
多层次可选择核卷积用于视网膜图像分类
2022-10-26 12:36:16朱纳,李明
重庆邮电大学学报(自然科学版) 2022年5期
朱 纳,李 明
(重庆师范大学 计算机与信息科学学院,重庆 401331)
0 引 言
糖尿病性视网膜病变(diabetic retinopathy, DR)是糖尿病病人身上一种常见的致盲性疾病[1]。据国际糖尿病联盟(international diabetes federation, IDF)研究表明,糖尿病病龄超过10年,视网膜病变几率高达60%,可能导致病人短暂性失明或永久性失明[2]。如果对糖尿病病人进行定期检查,早发现DR早治疗可以避免病情进一步恶化。
目前糖尿病视网膜病变主要有白内障、青光眼、年龄相关性黄斑病变(age-related macular degeneration, AMD)以及糖尿病性黄斑水肿(diabetic macular edema, DME)[3]。AMD又可按照临床表现和病理改变不同分为干性(DRUSEN)、湿性(CNV)两型。衰老和退变是引起AMD的重要因素,随着人口趋于老龄化,AMD已成为西方发达国家最主要的致盲疾病[4-5]。该病患者在前期并没有表现出任何外在症状,但是随着时间的推移,患者视力会逐渐退化,虽然不会导致视力完全丧失,但是会对患者的正常生活带来一定的不便。因此,对眼底图像DR的严重程度进行准确分类是当前研究重点。
光学相干断层扫描技术(optical coherence tomography, OCT)是近年来一种新型层析成像技术,它可以得到生物组织的结构图像。与传统的眼底检测技术相比,OCT更快捷、可进行活体眼组织显微镜结构的非接触式、非侵入性断层成像,更容易检测到眼底镜检查、荧光素眼底血管制影法无法检测的糖尿病引起轻微黄斑水肿(DME)[6]。因此,本文采用OCT视网膜眼底检测图像数据集进行分类研究。
随着深度学习神经网络的发展,一些学者在对视网膜OCT图像进行分类研究时使用深度学习对图像进行预处理,用于解决视网膜OCT图像的大小和质量不统一等问题。以上基于图像预处理的方法虽然取得不错的实验效果,但同时会导致图像丢失部分有用原始信息,在增加实验复杂性的同时也降低了模型鲁棒性。
为了使神经元能够自适应地调整其感受野大小,增加模型鲁棒性,本文采用了可选择卷积核(selective kernel, SK)在对多个尺度扩张率的卷积核之间进行自动选择操作。具体来说,引入了一个SK卷积,它由3个阶段组成:分割、融合和选择。分割阶段生成多条路径,这些路径具有相同的卷积核但不同的扩张率,对应不同的神经元感受野大小。融合阶段将多条路径的信息进行组合和聚合,得到一个全局的、全面的选择权重表示。选择操作再根据2种权值自身相似性和相对相似性选择权值对不同扩张率路径上的特征映射进行聚合。考虑到不同的视网膜OCT数据集本身存在天然差异,为了证明模型性能比较的公平性及泛化性能,本文在2个公开数据集(OCT2017、SD-OCT)中进行模型对比[7],实验表明,该算法具有良好的泛化性能,与以往的算法相比有一定优势。
1 相关工作
随着机器学习的兴起,越来越多的人开始研究机器学习算法和各种神经网络在医学图像分析中的应用。
2014年,Srinivasan等[8]将机器学习应用到基于OCT图像的AMD和DME疾病的诊断和分析。他们提取了OCT图像的HOG特征,并使用支持向量机(SVM)进行分类和识别,还通过杜克大学,哈佛大学和密歇根大学创建了一个公共OCT数据集,以方便将来的研究。 在2016年,Wang等[9]使用了Srinivasan等提供的公共数据集,利用OCT图像的线性配置模式(linear configuration pattern, LCP)特征和顺序最小优化(sequential minimal optimal, SMO)算法进行OCT图像的分类分析并进行识别分类。 值得一提的是,在特征的提取中使用了多尺度方法,因此,可以在多个OCT尺度上计算LCP特征,这使得OCT图像的局部信息和整体信息在提取的特征中互为补充。2017年,Rasti等[10]不仅使用Srinivasan等提供的公共数据集研究了OCT图像的分类和识别,还通过德黑兰的Noor Eye医院建立了另一个公共OCT数据集。使用多尺度卷积神经网络对2个OCT数据集进行分类和识别,并对OCT图像的局部和整体信息进行了组合,该方法可以有效地提高网络的识别能力。
2017年,Karri等[11]也使用了Srinivasan等提出的公共OCT数据集,对OCT图像进行分类和识别,对预训练卷积神经网络(CNN)GoogleLeNet进行了微调,以及对OCT图像进行训练和分类,从而可以训练神经网络,并通过使用有限的数据获得良好的效果。2019年,Feng等[12]还使用转移学习对OCT图像进行分类,以减少对数据集大小的依赖,以及对预训练的VGG16进行了微调和培训。文献[11-12]提出的迁移学习以减少神经网络的训练参数,从而减少了对数据集大小的依赖,但是这种方法对不同数据集之间的差异泛化性能较差。Juan等[13]通过彩色眼底图像利用VGG19,GoogLeNet,ResNet50和DeNet神经网络对青光眼疾病的识别和诊断性能进行了全面的比较分析。文献[14]提出了一种基于ResNet50的深度哈希算法来执行图像检索和分类任务。
文献[15]提出了一种自动聚焦层,可以自动为每层特征图分配相应系数,以突出某一特征的重要性。FractalNets[16]和Multilevel ResNets[17]实现了递归地扩展多个路径。InceptionNets[18-21]仔细地为每个分支配置了自定义的内核过滤器,以聚合更多信息性和多样化的功能。由于使用预训练模型或者迁移学习对图片进行识别和分类,仅在一定程度上可以改善实验效果。受文献[9]中提取图片多尺度特征方法的启发,并根据现有数据集的实际情况,本文在文献[22]上进行了改进。值得注意的是,本文提出的模型虽然遵循了InceptionNets 的思想,即为多个分支结构,但在至少3个重要方面有所不同:①本文提出的方法更简单,泛化性能更强;②实现神经元的自适应感受野大小;③将多条路径的信息进行选择时既考虑了样本特征与各类别的相似性,又考虑了样本特征间相对重要性,最终得到一个全局的、全面的选择权重表示。
2 网络架构
为了实现神经元自适应地调整其感受野大小,本文采用了SK在多个尺度的卷积核之间进行自动选择操作。具体来说,本文通过3个阶段:分割、融合和选择来实现SK卷积,如图1所示。其中,图1展示了2个分支的情况。虽然在该结构图中只有2种尺度的卷积核(卷积核大小同为3×3,扩张率分别为1和2),但很容易扩展到更多路径的情况。

