
基于深度特征选取的旋转机械跨域故障诊断*
2022-10-26 10:13何财林费国华宋俊材
机电工程 2022年10期
何财林,费国华,朱 坚,董 飞,宋俊材
(1.浙江工业职业技术学院 机电工程学院,浙江 绍兴 312099;2.嘉兴技师学院,浙江 嘉兴 314001;3.杭州第一技师学院,浙江 杭州 310023;4.安徽大学 互联网学院,安徽 合肥 230039)
0 引 言
旋转机械作为现代工业中的核心设备之一,常在恶劣工作环境和复杂工况下长时间工作,相关部件易受损,一旦发生故障,将严重影响正常的工业生产,并可能造成巨大损失[1]。
近年来,基于数据驱动的故障诊断逐渐成为保障设备安全运行的研究热点。针对实际工业中的旋转机械,如何从数据中挖掘有效信息,高效、准确地识别变工况下机械故障状态,成为当前研究难点之一[2]。
随着机器学习等一系列人工智能方法的快速发展,数据驱动的故障诊断方法中,基于人工智能的故障诊断方法逐渐成为研究热点[3,4]。
当前,深度学习方法凭借其强大的隐藏特征挖掘能力,受到许多研究者的关注和研究。例如,金江涛等人[5]提出了一种低维抽象特征提取方法,再结合长短期记忆网络和支持向量机,训练了故障诊断模型,提高了模型的收敛速率;但该研究未考虑变工况带来的数据分布差异对模型泛化性能的影响。赵志宏等人[6]提出了一种采用多任务深度学习方法,以此来增强模型的故障特征提取能力,进而提高故障诊断的准确率。任胜杰等人[7]提出了利用时频分析方法常数Q变换提取信号时频谱图,再输入深度网络,完成不同负载以及含噪情况下的故障识别;但是该模型未充分考虑不同负载下故障样本间分布差异。HE Z等人[8]提出了在少量样本情况下,预训练深度多小波自编码器网络,再进行深度模型迁移,完成了对新样本的故障识别。MAO W等人[9]提出了将特征样本的判别信息引入深度自编码器网络的训练,以获取更有益于故障识别的深度特征。
虽然上述基于深度学习的故障诊断方法获得了许多研究成果,但将其应用于实际工业场景中的旋转机械时,仍面临两方面问题[10]:(1)缺少足量的有标签故障样本;(2)不同工况下,相同故障类别下的样本存在分布差异,而大多数基于深度学习的模型是在训练样本与测试样本同分布情况下训练获得,因此,导致故障诊断模型对不同工况下样本的故障识别效果不佳。
针对上述问题,迁移学习方法在近年来逐渐受到了研究人员的关注。它能够通过从已有领域(源域:已有工况下带标签故障样本)挖掘学习知识和训练故障诊断模型,对来自不同领域(目标域:其他工况下无标签故障样本)的故障样本进行识别分类[11]。
张西宁等人[12]提出了一种利用有限的源域样本预训练的深度卷积网络,再进行模型微调,迁移至目标域,一定程度上克服了缺乏足量有标签样本的问题,完成了对不同工况下轴承故障进行诊断的目标。LIU S等人[13]提出了一种基于敏感特征迁移学习和局部最大边界判别的故障诊断方法,完成了变工况下轴承状态识别的目的。LEI P等人[14]提出了一种基于自适应流形概率分布的迁移故障诊断方法,通过对源域和目标域数据分布对齐的方式,完成了对目标域的自适应和跨域故障诊断。
虽然,上述文献中实现了迁移学习方法在旋转机械中的应用,但其更多地关注于模型的迁移或者减小域间分布差异,缺乏对所提取特征的域不变性和判别性能的综合考虑,而这些性能对于提高模型跨域故障诊断的有效性与泛化能力有重要影响[15]。
基于上述背景,笔者提出一种新的面向实际工业场景的跨域故障诊断方法,即使用特征选取方法对深度特征进行域不变性和类别区分度的量化评估,选取域不变性和类别区分度好的特征作为可迁移特征;改进联合分布适应进行特征迁移学习,降低源域和目标域间分布差异;最后利用迁移学习后的深度特征训练跨域模式识别分类器,以实现跨域故障诊断。
