
基于Logistic回归和随机森林的心力衰竭预后预测建模
2022-10-20 02:56阚丽虹朱中生
复旦学报(医学版) 2022年5期
童 睿 阚丽虹 朱中生
(上海市浦东医院-复旦大学附属浦东医院心内科 上海 201399)
心力衰竭是导致老年人住院的常见原因,具有极高的病死率和致残率。由于患者临床状况千差万别,不同研究报道的急性心力衰竭住院患者1年内病死率从20%到60%不等[1-3],及时根据患者临床状况对患者预后进行判断有助于对高危患者实施不同强度的个体化干预,改善临床结局。针对心力衰竭预后的预测模型,目前比较著名的有西雅图心 力 衰 竭 模 型(Seattle heart failure model,SHFM)[4]、心 衰 生 存 评 分(heart failure survival score,HFSS)[5]等。但是,尽管这些模型的表现在人群层面上尚可接受,其对个体的预测并不可靠[6-7];此外,这些模型建模数据均来自西方发达国家,其在亚洲人群、发展中国家的适用性仍待验证。
目前国内对于心力衰竭预后模型的构建主要基于前瞻性的队列研究[8-9],通过多因素回归分析绘制列线图进行危险分层,这种方式对随访数据要求较高,且由于纳入标准的限制,研究样本量有限,样本分布与真实临床场景下数据特征的分布存在偏倚,外部数据验证效果往往欠佳。随着电子病历系统的推广,各医疗机构积累了大量真实世界临床数据,但传统统计学方法难以对这种结构混杂、特征高维、缺失值多的数据集进行有效处理。近年来,由于能从海量的非线性的、存在干扰的真实世界医学数据中提取隐匿而有价值的信息,机器学习算法越来越受到关注。利用国外的公共数据库和多中心电子病历系统回顾性资料,一些研究者尝试将LASSO回归、随机森林、XGBoost等机器学习方法引入心衰预后建模和能有效预测心衰预后的临床特征探索挖掘中,提供了宝贵的真实世界临床证据[10-11]。相比而言,国内公开的符合临床伦理规范的心力衰竭电子病历数据较少,基于中国人临床电子病历数据利用机器学习方法建立心力衰竭预后模型仍是空白。
本研究拟利用一个基于中国医疗机构电子病历系统结构化临床信息的数据集,通过机器学习算法进行数据预处理、特征选择、模型拟合及效果评估,构建适合该医疗机构收治心力衰竭患者预后预测的模型,由此摸索并完善一套预后预测模型构建方法框架。
