
知识矩阵表示
2022-10-19 05:07张师超李佳烨
广西师范大学学报(自然科学版) 2022年5期
张师超, 李佳烨
(1.广西师范大学 计算机科学与工程学院, 广西 桂林 541004; 2.中南大学 计算机学院, 湖南 长沙 410083)
当前,人工智能迎来了第3次发展热潮,主要归功于大数据资源的利用需求增长和深度学习技术的突破[1]。严格地说,AlphaGo展现出的对人类棋手棋谱归纳学习能力,给人一种智慧革命的震撼[2-3]。所以,这次热潮是以神经网络学习为主的机器学习获得快速发展的一次机遇,是人工智能引导工业革命的一次期盼,也是人工智能自身再突破发展的又一次起航[4]。
深度学习现在几乎是机器学习与数据挖掘的代名词,近几年发表在相关会议和期刊上的研究成果几乎是清一色的深度学习改良与应用。比如,Albawi等[5]指出卷积神经网络在图像处理和自然语言处理等领域表现十分出色,取得了惊人的结果。Zhang等[6]提出异构图神经网络,具体地,首先引入一种带重启的随机游走策略来为每个节点采样固定大小的强相关异构邻居,并根据节点类型对它们进行分组;然后,设计一个包含2个模块的神经网络体系结构,以聚集这些采样相邻节点的特征信息;最后,利用一个图上下文丢失和一个小批量梯度下降过程以端到端的方式训练模型。苗旭鹏等[7]利用图神经网络将计算图的子图优化建模成经典的子图匹配问题,并估计每种子图替换规则的可行性。黄春等[8]为深度学习设计了批处理分块矩阵乘法。其实,AlphaGo的人工神经网络系统涵盖了人工智能的核心基础领域:知识表示、推理、机器学习和知识库[9-13]。众所周知,人工神经网络是一种经典的知识表示方法,通过神经元从仿生学角度模拟人类的智能行为[14-15]。深度学习扩展了传统人工神经网络的表示能力,增加了隐藏层次,执行特征学习[16-17]。Zhang等[18]提出数据的超类表示,改进了推荐算法运行效率,提高了推荐的速度。Yue等[19]利用矩阵表示对区间值直觉模糊神经网络进行改进,提高了最终真值的计算效率。Moroz[20]提出一个知识表示的概念模型,把知识表示为一种活跃的智力物质,并在此基础上研究在组织实践中单独或集体产生的知识转化过程的形而上学。该方法被应用到感知行为模型,它可以考虑机器人在其路径上遇到障碍物时可能出现的行为场景。Huang等[21]提出一种耦合本体和规则的知识表示方法,使用语义Web技术来丰富机器可读的方式,并正式表示地理可视化知识。除此之外,它还开发了一个原型系统来推断出相应的几何图形,以便在不同条件下进行可视化。可见,人工智能的核心基础问题依然是知识表示。
