
基于知识辅助的图像描述生成
2022-10-19 07:43:32李志欣
广西师范大学学报(自然科学版) 2022年5期
李志欣, 苏 强
(广西多源信息挖掘与安全重点实验室(广西师范大学), 广西 桂林 541004)
随着深度学习技术取得重大进展,以及一系列大规模数据集的开放,图像描述任务在人工智能领域引起人们越来越多的关注[1-3]。图像描述任务旨在为给定图像生成一个描述图像中显著目标以及目标之间联系的自然而有意义的语句。图像描述主要有图像和文本2种模态,而图像描述任务就是在这2种模态之间探索一种让两者能恰到好处地进行数据匹配、对齐的方式,而这恰到好处的意思就是既能准确描述图像中的内容,又能使描述的内容符合当代人的认知和表达。然而,现实中图像以及文本2种模态之间一直存在着语义鸿沟,要想使用自然语言来完成图像描述任务就需要优先解决语义鸿沟的重大难题。此外,由于生成描述语句的多样性,使得对描述语句质量的评估变得极其困难。因此,图像描述长期以来被视为一项具有挑战性的任务。此外,这个问题的研究具有重要应用前景,可以帮助有视觉障碍的人群理解不同场景中的内容,也可以作为早期儿童教育的一种辅助手段等[4-5]。
近年来,实现图像描述的主流方法通常采用编码器—解码器的生成架构[6-10],使用卷积神经网络(convolutional neural network,CNN)作为编码器,将图像编码为一个固定维度的中间层对象,在下一层使用长短期记忆网络(long short-term memory,LSTM)或循环神经网络(recurrent neural network,RNN),将这个中间层对象解码为一个描述语句。在这个基本流程中,注意力机制的加入表现出显著的有效性[11-19]。注意力机制允许模型在每一步都关注与生成各个单词相关的图像区域,而不仅仅是使用整个图像来指导描述语句的生成。当前集成注意力的图像描述方法虽然取得了很好的性能,但这些方法仍然存在2个局限:其一,图像描述方法中的视觉注意力可以视作图像区域和语句片段的映射,但这种映射过程大部分情况下都是在一个封闭“黑盒”里不可预测地、强制地执行,并且忽略了一个事实,即有些单词与图像中的任何实体都不相关,例如图1所示的检索中,识别到的“stop sign”,在这个场景中这位女士应该是在“bus station”等待“bus”。因此,它可能会导致图像区域和语句片段之间的不协调,从而降低生成语句的质量。其二,大部分图像模型依赖于大量键值对类型的图像—文本相关数据上,而训练中的数据,每张图像仅有少量的真实标注语句,想要表达图像中隐晦信息的意图仍然缺少足够的线索。如图1所示,依靠知识图谱中的关系数据可以获得一个信息:该女士可能在等候“bus”,但是如果采用常用的集成注意力的图像描述方法,要在语句中生成“bus”这个单词的概率则非常低。此外,为了从训练数据中使模型具备描述关联实体的推理能力,也非常有必要从外部数据源中吸收相关联的新知识。
本文致力于缓解上述2个局限,以生成更加准确和有意义的描述语句。在描述语句中,并非所有单词对描述图像内容都具有同等重要性,如图1标注语句中“woman”和“luggage”很明显是图像的主体,因为它们与图像中2个醒目的目标实体相互对应。相反“the”和“with”等副词连词则不太重要,它们与图像所要描述的事情没有直接联系。基于这种感知,为了优化语句中单词和图像区域之间的匹配、关联,本文提出一个特别的单词注意力方式。简单来说,初始时依照描述图像实体的权重等级为每个输入单词设置一个权重值,之后在预测单词的每个时间步计算输入词的上下文关联信息,通过充分利用来自标注语句中自底向上的语义信息来指导视觉注意生成过程。这使得提出的模型更符合人类对视觉场景的处理方式,即像人类一样更专注于描述视觉图像中的一些主要突出区域而不是非突出区域。同时,本文进一步利用从外部知识图谱中抽取出的常识性知识来实现模型更好的泛化性能。采取的方法是将语义相关的知识输入到LSTM语言生成器的单词生成阶段,增加词汇表中某些可能被用来描述给定图像内容的单词的概率。这些单词通常是重要的、与图像内容相关的,但是在依靠训练集中的图像—文本数据来训练模型时常常因为线索不足而被忽略。通过引入外部知识,本文的图像描述方法能获得更多线索,指导描述生成。
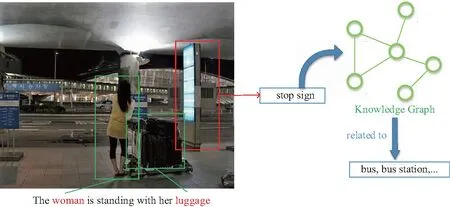
