制[19]、拓扑优化[20]等不同尺度的调控问题上。大量算例验证了和传统方法相比,AI 技术在求解复杂调控问题的适应性、在线决策效率、长时间序列的策略最优性上具有明显优势[21]。这是因为AI 技术通过无模型的算法处理,避免了对于底层物理模型的建模,同时在离线学习阶段通过大量样本挖掘最优策略并存储于价值网络(矩阵)/策略网络(矩阵)中,在线决策时则根据系统实时状态快速给出最优决策,从而省去了在线寻优的过程[22]。
从理论框架和算例支撑上来说,在新型电力系统的调控决策中,当前的AI 技术似乎能够很好地取代传统解析化方法。然而实际上,当前AI 应用于调控决策的研究仍停留于实验室理论研究层面,几乎没有真正参与电网调控自主决策的落地应用案例。目前,主流研究仍停留于验证电网调度领域中AI 技术代替传统方法的可行性,却忽视了阻止当前AI 技术在电网调度中实际可用的技术瓶颈和难点。造成当前AI 技术“不敢用”的原因可以归纳为以下5 点。
1)对于训练环境及样本的依赖性:目前,绝大多数研究都基于理想假设,即有完善的虚拟仿真环境能够准确模拟真实物理系统的反馈,同时具有充足的样本能够反映系统动态。然而,实际工程中该条件并不能够完全满足,因此算法需要具备在小样本环境下的收敛和学习能力。
2)复杂约束下决策可行性存疑:电网调度决策必须满足安全约束,而传统无模型的AI 方法难以在机理上保证决策满足复杂的约束条件。因此,如何在原理上提升AI 决策的安全性是实现相关技术落地应用必须解决的问题。
3)泛化性和拓展性弱:目前,绝大多数研究中算法的性能取决于训练环境/样本与测试环境/样本的一致性。在实际中,电网运维计划的差异将导致电力系统结构和运行目标发生变化,然而,当前的AI算法对于差异性环境的泛化和拓展能力仍有待提升。
4)可解释性差:与传统解析化方法不同,当前AI 的“黑箱”结构让运行人员难以厘清其决策逻辑,决策过程难以令人信服。
5)收敛性和最优性存疑:当前,AI 算法的策略寻优很大程度上依赖于探索和试错过程,在大规模问题求解时存在耗时长且收敛性差的问题,现有的电网调度理论和模型知识无法对该过程进行指导。
因此,解决上述研究难点是突破当前AI 技术在调度领域应用瓶颈的关键。而本文提出的混合增强智能调度,通过引入人的作用或认知至机器智能中,为解决上述问题提供了一种可行方案。
2 混合增强智能调度知识演化的内涵及关键问题
混合增强智能调度的关键特征就是要充分融合“人(调度员/运行人员)”和“机(AI 调度软件)”两者的知识,调度员智能和机器智能的协同是贯穿始终的。具体而言,一方面,通过调度员丰富的经验和理论知识干预机器智能,提升传统AI 算法寻优效率低、难以收敛、决策安全性存疑等问题;另一方面,通过AI 对于未知系统状态的探索,找到调度员难以发觉但又影响电力系统安全经济运行的系统状态和策略,并通过对AI 决策进行揭示,从而扩展调度员的知识认知。最终,通过人与机的协同交互,促进知识的不断演化,以适应随机复杂性日益增强的电力系统动态运行环境。
实现混合增强智能调度需要解决诸多理论和技术问题,而研究面向混合增强智能调度的知识演化理论,进而实现人机知识协同演化,使机器能以人的思维模式和知识结构进行分析、理解和决策,消弭当前AI 技术在电网调度可用性的瓶颈,是实现混合增强智能的关键。因此,厘清知识演化的方向、目标、途径和实现方法是实现混合增强智能调度的关键和基础。
本文将知识演化的内涵分解为“知识转化”和“知识进化”2 个层面。如图1 所示,知识转化负责打通人与机之间的双向理解通道。在“人到机”方面,通过调度规程和人工经验对机器学习的方向进行引导和规制,提升机器学习的效率和效果。在“机到人”方面,则是把机器智能隐性不可读知识转为调度员理解的显性可解释知识。知识进化则表示人类和机器的智能能够随外界客观环境或者电网运行环境的变化而进化,从而提升算法的泛化性,主要包括2 个方面,一方面是知识能够适应电网空间维度变化(例如电网规模、拓扑变化)而进化,另一方面适应电网运行方式在时间维度上的变化。

