
基于强化学习的自适应网络覆盖优化算法研究
2022-10-19 13:02:08柳旭东朱晓荣
光通信研究 2022年5期
柳旭东,赵 夙,朱晓荣
(南京邮电大学 江苏省无线通信重点实验室,南京 210003)
0 引 言
移动通信网络在满足多样性需求的同时,也要提供高质量的服务支持[1]。因此,稳定的广域覆盖成为网络发展中首要的技术保障[2]。
对于覆盖问题,现阶段的研究方法主要为使用最优化方法求解基站参数的最佳调整值,从而提高覆盖率。文献[3]采用了黄金分割搜索;文献[4]采用了梯度下降法;文献[5]采用了粒子群算法;文献[6]采用了模拟退火算法。
上述方法依赖于对优化场景的大量假设,在实际网络运行的过程中,无线信号传播环境的改变会影响对优化场景建立假设的准确性与灵活性,对网络环境的应变有较大的局限性。若使用现网数据构建网络场景模型,在通用性与基站部署环境的灵敏度上均有较好的表现。此外,随着网络规模的扩大,能够积累运维经验并自主形成优化策略的人工智能方法,能够进一步提高网络运维效率[7]。
针对上述两个方面,本文使用将数据挖掘与强化学习相结合的思路,使用通过现网数据训练的预测模型作为强化学习环境,使用Q学习作为优化算法的主体,并在动作选择阶段,通过引入优先级调整智能体选择动作的策略,得到具有自适应优先级的Q学习。算法仿真表明,使用改进的Q学习算法可以将覆盖率提升20%,并有效提高了收敛速度。
1 系统模型
1.1 系统框架
针对移动通信网络覆盖场景,本文提出的覆盖优化系统模型如图1所示。
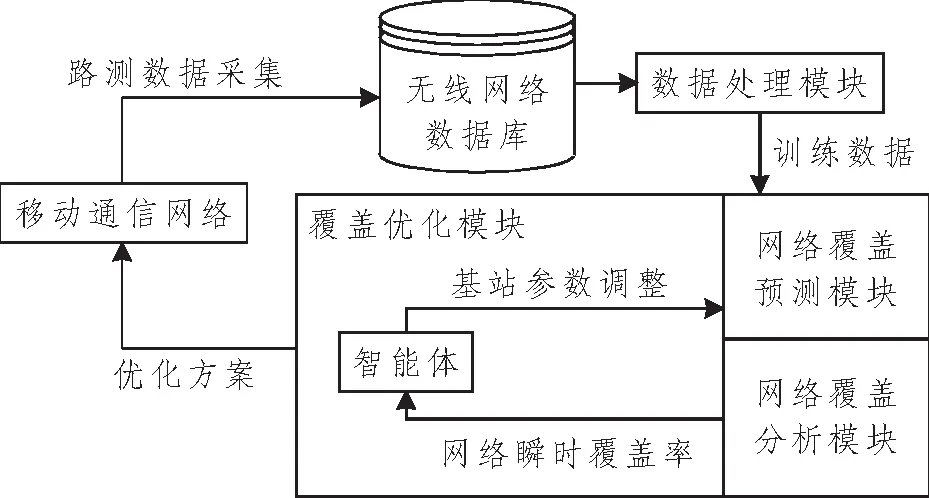
图1 覆盖优化系统模型Figure 1 Block diagram of coverage optimization system
首先,将从现网中采集到的路测数据在无线网络数据库中进行处理,包括数据去重、数据平衡化以及特征选择等操作。将处理后的数据根据网络覆盖标准,按照弱覆盖、重叠覆盖和正常覆盖3种情况添加标签。随后将已标记数据作为训练样本,进行覆盖预测建模,通过构建小区天线参数与其接入用户覆盖状况的映射关系,实现能够根据每个小区的不同参数调整,输出该小区内每个接入终端的覆盖标签,从而达到模拟真实网络环境的效果。本文使用的网络覆盖预测模型是随机森林 (Random Forest,RF) 算法[8]。RF算法包含多棵决策树,每棵树都作为一个分类器,在进行分类时,RF算法会将决策树中得到投票最多的标签作为整体的输出[9]。为保证模型的准确性,本文在第3节中使用现网数据对训练好的模型进行验证,并列出了覆盖场景中RF算法与其他常用算法的性能对比。
