
基于PSPNet改进UNet的轻量级视网膜血管分割算法*
2022-10-19 02:53蒋晨皓马玉良祝真滨
传感技术学报 2022年7期
蒋晨皓马玉良祝真滨
(杭州电子科技大学自动化学院,浙江 杭州 310018)
视网膜血管是眼底图像中可以检测到的主要解剖结构,其结构和特征变化反映了白内障、糖尿病性视网膜病变(DR)、高血压等疾病的影响[1]。因此医学上一般通过检查视网膜结构和血管变化来初步了解患者的健康状况,有利于辅助医生完成对相关病症的初步诊断。提取视网膜血管的基本特征,例如直径、长度、连通性等,对于筛选、评估和诊断眼部以及人体其他部位的病变程度具有重大意义。但是由于视网膜血管存在分布随机性强、细小分叉多、直径大小不一等特点,且医学影像设备检测性能和医学分割人员的专业知识、分割水准均存在局限性和不稳定性,人工分割血管的难度较大、效率较低并且受到软硬件多方面的限制。在计算机技术的不断进步和发展、临床需求的日益强烈等因素的推动下,视网膜血管自动分割技术应运而生。
目前视网膜血管分割的常用算法可分为有监督学习算法和无监督学习算法两大类。有监督学习算法可细分为基于支持向量机和部分集成算法的机器学习一般算法、基于神经网络的深度学习算法等。该类方法通常需要大量人工分割、标注的视网膜血管图像作为数据集,而且一般需要较长的模型训练时间,但其准确率较高,且在模型微调后可用于不同数据集,可移植性和泛化能力较强。而包括聚类方法、匹配滤波方法、数学形态学方法、血管跟踪方法等无监督学习算法无需人工标注的图像数据集,但是需要人为对分类后的不同簇进行类别标记工作,且存在分类偏好性较强、模型精度较不稳定等问题。经过几年来不同研究者们的推动,两类方法的分类性能、实用性均有所突破和创新。
在无监督学习算法中,文献[1]提出了一种以Fréchet概率密度函数为核的新型匹配滤波器方法,较好地实现了血管轮廓与Fréchet模板的匹配。文献[2]提出了一种结合匹配滤波和模糊C均值聚类的视网膜血管分割方法,该算法采用对比度受限的自适应直方图均衡化方法增强图像的对比度,再使用Gabor和Frangi滤波去除图像的噪声和背景,然后通过模糊C均值提取初始血管网络,运用综合水平集方法进一步细化分割。该算法取得了较好的敏感性和特异性,但是遗漏了部分细小血管。文献[3]提出了一种多尺度2D Gabor小波的自动分割方法,该算法采用不同尺度的2D Gabor小波对视网膜图像进行变换,通过形态学重构准确提取血管骨架,应用区域生长法精确分割细小血管,最后用后处理结合粗细血管,减少细小血管的信息丢失和背景像素点的误分割。该算法实现了较为平滑的血管分割效果,但是对于低对比度下的血管分割效果较差,分割灵敏度较低,同时和文献[2]一样,对于细小血管的分割遗漏较多。文献[4]提出了一种基于灰度-梯度共生矩阵的视网膜血管分割方法,该算法使用二维匹配滤波预处理以增强血管的灰度,结合图像的灰度和梯度信息使用了灰度-梯度共生矩阵的最大熵阈值化方法。该算法对于管径急剧变化及血管高度扭曲的视网膜血管图像分割效果较差,血管分叉部位的分割时常出现断点。