图1 混合增强智能调度的知识演化内涵Fig.1 Connotation of knowledge evolution of hybridaugmented intelligence based dispatch
根据以上阐述的面向混合增强智能调度知识演化的内涵,总结提炼出实现混合增强智能调度需解决的2 个关键问题。
第1 个关键问题是“如何实现多源调度知识的转化?”知识转化包含2 个层面的过程:一是如何将调度规程、调度员经验等知识转化为机器学习可利用的知识,如何将调度大数据转化为机器学习知识;二是如何将机器学习知识转化为调度员可理解的知识。
第2 个关键问题是“如何实现机器学习知识的持续进化?”由于电网是持续演变的系统,调度场景及需求也随着电网时空维度的变化而改变,仅利用历史数据训练的机器智能无法对新场景或极端场景给出针对性的决策,因此,要求机器智能随时更新以匹配电网及调度需求的变化。为此,如何应用调度员经验和仿真系统来促进知识持续进化并发现新知识,提升算法的泛化性就成为其中的关键。
3 混合增强智能调度知识演化的关键技术
为解决上述实现混合增强智能调度的关键问题,本文尝试提出以下4 项关键技术开展研究工作,概括为“一个架构、二个通道、一个推理机制”。“一个架构”,即需要构建支撑混合增强智能调度的知识架构,提供知识演化的基础;“二个通道”,即分别打通人对机、机对人的信息和知识传递的双向通道,形成知识演化的途径;“一个推理机制”,即建立人和机共融的知识推理和协同决策机制,促进知识的更新。从知识工程角度看,上述4 项关键技术也分别对应知识架构、知识获取、知识解释和知识推理等4 个部分。
3.1 混合增强智能调度的知识演化关键技术概述
1)知识架构。本文把混合增强智能调度的知识表示与计算架构合并称为“知识架构”。知识表示技术就是提出适应混合增强智能的电网调度知识库构建方法,实现模型、规程等人类调度决策先验知识与通过机器数据挖掘发现的隐性知识的分类存储、准确调用和自动更新。计算架构则是形成一个能驱动整个调度过程实现复杂计算和知识转化的计算流程框架,合适的计算架构有利于促进人和机器知识的共同演化。
2)知识获取。电网调度是一个复杂的优化决策问题,机器学习若采用纯粹基于数据驱动的方式直接进行应用,则将导致较低的学习效率和较差的学习效果。因此,将调度员已有的专业知识和经验融入到机器学习中,引导机器学习的规则和方向,将明显提高其学习效率及效果。然而,调度专业存在海量、多源、异构的知识,跨越历史、现在和未来各时间维度,知识体量十分庞大。如何利用调度员经验自动引导机器智能,实现调度领域知识获取及新知识发现,是促成混合增强智能调度自主知识演化的关键瓶颈技术之一。
3)知识解释。虽然以数据驱动的机器决策结果具有较高的准确性,但倘若人类调度员无法理解机器决策的逻辑,即使“黑箱”非常聪明,人机共融的协同决策也无法有效实施。另外,针对机器智能决策过程和决策结果的知识解释技术,也给调度员启发和创造新知识提供了途径,这也是促成知识演化、诞生新知识的又一个关键技术。
4)知识推理。混合增强智能的人机协同决策的实质有2 层含义:其一,是实现对电网各类实际调度场景的智能决策,这是常规AI 系统中的知识推理过程,实现对已有知识的高效利用,提升算法的泛化性;其二,研究人机共融的协同决策机制和算法,提升调度决策的安全性和置信度,以满足运行工况多变、场景复杂的电力系统调控需求,推动机器智能知识随物理系统变化而持续演化。
上述4 项关键技术中,知识架构是后续研究的基础;知识获取和知识解释的结果互为输入,构建了人机知识交流的通道,回答了第1 个问题“如何实现多源调度知识的转化?”,同时也为知识推理提供了基础;知识获取和知识推理则回答了第2 个问题“如何实现知识的持续进化”?
