
基于交互行为的突发事件微博用户社区识别及研究
2022-10-20 04:08林国英汪明艳
网络安全与数据管理 2022年9期
林国英,汪明艳
(上海工程技术大学 管理学院,上海 201600)
0 引言
网络的普及让人们接受消息的速度大幅度提升,微博等各大网络平台的出现也给大众提供了一个绝佳的讨论场所。人们可以在这些平台上发表自己对社会相关事件的看法与观点,同时还可以和网络平台上的其他人进行隔空互动,交流彼此的意见,观点相似的民众通过彼此间的互动形成了自己的社区,同一社区内的人们具有相似的看法或观点且彼此之间关系紧密。在面对突发事件网络舆情时,观点相似的用户在社区内快速传播舆情相关信息,这可能会造成用户间的情感与观点走向极化。因此如何在海量且复杂的网络舆情信息及舆情用户中快速发现用户社区,了解同社区内用户特征及用户关注重点对于网络舆情的引导十分关键。
目前学者们主要从用户发布的博文内容及用户关系方面对微博社区进行研究。徐建民等[1]借鉴引文分析理论分析微博社区内用户的交互行为,通过给不同的交互行为进行赋权从而计算各用户间相似度,并利用用户相似度进行社区发现。田博等[2]利用用户之间的转发关系、评论关系、点赞关系以及提及关系四方面交互行为构建加权的交互网络,然后以Newman模块度函数作为优化目标,得到社区内部节点联系紧密、社区之间节点联系松散的社区划分方法。邱少明等[3]提出一种基于节点多属性相似性聚类的社团划分算法SM-CD,其中节点属性包括节点结构属性与自身属性。钱芸芸等[4]提出一种融合主题相似度权重的主题社区发现模型,该模型首先计算节点间主题相似度并将其作为链接权重,然后将该链接权重作为模块度参数划分社区。张中军等[5]提出了一种基于链路结构和转发行为的微博社交网络重叠社区划分方法,该方法通过对用户间的转发行为进行对比来提高社区划分质量。何跃等[6]通过对每条微博进行情绪识别,定义情绪值并以此进行社区识别,研究不同社区内情绪变化情况。吴小兰等[7]通过对微博社区进行划分,从而追踪典型社区群体及社区话题演化发展。除此之外,有部分学者从社区结构出发对社区进行划分与识别。Golsefid等[8]提出通过模糊图聚类来进行社区发现,以可能性C-聚类模型为基础,根据聚类中心的相似度进行节点距离计算,最终完成社区发现。Tang等[9]利用数据场理论衡量用户间的联系程度,先确定初始聚类,然后采用粗糙集聚类算法进行社区发现。
综上所述,目前对于微博社区划分的研究主要从社区结构及微博内容出发,通过用户间的关注信息、用户自身属性及用户发布的博文内容相似度来进行微博社区识别,对于微博用户间的交流互动关系研究较少,无法多维度、深层次地发现网络舆情用户社区。基于此,针对现有研究的不足,本文以微博网络舆情用户为研究对象,结合用户交互行为,发现网络舆情用户社区,同时对不同社区内用户特征进行分析,不仅能更加准确地分析社区用户之间的交流互动,还能了解不同社区内用户特征,为引导网络舆论提供有价值的参考。
1 研究基础
1.1 微博交互行为