而对于有监督学习算法,文献[5]提出了一种新颖的图搜索元启发式分割方法。该方法先将复杂的血管树分为包含动脉和静脉的多个子树,并通过随机森林分类器训练得出结果。但是因为血管网络图形表示以及分类器性能的有限性,该算法破坏了部分血管的连通性和完整性。文献[6]将迁移学习和传统UNet相结合,使用ImageNet数据集预训练好的权重对网络进行初始化,并且通过BCE和Jaccard两种损失函数来联合优化模型,该模型对于细小血管分割的灵敏度较好,但是整体的分割准确率一般。文献[7]提出的算法将传统UNet双卷积结构输出的不同尺寸特征图进行稠密连接,取代普通的跳跃连接,贯穿上下采样的整个过程,较好地提升了整体血管分割的准确性、减短了训练耗时,但是模型对于细小血管病灶的灵敏度度较为欠缺,对于光照不均匀血管图像的适应能力较差。文献[8]在UNet基础上提出了CENet,该算法将空洞卷积和Inception-ResNet-V2相融合提出了DAC Block,通过增大感受野获取更多高层的语义信息,同时仿照PSPNet构建了RMP Block,结合不同尺度的空间信息,一定程度上缓解了UNet因为连续的卷积和池化操作导致的血管细节信息丢失问题。文献[9]在预处理上结合邻域知识引入光长补偿,对血管图像进行光照校正。将血管分割与动静脉分割结合作为multi-task,结合空域激活机制设计了multi-task output block以替代UNet的原始输出模块,利用相对简单的血管分割结果提升动脉分割的结果,有利于提升毛细血管的检测性能。文献[10]提出了一种结合了UNet、Bi-directional ConvLSTM、稠密连接机制的医学图像分割算法,该算法使用双向BConvLSTM取代了U-Net的跳跃连接中简单的拼接操作,并且在解码部分的最后一层卷积使用稠密连接的卷积层,实现了血管特征的传播和复用,该算法对于血管基本结构的分割性能较好,模型泛化能力较强,但是网络结构比较复杂,网络参数量较多。文献[11]提出了一种基于注意力机制的全注意力网络,通过双向注意力模块获取水平和垂直方向上密集的血管上下文信息。文献[12]提出了一种全局上下文的医学图像分割方法,该算法由编码和解码模块组成,解码模块由全局上下文注意GCA模块和挤压激励金字塔池SEPP模块组成,GCA模块将低级特征和高层特征连接起来以产生更具代表性的功能,SEPP模块则增加了感受野的大小和多尺度特征融合的能力,并且设计了加权交叉熵损失来更好地平衡分割区域和未分割区域,达到更优的分割性能。文献[13]提出了一种基于多特征和多分类器的视网膜分割算法,该算法结合对比度增强强度、B-COSFIRE滤波器响应、线条强度以及融合的灰色投票结果和2D-Gabor滤波器结果来构建特征向量,再将决策树和AdaBoost算法分类器结果进行融合。该算法结合了血管的多元特征,取得了较好的血管分类准确度和灵敏度。