3.2 混合增强智能调度的知识表示与计算架构
3.2.1 混合增强智能调度的知识表示方法
作为电网运行控制的指挥中枢,电网调度中心在长期的运行中积累了大量数据,包括电网模型、海量运行数据和调度规程、故障预案、调度日志等文本数据[23]。然而,当前调度领域的知识一般采用符号化(如物理模型)、文本化(如调度规程)的表示方式,而机器学习技术是数据驱动的,造成调度中心积累的经验知识无法直接为机器学习算法采用。从利于AI 学习和知识获取的角度,可尝试按照数据驱动知识、可解释性知识和规则引导知识3 个维度对电网调度知识分类,这3 类知识既可能显性存在于调度运行理论、调度规程中,也可能隐性存在于调度案例或调度员经验中。其次,综合模(分析模型)、图(知识图谱)[24]、树(决策树)、网(神经网络)等多种技术手段,对电网调度知识进行表示。
图2 归纳整理了混合增强调度各类知识的分类和表示方法。涉及的主要数据类型包括结构化数据和非结构化数据。非结构化数据主要用于机器学习设计、知识获取引导;结构化数据主要用于机器学习训练,以形成机器知识。具体来说,调度规程是文本数据,同时也涵盖了调度需求和已有调度知识,例如调度任务的调度目标、调度设备及优先级、调度约束及优先级。电网状态特征与决策方案均为结构化数据。可将电网状态特征与决策方案的映射关系(实质上为强化学习中的值函数或策略函数)定义为数据驱动知识。以日内有功经济调度为例,电网运行状态可为电网拓扑结构、负荷、潮流、机组调节特性等数据,决策方案为机组的优化出力数据。

图2 基于混合增强智能的电网调度的知识表示与存储Fig.2 Knowledge representation and storage for hybridaugmented intelligence based power grid dispatch
3.2.2 混合增强智能调度的计算架构
图3 对比了混合增强智能调度计算架构与传统调度计算架构。传统调度计划主要依据安全约束机组组合、安全约束经济调度进行优化计算,确定机组开停机和出力,但由于新能源和负荷预测不准确等问题,依靠建模优化的方法可能存在决策结果与电网实际运行不匹配的情况,需要调度员频繁进行人工干预。混合增强智能调度计算架构则采用知识和数据联合驱动,构建包含电网外部环境、调度决策对象、调度员和机器智能的小型生态环境,根据现有的调度运行理论、调度规程进行引导,基于来自实际电网和动态仿真系统[25]模拟生成的样本数据,以调度员和机器学习为调度决策核心,通过各环节之间的信息交互、闭环计算,促进调度决策知识生成与演化,并以此为基础进行决策知识的可解释性分析和决策方案的生成与评价。

图3 混合增强智能调度计算架构与传统调度计算架构对比Fig.3 Comparison between computing architectures of hybrid-augmented intelligence dispatch and traditional dispatch
3.3 混合增强智能调度的知识获取方法
与传统AI 不同,混合增强智能调度的知识获取方法包含以下3 个层面:一是调度运行理论及调度规程引导下的机器学习先验知识获取,强调的是如何利用先验知识,形成引导机器学习的基本规则;二是调度员干预引导下的机器学习知识获取方法,强调的是如何利用人工经验干预引导机器学习过程,提升学习效率;三是基于多源数据的机器学习方法,强调的是机器学习如何通过对于样本的学习,形成机器智能。
在实际使用中,层面1 主要关注机器学习先验知识获取,已有调度运行理论及调度规程主要提供调控任务的固定因果关系、调控目标及约束等引导规则,其中,固定因果关系用于压缩机器学习动作空间,调控目标及约束用于构建机器学习奖励函数;层面2 与层面1 使用方式一样,主要利用调度员已有经验校正机器学习动作及奖励函数,为提高实际使用的引导效率,需对调度员经验进行定量或定性的数学建模,实现自动引导;层面3 与一般的机器学习实际使用过程一样,只是利用真实历史数据和仿真器生成数据对其训练数据进行扩展,进而提高知识获取的可靠性和泛化性。层面1 和层面2 共同产生引导规则库,引导机器学习知识获取过程中的动作空间设计、动作选择、奖励函数构建;层面3 主要负责训练数据扩展和生成,为机器学习知识获取提供数据样本。
