
基于时间序列分析的新能源汽车销量预测研究
2022-10-17 08:32:22汪斯凯刘吉华
统计与管理 2022年7期
汪斯凯 刘吉华
(湖北大学商学院,湖北 武汉 430062)
一、引言
从新型冠状病毒爆发的2019年开始,疫情在全球范围内不断反复,对消费者的购买意愿产生了严重影响。以汽车行业为例,从网站 “汽车之家”的统计数据得出,2022年5月全国汽车销量为133.8万辆,相比于2021年5月的全国汽车销量同比下降21.7%,2022年1-5月全国汽车累计销量为731.3万辆,同比下降17.3%。由此可见,我国汽车行业面临着比较恶劣的市场经济形势。而新能源汽车仅占2022年5月的市场份额的19.7%,相比于传统的燃油汽车更是困难重重。所以为减轻汽车行业供应链的各个阶段的压力,做出精准的市场需求预测,更有助于供应链上游下游各厂商提前做好充足准备,合理分配好资源,按需生产,降低库存,减少库存成本,从源头上节约成本开销,提高整体收益。
而对于近几年才逐渐扩大销量,并占据了一定市场份额的新能源汽车其销售购买数据具有以下特点:消费者特征较为年轻、历史销售数据时间跨度较短、销售数据量较小等等[1]。目前年轻的消费者群体的普遍购买行为都会基于目前的大量网络信息进行考虑之后再进行决策购买,而且本国的大部分网络搜索数据研究基本上都来源于百度指数,虽然将网络搜索数据纳入研究特征是一个不错的选择,但是百度指数就目前本国市场上大部分的新能源汽车的搜索数据基本上都没有收录,所以本文仍以传统的历史销售数据进行汽车销量的预测,将纯电动的新能源汽车作为研究对象,结合LSTM(长短期循环神经网络)和时间序列分析的SARIMA进行拟合预测,探究问题如下:如何构建LSTM模型和 SARIMA模型对汽车销量进行预测?两模型对数据的拟合效果有什么差异?是否能通过改进分析方法来提高对汽车销量预测的精度和准确性?
二、文献综述
汽车销售预测研究有着很长时间的发展,众多学者都为该领域献力许多,并在理论和实际应用上取得了重大的突破。其中,经典统计学方法已经发展了很长时间,理论也非常成熟,在各种实际问题上得到了广泛的应用。然而,由于数据采集成本高、样本数量有限以及传统预测方法本身存在一些缺陷等原因,使得其适用范围受到限制。因此,如何提高汽车销量预测模型的准确性成为一个重要研究课题。
近几年来,随着机器学习、神经网络等数据挖掘技术的逐渐兴起,越来越多的学者也开始将这些技术应用到汽车销量预测中[2]。如:谢亚南提出了基于结构关系识别的汽车销量预测方法[3];丁锐等人提出的基于SARIMA和LSTM组合预测模型[4];陈科秀等人提出的基于ARIMA的新能源汽车销量预测模型[5];刘吉华等人基于卷积神经网络构建了汽车销量预测模型[6];崔东佳等人将网络搜索数据正式的带入汽车销量预测[7]等。
在汽车销量的预测问题中,大部分学者都将时间跨度较大、市场份额较高的燃油汽车作为研究对象,对比于燃油汽车,新能源汽车的销量预测有着极大的困难:
第一、运用大数据、神经网络等一系列技术手段进行销量等一系列生产经营活动的预测需要大量的数据支撑,而新能源汽车作为近几年发展起来的行业,并没有大量的数据能够很好的进行模型的拟合和训练;第二、新能源汽车作为面向未来的绿色环保产业,需要设计高科技等一系列元素作为看点吸引消费者,这种类型的产品基本都具有生命周期段、迭代快速等特点,导致新能源汽车的历史数据并不能很长;第三、新能源产业作为国家重点关注对象,政府也出台了很多有关新能源汽车的政策,对汽车的销量也有比较大的影响;第四、目前全球疫情不断反复,也导致消费者的购买欲望明显降低,对销量的预测有重大的影响。
本文在神经网络的有关知识的基础上,提出了针对纯电新能源汽车的基于LSTM的汽车销量预测模型,通过与SARIMA的预测模型的对比,试图找出高精度的新能源汽车的预测模型。