文献[14]将视网膜血管分割工作分为厚血管分割、薄血管分割和血管融合三个部分,该算法对厚血管和薄血管进行单独的分割而获得更好的判别特征,并在血管融合阶段通过进一步识别非血管像素并改善总体血管厚度一致性来改善结果,分割模型由用于粗血管分割的ThickSegmenter、用于细血管分割的ThinSegmenter和用于血管融合的FusionSegmenter三部分组成,但是由于血管细节信息的丢失过多,算法效果较为一般。文献[15]提出一种结合短连接和密集块的深度卷积对抗网络算法,该算法仍然采用U型编码译码结构,并在卷积块之间增加了短连接块,防止深度卷积网络造成梯度色散。鉴别器全部由卷积块组成,同文献[7,10]一样在卷积网络的中间添加密集连接结构,加强特征的传播,提高网络的鉴别能力。算法稠密连接的紧密程度不如文献[8],但是分割结果的准确率和灵敏度却优于文献[7]。
为了解决上述文献中对于血管分割无法兼顾准确率和灵敏度以及网络参数较多的问题,提出了一种基于PSPNet改进UNet的轻量级视网膜血管分割算法,该算法由金字塔解析结构、UNet编码解码结构、稠密连接、DropBlock正则化方法和空间注意力机制等部分组成,用来实现视网膜血管的高效准确分割。相较于传统的监督学习和无监督学习方法,本文提出的算法在分割综合性能、泛化能力以及训练效率上都有明显的提升。
1 研究方法
1.1 预处理
本文将数据集中的图像都转换为576×576像素的大小,并选用了原图像的绿色通道作为预处理的输入图像,由图1可知,相比于原始RGB三通道、红色通道以及蓝色通道而言,绿色通道呈现出的血管与图像背景的对比度更好,血管结构更清晰。
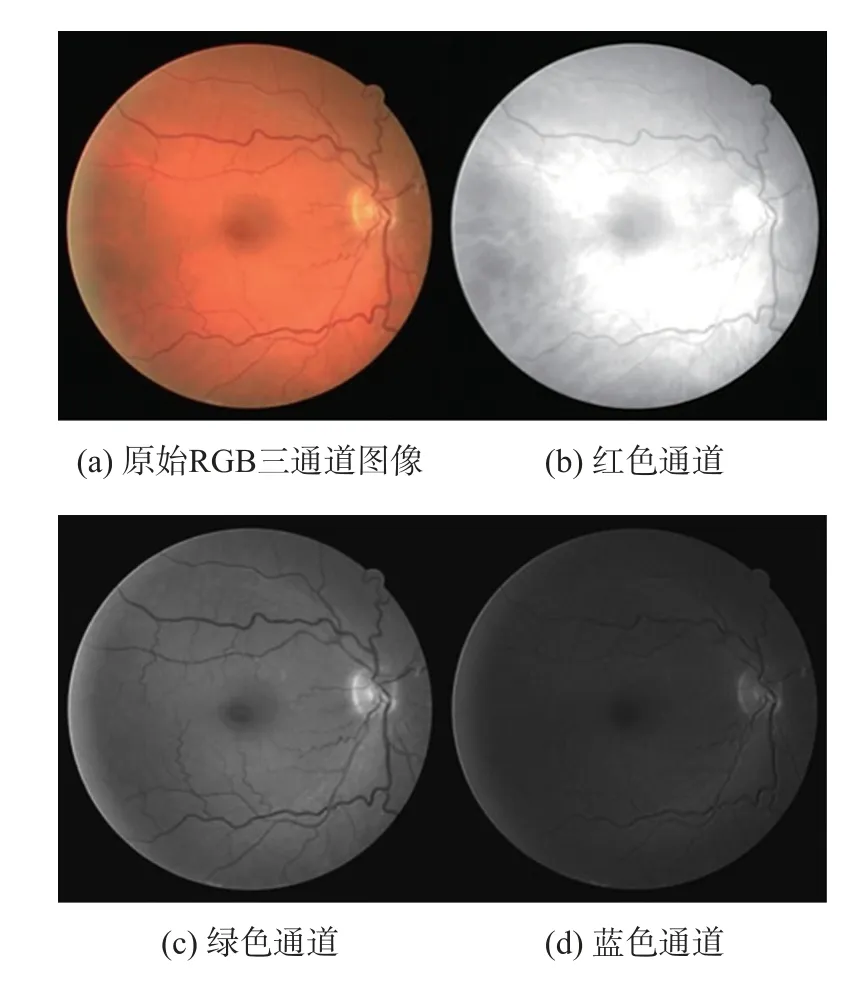
图1 彩色眼底图像和不同通道
为了进一步提升图像的对比度,改善图像整体较暗的问题,使得血管特征更便于模型进行分割预测,使用了对比度受限的自适应直方图均衡化方法(Contrast Limited Adaptive Histogram Equalization,CLAHE)增强血管部分与无血管部分的对比度,将血管的基本骨架和细小分叉更清晰地呈现出来。为了解决训练集样本过少不利于提高模型通用性的问题,分别使用了随机角度旋转、色彩抖动、添加Drop-Block噪声、随机翻转方法对原始训练集进行数据扩增。针对DRIVE数据集,先将训练集复制5次,每组都包含训练集中全部20张图像,第1组只进行随机角度旋转,第2组只进行色彩抖动,第3组只添加DropBlock噪声,第4组只进行随机翻转,第5组则对每张图像集中使用上述四种方法进行数据扩增。针对STARE数据集,则先将训练集复制10次,每两组为一个单位,重复上述操作。
其中,添加DropBlock噪声的方法运用了卷积神经网络中DropBlock正则化的思想。本文算法先随机生成图像的一个有效坐标,将以该点为中心的N×N个像素点的值都转换为255。该方法根据卷积的特点,通过遮挡部分可使用卷积获得的语义信息来激励网络自主学习,提高网络对于细小血管结构的分割能力和整体泛化能力。最后,经数据扩增处理后的部分图像如图2所示,总共生成100张除了原始图像以外的增强图像。