图1 多层次可选择核卷积网络结构图Fig.1 Overview of multilevel selective kernel convolution network
2.1 分 割

2.2 融 合
本文期望神经元能够根据刺激内容自适应地调整其感受野大小。主要的思路是通过门控使得承载不同信息量的2个分支信息流进入下一层的神经元。为了实现这一目标,各部门需要整合2个分支机构的信息。本文首先通过元素求和将来自2个分支的结果融合在一起,表示为

(1)
然后,仅使用全局平均池来生成按通道的统计信息s∈C便可嵌入全局信息。具体来说,s中的第c个元素是由U缩小至空间维度H×W计算所得,表示为

(2)
此外,z∈d×1用于表示特征更精确和自适应选择的结果。通过简单的全连接层实现,降低了维度,同时提升了效率。
(3)
(3)式中:δ表示激活函数ReLU[21],B表示批归一化;W∈d×C。引入缩减比r来研究维度d对模型效率的影响,其中,L=32表示d的最小值。
d=max(C/r,L)
(4)
2.3 选 择
通过压缩后的特征表示z,跨通道的软注意力用于自适应地选择信息的不同空间比例。具体来说,分别将softmax,sigmoid运算符应用于通道数字,即
(5)
(5)式中:A,B∈C×d,a和b分别表示和的软注意力向量。Ac∈1×d表示A的第c行,而ac表示a的c个元素,Bc和bc同理。然后将2个分支卷积核上的注意力加权求得各层次的特征图,即