3.3.1 调度运行理论及调度规程引导下的机器学习先验知识获取方法
首先,为形成调度规则知识,本文借鉴文献[24]构建的智能调控领域知识图谱框架,进一步以机器学习理解和利用为导向,分别从数据选择、数据处理、知识抽取以及知识模型等过程,构建调度运行理论及调度规程的调度知识图谱。
在数据选择方面,整理与调度相关的电力专业词库及电力知识等半结构化数据,整理与调度相关的调度规程等非结构化数据;在数据处理方面,先对半结构化数据及非结构数据进行预处理,然后针对其中一部分样本采用现行标准的BIOES(B 表示begin,I 表示inside,O 表示outside,E 表示end,S 表示single)规范对实体和关系进行人工标记,剩余数据采用数据增强工具进行自动标记;在知识抽取方面,针对不同输入类型的标记数据分别采用基于规则和深度学习方法提取实体和关系。其中,基于规则的知识抽取采用中文分词工具和正则表达式实现;基于深度学习的知识抽取可利用语义识别技术将文本转化为词向量,将词向量作为输入,使用神经网络等方法实现实体及关系标签[26];在知识模型方面,利用余弦相似度等方法将识别出来的实体和关系进行知识融合。然后,对知识进行表示和存储,分别存储关系类知识和属性类知识。
在构建调度知识图谱后,即可利用实体之间的属性关系对机器学习进行引导。以附录A 图A1 给出的调度知识图谱示例,图谱包含4 类实体:状态分类、目标分类、约束分类、调度规则,实体之间存在调度运行理论与调度规程已有的映射或关系信息。知识图谱在使用时,先根据当前调控任务状态作为查询输入,确定对应的状态分类实体,从而寻找到对应目标分类、调度规则、约束分类,目标分类可提供调控目标,调度规则实体可提供调控变量优先级,约束分类实体可提供调控变量边界信息,最终形成可引导机器学习知识获取的奖励函数评价依据、动作设计及选择依据。
1)实体“感知状态”与“目标分类”之间的属性关系s→f,可为机器学习寻优目标进行引导,其中s与f分别为系统状态向量和目标函数值。
2)实体“目标分类”与“约束分类”之间的属性关系f→{G,H },可为机器学习寻优空间进行约束,其中G、H 分别为不等式和等式约束集合。
3)实体“调度规则”可为机器学习提供寻优方向,以系统发电煤耗最小目标为例,其调度规则为优先调度煤耗低的机组。
4)实体“选择调控设备”可为机器学习算法压缩寻优空间,表示如下:
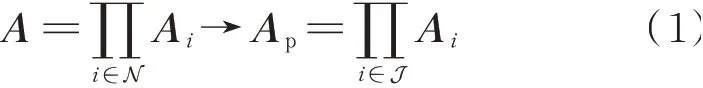
式中:A为机器学习算法的动作空间;N 为可控设备构成的集合;Ai为机器学习算法中可控设备i原有的决策动作空间;Ap为引导机器学习算法后的动作决策空间;J 为针对决策目标的主要控制设备集合。
5)实体“调度方案评价”可辅助机器学习算法设计奖励函数,即(s,a)→R,其中a为算法的动作向量;R为奖励函数。
利用调度知识图谱的引导信息,基于实际系统调度大数据,即可生成机器学习的先验知识。以常见的深度Q 学习算法为例,其数据驱动知识以网络参数向量θ存储于深度强化学习的值函数网络中。其中,第k次迭代的参数向量θk计算方式如下[27]:
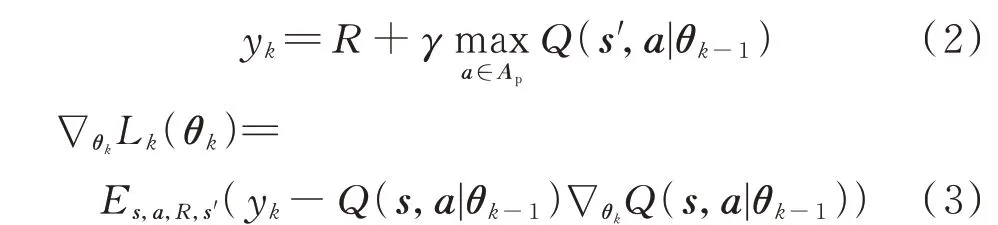
式中:yk为第k次迭代时Q 值网络的目标值;Q(·)为Q 值网络函数;s'为系统下一状态的向量;γ为折扣因子;∇θk为针对θk的梯度算子;Lk(·)为第k次迭代时Q 值网络的损失函数;Es,a,R,s'(·)为针对s、a、R和s'的期望算子,不同状态向量s下算法可根据知识图谱调度规则选择动作向量a进行优先探索。
奖励函数R直接与知识图谱中实体“目标分类”与“约束分类”相关,一般采用目标函数f加上约束罚函数M的形式,如下所示。

式中:M为系统调度约束越限惩罚项,越限偏差越大,惩罚则越大。
3.3.2 调度员经验干预引导下的机器学习知识获取方法