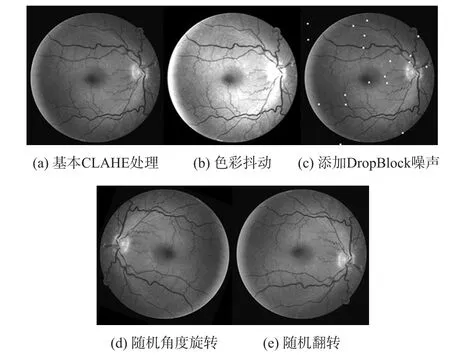
图2 CLAHE和数据扩增后
本文将数据扩增处理后的100张图像作为训练集,未经数据扩增处理(仅仅提取绿色通道、使用直方图均衡化)的原始图像作为验证集。为了提取到更精细的血管特征,本文将扩增后数据集的每张图像分为81个不重复的分辨率为64×64像素的patch,把小尺寸的patch作为网络的初始输入进行训练,网络输出相应也为64×64像素大小,最后通过patch的拼接以及图像阈值处理获得最终的二值分割结果。
1.2 密集连接卷积模块
本文用图3所示的密集连接的三卷积层代替了传统UNet编解码器双卷积层结构。而在DenseNet中,每一层隐藏层的输入采用前面所有层输出的集合,增强前层与后层之间的联系,这样网络中如果有N个隐藏层就存在N×(N+1)/2个连接,有利于缓解梯度消失。DenseNet能综合利用靠近输入层中具有低复杂度的特征,使得网络更容易得到一个具有更好泛化性能的决策函数。本文借鉴了DenseNet的稠密连接思路,在其基础结构之上,加入了DropBlock层和批归一化层(BN),并且相对应地调整了密集连接的具体方式。如图4所示,DropBlock是Dropout的结构化形式,防止卷积神经网络过拟合效果更佳,特别是针对于语义分割问题。DropBlock和Dropout的主要区别在于,DropBlock从一层的feature map中丢弃卷积状的连续区域,一定程度上等同于舍弃了部分语义特征,而Dropout丢弃的是随机且相对独立的特征单元。使用DropBlock的模型更容易适应不同的语义分割场景,鲁棒性和灵敏度更强,比如应对视网膜血管分割中经常出现的图像某块区域亮度不足、清晰度较差以及血管细小分叉难以捕捉等情形时,模型更容易学习到较完整的血管结构以及细小血管的分叉特征。BN层用于保持输入输出数据分布的稳定性,减少对于初始输入数据的依赖性。本文密集连接卷积块包括了三个子卷积结构,每一个都由3×3-Conv、DropBlock、BN、ReLU顺序组成;将每个子结构BN层的输出加入到接下来N个子结构的ReLU层的输入集合中,这一做法有利于减缓由于数据的分布逐渐向非线性函数的两端靠拢带来的梯度消失问题,而不同BN层输出的集合结合了多层次的归一化后的特征,较好地提升了梯度下降的速度,使得模型可以用较少的迭代次数寻找到更接近最优解的局部最优解;再将经过DropBlock随机丢弃语义特征后的不同数据仿射变换至一个分布稳定的特征空间中,有利于增强梯度下降的稳定性、加快收敛速度;除此之外,本文还用1×1-Conv对输入集合进行特征映射,不仅降低特征维度和网络参数量,还能够实现跨通道的信息交互,结合各个通道的特征信息;最后再输入到ReLU层。
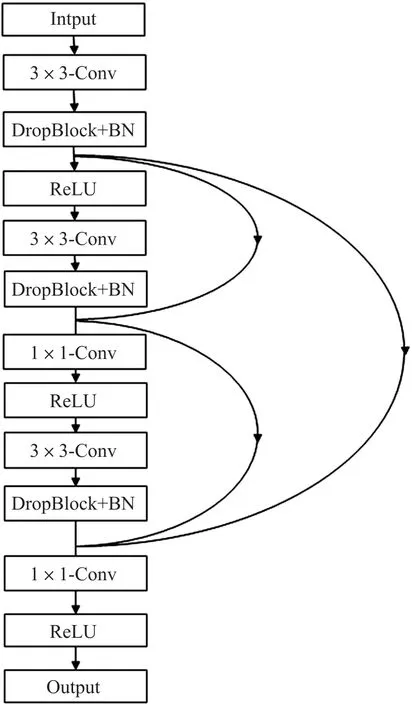
