
基于反向翻译的英语语法纠错应用研究
2022-10-24 01:20孙晓东王丕坤杨东强
计算机技术与发展 2022年10期
孙晓东,王丕坤,杨东强
(山东建筑大学 计算机科学与技术学院,山东 济南 250101)
0 引 言
语法纠错(Grammatical Error Correction,GEC)的主要目的是在不改变语句的基本语义前提下最大限度地纠正语法错误。早期面向英语学习者的GEC研究方法主要以基于规则和统计的模型为主[1]。基于规则的方法人工设定语法规则数据库,只对有限的错误类型有效。而且对于相对复杂的语法错误,需要设计大量的检测和纠正规则,规则之间容易产生冲突。基于统计的GEC方法主要构建统计模型,一定程度上避免了基于规则的GEC方法其纠错类型有限的弊端。在随后出现的基于分类的语法错误纠正方法[2]中,不同错误类型的纠正被看作分类任务,通过结合上下文语境训练GEC分类器进行错误的预测纠正。而对于基于机器翻译的GEC方法主要将语法纠正看做语言翻译任务,利用噪声信道模型生成翻译规则,把错误的源语句“翻译”成正确的目标语句。
相比于上述早期的GEC方法,现阶段基于数据驱动和神经网络的机器翻译方法已成为英语语法纠错的主流[3],其中应用神经网络编码器-解码器结构的模型已经取得显著成效。神经机器翻译(Neural Machine Translation,NMT)是基于神经网络以端到端的方式进行翻译的方法,与早期的机器翻译系统相比,采用注意力机制的NMT模型,解决了上下文中长距离语义依赖的问题,能够更好地实现语法纠正。典型的端到端NMT模型将束搜索(beam-search)得到的解码结果作为输出,同时还引入外部语言模型、编辑距离、编辑操作数等多个特征评价模型的解码输出。
基于NMT的GEC模型性能主要取决于训练数据的数量和质量。由于人工标注数据成本较高,目前研究主要集中在如何自动合成训练数据上。研究表明[4]人工数据合成可以弥补学习者语料库不足的问题,提高GEC性能。对于GEC中数据增广方法,相对于基于错误规则或错误模式的无监督数据产生方法,监督式数据合成方法生成的数据更接近语法错误的实际分布状态,但是监督式数据合成方法需要足够数量的人工标注数据,并且有限的人工标注数据以及其中的错误类型分布和修改风格等会对生成模型的效果产生较大影响。因而通过结合有限的规则和反向翻译模型生成训练数据,不仅可以兼顾质量和数量的优势,还能够提高语法纠错模型的性能。
该文使用Transformer模型[5]分别作为语法错误产生和纠正的基础结构,主要探索结合规则的数据增广方法和反向翻译模型为GEC生成人工合成数据,从而提高语法纠错系统的性能。主要创新在于:
(1)与将人工规则方法产生的数据直接训练GEC模型不同,该文提出将基于规则的数据增广方法与NMT相结合,首先建立语法错误生成(Grammatical Error Generation,GEG)模型,然后将GEG模型产生的合成数据用于GEC模型的预训练。
(2)为了提高GEC模型的错误识别能力,该文提出一种由GEG到GEC再到GEG模型的交替训练结构。使用GEC系统的输出候选句对GEG模型再次训练,以提高其错误生成能力。
对比实验表明,提出的数据增广策略和交替训练方法能够产生更加接近学习者语料库质量的合成数据,并显著提高GEC系统的性能。基于CoNLL-2014和JFLEG测试集的实验结果表明:该方法的GLEU和F0.5值分别达到61%和62%。
1 语法纠正领域数据增广方法相关工作
针对GEC的人工数据增广方法主要有基于人工规则的方法、基于机器翻译的方法以及基于维基百科等社交媒体的修订历史记录方法等。
1.1 基于人工规则
基于规则的数据增广方法是使用限制性规则完成对数据的加噪处理,已成为提高训练数据质量的一种重要手段。该方法简单有效,能够涵盖不同类型的语法错误。例如,在CoNLL-2014测试集上,Xu等人[6]引入五种错误规则合成训练数据,用此合成的数据训练基于NMT的GEC模型,取得优异的结果,F0.5值达到60.9%。在面向GEC的数据增广任务中,人工规则主要利用单词或字符级别上的增加、删除、取代、交换等四种编辑距离及其衍生变种。
1.2 基于机器翻译
基于机器翻译的数据增广方法主要包括两种:基于反向翻译和基于往返翻译的方法。基于反向翻译的数据增广方法是训练一个反向NMT错误生成模型,输入为语法正确的源语句,输出为含有语法错误的目标语句。该方法能够覆盖多种不同种类的错误,但是反向翻译模型往往需要大量带有标注的学习者语料库作为支撑,因而也面临着人工标注数据短缺的问题。基于往返翻译的数据增广方法[7]是训练两个机器翻译模型,首先是由英语翻译到中间语言,再由中间语言翻译到英语。使用往返翻译合成的训练数据可以借助多种中间语言,不需要大量的人工标注数据,翻译模型性能的优劣通常会影响合成数据的质量。该方法存在需要协调不同翻译模型的质量搭配问题。高质量往返翻译模型的合成数据可能不存在语法错误现象,而低质量的翻译模型产生的合成数据可能包含除语法错误之外的其他错误,如源语句的语义信息丢失等。
1.3 基于人工修订
维基百科包含其百科知识修订(wiki-edit)历史页面,可以从中提取相应数据作为“源-目标”语句对,其中源语句由较旧的修订历史提供,目标句是对应较新的连续修订历史提供。除此之外,Lang8作为一个在线的语言学习网站,包含了80多种语言,主要利用社交媒介纠正语言学习中的错误,可以从中挖掘出大量的“源-目标”平行句对。
1.4 评价指标