除了根据调度运行理论和规程引导机器学习外,调度员也可根据自身经验,干预和引导机器学习过程。典型的干预和引导手段有动作空间引导、奖励函数引导、示范决策等。
1)动作空间引导:调度员可根据状态量或目标值与决策动作量之间的关系,形成调度员对机器学习的决策方案干预知识,从而引导机器学习动作的正确选择。其中,对于可定性描述的关系,可对某些调度设备的动作空间进行引导,如下所示。

对于可定量描述的关系,例如式(8)给定的某些控制量与状态量之间的定量数学关系(例如线性相关),调度员可引导机器学习降低调度决策的难度和复杂度,可进一步细化具体的动作值,提高决策精度。

式中:gj(x)为状态变量sj与决策向量x之间的定量关系函数;ωij为第i个可控变量xi与第j个状态变量sj之间的线性相关权重值。
对于式(7)和式(8)给出的动作引导,可直接作用于机器学习知识获取中的寻优动作空间和动作选择,并按式(2)和式(3)同样的方式进行知识获取。
2)奖励函数调整:当调度员认为机器选择的决策目标不当或各目标权重不合适时,可以对机器决策目标进行调整。

式中:x0、F0和ω0分别为上一次机器决策采用的决策向量、决策目标向量及各目标的权重向量;F、ω分别为调度员偏好的目标向量及权重向量;hT为调度员的选择过程。
3)示范决策:当调度员认为机器决策效果利用价值不高时,可采取示范决策的方法。调度员根据经验直接给定一个或一组示范决策,由机器在这些决策附近寻优,利用人类经验直觉的同时又可进一步提高决策效果。
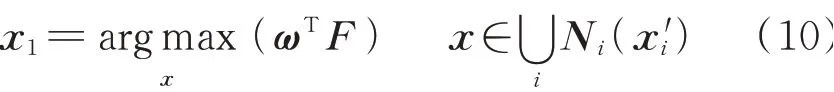
式中:x1为新的决策向量;x'i为调度员给定的第i个示范决策向量;Ni(x'i)为x'i的邻域,具体形式由调度员指定。示范决策可与动作空间引导方式相结合,调度员只需给出部分决策变量值即可。
3.3.3 基于多源数据的机器学习方法
机器学习需要大量的场景和数据样本进行离线训练以获取知识。虽然历史调度数据可提供部分数据来源,但由于电力系统的结构和规模在持续发生变化,导致有效数据数量少、样本效率低等问题。为解决该问题,除了采用现有的调度数据外,还将通过生成随机环境下的虚拟数据样本,用来训练机器学习,使其获取随机环境下“源-网-荷-储”协同的调度数据驱动知识。
本文提出的基于多源数据的机器学习知识获取架构如图4 所示。包含以下部分:首先,根据调度理论和规程获取先验知识,同时调度员可以干预机器学习过程;其次,可基于生成对抗网络[28](generative adversarial network,GAN)扩展未来调度场景数据,并汇聚历史调度数据和决策案例,共同形成训练数据源;最后,采用深度强化学习算法从训练数据源中获取知识,利用历史及未来调度数据提高机器学习知识的泛化性。除此之外,混合增强调度的机器学习还需解决传统机器学习方法求解大规模复杂电力系统调度问题时可能遇到的问题主要包括高维连续的状态动作空间下导致策略寻优产生的“维数灾难”问题、样本类别不平衡、系统部分状态无法测度导致学习性能下降等[21]。

图4 基于多源数据的机器学习知识获取架构Fig.4 Knowledge acquisition architecture of machine learning based on multi-source data
3.4 混合增强智能调度的知识解释方法
调度过程中,机对人的可解释人工智能技术包括2 个方面:一是“增强过程”可解释性;二是“增强结果”可解释性。其中,过程可解释主要是为深度强化学习方法设计通用可解释性接口,为调度员提供知识获取方法的调试工具,帮助其以调度决策的角度进行知识获取过程推演,实现对调度决策的干预;结果可解释基于决策变量与决策结果的关系,研究基于灵敏度与多维指标融合的电网调度决策结果可解释方法,帮助调度员理解当前调度案例以及未来调度场景案例数据中的决策结果与决策变量的关系。
3.4.1 基于知识获取过程的可解释性方法
