
行人轨迹预测条件端点局部目的地池化网络
2022-10-29 03:34:58解云娇杨大伟张汝波
电子与信息学报 2022年10期
毛 琳 解云娇 杨大伟 张汝波
(大连民族大学机电工程学院 大连 116600)
1 引言
随着人工智能技术的发展,人类生活环境中出现越来越多的智能自主系统,并且在视频监控、人机交互以及交通检测等方面有着广泛的实际应用。并且这些应用是建设智能运输系统[1,2]和智慧城市[3–5]的重要组成部分,例如自动驾驶汽车、服务型机器人和高级监控系统。在现实道路场景中,预测动态对象的轨迹是智能自主系统的核心任务之一。这项任务中根据不断变化的环境,利用历史轨迹进行未来轨迹预测确实需要平滑和安全的路径规划。而实际应用中最常遇见的动态对象之一是行人,因此预测行人运动轨迹对于自动驾驶中的导航规划、人机交互和智能监控等任务至关重要。经过算法和文献的调研分析,现有的轨迹预测算法普遍存在的问题之一是:模型在通过历史轨迹学习邻居之间的社交互动时,均不同程度地忽略了行人的局部目的地信号,进而导致预测轨迹逐渐偏离真实轨迹。本文针对这一问题展开研究,并对算法模型进行相关改进。
行人的主观意识会不断调整轨迹方向,所以在轨迹预测时一个极具挑战性的问题是建模拥挤空间中人们之间发生的社交互动。Alahi等人[6]首次将长短时记忆方法(Long Short Time Memory,LSTM)引入到轨迹预测领域,同时提出社交池化长短时记忆网络(Social pooling LSTM network,Social LSTM)从有限时间步中学习行人之间的社交互动关系,并用社交池化层来捕捉邻居之间的关键互动,由此LSTM隐藏态将学习到行人随时间变化的运动特征,该模型可以融合邻居行人运动特征对主要行人进行联合推理。在公开数据集上测试评估后,展现算法优秀的推理性能,该方法成功预测由社交互动引起的各种非线性行为。考虑到行人倾向于表现出连贯的运动模式,Bisagno等人[7]提出一种群组长短时记忆网络(Group-LSTM network,Group-LSTM),该算法将相干滤波算法与LSTM网络相结合,进而利用运动相关性来对具有相似运动趋势的轨迹进行聚类,在群体层面上预测拥挤场景中行人的未来轨迹。在两个公共基准行人鸟瞰数据集(Walking pedestrains In busy scenarios from a BIrd eye view, BIWI)[8]和塞浦路斯大学多人轨迹数据集(University of CYprus, UCY)[9]上,实验结果表明,所提出的Group-LSTM在预测任务上的性能表现优于Social LSTM。但是该算法并没有考虑场景信息,针对这一问题Xue等人[10]提出一种基于分层编码的社交场景长短时记忆网络(Social Scene-LSTM network, SS-LSTM),共用3层编码分别学习行人尺度、社会关系尺度、场景尺度的行人状态信息,其社会关系编码中的传统矩形领域轨迹映射替换为圆形领域映射,并将3层编码信息相加后作为解码器的输入。该算法在城镇中心数据集(town centre)[11]上进行的预测不同长度轨迹的实验表明,当轨迹预测长度较大时,其模型在社会尺度上表现更好。虽然SS-LSTM方法在长时预测结果优于其他方法,但短时轨迹预测结果不如其他算法准确。Bartoli等人[12]将特定场景中影响行人运动的因素分为两个方面,分别是人与人和人与空间的相互作用,为此提出一种新型的上下文感知池化,用来学习和编码人与人和人与空间的交互,该算法基于LSTM体系结构,在公开数据集上证明了模型的有效性。
以上所述算法模型虽然使轨迹预测精度有所提升,但行人在前往目的地过程中长期依赖历史轨迹信号,缺乏该行人与周围邻居发生信息交换而引发社交互动后的关键信息,进而造成局部端点特征推理的局限性。并且多模态预测没有获取足够丰富的推理信号,难以建模多个符合真实轨迹的中间随机目标。
