
基于视觉语义关联的卷烟零售终端文字识别
2022-10-24 04:48韦泰丞谭颖韬
无线电工程 2022年10期
韦泰丞,谭颖韬
(1.广西中烟工业有限责任公司,广西 南宁 530001;2.中国科学院自动化研究所,北京 100190)
0 引言
随着互联网技术的发展以及具备拍照功能的移动终端的普及,各种终端所拍摄自然场景的图片往往包含一定的文字内容。不同于一般的视觉元素,文字直接承载了丰富而准确的高层语义信息,有着极强的场景表达力。因此,自动检测和识别图片中的文字具有很广泛的应用场景,例如店招识别、车牌识别和单据阅读等。光学字符识别(Optical Character Recognition,OCR)和场景文字识别(Scene Text Recognition,STR)技术,即从图像中检测与识别文字信息,已成为计算机视觉、文档分析等领域的热点研究方向,得到了来自学术界与工业界的强烈关注。
在烟草行业,零售终端店招名称以及烟草专卖零售许可证的文字信息是店铺信息采集的重要内容。传统的信息采集多以人工为主,耗时费力,并且容易出现差错,亟需建立智能化的终端文字信息采集系统。然而,传统的OCR技术无法解决复杂场景下的文字识别问题。针对实际场景中的文字识别难点,本文提出了一种基于视觉语义关联的文字识别网络,有效地提高了文字识别性能。
1 问题分析
零售终端店招文字识别以及终端许可证识别分别属于场景文本[1]和文档文本[2],如图1所示。终端店招文字处于真实的复杂场景之中,具有目标尺度变化大,字体种类、风格多样,背景较为复杂的主要特点。许可证文字处于纸质文档之中,此类图片有图像质量较低、文字不清晰、尺度小、文字密度较大的特点。

图1 图片样例Fig.1 Examples of picture
文字检测和文字识别通常以串联的结构组成系统,文字识别作用于文字检测分支检测出的文字区域。由于本文重点是文字识别部分,故不对文字检测部分进行过多叙述,直接采用文字检测器输出的文字区域图像作为文字识别系统的目标图像,如图2所示。

(a) 店招文字
近年来,随着深度学习的发展,基于卷积神经网络的文字识别方法以其优越的性能逐渐成为文字识别领域的主导方法。文献[3-4]使用循环神经网络(Recurrent Neural Network,RNN)深入建模像素之间的序列关系,增强文字上下文之间的理解,经过CTC翻译算法计算每个字符的概率,将RNN层的输出转化为一个字符串,作为最终结果。文献[5-7]使用一种自回归的方式,利用RNN结合空间注意力机制,逐个识别每个字符,获得了比CTC转译更好的性能。近年来,表达能力更强的自注意力模块[8]逐渐被使用在场景文字识别任务上,文献[9-10]使用自注意力机制获得更鲁棒的特征表示,取得了目前最佳的识别性能,并且逐渐将文字的语言模型引入以辅助识别任务,将其从简单的视觉分类建模为更全面的视觉和语言相结合的模型。由于其结合了语言的语义关系,在图像不清晰、有干扰的情况下仍能取得较好的结果。
本文为了针对性、鲁棒性地处理实际卷烟零售终端中出现的场景复杂和图像质量低等影响文字识别准确率的问题,设计了一种基于视觉语义关联的文字识别网络,在实际零售终端的多场景环境中均得到较好的效果,包括以下特点:
① 提升网络长跨度感受野。文本图像与一般的分类任务图像不同,其拥有极大的宽高比并且输出结果是不固定长度的序列。直接沿用分类卷积网络的方形卷积操作难以提升有效感受野,无法获取文本行各个字符之间的空间长跨度联系。本文使用自注意力机制增强横向文本的文字感知性能,有效提升文字识别准确率。
② 结合中文语义,融合图像和语言双模态特征获取更鲁棒的识别结果。本文提出了一种全局语义联系模块,利用中文的语义信息,有效地处理实际拍摄过程中产生的图像干扰等传统视觉模型无法解决的问题,降低图像识别中字体的多样性、光照不均匀、颜色变化及尺度不一等干扰。
③ 采用Focal Loss作为最终的损失函数降低中文样本不均衡分布的影响。由于实际场景样本中文字类别分布极度不均匀,在训练中使用Focal Loss提升网络对于出现频率较低文字的识别准确性,进一步提升网络的总体识别性能。
2 算法设计
基于视觉语义关联的文字识别网络是一种根据场景文字中的文字信息具有语言逻辑性的任务特点来设计的文字识别网络结构,本节对其网络细节进行重点阐述。
2.1 算法概述
提出的基于视觉语义关联的文字识别网络结构如图3所示。一方面,摒弃现有低效的RNN解码方式,通过高效并行的注意力模块定位文字字符的准确位置,加快多条目文本的识别速度;另一方面,利用transformer模块深层次挖掘中文文本的语义内容含义,对识别结果进行纠正,使识别结果具有语言逻辑性。对由于图像噪音等图像低质量问题造成的错误识别具有一定的纠错能力,实现高精度的文字定位和识别。

图3 基于视觉语义关联的文字识别网络结构Fig.3 Configuration of the proposed text recognition network
提出的文字识别网络包含4个主要模块:
(1) 主干网络
采用卷积神经网络和自注意力机制相结合的主干网络,卷积神经网络使用目前性能优越的残差连接网络。使用特征金字塔网络结合不同尺寸的特征图,一方面,为了更好地捕获中文的笔画细节;另一方面,为了增强网络对于不同细粒度文字特征提取的鲁棒性。此外,在特征提取器基础上,使用基于transformer的长跨度自注意力进一步增强特征的全局联系性。
(2) 并行注意力对齐模块
提出一种高效的并行视觉注意力策略。传统的字符串识别方法执行网络前向过程仅识别一个字符,识别整串需要执行多次前向,处理许可证版面的长文本十分费时。因此,提出并行注意力机制,一次前向过程识别文本行中所有字符,速度提升10倍以上。另外,由于店招文字以及许可证文本每行文字分布均匀,网络可以轻易学习出字符的位置信息,高效准确地对文字进行捕捉。
(3) 全局语义联系模块
中文文字具有强烈的语义特征,通常的文字识别方法中将语义分析作为后处理操作,无法与识别网络进行端到端训练。本文提出全局语义联系模块,单独挖掘语义信息并随网络端到端训练。使用长跨度序列注意力模型,将识别出的文字结果进行语义级别的矫正,使输出结果具备语言逻辑性。
(4) 视觉—语义融合模块
综合并行注意力对齐模块以及全局语义联系模块的视觉和语义识别结果,进行文字逐位比较,使用注意力机制权衡视觉以及语义识别结果的置信度获得最终视觉—语义关联的识别结果。
