
基于人工神经网络的地下水封洞库涌水量预测
2022-10-28 08:54何国富张奇华柳耀琦
水利与建筑工程学报 2022年5期
何国富,张奇华,柳耀琦,沙 裕
(1.中石化上海工程有限公司,上海 200120;2.中国地质大学(武汉) 湖北巴东地质灾害国家野外科学观测研究站, 湖北 武汉 430074)
地下水封洞库是利用水封原理在地下岩体中人工成洞储存原油的一种新方式,洞库的涌水量是评价其技术经济综合性价比和工程质量安全的一个重要指标。在一定库容规模的条件下,涌水量的大小直接影响着施工渗水治理成本和洞库运维成本,甚至一定程度上影响洞库的安全运行和环保。因此,地下水封洞库涌水量的分析预测是工程建设中一项十分重要的内容。
然而,目前规范[1]推荐和工程上采用的分析预测方法均以等效连续介质为基础进行求解,如经验解析法、水文地质比拟法和数值模拟分析法等[2-5],其预测值均与工后实际值存在较大的偏差,因而不能满足工程需要。其原因主要在于作为非连续介质的裂隙岩体渗流分析的高度复杂性、地质构造模型与理论模型的不成熟、不完善,以及地质参数获取时的较大离散性和局限性,导致预测不准确。
人工神经网络(Artificial Neural Network, ANN)分析方法的一个显著特征是其具有强大的非线性映射能力和学习能力,适合于处理各种过程和对象的关系模糊、不确定以及解析分析不清晰之类的问题。近20多年来,基于人工神经网络的方法在岩土工程中得到了较广泛的应用[6],并对各种边坡稳定、地基沉降和地质灾害以及隧道围岩稳定等岩土工程地质问题进行了模型预测[7-11]。但是目前将神经网络技术应用于地下水封洞库领域特别是涌水量的分析预测尚未有相关文献资料。在常用的方法难以及时响应各种实际观测指标发生变化并对涌水量进行分析预测的局面下,研究与探索一种更为简洁快速和有效的预测方法具有较大意义。本文尝试采用ANN方法进行地下水封洞库的涌水量分析预测。
1 BP神经网络算法理论[12]
