
基于模式匹配算法的空间属性数据挖掘仿真
2022-10-25 12:15:06曹丽娜
计算机仿真 2022年9期
曹丽娜,王 霞,周 瑛
(石家庄铁道大学四方学院,河北石家庄051132)
1 引言
随着数字化的发展,地理信息系统应运而生。地理信息系统是一种空间信息系统,包含各种地理分布属性数据,海量信息对数据的存储和管理增加了不小的压力。从海量多属性数据中过滤冗余数据,挖掘出主要数据信息难度较大,空间属性数据的准确挖掘至关重要。
卢浩等人提出利用Apriori算法完成数据挖掘。模式匹配算法是一种用于挖掘数据的常用算法,具有简单直接易懂等优点。但该算法运行时间过长。马兰等人以模式匹配算法为基础,提出使用无回溯模式匹配算法进行数据挖掘,解决了普通模式匹配算法不必要的回溯匹配问题,能够提高效率,但数据的复杂程度较高,导致匹配准确性不够理想。
因此本文在上述研究基础上提出基于弱无回溯模式匹配算法的空间属性数据挖掘方法,在保证高效率挖掘空间属性数据基础上,提升挖掘准确性,为数据挖掘提供技术支持。
2 空间数据库
数据库有一般关系数据库、事务数据库等类型,其中地理信息系统使用的数据库为空间数据库,该数据库由相当多的空间数据和属性数据组成,具有特殊重要性。空间数据库系统的语义信息比其它数据库系统更复杂和丰富,但这种丰富也造成更多冗余数据出现。因此从空间数据库中挖掘重要信息和知识尤为重要,这种约减空间数据和属性数据行为称为空间数据挖掘。
地理信息系统的空间数据库中除了有关于对象集合的空间位置和拓扑关系外,还拥有与该对象有关的属性信息。其中空间数据具体包括位置信息和拓扑信息,属性数据具体包括名称、类型和特性等信息。
在空间参照系中空间实体的具体位置以及和其它相邻对象间的关系均可通过空间定位特征确定,由空间数据描述的空间对象都具有这种特征。空间对象还具有由属性数据的属性码和属性值描述的质量特征。
除此之外,空间对象还具有多维特征和时序特征。多维特征中二维指平面,三维指空间位置,在三维基础上加入时间参数是四维,二维基础上加数字地面模型是2+1维,二维基础上加高度属性值是2.5维。空间对象随时间变化的特征称为时序特征。
属性数据反映了空间对象的特征,分为非空间型和空间型两种。类型、名称等为非空间型的特征,边长、体积等则为空间型的特征。
3 空间属性数据的弱无回溯模式匹配挖掘算法
有效结合空间数据库特点,采用挖掘效率和精度更具优势的弱无回溯模式匹配(KMP)算法挖掘空间数据库中的属性数据。
3.1 模式匹配算法思想