1 基于深度自编码器的特征提取
1.1 深度自编码器(DAE)
自编码器是一种能够从无标签样本中提取隐藏特征的神经网络,包括编码和解码两个部分。输入无标签样本时,会经编码层映射变换到隐藏层,隐藏层再经解码层映射变换得到重构输出层。
一个自编码器网络如图1所示。
其隐藏层由下式计算获得:
hn=fact(W·x+b)
(1)
式中:fact—激活函数;W—编码权重矩阵;b—偏移向量。
隐藏层通过如下表达式映射变换得到解码层:
zm=fact(W′·hn+b′)
(2)
式中:W′—解码权重矩阵;b′—偏移向量。
自编码器网络以最小化重构误差为优化目标,获得网络的参数θ={W,b,W′,b′}。
优化目标的表达式如下:
(3)
在自编码器的基础上,通过多个自编码器网络的堆叠,即前一个自编码器网络的隐藏层作为下一个自编码器网络的输入层,可获得深度自编码器网络。利用这种堆叠方式构建的深度网络,能够进一步提高模型的深度特征提取能力,进而挖掘出更好的深度特征用于故障模式识别与分类。
一个深度自编码器网络如图2所示。
1.2 深度特征提取
图2中,深度自编码器网络中包含多个自编码器子网络,每一层自编码器网络的隐藏层作为下一层自编码器网络的输入层,如此堆叠多层,可从最后一层自编码器网络获得深度特征。
鉴于深度学习网络强大的隐藏特征提取能力,为获取更多的深层特征用于故障模式识别[16],笔者分别采用不同激活函数下的深度自编码器网络进行深度特征提取,构建深度特征池(deep feature pool, DFP)。
深度特征池的构建如图3所示。
激活函数如表1所示。
笔者采用表1中5种激活函数构建5个深度自编码器网络,原始信号经每个深度自编码器网络提取出一个深度特征集,最后将所有深度自编码器网络提取出的深度特征集融合为一个特征池,用于后续的特征可迁移性评估。

表1 激活函数
2 面向跨域诊断的深度特征选取
2.1 K-means
K-means是一种经典的聚类算法,该算法调整的兰德指数(adjust rand index, ARI)不仅可以对数据聚类结果进行评价,还能够对不同类数据间的相似度进行评估。
给定一组样本X={x1,x2,…,xN},Y={y1,y2,…,yN}为样本X经聚类分析后得到的类别,C={c1,c2,…,cN}为X的真实类别,则调整兰德指数的表达式如下:
(4)
式中:a—Y和C中同属于一类的样本数;b—C中同属一类而在Y中不属一类的样本数;c—C中不属一类而在Y中同属一类的样本数;d—在Y和C中均不属一类的样本数。
因此,调整兰德指数能够用于评估特征的在不同类别样本间的区分度,调整兰德指数值越大,表明该特征的类别区分度越高,越有益于分类。
2.2 多核最大均值差异(MK-MMD)
目前,最大均值差异是被广泛用于迁移学习中度量不同域间数据分布差异的方法。给定两个概率分布不同的数据样本DS={x1,x2,…,xnS}(源域)和DT={y1,y2,…,ynT}(目标域),样本数分别为nS和nT。
该两个数据样本间边缘概率分布的最大均值差异为:
(5)
式中:H—再生核Hilbert空间;φ—H中的非线性映射函数。
两个数据样本间条件概率分布的最大均值差异为:
(6)
式中:C—样本的类别数。
根据相关研究结果,多个不同内核混合的最大均值差异,能够提高迁移学习模型的自适应效率。因此,笔者将式(5,6)中的H采用不同的内核,多个内核的Hk为:
(7)
式中:K—内核总数;kθi—带宽为θi的高斯核。
2.3 基于ARI与MK-MMD的迁移特征选取