本文提出一种条件端点局部目的地池化网络(Conditional Endpoint local destination Pooling NETwork, CEPNET),可以有效学习社交互动以及提供有价值的特征推理信号。本文的主要贡献具体包括3个方面:一是使用历史轨迹编码信号,引入条件变分自编码器来建模社交向量的概率估计,并进行了消融实验来定性分析编码器的信号推理能力;二是创新性地构建条件端点特征推理算法和社交池化自注意力掩码机制来融合结构化的深度生成模型的高斯信号,通过自我注意力社交池化层过滤噪声信号进而降低模型预测误差,提高轨迹预测的准确率;三是将CEPNET在公开数据集上与现有Vanilla[19], SGAN[13]和Social-BiGAT[16]等先进算法进行比较,结果证明该模型性能超越现有算法,有效提升轨迹预测精度。
2 条件端点局部目的地池化网络
在特定场景中,由于建筑环境在一定的时期内是固定不变的,所以行人在此场景中的物理轨迹存在一定的规律性,比如,相似的目的地,相似的移动路径和相似的交互行为。行人倾向于在前往目的地的路上根据环境变化和其他行人的社交行为来调整自己的轨迹,为建模这个复杂的心理过程,使模型可以从历史轨迹中学习具体的行人之间的交互行为动机,本文提出条件端点局部目的地池化网络CEPNET,算法逻辑框图如图1所示。该网络主要包含3部分,分别为条件变分自编码器,条件端点特征推理器和自注意力社交池化网络,其中在自注意力社交池化网络中,设计自注意社交关系掩码来增强行人轨迹预测的自我方向的关注度。
2.1 条件变分自编码器
有监督深度学习已经成功地应用在许多识别问题上,在提供大量训练数据的前提下,它可以很好地近似一个复杂的多对1函数。但要建立能够有效执行概率推理和做出多种预测的复杂结构化输出的算法模型,仍然是一个挑战。在这项工作中,引入条件变分自编码器[20,21](Conditional Variational Auto-Encoder, CVAE)。CVAE是一个深度条件生成模型,该模型将高维输出空间的先验分布建模为以输入观测为条件的生成模型,在特征学习的同时结构化输出预测的高斯潜变量。
2.2 条件端点局部特征推理器
在结构化输出预测中,学习能够执行概率推理和进行多种合理预测的模型是非常重要的,这是因为轨迹预测任务需要对从单个输入到许多可能输出的概率映射进行建模。而条件变分自编码器生成的轨迹概率分布特征,虽然对预测轨迹推理提供丰富的生成信号,但是容易造成整个算法模型的泛化能力降低,进而导致该算法对未参与训练的场景轨迹预测误差偏大。因此,为将学习到的局部目的地进行概率推理和增强模型的整理泛化能力,提出条件端点局部特征推理算法(Local Feature Inference algorithm, LoFI),算法框架如图3所示。
2.3 自注意力社交池化网络
自注意力社交池化网络是利用本地自注意社交掩码来提取相关信息的新方法,该方法能够通过社交掩码归纳偏差的同时忽略杂散信号,从而学习更稳定的社交信息。
3 仿真分析
本文的实验环境为Ubuntu16.04系统,使用NVIDIA GTX1080Ti GPU,Intel Xeon CPU E5-2683。算法采用Python3和Pytorch1.8.0框架,运行环境为CUDA10.2,迭代学习率配置如表1所示。

表1 模型迭代学习率配置
数据集:为验证模型的有效性,实验仿真使用轨迹预测领域的行人鸟瞰数据集(Walking pedestrians In busy scenarios from a BIrd eye view, BIWI)[8]和塞浦路斯大学多人轨迹数据集(University of CYprus, UCY)[9],其中BIWI[8]包含ETH和Hotel两组场景数据,UCY[9]包含Univ, Zara01和Zara02,总共有5组数据,4个不同场景,涵盖1536名行人在拥挤环境中的运动信息。其中,ETH,Univ和Zara02没有参与训练,对应的测试结果可用来衡量算法的泛化能力;Hotel和Zara01的数据则按照6:2:2的方式被划分为训练集、验证集和测试集,对应的测试结果用来衡量算法的拟合能力。在这5个测试数据集中,ETH和Hotel行人密度更稀疏,而Univ, Zara01和Zara02包含更多的拥挤区域。这些数据集包含真实世界中不同场景下的行人轨迹信息,具体是根据在不同场景中录制的俯视角视频,按照2.5 fps从视频采样图片后人工标注的行人轨迹位置,该数据集广泛应用于轨迹预测算法的性能比较。
而在凡俗如方某者,自不敢奢望“三不朽”,那是“圣贤”们的伟业。写写弄弄三十年,在我只许愿:曾经的笔墨并未因轻浮与应景,若干年后复读时而令自己心惭脸红,则在笔者也算是经“墨磨”过的卖稿人了!