自人工神经网络理论诞生以来,先后发展出了几十种不同网络模型,其中Runelhant等提出的BP神经网络因具有较强的从输入到输出的非线性映射能力和良好的泛化性、自适应性以及容错能力而广泛用于模型预测。
BP神经网络是一种前馈神经网络(感知器),具分层结构(通常由三层组成),信息从输入层进入网络,经隐层处理后传向输出层,若实际输出与期望输出(教师信号)不一致,则将其误差转入反向传播。误差反传是将输出误差以某种形式经隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此信号即为修正各单元权值的依据。这一信号的正向和反向传播的各层权值调整过程,是反复进行的,权值调整的过程即为学习训练过程,一直到误差减小到可接受的程度。
典型的BP网络结构原理见图1,图中输入层输入模式向量为X=(x1,x2,…,xn)T,n为输入层神经元个数,隐层输出向量为H=(h1,h2,…,hm)T,m为隐层神经元个数,输出层输出向量为Y=(y1,y2,…,yl)T,l为输出层神经元个数;另定义期望输出向量为D=(d1,d2,…,dl)T。输入层到隐层的权值矩阵表示为V,V=(V1,V2,…,Vj,…,Vm) ,其中列向量Vj为隐层第j个神经元对应的权向量,Vj=(v1j,v2j,…,vnj)T;隐层到输出层的权值矩阵表示为W,W=(W1,W2,…,Wk,…,Wl) ,列向量Wk为输出层第k个神经元对应的权向量,Wk=(w1k,w2k,…,wnk)T。
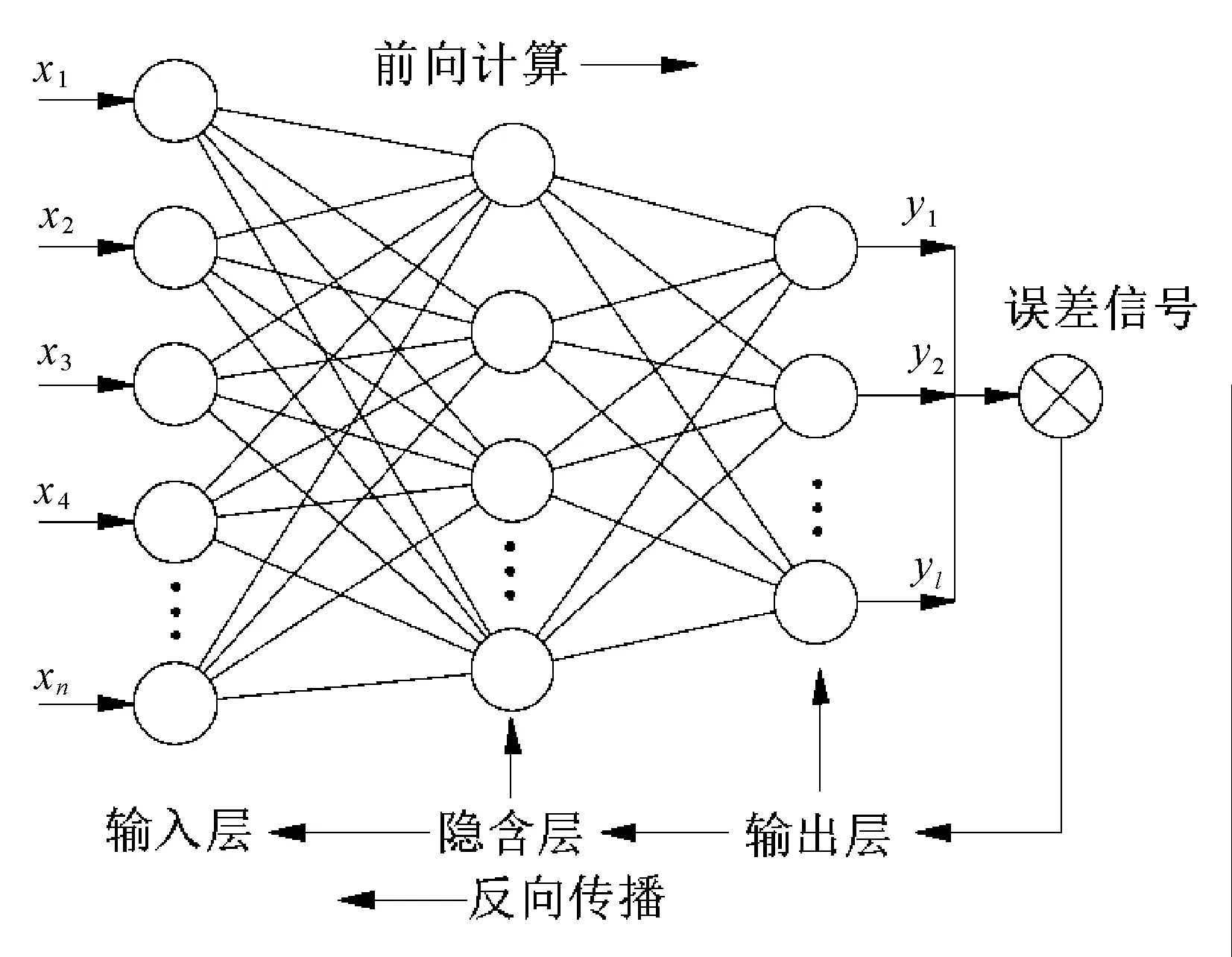
图1 BP网络结构原理图
前向计算时,输入层向隐层输出,则隐层各神经元的输入和输出分别为netj和hj:
(1)
hj=f(netj)j=1,2,…,m
(2)
对于输出层,输入和输出分别为netk和yk:
(3)
yk=f(netk)k=1,2,…,l
(4)