图3 密集连接卷积结构

图4 Dropout(左)和DropBlock(右)
1.3 PSP金字塔池化模块
众所周知,全局平均池化(AvgPool)作为全局上下文先验是一种很好的基线模型,被成功地应用于语义分割[16]。原始的PSPNet先使用预训练的Res-Net101和空洞卷积来提取特征图,再将特征图经过PSP Module融合局部和全局的上下文信息,最后通过一个卷积层获得输出。而本文以UNet为基础框架应用PSP Module,并根据视网膜图像的尺寸特征,改进了PSPNet的结构并提出了如图5所示的金字塔池化模块(以16×64×64的输入为例)。首先利用全局平均池化,将输入特征映射到1×1、2×2、4×4、8×8四个不同的金字塔尺度;再利用1×1-Conv进行特征提取,对每个金字塔尺度特征的内部进行跨通道的信息传递;然后运用双线性插值将低维特征图上采样到与原始输入特征图相同大小,以便于多层次特征的通道连接。最后将不同层次的特征以及原始的输入特征连接为最终的金字塔池全局特征,并通过1×1-Conv将金字塔全局特征映射为原始输入特征的大小。该结构通过全局平均池化,构造了四种尺度的感受野以检测不同大小的血管特征,充分结合了上下文的有效信息进行合理分割,尽可能减少了血管分割的基础性错误,保证了视网膜血管基本骨架的分割完整性,明确了部分细小血管及其分叉的区域信息以及大致的分割方向。同时,本文将该结构应用在密集卷积模块后,对每次提取后的特征图都进行局部和全局信息的整理和融合。
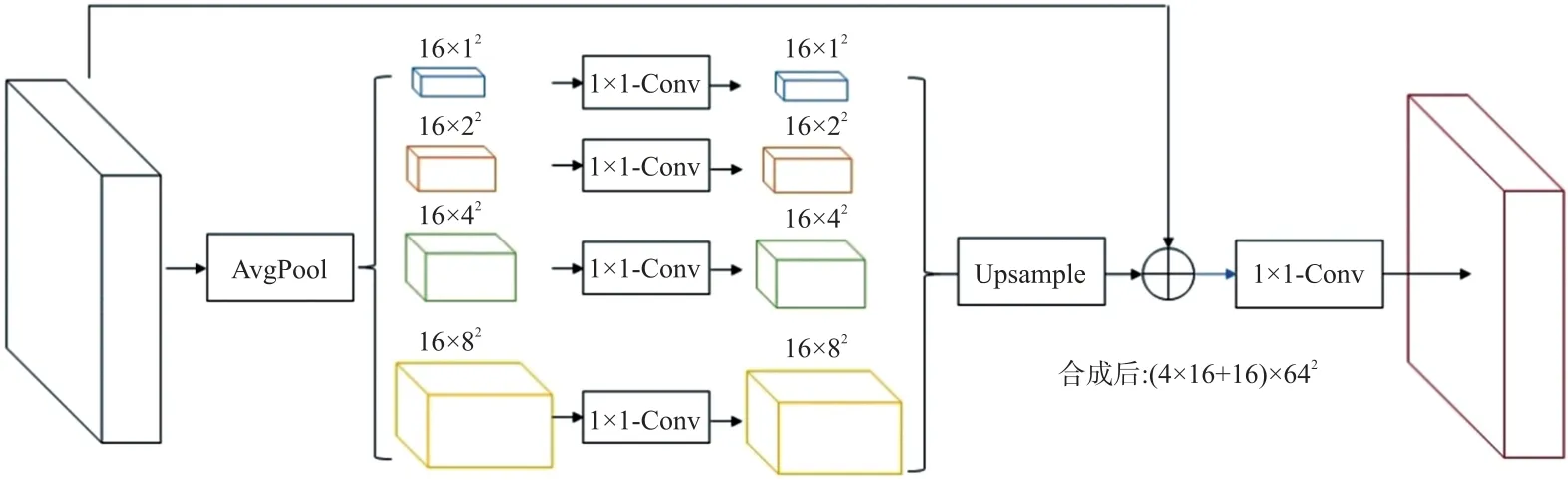
图5 金字塔池化结构
1.4 空间注意力跳跃连接
空间注意力机制作为卷积神经网络注意模块的重要部分,可用于分类、分割和检测。空间注意力机制利用特征之间的空间关系来生成空间注意力图,赋予每个特征单元以不同的权值来表示该区域血管特征的密集性和结构性。为了计算空间注意力,如图6所示,该结构先对于输入特征:F∈RH×W×C的通道轴分别进行平均池化(AvgPool)和最大池化(MaxPool)操作,再 将 输 出 的 两 个 特 征 图(FMp∈RH×W×1、FAp∈RH×W×1)进行连接以获得有效的特征描述的空间信息,然后用3×3-Conv对于级联特征描述图进行特征提取,最后通过Sigmoid激活函数生成空间注意力分布图MS(F)∈RH×W×1,并与输入特征图相乘获得新的特征输出FS∈RH×W×C。计算公式如下所示:

图6 空间注意力机制

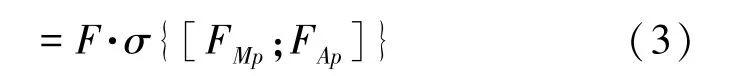
式中:σ符号代表了包括拼接用3×3卷积进行特征提取,使用Sigmoid函数等将FMP和FAP转换成空间注意力图的一系列操作。