图1 借助外部知识发现图像隐含意义以及描述语句中不同单词的重要性Fig.1 With the help of external knowledge, the implied meaning of the image and the importance of different words in the description sentence can be found
综上所述,本文的主要贡献包括:
1)提出一种集成内部知识与外部知识的图像描述生成学习框架,试图为给定图像生成包含新概念、新知识,能结合场景信息,符合人类感知推理的描述语句,而不是生硬的串联识别的语句。
2)提出一种新的文本相关的注意力机制(即单词注意力)以辅助计算视觉注意力,能够更好地识别图像中地实体,从而利用内部知识生成更准确的描述语句。
3)将知识图谱引入到编码器—解码器架构中,能够利用训练集中没有包含的外部知识来促进生成新颖和有意义的描述语句。
此外,在MSCOCO和Flickr30k基准数据集上的实验结果表明,本方法具有良好的性能,优于许多现有的先进方法,并能在某些情况下生成图像没有直接体现的新实体或新关系。
1 相关工作
当前主流的图像描述方法是基于神经网络的序列学习方法,通常使用CNN将图像编码成固定长度的图像表示,然后使用RNN将图像表示解码成有意义的描述语句,因此描述生成过程是一个端到端的过程。
尽管早期许多图像描述方法取得了优越的性能[6-10],但由于这些方法仅仅使用图像级表示初始化RNN或LSTM的隐含状态,故通常面临目标缺失和误预测的问题。将注意力机制引入到图像描述方法中,可以缓解这2个问题。受到在机器翻译任务中成功使用注意力机制的启发,Xu等[11]将视觉注意力集成到图像描述的编码器—解码器架构中,使图像描述的性能获得显著提升。视觉注意力的作用相当于在逐词生成描述语句时,学习语句中单词与图像区域之间的潜在对齐关系。这个尝试成功之后,多种基于注意力的图像描述方法陆续被提出。You等[12]提出一种语义注意力模型,该模型有选择地注意从给定图像中检测到的语义属性,从而更好地利用自顶向下的视觉信息和自底向上的语义信息。与上述方法不同,Liu等[13]和Lu等[14]研究图像区域和对应单词的一致性。前者定义了一个定量指标来评估由注意力模型生成的注意图的“正确性”,并采用监督来提高注意的准确率;而后者提出一种自适应注意,并通过“视觉哨兵”来决定什么时候关注视觉信号,什么时候依靠语言特性来预测下一个单词。韦人予等[15]在编解码器结构以及注意力机制的基础上,根据激活层通道之间的依赖关系,实现一种注意力特征自适应矫正的方法。张家硕等[16]提出一种双向注意力机制的图像描述方法,新增一种图像特征到语义信息方向的注意力机制,设计一种门控网络,将新的注意力方法与原注意力方法进行信息融合,提高了描述语句的准确性。李文惠等[17]利用VGG19和ResNet101进行特征提取,在注意力机制中引入分组卷积操作取代惯用的全连接操作,提出一种改进的注意力机制提高图像描述模型的准确度。Li等[18]则利用一个Global-Local注意将图像全局特征和局部特征结合起来指导描述语句的生成,其中局部特征通过目标检测算法获取。类似地,Anderson等[19]使用Faster R-CNN[20]实现了其Bottom-Up注意,然后构造一个Top-Down注意来聚焦图像的显著区域。以上这些工作都证明注意力机制在图像描述任务中具备有效性。本文在统一的视觉注意力模型上增加了一个新的文本相关的单词注意力,其计算只依赖于训练数据中的内部标注知识,可以提供丰富的语义信息,指导视觉注意力的生成。
虽然图像描述方法取得了很大的进展,但普遍缺乏描述训练集之外的新目标或属性的能力,也无法表达图像的隐含语义,因为从真实标注语句中获取的知识是不够的。这个问题既可以通过整合场景特征的方法[21]解决,也可以通过将外部资源的知识整合到描述生成过程中来解决。Hendricks等[22]利用来自外部目标识别数据集或文本语料库的目标知识来促进生成新目标描述。Yao等[23]利用“copying”机制将训练集中不存在的,而是从目标识别数据集中学习到的新目标直接复制到LSTM生成的输出语句中,使提出的方法获得了优越的效果。Li等[24]进一步扩展这一工作,使用“pointing”机制来协调“copying”机制和单词生成之间存在的间隙,从而生成更准确、更自然的描述语句。随后,Zhou等[25]提出利用知识图谱来促进图像描述生成,这与本文方法的集成知识图谱部分有相似之处。同样地,陈开阳等[26]也提出利用知识图谱提高图像描述的准确性,不同点在于,该类方法使用一个目标检测器检测出图像中包含的目标实体,再利用这些目标实体从知识图谱中抽取出相关术语和不相关术语来训练一个RNN;而本文方法则将语义相关的信息注入到LSTM的输出阶段,以增加每次解码时与图像内容相关的潜在有意义单词的概率,这也允许模型生成更加新颖和有意义的描述语句。