随后,本文提出了一种基于Q学习的自适应网络覆盖优化算法。Q学习属于强化学习的一种,通过学习求解出状态—动作与预计收益的映射表来实现优化的目的。如图1中覆盖优化模块所示,在每轮迭代开始时,智能体观测环境的状态,即计算网络中的瞬时覆盖率,并根据覆盖率维护一个优先级列表,覆盖率越低的小区会被设定越高的优化级。随后选择需要调整的小区,以及该小区的天线电子下倾角和天线发射功率的调整值,并将其输出到环境中;随后环境输出小区内所有终端的覆盖情况,通过统计计算得出小区以及全局的覆盖率,反馈给智能体一个奖励,智能体通过最大化奖励不断与模型交互,求解出在不同网络状况下的最优参数配置方案。
1.2 覆盖分析
网络中的覆盖问题主要分为弱覆盖与重叠覆盖。弱覆盖也叫作覆盖不足,定义为服务小区不能为接入的终端提供有效覆盖,通常表现为无主导小区、覆盖间隙以及覆盖盲区等。重叠覆盖定义为网内小区为移动台提供了过多的有效覆盖,通常表现为无主导小区和主导小区信噪比低等情况。在移动通信网络中,衡量覆盖程度最关键的参数是参考信号接收功率(Reference Signal Receiving Power,RSRP)。
弱覆盖点的判定标准是,若终端从其服务小区接收到的RSRP小于阈值K,则认为该终端处于弱覆盖。无线网络优化中规定弱覆盖判定阈值为-107 dBm。若假设用户设备位置为x,弱覆盖评价函数可表示为
式中:RSRP(x)为在x位置的参考信号接收功率大小;Pointweak为每个采样点的覆盖标签;W为终端采样点与弱覆盖阈值的偏差值。若W>0,则处于x位置的终端RSRP低于阈值,将其判定为弱覆盖样本点,并标记Pointweak=1;若W≤0,则将其判定为正常样本点,并标记Pointweak=0,表示该终端所处位置不存在弱覆盖问题。
在长期演进(Long Term Evolution,LTE)网络中对重叠覆盖的判定标准如下:
(1) 移动台RSRP>-105 dBm表示移动台可以正常接收有效信号;
(2) 移动台接收到来自邻区的RSRP与主服务小区同频率,若有当前小区频率earfcncell和相邻小区i的频率earfncelli,则表示为earfcncell=earfncelli,且信号强度差值小于6 dB,若有采样点收到来自主服务小区的参考信号接收功率RSRPcell和来自相邻小区i的参考信号接收功率RSRPcelli,则有|RSRPcell-RSRPcelli|<6 dB,表示移动台收到过多的有效信号;
(3) 满足条件(2)的邻区数量≥3个。
由此,重叠覆盖的评价函数可表示为
式中:RSRP0为从主服务小区接收到的RSRP;RSRPi为来自第i个邻区的RSRP[10];E为主服务小区的RSRP与相邻小区的RSRP的差值;celli为在目标区域内的基站;neighbors为当前主服务小区的相邻小区集合;Pointover为1表示该样本所处位置存在重叠覆盖问题,Pointover为0表示该样本所处位置不存在重叠覆盖问题。
1.3 优化参数
无线网络覆盖问题产生的原因可概括如下:
(1) 不合理的基站选址。