实验细节:将只含有CVAE算法的交互方法描述为条件端点局部目的地推理网络(Conditional Endpoint local destination Inference NETwork,CENET-I),该方法同样使用本文对前t时间步的历史轨迹划分方式来编码历史观测轨迹序列,保留了E1和E2编码器。相比于CENET-I,CEPNET则表示融合CVAE, LoFI, SA-Social Pool和SA-Social Mask的条件端点局部目的地池化网络。本实验将2018年发表的SGAN[13]、2019年提出的S-BiGAT[16],以及本文的CENET-I,CEPNET作为轨迹预测的交互模块在Trajnet++基准上进行消融实验,Vanilla[19]为4种算法的基线算法,具体是去掉整个交互模块的LSTM网络,其逻辑框架如图7(a)所示。各个算法在Trajnet++基准上的集成方式,如图7(b)所示。
为确保模型评估的公平性,该实验仿真中的SGAN[13], S-BiGAT[16], Vanilla[19], CENET-I和CEPNET模型使用相同训练集、验证集和测试集,且同样迭代25次,迭代平均运行时间如表2所示。在提升轨迹预测性能的前提下,CEPNET平均每59.09 min迭代1次。训练、验证、测试的规则均为模型输入9个时间步(3.6 s)的观测轨迹,然后预测未来12个时间步(4.8 s)的预测轨迹。

表2 各算法模型迭代平均运行时间(min)
3.1 评价指标
为对模型性能进行客观评估,除了本领域常用的平均偏移精度误差(Average Deviation accuracy Error, ADE)和最终偏移误差(Final Deviation accuracy Error, FDE)之外,又引入新的评估指标预测碰撞率(prediction Collision, Col-I)和真值碰撞率(ground truth Collision, Col-II)。测试评估采用以交互模型为中心的行人轨迹预测基准Trajnet++[19],该基准将行人交互轨迹分为4大类别,分别为静态I、线性II、交互III和非交互IV。静态类型是指主要行人在场景中走过的总距离小于1 m;线性类型是指使用扩展卡尔曼滤波预测的最终位移误差(FDE)小于0.5 m;互动类型是指存在同向跟随、避免碰撞、群组汇聚或是相邻行人出现在主要行人附近的其他互动;非互动类型是指主要行人轨迹是非线性的,并且在预测过程中没有社会互动。
其中ADE用于计算整个预测序列的预测轨迹值与对应真实轨迹值之间的L2平均距离,误差值越小越好,单位为(m);FDE则关注预测序列的最终目的地与其真实最终目的地之间的距离,误差值越小越好,单位为(m);Col-I是当前时刻行人预测值与相邻行人预测值的碰撞概率百分比(%),概率值越低越好;Col-II是当前时刻行人预测值与相邻行人真值的碰撞概率百分比(%),概率值越低越好。
3.2 定量分析
根据上述的ADE, FDE, Col-I和Col-II指标在ETH和UCY数据集上进行同领域先进算法之间的性能比较,CEPNET相比于基线算法Vanilla[21],ADE降低22.5%,FDE降低20%,Col-I降低9.75%,Col-II降低9.15%,具体的实验结果如表3所示。