为了解决图像描述任务中评价指标的“不可微”以及模型在训练和测试阶段中出现的“暴露偏差”问题[27],一种可行的方案是将强化学习技术融入到描述生成方法中。Ren等[28]将图像描述任务视作一个决策任务,并设计一个基于强化学习的模型来生成输入图像的自然语言描述。该方法使用一个“策略网络”和一个“价值网络”,在每个时间步共同预测下一个单词。Rennie等[29]提出一种自批判训练方式(self-critical sequence training,SCST),将测试指标(特别针对CIDEr指标)用于优化描述生成模型的训练过程,从而使模型在训练阶段和测试阶段保持一致。SCST方法避免了同时估计奖励信号和考虑如何规范化奖励的问题,利用推理阶段生成的描述语句作为“基线”,以鼓励生成更准确的最终描述语句。在此基础上,Anderson等[19]和Qin等[30]采用相似的方式来提高描述模型的性能,但在序列采样的方式上有所不同。前者提出一种结合Bottom-Up注意和Top-Down注意的模型,简称Up-Down模型,而后者则使用这个模型作为主干网络实现其“向后看”和“向前预测”(look back and predict forward, LBPF)模型。
2 图像描述生成方法
本文提出的图像描述生成方法同时集成数据集内部和外部的知识,因此称为IIEK (incorporating internal and external knowledge)方法,其总体框架如图2所示。IIEK方法试图为给定图像生成符合人类语言表达的描述语句,同时能够包含图像中没有直接表达的新概念和新知识。该方法包含2个新思路:一方面,设计一个特殊的单词注意力来处理图像区域与语句单词之间的不协调和不匹配的问题;另一方面,考虑了从外部知识图谱中提取的常识性知识,以生成新颖而有意义的描述语句。实际上,整个模型更加充分利用了内部的标注知识和外部的常识性知识来指导描述语句的生成,而提出的单词注意力和知识图谱方案以不同的方式分别利用内部知识和外部知识,共同生成更符合人类感知的图像描述语句。
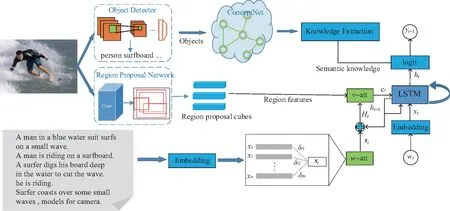
图2 IIEK方法的总体框架Fig.2 Framework diagram of IIEK method
2.1 图像特征提取及词嵌入
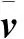
常见的单词嵌入方式是one-hot编码方式,即独热编码。这种编码方式将向量中的某一位设置为1其余位为0来表示词汇表的一个单词。如果词汇表中单词的数目过多,会使得one-hot向量变得稀疏,也会出现维度爆炸问题。而且,one-hot编码方式没有考虑单词之间的先后顺序,这对单词注意力的计算是不利的。因此,本文使用预训练的Word2vec模型进行单词嵌入。Word2vec模型实质上是一个神经网络,通过输入one-hot向量来训练得到最终的单词向量。Word2vec词嵌入充分考虑了单词之间的上下文信息,可以提供更加丰富的语义信息。
2.2 单词注意力的结合
本节探讨单词注意力以什么方式来提高视觉注意力的正确性。实际上,单词注意力的动机来自于这样一种认知,即某些单词与给定图像内容的联系比其他单词更紧密。那么需要做的就是加强这种联系,让这些单词在训练过程中起到更好的指导作用。最终,该模型可以学习到更合适的图像与语句之间的映射模式,从而提高生成描述语句的质量。
假定一张图像I,其对应的自然语言描述为S={w1,w2,…,wN},其中N表示描述语句的长度。序列学习方法通常使用RNN或LSTM在每个时间步长生成每个单词,本文在语言生成部分添加单词注意力来构建描述生成模型。在训练阶段,单词注意力主要依赖于真实标注语句,其操作表示如下:
δti=fw(wi);
(1)
(2)
(3)
式中:fw是计算分配给每个输入单词权重值的函数;xt是语句S中第i个单词wi的嵌入向量表示;st则是在时间t的单词上下文向量。每个输入单词对应的δ值保持不变,直到最后一个时间步。本文采用TF-IDF方法[31-32]作为函数fw,该方法通过计算出每个单词的得分来衡量单词在语句或文档中的重要程度。将单词上下文向量st与LSTM解码器前一时刻的隐藏状态ht-1融合,从而结合更紧凑的语义信息来引导视觉注意力,其计算表示如下:
Ht=st⊙ht-1;
(4)
(5)
(6)
(7)
式中:⊙表示元素相乘运算;We、Wv、Wh是学习参数;tanh是双曲正切函数;视觉上下文特征向量ct是所有图像区域的加权和。通过结合单词注意力提供的语义信息,LSTM编码器在时间t的更新过程如下:
it=σ(Wixt+Uict+Ziht-1+bi);
(8)
ft=σ(Wfxt+Ufct+Zfht-1+bf);
(9)
ot=σ(Woxt+Uoct+Zoht-1+bo);
(10)
gt=σ(Wgxt+Ugct+Zght-1+bg);
(11)
mt=ft⊙mt-1+it⊙gt;
(12)
ht=ot⊙tanh(mt);
(13)
(14)
式中:it、ft、ot、gt、mt和ht分别表示在t时刻LSTM的输入门、遗忘门、输出门、记忆门、记忆单元和隐藏状态;σ(·)表示sigmoid函数;W*、U*、Z*、b*是学习的权重矩阵和偏置项;最后式(14)使用生成机制[33]预测下一个单词,Mg是转移矩阵。
这样,单词注意力以可训练的方式插入到编码器—解码器架构中,从而更好地利用训练集内部标注的语句知识,使得生成的描述语句质量得到提高。
2.3 知识图谱的集成
在图像描述任务中,知识可以为生成描述语句提供大量线索。成对图像—文本数据集中每张图像对应的真实标注是人类为计算机自动生成描述提供的知识,可以称之为内部知识。然而,在许多现有数据集中,不可能包含所有必要的知识,这限制了图像描述语句的新颖性。因此,本文考虑从外部资源中获取知识来辅助描述生成,以提高描述模型的泛化性能。本文使用ConceptNet[34]来帮助模型进一步理解图像中隐含的意图。ConceptNet是开放的多语言语义知识网络,包含与人类日常生活密切相关的常识知识。
知识图谱中的每条知识都可以看作是一个三元组(subject, rel, object),其中subject和object代表现实世界中的2个实体或概念,rel是它们之间的关系。为了获得与给定图像相关的知识,首先使用Faster R-CNN来检测一系列视觉目标,然后使用这些视觉目标从知识图谱中检索语义上相关联的知识。图3给出了使用检测到的目标“surfboard”从ConceptNet中检索语义知识的示例。如图3所示,检索到每个知识实体对应一个表示相关程度的概率,这将作为模型利用知识的重要依据。对于每个被检测到的目标,选择相关的知识实体运用于描述任务,就可得到一个包含最相关知识的小型语义知识库WK。这里的关键问题在于如何应用从知识图谱中提取的重要语义知识来指导描述生成的过程。不必要的输入可能会在训练阶段产生噪声,从而降低模型的性能,因此,本文并不直接将语义知识输入到LSTM的输入层进行训练,而是在预测下一个单词时,增加在所构建的语义知识库中出现的词汇表中的某些单词的概率。将式(14)的生成机制改为
(15)
式中λ是一个控制引入语义知识程度的超参数,并通过自行设置其值实现。如果单词wt+1存在于构建的语义知识库WK中,则单词的预测概率将由生成机制的预测概率和相应的检索概率pk(wt+1)决定。通常,应用一个Softmax函数于式(15)来获得一个归一化的单词概率分布。在计算时,每个单词都是以向量的形式存在,通过式(15)来得到单词的概率分布,而在预测当前单词时一般可以利用贪心搜索或者集束搜索,通过给每个可能的单词增加一个额外的概率,模型就能够发现一些隐含的线索,从而产生更多新颖和有意义的描述。
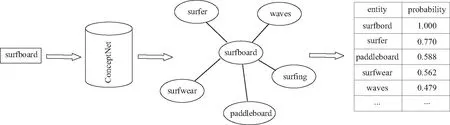
图3 外部知识的抽取过程Fig.3 Extraction process of external knowledge
2.4 基于强化学习的序列生成
在训练和推理阶段,本文提出的2个方案不仅可以适当地结合在一起来指导描述生成过程,而且每个方案都可以单独实现,以解决之前模型中存在的不同缺陷。本文模型采用主流的序列生成方式,也就是描述语句是按照一个单词接着一个单词生成,通常通过优化交叉熵损失函数训练模型,
(16)

Lr(θ)=-Ew1:T pθ[r(w1:T)],
(17)
式中r(w1:T)是评分函数。这里如文献[19,30]一样选择CIDEr,这个损失函数的梯度可以近似为
(18)
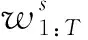