资料和方法
数据来源本研究处理的数据来自Zhang等2020年在PhysioNet网站上公开的一个心力衰竭回顾性随访队列临床数据集[12-13],该数据集从医院电子病历系统中提取该队列患者结构化临床信息,以及住院期间治疗结局,并通过随访获得其6个月内死亡结局。该研究得到四川省自贡市第四人民医院伦理委员会批准(批准号:2020-010)[12]。
研究对象纳入标准根据公开数据集,本研究纳入自2016年12月至2019年6月在四川省自贡市第四人民医院住院且入院诊断为“心力衰竭”的所有患者,其中心力衰竭定义参照欧洲心脏病学会(European Society of Cardiology)制定的标准[14],包括急性心力衰竭、慢性心力衰竭、左心衰竭、右心衰竭、全心衰竭在内的所有类型心力衰竭患者均应纳入,即电子病历系统中所有入院诊断符合表1所示ICD-9编码的患者为纳入研究对象[12]。
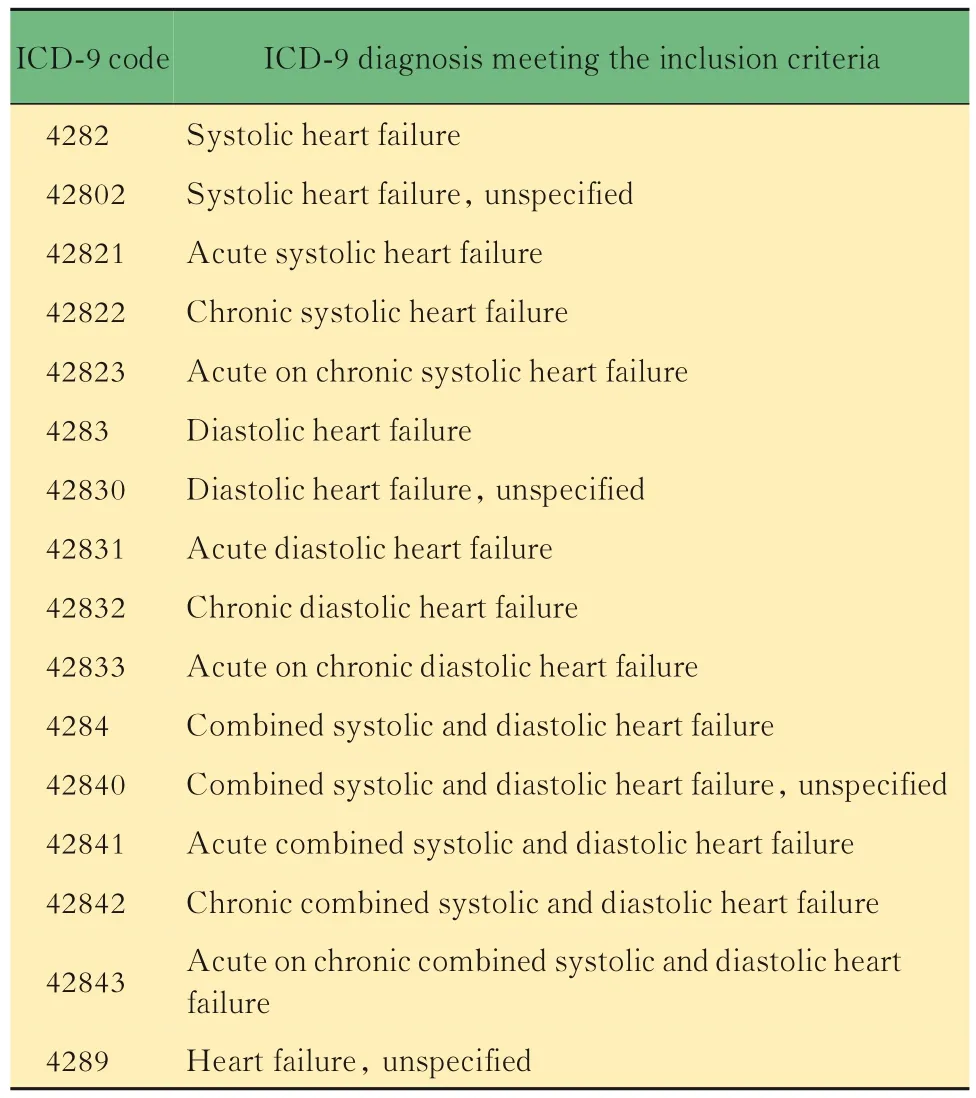
表1 符合研究纳入标准的入院诊断ICD-9编码列表Tab 1 List of the ICD-9 diagnosis code on hospital admission meeting the inclusion criteria
数据分析建模环境Python 3.8.5版,开源的Anaconda3-2020.11发 行 版 本 ,Jupyterlab 2.2.6版 开发环境下进行数据分析和建模。
数据预处理根据业务知识删除重复特征并去除完全共线性特征,特征如缺失值超过70%直接删除。用scikit-learn库SimpleImputer模块,对连续型特征进行均值填补,分类型特征进行众数填补,无序分类变量用OneHotEncoder模块进行独热编码,形成预测6个月内死亡风险的特征矩阵,进一步剔除出院时才能揭盲的特征,形成预测住院结局的特征矩阵。住院结局标注成存活和死亡二分类;6个月死亡结局沿用原始数据标签二分类。
训练集和测试集划分利用scikit-learn库model_selection模块train_test_split类进行训练集和测试集划分,取30%的样本作为测试集进行模型内部验证,其余70%样本构成训练集用于模型构建和优化。