(2) 网络规划的结果与实际的覆盖效果产生偏差。在网络规划和部署之初,工作人员会根据基站部署地周边的传播环境和地理信息,结合指定的覆盖要求做相关的链路预算,并根据计算出的预留量来设定基站工程参数,如天线下倾角和发射功率等。随着基站周围的环境发生变化,如产生新的建筑造成遮挡,或产生新的覆盖需求等原因,最初的基站工程参数配置已不是最优配置。
(3) 基站的硬件设施故障。
解决弱覆盖的思路是,在弱覆盖地区找到一个合适的信号,并使之加强,加强信号主要通过调整天线的方位角和下倾角等工程参数以及修改功率等方式实现。另外在弱场引入远端射频单元(Remote Radio Unit,RRU)拉远也可以解决问题。重叠覆盖的解决思路也很明确,就是减小重叠覆盖小区的覆盖范围,使之对其他小区的影响减到最小。对下倾角和功率等参数的调整能够有效地减轻重叠覆盖问题[11]。
远程调整基站参数优化成本低,可操作性高,是实际工作中重点研究的优化对象和优化手段。此外,为了保证优化过程中不对网络造成负面影响,要求保证基站的正常运作,在改变天线挂高和机械下倾角时,需要关闭整个系统,实际工作中很少调整这些参数。本文使用调整天线的电子下倾角和天线发射功率作为优化手段提升覆盖率。
1.4 覆盖预测模型
本文采用RF算法构建小区天线参数与小区内采样点覆盖情况的映射关系,可以根据小区调整后的工程参数设置,预测出小区内接入终端覆盖情况的变化。RF算法属于多分类器系统,是集成学习算法之一,该算法通过构建并结合多个监督学习模型实现学习任务。
RF算法是基于集成学习框架下的决策树模型的,其算法流程如下:
(1) 对于数据集合大小为N的训练集合,随机有放回地从中抽取N条数据样本作为决策树的训练集合,重复K次,产生K组训练集合;
(2) 从总量为L的特征向量中随机选择l个特征;
(3) 利用已选取的l个特征训练决策树;
(4) 使用加权投票法产生最终预测结果H(x):
式中:wi为决策树的预测权重;hi(x)为每个决策树的预测结果。
因为RF算法在训练过程中引入了随机样本与随机特征,使得训练后的模型不容易陷入过拟合。此外由于多棵决策树的组合,使得RF算法在处理非线性数据时也能得到较好的效果,这些特性使得RF算法在网络覆盖预测的应用场景中能够有出色的表现。
1.5 优化目标
将单个小区的网络覆盖率表示为该小区内正常接入的终端采样点与总终端采样点的比值,若用Point表示小区内的采样点,则有:
式中:ratiowhole为全局覆盖率;ratiocelli为第i个小区的覆盖率;M为小区总数。覆盖优化的目标为弱覆盖率和重叠覆盖率最小,即最大化全局覆盖率。具体地,每次迭代产生小区的天线参数调整值,将其输入到覆盖预测模型中,对小区内所有采样点更新覆盖标签,进而计算出小区覆盖率。需要强调的是,式(7)中计算全局覆盖率的方式为所有小区的覆盖率加权和,为消除每个小区终端数量的差异带来的全局覆盖率计算偏差,在进行仿真前保证每个小区中采样点数量近似。
2 基于强化学习的覆盖优化算法