2.2 算法模块分析
(1) 主干网络
本文采用了残差神经网络[11]结合自注意力机制的主干网络,其中,残差神经网络参考文献[3]提出的45层轻量级网络的结构设计。每个残差模块单元包含一个空间尺寸为3的卷积层用于收集上下文信息,扩大网络的感受野;一个尺寸为1的卷积核减少参数量并且增强特征表达,具体的主干网络配置如表1所示。由于文字图像长宽比例的特殊性,更改了原始等比例下采样的策略,在第3阶段之后采用纵向下采样、特征图宽度不变的策略以保持文字的横向排列特性。
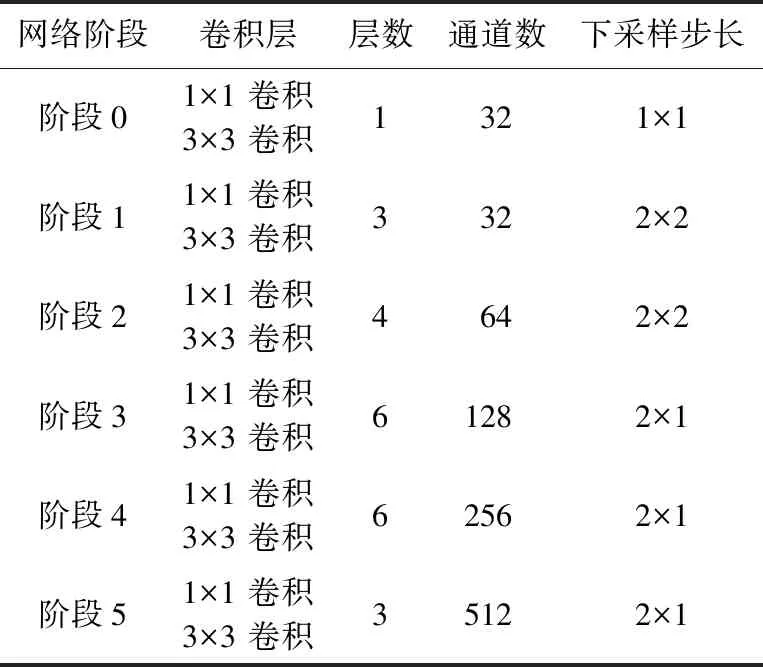
表1 主干网络配置Tab.1 Backbone network configuration
近年来,基于自注意力机制的主干网络在计算机视觉领域取得了很大的成功[12-13]。自注意力模块和卷积神经网络相结合的混合模型[14-16]更是取得了优异的效果。卷积神经网络拥有出色的归纳偏置,对通用特征的提取起到了极大的帮助,而自注意力模块以数据为驱动深度挖掘特征之间的关联,并且改进卷积操作感受野的局限性,二者相得益彰。transformer结构如图4所示。本文将基于标准transformer的空间长跨度自注意力模块置于卷积网络之后,其具体结构如图4(a)所示。
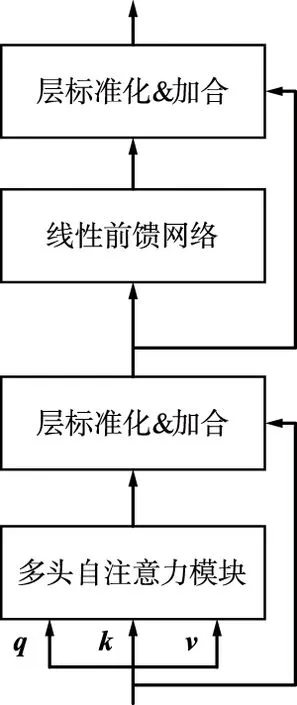
(a) transformer模块组成结构
在自注意力模块[8]中,查询向量q为输入序列中某个元素,键向量k和值向量v构成
(1)
式中,Q∈Rn×dk;K∈Rn×dk;V∈Rn×dv。本文中自注意力模块的输入q=k=v=F。F∈Rn×C为卷积神经网络的输出特征,n=H×W为序列长度,C,dv,dk为特征通道数。
由于transformer模块结构无法感应输入数据的相对次序,通常为输入特征额外复合代表位置关系的位置编码[12-13],为了适应图像特征的2维位置关系,使用了自学习2维位置编码提升图像的自注意力机制识别效果。表达如下:
(2)
式中,PEi,j∈Rn×dk为自学习位置编码向量,i,j分别代表空间的行列位置,以使transformer模块感知空间的特征关系。位置编码只作用于查询向量q以及键向量k,建立自注意力空间位置关系,而不改变值向量v,以保证图像判别性特征不被改变。
自注意力是一种关注输入序列内部元素间关系的注意力机制。自注意力机制的中心思想是计算输入序列中每个元素与其他所有元素间的相互关系权重,自主学习序列中元素的编码表示,该编码表示同时包含元素本身的信息和输入序列中其他元素与该元素的关系,即所有的文字信息。如图4(a)所示,加入了残差连接和层归一化计算方式,处理深度学习模型的退化难题。增加全连接层构成的前馈网络,增强每个元素的特征表示。
终端店招文字识别具有内容长的特点,使用空间长跨度自注意力模块可以高效、准确地解析所有字符。
(2) 并行注意力对齐模块
基于空间注意力的文字识别解码[4,17]通常通过自回归的方式从左至右依次定位图像中各个文字的位置,并且识别为相应字符。其最大弊端是每次解码字符均需要执行一次前向过程,当文字序列过长时计算效率过于低下。为此,使用了并行注意力解码方式,一次前向过程解码所有字符。计算如下:
(3)
式中,K=V=G为图像视觉特征;Qd为次序编码,形式上为一个自学习矩阵Qd∈Rn×dk。最终,得到Fv为各个字符的视觉特征。
(3) 全局语义联系模块
全局语义联系模块由语义嵌入映射和语义关系挖掘2个子模块构成。语义嵌入映射模块利用词嵌入 (Embedding)操作,将视觉特征Fv的字符分类结果映射至高维语义特征,这些特征通过语义关系挖掘模块深入探索语言的语义关联性。
全局语义关系模块如图5所示,其基本结构为4层相连的transformer模块。利用transformer中自注意力模块的全局交互,文字序列中的每一个文字之间深层语言信息被挖掘,建立文本串的语言逻辑知识。
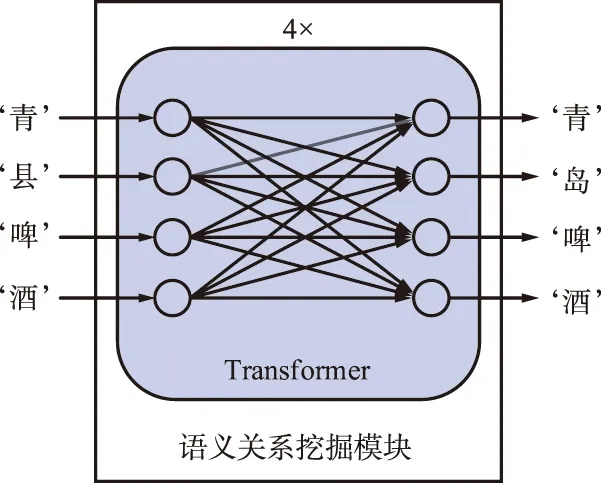
图5 全局语义关系模块Fig.5 Global semantic association module
采用图4(a)的transformer结构,输入q=k=v是视觉并行注意力对齐模块的解码结果相应的嵌入结果并且复合位置编码以表明文字的相对前后关系[8]。利用自注意力模块的计算能力深度挖掘各个文字之间的关系,建模文本行的语义知识。对于模糊、检测缺失和遮挡污渍等视觉干扰,纯粹利用卷积神经网络的视觉建模无法解码正确字符,但是利用上下文的整体语义信息可以对结果进行弥补。遮挡图像示例如图6所示,其视觉识别结果为“青县啤酒”,使用语义上下文建模,理解中文语言语境,纠正结果为“青岛啤酒”。

图6 遮挡图像示例Fig.6 Occlusion image example
由于全局语义联系模块基于视觉识别网络的识别结果,仅作用于中文语言空间而与图像特征无直接关系,故此模块可以独立于文字识别模型进行中文语义的预训练。参考文献[18]的预训练方式,本文在大量中文语料中预训练,并在终端店招和零售许可证图像中分别微调此模块。预训练策略为随机掩码,对于输入的中文文字嵌入信息,随机掩码输入序列中的若干文字,并最终预测这些被替换的文字,以此学习文字间的语言关系。其中,EM∈RC为所述掩码,其本身无意义,在训练中随机替换文字的嵌入信息。
在微调阶段,对于视觉模型的输出结果,其识别置信度往往和其字符识别准确率高度正相关。对于错误识别的字符,其识别准确率p往往较低,为了不使错误的识别结果干扰语义联系模块的识别,本文以字符识别准确率p作为置信度权值复合文字嵌入代表最终的输入:
Ein=p×E+PE,
(4)
式中,E为中文文字的嵌入信息;PE为可学习位置编码。随着置信度p的作用,错误的文字信息不会被带入全局语义联系模块干扰上下文的学习;另一方面,其输入文字信息被掩码后信息缺失,只能通过上下文的文字语言知识进行推断,与预训练的动机更加贴合。
(4) 视觉—语义融合模块
如上所述,视觉处理中的视觉识别特征Fv以及语言建模后的语义特征Fs分别代表各个字符的视觉信息和语言信息,使用一个门控机制进行视觉—语义方面的权衡,最终的特征D表达为:
D=σFv+(1-σ)Fs,
(5)
σ=Wg([Fv;Fs]),
(6)