由表3可知,SGAN[13]算法在行人密度稀疏的场景中,性能是具有优势的,但在密集区域的轨迹预测误差较大,社交推理能力信号极易受到周围邻居的影响。S-BiGAT[16]算法的社交图注意力机制虽然对周围邻居的互动信号有极强的结合能力,其预测值碰撞率Col-I的评估结果误差较小,但是计算量很大且模型的推理能力并不理想,导致ADE和FDE误差较大。Vanilla[19]算法是基于线性计算,对于非线性曲线的拟合能力很差,在各方面的预测误差均较大。CENET-I算法虽然在Hotel和Zara01数据集中实现同于或优于Vanilla[21]的预测性能,但对陌生场景(ETH, Univ和Zara02)的泛化能力较差。由于CEPNET算法能够合理地学习局部端点特征信号和强大的泛化推理能力,在所有场景中普遍降低各方面的误差值。根据测试平均结果可以看出,CEPNET算法综合性能已经超过SGAN[11]和S-BiGAT算法,而CEPNET算法在5个数据集上ADE和FDE的评估表现均优于其他算法,该算法实现轨迹预测最佳性能。
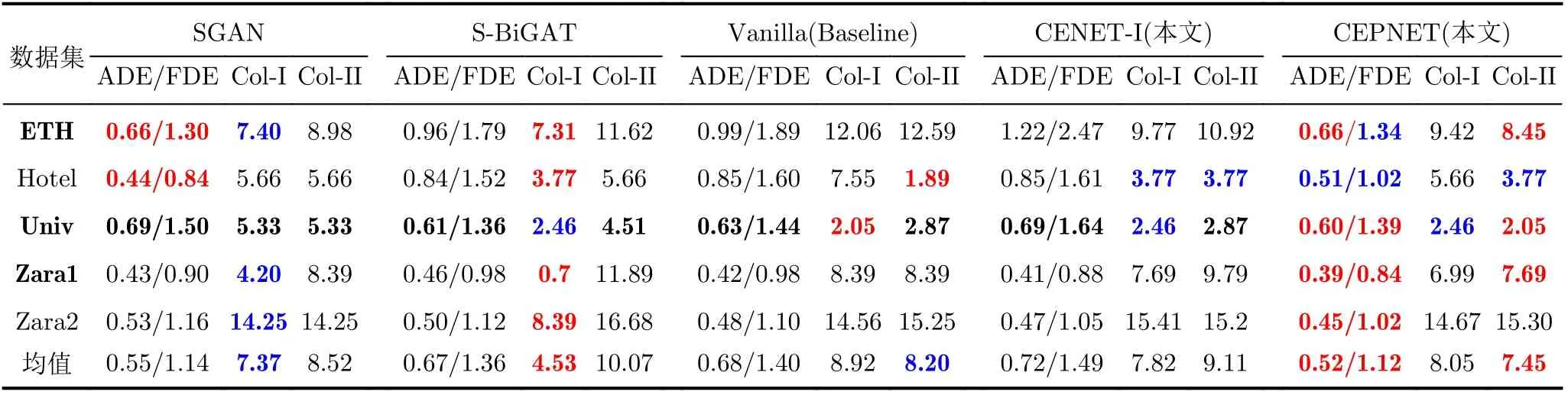
表3 CEPTNET与其他算法在ETH和UCY数据集上的定量结果
除以上所述测试结果之外,还对特定场景中的不同社交互动类型进行对应指标的测试分析,表4为随机抽样结果。在这5种算法中,SGAN[13]算法在交互类型III上的轨迹推理误差较小,而S-BiGAT[16]在预测值碰撞率Col-I上依然保持优势。CEPNET算法跟CENET-I算法相比,其社交池化网络优化数据通道中的轨迹信号,将同一时刻的社交信息有效地融合到轨迹预测的结果中,提高模型的泛化能力。与基线算法Vanilla[19]相比,CEPNET算法通过CVAE生成的条件端点局部目的地,条件端点特征推理器对该局部目的地进行特征编码,得到的概率特征有效地指导模型对未来轨迹的预测。由表4评估结果的整体误差排名可知,CEPNET算法综合性能优于其他算法。

表4 不同场景下4种交互类别的预测值评估结果
3.3 可视化分析
图8是对5个算法模型训练和验证损失的折线图,其中图8(a)中各颜色的曲面是对应模型的训练损失值震荡区间,实线是对应迭代次数的损失均值;图8(b)是模型在验证集上每次迭代测试后所对应的损失曲线。在训练集和验证集上,可以看出CEPNET算法的损失值均比其他算法更小且收敛速度更快。
在拥挤的场景中,建模行人的个人行为对其他行人轨迹的影响是非常重要的。传统轨迹预测方法使用吸引力和斥力模型来构建模型逻辑,而CEPNET采用纯数据的驱动方法来学习历史轨迹中发生的交互行为信息。CEPNET模型会根据当前主要行人的个人空间信息、历史轨迹信息、感知到的社交互动和最终目的地来规划该行人的路径轨迹。为分析模型对行人是否有实际的交互推理能力,根据真实场景的坐标系,将SGAN[13], S-BiGAT[16], Vanilla[19],CENET-I和CEPNET模型的预测值和真值进行可视化分析,具体如图9、图10所示。图9、图10中黑色实线是本场景中的主要行人的轨迹真值,即对此人用3种模型进行轨迹预测分析,虚线是本场景中的其他行人轨迹真值。红色点表示SGAN[13]算法的预测值,蓝色点表示Vanilla[19]算法的预测值,橙色点表示CENET-I算法的预测值,绿色点表示CEPNET算法的预测值。每组场景中的所有轨迹长度,均为连续21个时间步(8.4 s)上的可视化结果。