(6)
(6)式中,V=[V1,V2],Vc∈H×W。最终图片的输出表示O由V降维得到。值得注意的是,本文仅讨论了为双分支情况,可根据需求增加不同尺寸卷积核通过扩展至多分支。
3 数据集及参数设置
3.1 数据集描述
本文采用了公开数据OCT2017和SD-OCT。第1个数据集OCT2017的原始训练集为来自4 686名患者的83 484张OCT图片,其中与年龄相关的湿性黄斑变性(CNV)有37 205张,与年龄相关的干性黄斑变性(DRUSEN)有8 616张,另外糖尿病性黄斑水肿(DME)有11 348张,正常图像(NORNAL)有26 315张。测试集是来自于633名患者的CNV、DRUSEN、DME、NORMAL各250张图片。本文对数据集OCT2017做了下采样处理,以黄斑变性的数据量8 616为基准,对各个类别进行等样本随机采样,然后按照训练集测试集比例8∶2进行数据划分。第2个数据集SD-OCT包含许多眼球图像,而不仅仅是视网膜图像,因此需要适当地筛选。经筛选后,该数据集中有5 084张图片,其中,1 185张为DME,1 524张为AMD,2 375张为正常。表1显示了本文2个数据集的主要统计数据。
由于2个公共数据集的质量和大小不同,因此将它们分开进行训练和评估,这也可以验证不同神经网络模型对数据集差异之间的差异泛化性。图2、图3分别展示了2个数据集的样例。