三、研究模型
(一)SARIMA模型
SARIMA (Seasonal Autoregressive Integrated Moving Average)是在ARIMA模型的基础上,进行了改进。现实生活中,经济类数据常常存在周期性,需要加入季节性调整项,消除原始数据的周期,而汽车历史销售数据就具有很强的季节性,所以用该模型非常合适。
设Xt={x1,…,xt,…,xn}为时间序列数据,xt为t时刻的观测值,记B为延迟算子,表示如下:

SARIMA模型和其他的时间序列模型一样,其的建立需要平稳非白噪声时间序列数据,通常先对数据进行差分,定义差分算子见 (2)。部分情况下,经过一阶差分仍然无法转换为平稳序列,则需进行多次差分,则d阶差分表示为公式 (3)。
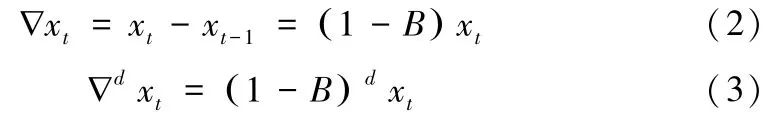
SARIMA模型由自相关部分和移动平均部分组成,经过差分后的序列可以探究其各部分的函数形式。假设φi代表自回归系数,则p阶自回归模型形式见 (4)。引入p阶自回归算子Φ(B)[8],则p阶自回归模型见 (6)。

由误差及其不同滞后期构建,主要拟合除变量之外的其他无法观测的噪声因素。移动平均模型的模型形式见 (7)。定义q阶移动平均算子 Θ (B),则q阶移动平均模型见 (9)。
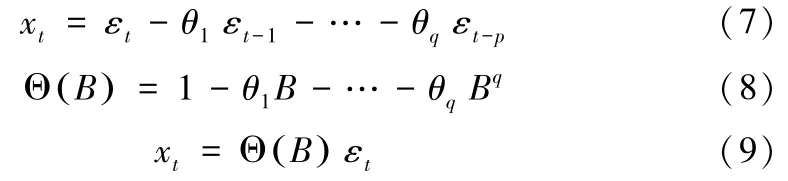
ARIMA(p,d,q)模型可以在对原序列进行d阶差分后,用自回归部分和移动平均部分表示,表达式见 (10)。

令P表示季节性自回归阶数,Q表示季节性移动平均阶数,D为季节差分阶数,记S为原始序列的季节周期,引入季节性自回归算子ΦS(Β),季节性移动平均算子ΘS(B),则SARIMA模型的形式如下 (11):
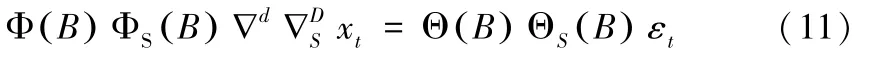
时间序列模型如SARIMA模型的求解一般包括四步:数据处理、模式识别、模型检验、预测。而其中最需要注意的模型构建方法就是数据处理和模式识别。
在构建SARIMA模型之前,需要的对数据进行检验处理,判断数据是否平稳且是否为白噪声。判断是否平稳所使用的方法一般是由画图确认和通过ADF(单位根检验)来判断滞后阶数和确认该数据是否平稳,若该数据不平稳则需进行差分,进而转换为平稳序列;而判断是否为白噪声的方法一般通过纯随机数序列检验来判断其各个滞后阶数的P值是否小于0.05,纯随机数序列检验的原假设为纯随机数序列,P值小于0.05则拒接原假设,认为该数据为非纯随机数序列。
在处理好数据之后,就需要进行模式识别,判定如何构建模型。主要有两种方法,图示法和数值法。图示法通过观察平稳序列的自相关图ACF和偏自相关图PACF定阶;数值法主要通过信息准则AIC、SBC等确定阶数[9]。也有学者将两者结合,先通过图示法大致确定阶数范围,然后循环阶数选择信息准则最小时的阶数组合[10]。
(二)LSTM模型
LSTM (Long Short Term Memory),全称长短期循环神经网络,是RNN(循环神经网络)的一种特殊模型,是由Hochreiter等人提出,被 Alex Graves进行了改良和推广[11]。LSTM之所以被广泛使用,是因为其可以解决长期的信息依赖问题,这是不能被解决的在其他神经网络模型中。
LSTM也具有类似于RNN的链状结构,但拥有着与标准RNN所不同的重复模块结构。其中并没有单一的神经网络层,取而代之的是由四个激活函数所组成的神经网络层,以一种非常特殊的方式相互作用,如图1所示。
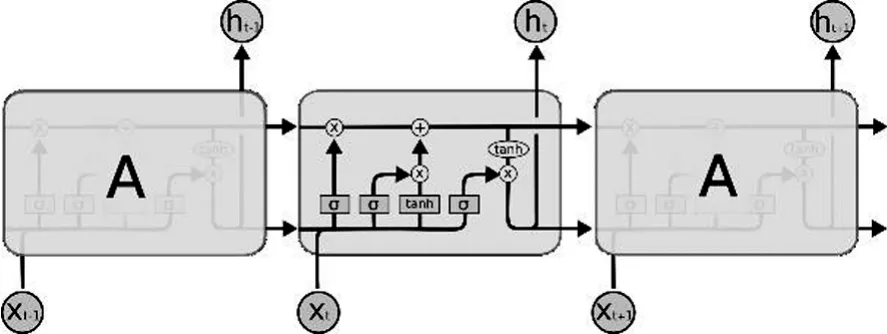
图1:LSTM中的由四个交互的神经网络层组成的重复模块
1、LSTM的核心思想