本文介绍一种知识表示方法——矩阵表示,称为知识矩阵表示。该方法利用矩阵的强大表示能力,将知识的某种关系表示成矩阵并定义相应演算。例如,在时态推理中,Allen[22-23]定义了时间区间的代数理论,为时间区间关系演算奠定了基础。其实,时间区间关系可以采用矩阵方法表示,是一个5×5的矩阵[24],时态关系演算与传播可以通过矩阵计算获得[25-26]。本文将重点描述时间区间关系的矩阵表示方法,同时,也阐述另外2种知识的矩阵表示方法:不确定性规则的矩阵表示和训练样本关系的矩阵表示。这3种矩阵表示方法针对不同的应用且是相互独立的,但它们都巧妙地改进了相应的算法。具体地,时间区间关系的矩阵表示把时间区间关系转化成矩阵表示,这样,时态关系的演算和传播就可以通过矩阵计算来进行了,可以有效提高时间区间关系的计算效率;不确定性规则的矩阵表示把不确定规则转化成一个条件概率矩阵,并利用该矩阵建立一个计算公式,以此来提高不确定性推理的效率;训练样本关系的矩阵表示可以把训练样本和测试样本之间的关系存储到矩阵中,在KNN中,通过该矩阵表示可以得到测试数据的K值和K个近邻,这使得KNN懒惰学习的部分被数学模型化,从而提高了KNN中寻找测试数据K近邻的效率。从这3种类型的知识矩阵表示可以看出,矩阵具有强大的表达能力,期待在更多领域中获得推广应用。
1 时间区间关系的矩阵表示
时态推理是一门研究含有时态词的命题及其推理形式的学科,其核心问题是时态关系演算[22-23]。最简单的时态命题是一个命题P附加一个时间区间I,即命题P在时间I期间为真。所以,时态关系演算通常被看成是区间关系演算[22],Allen[22-23]定义了时间区间的13种关系,见表1。

表1 Allen的13种时间区间关系与符号约定
1983年,Allen[22]不仅定义了时间区间的13种基本关系,也定义了复合关系表。2018年全国科学技术名词审定委员会公布的计算机科学技术名词中,艾伦区间代数(Allen’s interval algebra)就是其中之一。
1.1 时态矩阵表示
Allen区间代数的基本元素:时间区间I的2个端点值。其实,I可以被看成是时间轴的一个划分,分成5个部分:区间的左边IL、左端点I-、内部I1、右端点I+、右边IR。则13种时间区间的关系可以被重新描述,如表2所示。

表2 13种时间区间关系的简化说明
根据上述划分,文献[24]将2个时间区间X和Y之间的关系表示为矩阵,
(1)
式中X*·Y#∈{0,1},*,#∈{L,-,1,+,R}。X*·Y#=1,当且仅当X*和Y#的交集是非空的,否则,X*·Y#=0。
时间区间X和Y的13种关系可以分别被表示成如下矩阵:
总结以上时间区间之间的关系,如表3所示。
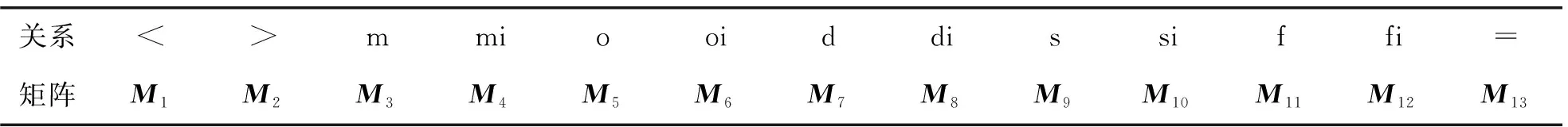
表3 时间区间X和Y的13种关系的矩阵表示对应
1.2 时态关系演算
定义1给定3个时间区间A、B和C,操作⊗和⊕定义如下:
1)B!·C%⊗A*·B@∈{0,1},且B!·C%⊗A*·B@=1,如果B!·C%=1且A*·B@=1。否则B!·C%⊗A*·B@=0。
2)B!·C%⊕A*·B@∈{0,1},且B!·C%⊕A*·B@=1,如果B!·C%=1或者A*·B@=1。否则B!·C%⊕A*·B@=0。
式中:!,%,*,@∈{L,-,1,+,R};⊗是逻辑“与”运算;⊕是逻辑“或”运算。
接下来,为了利用上面的矩阵更好地表示时间区间关系,定义矩阵的⊗和⊕操作。