尽管GEC研究取得了一定的成功,但仍然面临评价指标合理性的挑战。最大匹配分数 (Max Match score,M2)和ERRANT是评估GEC常用的评测方法,主要采用基于Levenshtein距离的对齐策略,计算将纠正语句转换成人工标注的参考语句所需要的编辑(插入、删除、替换)数量。最大匹配分数以精确度(P)、召回率(R)、F0.5值为主要评价指标。计算公式为:
(1)
(2)
(3)
式中,ei∩gi={e∈ei|∃g∈gi,e==g}。其中ei表示GEC系统预测的纠正编辑集合,gi表示人工标注、标准的纠正编辑的集合。通过计算GEC系统输出的纠正编辑集合和人工标注的纠正编辑集合之间的匹配程度来衡量系统的性能。
除此之外,Napoles等人[8]提出GLEU评价句子的流利度,主要计算纠正语句相对于参考语句的n-gram重叠度。原始输入的错误句简称源句S,人工标注的标准句称为参考句R。英语语法纠正系统输出的纠正句子称为假设句C,Wn表示均匀分布的权重。计算假设句相对于参考句的n-gram精度Pn,计算公式为:
(4)
(5)
在BP(brevity penalty) 的计算公式中,c为假设句的长度,r为参考句的长度。GLEU计算假设句与参考句之间的n-gram精度,只适用JFLEG数据集。
2 方法与模型
该文首先利用基于规则的数据增广策略合成训练数据,并与学习者语料共同训练GEG模型。之后利用GEG模型合成的训练数据与学习者语料训练GEC模型。受Popel等人[9]交替训练英语到捷克语的翻译模型工作启发,使用GEC模型纠正学习者语料中的源句,将纠正的结果与学习者语料中的标准参考句重新构成平行语料加入到GEG模型的训练数据中,再次训练GEG模型。模型重复多次训练直到满足系统需要为止,其基本操作过程如图1所示。
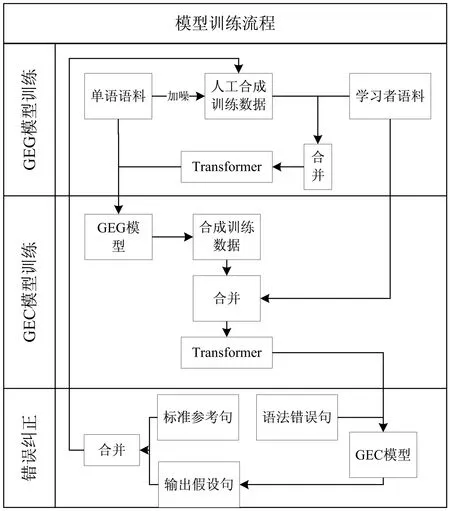
图1 交替训练模型
2.1 基于规则的数据增广方法
人工标注语料库的规模与数量限制了基于数据驱动的神经机器翻译模型的性能,因此,如何通过数据增广扩展语料库规模是提高语法纠错性能的重要因素之一。对于基于规则的数据增广方法,在单词级别上执行插入、替换、交换、删除四种操作,该文四种规则的引入概率与Abhijeet等人[10]保持一致,分别为0.3、0.25、0.25、0.2。其次,通过对学习者语料库中错误类型的分布情况[11]分析,发现动词(约7%)、名词(约4.5%)、冠词(约10.86%)、拼写(约9.59%)、介词(约11.2%)和标点错误(约9.7%)占比较高。针对这些错误类型,分别建立动词、名词、冠词、介词、拼写和标点混淆集,混淆集示例如表1所示。

表1 不同词性候选集示例
合成数据的过程中,对选中的待操作词随机执行插入、删除、替换、交换四种操作之一。对于替换规则,从创建的不同词性候选集中随机选择一个单词进行替换。通过人工规则构建种类丰富的多词性错误可以为GEG和GEC模型提供更多的训练数据。