式中,门控单元σ自适应地由视觉和语义特征得到;Wg为自学习向量用于调控视觉和语言特征的比重。对于视觉信息较弱的受干扰文字,语言特征Fs的作用尤为突出,而对于纯数字等无意义文字,视觉特征Fv更加关键。门控机制针对这一问题进行了建模,自适应地权衡融合特征比重。
最终网络的优化目标包含3个部分:视觉识别结果的损失、语言纠正结果的损失以及视觉—语义相关联的结果损失。三者的损失函数均使用Focal Loss[19]并且有相同的标签。由于中文文字识别具有分布不均匀的特性,尤其在终端场景中,“烟草”“超市”等文字出现更为频繁,故使用处理分布不均匀的Focal Loss对视觉特征Fv、语义特征Fs以及融合特征D进行多损失联合优化:
L=λvLv+λsLs+λDLD,
(7)
式中,Lv,Ls,LD为Focal Loss:
l=-α(1-pt)γln(pt)。
(8)
3 应用效果
3.1 实验设计
输入图像的高度归一化至32 pixel,宽度通过保持长宽比的方式动态调节。先等比例缩放图像,保证图像高度为32 pixel,宽度不足32 pixel的部分补0,超过的部分宽度缩放至32 pixel。对于并行注意力对齐模块,其次序编码个数对于店招文字和许可证文字分别为20,50,以针对图中最大长度的文字限制,在前向测试中根据图像的长宽比进行动态调整以提升计算效率。网络中的每个卷积层默认紧跟一个批归一化层和一个非线性整流激活函数(ReLU)。使用的网络自注意力模块和并行注意力对齐模块维度均为512,其中,多头注意力的头部数量为8。使用Adam[20]优化器进行训练,默认学习率为10-3,损失函数中λv=λs=λD=1,Focal Loss超参数α=0.25,γ=2 。
使用预训练和微调的整体训练策略。对于视觉识别模型,采用大量真实样本和生成样本训练本文提出的模型。使用公开真实文字识别数据集,例如LSVT,RCTW-17,MTWI2018和CCPD以及生成文字图像等总计4 000 000的文本数据,大量的文本图像预训练提升网络的通用识别性能。对于全局语义关联模块,使用中文维基百科EXT等500 000 000个中文文本数据预训练。
在微调的过程中使用实际场景的数据训练整体网络,其中,视觉识别模型和全局语义关联模块经由预训练得到,二者微调时学习率为10-4。店招图像的图像数9 285,许可证条目图像数92 200。测试集中,店招条目图像数1 034,许可证条目图像数10 213。遵循场景文字识别的标准评判准则,图像正确的依据为字符串中所有文字全部正确。网络使用4块12 GB 显存的NVIDIA TITAN Xp GPU进行训练,总共训练250个epoch。
在性能评测时,遵循行内全部文字正确识别代表该文本图像正确识别,准确率指标计算如下:
准确率=(正确识别文本图像数目/文本图像数目)×
100%。
(9)
3.2 实验结果
(1) 准确率分析
使用本文提出的结构训练神经网络,店招文字的识别准确率达到86.4%,许可证文字的识别准确率为94.1%。平均的GPU前向推理时间为0.073 4 s,即13.62帧/秒。训练准确率曲线如图7所示。
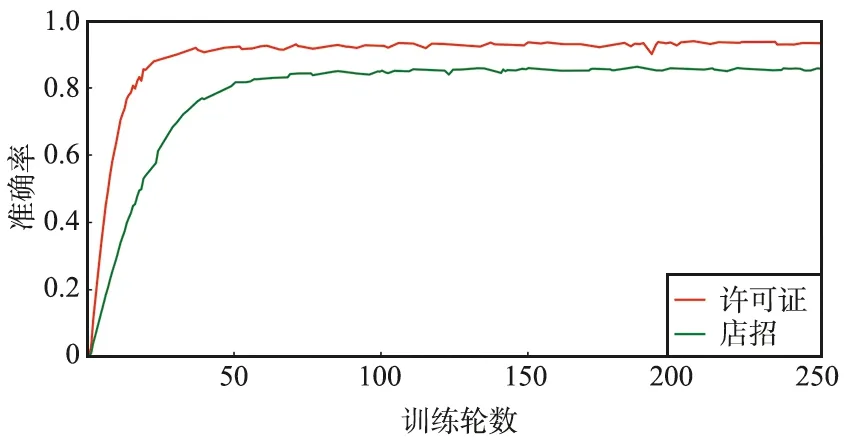
图7 训练准确率曲线Fig.7 Illustration of training accuracy