2.1 强化学习概述
强化学习是一类特定的机器学习问题,一个强化学习系统由环境与智能体两部分组成,智能体通过观察环境,做出行动,随后获取来自环境的奖励,因此强化学习是一个通过与环境的交互来学习如何最大化奖励的优化过程,本文使用Q学习作为覆盖优化算法。
若定义回报Gt为强化学习的奖励和,则有:
式中:t为一个确定性的变量,表示回合数;T为回合的总步数,是一个随机变量;γ为折扣系数;R为奖励信号。基于回报的定义,可以得到Q学习中对于价值函数qπ的表示:
式中:St为当前状态;At为当前动作;s为属于状态空间S内的状态;a为属于动作空间A中的动作;π为策略;E为期望。将π定义为从状态到动作的转移概率,表示为
式中:P为动作为a且状态为s的转移概率。
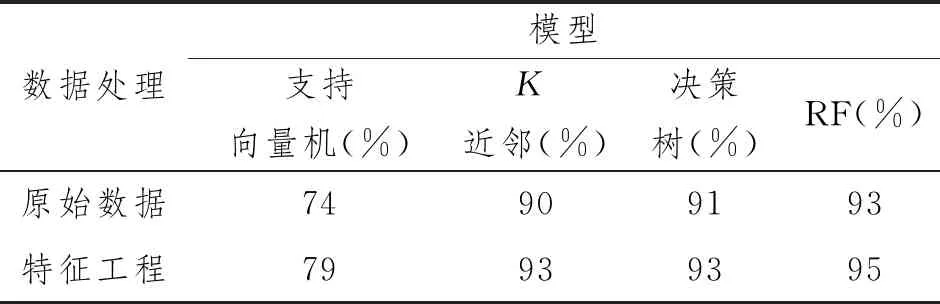
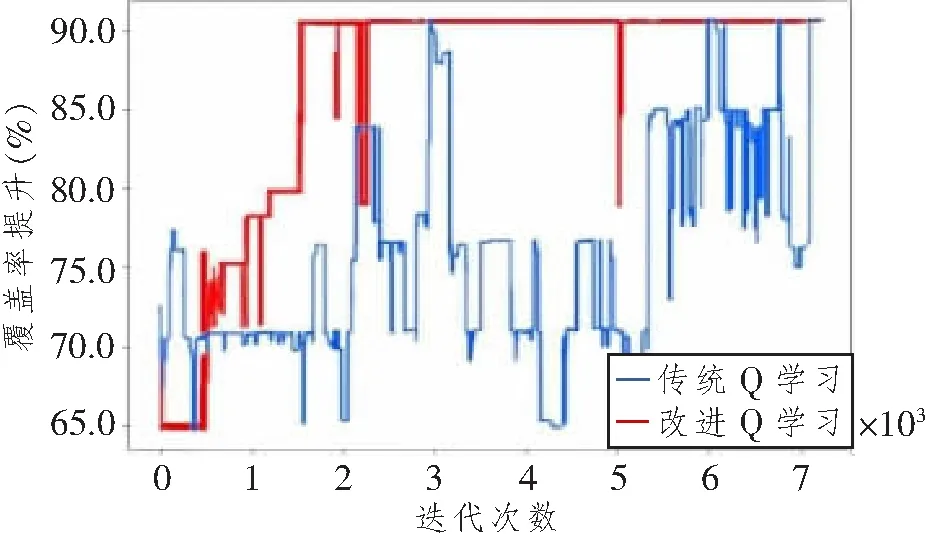
强化学习训练智能体的目的在于,在迭代的过程中,通过最大化回报来求解出最优策略。对于不同的策略π和π',若有任意s∈S,都有qπ(s,a) 式中,q*(s,a)为最优(动作)价值函数。 若有不止一个动作使得q*(s,a)最大,则随机选取一个动作执行即可[12]。q*(s,a)可表示为 式中,maxπ为在策略π下的最大动作状态函数值。 强化学习框图如图2所示,在每次迭代过程中,Q学习智能体将本次迭代所调整的小区编号、天线电子下倾角与天线发射功率作为动作输入到覆盖预测模型中,该模型会遍历小区中所有的采样点,输出与该小区对应的每个采样点的覆盖标签,从而计算出小区的覆盖率,以提高覆盖率为依据,环境在每一轮迭代中向智能体反馈奖励信号,智能体根据奖励信号更新价值函数。Q学习算法的输出是一张Q值表格,表示在每一个网络覆盖状态s下,选取优化动作a所能带来的回报,回报越高,表示选择该动作对于覆盖率的提升有越好的效果。 图2 强化学习框图Figure 2 Reinforcement learning block diagram 针对网络覆盖优化场景的Q学习问题,映射分为状态空间、动作空间、奖励函数、Q值更新以及改进的自适应优先级动作搜索算法5个方面,下面依次进行说明。 2.2.1 状态空间 将Q学习算法应用在网络覆盖优化场景中时,需要对状态空间进行一定的设置和约束。Q学习的状态反映了当前的无线网络性能状态,在本文的覆盖优化场景中,智能体每次选择区域中多个小区中的一个小区作为优化目标,调整其天线参数配置。将调整后的网络覆盖率和本轮迭代被调整的小区作为Q学习的状态,因此,本文描述的覆盖优化问题所对应的状态空间State可表示为 式中:Currenteci为当前调整的小区编号;Coverageeci为该小区对应的局部覆盖率;Coveragetotal为整个待优化区域的全局覆盖率。 