2.2 模 型
GEG和GEC模型均使用基于注意力(attention)机制的Transformer结构,将GEC和GEG作为基于编码器-解码器的机器翻译任务,反向传播最小化系统输出与真实输出之间的交叉熵损失函数。该模型采用开源的FAIR Sequence-to-Sequence工具包实现,GEG系统解码使用beam search(束搜索)解码。词向量的维度和目标端的维度为512,编码器和解码器包含的网络层为6层,设置前向神经网络子层的隐含层(FFN)维度为4 096,dropout率设置为0.2,优化算法使用Adam,8个注意力头,初始化学习速率为0.002,标签平滑率设置为0.2,warmup步长为16 000。GEC系统使用C-Copy-Transformer结构,模型参数与Zhao等人[12]的设置保持一致。
2.2.1 Encoder
Transformer中attention机制让模型关注到上下文中有价值的信息。当对词进行编码时,不仅仅考虑当前词,还考虑当前词的上下文语境。把整个上下文语境融入到当前的词向量当中。Transformer模型没有循环神经网络的迭代操作,位置信息的融合使模型更容易识别出语言中的顺序关系。编码器由若干层组成,每层包括两个子层,分别是自注意力层和前馈神经网络层。多注意力层拼接成多头注意力层,如公式(6)~公式(9)所示。
attention_output=Attention(Q,K,V)
(6)
MultiHead(Q,K,V)=Concat(head1,head2,…,headn)W0
(7)
(8)
(9)
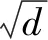
2.2.2 Decoder
解码器与编码器层数一致,包括自注意力层、编码-解码注意力层和前馈神经网络层,编码-解码注意力层将帮助解码器将注意力集中在输入句子的相关部分。编码器和解码器中的每一个子层采用残差连接和归一化,归一化把神经网络中的隐藏层归一到标准正态分布,加快训练速度和收敛速度。
2.3 交替训练机制
不同于以往工作将基于规则的数据增广方法合成的训练数据直接训练GEC模型,该文首先将其用于GEG模型的预训练,然后再使用学习者语料库微调GEG模型,期望通过不同数据增广方法的融合提高合成数据的质量。与Sennrich等人[13]的反向翻译模型近似,使用的目标端句子均具有真实性。为了进一步提高语法纠错的性能,使用GEC模型纠正学习者语料库中的训练数据,并将其纠正结果与训练集中的标准参考句构成平行语料,作为重复训练GEG模型的扩充数据,因而GEG模型将产生更多接近学习者语料库的训练数据。
3 实验与结果分析
3.1 实验数据
