
基于航迹数据的耙吸挖泥船施工轨迹的识别
2022-10-27 04:39徐婷戴文伯张晴波周雨淼
中国港湾建设 2022年10期
徐婷,戴文伯,张晴波,周雨淼
(中交疏浚技术装备国家工程研究中心有限公司,上海 201208)
0 引言
耙吸挖泥船具有挖泥效率高、抗风能力强、施工避让灵活等优点,是港口航道、吹填造地、海洋资源开发及海域国家重点工程不可替代的工程机械[1]。耙吸挖泥船分布广泛,传统的监控管理模式大多是船岸分离的,无法做到实时监控、历史查看、智能报警[2]。在大数据技术和人工智能技术高速发展的背景下,基于大数据及人工智能技术从公开的航迹数据辨识出耙吸挖泥船的施工行为模式,有助于实现耙吸挖泥船全方位监控、有效防范施工风险[3]。
在交通船领域关于船舶轨迹识别的研究已经取得一些成果,如江玉玲等[4]利用船位转向角和航速变化量作为信息度量对船舶轨迹进行分段,采取Frechet距离衡量船舶轨迹相似度,基于类似DBSCAN聚类方法对轨迹段进行聚类,得出船舶运动典型轨迹。Zhao等[5]基于原始朴素DP算法和DBSCAN算法实现船舶轨迹模式的快速分类辨识。张春玮等[6]将位置、航速、航向等多个运动参量进行加权求和来度量船舶行为,基于行为相似度利用无监督DBSCAN算法进行聚类实现了航道内船舶异常行为的识别。在疏浚船领域,徐婷等[7]基于DBSCAN聚类算法和局部异常因子算法(Local Outlier Factor,LOF)辨识出绞吸挖泥船的施工区和施工轨迹,但该文章仅对绞吸挖泥船进行论述,并未对耙吸船的航行轨迹进行探讨。但是耙吸船与绞吸式挖泥船及其他船舶作业模式差距较大,耙吸船的施工区有明确的挖泥区域和抛泥区域,且施工过程包含“挖、运、卸、返”4个关键阶段,需要频繁地改变施工行为模式,故不能将上述方法直接应用在耙吸船领域。
针对上述背景,考虑到耙吸船的作业特征,提出一种基于航迹聚类的耙吸船施工行为辨识方法,该方法基于分层多次聚类的思想,融合了位置、航速、航向等多个变量信息,通过3次逐层递进式聚类,解决多变量单次聚类过程中变量参数权重设置困难的问题,也提升了模型的适用性和鲁棒性。
1 耙吸船行为识别框架
耙吸船的施工过程可以概括为:维持低速“挖泥”、提速“运泥”、低速“抛泥”、提速“返回”4个过程,并形成一个密度不均匀的轨迹密集区域。为此,本文提出一种耙吸船行为识别框架,依据耙吸船施工过程的特性,设计出一种分层多次聚类算法,逐步识别出耙吸船的行为。该框架如图1所示,首先对轨迹进行预处理,得到清洗后的轨迹;然后基于经纬度信息建立DBSCAN聚类模型,识别出施工区;再对施工区轨迹,基于速度信息建立GMM聚类模型,识别出“挖泥”、“抛泥”、“往返”轨迹;最后对“往返”轨迹,基于航向信息建立GMM聚类模型,识别出“运泥”、“返回”轨迹。
2 耙吸船行为识别算法
2.1 轨迹预处理
对瞬时速度(大于20 kn)或者航向(小于0°或大于360°)异常航迹点直接过滤。而对异常位置点会根据情况选择合适的操作,如图2所示,如果两个相邻轨迹点A、B构成的轨迹线段L1的平均速度超过最大速度阈值20 kn,那么B判定为异常位置轨迹点。

图2 异常位置轨迹点处理Fig.2 Processing of abnormal position track points
处理异常轨迹点B的方法有:若A点与C点相连构成新的轨迹线段L2的平均速度没有超过速度阈值20 kn,则认为B点的异常位置可以弥补,直接过滤即可;反之,则认为B点的异常无法弥补,将轨迹从A点与C点之间切断,并且删除B点。
2.2 DBSCAN算法
DBSCAN算法是一种很典型的密度聚类算法,无须事先设定簇个数,非常适合形状不确定的空间聚类。DBSCAN算法过程如下:
1)设置的邻域半径ε和簇内元素最小数目MinPts;
2)随机选择一个未访问的轨迹点p,标记p为“未访问”,并检查p的ε邻域是否至少包含MinPts个对象。如果不是,则p被标记为噪声点,否则为p创建一个新的簇c,并将轨迹点p的邻域范围内所有点加入“候选集N”;
3)对“候选集N”中所有尚未处理的轨迹点q进行判断,检查其在半径为r的邻域范围内是否包含至少MinPts个轨迹点,如果是则将轨迹点q的r邻域中未归入任何一簇的轨迹点加入簇c,如果不是则从“候选集N”中移除;重复此步骤,直至所有轨迹点被处理;
4)重复步骤2)、3)直至所有的轨迹点归入了某个簇或者标记为噪声。
2.3 GMM算法
高斯混合模型(GMM)是一种混合概率分布模型,其概率密度由多个单高斯分布加权平均得到,数学形式如下:

式中:gk(x;μk,σk)为单高斯分布;πk代表混合权重;c代表该模型中高斯成分数量,其实每个高斯模型就代表了一个类(cluster),将样本数据在这c个高斯模型上投影,就得到样本属于各个类上的概率,选取概率最大的类所为判决结果。
3 实证分析
3.1 数据描述
本文以1月1日—12月31日为期1 a的某耙吸挖泥船的AIS数据为例,总样本点数为104 220个,运动轨迹图如图3所示,有3个密集区域。
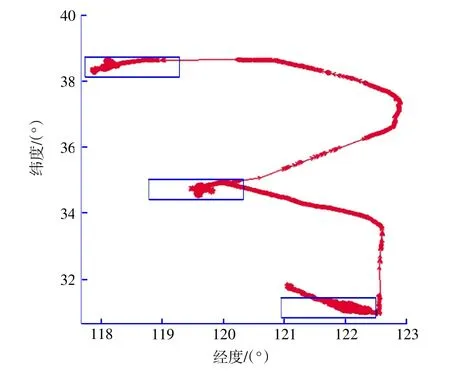
图3 某耙吸挖泥船的运动轨迹Fig.3 Trajectory of TSHD
3.2 轨迹预处理
表1是按照2.1节轨迹预处理技术处理后得到的7个有效轨迹片段。图4为7个有效轨迹片段的运动轨迹。可以看出轨迹片段1和4属于同一区域,可以合并分析。轨迹片段2、3、6无施工特征,无需聚类分析,轨迹片段1、4、5、7需要进一步聚类分析。
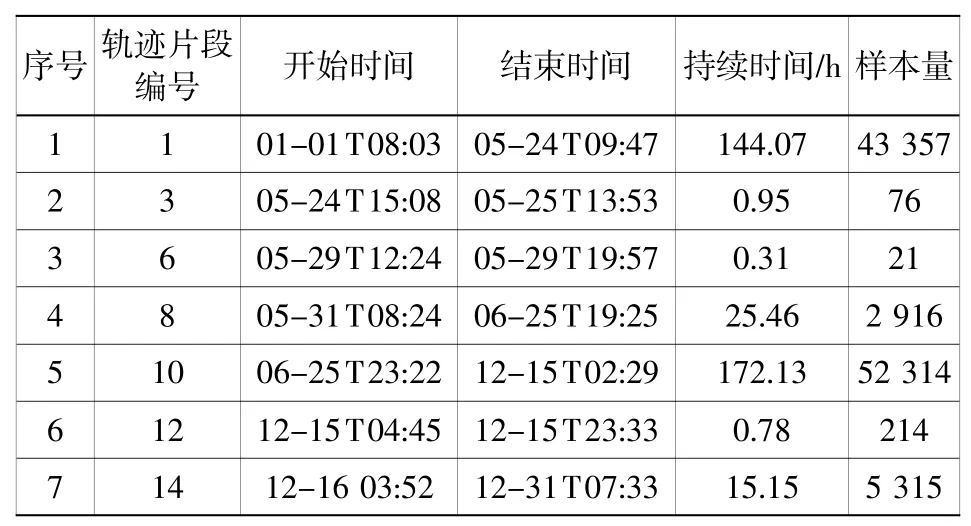
表1 某耙吸船有效轨迹片段Table 1 Effective trajectory segments of TSHD
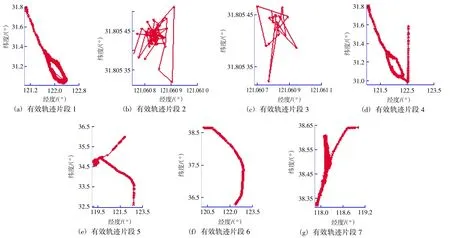
图4 有效轨迹片段运动轨迹Fig.4 Effective trajectory segments of trajectory
3.3 分层多次聚类
1)经纬度聚类
有效轨迹片段1和4合并后,样本量为46 273个,利用DBSCAN算法进行第1层次聚类,根据KNN算法确定DBSCAN参数,取k=6,计算全部点的k-distance并递增排序,发现k-distance在0.04附近急剧变大。因此最少点数目MinPts设置为6,邻域半径设置为0.04,聚类结果如表2所示,将区域聚为2类,cluster=0表示为异常值点,一共有124个点。
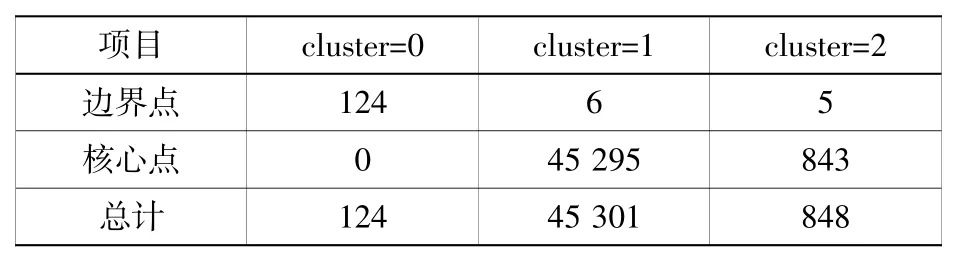
表2 DBSCAN聚类结果表Table 2 Table of DBSCAN clustering results
图5为利用ggplot2将聚类结果可视化,透明度(alpha)设置为0.2,更清晰看出点的重叠情况。