表1 数据集统计Tab.1 Dataset statistics

图2 OCT2017数据集图片示例Fig.2 Sample demo of the dataset OCT2017

图3 SD-OCT数据集图片示例Fig.3 Sample demo of the dataset SD-OCT
3.2 实验环境及模型参数配置
本文实验代码基于Python3.6,pytorch版本为1.8,torchvision 版本0.7.0,Linux系统版本为16.04,GPU配置为Tesla V100-PCIE。在网络训练过程中,将学习率设置为0.001,损失函数为交叉熵损失,优化方式为SGD梯度下降法,Batch size大小设为30。
3.3 统计评价指标
由于不同评价指标对实验结果的评估意义不同,所以本文使用了常用的正确率、精准率、召回率3种评估指标对实验结果进行评估。另外为了使实验更加简洁易懂,将使用混矩阵将每一类数据的分类结果展示出来。其中,正确率、精确率、召回率分别定义为
(7)
(8)
(9)
(7—9)式中:TP代表把正样本预测为正样本的样本数量;TN代表把正样本预测为负样的样本数量;FP代表把负样本预测为正样本的样本数量;FN代表把负样本预测为负样本的样本数量;TP+FP代表预测为正样本的全部样本数量;TP+FN代表正样本的全部数量。
4 实验结果分析
4.1 基线模型介绍
VGG16卷积神经网络是牛津大学在2014年提出来的模型VGG[24]的变种。作为深度学习基础网络,它不仅简洁且实用,VGG16在图像分类和目标检测任务中都表现出非常好的结果。
RepVGG[25]用结构重参数化(structural re-parameterization) 实现VGG式单路极简架构,一路3×3卷到底,在速度和性能上达到先进水平。
ResNet-50是残差网络 (residual network) 的典型网络,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分。
Res2Net-50[26]用一个较小的3×3过滤器取代了过滤器组,同时可以将不同的过滤器组以层级残差式风格连接。模块内部的连接形式与残差网络类似。
SENet[27]采用了聚合和权重分配(squeeze-and-excitation, SE)模块主要为了提升模型对通道特征的敏感性。SKNet与SENet相似,SKNet主要是提升模型对感受野的自适应能力。
MSKNet*为本文模型的变形,将MSKNet的2个分支改为同为扩张率为1的3×3卷积核。
4.2 模型结果对比
4.2.1 主要实验结果
表2为改进模型MSKNet与基线网络在2个数据集上的主要实验结果,其中带下划线数据为不同网络在各类别中分类准确率最高的结果,而通过这些数据可以看出,本文改进模型不管与原模型SKNet相比,还是与其他基线网络相比,都是最具优势的模型,在2个数据集上分别达到了95.39%和99.18%的分类效果。
通过表2在2个不同数据集上的实验结果显示,本文模型MSKNet不仅相对于现有模型的实验结果有一定提升,还证明了本文模型具有较强的泛化性能,能学习到图像中视网膜病变区域的有效特征,从而正确识别视网膜疾病。此外,从数据集SD-OCT的3分类到OCT2017的4分类,分类难度增加,但实验结果显示出本文模型MSKNet提升更多。
4.2.2 混淆矩阵
为了更好地证明本文创新点的可行性,本文将以OCT2017数据集为例对7个模型的实验结果通过混淆矩阵进行了进一步地展示,结果如图4所示。
图4中,类别0.0,1.0,2.0,3.0分别代表CNV,DRUSEN,DME,NORMAL。从模型的角度来看,本文模型的混淆矩阵对角线上的正确分类中是5种模型中最多的,这证明了本文模型在视网膜疾病识别任务中有很好的效果。与VGG16的分类结果相比,本文模型的优势更加明显,在4分类任务中分别多了130,116,188,86个正确预测样本。这进一步说明本文创新点的可行性和有效性。从数据集的角度来看,无论是哪种模型,都容易将样本2预测为样本0,将样本3预测为样本2。对于这2种较难分类的情况,本文模型却在5种模型中分类效果最好,即错分的样本数最少。
4.2.3 准确率与训练轮数关系
随着模型的训练次数增加,模型的精确率会逐步趋于稳定。无论在OCT2017数据集上还是SD-OCT数据集上,当模型训练到达150轮左右时,测试集精确率都逐渐趋于稳定,如图5所示。不同数据集的测试结果显示,本文提出的模型要显著优于已有的基线模型SENet及SKNet,这表明了本文模型的泛化性强,在疾病诊断中更具有实际价值。进一步比较可发现,OCT2017数据集的准确率要低于SD-OCT数据集,这反映出数据集的复杂度更高,但本文提出的MSKNet的优势更加明显,证明在复杂的环境下本文模型对视网膜病变区域识别效果更显著。