上述基于强化学习的训练方法的核心思想是,将当前模型在测试过程中使用的推理算法所获得的奖励作为强化算法的基线。这种方法使模型在训练和推断期间保持一致,从而显著提高了生成描述语句的质量。在本文实验中,结合强化学习训练方式的有效性得到了验证。
3 实验结果分析
本章通过实验来评估所提出模型的有效性。首先介绍实验用的基准数据集和评估指标,并给出实验的实现细节,然后将本文方法与其他先进方法进行对比,并对生成描述语句的结果进行定量和定性分析。
3.1 数据集和评估指标
本文算法以及模型是基于Pytorch框架实现的,使用的计算机环境为Intel 第8代i7 CPU和Geforce RTX 3090 GPU,主要使用MSCOCO 2014数据集来验证模型的有效性。这个大型数据集包含123 287张图像,每张图像至少有5个真实标注语句用于图像描述任务。为了与其他方法进行公平比较,对数据集采用广泛使用的“Karpathy”划分方法[38],得到113 287幅图像用于训练,5 000幅图像用于验证,5 000幅图像用于测试。另一个用于评估的Flickr30k数据集包含31 000张图像。Flickr30k数据集没有提供官方的划分标准,所以在实验中同样采用文献[38]的划分方法,即29 000幅图像用于训练,1 000幅图像用于验证,剩余1 000幅图像用于测试。词汇表由MSCOCO标记语句中经过小写转换和标记化之后至少出现5次的单词组成,单词的个数为9 568个,包括语句开始标记〈start〉和语句结束标记〈end〉。
自动评估机器生成的描述语句的质量仍然是一个巨大挑战,这主要是因为机器缺乏像人类那样独立做出适当判断的能力。现有的图像描述任务评价指标主要根据真实标注语句与生成描述语句的一致性来计算。实验中使用的评价指标包括BLEU[39]、METEOR[40]、CIDEr[41]和ROUGE-L[42]。BLEU指标是评估机器生成语句中最常用的一种指标,基于n-gram计算,因此实验中选择BLEU-1、BLEU-2、BLEU-3和BLEU-4来评估模型性能。METEOR指标是为了弥补BLEU指标不足而设计的,将句干和同义词纳入考虑来评价生成的语句。CIDEr指标衡量人工标注语句和生成语句的共识度,它主要是为自动描述生成设计的。ROUGE-L指标则更加关注召回率。
3.2 实现细节
本文使用Faster R-CNN来检测图像中包含的目标,Faster R-CNN首先在Visual Genome数据集上进行预训练,然后在MSCOCO数据集上进行微调。Faster R-CNN的组成部分RPN网络也被运用于生成图像的区域特征,并且建议区域的个数设置为36。因此,对于每一幅经过预处理得到的256×256大小的图像,可以得到36个2 048维的图像特征向量,在编码阶段所有的向量固定以这个维度控制输入输出进行加强优化。在解码阶段,使用LSTM作为语言生成器,其输入层和隐藏层数量均设置为512。Word2vec嵌入向量的维度同样设置为512。由于复杂的网络结构会导致模型过拟合,采用dropout技术随机灭活网络中一些神经元,并将dropout率设置为0.5。超参数λ的值设置为0.2,其选取情况在下文给出。
整个训练过程分为2个阶段:在第一阶段,利用交叉熵损失函数训练模型,训练的批量大小为64。使用Adam优化器来加速模型收敛过程,初始学习率设置为5×10-4,动量大小设置为0.9。在训练过程中,每经过5个epoch,学习率衰减为原来的0.7倍。为了得到较优的模型,本文选择BLEU-4作为监控指标,当BLEU-4得分在连续3个epoch都下降时停止训练。在第二阶段,运行强化学习优化算法,选择前面最优的模型继续训练。由于第一阶段的训练已经使模型达到收敛,这时通过使用生成的语句直接对CIDEr指标进行优化,改变了模型梯度陷入局部最优的状态,使模型进一步优化。在这一阶段,将训练的批量大小调整为32,学习率固定为1×10-4,其余参数的设置不变。在推理生成语句时,使用集束搜索技术,从候选语句集中选择最合适的描述语句,集束大小设置为3。
3.3 在MSCOCO和Flickr30k数据集上的结果