在现有NUCLE、FCE、W&I+LOCNESS三种学习者语料库[11]及单语语料库One Billion Word[14]上进行验证实验。除此之外,为了方便与现有工作做对比,在最后使用Lang-8语料微调GEC模型。表2给出了使用的训练语料及相应的数据规模。通过统计学习者语料库中的句长分布,约束单语语料库中句子的长度。其中单语语料库中训练数据长度均被规约到5至100的标记(token)长度大小。

表2 训练语料规模
实验将使用常用的CoNLL-2014测试集和M2作为评测指标,除此之外,还使用JFLEG测试集和GLEU值对GEC的纠正结果进行流利程度分析。
3.2 数据增广过程
3.2.1 基于规则的数据增广方法
步骤1:使用现有的三种学习者语料(NUCLE、FCE、W&I+LOCNESS)训练GEC模型,在CoNLL-2014测试集上验证结果。
步骤2:使用基于规则的数据增广方法分别生成文件规模为20 M(句子数量约190 K)、80 M、140 M、200 M的训练数据,用不同规模的合成数据分别训练GEC模型,对比使用不同规模数据对训练GEC的影响。
3.2.2 基于规则与反向翻译的数据增广融合使用过程
步骤1(GEG1→GEC):使用三种学习者语料训练基于反向翻译的错误生成模型(GEG1),再使用GEG2模型生成训练数据,最后用生成的数据训练GEC模型。
步骤2(GEG2→GEC):为了进一步优化GEG1模型,尝试将两种数据增广方法结合使用。首先使用基于规则的合成数据预训练GEG,再用学习者语料对其微调,得到优化后的错误生成模型GEG2。使用GEG2模型处理单语语料,分别生成文件规模为20 M、80 M、140 M、200 M的合成数据,并将合成的数据用于GEC模型的训练,以此来验证不同数据增广方法的融合使用效果。
3.3 交替训练
步骤1:选取3.2.2节中训练得到的性能最佳的GEC模型处理三种学习者语料库中的源句,将模型输出的候选句与学习者语料库中的标准参考句合成训练集。与基于规则的数据增广方法合成的训练数据混合后再次训练GEG,并使用三种学习者语料库微调得到错误生成模型GEG3。
步骤2(GEG3→GEC):使用GEG3模型处理单语语料库,再次生成20 M、80 M、140 M、200 M不同规模的合成数据,训练GEC模型。
步骤3:在现有合成数据的基础上,为了进一步提高GEC模型的性能,尝试扩大预训练数据规模。
3.4 实验类型与结果
在单语数据充足的情况下,将研究如何使用较少的标注数据最大化模型性能。相对于有限的标注数据,尝试使用较多的单语数据自动生成学习者语料以便提高系统性能。共设置了三组实验:
第一组实验:验证基于规则的数据增广方法效果。