表2 实验结果比较Tab.2 Experiment results
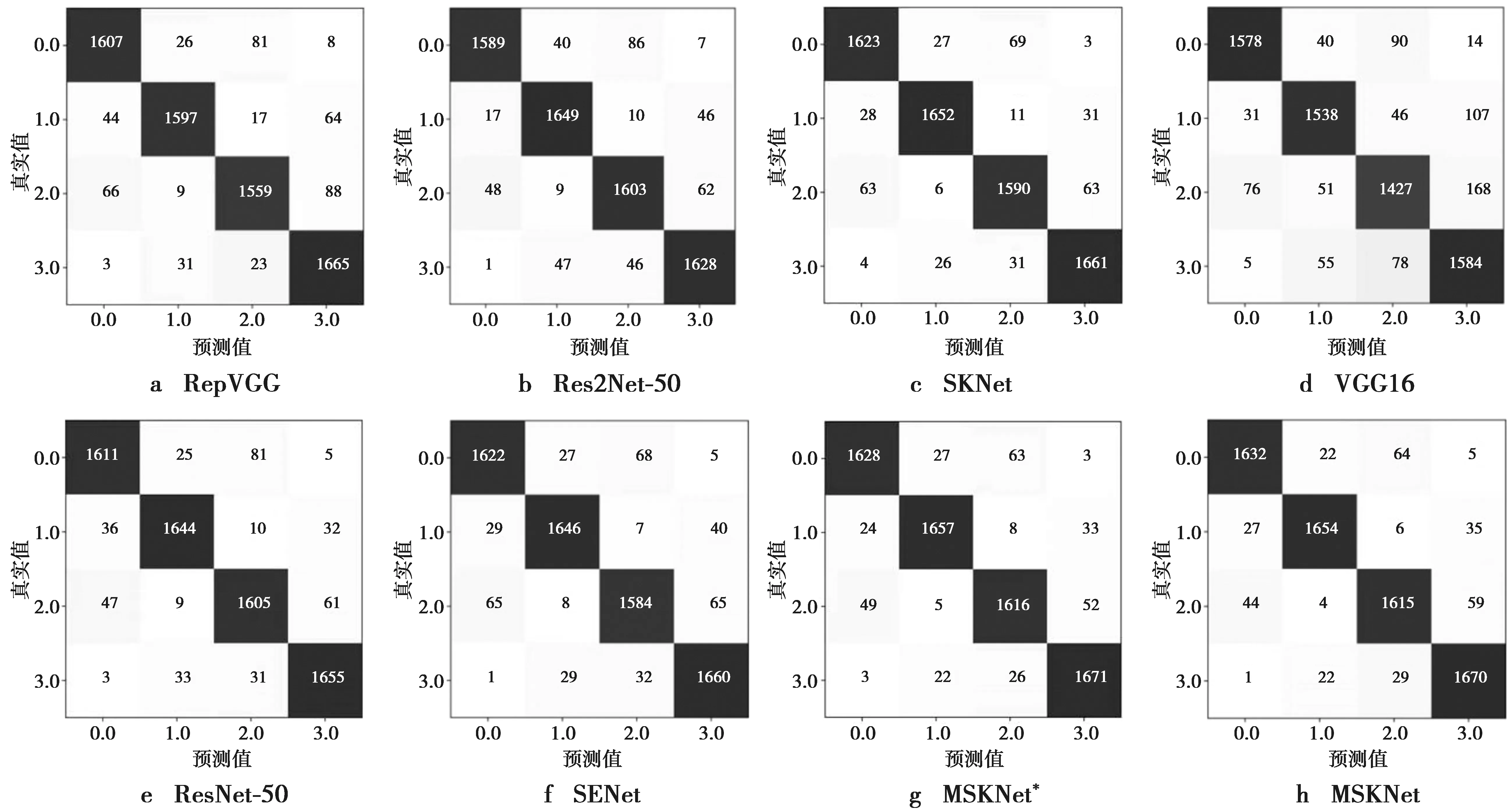
图4 数据集OCT2017中模型混淆矩阵Fig.4 Models confusion matrix in dataset OCT2017

图5 不同数据集下训练准确率与训练轮数关系Fig.5 Relationship between models and training step
5 结 论
本文采用可选择卷积核自适应地调整神经元感受野大小,并对来自不同扩张率卷积的特征进行选择操作,既考虑了视网膜病变种类间的相对重要性,又保持了图片特征与各类别独立相似性。具体来说,本文引入了一个SK卷积,它由3个阶段组成:分割、融合和选择。分割阶段生成多条路径,这些路径具有相同的卷积核但不同的扩张率,对应不同的神经元感受野大小。融合阶段将多条路径的信息进行组合和聚合,得到一个全局的、全面的选择权重表示。选择操作再根据2种权值自身相似性和相对相似性选择权值对不同扩张率路径上的特征映射进行聚合。大量实验结果表明,本文提出的多层次可选择卷积核网络较目前其他主流算法具有显著优势。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11 09:53:56
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:28
中医眼耳鼻喉杂志(2021年2期)2021-07-21 08:53:34
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
湖南中医药大学学报(2016年1期)2016-12-01 04:08:18
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