上式输入层和隐层的输入中,i=0和j=0,分别为输入层和隐层各神经元的阈值。函数f为神经元输入和输出的激励函数,一般均采用单极性Sigmoid函数,f(x)=(1+e-x)-1。
当网络输出与期望值不等时,即存在输出误差(信号)E:
(5)
该误差与隐层关系可表达为:
(6)
与输入层的关系可进一步表达为:
(7)
可见,网络误差E是各层权值wjk和vij的函数,调整权值即可改变误差,调整的过程即为反向传播。调整权值的原则应使误差不断减小,因此其调整量也应与误差的梯度下降成正比。同时,为提高训练效率和加快收敛,减小收敛振荡,计算中采用了改进的BP算法,即在权值调整中采用自适应调整学习率和增加附加动量项,表达式为:
(8)
(9)
上面等式中的第一项表示为调整梯度,负号表示梯度下降,η为学习率,取0~1之间的某个值,在训练中根据梯度变化进行自适应动态调整;第二项为增加的附加动量项,α为动量系数,以考虑前后时刻梯度的不同方向,减小收敛振荡。
另外,考虑到计算中当神经元的输入输出进入激励函数的饱和区时,权值调整将进入误差曲面的平坦区。通过引入陡度因子可使输出退出激励函数的饱和区。调整方法是在激励函数中将函数输入值x除以一个大于1的系数λ(陡度因子),x=x/λ,当退出饱和区后恢复为1。
不断重复上述调整权值的过程即为学习训练的过程,直到网络总误差E小于设定的训练精度ε要求为止,因此该算法亦称非线性梯度下降算法。
2 地下水封洞库涌水量预测模型
2.1 影响涌水量的因素
通常的涌水量分析预测主要有经验解析、工程类别和渗流场数值模拟,需要在一个相对独立的水文地质单元内,根据水力边界条件、岩体的水力学参数和地下水的汇源等条件进行[13-14]。然而,根据对现有地下水封洞库涌水量的研究观察发现,影响洞库涌水量的因素与下列水文环境和工程基本特征因素有密切关系:
(1) 场地地下水水位:水头高度显著影响涌水量,同时反映一定时间内地下水的变化趋势。
(2) 地区降雨量:不同时节和不同地区的降雨量对地下水补给影响较大。