第二组实验:验证基于规则和反向翻译的数据增广方法融合使用的有效性。第三组实验:验证交替训练对提升GEG模型合成数据的质量和提高GEC纠错性能的有效性。
3.4.1 基于规则的数据增广方法结果
分别使用基于规则的数据增广方法生成的不同规模训练数据,以及学习者语料训练GEC模型。其在CoNLL-2014测试集上的结果如图2所示。随着合成数据规模的不断增加,GEC模型的F0.5值达到37.9%,超出仅使用学习者语料库训练GEC模型得到的F0.5值11.4%左右。
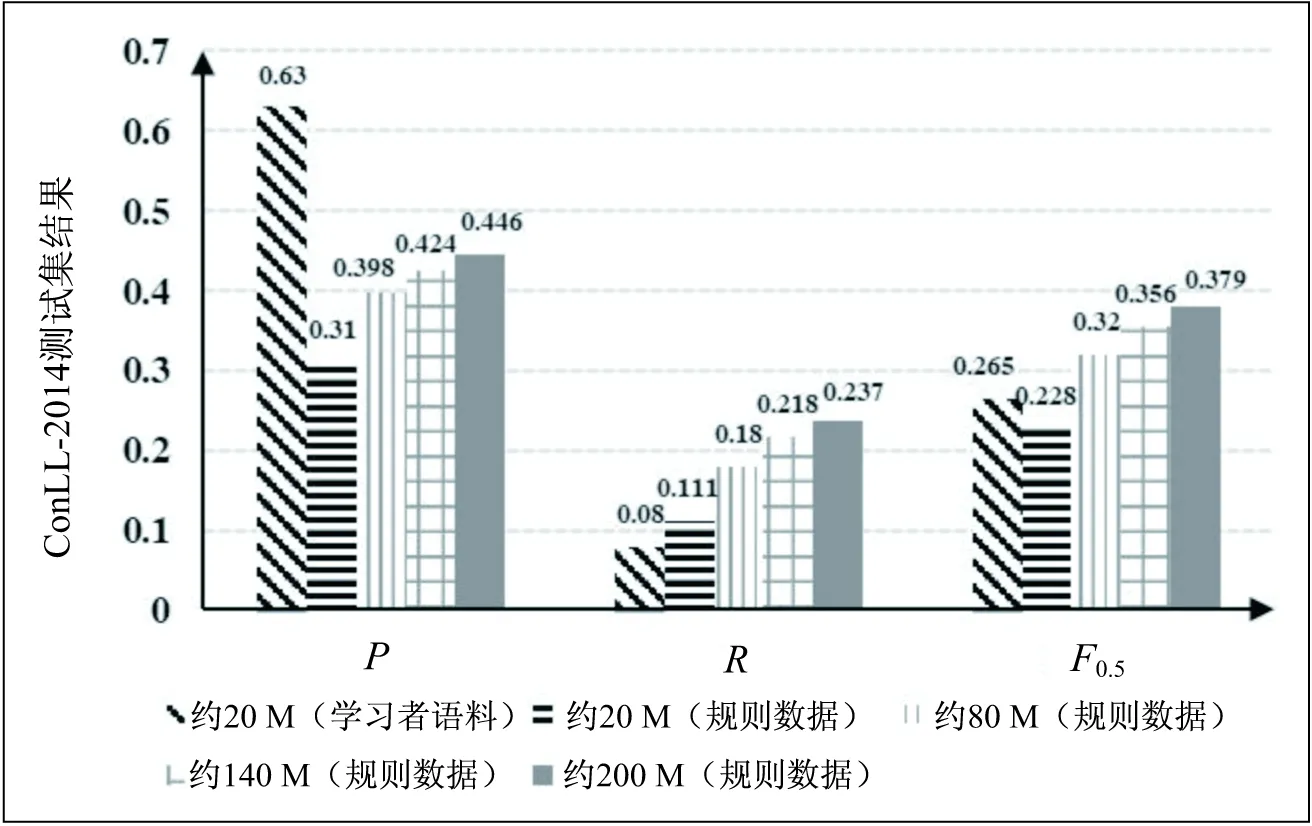
图2 不同规模数据训练的GEC模型性能
3.4.2 基于规则和反向翻译的数据增广方法融合使用结果
在不同数据增广方法融合使用的效果验证过程中,GEG1表示仅使用学习者语料库训练错误生成模型,GEG2表示融合使用基于规则和反向翻译的数据增广方法训练的错误生成模型。使用GEG模型生成不同规模合成数据训练GEC,其结果如表3所示。使用GEG1得到最佳GEC模型的F0.5值达到0.286,使用 GEG2合成的200 M训练数据得到的GEC模型性能比前者的P、R、F0.5值分别提高约5.2%、3.9%、4.9%。
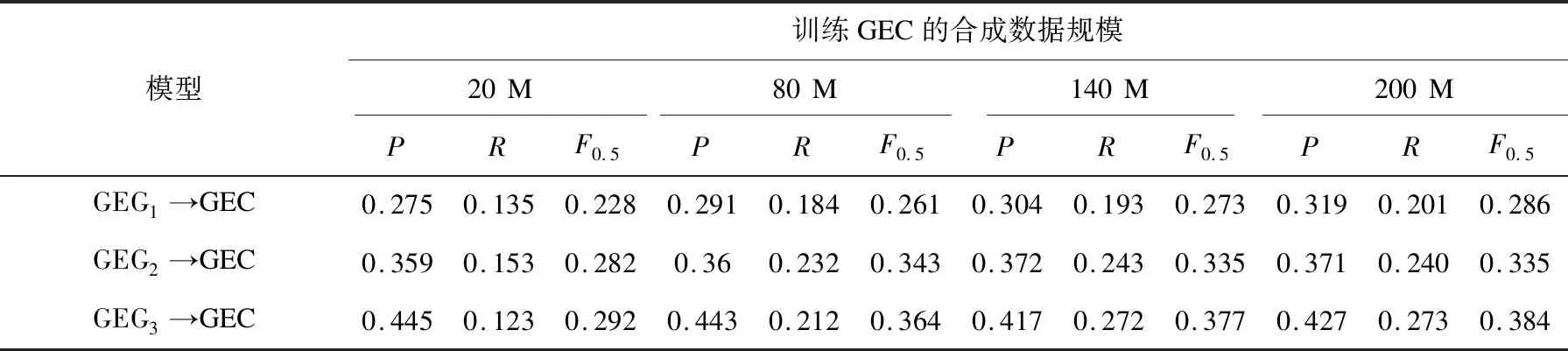
表3 利用合成数据训练GEC性能对比
3.4.3 交替训练结果
如表3模型GEG3→GEC所示,通过交替训练得到的语法错误生成模型GEG3,其合成的训练数据在GEC上的F0.5值达到0.384,高出利用GEG2模型训练GEC得到的F0.5值约4.1%。
如表4所示,如果在GEC训练过程中加入学习者语料进行微调,对于200 M数据预训练GEC而言,利用GEG3合成数据训练GEC模型(GEG3→GEC)的P、R、F0.5值分别达到0.659、0.32、0.543。进一步扩大预训练数据规模,将由GEG3合成的200 M训练数据与基于规则的数据增广方法合成的200 M数据混合后预训练GEC模型,然后使用三种学习者语料微调。由表4的实验结果可知,数据规模扩大后,P、R、F0.5值分别达到0.677、0.338、0.564,超出不使用学习者语料微调GEC模型20%、2%、13%左右。
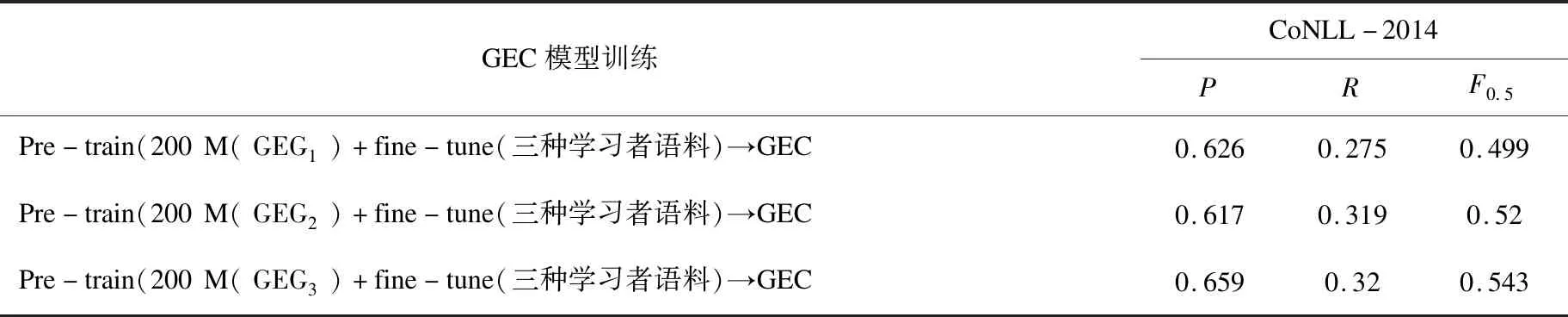
表4 交替训练及GEC预训练模型数据扩充实验结果对比
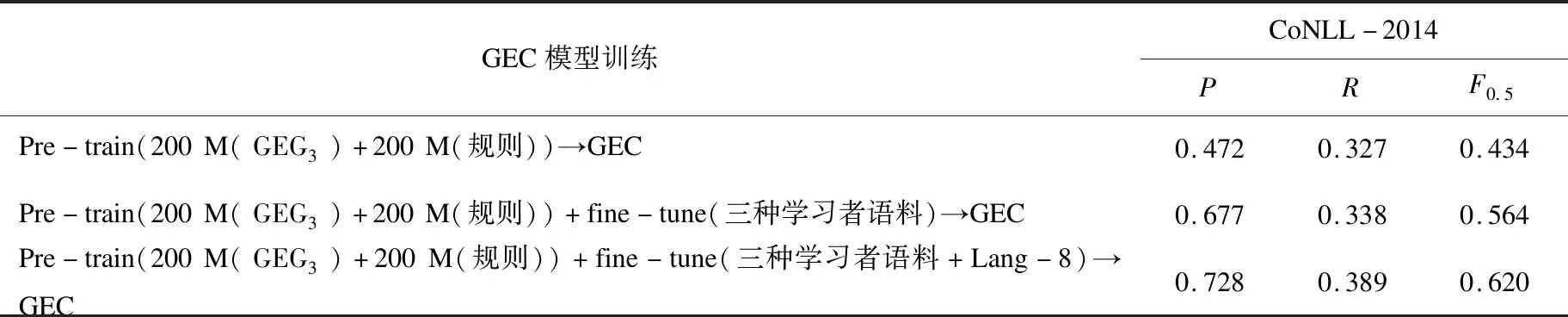
续表4
3.5 现有研究成果
为了更好地与现有工作对比,在三种学习者语料的基础上加入Lang-8语料,仅用于GEC模型的微调,模型性能进一步提高。在没有使用多模型集成和重排序等情况下,GEG3的值F0.5达到0.62,如表5所示。其中,在JFLEG测试集上的GLEU值达到0.61,超出Xie等人[15]在JFLEG测试集结果约5%。该文GEC模型精确度达到0.73,在纠正英语错误的准确度上具有明显优势。