此部分研究将构造机器学习方法与电网调度员之间的通用可解释性接口,帮助调度员了解知识生成过程。当机器学习结果获得了一个与调度员认知相悖的结果时,可解释性接口通过一个简单且可解释的模型实现知识获取过程对调度过程的映射,调度员利用上述模型给出的调度过程进行人工调试,最终了解知识获取的机器学习训练过程,并能够进一步根据对知识获取过程的理解进行调度决策干预。
本文给出了可解释性接口的一种可行形成方法,如附录A 图A2 所示。在知识获取的同时,训练一个准确率高与复杂度小的决策树[29],使形成的决策树与知识生成的过程形成严格映射。一种可行的方式为,决策树在某状态节点下的决策动作选择对应电网某节点状态下,该节点调度动作大概操作范围。由此,调度员可以通过决策树对知识获取过程进行人工调试。除此之外,引入正则化方法,惩罚深度强化学习训练过程中与调度结果不相关的特征,从而获得对结果影响大的稀疏特征,便于调度员理解。大致过程可表述如下:在知识生成的同时训练决策树,决策树的输入为深度强化学习方法训练过程中的第l部分的权重ωl,输出为ωl与电网状态及决策动作产生的关联函数值Ω(ωl),通过最小化关联函数值的误差和最小化决策树的复杂度(求解式(11))来实现知识生成及演化过程的决策树表示。

式中:Ω̂(ωl)为所有关联函数值Ω(ωl)的平均值;L为深度强化学习方法需训练部分的总数量;IAPL,l为第l部分决策树的平均路径长度,即某一节点选择不同的树枝后平均经过的节点数,其中节点为电网状态,树枝为电网调度决策的动作;λ为权重系数。
3.4.2 基于机器智能调度决策结果的可解释性方法
研究复杂随机电网调度场景下机器决策结果的可解释评价方法,有助于调度员量化机器决策结果的好坏,理解机器决策的内在逻辑。如图5 所示,本文认为可采用灵敏度分析和相关性分析法开展机器决策结果可解释性研究。灵敏度分析和相关性分析是从2 个不同的角度反映决策结果与决策变量的关系,灵敏度分析反映了决策变量对决策结果的重要性,相关性分析反映了决策变量对决策结果的影响力。
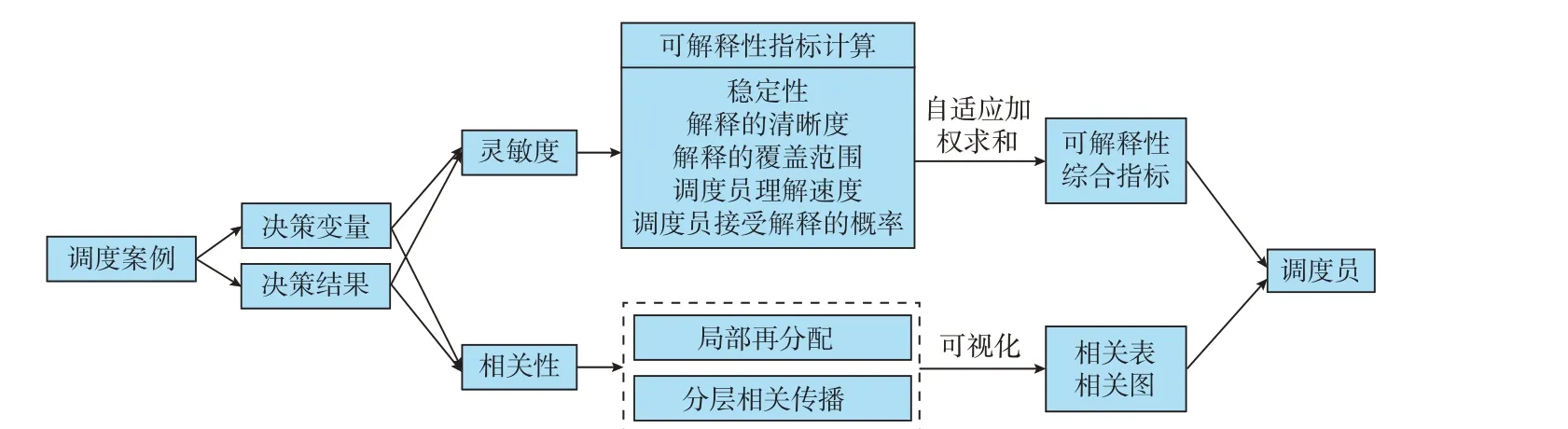
图5 基于可解释性指标与相关性可视化的调度案例结果可解释方法Fig.5 Interpretable method for dispatch case results based on interpretability index and visualization of correlations
灵敏度分析作为最简单决策结果分析工具,通过对数据或者场景施加人为扰动,判断模型的行为或预测结果是否仍然稳定。除灵敏度指标外,本文还提出多种可解释性指标,为调度员提供关于决策结果可解释性的显式表达,包括:灵敏度稳定性、解释的清晰度、解释的覆盖范围、调度员理解速度、调度员接受解释的概率。
灵敏度稳定性反映了当数据或者场景发生大小为ΔD的改变后灵敏度S的平均变化量。如果在数据或者场景发生改变后,决策结果仍然表现稳定,那么稳定性分析就可以提高调度员对模型的信任。
解释的清晰度与灵敏度在区分重要变量方面的能力有关。计算各个决策变量xi对决策结果的灵敏度Si的方差V(Si),若方差越小则各个灵敏度差别越小,说明区分重要变量的能力越弱,则解释的清晰度越低。解释的清晰度与上述方差正相关。
解释的覆盖范围与大于设定灵敏度阈值的决策变量和中间变量的数量占变量总数的比值有关。设定灵敏度阈值为ε,若Si<ε,则认为xi对决策结果的影响很小或者无影响。
调度员理解速度与调度员工作状态、调度员的知识经验、调度决策模型的可解释性和灵敏度分析结果等因素有关,难以量化,因此,通过先初始化再在线统计的方式进行衡量。划分理解用时区间,用时越少评分越高。调度员接受解释的概率也难以量化,因此通过先初始化再在线统计的方式进行衡量。假设m次统计有m'次接受解释,每一次调度决策在线更新m和m'。调度员接受解释的概率指标IPAI的计算公式如下。