2.2.2 动作空间 本文中涉及的覆盖优化问题是小区天线电子下倾角和天线发射功率的多维优化问题,因此将本文的动作集合Action设置为 式中:actioneci为选择调整参数的小区编号;actiondown_tilt和actionpower分别为天线电子下倾角和天线发射功率的调整,可表示为{increase,keep,decrease},分别为增加、保持当前不变和减少3个动作,在仿真部分会针对不同的调整步长做比较分析。 2.2.3 奖励函数 (1)治疗:对照组--抗感染治疗,青霉素静点200-2000万U/d;祛痰治疗,口服氯化铵0.3-0.6g/次;病情较严重者以利尿为主实施微循环改善辅助治疗,可使用药物为硝酸甘油(10-200ug/min)。观察组--在对照组治疗方法基础上,用冠心宁改善患者血液循环,若患者出现水肿伴心力衰竭,静推20-40mg/次。临床治疗需对两组患者进行密切观察与记录,根据患者病情加减药物。 Q学习作为强化学习的经典模型,学习的最终目标是构建一个q(s,a)值表格,这个表格反映了在每个状态下选择不同动作的收益,值越大表示该动作所带来的收益越高,收益由奖励信号通过式(8)和式(9)得出。 奖励信号为环境系统对于智能体上一步操作的评价。小区天线参数调整的目标是提高基站覆盖率,即将处于重叠覆盖或弱覆盖的接入终端数量降到最低,因此Q学习中的奖励信号参考全局覆盖率变化这一个量纲,由式(6)和式(7)得出。若有coveragecur表示当前覆盖率,coveragepast表示上一时刻覆盖率,n表示奖励的取值,则对奖励函数Reward的计算可表示为 当全局覆盖率提升时,表示当前小区的参数调整为积极有效的调整,此时应反馈给智能体一个正值奖励;若全局覆盖率下降,则表示当前调整为消极错误的调整,应反馈给智能体一个负值奖励;此外,当全局覆盖率在一次迭代后维持不变时,也应该反馈给智能体一个较小的负值奖励,表示当前的调整为无效调整,这样的设置可以缩短优化算法的收敛时长。 2.2.4Q值更新 在起始阶段,Q表中的每一个值会被随机赋值,当智能体每采取一个动作并执行后,就会产生一个相应的回报,智能体以此回报更新Q表内的数值。Q表中的值可以根据价值函数来进行更新,价值函数的更新可表示为 式中:Qt(s,a)为状态—动作对在t时刻的值函数;αt∈[0,1]为学习因子,用于控制学习速度,其值越大收敛速度越快,但是可能导致无法获得最优解;若有rt表示Q学习中当前瞬时的回报值,则(rt+γmaxa'(Qt(s',a')))为主要的更新内容。 2.2.5 改进的自适应优先级动作搜索算法 策略更新算法可能会以一个并不好的策略作为起始,在迭代过程中仅仅经过一些较差的状态,导致更好状态的价值函数没有得到更新,伴随着回合更新次数的增加,最优策略却没有找到。为解决此问题,可使用贪心策略进行动作选择,用于在迭代过程中覆盖所有的状态动作对。贪心策略可表示为 针对覆盖优化场景,本文将自适应小区优化优先级的概念融入上述贪心策略。