本文方法主要在MSCOCO和Flickr30k数据集上进行验证评估。为了证明IIEK方法的有效性,将IIEK方法与其他先进方法进行比较,包括基于注意力的方法、集成外部知识的方法和基于强化学习训练方式的方法。表1显示了IIEK方法与其他先进方法在MSCOCO数据集上的比较结果。可以看到,IIEK方法在几个指标上都优于其他方法,特别是在BLEU指标和ROUGE-L指标上,其中BLEU-1、BLEU-2、BLEU-3、BLEU-4、ROUGE-L的得分分别为0.792、0.640、0.489、0.371和0.573。除了基于强化学习训练方式的SCST方法外,IIEK方法性能明显优于其他方法。而与SCST方法相比,IIEK方法在BLEU-4和ROUGE-L指标上分别提高了3.8个和2个百分点。表2展示了在Flickr30k数据集的比较结果。由表中可以看出,IIEK方法与其他方法相比取得了更佳的性能。Flickr30k数据集包含较少的训练数据,导致性能小幅降低,即便如此,本文模型在所有标准的评估指标上都取得了很好的结果。
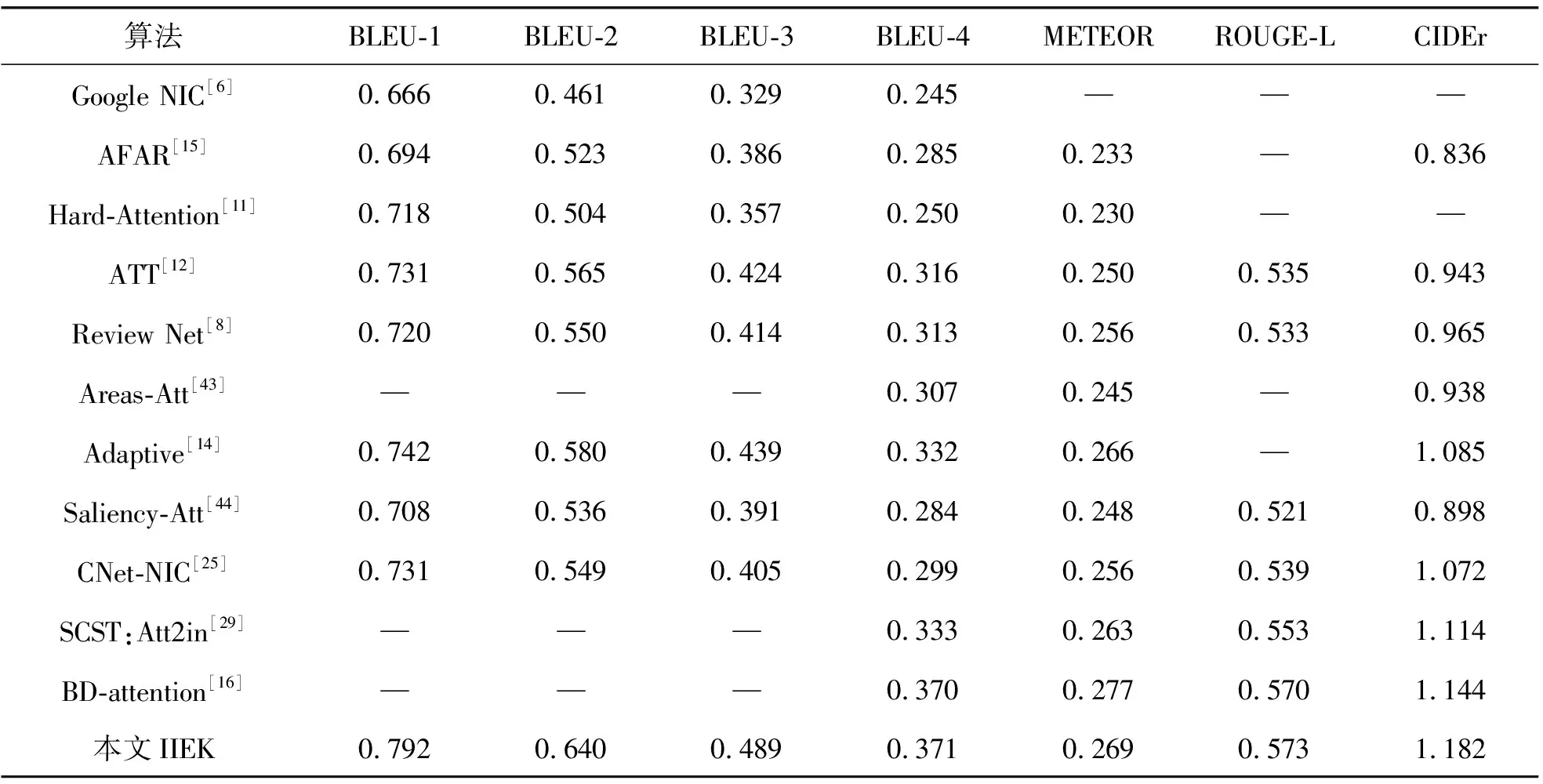
表1 在MSCOCO数据集上与其他先进模型的比较结果
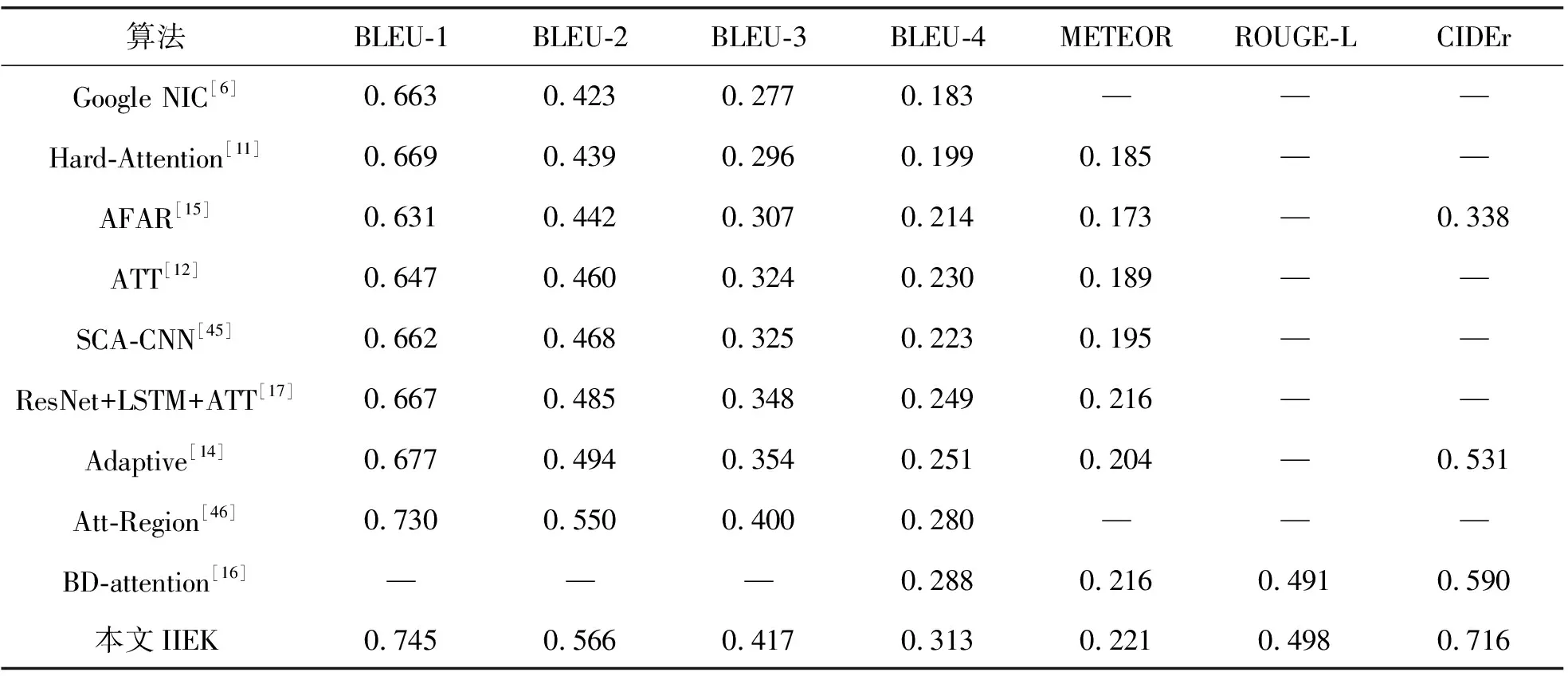
表2 在Flickr30k数据集上与其他先进模型的比较结果
3.4 引入外部知识的结果分析
现有的图像描述生成方法通常描述图像中少量的显著目标,描述语句中很少超过4个目标。为了进一步证明本方法的有效性,从MSCOCO数据集中随机选取500张图像以及对应的标注语句信息,使用Stanford CoreNLP工具对标注句进行词性分析与名词提取,对标注语句中出现的不同名词目标的数量进行统计。图4(a)中给出了图像对应的5个标注语句中出现所有目标情况,图4(b)中给出了语句集中每个标注语句包含的目标情况。图中可以看出,对给定图像,对应的5个标注语句中包含4个和5个目标的情况比较常见,然而每个标注语句通常描述图像中2~4个目标。受制于描述语句的长度,以及图像中有些目标通常存在密切的联系,如“person”一般与“shirt”和“shoe”同时出现,因此,在实验中,只根据检测到的目标的得分来选择前3个目标。
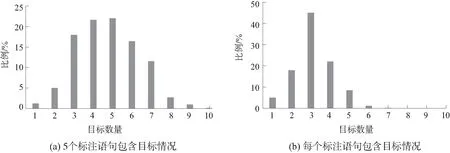
图4 标注语句的目标分布情况Fig.4 Target distribution of annotation statements
然后,对于每个目标实体,分别从知识图谱ConceptNet中检索相关的语义知识,每条知识包含2个部分:语义实体和相关概率。最后,本文使用超参数λ来控制引入知识的程度,而λ的值直观地设置为从0到0.9的10个值。图5显示了BLEU-1、BLEU-2和ROUGE-L指标得分随参数λ值变化的情况。当λ=0时表示不应用外部知识来促进描述生成,尽管如此也得到了较好的效果。可以看到,其中BLEU-1指标和ROUGE-L指标的得分在λ=0.2时同时取得最大值,而BLEU-2指标在λ=0.3时到达最大值。随着λ值的持续变大,这几个指标的得分呈现逐渐降低的趋势,甚至在λ=0.9时模型的性能表现得很不好。这是因为过于增大词汇表中的某些单词会使得模型的稳定性降低。不难想象,假如某些单词在预测时取得很高的概率,这将使得错误选取单词的概率也随之增加,从而降低了生成语句的质量。总体来看,本文引入外部知识的方法对实验定量指标得分的提高是有限的,但本文方法实现的目的主要是为了让模型生成更加新颖和有意义的描述。为了取得最大效益,其他实验中将λ的值设置为0.2。
3.5 视觉注意力可视化分析
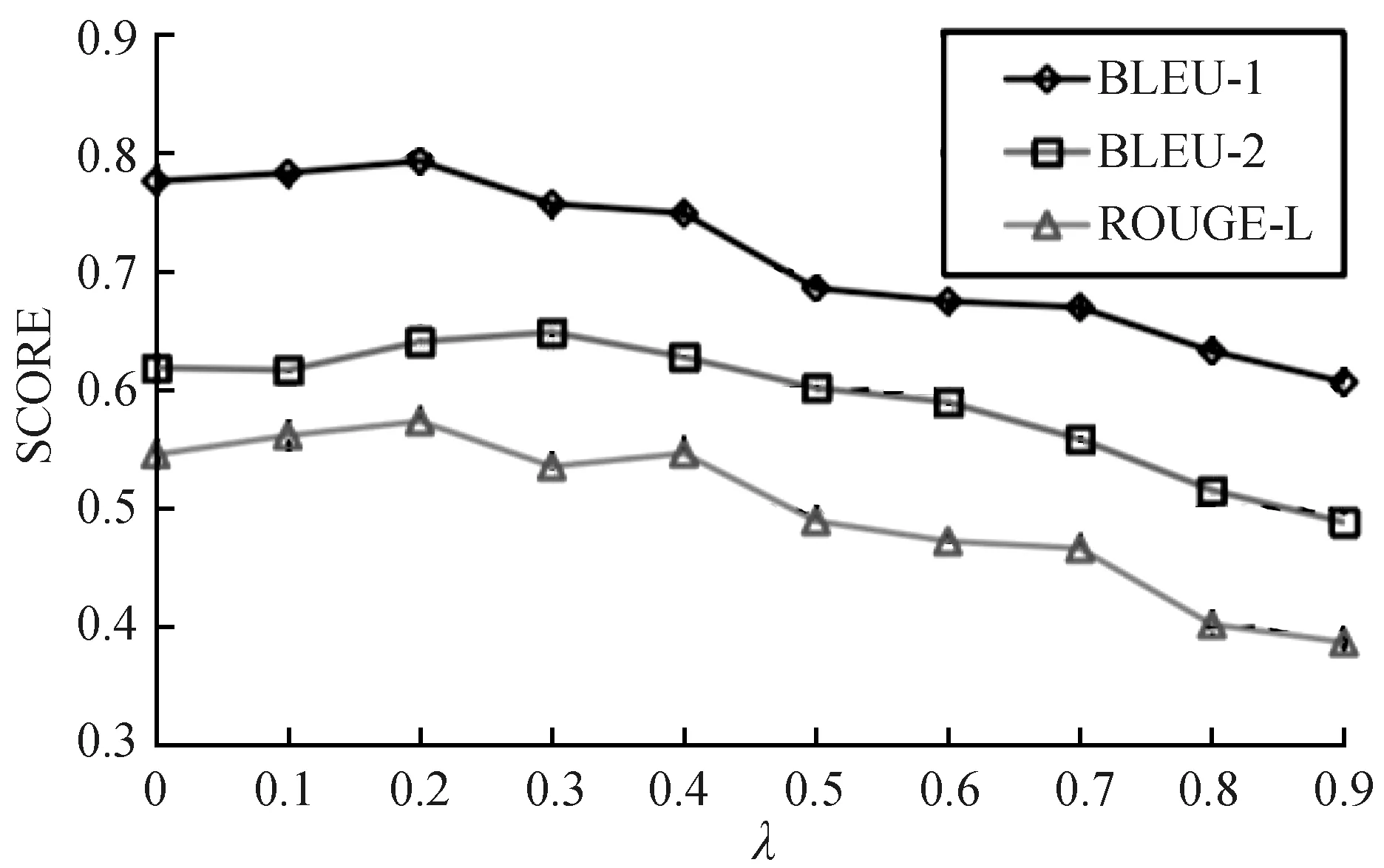
图5 不同λ值对实验性能的影响Fig.5 Influence of different λ values on experimental performance
本文将视觉注意力的结果在像素级别上进行可视化分析,从而更好地验证单词注意力对视觉注意力的优化作用。图6显示了当模型聚焦于图像不同区域时的语句生成示例图,也就是视觉注意力的可视化结果。其中图6(a)表示结合提出的单词注意力后视觉注意力引导语句生成的示例图,图6(b)表示从模型移除单词注意力后视觉注意力引导语句生成的示例图。通过这个例子可以看出,在生成描述性词语时,添加单词注意力的模型在生成描述语句时可以准确地聚焦在图像的适当位置,而没有添加单词注意力的模型在聚焦图像时会比较分散。例如,在生成“man”和“car”这2个重要单词时,可以明显看出,本文的模型可以聚焦于图像中更准确和更集中的区域。特别地,在生成第1个单词“a”时,尽管图像中没有与之直接对应的目标实体,但是通过第2个描述的单词“man”可以得知,它们对应的应该是相近或相同的图像区域,而模型添加单词注意力后更符合人类的这种感知。同时,添加单词注意力后,模型可以生成“parked”这个描述性单词,使得整个描述语句更加详细。实验表明,本文提出的单词注意力与标准的视觉注意力相结合,可以很好地促进单词生成过程,并有助于生成更准确、更细粒度的描述语句。