定义2给定3个时间区间A、B和C,MA,B=(da,b)5×5和MB,C=(eb,c)5×5是时态关系矩阵,矩阵的操作⊗和⊕定义如下:
MA,C=MB,C⊗MA,B=((eb,1⊗d1,b)⊕(eb,2⊗d2,b)⊕…⊕(eb,5⊗d1,5))5×5,
NA,C=MA,B⊕MB,C=(da,b)5×5⊕(eb,c)5×5=(da,b⊕eb,c)5×5。
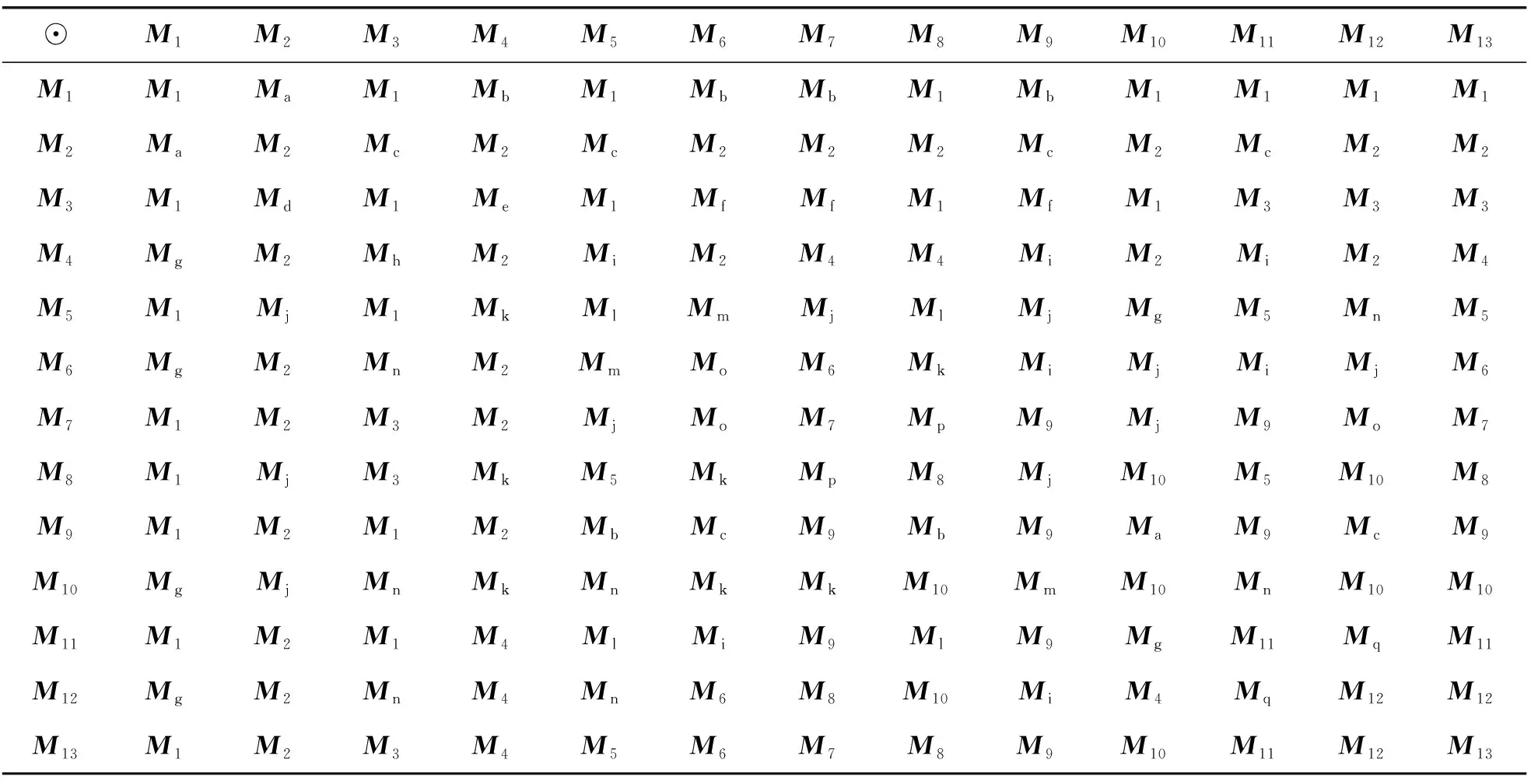
例如,让A (2) 因为Mi⊕MA,C=MA,C(i= 2, 4, 6, 7, 9)及Mi⊕MA,C≠MA,C(i= 1, 3, 5, 8, 10, 11, 12, 13),所以,A和C之间的关系可能是{>,mi,oi,f,d}之一。 Zhang等[24]提出的时态推理方法巧妙地把时间区间关系用一个矩阵表示,并根据矩阵构建了合适的时态推理规则,是一个很大的改进。时态关系演算在矩阵表示中就是矩阵计算: Ma=M1⊕M2⊕…⊕M13;Mb=M1⊕M3⊕M5⊕M9⊕M11; Mc=M2⊕M4⊕M6⊕M7⊕M9;Md=M2⊕M4⊕M6⊕M9⊕M11; Me=M7⊕M8⊕M13;Mf=M5⊕M9⊕M11; Mg=M1⊕M3⊕M5⊕M9⊕M10;Mh=M11⊕M12⊕M13; Mi=M6⊕M7⊕M9;Mj=M5⊕M7⊕M9⊕M11; Mk=M6⊕M10⊕M11;Ml=M1⊕M3⊕M5; Mm=M5⊕M6⊕M7⊕M8⊕M9⊕M10⊕M11⊕M12⊕M13; Mn=M5⊕M7⊕M10;Mo=M2⊕M4⊕M6; Mp=M7⊕M8⊕M13;Mq=M11⊕M12⊕M13。 (3) 13种时态关系的传播可以用表4来描述。 表4 13种时态关系传播 时态关系传播例子: (M3⊙M4)⊙M3=(M4⊗M3)⊙M3=Me⊙M3= (M7⊕M8⊕M13)⊙M3=(M7⊙M3)⊕(M8⊙M3)⊕(M13⊙M3)= (M3⊗M7)⊕(M3⊗M8)⊕(M3⊗M13)=M3⊕M3⊕M3=M3。 (4) 给定一个规则X→Y对应的关系矩阵, MY|X=p(y|x)=p(Y=y|X=x)=[p(yj|xi)]m×n, 式中:p(yj|xi)=p(Y=yj|X=xi)是Y=yj的条件概率;X∈{x1,x2,…,xm};Y∈{y1,y2,…,yn}。给定X=a=(p(a1),p(a2),…,p(am)),则能够通过式(5)得到Y=b=(p(b1),p(b2),…,p(bn))。 b=aMY|X。 (5) 式(5)是贝叶斯网络中著名的概率传播[27-28],其中MY|X是一个条件概率矩阵,它的第i行表示所有的事件Y在xi发生的条件下发生的概率,第j列表示第j个事件yj在X发生的条件下发生的概率,每一个元素p(yj|xi)表示第j个事件yj在xi发生的条件下发生的概率。本章的目的是寻找一个新的近似传播方法来替代式(5)[29],具体地,如以下4点: 1) 编码向量a为一个整数EX(a)。 2) 编码向量b为一个整数EY(b),其中b=aMY|X。 按照矩阵表示模型,需要构造以下形式的多项式函数, (6) 不失一般性,假设n=2,即得到公式(7), (7) 接下来,首先对EX和EY进行编码。 