基线数据统计描述全数据集、训练集和测试集基线数据,连续型变量非偏态分布计算均值和标准差,偏态分布计算中位数和四分位数,分类型变量计算在全数据集、训练集和测试集中各自的频数和频率。
特征选择经典统计学方法特征选择采用方差分析(analysis of variance,ANOVA)F检验进行相关性过滤,利用scikit-learn库f_classif模块选取F检验P<0.05的特征作为相关性特征,结合SelectKBest模块提取相关性最强的10个特征。基于算法的特征选择采取嵌入法和包装法结合策略,嵌入法最佳特征子集的求解利用feature_selection模块中SelectFromModel类进行,Logistic回归建模时通过L1正则化引入惩罚项压缩特征参数实现特征选择(least absolute shrinkage and selection operator,LASSO),随机森林建模时通过设定特征重要性阈值实现特征选择;包装法特征选择采取递归特征消除法(recursive feature elimination,RFE),利用feature_selection模块RFE类将预测模型特征数量压缩至10个。
结局样本类别不平衡处理当结局类别存在不平衡现象时,使用合成少数类样本的过采样技术(synthetic minority over-sampling technique,SMOTE),利 用imblearn库 中over_sampling模 块SMOTE类来平衡样本类别,使得多数类和少数类样本1∶1平衡。
模型拟合和优化Logistic回归建模利用scikit-learn库linear_model模 块LogisticRegression类实现,求解方式选择“liblinear”;随机森林建模利用scikit-learn库 中 集 成 算 法ensemble模 块RandomForestClassifier类实现;模型优化以scikitlearn库cross_val_score模块5折交叉验证计算ROC曲线平均AUC值最大为目标,比较不同超参数(Logistic回归模型中正则化强度倒数C,随机森林模型中不纯度衡量指标criterion,最大树深度max_depth)下模型效果差异,选取交叉验证下平均AUC值最大的超参数组合对训练集最终建模。