图6 视觉注意力引导下语句生成示例Fig.6 Visual attention guides the following statements to generate sample graphs
3.6 定性结果分析
为了评估整个模型生成的描述语句的质量,并进一步验证本文提出的2个方案的有效性,对实验结果进行定性分析,其可视化结果如图7所示。可以看出,通过将单词注意力和知识图谱结合起来,本文方法可以生成更细粒度的描述,同时也可以揭示图像中隐含的内容,而这些隐含内容通常不容易被机器发现,但对人类来说并不困难。例如,看第1张图片,本文方法可以预测目标“court”,即使它不是直接出现在标注语句中。但是利用目标“tennis racket”从知识图谱中检索到的相关知识中包含“court”实体,本文方法在生成单词时适当增大了选取单词“court”的概率,使得“court”出现在最终的生成语句中。同时,该方法更倾向于使用检测到的目标来描述图像,而这些目标也出现在构建的语义知识库中。然而,由于目标检测模型在训练时受限于数据集中目标的类别,使得本方法在最后一张图片中检测到了错误目标“dining table”,从而利用了错误的语义知识,如“food”。并且,在这张图片中,本方法不能描述目标“table”和“computer”,是因为本方法与现有的大多数方法一样,受到描述语句长度的限制,在处理具有多个目标的复杂图像时表现不佳。此外,在利用图像的标注语句指导模型生成新的描述语句过程中,单词注意力为标注语句中出现的重要单词赋予更大的权重,如第2张图片和第3张图片分别对应的标注语句中的“wave”和“cat”,使得它们更易于出现在生成语句中。

Detected objects:person; tennist racket; sport ballKnowledge entities:man; woman; tennis; pickleball; badminton; racquet; racket; court; hard courtGenerated:A tennis player is playing tennis in the court.Annotations:A man in blue tennis shorts and a while polo shirt braces to hit the tennis ball. A tennis player locked on to the tennis ball with his racket and eyes. A middle-aged man is about to hit a tennis ball with his racket. A tennis player attempts a backhanded shot. A man in a white shirt is playing tennis. Detected objects:person; surfboard; beachKnowledge entities:man; woman; surfboard; wave; surfing; surf wear; surfer; pad-dle board; water; over waterGenerated:A man riding a surfboard on top of a wave.Annotations:Surfer performing one of his moves on a nice sunny day with a scene in the background. A skilled surfer grabbing the tip of his board while the rides a wave. One male surfer doing a turn on a surfboard in the o-cean.A surfer in a black wetsuit catches a small wave. Man surfing a wave and pulling off a trick. Detected objects:person; cat; aeroplaneKnowledge