定义3设R(X)={x1,x2,…,xk},X的状态空间为 编码器EX被定义为 EX(p1,p2,…,pk)=10dp1+102dp2+…+10kdpk。 (8) 式中d>0是一个正整数。如果被要求的小数位数为r,则d=r+1,否则d=n+1。 理论 1以上的编码器,即式(8),是一对一映射的。 证明归谬法。让(p1,p2,…,pk)的编码等于(p′1,p′2,…,p′k)的编码,即, EX(p1,p2,…,pk)=EX(p′1,p′2,…,p′k)。 (9) 假设当i=j1,j2,…,jm时,pi-p′i≠0,其中j1 (10) (11) 加入系数之后,进一步得到 (12) 因为jm-1 (13) 与之前的假设相矛盾,因此编码器EX()是一对一映射的。证毕。 bi=(INT(F(a)/10(i-1)d)-INT(F(a)/10id)×10d)/10d。 (14) 式中i=1,2,…,m,INT()是取整函数。为了确保概率和为1的性质,最终结果如下: b1=max{0,1-(b2+b3+…+bm)};bi=bi/(b1+b2+b3+…+bm),ifb2+b3+…+bm>1。 (15) 在计算模型中,假设因计算误差导致仅p(y1)的概率被改变,解码时设置b1=max{0,1-(b2+b3+…+bm)}。 (16) 利用式(16)分别对k2、k1和k0求偏导,并令导数为零,得到: (17) (18) (19) 通过求解,可以得到k2、k1和k0的值如下: (20) (21) (22) 式中: 作为十大数据挖掘算法之一的KNN分类,被广泛应用于文本分类、模式识别和图像处理等领域[30-32]。它的核心思想是,寻找到测试样本的K个近邻并把近邻样本的多数标签作为测试样本的预测标签。其中,寻找测试样本的K个近邻(测试样本与训练样本之间的关系)至关重要,影响着算法的最终预测准确性。 本章利用矩阵表示的方法来构建测试数据和训练数据之间的关系。给定一个包含n个训练样本的数据矩阵X∈Rn×d,m个测试样本的数据矩阵Y∈Rm×d,构建式(23)所示的目标函数来进行矩阵表示下的一步KNN: (23) (24) 式(24)中W∈R6×5,它表示了5个测试数据和6个训练数据之间的关系。在矩阵W的第1列中,第3、4、5个位置的元素为零,即表明与第1个测试数据关系最近的训练样本是第1、2、6个训练样本,且它的最佳K值为3。相似地,对于第2个测试数据,它的近邻是第1、2、3、5个训练数据,它的最佳K值为4;对于第3个测试数据,它的近邻是第2、3、4个训练数据,它的最佳K值为3;对于第4个测试数据,它的近邻是第1、4、5、6个训练数据,它的最佳K值4;对于第5个测试数据,它的近邻是第2、3、6个训练数据,它的最佳K值是3。 通过以上目标函数,可以把KNN算法通过矩阵表示的一步计算来进行。即,通过式(24)的矩阵表示计算,可以得到所有测试数据的最佳K值和对应的K个近邻。接下来,需要对目标函数进行优化求解,以得到最终的W值。 