除灵敏度指标外,还可引入相关性分析量化决策变量对决策结果的影响力,为调度员提供可视化的相关性分析结果。首先,计算决策变量与决策结果的相关系数。其次,引入分层相关传播(layerwise relevance propagation,LRP)技 术[30]将 相 关 系数由决策结果往决策变量进行逐层重新分配,并对每一层的变量对决策结果的相关性进行局部再分配,从而运行人员能够掌握每一个决策变量与中间变量对决策结果的贡献大小。最后,引入相关表和相关图对电力调度决策变量及中间变量对决策结果的相关性进行可视化表示。上述过程中,LRP 技术使用局部再分配规则[30]将总相关性向后重新分配,直到为每个决策变量和中间变量分配一个相关性评分。LRP 技术能够解释调度决策的全过程,结合相关表和相关图的可视化技术使运行人员对机器决策结果有一个全面直观的掌握,从而提高调度员对调度决策结果的理解和信任。值得一提的是,机器学习的严格可解释方法具有相当的研究难度,但本文按照调度员习惯的工程化方法对其进行了一定的简化,保证了此部分研究的可行性。
3.5 混合增强智能调度的知识推理方法
由于电网是持续演变的系统,调度场景及需求也随着电网时空维度的变化而改变,由上述方法得到的机器智能在实际应用中,难以对未知或极端场景给出针对性的决策方案。因此,需要研究知识推理方法,在先验知识的基础上,推断出未知场景的知识。混合增强智能调度知识推理方法通过引入人机共融的协同决策机制,提升现有知识的泛化性,实现对复杂场景的高置信度决策,进而推动系统知识随着电网环境变化而持续演化。此部分的研究可从以下两方面开展:一方面,研究复杂环境下的机器决策方法,目的是尽可能地提升机器决策质量和安全性;另一方面,研究人机共融的决策机制,旨在通过调度员的经验改善决策质量,保障电网安全。
3.5.1 基于电网关键特征感知的分区决策技术
要实现人机共融的知识推理过程,首先要解决机器调度复杂随机场景下的决策问题,实现对已有知识的高效利用。这就要求机器能够基于先验知识,推断出新状态下的机器最优决策。值得注意的是,这里的新状态指的是由于电网结构的持续演变和调度需求变化,导致机器先前获取的知识难以直接应用。附录A 图A3 给出了基于关键状态特征感知的电网调度分区决策技术的一种实现思路,包含2 个关键特征,即关键状态特征感知和分区决策。
首先,大电网实时采集数据普遍存在高维度且低密度的问题,难以准确反映电网当前的运行状态及未来的状态转移,继而难以得到调度任务的决策依据,导致机器决策能力不足。与传统的电网状态估计和感知不同,关键特征感知不仅根据运行数据获取电网的运行状态,更是要对影响决策的关键系统特征进行感知和判断,例如:系统关键运行断面情况、未来可能出现的负荷高峰情况等。本文提出构建基于注意力模型[31]的电网关键状态特征感知框架,将运行数据、负荷/清洁能源出力预测结果、网络拓扑、机组参数等电网状态作为输入序列,输出序列为更加抽象的电网状态表征结果,此结果将作为机器调度的决策依据。在注意力模型的具体设计上,如基于长短时记忆(long short-time memory,LSTM)网络的编码网络架构设计,注意力的权重系数如何自适应求取,解码网络架构设计等,都要根据实际问题分析,也是后续研究的一个重点。
其次,注意力模型得到电网状态感知结果后,倘若知识库中包含当前状态和决策结果的先验映射知识,则可直接依据先验知识得到调度决策。但由于电力系统自身结构和状态的不断演化,实际运行中存在先验知识无法覆盖当前决策任务的情形,此时便涉及电网面对新状态如何快速地进行推理决策的问题。为此,本文提出分区决策技术,其核心是将复杂的系统状态按区域分解,再根据各分区状态,采用迁移学习[32]等技术确定各分区的近似最优决策,最后将决策重组得到当前状态下的最优决策。
上述研究内容可实现未知电网状态的快速机器决策,但此决策并未经过先验知识的检验和电网的安全校核,并不一定是当前状态下的最优决策;同时,决策的安全性和鲁棒性尚存疑。因此,还需要引入人机协调机制,通过人机共融决策,确保得到新状态下的可行决策。
3.5.2 人机共融决策机制
对于复杂多变的决策问题,机器策略难以保证最优性,仍存在改进空间。人类专家可以根据自身经验指出策略改进方向,即广义上的策略梯度方向,通过迭代交互改善决策结果的同时帮助机器提升决策能力。本文提出研究人机决策协调机制的思路:1)基于多维指标融合,研究包含调度员偏好在内的调度决策置信度事前评价方法;2)基于评价结果,研究人机协调决策机制,通过人对机器决策理解评价和引导示范的迭代,实现调度策略的调整与改进,并推动机器智能知识不断向增强梯度方向演化;3)利用人机共融决策结果和系统实际运行效果构造参考策略和价值网络,通过比较对机器策略进行评价以指导机器策略的改进。