(3) 库区地形环境:地下水的赋存条件和渗流特征与山地丘陵、平原和滨水(湖、海等)岛屿等不同地形密切相关,同时也决定着洞库埋深的确定。
(4) 水幕补水量:水封洞库需要满足水封性,当洞室上方地下水水位降低或洞室内操作压力增大时,需要通过水幕补水来保证洞库的水封性[15]。
(5) 洞室上方油气压力(操作压力):洞室内装了一定量的介质后,其运行时上方保持的油气压力作用在洞室围岩的地下水排泄面上,形成压力边界,对涌水量有一定影响。
(6) 储油量状态:与气象压力类似,液体介质(通常比重小于水)作用在洞室围岩裂隙水排泄面上,抵消了部分裂隙水的渗透压力。储油量状态(即实际储油量)对涌水量具有不可忽略的作用。
(7) 洞室容积;岩体渗流的复杂性和非线性,容积大小与涌水量并不成线性关系,即使容积相同,其涌水量也并不一致。
上述影响因素中,第3项地形环境为定性变量指标,可以将其定义为定量的数值指标,即:山地丘陵为1,平原为2,滨水为3,目前尚未有建成的滨水工程资料,则数值区间暂取为[1,2]。其它因素条件均为实际定量观测值。
2.2 BP网络结构建模
一个三层BP神经网络能够以任意精度体现任意连续函数的非线性映射,并通过学习训练来实现。因此隐层数取1层。
隐层神经元的数量根据目前样本数量和输入指标中存在“含噪”信息的实际情况,用“试凑法”确定为15个,即用同一样本集,将隐层神经元数量从小到大逐渐增加,从中确定网络误差最小时对应的隐节点数。网络初始权值和阈值采用(0,1)之间的随机值。
3 网络训练与模型预测
3.1 训练样本
根据国内已经建成投用的4个储油库自封洞后(包括进油前)的涌水量实测记录,筛选了在一定时间内数据相对稳定的部分记录值,随机分为学习训练和泛化测试两部分样本,为避免输入/输出数据中各分量之间由于量纲不同而造成各个误差相差偏大的问题,提高训练效率和网络敏感性,对输入/输出数据在[0.2,0.8]区间作归一化处理。表1、表2分别为部分输入样本数据和归一化处理后的数据,表3为部分泛化测试样本数据和测试误差结果。