设两个字符串和:=,,…,,=,,…,,其中0<<=,表示目标子串,表示模式子串。在中查找与相同的子串即为目的。如果在中查找到子串与相同,则匹配完成,指出该子串在的位置,实现数据挖掘;如果在中有不止一个子串与相同,找出第一个子串即为挖掘成功。若中匹配一次找不到模式为的子串则称第一次匹配失败,此时串移动一个字符位,强制串的指针向前返回,串重新对比串对应字符,进行第二次匹配,这种行为称为算法的回溯。在这种算法下,当中逐渐增大时,回溯次数也随之增加。
这就出现一个问题,最好情况是一次匹配成功,但可能出现最坏情况即最后一次匹配成功——匹配-+1次,每次匹配对比次,共需要对比×(-+1)次,导致匹配挖掘时间大幅增加。由此提出无回溯模式匹配算法。
3.2 无回溯模式匹配算法(KMP)
3.2.1 KMP算法思想
模式匹配算法中的回溯行为是无意义的。比如与字符串中,=,=,〈〉,由〈〉得到〈〉,右移一个字符位再与比较肯定是不相等的,因此一次回溯无意义。而=又能得到=,此时右移一个字符位依然不等于,二次回溯无意义。当右移三个字符位时出现了必要移动,此时串的指针不必向前返回,而是从串中定位一个合适点进行比较。
当串在匹配过程中已经成功匹配[]前的每个字符,而[]≠[],即[1…-1]=t[j-+1…j-1]时,串无回溯。此时判断串右移位数,确定中与中当前字符比较的字符,记为[]。[]位置比[]更靠前,因此比大,则对于不同的值有不同的值,值只由串中的前个字符决定,与串不相关。那么考虑将这个匹配进程加快,通过建立数组先计算出每个[]处的移动值实现。对应i的k值用next[i]表达,当next[i]与0相等时,不需要再将Y串中字符对比t[j];否则匹配过程中出现y[i]不等,next[i]比0大,需要使用Y中第next[i]个字符对比t[j]。
3.2.2 KMP算法
设完成匹配next[i]数组
[初始化]
i←1:j←i
[重复使用next[i]比较]
循环i<=m且j<=n时重复执行
若y[i]=t[j]则i←i+1:j←j+1
否则若next[i]>0则i←next[i]
否则i←1:j←j+1
KMP算法中T串无回溯,受j值持续增大影响导致,出现匹配失败时Y串立即通过next数组移动到合适的位置。