图5 DBSCAN聚类结果Fig.5 DBSCAN clustering results
根据速度特征辨识3个区域,如图6所示,cluster=0区域速度主要集中在10~14 kn,又是异常值,识别为航行轨迹,无需二次聚类;cluster=2航速维持在0.15 kn附近,识别为抛锚区域,无需二次聚类;cluster=1,该区域有3种速度特征0~0.15 kn,2~5 kn,10~15 kn,识别施工区轨迹。

图6 速度概率密度分布图Fig.6 Velocity probability density distribution
2)速度聚类
将已识别出的施工区轨迹,利用GMM算法基于速度信息进行第2层次聚类。因施工区轨迹包含“挖泥”、“抛泥”、“往返”轨迹,因此高斯成分个数c设置为3。聚类结果如表3所示,classification=1的速度均值为0.134 1 kn,识别为抛泥轨迹;classification=2的速度均值为3.089 9 kn,识别为装舱轨迹;classification=3的速度均值为10.706 7 kn,识别为“往返”轨迹。

表3 基于速度GMM聚类算法结果Table 3 Results of speed-based GMM clustering algorithm
3)航向聚类
将已识别出的“往返”轨迹,利用GMM算法基于航向信息进行第3层次聚类,可进一步识别出“运泥”和“抛泥”轨迹。高斯成分个数设置为2,得到聚类结果如表4所示,由上文耙吸船施工周期部分分析可知,classification2=1的航向均值为100.386 6°,识别为返回轨迹,classification2=2的航向均值为284.396 9°,识别为运泥轨迹。聚类可视化结果如图7所示。

表4 基于航向GMM聚类算法结果Table 4 Results of heading-based GMM clustering algorithm

图7 速度时序聚类结果图Fig.7 Speed sequence clustering results
3.4 模型验证
1)运用人工观察打标方法和模型结果对比
将施工区轨迹类别辨识结果重新打上标签,随机挑选一段速度聚类结果的时序图,如图7所示,虽然聚类过程中并未考虑时间因素,但是速度时序图像被精准的贴上标签,且周期性特征明显,聚类效果显著。
2)运用企业施工管理的记录报告和模型结果对比
如表5所示,算法计算的施工时间与生产单位统计报表数据偏差很小,基本上控制在5%以内。说明聚类效果很好。

表5 施工时间对比Table 5 Comparison of construction time
4 结语
1)分层多次聚类算法,解决了一次聚类多参数权重设置的难题,提高了模型的鲁棒性。
2)分层多次聚类算法可以有效地挖掘耙吸船施工周期性模式,对耙吸船施工状态的辨识效果显著。
3)研究成果运用公开数据挖掘分析耙吸船施工状态,为耙吸船安全状态分析、经济分析提供新的依据。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
农业工程学报(2022年7期)2022-07-09
舰船科学技术(2022年10期)2022-06-17
知识就是力量(2022年6期)2022-06-16
科技与创新(2021年24期)2022-01-03
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
中国船检(2019年4期)2019-05-30
民用飞机设计与研究(2019年4期)2019-05-21
发明与创新·大科技(2016年11期)2016-11-19