由图7可以看出,训练在50个epoch之后呈现稳定趋势,在50~150个epoch上由于数据增强的存在,准确率微弱上升。由于许可证文字多为白底黑字,排列规整,其准确率更高、收敛速度更快。店招文字由于其多变的字体和复杂的背景,识别准确率稍低。
(2) 模型结构对比分析
为了证明所使用方法的有效性,分别对视觉模型和语言模型的性能进行详细比较。在视觉模型中,使用了基于自注意力模块transformer的上下文建模和基于并行注意力机制的解码方式作为视觉模型基准线的设置。相比于传统方法中同等作用的CTC解码和基于双向LSTM的上下文建模,本文采用的方法具有最佳的识别准确率,结果如表2所示。
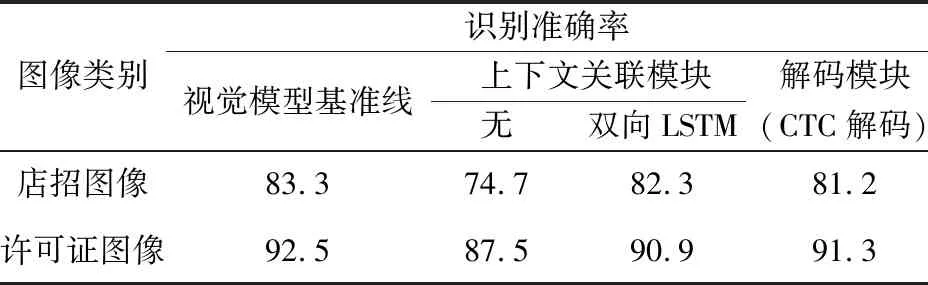
表2 视觉模型模块对比实验Tab.2 Ablation study of visual model 单位:%
上下文关联模块和解码模块分别为transformer和并行注意力解码,在各实验中仅替换相应模块以达到公平比较。可以看到,使用的视觉模型相比其他算法有一定优势,相比于传统的双层双向LSTM的上下文关联算法,使用的transformer模块分别在店招图像和许可证图像识别准确率上有1.0%和1.6%的提升,说明了自注意力模块的优越性;另一方面,使用的基于注意力的解码模块相比CTC解码模块有着2.1%和1.2%的性能增长。CTC模块因其简单、高速的特点,广泛使用于文字识别的解码中,但是由于其训练指导性较弱,近年来逐步被训练区域定位更精确的空间注意力机制超越。在许可证文字识别中,CTC解码的性能相对较高,这是由于许可证文字是打印文字,其排列规律均匀,有利于CTC的解码,但是在店招的复杂场景中,本文采用的解码方式更能体现出优势。
为了进一步探究语义联系模块在中文文字识别中起到的补充辅助作用,进行模型在没有该模块时的性能对比,结果如表3所示。在去除语义联系模块的模型中,店招文字和许可证文字识别准确率分别有3.1%,1.6%的下降,体现语义联系模块的重要性。其中,店招文字存在遮挡和艺术字体等原因导致纯粹的视觉模型难以十分准确地识别,利用中文语言语境的关系进行识别结果的修正显得更加重要。

表3 语义联系模块的比对实验Tab.3 Ablation study of semantic association module 单位:%
(3) 与其他方法比较
在同样的训练条件下和目前在中文文字识别中广泛使用的CRNN算法进行比较,结果如表4所示。由表4可以看出,提出的网络有更优越的性能。相比于CRNN算法,提出的方法分别有6.6%,3.6%的性能提升。由于店招图像场景更为复杂,该方法取得了更大的提升。在规则的水平文字场景,即许可证图像文字识别中,该方法仍然远优于CRNN,证明了所提方法的鲁棒性。

表4 和其他方法性能对比Tab.4 Comparison of performance with other methods 单位:%
部分可视化识别结果如图8所示。图片第一列是图像区域的文字检测结果,不同的文字条目检测结果由不同的颜色区分。为了公平对比提出的方法和CRNN的差异,使用相同的文字检测结果。文字区域执行不同的文字识别算法,其中第二列是CRNN的文字识别结果,第三列为提出的方法的识别结果,其中错误识别的文字用红色字体标出。