在微博网络中,用户可以对自己感兴趣的内容进行点赞、评价与转发等。通过这些行为,用户与其他用户建立联系形成关系网络。微博用户间的交互行为主要有以下6种:转发、评论、点赞、被@、私信以及收藏,考虑到数据收集的方便性,本文只研究点赞、转发以及评论这3种交互行为。根据上述描述可知微博网络用户交互行为结构图如图1所示,第一层节点为微博用户集合,第二层节点为微博用户的博文集合,第三层为用户对博文的交互集合。将上述“用户-微博-用户”网络中的微博节点去掉,并将微博节点与用户节点间的关系叠加到对应的用户节点关系上,构建“用户-用户”行为关系网络[10],从而构成了第一类用户与第二类用户的交互网络。

图1 微博交互网络图
1.2 社区发现
社区被称为节点的局部密集连通子图或聚类[11],社区发现则是指以相似特征为基础的聚类[12]。传统社区发现算法主要包括图分割法[13-14]、标签传播算法[15-18]、CPM算法[19]等。除此之外还有一类基于模块度最大化的算法,其中以GN社区发现算法[20]和Louvain社区发现算法[21]为代表。
2 基于微博用户交互度的微博社区发现算法
本文以新浪微博为数据采集平台,通过分析用户交互行为,计算用户间的交互度,并以此作为权重进行微博社区的发现。
2.1 微博用户交互度计算
用户间的交互次数体现了用户间关联的紧密程度,用户交互联系越频繁与紧密,彼此之间就越有可能进行信息传递,被划分到同一社区的可能性也就越大。基于此,本文根据用户间交互次数计算两用户交互度。计算公式如下所示:
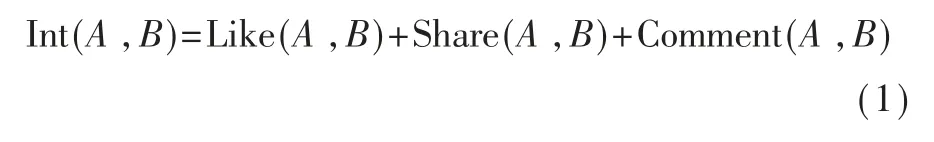
其中,Int(A,B)表示用户A与用户B之间的交互度;Like(A,B)表示用户A与用户B之间的点赞次数;Share(A,B)表示用户A与用户B之间的转发次数;Comment(A,B)表示用户A与用户B之间的评论次数。
微博用户间的交互行为可以分为两类,一类是直接交互,另一类是间接交互。所谓直接交互是指用户对另一用户发布的博文进行直接的点赞、转发以及评论等行为。而间接交互则是指两用户对同一条博文进行点赞、转发以及评论等交互行为。式(1)只考虑了用户间的直接交互忽略了间接交互,基于此本文对上述公式进行修改,融合用户间的间接交互度,修改后的公式如下所示:

其中,Interaction(A,B)表示加入了间接交互的用户A与用户B的交互度;Int′(A,B)表示用户A与用户B之间的间接交互度;Like(A→O,B→O)表示用户A与用户B对用户O的共同点赞次数;Share(A→O,B→O)表示用户A与用户B对用户O的共同转发次 数;Comment(A→O,B→O)表 示 用 户A与 用 户B对用户O的共同评论次数;α为权重系数,其值根据经验设定为0.7。
根据上述公式可得用户n×n的对称交互度矩阵,该交互度矩阵中的每一个值均刻画了该网络中的某个节点与其他节点的交互程度,如式(4)所示:
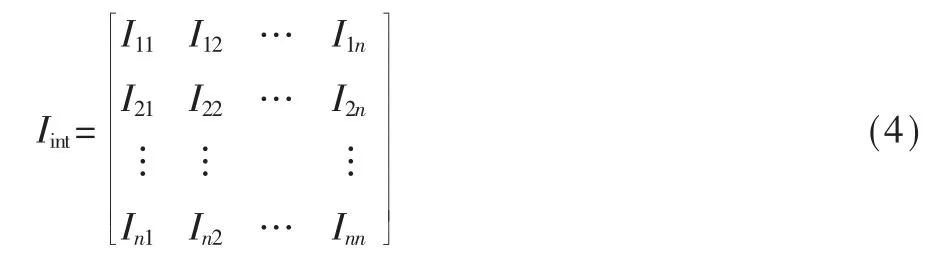
2.2 基于微博用户交互度的社区发现算法