上述算法中j以1为初值,且持续增大,循环过程中始终j<=n,因此算法中最多循环执行n次j←j+1,同样地,i←i+1也最多执行n次。此外i也以1为初值,循环过程中始终i>0,next[i] 目标串T与next无相关性,由模式串Y决定next数组的值。因此next数组的值可在给定模式串Y匹配前预先求得。next[i]由下述k的性质决定,取最大值。 1)1<=k 2)y[1…k-1]=y[i-k+1…i-1] 3)y[k]〈〉y[i] 若k不满足上述条件,取k的值为0。 next[i]的值减去1即为y[1…k-1]中相同的前缀子串和后缀子串的最大长度,因此要找出真子串最值再计算next[i]。实际上确定next[i]值的过程同样是模式匹配,只是模式串和目标串都是Y串。next数组算法见下文。 [初始化] i←1:j←0;next[1]←0[重复对比计算] 循环当i 1)[找到y[1…i]中相同前缀和后缀的最大长度,将此值送j] 循环当j>0,y[i]〈〉y[j]时,反复执行j←next[j] 2)[计数器+1] i←i+1;j←j+1 3)[计算next[i]] 当y[i]=y[j],则next[i]←next[j],否则next[i]←j next数组算法通过无回溯模式匹配算法进行优化可降低其时间复杂度。优化后的算法不需逐个移位,更不需每次移位后都重新进行对比,只需考虑y[1…i]中的前缀和后缀。计算next[i+1]时只需先求得next[1],next[2],…,next[i]的值然后加以利用即可快速匹配,提升匹配效率。任何模式串Y中始终有next[1]=0,由此提供了计算next[i]的基础。 3.3.1 基本思想 KMP模式匹配算法严格查找与模式串相同的字符串,当数据出现信息倒置或修饰等情况,就会影响KMP算法的挖掘准确率。因此对KMP算法进行改进,提出一种弱KMP模式匹配挖掘算法进行空间属性数据挖掘。 目标串中存在部分与模式串相似但不完全相同的字符,KMP算法的严格性会忽略这种相似信息,认为这种目标串并不是完全不匹配模式串,因此利用一些手段重新查找匹配。加入数据准确权数标准和数据增多滑动窗口,此时再进行比对,这种算法称为弱KMP模式匹配挖掘算法。 3.3.2 逆序数 全排列的产生使用从1开始的自然数编号个不同元素。令其中一个为标准排列,若其它排列中存在逆序,该排列的部分元素就与标准排列中这部分元素排列次序相反。一个排列中一共含有多少个逆序,逆序数的数值就为多少。 333 数据准确权数 反应模式串与目标串匹配程度的参数为准确权数。假设一个串由个数据组成,当发生完全匹配时,准确权数就为;当发生不完全匹配时,准确权数设为(0<=<=),则目标串和模式串的匹配程度为。 