对于一个由多个小区组成的区域,全局覆盖率可以由各个小区覆盖率的加权累和求出,如1.5节式(7)所示。对于式(17)所示的传统贪心策略,选择动作时,有a∈A(s),表示从所有的小区编号、天线电子下倾角调整值和发射功率调整值的所有组合中选取一个动作,因此可以缩小动作空间A(s)的范围为A'(s)。具体地,在计算每个小区的覆盖率之后,智能体可以优先选择覆盖率较低的小区进行调整,根据小区覆盖率列表,将动作空间缩小为A'(s)=[ECImin,Tilt,Power],式中,Tilt为基站天线的电子下倾角;Power为天线的发射功率;ECImin为覆盖率最低的小区,即对于每一个时刻,智能体优先选择覆盖率最低的小区,在确定了优化目标小区后,使用贪心策略和Q值表,从参数组合中选择执行的动作。使用自适应优先级的动作算法会加速算法收敛,优化曲线更加平滑,提高优化效果和效率。 综上所述,改进的自适应优先级动作搜索算法的实现过程如下: 输入:环境、策略π。 输出:动作价值函数q(s,a)。 1.初始化:q(s,a)←任意值,s∈S,a∈A。若有终止状态send,则令q(send,a)←0,a∈A。 2.对每个回合执行以下操作: 2.1.初始化状态动作对:选择状态s。 2.2.如回合未结束,执行以下操作: 2.2.1.以celli为单位,计算覆盖率并将其存入数组Dict[i],并用i表示对应的索引位置; 2.2.2.选择覆盖率最小的ECImin; 2.2.3.在状态s下,按照改进的贪心策略决定动作a; 2.2.4.执行动作a,观测得到奖励R和新状态s'; 2.2.5.计算回报的估计值U: U←R+γmaxa∈A(S')q(S',a) ; 更新q(s,a)以减小[U-q(S,A)]2。 为验证算法的可行性,本文使用来自江苏省南京市2020年7月某7天内的蜂窝网络数据,在北纬 31.770~31.784 °,东经118.820~118.862 °,约4.23 km2区域内采样。 本文使用的数据字段及其说明如表1和表2所示。 表1 基站侧数据 表2 采样点数据 表1基站侧的相关字段中,E-CGI由4部分组成:移动国家码、移动网络码、位置区号码和小区标识码。在采样点侧属性中,ECI为小区编号,提取基站侧属性E-CGI中的位置区号码和小区标识码字段,通过ECI将终端采样点数据与对其进行服务的小区数据进行关联拼接,作为一条完整的样本数据,即拼接后的数据中既包含终端采样点的数据,也包含该终端接入小区的工程参数配置数据,该样本数据用于训练覆盖预测模型。 本文使用数据来自于城市配送服务工作者配备的路测设备,因此采集到的数据中会夹杂重复数据,此外,还存在部分字段值缺失的数据。在数据处理时,首先应该对冗余和无效数据进行清除,随后对数据添加覆盖标签,以用于训练覆盖预测模型。文本按照式(2)和式(4),将正常采样点标记为0,将处于弱覆盖的采样点标记为1,处于重叠覆盖的采样点标记为2。