Louvain算法是Blondel等人[21]在2008年提出的一种基于模块度的社区发现算法,该算法通过重复合并模块度增量最大的用户节点从而最大化整个社区网络的模块度,实现社区优化。模块度公式如下:
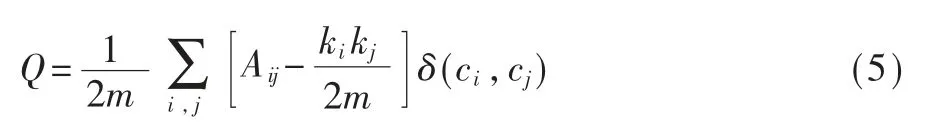

其中,Aij表示节点i和节点j之间的权重;表示所有与节点i相连的边的权重之和;cj表示节点i所属社区;表示所有边的权重之和[22]。
基于上述模型方法,根据式(1)~式(3)计算用户交互度,并将该交互度作为两节点间边的权重,通过Louvain算法进行微博突发事件用户社区划分。本文首先对输入的数据源进行预处理,在预处理过程中主要包括对用户交互关系进行提取,根据提取的用户关系计算用户交互度,并通过对间接交互与直接交互进行加权得出总的用户交互度;然后利用两两节点之间的交互构建交互度矩阵,将交互度作为两节点间边的权重,不断合并和更新交互度最大的社区,直到网络模块度不再增加,模块度最大的社区即为最优划分结果[23]。算法流程如图2所示。
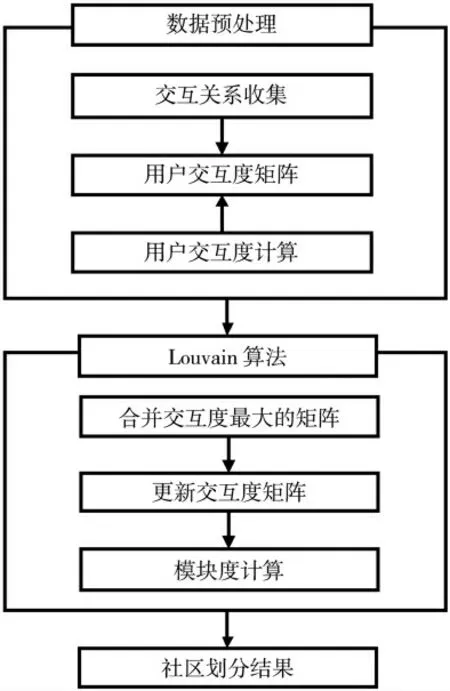
图2 算法流程图
3 实验验证
3.1 数据采集与处理
微博具有鲜明的社交网络特点,吸引了众多的舆情用户,对网络舆情研究具有重大意义。本文选取公众关注的突发事件——7.20河南暴雨话题作为信息源采集全部数据,进行微博社区分类。使用Python采集舆情用户发布的“河南暴雨”关键词下的用户相关数据。具体步骤如下:(1)本文数据采集时间从河南暴雨发生时间2021年7月20日开始至2021年8月2日河南省人民政府新闻办公室新闻发布会通报受灾情况结束。利用微博高级搜索功能,以“河南暴雨”为关键词搜索相关博文。(2)通过Python采集博文相关信息,包括用户ID、博文内容以及发布时间等。(3)记录每个用户ID所发布的博文下的点赞、转发及评论名单。(4)统计每个ID的直接与间接交互用户并记录其与用户之间的交互类型与交互次数。数据采集结果如图3所示。

图3 数据采集结果
在得到初步数据后通过Python和Excel进行数据处理,包括数据清洗、删除重复数据和无用字段,之后通过Jieba分词过滤无关字符以及去停用词获得微博文本分词数据,最终获得用户ID 2 712名,微博博文7 467条以及32 498条交互关系。
3.2 实验结果与分析
在计算上述各用户间交互关系及交互度的基础上,通过Louvain算法对微博用户进行社区划分,将划分结果利用Gephi进行可视化。由于最终获得的社区数目较多,本文选择了节点数量前7的社区,社区划分结果如图4所示。
从图4可以看出,微博网络用户之间相互联系形成不同的社区结构,其中,社区3、社区4、社区5、社区6、社区7内网络密度相对较大,社区1、社区2网络密度相对较小,社区成员较为分散。图中节点的大小代表了节点度的大小,节点越大代表节点同其他节点的交互越多。基于此可以从图中看出,在社区内存在意见领袖,不同社区内意见领袖个数有所不同,社区内其他用户紧紧围绕在意见领袖周围,同意见领袖进行交互,即少数关键用户拥有大量的交互关系,普通用户之间交互较少。