3.2 模型训练和泛化
控制训练精度ε=0.007,为加快收敛,计算中采用改进的BP算法,设置动量项和自适应调整学习率以及陡度因子,取动量系数取α=0.3,初始学习率η=0.2,调整步长0.05,陡度因子λ=1.25。网络总误差采用均方根误差ERME:
(10)
式中:P为训练样本对;p为样本序列计数号;E为某样本的输出误差(信号),当E<ε时,训练停止。经11 563次迭代训练,耗时31 min,网络满足收敛条件,图2为训练过程中迭代次数与网络总误差函数收敛的变化状况,由于采用了改进的BP算法,误差函数收敛平滑,基本无振荡。
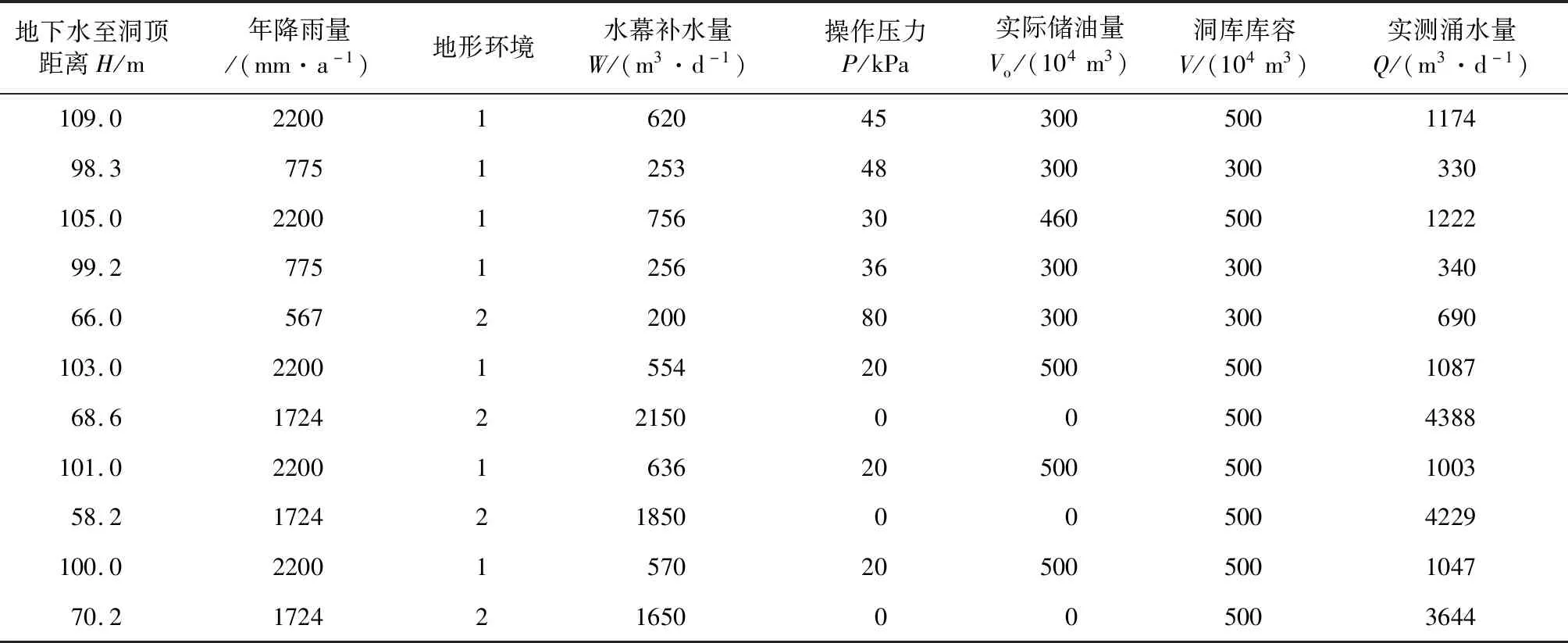
表1 洞库涌水量预测模型输入/输出训练样本
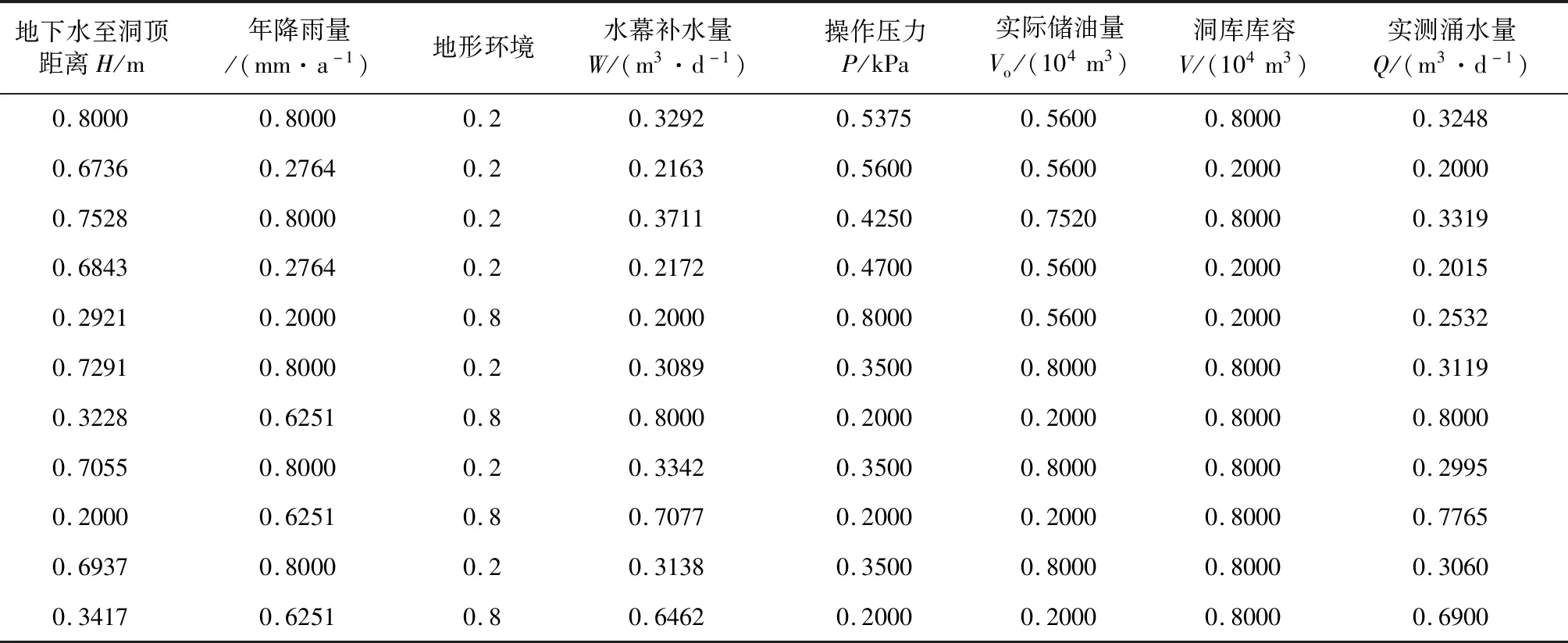
表2 洞库涌水量预测模型输入/输出训练样本归一化数据
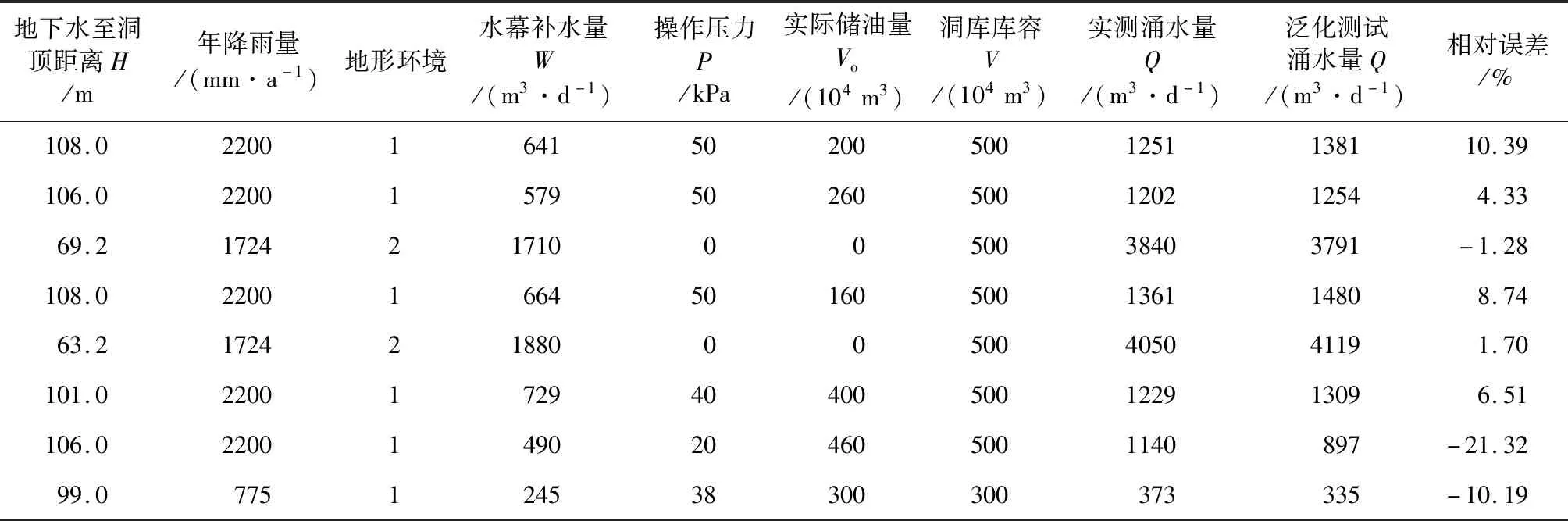
表3 洞库涌水量预测模型输入/输出泛化测试样本和测试误差
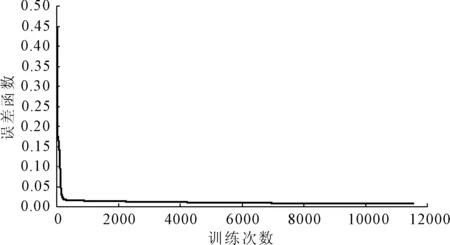
图2 模型训练与总误差关系
表3泛化测试结果表明,其输出元(涌水量)的实测值与预测值之间的相对误差最大为21.32%,多数可控制在10%左右,甚至更小。目前对于地下水封洞库涌水量的预测误差能达到25%以内,是完全可以满足实际工程需要的。可见,BP网络算法建立的预测模型不仅拟合效果好,泛化能力也较强,只要经过充分的学习训练,即能获得较高的预测精度。
3.3 工程涌水量预测分析
不难发现,根据目前选定的7个参数所建立的网络模型,在拟合度适中的情况下,模型具有类似设计的“查表”式功能,即改变某一个指标,即可得到所需的预测值。利用本模型,对拟建南方某地下水封洞库的涌水量进行运营期预测分析。