最终得到6 880条数据,标签为0的采样点数据量为5 941条,占比86.3%;标签为1的数据量为447条,占比6.5%;标签为2的数据量为939条,占比13.6%。这是一个典型的不平衡数据集。使用类别标签失衡的数据集进行训练,会导致模型失效。合成少数类过采样(Synthetic Minority Over-sampling Techique,SMOTE)算法一直是解决不平衡数据集的一个有效方法[13],本文通过SMOTE欠采样与过采样结合的方法,首先对大样本数据进行欠采样,随后对重叠覆盖以及弱覆盖采样点进行过采样。平衡化前后的采样点分布如图3所示,由图可知,在保证合理分布的情况下,增加了弱覆盖和重叠覆盖这些小样本数据的数量。 图3 样本分布Figure 3 Distribution of Samples 本文使用基于强化学习的覆盖优化方法,是在覆盖预测模型的基础上进行迭代优化,因此覆盖预测模型的准确度是一个十分重要的性能指标。 本文选择的参与模型训练的特征包括:基站位置信息(经度和纬度)、接入终端位置信息(经度和纬度)、基站和基站与接入终端的距离信息、天线方位角、天线电子下倾角、天线机械下倾角和基站站高。 为了验证预测模型的准确性,将带标签的现网数据集合按比例切分为训练集合与测试集合,使用训练集合训练模型;随后使用测试集合来验证模型的预测性能。测试数据集与训练数据集拥有相同的结构,但对于模型来说属于陌生数据。将使用预测模型得到的标签与测试数据集中真实的标签计算,得到预测模型的准确率。 RF算法与其他标准分类算法的性能比较如表3所示。其中原始数据表示直接使用未经过数据清洗的数据,特征工程表示使用经过平衡化并对特征进行归一化处理后的样本数据。 表3 预测模型准确率对比 对比结果表明,RF算法对于新的输入数据具有很好的预测效果,且RF算法相较于其他预测算法,具有更好的预测性能。 图4所示为覆盖优化过程的迭代对比图,使用基于改进的Q学习算法,并将天线下倾角调整步长设置为1 °,天线发射功率调整步长设置为10 dBm时,将强化学习奖励值n取值为10,传统的Q学习在每一轮迭代中,随机选取一个小区进行优化,改进算法在优化过程中,优化动作被限定在覆盖率最低的小区所对应的动作空间中,因此在覆盖率提升方面呈现出稳定的逐步上升趋势,有更稳定的表现。在减少大量波动的情况下,迭代至1 400次时趋于收敛,相较于传统算法,收敛速度也得到了提升。优化后总覆盖率提升接近20%。 图4 覆盖优化迭代对比Figure 4 Iterative comparison of coverage optimization 图5所示为对于天线下倾角和天线发射功率不同调整步长的迭代曲线对比。分别将天线下倾角和天线发射功率的调整步长设置为1 °和5 dBm、1 °和7 dBm、1 °和10 dBm、2 °和5 dBm以及2 °和10 dBm。