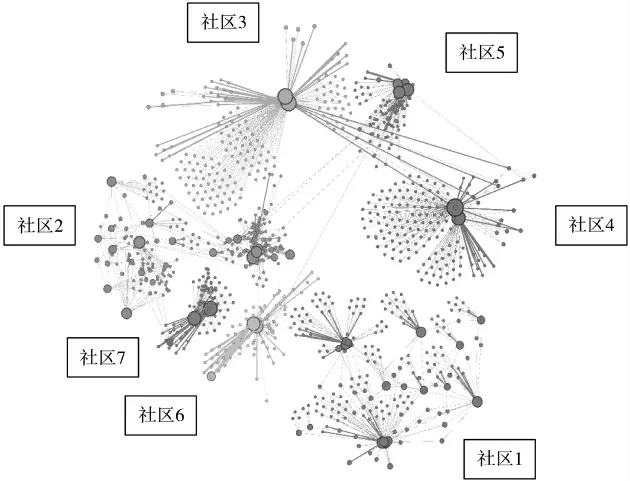
图4 社区划分结果
通过研究微博用户社区可直观展示出在“河南暴雨”舆情空间下,舆情用户主题的构成和分布情况,确定舆情用户的主题倾向。将各社区内用户所发的河南暴雨相关博文内容汇总,通过Jieba分词对文本内容进行分词,统计各社区内词频数前10的词语,结果如表1所示。
从表1可以看出不同社区内用户对于此次暴雨事件的关注重点存在不同之处。在社区1内用户发布的暴雨相关博文主要与救援相关,呼吁人们给予暴雨中的小县城关注与救援。社区2内用户则主要关注暴雨导致的地铁21号线乘客被困事件,人们对地铁内被困的人员给予关注与鼓励,同时也强烈要求查明相关事故原因。社区3内用户主要关注救灾物资捐助以及灾后受灾人民的赔偿相关问题,例如#涉河南行程可免费退改#、#汽车被淹保险怎么赔?#等。社区4内用户主要关注群众救援问题,特别是老人等弱势群体的救援。社区5和社区6内用户话题相似,主要包括暴雨信息的求助及物资和救援相关问题。社区7内用户则主要关注暴雨中的感人画面,将视角聚焦到暴雨下的普通人。尽管各社区内用户关注的重点有所不同,但7个社区内词频数最多的都是“暴雨”与“河南”,这是此次突发事件的共同主题,除此之外救援、被困、洪水等词语也同时出现在不同社区内部,这表明不同社区内存在话题重叠问题。
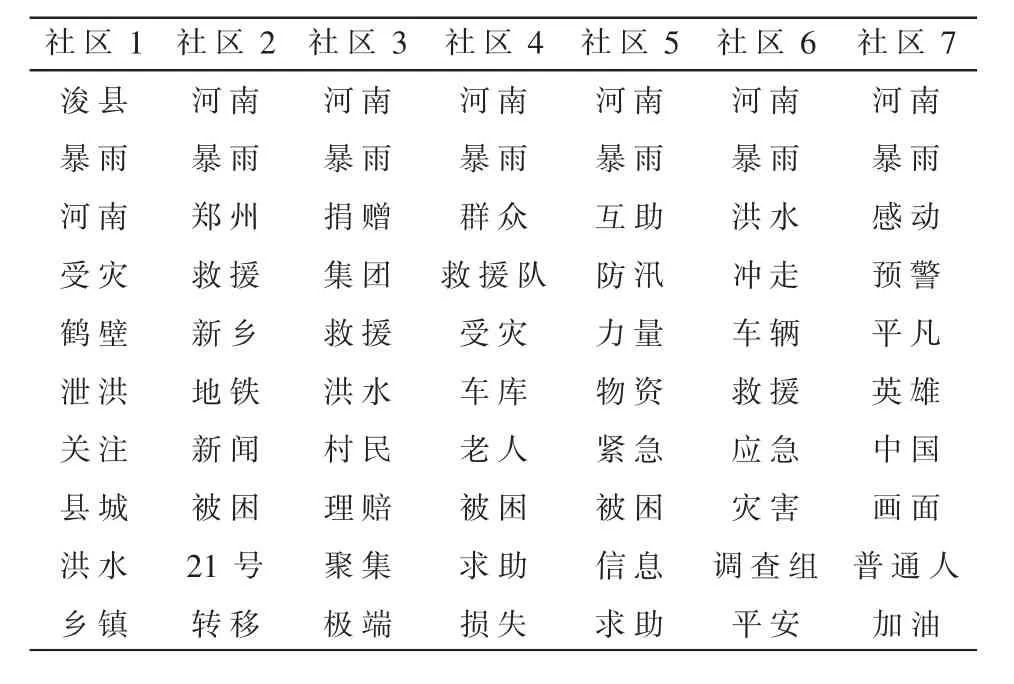
表1 社区词频统计
4 结论
本文从社会网络分析的角度出发,分析了微博网络上用户间交互行为及交互网络,根据用户间点赞、转发及评论等交互行为次数获得用户交互度,结合Louvain算法完成突发事件下微博用户社区发现。根据实验结果,该方法能更好地考虑用户之间的交互行为从而使社区划分结果更加准确,社区内部联系也更加紧密。将社区发现结果与突发事件下用户发布的相关博文相结合可知,不同社区内用户对于同一事件的关注重点有所不同,同时不同社区内话题存在重叠现象。本文从用户间交互行为出发研究突发事件下微博用户社区特征,可为网络舆情引导工作提供更全面的参考。本研究从新浪微博采集数据,且实验数据是在新浪微博上随机获取的部分数据,权威性不高,所以在未来的工作中将寻找更加权威的数据进一步加强研究的有效性。
猜你喜欢
环球时报(2022-08-10)2022-08-10
作文大王·低年级(2022年3期)2022-03-19
南方周末(2019-06-13)2019-06-13
小学生作文·小学低年级适用(2018年12期)2018-04-11
支点(2017年8期)2017-08-22
消费电子(2016年12期)2017-01-19
校园英语·下旬(2016年2期)2016-03-18
少儿科学周刊·儿童版(2015年7期)2015-11-24
网络传播(2014年12期)2015-03-16
网络传播(2014年11期)2015-01-14