entities:man; woman;girl; cat; dog; kit-ten; sharp teeth; aeroplane; air-plane; fly machineGenerated:A girl is playing a top airplane next to a cat.Annotations:A little girl dressed in pink on the floor playing with a toy airplane with a cat looking on. A cat is watching the movement of a young girl who is playing with a toy airplane.A girl and her cat are curious to see how this airplane is built with Legos.A small child plays with her airplane as a cat looks on.A cat is watching a girl construct a Lego airplane. Detected objects:person; chair; dining tableKnowledge entities:man; woman; table; tabletop; worktable; place mat; chair; so-fa; bed; foodGenerated:A man in a black shirt is speaking using powerpoint.Annotations:A wan in a black polo and khakis is giving a powerpoint presentation.Man presenting a powerpoint presentation for several people.A man in a black shirt is addressing a group of people.A gentlemen is giving a presentation via powerpoint.A man is standing before a classroom and speaking.
图7 IIEK方法生成描述语句的实例
Fig.7 IIEK method generates an instance of the description statement
综上所述,本文方法适用于大多数场景的描述,具备良好的有效性和鲁棒性。从定量评价指标上看,本方法与当前最先进的方法相比也具有优势。从定性实验结果上看,本方法生成的描述语句在某些场景下能够发现图像中的新目标和隐含信息,使得描述语句的表达和语义更符合人类感知。
4 结论
图像描述是具有广泛应用前景的研究课题,本文探索如何集成更多的语义知识来指导模型生成更加准确和有意义的描述语句,包括训练数据中的内部标注知识和抽取自知识图谱的外部知识。首先,提出一种新的文本相关注意力机制,称之为单词注意力,以提高在序列生成描述语句时的视觉注意力的正确性。这种特殊的单词注意力在关注输入图像的不同区域时强调单词的重要性,并为视觉注意力的计算提供重要的语义信息。结果表明,结合了单词注意力和视觉注意力的模型能够有效提高图像中区域与语句中单词的一致性。然后,将从知识图谱中抽取的常识性知识注入到编码器—解码器架构中,生成更新颖和有意义的描述语句,这也提高了描述方法的泛化性能。此外,本文还利用强化学习来优化模型训练过程,从而使生成描述语句的质量有了显著提高。通过结合上述几种策略,本文方法在几个标准的评估指标上获得了良好的性能。未来的工作将探索如何更高效地利用知识图谱来促进图像描述语句生成,基本方向是利用给定图像—文本对的训练数据的图像级和语句级语义信息来自主构建更紧凑的知识图谱。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
开放教育研究(2020年2期)2020-03-31 01:54:14
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
语文知识(2014年4期)2014-02-28 21:59:52
外语学刊(2011年1期)2011-01-22 03:38:33