店招文字识别结果如图8(a)所示,可以看到店招文字由于字体的多样性和复杂场景的干扰,对识别结果产生了较大的干扰。“嶽”在大规模训练中是出现很少的文字,单纯的图像视觉难以正确识别,但是提出的语义关联模型针对该场景的中文语料将其纠正为正确的识别结果。同样,在图中“烟”字被复杂场景遮盖,纯粹的识别模型无法直接识别,但是受到上下文的语义纠正捕捉到“烟酒商行”这一短语。

(a) 店招图像区域识别结果展示
许可证文字的识别结果如图8(b)所示,相比于店招文字,许可证文字排列简单而且字体单一,但是其由于文字较小常常分辨率较低,模糊的文字干扰识别,通过语义补充可以一定程度上弥补这一不足。如图中“雪茄”识别为“雪范”,虽然图像的模糊对视觉识别造成困难,但是在该场景的上下文语料中能够轻易纠正为“雪茄烟零售”。图中“擂”字同样很少出现在训练的图像中,故CRNN识别错误为“播”,通过结合上下文的“擂鼓”仍能给予纠正,由此体现了提出的语义信息补充在文字识别中起到了关键性的作用。
(4) 在公开数据集中的比对
为了证明本文提出的方法具有鲁棒性,在中文公开数据集中进行对照实验,实验结果如表5所示。由表5可以看出,提出的方法相比于CRNN[3],SRN[9]具有更高的识别准确率。收集RCTW,ReCTS和LSVT等中文公开数据集作为本节实验数据,其中训练数据集包括500 000个中文字符串训练数据,测试数据集包括60 000个。
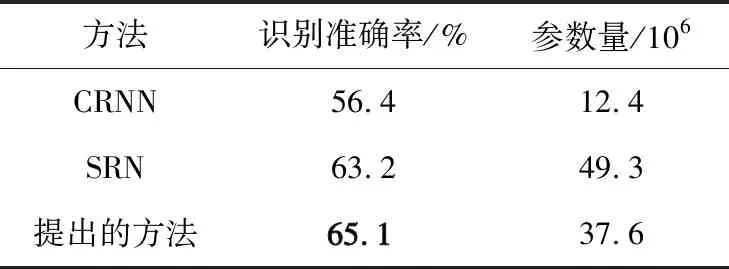
表5 在公开数据集中和其他方法性能对比Tab.5 Comparison of performance with other methods on benchmarks
相比于传统的纯视觉模型CRNN,本文提出的方法考虑了文字的语义关系有明显的性能提升;相较于语义关联网络SRN,本文使用的模块设计以及新的损失函数等策略改变带来了很大收益,能够在中文数据上展示出更强的识别性能。全局语义关联模块采用基于双向感知的结构,相比于SRN中使用的前向语义以及反向语义2个网络的实现,本文提出的结构具有更少的参数量以及计算消耗。
4 结束语
本文将中文语言的语义关系融合至卷烟零售终端店招文字和许可证文字识别的模型当中,取得了良好的识别效果。其中,利用自注意力机制在视觉模型和语言模型中均取得了较大的成功:一方面,提升了识别的准确率;另一方面,减少了由于RNN带来的耗时以及注意力机制偏差。语言模型的加入很大程度上解决了真实终端拍摄图片存在的问题,缓解纯视觉模型的固有缺陷。在未来的工作中,将着重关注模型的预训练方式,因为对于文字识别,通用的文字识别是最终的目标,不应该有场景的区分。场景的真实样本数量相比于公开的通用识别数据和生成图像数据少之又少,因此,在预训练模型的基础上,利用少量真实场景图像进行微调,即可提升模型在各个场景的通用性和泛化性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
中学英语之友·高一版(2008年10期)2008-12-11