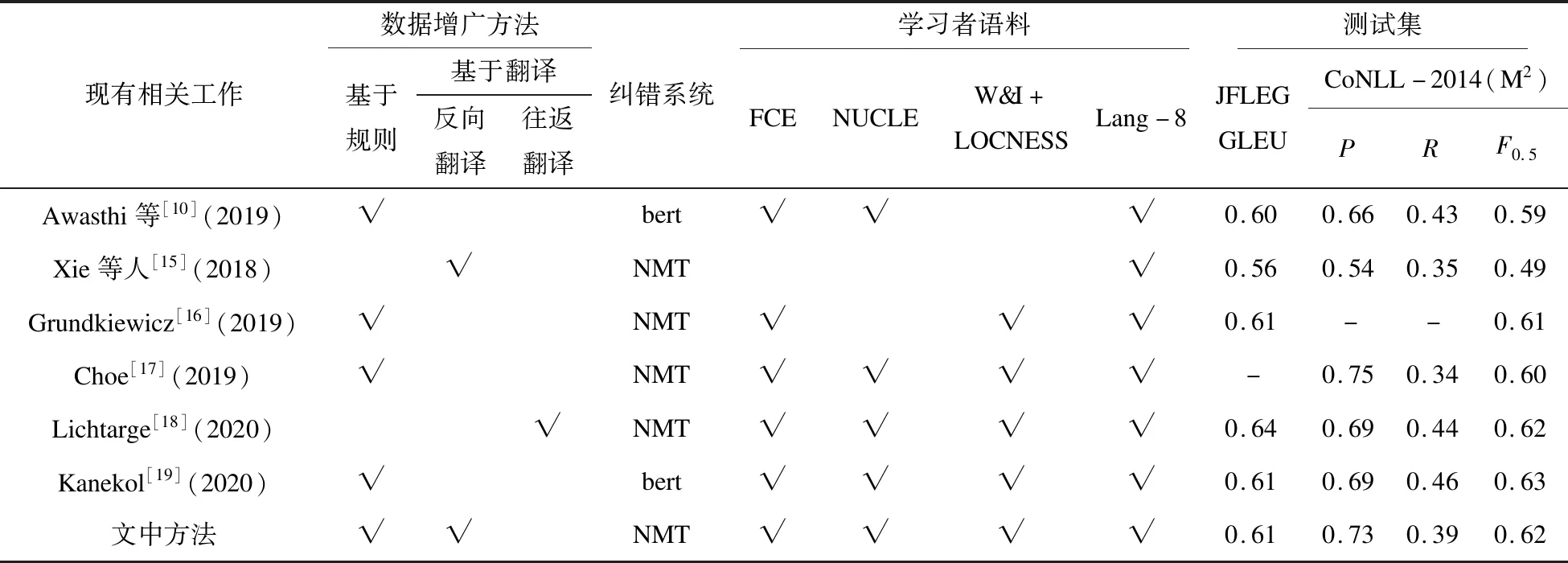
表5 现有工作实验结果对比
3.6 测试实例结果
该文使用GEG1、GEG2、GEG3模型合成的200 M训练数据与三种学习者语料共同训练三种语法错误纠正模型,相应语法错误纠正模型的纠正句分别为纠正句1、纠正句2、纠正句3。源句是包含语法错误句,参考句是标准的纠正句,CoNLL-2014测试集中的部分实例纠正结果如表6所示。结果表明,使用GEG3模型合成的数据训练英语语法纠错模型的性能优于GEG1、GEG2模型。
4 讨论与分析
4.1 不同GEC模型纠正结果对比分析
由表6示例1所示,通过纠正句1,发现模型可以对冠词错误较好的初始纠正,这得益于构建词性候选集融入的冠词错误。纠正句2所有错误均被纠正,源于规则与反向翻译的数据增广方法融合使用,使生成的训练数据覆盖更加丰富的错误类型,合成的数据不受固定规则、固定候选集的的限制,进一步提高GEC模型纠正动词等错误的性能。

表6 GEC模型在不同错误语句中的表现
如示例2所示,纠正句1与源句相比,不存在标点错误,GEC模型对标点错误有一定识别纠正能力。但是纠正句2并没有进一步纠正,说明在某一上下文语境中,GEC模型对特定语法错误的纠正仍存在缺陷。交替训练的使用,部分程度弥补了此缺陷,如纠正句3所示。GEC模型对错误的检测与纠正力度进一步提高,但是仍然存在部分错误未被纠正。
如示例3,通过该文建立的基于规则的数据增广方法,合成的训练数据存在固定词语搭配失误、介词搭配失误、拼写错误等类型,因此训练得到的GEC模型一定程度强化了对此类型的识别与纠正。
4.2 基于规则的数据增广方法结果分析
使用基于规则的数据增广方法,随着数据规模的不断增加,训练得到的语法纠错模型性能不断提高。当使用200 M合成数据训练GEC模型时,其在召回率上的表现超过仅使用学习者语料训练GEC模型的表现,这得益于该文使用的数据增广策略,即在生成训练数据的过程中,融入不同单词的词性错误。与简单的从词表中随机选词替换相比,错误类型更加丰富且具有针对性,召回率得到显著提高。
4.3 基于规则、翻译的数据增广方法融合使用结果分析
该文将规则方法合成的数据与学习者语料共同训练错误生成模型。与直接将规则数据训练GEC模型相比,使用前者错误生成模型合成的数据训练GEC的效果更佳,表明不同数据增广方法融合使用的有效性。如表3所示,与GEG1模型相比,使用GEG2模型产生的80 M合成数据训练GEC模型,提高了纠错模型的召回率和F0.5值。原因是相比于基于规则的数据增广方法,基于反向翻译的数据增广方法为模型提供更加丰富的训练信息。同时,规则合成数据的使用加强了模型对特定规则错误的检测与纠正,最终提高模型的召回率。