为从深度特征池中选取更有益于迁移学习的深度特征,笔者提出一种面向迁移学习的深度特征选取方法(transferred features selection based on ARI and MK-MMD, TFSAM),从两种角度对深度特征进行量化评估:特征的判别性能和域不变性。
首先,笔者利用K-means算法对由源域数据训练得到的各深度特征样本进行聚类分析,获得各特征的调整兰德指数指标,调整兰德指数值越大,表明该深度特征的类别区分度越好,有益于分类;
然后,计算源域和目标域中正常状态下的特征样本间多核最大均值差异,对特征跨不同域时的不变性进行量化,多核最大均值差异越小,表明特征的域不变性越好;
最后,基于前两步获得的调整兰德指数与多核最大均值差异,构建深度特征可迁移性指标,量化各特征的可迁移性,可迁移性指标值越大,则可迁移性越好。
笔者将基于各深度特征的可迁移性指标值,从深度特征池中选取一定数据的深度特征,重构训练特征集,进行特征迁移学习,用于跨域故障诊断。
TFSAM的步骤概述如下:
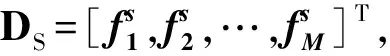
(8)
利用K-measn算法获得各特征样本的调整兰德指数值,M种特征的调整兰德指数值值构建一个序列,即:
ARI={ari(1),ari(2),…,ari(M)}
(9)
(2)基于多核最大均值差异的特征跨域不变性评估。基于DS和DT中的在设备正常状态下提取的特征样本,计算特征在这两个域之间的多核最大均值差异值,量化该特征的跨域不变性。
基于式(5),可得到M个特征的多核最大均值差异值序列:
MKMMD={mkmmd(1),mkmmd(2),…,mkmmd(M)}
(10)
(3)构建特征可选性的量化指标,即ARI与MK-MMD比(ratio of ARI and MK-MMD,RAM)。
为从两种角度对深度特征进行量化评估,综合考虑特征的判别性能和域不变性能,笔者提出一种新的特征可选性量化指标RAM,其表达式如下:
(11)
因此,可得到包含M个特征的RAM值的序列为:
{ram(1),ram(2),…,ram(M)}
(12)
笔者认为,RAM值越大的,表明特征的类别区分度好,即判别性能高,同时其在不同工况下的分布差异小,即跨域不变性好。因此,RAM值大的特征,其用于后续迁移学习的价值越高,更有利于提高迁移学习效果,训练出的故障模式识别分类器的跨域识别分类性能越好。
最后,笔者对M种特征的RAM值进行大小排序,选取RAM值大的特征用于下一步的特征迁移学习。
3 基于DFS与TL的跨域故障诊断
3.1 联合分布适应(JDA)
联合分布适应是一种基于特征的迁移学习方法。该方法针对经典的迁移学习方法迁移成分分析(transfer component analysis, TCA),仅考虑了不同域数据间边缘概率分布的不足,将条件概率分布引入度量数据间分布差异,扩展了非参数最大均值差异来实现同时度量边缘分布和条件分布的差异。该方法概述如下:
给定有标签的源域数据DS={(x1,y1),…,(xnS,ynS)}和无标签的目标域数据DT={(xnS+1),…,(xnS+nT)},假设两个域数据集的边缘概率分布与条件概率分布均不相等,即PS(xS)≠PT(xT)和QS(yS|xS)≠QS(yT|xT)。
联合分布适应算法的目标是:基于DS和DT样本学习得到一个映射变换A,源域与目标域样本经A映射变换后的数据的边缘概率与条件概率分布差异尽可能减小。
这两种分布差异的度量表达式如下:

(13)
式中:M0—最大均值差异矩阵,表达式如下:
(14)
ATxS与ATxT间的条件概率分布的最大均值差异距离为:

(15)
Mc的表达式如下:
(16)