图9(a)是ETH中第1015组场景,此场景中轨迹密集、路线复杂,且存在同向跟随、相向避让等多种社交互动,CEPNET算法的抗干扰能力明显优于其他算法;图9(b)是Hotel中第223组场景,此场景中主要行人的社交互动相对简单,但是属于非线性路径,由图可知,在其他算法方向逐渐偏离目的地的过程中,CEPNET算法依然能够正确预测该行人目的地的方向;图9(c)是Univ中第3组场景,该场景中存在同向跟随的社交关系,各算法均存在不同程度的偏离目的地方向,而CEPNET的位移误差最小;图9(d)是Zara01第904组场景,该场景同样为一对朋友相伴而行的情况,CEPNET算法虽然相较S-BiGAT[16]算法在速度预测上存在一定误差,但能够保持算法学习到正确的目的地方向。
图10(a)是静态类型行人轨迹预测,图10(b)是线性类型行人轨迹预测,图10(c)是存在社交互动的交互类型轨迹预测,图10(d)是非交互类型的轨迹预测。在非交互类型中,一个有趣的现象是现有算法主要行人的预测轨迹很容易被模型学习到的邻居行人的轨迹所干扰,而CEPNET算法有效地减少这种干扰,这有力地说明社交自注意力掩码在本算法中的可靠性和实用性。通过可视化模型在不同场景和不同类型的预测值,发现CEPNET算法相较于另外4个模型,极大地提高了预测性能。
综上所述,在公开数据集上的定量评估和可视化结果均证明了CEPNET算法在轨迹预测领域的先进性。
4 结束语
本文针对行人社交互动过程中存在局部目的地特征信号考虑不足所导致的无法准确预知未来轨迹概率分布的问题,提出一种条件端点局部目的地池化网络(CEPNET)。通过在公开数据集上的消融实验和定量分析结果证明提出的LoFI和SA-Social Pool在轨迹预测过程中的可靠性。此外,仿真实验还定性地证明自注意力社交掩码对于非互动类型的非线性轨迹预测的有效性,CEPNET算法评估结果达到先进水平并且优于基线算法Vanilla[19]的预测性能。CEPNET算法虽然很好地实现了对观测轨迹的特征推理,但仍然存在与现有模型相似的缺陷,就是无法准确预测行人未发生社交互动时的非线性轨迹。因此,对非线性轨迹的概率推理,是下一步的研究重点。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
小主人报(2022年7期)2022-08-16 06:59:30
数学物理学报(2022年2期)2022-04-26 14:08:34
软件导刊(2022年3期)2022-03-25 04:45:04
小天使·三年级语数英综合(2021年4期)2021-06-15 03:25:33
中学生数理化·教与学(2019年8期)2019-09-18 15:08:40
计算机技术与发展(2019年1期)2019-01-21 00:56:38
小猕猴学习画刊·下半月(2018年9期)2018-05-14 13:34:42
数学物理学报(2017年1期)2017-06-05 09:12:28