一种可行的人机共融决策机制如图6 所示。

图6 人机共融决策机制Fig.6 Human-machine integration decision-making mechanism
在得到机器决策结果之后,首先要对其可用度进行分析,此时考虑的指标包括反映系统运行情况的客观性指标和反映调度员评价的主观性指标。其中,客观性指标可采用新一代调度控制系统[25]中使用的指标,包括系统实时运行指标,如系统安全性指标、系统经济性指标、清洁低碳指标等,此类系统运行指标可通过数字仿真系统得到。另外,电网运行后评价指标也可纳入决策评价体系,但由于此类指标需要所有日内调度任务完成后才能定量得到,可采用监督学习的方法对历史决策数据和指标数据进行拟合,进而得到相关指标的估计值。反映主观性的指标来源于调度员的评价。为实现快速的人机交互,得到简明清晰的决策置信度指标是非常必要的。因上述指标都是低维且可量化,本文推荐采用线性加权法得到决策的置信度指标,各指标的相关权重值可根据调度员偏好确定,也可采用自适应加和法、隶属度法、灰色关联度法等成熟方法来确定。
得到决策置信度的量化指标后,可根据知识库中是否存在先验知识、决策置信度指标高低、调度员是否认可等因素将决策分为可用决策和不可用决策,具体的划分手段可用直接定量划分或采用模糊分类/聚类等方法。对于不同置信度的决策将采取不同的人机协调方法,具体描述如下。
1)可用决策:知识库中存在先验知识或决策置信度指标较高,调度员认可。为提升决策效率,此类决策不需要人工干预,可直接作用电力系统。
2)不可用决策:知识库中不存在先验知识、决策置信度指标偏低,调度员不认可,此类决策并不可直接作用于电力系统。
对于不可用的决策,调度员可结合机器决策的解释结果,采用多种手段对决策进行干预和引导,这里仍可采用3.2.2 节提到的动作限定引导、目标调整和示范决策等3 种方式。
人机共融决策的目的除了提升针对单次决策的最终效果之外,还要为知识库中机器策略的改进提供参考。此部分内容得到的机器决策、人机共融决策结果、调度员干预过程和策略评价将作为实际系统的运行样本、人工干预知识和实际系统的运行评价,为知识演化提供现实依据和支撑。随着系统的持续运行,知识库的先验知识将持续扩充与完善,机器调度决策的置信度也将不断提升,调度员的干预率会持续下降,最终实现混合增强智能调度中以机器决策为主、调度员干预和引导为辅的调度模式。
4 结语
针对由于当前电网调度领域AI 方法技术缺陷引起的实用性不足问题,本文提出基于混合增强智能调度的解决思路,提炼了其关键问题——面向电网调度的混合增强智能知识演化机理与方法,探讨了其内涵,提出并阐述了知识架构、知识获取、知识解释及知识推理4 个关键技术的框架和解决思路,尝试将机器智能强大的搜索、计算、优化能力与调度员的高级认知能力交互融合,实现人机双向的知识交互和共同演化,达到提升电力调度智能决策水平的目的。混合增强智能技术在解析方法、传统AI 和人工经验都难以解决的复杂随机调度决策问题上具有良好的应用前景,例如:高渗透率新能源接入下的大规模交直流互联电网潮流控制、有功/无功拓扑联合调度、含多元异构主体的电网优化运行。后续将围绕具体调度决策场景和问题下的算法设计,以及如何与现有调度自动化系统充分衔接融合等方面开展研究工作。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
计算机与数字工程(2022年7期)2022-08-26
南方农业·下旬(2022年4期)2022-05-24
今日自动化(2022年1期)2022-03-07
数学大王·趣味逻辑(2021年11期)2021-12-03
环球时报(2016-12-07)2016-12-07
当代工人(2016年1期)2016-03-11