联合分布适应的总优化目标为:

(17)
3.2 改进联合分布适应(IJDA)
虽然联合分布适应同时将边缘概率和条件概率分布引入到降低不同域样本间分布差异过程中,提高迁移学习后模型跨域故障诊断的性能,但是,联合分布适应则忽视了不同数据样本分别在这两种分布上的差异有所不同,有的数据应更多考虑边缘概率分布差异,而有的数据却更应考虑条件概率分布,对此,笔者提出一种改进联合分布适应。
相比于联合分布适应,改进联合分布适应有两方面改进:(1)平衡考虑边缘概率与条件概率分布,在优化目标中引入平衡因子,实现对两种分布适应的调节;(2)为进一步提高迁移学习的效果与自适应效率,采用多核最大均值差异作为数据分布差异的度量方法。
因此,在式(17)基础上进行修改,笔者得到改进联合分布适应的优化目标为:
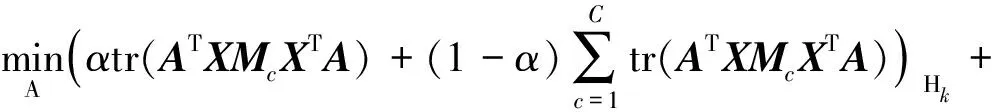
s.t.ATXHXTA=I
(18)
式中,α—平衡因子,α∈[0,1],根据人工经验确定数值。
3.3 基于TFSAM与IJDA的跨域故障诊断方法
在基于深度自编码器的特征提取,面向跨域诊断的深度特征选取以及改进联合分布适应的基础上,基于TFSAM与IJDA的跨域故障诊断(cross-domain fault diagnosis based on TFSAM and IJDA, CDFD-TFSAM-IJDA),笔者提出一种面向实际工业场景中的旋转机械故障诊断方法,。
基于TFSAM与改进联合分布适应的跨域故障诊断方法如图4所示。
该方法包括如下4个步骤:
(1)针对采集自不同工况下的原始振动信号,采用不同激活函数下的深度自编码器网络进行深度特征提取,构建深度特征池;
(2)面向跨域诊断的深度特征选取。分别采用K-means聚类算法和多核最大均值差异对深度特征池中各特征进行类别区分度和跨域不变性的量化评估,K-means算法处理源域有标签特征数据获得各特征的调整兰德指数值,再基于源域和目标域中正常状态故障特征数据,计算各特征在源域和目标域间的多核最大均值差异,基于特征的调整兰德指数与多核最大均值差异,构建深度特征可选性指标,选取有利于后续特征迁移学习的深度特征;
(3)特征迁移学习。基于笔者提出的改进联合分布适应,对源域和目标域特征集进行迁移学习,降低域间分布差异,获得迁移学习后的训练集与测试集,用于后续的故障模式识别分类器训练与测试;
(4)训练故障模式识别分类器并输出结果。基于第(3)步获得的源域和目标域特征集,利用源域特征集训练经典模式识别分类器(主要有:支持向量机SVM、K近邻KNN或随机森林RF等),最后采用训练后分类器对目标域测试特征集进行故障模式识别与分类,输出跨域故障诊断结果。
4 实验验证
为验证笔者提出的跨域故障诊断方法CDFD-TFSAM-IJDA的有效性与适应性,笔者基于SQI-MFS机械综合故障模拟实验台,采集不同转速情况下的轴承和电机振动信号。
4.1 轴承跨域故障诊断实验
4.1.1 实验数据
笔者分别采集1 200 r/min和1 800 r/min转速下的轴承振动信号作为故障诊断实验样本,设置3种故障类型和3种故障尺寸,加上正常状态下的轴承振动信号,共计10种状态下的轴承振动信号样本。
在每种状态下,笔者利用高速采集卡以16 kHz采样频率采集90组样本,每组样本包含3 000个数据点。
基于上述采集样本,笔者设置两个跨域故障诊断任务:(1)随机抽取1 200 r/min下的30组数据样本作为源域,随机抽取1 800 r/min下的60组数据样本作为目标域,训练跨域故障诊断模型实现对目标域的故障识别与分类;(2)随机抽取1 800 r/min下的30组数据样本作为源域,随机抽取1 200 r/min下的60组数据样本作为目标域。