模型内部验证通过scikit-learn库metrics模块计算模型在测试集上AUC验证模型效果,利用bootstrap方法对测试集进行1 000次自助重抽样,取模型在1 000个自助样本上AUC分布的第2.5和第97.5百分位数作为模型在测试集上AUC的95%置信区间,利用roc_curve类结合matplotlib.pyplot绘制ROC曲线并计算最佳切点阈值和约登指数,并计算对应阈值下模型的精确度、召回率、F1分数和准确率。
结 果
各结局标签分布共2 008例病例,住院治疗期间死亡11例,存活1 997例,多数类占比99.5%,存在严重样本类别不均衡,其中训练集1 405例病例中住院期间死亡9例,存活1 396例,通过SMOTE方法平衡样本后训练集扩充至2 792例,死亡和存活病例各1 396例;6个月内死亡57例,存活1 951例,多数类占比97.2%,存在样本类别不平衡,其中训练集1 405例病例中6月内死亡45例,存活1 360例,通过SMOTE方法平衡样本后训练集扩充至2 720例,死亡和存活病例各1 360例。
数据预处理后特征矩阵原始数据集进行数据预处理后,最终形成的6个月死亡风险建模特征矩阵具有155个特征,进一步剔除出院后才能揭盲的特征,形成的住院期间死亡风险建模特征矩阵具有146个特征,特征重建流程见图1。这些用于建模的特征包括患者基本信息特征(性别、年龄、职业类别、入院途径、入院科室等)、入院病情评估特征(生命体征、心衰分型、NYHA分级、Killip分级、心衰病因、合并症、意识状况、呼吸状况等)、实验室和辅助检查特征(超声心动图、血常规、肝功能、肾功能、电解质、心肌损伤标志物、凝血功能、血脂、血气分析等)以及出院特征(住院天数、出院科室、出院去向)。本研究部分人口学特征和临床建模特征在训练集和测试集中的基线水平如表2所示。
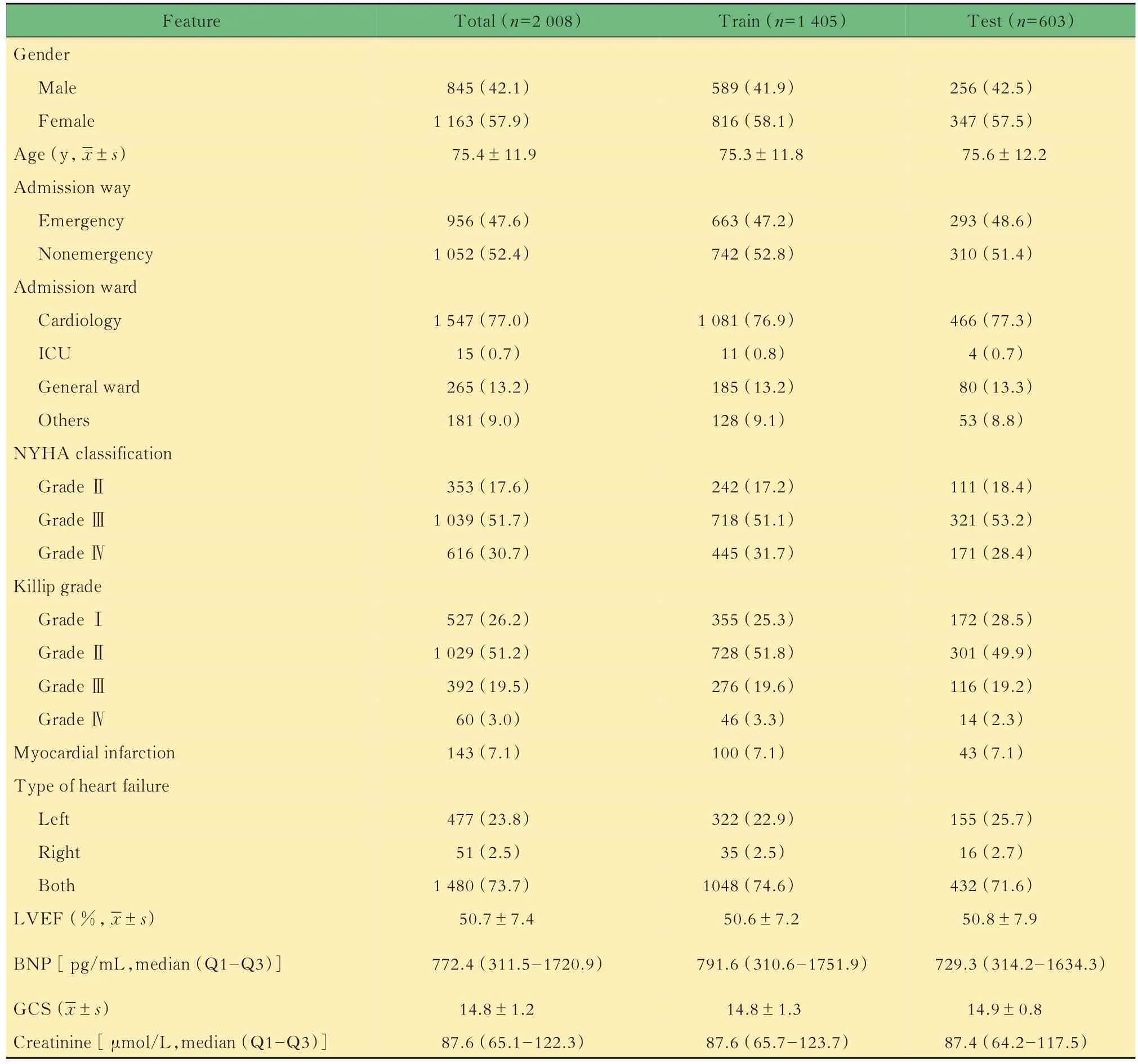
表2 部分人口学特征和临床建模特征基线水平Tab 2 The baseline level of population characteristic and several clinical features in modeling [n(%)]