该洞库建于南方山地丘陵地区,年降雨量1 269 mm/a,设计稳定地下水位为海平面±0.000 m,洞室埋深-100 m(洞顶),水幕系统水幕孔高程-73.8 m,地面绝对高程12 m~65 m,库容300×104m3。预测过程如下:
运营期条件为设计稳定地下水位,稳定涌水量预测输入参数为:
水文环境因素参数:
1)地下水位取稳定设计水位时的离洞顶的距离为H=100 m
2)当地年降雨量Rw=1269 mm/a
3)地形环境为丘陵,取值为1
工程特征因素为:
4)正常水幕补水量取W=300 m3/d
5)操作压力P=40 kPa(氮封压力)
6)进油量Vo=0 m3,100×104m3,300×104m3(洞罐封洞后准备进油状态、进油1/3和满油状态)
7)洞库库容V=300×104m3
则BP神经网络模型预测的涌水量约分别为848.7 m3/d、694.6 m3/d和436.4 m3/d,这与规范要求的运营期长期稳定涌水量万分之二的600 m3/d要求基本相吻合。
受洞室开挖范围和注浆等施工期不同因素干扰影响,对施工期的涌水量预测是极为困难的。在不考虑注浆对围岩渗透性改变和洞室全部开挖完成这一极端工况情况下,近似将模型泛化应用于施工期涌水量的定性趋势预测。由于施工期条件为地下水位不断下降,水幕补水量逐渐增加,操作压力和进油量可定义为0 kPa和0 m3,则利用模型的“查表”功能,得到施工期近似预测涌水量数据,见表4。

表4 某洞库施工期涌水量预测
表4预测结果表明,当地下水位逐渐降低,水幕补水量增加,涌水量也相应增大。当水位降至50 m接近控制最低水位线时,水幕的补水量为最大;水位降至70 m时(一般工程均有大约25 m~30 m的降深),涌水量在2 660 m3左右。这一量级、趋势和规律与同处南方地区的我国另外两个已建洞库的实际情况非常相似。