这两个任务的实验数据集,即轴承跨域故障诊断实验数据集,如表2所示。

表2 轴承跨域故障诊断实验数据集
笔者开展故障诊断实验的装置,即SQI-MFS机械综合故障模拟实验台,如图5所示。
4.1.2 实验结果分析
根据笔者提出的CDFD-TFSAM-IJDA跨域故障诊断方法,首先将原始振动信号作为输入,采用不同激活函数下的深度自编码器网络进行深度特征提取,构建深度特征池。
笔者利用深度自编码器网络提取深度特征池所采用的激活函数,以及深度自编码器网络参数,如表3所示。
笔者将第三层隐藏层作为深度特征构建深度特征池,5个深度自编码器网络,共获得500个深度特征。基于第(1)步获得的深度特征池,再采用TFSAM特征选取方法,对各深度特征进行可迁移性量化评估,获得深度特征可选性指标,再基于该指标选取深度特征构建特征子集,用于后续的特征迁移学习和跨域故障诊断分类器训练;经第(2)步骤选取可迁移性高的深度特征后,再对源域和目标域特征进行迁移学习,降低域间分布差异。最后将迁移学习后的源域特征集用于训练跨域故障模式识别分类器,对目标域进行故障模式识别与分类。

表3 深度自编码器网络参数
为进一步验证笔者提出的TFSAM与IJDA方法的有效性,笔者选择经典的机器学习分类器(SVM,KKNN,RF,SoftMax分类器)和迁移学习方法迁移成分分析,联合分布适应,改进联合分布适应,构建设置多个对比模型,进行了跨域故障诊断性能对比。
对比故障诊断模型如表4所示。

表4 对比故障诊断模型
设置这些对比模型的目的是:
(1)传统机器学习分类器构建的模型与基于深度特征选取和迁移学习构建的模型之间对比,验证跨域故障诊断情况下,后者更具优势,能够取得理想的故障诊断准确率;
(2)仅使用经典迁移学习方法构建的故障诊断模型与基于深度特征选取和迁移学习构建的模型之间进行对比以验证笔者提出的面向跨域诊断的深度特征选取方法的有效性,说明原始的高维深度特征池中,存在大量冗余和干扰特征,选取出判别性能和域不变性好的特征进行迁移学习,更能发挥迁移学习在降低不同域间分布差异的能力,提高模型跨域故障诊断的性能。
在表4模型中,DFP-SVM模型表示源域的深度特征池中所有特征输入SVM分类器,训练故障诊断模型,再对目标域深度特征池进行模式识别与分类。DFP-TCA表示深度特征池直接经过TCA算法进行特征迁移学习,然后再输入SVM分类器,训练跨域故障诊断模型。DFP-TFSAM-JDA表示深度特征池经TFSAM方法进行特征选取后,将选取的特征子集再经联合分布适应方法进行迁移学习,最后再输入SVM训练跨域故障诊断模型,其余结合了迁移学习的故障诊断模型均采用SVM作为最后的模式识别分类器。
对比模型的跨域故障诊断结果如图6所示。
从图6中能够看出:笔者提出的CDFD-TFSAM-IJDA故障诊断方法取得的跨域故障诊断结果最优,在任务1和任务2下的取得的最大故障诊断准确率分别可达92.92%(基于特征可选性指标值降序排列选取232个特征)和95.42%(选取210个特征);
其他模型的最大故障诊断准确率分别为:DFP-SVM(任务1:70.33%,任务2:75.67%),DFP-KNN(任务1:68.17%,任务2:73.33%),DFP-SoftMax(任务1:62.33%,任务2:64.67%),DFP-RF(任务1:69.67%,任务2:76.33%),DFP-TCA(任务1:56.83%,任务2:61.30%),DFP-JDA(任务1:60.00%,任务2:65.50%),DFP-IJDA(任务1:66.00%,任务2:69.67%)。
基于深度特征选取与特征迁移学习的模型故障诊断结果,如表5所示。