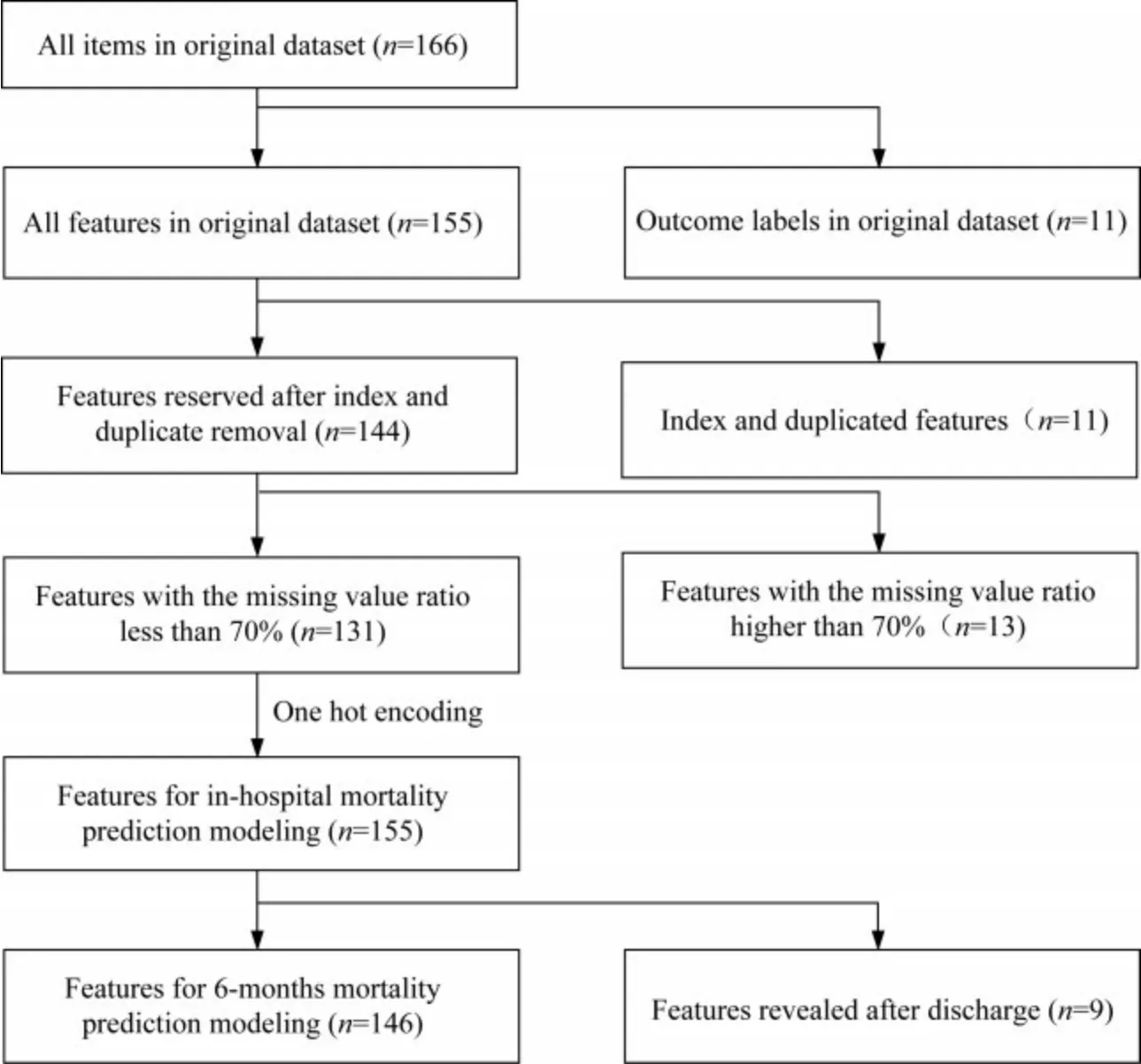
图1 数据预处理阶段特征选择重建流程图Fig 1 The flow chart of feature selection and reconstruction during the data preprocessing
住院期间死亡风险预测模型构建基于方差分析,与住院期间死亡结局相关特征共126个,相关性最强10个特征的F检验统计量和P值如表3所示。基于LASSO和RFE,以及随机森林特征重要性进行特征选择构成的特征子集如表4所示。用Logistic回归和随机森林模型对各特征子集建模,调整最佳超参数组合后,在测试集中计算AUC评估结果如表5所示。经比较,用随机森林算法对全部特征构成的矩阵进行建模,不纯度衡量指标criterion选择gini(基尼系数),剪枝限制单个评估器决策树最大学习深度max_depth为6时,测试集AUC最大,达到0.893 1。此最佳模型下ROC曲线及最佳阈值切点如图2所示,最佳分类概率阈值为0.007,约登指数为0.785,此阈值下模型的准确率0.786,精确度0.015,召回率达到1,F1分数0.030。
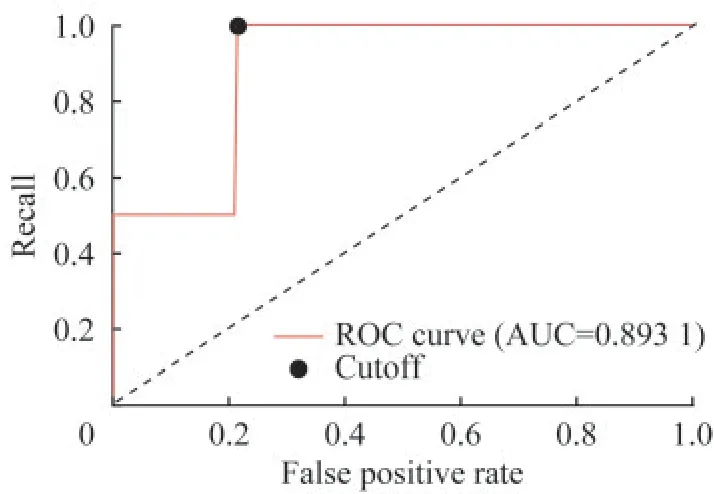
图2 最优超参数下住院期间死亡随机森林预测模型ROC曲线Fig 2 The ROC curve of random forest model of death during hospitalization prediction with optimal hyper-parameters
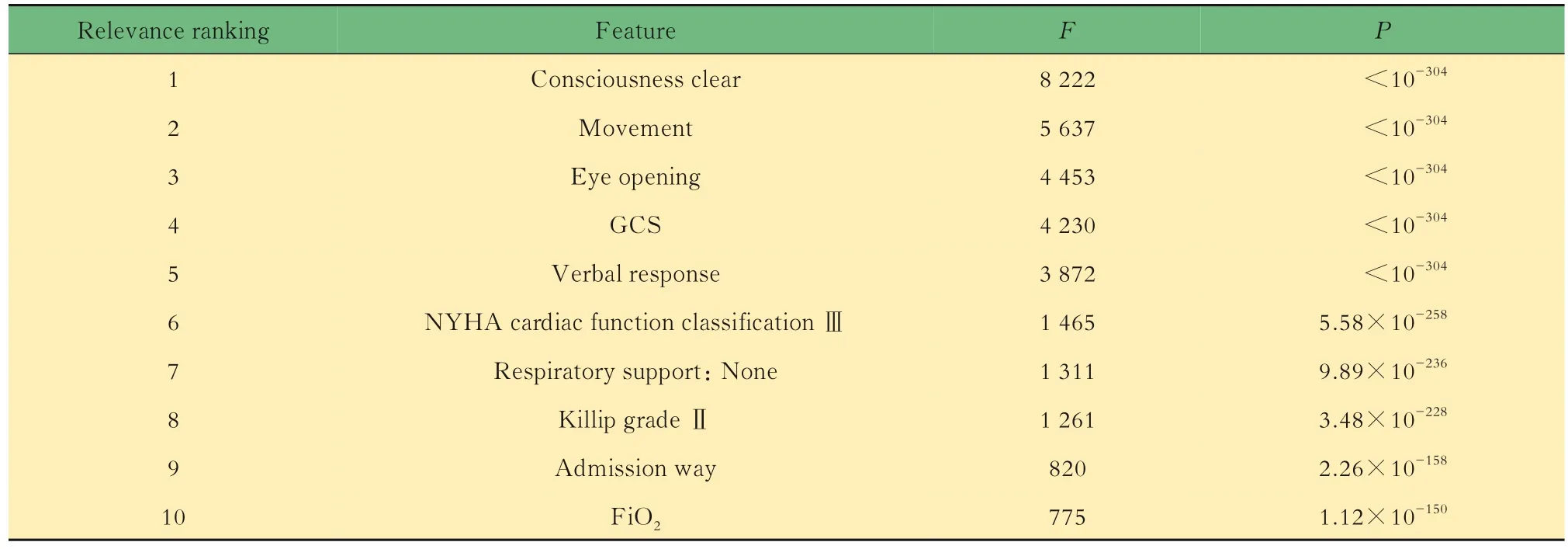
表3 基于方差分析F检验的住院期间死亡相关特征排序Tab 3 Ranking of the relevant features to death during hospitalization based on ANOVA
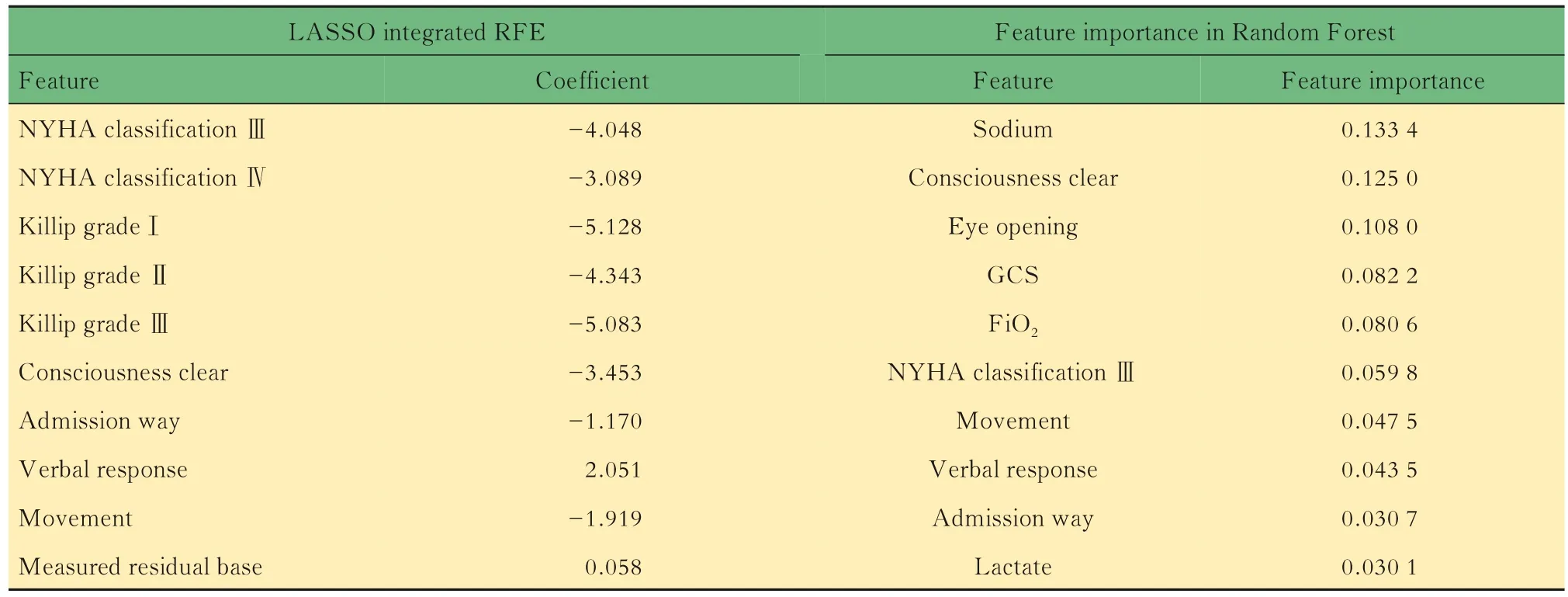