空间注意力机制将原始特征映射到另一个特征空间,保留并强化了原始特征的关键信息。由于该结构具有旋转、缩放变换的功能,所以同一血管特征即使经过不同位置变换,模型提取出的血管结构也相同。结合空间注意力分布图,模型对于关键信息的关注度相应提高。本文主要将空间注意力机制和UNet跳跃连接相结合,将尺寸相同但包含语义信息不同的特征先进行通道融合;再将融合后的输出通过空间注意力机制进行关键性分析,收集更多通道的有效描述信息;本文利用感受野较小的3×3-Conv连续检索细小血管的关键信息,提升细小血管的分割关注度,从而提高网络对于血管细节特征的分割灵敏性。
1.5 PDA-UNet基本网络结构
本文提出的PDA-UNet的基本网络结构如图7所示,PDA-UNet由编码器和解码器两部分组成。编码器遵循典型的卷积结构,它由一个密集连接卷积结构和一个PSP金字塔池化结构组成,再通过2×2的最大池化操作进行下采样,并且将特征通道加倍,各部分特征通道数分别为16、32、64、128。解码器将特征先通过2×2的转置卷积进行上采样,压缩特征通道,再将压缩后的特征与编码器中通道数相同的特征进行跳跃连接,然后利用空间注意力机制进行特征映射、提取出关键信息,并通过密集连接卷积结构和金字塔池化结构提取血管特征。最后使用Sigmoid激活函数输出每个特征单元的激活值。
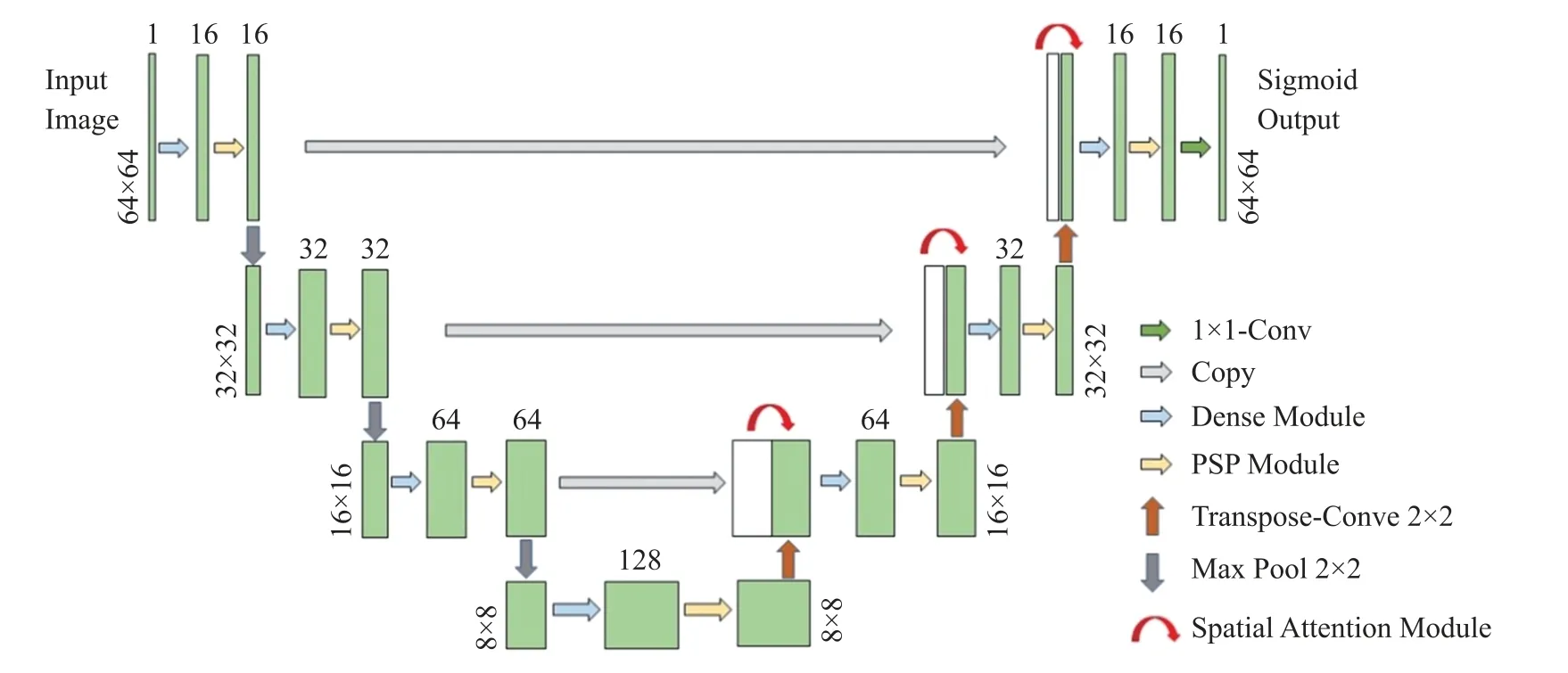
图7 PDA-UNet网络结构
2 实验
2.1 数据集
为了验证算法的有效性,本文选用了常用的公开数据集DRIVE和STARE来进行训练和测试。DRIVE数据集来自于荷兰糖尿病视网膜病变筛查计划,包括了40张彩色视网膜眼底图像,标号21~40的图像作为训练集,标号1~20的图像作为测试集,每张图像分辨率为584×565像素;STARE数据集来自于儿童心脏和健康研究,包含了20张彩色视网膜眼底图像,分辨率为605×700像素,该数据集没有官方给定的训练集和测试集,本文为了方便对比,将标号1~10的图像作为训练集,标号11~20的图像作为测试集,且使用manual1作为训练标签。以上两个数据集都含有两组由两位专业医生手动分割的视网膜血管图像标签。
2.2 实验细节
在DRIVE数据集和STARE数据集的实验过程中,本文设置的batch size为81(81个64×64像素的patch,即保持与原始图像576×576像素相同);采用的损失函数是二元交叉熵损失函数(binary cross entropy loss),使用的优化器是Adam优化器;考虑到本文训练使用的单个path大小为64×64像素的小尺寸图,对于所有DropBlock设置其保留率为0.75,丢弃块尺寸为3×3像素;对于空间注意力机制设置其卷积尺寸为3×3像素;训练迭代次数(Epoch)设置为100,使用的固定学习率为0.01,设置early stop=25。
该实验的代码实现基于深度学习框架Pytorch,所有实验都是在单块NVIDIA GeForce GTX1050(显存为4GB)显卡上运行。因为PDA-UNet是一个轻量级的网络,其输入的特征通道数较少,使得整体网络的参数都较少,所以本实验的训练时间控制在3 h以内。