表5 基于深度特征选取与特征迁移学习的模型故障诊断结果
表5所示为迁移学习方法TCA,JDA,IJDA与特征选取方法TFSAM结合的故障诊断模型的实验结果。表5中实验结果表明:当笔者选取合适数量的深度特征后,再结合特征迁移学习方法TCA,JDA和IJDA,能够明显提高故障诊断准确率。CDFD-TFSAM-IJDA模型在笔者选取200个深度特征时,任务1和2的故障诊断准确率分别可达90.33%和94.17%,明显高于DFP-IJDA模型的66.00%和69.67%;同样,DFP-TFSAM-TCA和DFP-TFSAM-JDA模型也是在笔者选取合适数量特征时,故障诊断结果得到明显提升。DFP-TFSAM-TCA模型在笔者选取250个深度特征时,任务1和2的故障诊断结果分别为82.50%和80.17%,分别比DFP-TCA模型高25.67%和19.4%。DFP-TFSAM-JDA模型在笔者选取200个深度特征时,任务1和2的故障诊断结果分别为85.00%和87.67%,分别比DFP-JDA模型高25.00%和22.17%。
基于上述实验结果分析,总结如下:
(1)笔者所提出的跨域故障诊断方法CDFD-TFSAM-IJDA在笔者选取合适数量的深度特征时,能够取得理想的故障诊断结果,任务1和2的最大故障诊断准确率分别可达92.92%和95.42%,明显高于其他对比模型;
(2)笔者提出的面向跨域诊断的深度特征选取方法TFSAM,与特征迁移学习方法相结合,能够明显提升模型跨域故障诊断的性能,表明TFSAM方法选取出的类别区分度和域不变性高的特征能够更有利于迁移学习的深度特征,提高跨域诊断精度;
(3)笔者提出的IJDA特征迁移学习方法,与经典的TCA和JDA相比,其降低域间分布差异的能力更优,DFP-IJDA模型的最大故障诊断准确率高于DFP-TCA和DFP-JDA模型。
4.2 电机跨域故障诊断实验
4.2.1 实验数据
为验证笔者提出的CDFD-TFSAM-IJDA方法的有效性和适应性,笔者还采用不同工况下电机故障振动信号,开展了跨域故障诊断实验。
4种故障电机(转子断条故障,绕组故障,转子弯曲故障,单相电压不平衡故障)如图7所示[17]。
笔者在图5所示的试验平台上采集振动信号,设置1 200 r/min和1 800 r/min两种转速,利用高速信号采集卡以16 kHz采样频率采集安装于电机驱动端的加速度传感器信号。因此,笔者分别采集两种工况下5种电机状态振动信号,每种状态采集90组信号,每组信号样本包含3 000个数据点。
基于上述采集样本,与轴承故障诊断实验设置类似,电机故障诊断也设置两个跨域故障诊断任务:(1)随机抽取1 200 r/min下的30组数据样本作为源域,随机抽取1 800 r/min下的60组数据样本作为目标域;(2)随机抽取1 800 r/min下的30组数据样本作为源域,随机抽取1 200 r/min下的60组数据样本作为目标域。
电机跨域故障诊断实验数据集如表6所示。
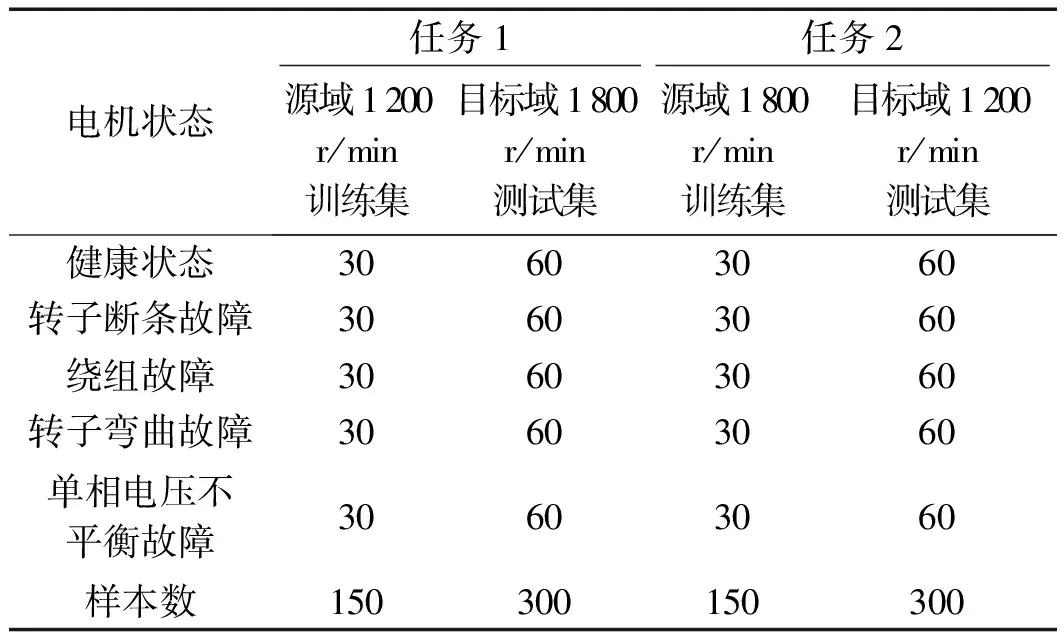
表6 电机跨域故障诊断实验数据集
4.2.2 实验结果分析
笔者基于CDFD-TFSAM-IJDA方法开展电机跨域故障诊断实验分析,实验步骤与上述步骤相同。
首先,笔者将原始振动信号作为输入数据,采用5种激活函数(表1)下的深度自编码器网络进行深度特征提取,构建包含500个深度特征的深度特征池;然后,采用TFSAM特征选取方法进行特征选取,选取类别区分度和域不变性高的深度特征,用于后续的特征迁移学习和跨域故障诊断分类器训练(特征迁移学习是利用IJDA来降低源域和目标域间分布差异);最后,将迁移学习后的源域特征集用于训练跨域故障模式识别分类器,对目标域进行故障模式识别与分类。