表4 基于LASSO结合RFE以及特征重要性筛选的10个预测住院期间死亡的最佳特征Tab 4 The top 10 features to predict in-hospital mortality selected by LASSO integrated with RFE and feature importance
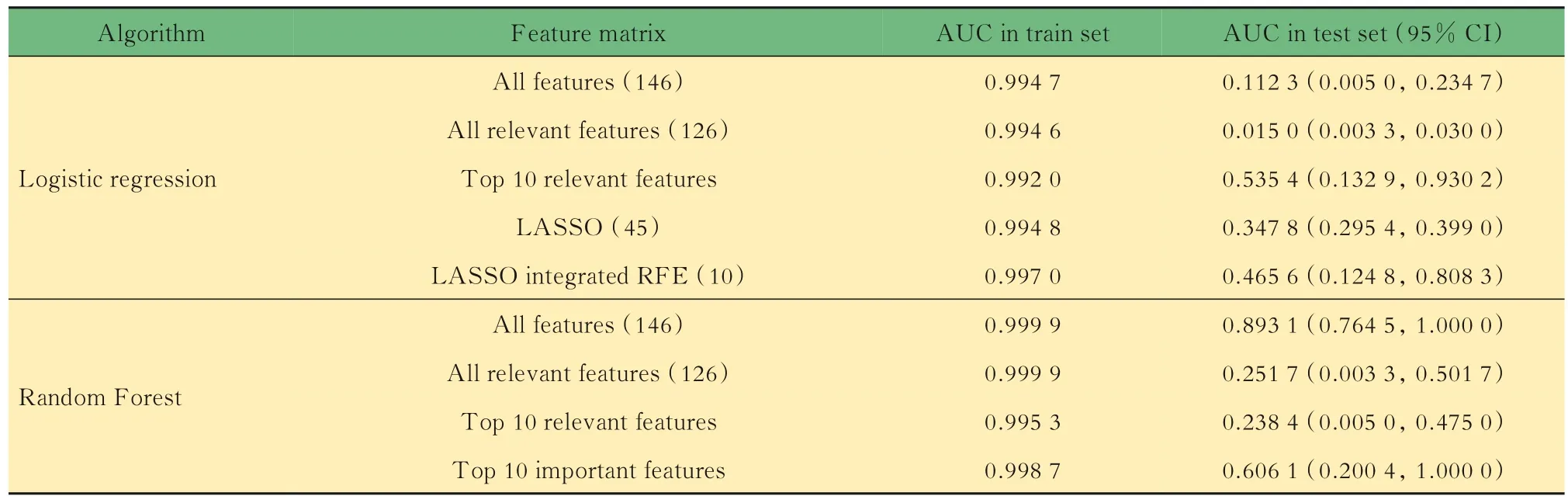
表5 Logistic回归和随机森林模型预测住院期间死亡效果评估Tab 5 Model evaluation of Logistic regression and random forest for in-hospital mortality prediction
6个月内死亡风险预测模型构建基于方差分析,与6个月死亡结局相关特征有128个,相关性最强的10个特征F检验统计量和P值如表6所示。基于LASSO和RFE,以及随机森林特征重要性进行特征选择构成的特征子集如表7所示。用Logistic回归和随机森林模型对各特征子集建模,调整最佳超参数组合后,在测试集中计算AUC评估结果如表8所示。经比较,用随机森林算法对全部特征构成的矩阵进行建模,不纯度衡量指标criterion选择entropy(信息熵),剪枝限制单个评估器决策树最大学习深度max_depth为11时,测试集AUC最大,达到0.8460(95%CI:0.7504~0.9305),此时最佳分类概率阈值为0.099,约登指数为0.579,模型的准确率0.587,精确度0.046,召回率达到1,F1分数为0.088。而利用LASSO结合RFE选择10个特征后Logistic回归,正则化参数C=0.76时预测效果与之相当,AUC达到0.8336(95%CI:0.7213~0.9286),此时最佳分类概率阈值为0.027,约登指数为0.568,模型的准确率0.736,精确度0.060,召回率为0.833,F1分数为0.112。

表6 基于方差分析F检验的6个月内死亡相关特征排序Tab 6 Ranking of the relevant features to death within 6 months based on ANOVA
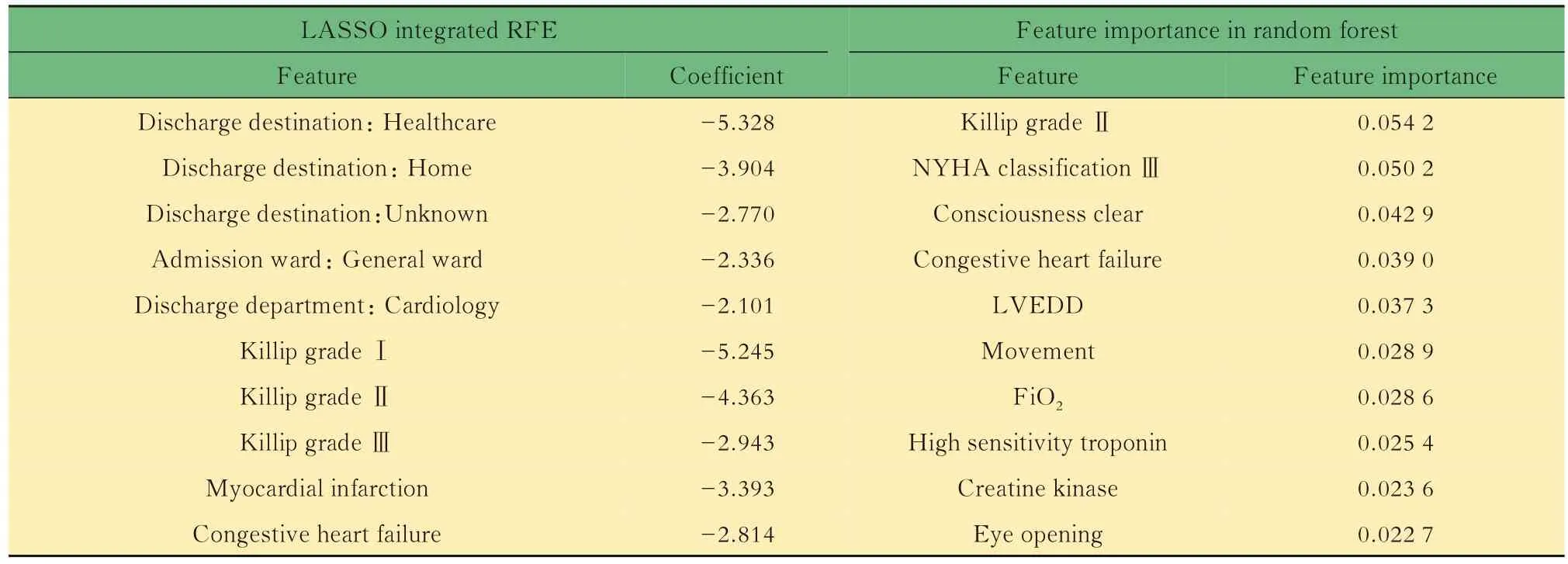