在这一节中,对所提出的目标函数进行优化求解。首先通过定理1可以对式(23)进行转化。 定理 1公式(23)等价于 (25) 式中θ可以由式(26)得到, (26) (27) 通过求解式(28)来得到θ的最优解, (28) 进一步得到θ的最优解为 (29) 由式(29),式(28)可以写成 (30) 因此,式(23)可以重新写为 (31) 当α=0时,式(31)可以看成是Group lasso。在Group lasso中,所有的样本被分组,每一组中的样本都是相似度很高的。组与组之间的样本是相似度很低的。它用l1-范数对组内进行稀疏,用l2-范数对组间进行不稀疏。这样可以有效地从所有训练数据中选出测试数据的近邻样本,并得到最佳K值。 式(31)等价于 (32) 式中Q和F都是对角矩阵,它们的对角线元素为: (33) (34) (35) (36) 下面给出算法的伪代码。 算法 1一步KNN算法。 输入:训练样本X∈Rn×d,训练数据的标签Xlabel∈R1×n,测试数据Y∈Rm×d,可调参数α和β; 输出:测试数据的类标签。 1.初始化t=0; 2.随机初始化矩阵W(0); 3.利用余弦相似函数或模糊C均值聚类对数据进行分组,从而构建IGg; 4.do{ 4.1 通过式(34)计算F(t+1); 4.2 通过式(33)计算Q(t+1); 4.3 通过式(36)计算W(t+1); 4.4 更新t=t+1;} 5. while (式(23)收敛) 如上述伪代码所示,在算法中,本节采用交替迭代优化的方法来求解W,即固定一个变量去求解其他变量的方法。当W被随机初始化之后,可以利用W中的值来计算出F和Q矩阵,然后根据式(36)计算出新的W矩阵,不断迭代,直到式(23)收敛,从而获得最终的W矩阵。 为了证明所提出的目标函数是收敛的,首先引入下面的引理和推论[33]。 引理1对于任何2个非负向量a∈Rd×1和b∈Rd×1,以下式子成立: (37) 推论1根据Cauchy-Schwarz不等式,可以得到 (38) 因此,可以得到 (39) 接下来,证明目标函数式(32)的值在每次迭代中是单调递减的,即目标函数是收敛的。通过设置W在第t次迭代的值为W(t),式(32)可以写成 (40) 进一步,可以得到如下式子: (41) 根据引理1,可得: (42) 由式(41)和式(42)可得: (43) 至此,可以证明所提出的目标函数是收敛的。 在这一节中,KNN分类可以被分为3步:1)利用距离函数或相似性计算函数来得到测试数据与所有训练数据的距离;2)根据这些距离,选取离测试数据最近的K个近邻;3)根据K个近邻的类标签来获取测试数据的标签。而用样本关系的矩阵表示可以把前2步合并为一步,如式(24)所示,矩阵W中记录着训练数据与测试数据的相似性和它的K个近邻的索引信息。 本文主要从3方面介绍知识矩阵表示,即:时态推理中的区间关系;产生式规则的相互关系;KNN的近邻寻找和K值计算。矩阵表示在这3个方向上都简化了算法的过程,使其从知识表示的根本上改进了相应算法。但是在这3方面仍然具有一些挑战: 1)高维数据带来的挑战。