2.3 评价指标
为了评价该算法的性能,本文使用了4种常见的评价指标,分别是准确度(ACC),灵敏度(SE),特异性(SP),F1值(F1-score),其计算公式如表1所示:
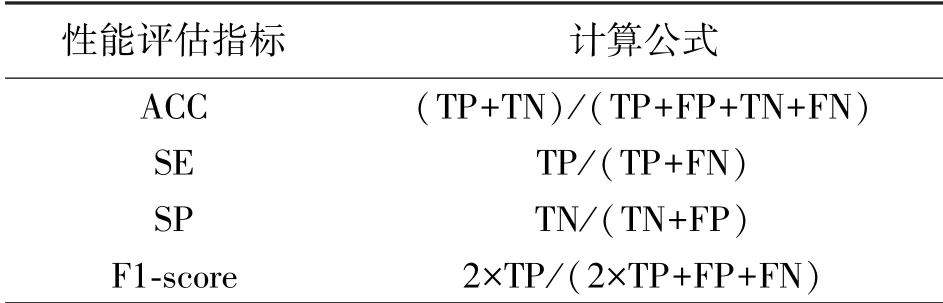
表1 评价指标
其中TP(真阳性)表示分割正确的血管点,TN(真阴性)表示分割正确的背景点,FP(假阳性)表示分割错误的背景点,FN(假阴性)表示分割错误的血管点。准确度(ACC)表示算法分割的精确度,衡量的是分割结果和真实标签之间的差异;灵敏度(SE)表示血管和背影的分割程度,体现的是算法对于细小血管的分割情况,更高的灵敏度意味着算法分割出了更多的细小血管;特异性(SP)表示识别背景元素的能力;F1值(F1-score)表示算法分割血管的综合性能。
2.4 实验结果及分析
为了说明本文提出的PDA-UNet的分割效果,本文在表2、表3中列举了近几年来不同文献在DRIVE、STARE数 据 集 上 的 分 割 结 果[10,17-25]。从表2中可知,在DRIVE数据集上,本文相较于传统UNet,分割结果的各项指标均有一定提升,特别是在灵敏度和F1-score上,分别提升了3.36%和1.99%;文献[17]、文献[18]方法的分割准确度以及F1-score都和本文相近,但是灵敏度差距较大,算法对于细小血管的分割情况较差;而文献[19]在分割灵敏度、特异性、F1-score上均达到本文相近水平,但是在精确度上还存在改进空间。从表3中可知,在STARE数据集上,本文算法相较于传统UNet,在灵敏度和F1-score上的提升分别达到了11.65%和4.05%;与其他文献相比,本文算法的分割结果在保证了准确度和特异性的同时,达到了较优的分割灵敏度和F1-score。本文选择DRIVE数据集测试集中标号为19_test的图像来显示分割结果,如图8所示。传统UNet基本实现了对于血管基本骨架的分割,但是由于传统UNet连续卷积和池化操作导致了特征丢失,使其在细小血管分叉和连接处的分割效果与本文分割结果相形见绌。文献[19]、文献[24]与本文的分割效果相近,但是文献[19]对于细小血管的分割存在部分遗漏的问题,文献[24]对于血管分叉的敏感性上与本文相比仍显不足。
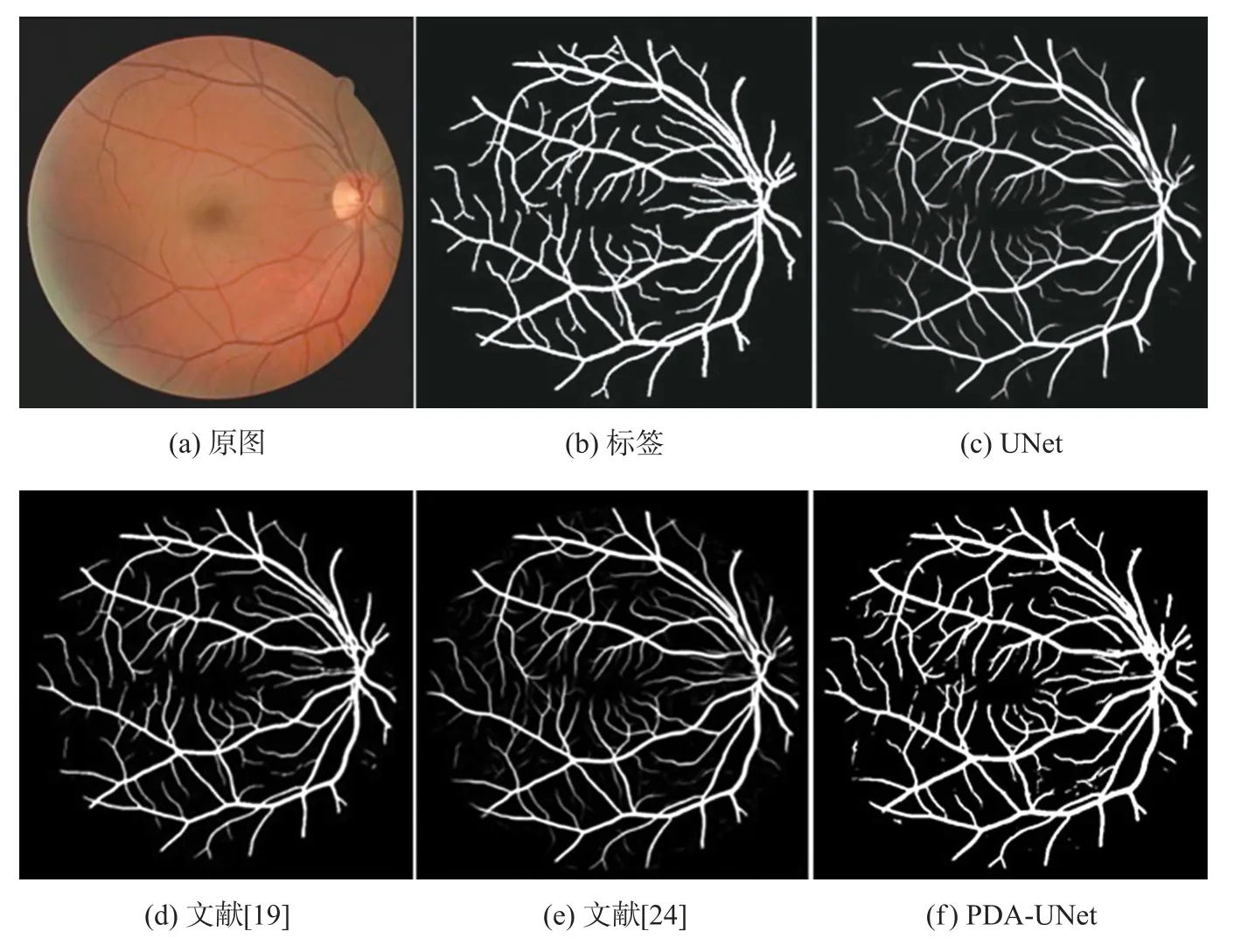
图8 DRIVE数据集上不同方法的比较
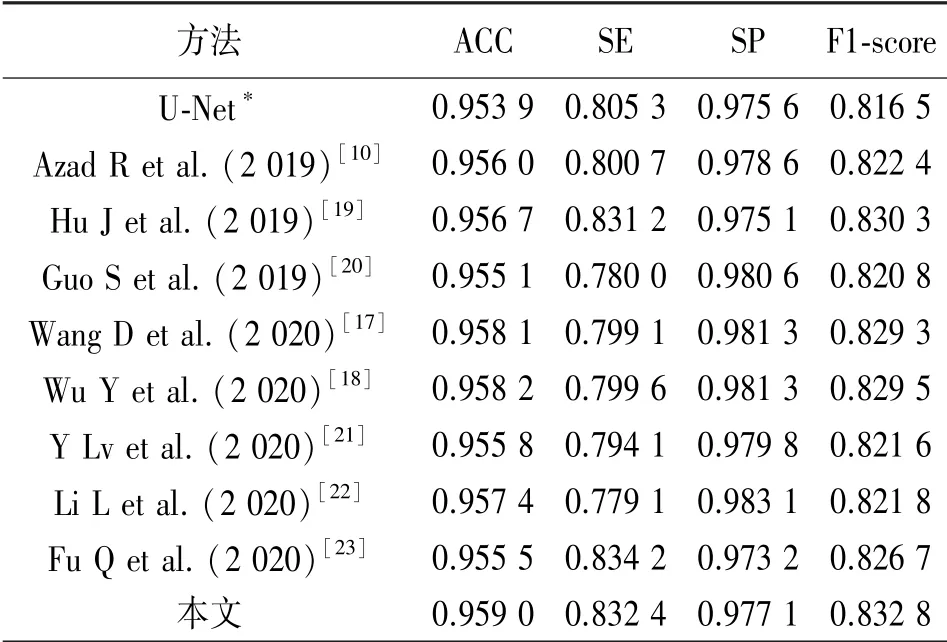
表2 DRIVE数据集分割结果比较
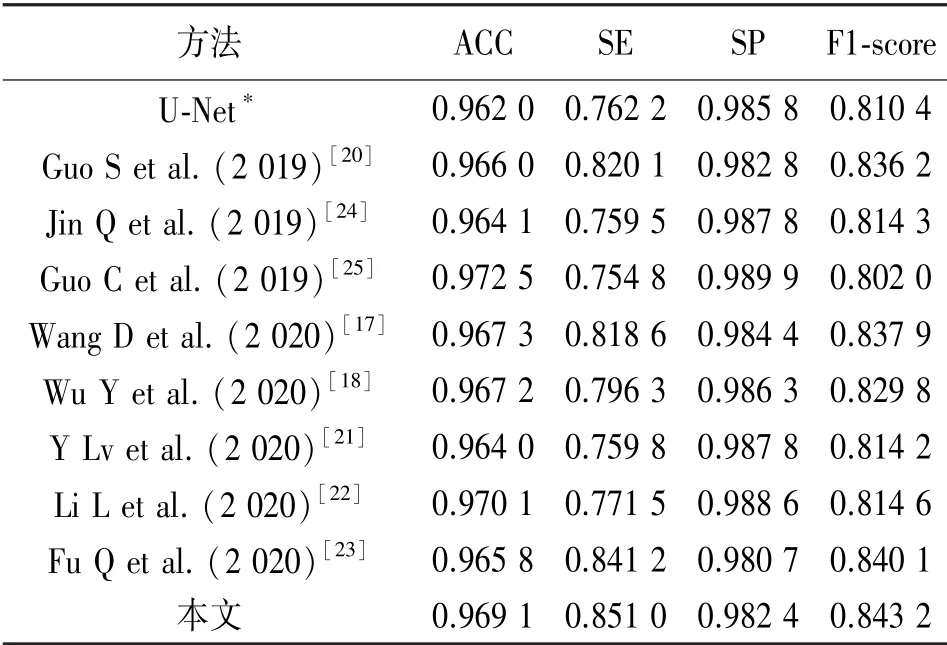
表3 STARE数据集分割结果比较