假设模式串中有个按顺序排列的数据,但这些数据还可以变换顺序,为了求出数据序列的逆序数,编号每个数据,则最大逆序数按照式(1)计算 (1) 将目标数据的准确权数关系式定为式(2) (2) 当=1,=0时,准确率为1。 334 数据增多滑动窗口 假设模式串中有个按顺序排列的数据,当目标串中含有的对应数据比模式串多,长度较长,要分别向前和向后延长滑动窗口,延长长度为所有缺少的数据数。 在本文方法中,当数据准确权数为时,选择KMP模式匹配算法进行数据挖掘即可;数据准确权数为a(0<=a<=n)时,使用弱KMP模式匹配挖掘算法,将滑动窗口延长,扩充进缺少数据,对新的数据计算准确权数,最终结果与原窗口数据的准确权数相加,保证挖掘准确率。 使用本文方法对某地农业空间属性数据库进行挖掘仿真,挖掘2016年到2020年夏玉米和冬小麦的相关数据,其中夏玉米选取6月数据,冬小麦选取4月数据,挖掘结果见表1。 表1 本文方法挖掘空间属性数据 根据表1可知,使用本文方法可对空间属性数据进行有效挖掘。且查阅历史数据,发现本文通过仿真获取的挖掘数据与真实数据误差较小,因此可以确定本文方法在挖掘空间属性数据上的应用性良好。 从数据库中选取三个文档A、B、C,大小分别为95kB、158kB、384kB,采用本文方法分别对其进行匹配挖掘,匹配次数对比结果见图1。 图1 各文档挖掘匹配次数 根据图1可知,匹配次数随着模式串长度增加而相对稳定增加。数据越多,其中可匹配的模式串就越多,因此匹配次数也随之增加。由图2可知当模式串数值较小时,与匹配次数间线性关系较小,出现包含较大数据量的文档C匹配次数比文档A与文档B小的情况;且模式串较小时,越大的文档匹配次数上升趋势也越大。模式串逐渐增大时,文档C的匹配次数上升趋势逐渐放缓,即匹配时间也随之降低,说明本文方法在大量数据中挖掘效率更高。 为了对比本文方法应用的弱KMP算法进行空间属性数据挖掘的优越性,将其与KMP算法和模式匹配算法进行对比分析。从空间属性数据库中选取五个空间属性数据包,大小依次为198k、356k、525k、684k、837k,对比应用三种算法挖掘空间属性数据的时间和准确率,对比结果见图2。 图2 不同数据量下三种算法挖掘性能 由图2(a)可得,三种算法的挖掘时间均受数据量影响,呈正比例关系,模式匹配算法时间消耗量始终高于另外两种算法;弱KMP算法和KMP算法上升趋势更平稳,且前者消耗时间最少。这是因为KMP算法比模式匹配算法少了不必要的回溯匹配过程,大大缩减了挖掘时间,提高运行效率,而弱KMP算法避免了数据出现信息倒置等情况,运行效率更高一点。 