表7 基于LASSO结合RFE以及特征重要性筛选的10个预测6个月内死亡最佳特征Tab 7 The top 10 features to predict 6-month mortality selected by LASSO integrated with RFE and feature importance
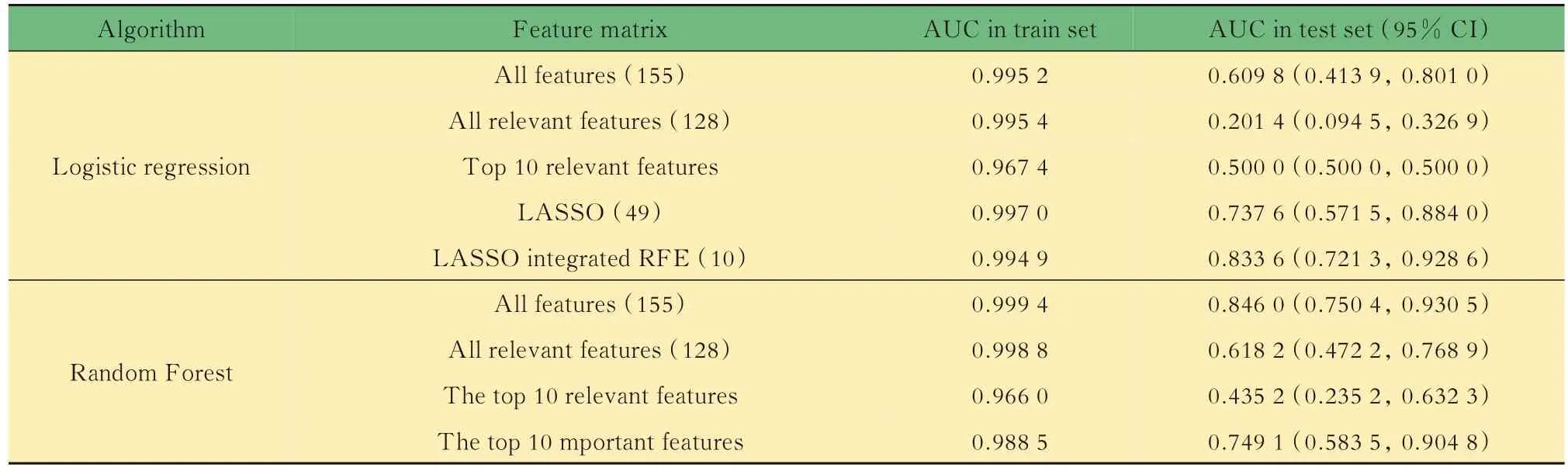
表8 Logistic回归和随机森林模型预测6个月内死亡效果评估Tab 8 Model effects evaluation of Logistic regression and random forest for 6-month mortality prediction
讨 论
目前疾病预后模型构建的主流方法是Cox生存回归分析,但该方法实施需完整的患者生存资料,更适合注册登记临床研究的预后分析。在真实世界研究数据建模场景下,这种生存资料往往缺失。本研究探索了一套基于国内电子病历系统临床数据进行数据预处理、特征工程,利用机器学习方法进行模型构建、优化并验证的方法框架,充分挖掘真实世界临床数据的价值,构建出兼顾预测准确性和高危个体识别能力的心衰预后预测模型。
本研究比较了两类不同机器学习模型对住院期间和6个月内死亡两类结局的预测效果。在以AUC为评估指标的前提下,对住院期间死亡结局的预测,随机森林模型明显优于Logistic回归预测模型,这提示临床上来自病历系统的这些特征与住院死亡结局之间可能呈现非线性的关系,而擅长于拟合线性关系的回归模型在这类临床预测问题上往往表现较差。对于6个月内死亡结局的预测,虽然随机森林模型的效果略优于Logistic回归,但经过LASSO和RFE特征选择简化后的Logistic回归模型效果已极其逼近利用全部特征建模的随机森林模型,而如果对随机森林用于预测的特征数量加以压缩限制,模型的预测效果下降明显,考虑到模型的临床实用性和模型可解释性,在这一问题上这种只需要少量临床信息即可达到较优效果的高效Logistic回归建模方式可能具有更高的临床价值。
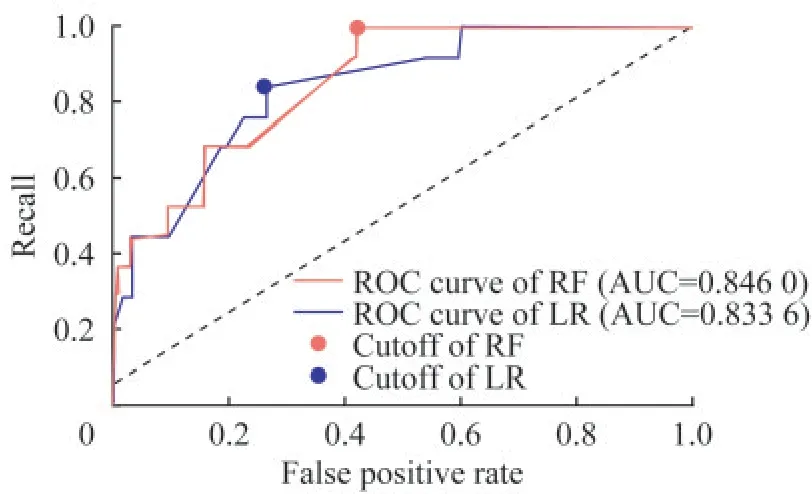