由图可见,当天线下倾角调整步长设置为1 °,天线发射功率调整步长调整为5 dBm时,算法拥有最快的收敛速度;当天线下倾角调整步长为2 °,天线发射功率调整步长设置为10 dBm时,收敛最慢,因此可知,仿真使用数据的覆盖率对于天线发射功率较为敏感,使用小步长动作空间的收敛速度明显优于使用大步长的。 图5 覆盖优化参数对比Figure 5 Comparison of coverage optimization parameters 需要指出的是,覆盖问题可能由多个因素造成,针对天线下倾角和发射功率的覆盖优化并不能解决所有的覆盖问题,在工程中,如果始终未能达到理想的覆盖效果,应该考虑多种因素和对应的解决方案。 针对移动通信网络覆盖场景,本文提出了基于Q学习的自适应网络覆盖优化算法,使用RF模型模拟网络环境,并以此作为Q学习的环境,使用基于优先级的动作决策算法进行覆盖优化,减少了对于环境假设以及数学建模的依赖。通过改进的Q学习算法,优化区域覆盖率提升达到20%,有效降低了重叠覆盖率与弱覆盖率,同时相较于传统的Q学习算法,将收敛速度提升至1 500次内,此外缩小天线参数调整的步长,可以将收敛速度进一步提升。相较于启发式天线参数优化算法,本文提出的算法具有经验积累和自主优化的优势,训练后的模型能够识别覆盖问题,并快速做出优化决策;与针对仿真场景提出的天线参数优化方法相比,本算法从实际的网络场景出发,使用现网数据训练模型,具有一定的工程实践基础以及运维工作指导意义。 根据本文研究内容,下一步需要将优化问题扩展为小区容量与覆盖联合优化模型,在保证覆盖率的同时合理地分配网络资源[14]。
2.2 Q学习问题映射
3 仿真结果与分析
3.1 数据说明
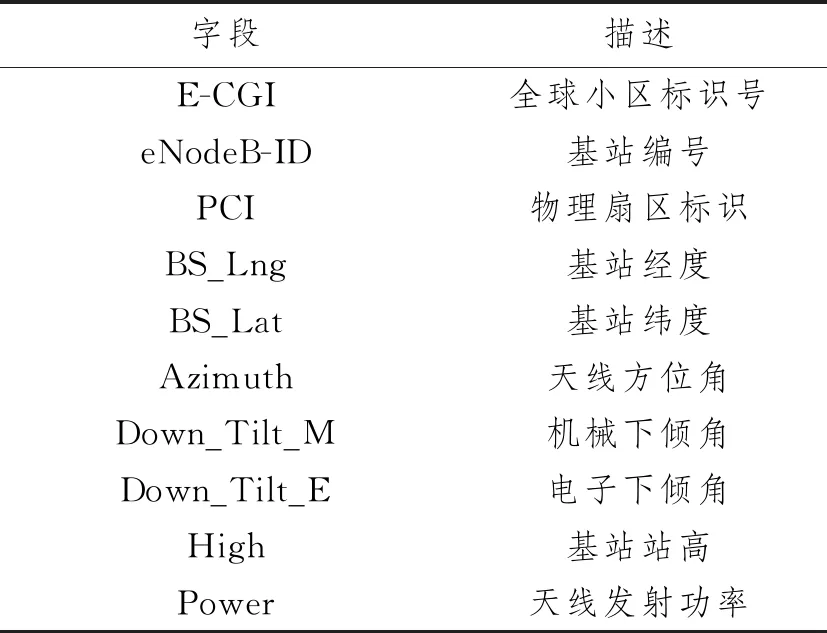
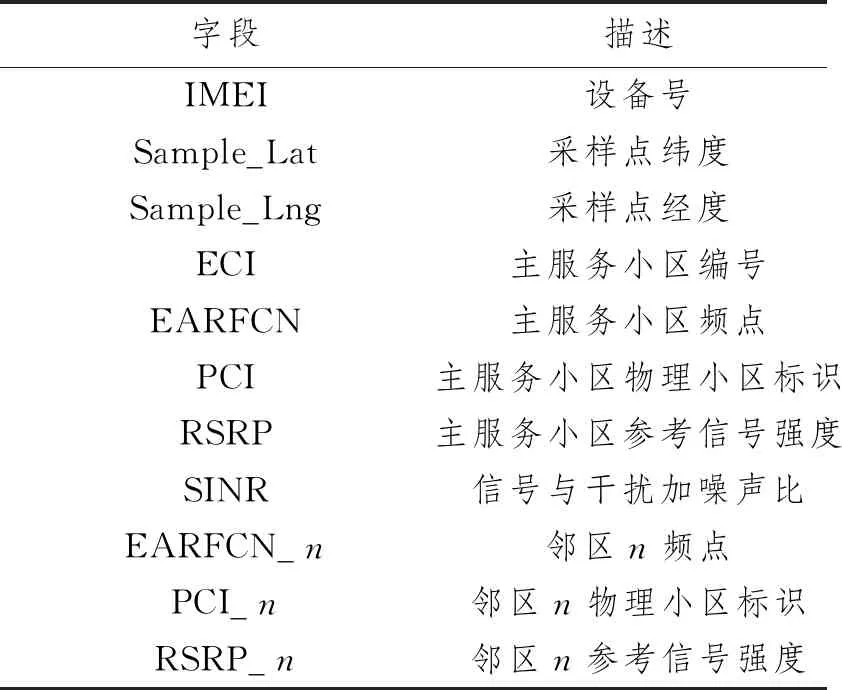
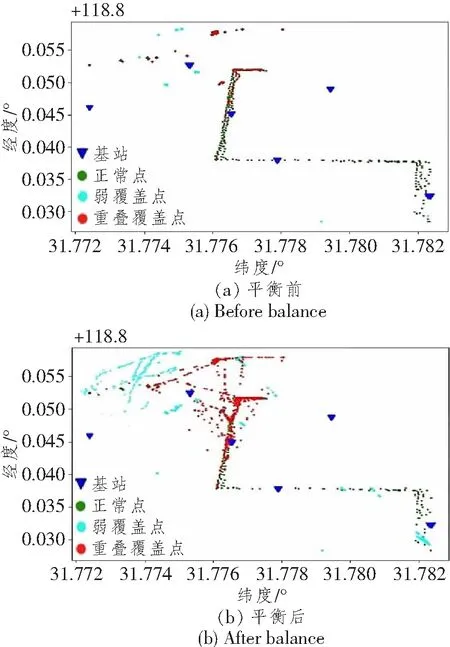
3.2 数据处理
3.3 模型验证
3.4 优化结果分析

4 结束语
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
今日农业(2021年21期)2021-11-26 05:07:00
中国交通信息化(2017年10期)2017-06-06 07:13:20
探索科学(2017年4期)2017-05-04 04:09:47
电子制作(2016年1期)2016-11-07 08:42:54
学习月刊(2016年19期)2016-07-11 01:59:46
中国交通信息化(2016年8期)2016-06-06 03:56:25
西南交通大学学报(2016年6期)2016-05-04 04:13:05
移动通信(2015年17期)2015-08-24 08:13:10
发明与创新(2015年29期)2015-02-27 10:39:43