4.4 交替训练及现有工作对比分析
由表3可以看出,通过GEG模型和GEC模型的交替训练,再次提高了GEG3的性能。由于交替训练不断强化模型识别不易检测的错误,明显改进错误生成模型合成数据的质量,进而提高GEC模型性能。GEC模型的提高还得益于学习者语料的多次使用:GEG1仅使用规则数据训练,未使用学习者语料;GEG2模型在使用规则数据预训练的基础上使用学习者语料微调;GEG3与GEG2模型相比,训练数据再次增加GEC模型纠正学习者语料后的数据。
如表4所示,200 M GEG3模型合成数据与学习者语料对GEC模型预训练、微调的方法比使用同规模合成数据、训练方式的GEG1、GEG2模型取得更优的结果,原因是学习者语料的重复利用,提高模型的性能。将GEC模型预训练数据扩增:使用规模400 M的混合数据显著高于仅使用200 M合成训练的GEC模型,这表明预训练数据的增加一定程度上提高了模型的性能。
如表5所示,文中模型在精确度上优于Xie等人提出的模型。由于重复使用较多的学习者语料,模型对错误的纠正精确度随着交替训练不断被强化。其次,模型在纠正过程中更好地利用语句上下文信息,模型对于语句流利程度的纠正控制表现较好,在GLEU值上表现超过Xie等人的8%左右。Grundkiewicz等人使用与文中相近规模的数据集,在精确度上低于文中模型。该文使用规则与反向翻译融合的数据增广方法,利用不同数据增广方法之间的优势可以合成质量较高的训练数据,并且交替训练的加入,强化模型学习到更多原来未学习到的语法信息,为模型的训练带来较大增益,加强了GEC模型对错误类型的识别与纠正。
5 结束语
在训练数据短缺的情况下,如何充分利用丰富的单语数据以提高GEC模型的性能变得至关重要。在大量的单语数据下,优异的数据增广方法可以使预训练模型获得好的初始化参数。提出利用不同数据增广方法之间的优势来提高GEG、GEC模型的性能。同时,模型交替训练的加入,明显改进了模型的性能。未来工作中,将继续探索GEG、GEC模型的优化方法以及探索通过单一错误纠正、多模型集成、重排序等策略进行错误纠正工作。
猜你喜欢
外语学刊(2021年1期)2021-11-04
厦门大学学报(自然科学版)(2021年4期)2021-06-22
天津外国语大学学报(2020年1期)2020-03-25
电脑知识与技术(2019年23期)2019-11-03
科技资讯(2016年25期)2016-12-27
青春岁月(2016年22期)2016-12-23
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
教学与管理(理论版)(2009年9期)2009-11-04