如图9所示,本文选择了STARE数据集中标号为12的图像的分割结果进行对比,传统UNet忽略了部分粗血管的基本结构,没有保证视网膜血管的完整性,且细节存在较多的漏分、误分问题;文献[20]和文献[24]虽然保证了基本的血管脉络,但是对部分粗血管分叉为多个细小血管的情况分割结果不清晰,不能还原血管的真实长度和连接情况,与本文的分割效果相比仍存在一定差距。相比于现有的分割方法,本文所提出的PDA-UNet既完好地保留了粗血管的形状和连通性,又扩展了网络对于细小血管分叉的敏感性和一定的分割精准性,在两个公开数据集上均有优秀的分割表现。
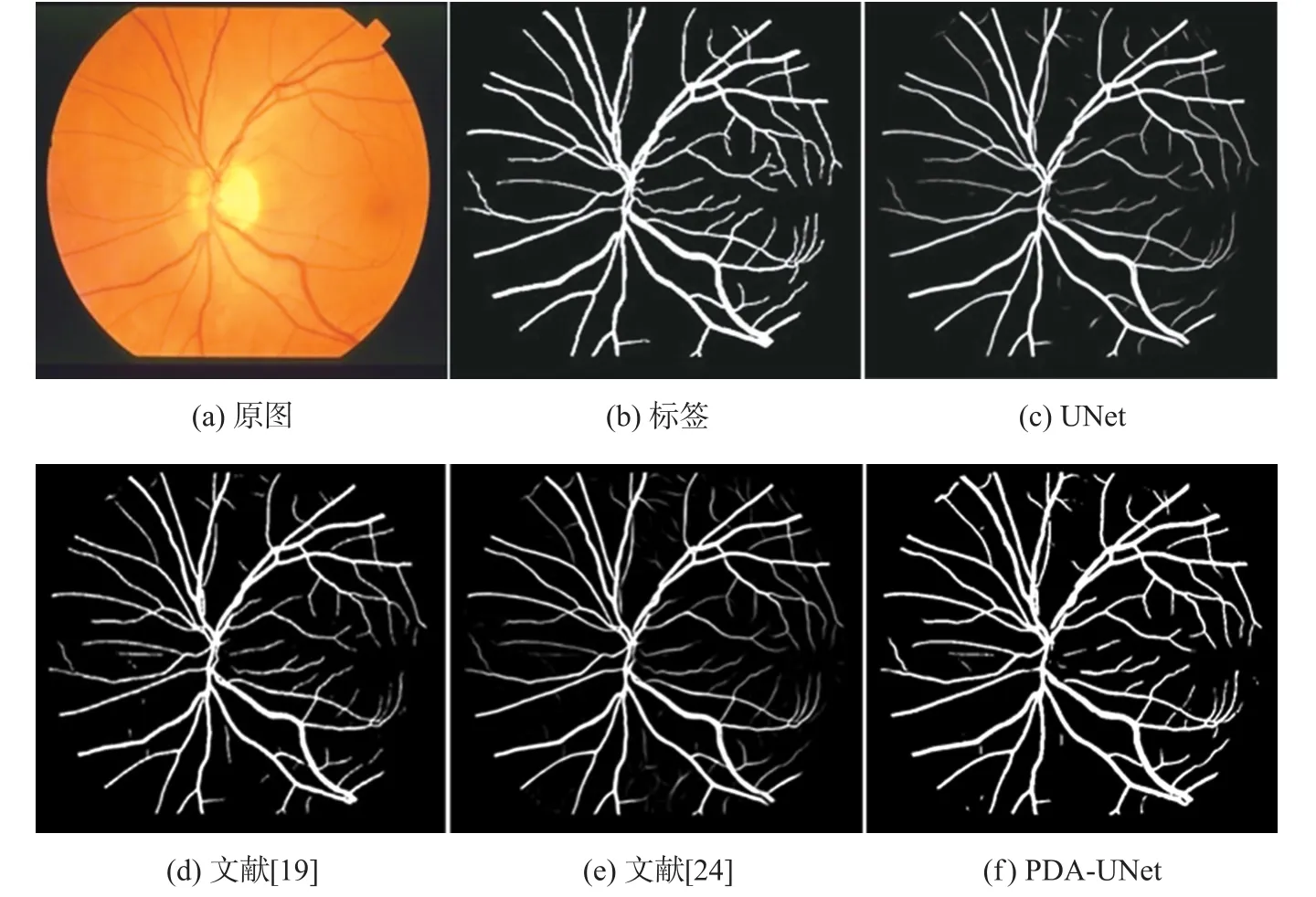
图9 STARE数据集上不同方法的比较
4 结论
本文提出了一种基于PSPNet改进UNet的轻量级视网膜分割算法——PDA-UNet。在数据预处理上,为了锻炼模型的鲁棒性,本文借助DropBlock正则化的思路,采用随机丢弃部分结构化语义信息的方式对数据进行增强。在模型构建上,为了融合多层次的语义特征、充分利用特征信息,本文用基于DenseNet的密集连接卷积块代替传统UNet的双卷积结构;然后用随机丢弃块状信息的DropBlock取代随机丢弃像素级信息的Dropout,激励网络结合多种不同的特征来学习血管的基本结构,尽可能多地预测出光照不均处血管的脉络;再将PSPNet中的金字塔解析池化结构应用至密集连接卷积块,在不同层级对特征信息进行循环利用,实现全局信息和局部信息的融合;最后将空间注意力机制和传统UNet跳跃连接联系起来,使得模型聚焦于细小血管的基本特征。实验结果表明,本文提出的PDA-UNet在两个公开数据集——DRIVE和STARE上的准确率、灵敏度、特异性、F1-score分别达到0.959 0、0.832 4、0.977 1、0.832 8和0.969 1、0.851 0、0.982 4、0.843 2,其中在灵敏度和F1-score这两项指标上本文所提方法与文献相比有较大的提升,实验证明本文算法通过对于小尺寸图像输入(64×64)中有限信息的重复利用,在实现较好分割效果的同时减少了参数量,既提高了网络的训练效率,又完整地勾勒出了血管的基本结构、优化了对于细小血管的分割性能。由于本文没有对数据集进行过多的预处理,图像基本的清晰度和亮度在一定程度上限制了模型的分割效果。同时使用DropBlock会出现部分细小血管信息缺失,导致部分血管被误分为背景。而过多跳跃连接的使用容易导致分割边界不清晰、血管过度分割。因此,如何通过更加细致的预处理提升图像的分割质量、构建自适应的DropBlock、减少跳跃连接的依赖性使用,提高模型在面对不同分割任务时的适应度将会是未来一个不错的研究方向。
猜你喜欢
读者(2022年7期)2022-10-20
农业工程学报(2022年12期)2022-09-09
现代仪器与医疗(2022年2期)2022-08-11
老友(2022年4期)2022-05-18
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
农村百事通(2021年12期)2021-01-17
飞天(2020年8期)2020-08-14
保健与生活(2019年12期)2019-07-31