对比模型的跨域故障诊断结果如图8所示。
根据图8中的对比结果可知:
CDFD-TFSAM-IJDA故障诊断方法取得的跨域故障诊断结果最优,在任务1和任务2下的取得的最大故障诊断准确率分别可达85.50%(选取185个特征)和88.67%(选取197个特征)。其他模型的最大故障诊断准确率分别为:DFP-SVM(任务1:50.33%,任务2:57.67%),DFP-KNN(任务1:46.33%,任务2:51.00%),DFP-Softmax(任务1:49.67%,任务2:54.67%),DFP-RF(任务1:48.00%,任务2:54.33%),DFP-TCA(任务1:60.33%,任务2:69.67%),DFP-JDA(任务1:66.00%,任务2:72.50%),DFP-IJDA(任务1:73.00%,任务2:76.67%)。DFP-TFSAM-TCA和DFP-TFSAM-JDA模型在任务1和2下的最大故障诊断准确率高于DFP-TCA和DFP-JDA模型。
上述实验结果进一步验证了:
(1)跨域故障诊断方法CDFD-TFSAM-IJDA的有效性与优越性,笔者选取合适数量的深度特征时,能够取得明显优于其他模型的跨域故障诊断性能;
(2)深度特征选取方法TFSAM的有效性;
(3)IJDA特征迁移学习方法,与经典的TCA和JDA相比,其降低域间分布差异的能力更优。
5 结束语
为了解决实际工业场景中,对旋转机械进行故障诊断时存在的标签故障样本不足和数据分布差异问题,笔者提出了一种面向实际工业场景中的旋转机械故障诊断方法,其基于TFSAM与改进联合分布适应的跨域故障诊断方法(CDFD-TFSAM-IJDA)。该方法包含4个步骤:基于深度自编码器的特征提取,面向跨域故障诊断的特征选取,特征迁移学习和故障模式识别分类器训练。为验证CDFD-TFSAM-IJDA方法的有效性与适应性,笔者采用SQI-MFS机械综合故障模拟试验台开展了轴承和电机跨域故障诊断实验。
研究结果表明:
(1)笔者所提出的跨域故障诊断方法CDFD-TFSAM-IJDA在笔者选取合适数量的深度特征时,能够取得理想的故障诊断结果,最大故障诊断准确率明显高于其他对比模型;
(2)笔者提出的面向跨域诊断的深度特征选取方法TFSAM,与特征迁移学习方法相结合,能够明显提升模型跨域故障诊断的性能,表明TFSAM方法选取出的类别区分度和域不变性高的特征能够更有利于特征迁移学习,提高跨域诊断精度;
(3)与经典的TCA和JDA相比,笔者提出的IJDA特征迁移学习方法降低域间分布差异的能力更优,使用了IJDA的故障诊断模型的最大故障诊断准确率高于DFP-TCA和DFP-JDA模型。
下一步工作中,笔者将在当前研究的故障诊断方法基础上,开展针对不同设备中的轴承和电机的跨域故障诊断研究,以及更复杂工况下的故障诊断。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年16期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
舰船科学技术(2022年11期)2022-07-15
读报参考(2022年1期)2022-04-25
一重技术(2021年5期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
科学家(2021年24期)2021-04-25
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