从上述模型对涌水量的预测结果可知,模型在训练过程中采用了多个洞库的实测数据作为样本训练,可以充分体现出网络模型经过训练拟合后用于实际工程预测分析的可行性和合理性,对水封洞库的涌水量预测是具有积极实用意义的,对施工期的地下水位控制也有一定的参考作用,体现出了其应用简单、快速和高效能的特点,这是目前常规预测方法所不及的。目前,该模型已经在工程实际中得到应用,随着工程的进展也将不断得到验证和完善。
4 结 论
本文尝试利用已建工程的实测资料作为样本,采用ANN方法建立了BP神经网络的地下水封洞库涌水量预测模型,得出以下几点结论:
(1) 将BP神经网络模型引入地下水封洞库的运营期涌水量预测,预测精度能满足现阶段国内水封洞库工程的需要,是解决目前地下水封洞库涌水量预测的一种有效的方法,因而在实际工程中应用是可行的。
(2) 用ANN方法建立的网络模型进行水封洞库涌水量的预测,其方法简单、快捷而实用高效,特别是不再涉及理论模型和地质参数等难以确定的复杂问题。
(3) 建立一个健壮的网络模型,需要有一定数量的可靠实例样本作为基础,只要不断补充工程实例样本并经过充分的学习和训练,可大大提高网络的泛化性能,使预测更为准确。
(4) 经过充分训练后的网络预测模型具有类似工程设计的“查表”功能,可以通过若干个实时观测数据进行快速的预测分析。
(5) 限于国内目前地下水封洞库实例工程仍较少的情况,特别是缺少建造在滨水环境下的工程建成实例,因此目前所建立的这一预测模型尚有待进一步研究和不断完善。
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
陕西煤炭(2022年4期)2022-07-23
陕西煤炭(2021年5期)2021-09-23
石材(2020年6期)2020-08-24
商洛学院学报(2020年4期)2020-07-08
隧道建设(中英文)(2019年8期)2019-09-10
人民珠江(2019年4期)2019-04-20
生物化工(2019年3期)2019-02-17
铁路计算机应用(2018年5期)2018-06-01
中国矿业(2017年3期)2017-03-23