由图2(b)可知,模式匹配算法和弱KMP算法在数据量增多时均能保持高准确率,模式匹配算法不断回溯精准匹配对比,而本文应用的弱KMP算法准确挖掘水平也能达到与模式匹配算法不相上下,但时间消耗却缩短了一半。 弱KMP算法挖掘时间消耗偶尔较KMP算法多,但整体时间效率和准确率都比另外两种算法高。与模式匹配算法相比,KMP算法在节省时间上更有优势,而模式匹配算法准确率更高。但弱KMP算法保证时间效率下挖掘准确率也能达到90%以上,主要原因为当模式串中字符顺序发生改变,或者含有其它信息掺杂在一起,KMP算法严格匹配性导致较难准确挖掘,但本文提出的弱KMP算法可通过延长滑动窗口、计算准确权数应对各种复杂变化形式,能够有效匹配,提高挖掘准确率。 综合时间效率与准确率两个方面,本文应用的弱KMP模式匹配算法在空间属性数据挖掘中展现出了较好的优越性。 提出基于弱KMP模式匹配算法挖掘空间属性数据。以数据挖掘时间效率和准确率为测试指标,设计仿真。仿真结果验证了本文方法能够在复杂数据环境中保证高准确率,且大幅提高挖掘效率,具有较好的应用性。3.3 基于弱KMP算法的数据挖掘
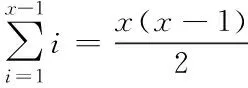
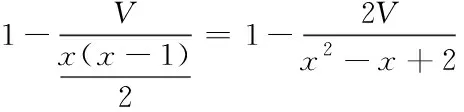
4 仿真研究
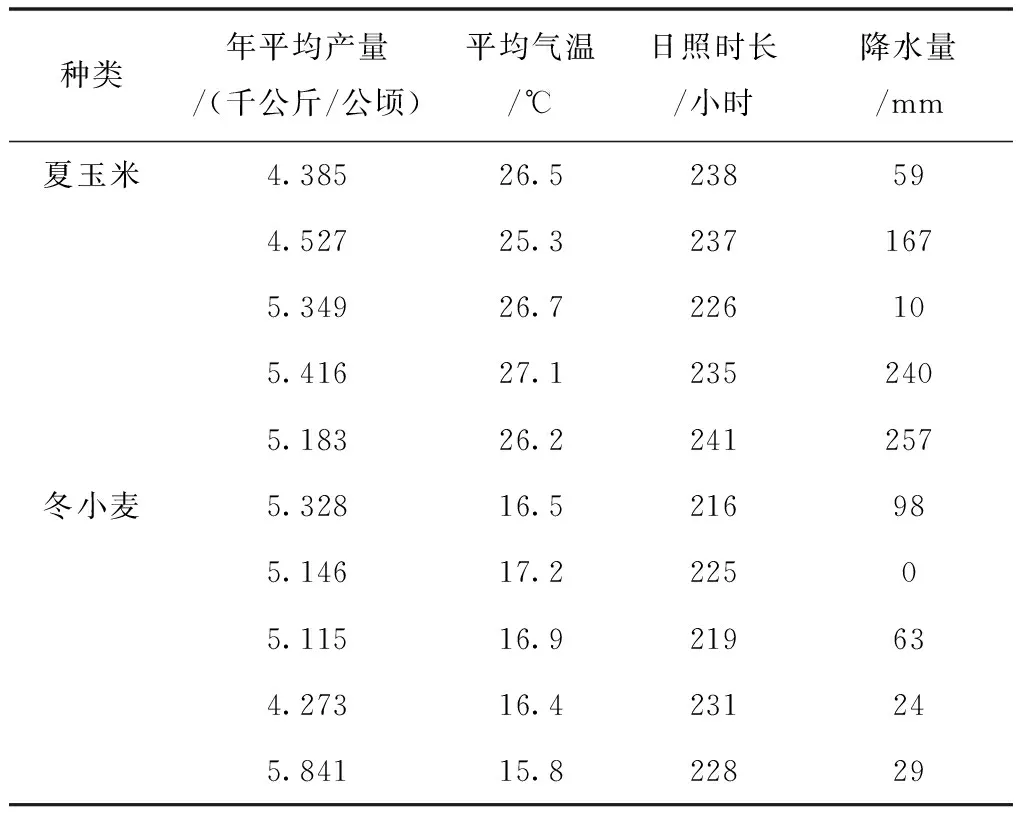
4.1 本文数据挖掘方法的应用效果
4.2 多种类数据文档下挖掘性能分析

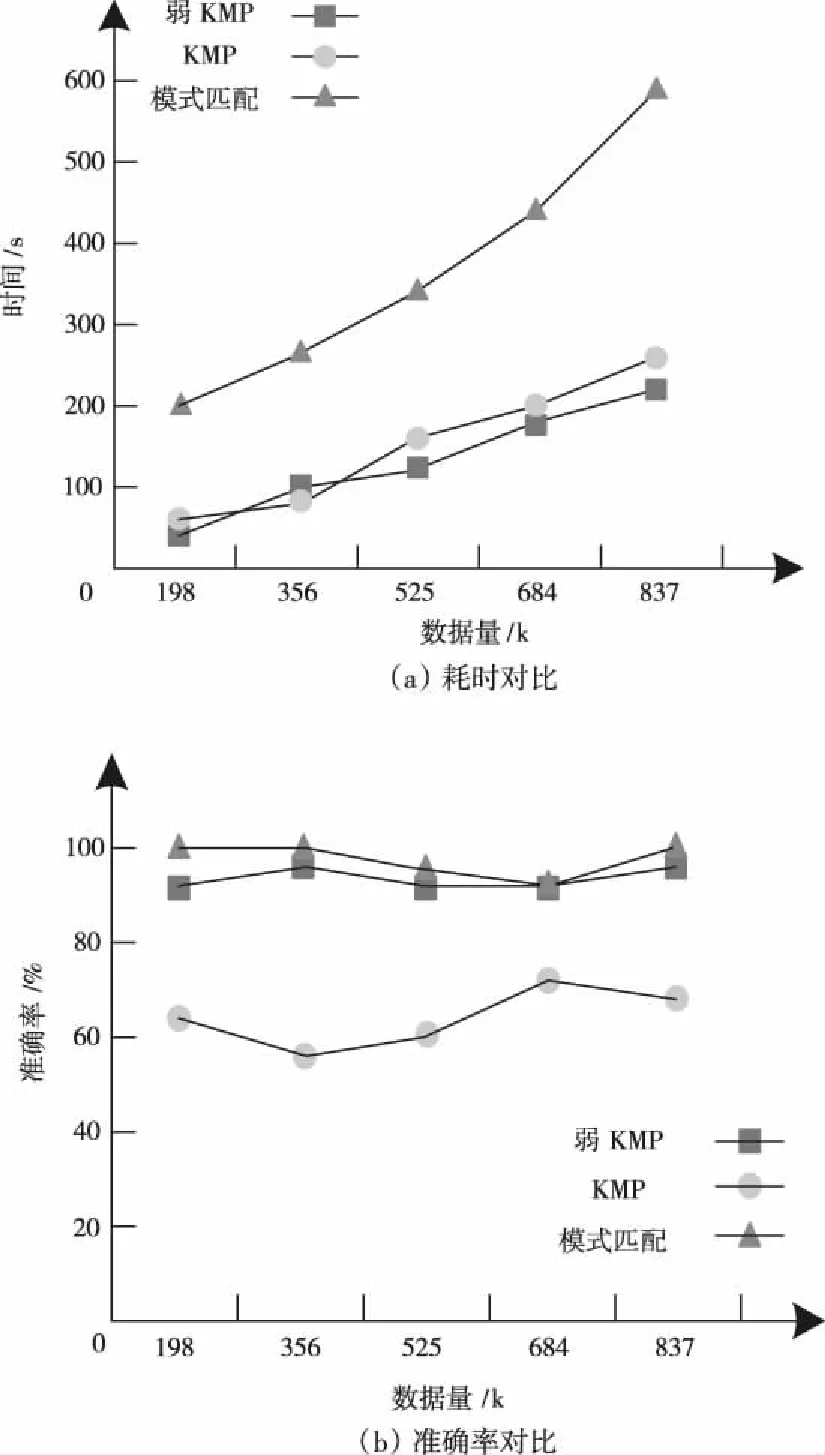
4.3 挖掘效率和准确率测试
5 结论
猜你喜欢
统计与信息论坛(2020年5期)2020-06-03 06:57:04电子制作(2019年13期)2020-01-14 03:15:32科技资讯(2019年18期)2019-09-17 11:03:28中国科技纵横(2019年15期)2019-08-27 03:34:44证券市场周刊(2019年25期)2019-08-16 01:27:48证券市场周刊(2019年26期)2019-07-20 10:00:48教育界·下旬(2019年1期)2019-04-26 10:06:40移动信息(2018年1期)2018-12-28 18:22:52统计与决策(2018年23期)2018-12-21 07:14:20中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