在人工智能时代,随着数据的海量增长,各行各业的数据维度都在不断增长,从而带来“维度灾难”,这给人工智能算法带来巨大的挑战[34-35]。因此,本文所提出的知识矩阵表示方法也面临这样的挑战,比如,在KNN算法中,本文虽然巧妙地把它的近邻寻找和K值计算转化成了矩阵表示下的矩阵计算,但是它仍然面临高维数据的挑战。因为随着数据维度的增加,KNN算法的分类性能是先增后减的,当维度增加到一定程度时,它的性能会不断下降。另一方面,随着数据维度的增加,测试数据的最近邻和最远邻距离的区分度越来越低,这已在文献[36]中得到证明。 2)噪声和缺失数据带来的挑战。数据在收集或采集过程中往往会产生噪声,比如高斯噪声和白噪声,这些噪声都会对算法的性能带来一定影响[37-38]。除了噪声,数据中也可能存在缺失值[39-40]。如何处理数据中的噪声和缺失值是十分重要的。比如,在有缺失值的数据中,矩阵表示的形式就需要发生改变:①可以先对缺失值进行填充,然后再用矩阵表示;②改进矩阵表示方法,直接表示含有缺失值的数据,并应用于后续的数据挖掘任务。 除了以上2点存在于矩阵表示的问题之外,还可以扩宽矩阵表示的范围,即,矩阵表示不局限于本文提到的3个方向。比如:从矩阵表示下深度学习模型、矩阵表示下的随机森林算法和矩阵表示下的关联规则模型等方向进行一系列的研究。当然,知识矩阵表示的演算方法不固定,它需要针对具体内容的具体问题来定义。 综上所述,未来的研究可着眼于2方面的工作:①从降维、去噪和缺失值填充等方面去改进本文所提出的知识矩阵表示方法;②把知识矩阵表示应用到其他方向中,针对不同的模型定义不同的矩阵表示方法。1.3 时态关系传播
2 不确定性规则的矩阵表示
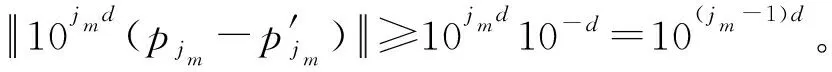
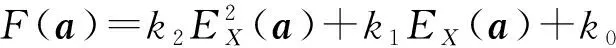

3 样本关系的矩阵表示
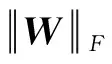

3.1 优化
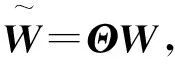
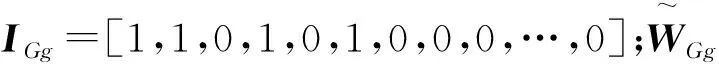
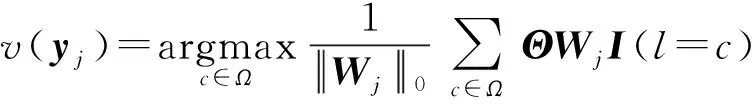
3.2 收敛性分析
4 未来工作展望
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24家庭影院技术(2021年2期)2021-03-29中国外汇(2019年13期)2019-10-10科学与财富(2018年30期)2018-12-28中学生英语(2016年15期)2016-12-01计算机应用(2016年9期)2016-11-01体育科技(2016年2期)2016-02-28北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27海外英语(2013年4期)2013-08-27体育师友(2011年5期)2011-03-20