图3 最优超参数下6个月内死亡随机森林和Logistic回归预测模型ROC曲线Fig 3 The ROC curve of random forest and Logistic regression prediction model of death within 6 months with optimal hyper-parameters
本研究存在许多局限性:数据来源来自单个医疗机构,我们利用测试集对模型效果进行了内部验证,但限于收集到的数据资源,没有利用其他中心外部数据对模型进行外部验证。考虑到人群的代表性和医疗机构间不同的质控水平,本研究仅提供一种值得参考的心力衰竭预后建模方法框架,建立的模型本身以及模型相关参数在实际应用中仍需各中心数据进行验证和调整。对于住院期间死亡结局预测,虽然随机森林模型的AUC值较高,但该模型需要纳入的变量过多,临床实用性较差,而经过特征选择限制变量数量后,无论是随机森林还是Logistic回归模型,预测效果均不理想,这一问题上仍有必要进行特征工程和建模方法的深入探索。本研究出于探索目的,建模时纳入一些存在大量缺失值的特征,如既往文献报道的与心衰预后密切相关的左室射血分数[7],在原始数据集中缺失达69%,本研究采取均值填补和众数填补方式处理,可能导致相关信息损失,如果要进行严格的验证性方法研究,需充分考虑这种偏倚,采取必要的敏感性分析以证实结论的稳健性。
作者贡献声明童睿 机器学习模型拟合,参数调整,论文撰写。阚丽虹 数据获取和预处理,文献调研。朱中生 研究设计,获取资助,论文修订。
利益冲突声明所有作者均声明不存在利益冲突。
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30
成都信息工程大学学报(2021年5期)2021-12-30
南京理工大学学报(2021年4期)2021-09-15
昆明医科大学学报(2021年8期)2021-08-13
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
电子制作(2018年17期)2018-09-28
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2017年3期)2017-05-24
电子制作(2017年23期)2017-02-02