LSTM运行的关键是单元状态 (cell state)。是 LSTM可以解决长期依赖关系的重要构思。它直接沿着整个链条运行,在重复模块运行过程中,只通过线性交互进行一些微小的改变。从上一模块传进来的信息Ct-1沿整条线路进行细微的改变,输出信息Ct到下一个模块。
LSTM中能够对单元状态进行增删改的关键结构被称为“门”,是LSTM的核心概念,其可以精准的控制信息的通过量。它主要由激活函数Sigmoid的神经网络层和逐点乘法计算构成。
LSTM具有三个门,分别为 “遗忘门”、“输入门”和 “输出门”,三个门共同对单元状态进行增删改的信息量操作,用来确定输入数据的输出量和保持量。
2、遗忘门
LSTM运行过程中的第一步是通过 “遗忘门”控制什么信息从细胞状态中删除,该门会读取数据ht-1和xt,通过激活函数Sigmoid将一个零到一之间的数值传递给重复模块中的初始细胞状态Ct-1[12]。函数表达式为 (12)。
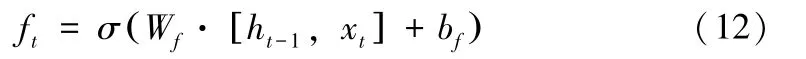
3、输入门
第二步则是通过 “输入门”控制需要对细胞状态进行更新的信息量。这一步分为两部分。首先,通过 “输入门”进行计算确定需要更新it数量的信息,函数表达式为 (13)。然后,再通过一个tanh激活函数创建一个新候选值的向量t,决定输入数据中有那些需要更新到细胞状态中,函数表达式为(14)。在下一步中,LSTM 对it和t进行向量乘法,将通过两个值的乘法计算对单元状态进行更新。
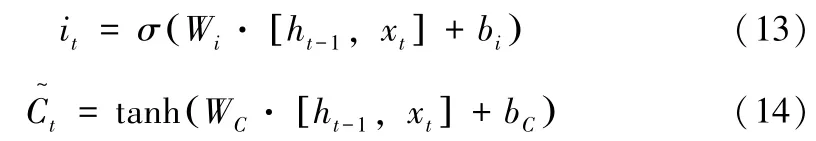
4、更新单元状态
在进行了前面的 “遗忘门”和 “输入门”操作后,LSTM就会更新旧的单元状态Ct-1,创建并形成新的单元状态Ct。过程是将旧单元状态Ct-1乘以ft,“遗忘”之前决定要删除的信息。然后加上 “输入门”需要添加到单元状态中的信息 (it*t),函数表达式为 (15),这就是新的候选值,根据 LSTM决定更新每个单元状态值的程度进行缩放。
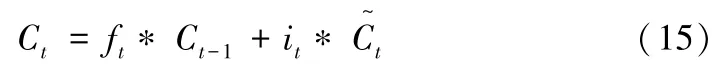
5、输出门
最后,LSTM通过 “输入门”对需要输出的信息进行控制。“输入门”对已经更新的细胞状态经过筛选的之后的到的信息。和前面几乎相似,首先,通过sigmoid激活函数,得到需要选择值为ot的单元状态,函数表达式为 (16),该值决定了需要从细胞状态中输出多少信息。然后,对细胞株那台进行tanh函数的运算,将其数据转换成-1到1之间,加速了模型的拟合速度,并将其乘以ot得到输出的信息,函数表达式为(17)。
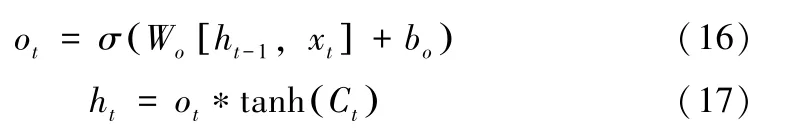
综上所述,LSTM模型能够很好的处理拥有长期依赖关系的关键核心就是,该模型有一个可以持续更新的单元状态Ct,于此同时,还有可以不断输出的ht。
四、基于LSTM模型的汽车销量模型的构建
通过对不同学者做出的文献成果的反复研究,本文综合消费者购买行为模式,提出了如图2所示的LSTM模型的汽车销量预测模型[13],共有4部分,分别为:纯电新能源车型的选取、数据的采集与预处理、LSTM模型、预测结果分析。

图2:LSTM汽车销量预测模型图
(一)车型的选取
“搜狐汽车网”作为中国汽车网站中信息最快、最全的网站被很多学者都用来作为可靠的数据来源网站。本文对其网站中的车型销量排行榜中的687个车型进行筛选,将时间长度小于三年的车型去除,从剩余的391个车型挑选出纯电动的车型有36个,例如:“吉利帝豪EV”、“长安CS15”、“宝骏E100”、“比亚迪宋EV”、“东风风神E70”、“云度π1”、“蔚来汽车es6”、“蔚来汽车es8” 等。
车型的选取对后序实验的进行和模型预测结果的准确度的影响极大,所以本文对剩余的36个车型的历史数据进行逐一对比查看,将其车型历史销量中数据空缺长度较大、数据结构不稳定和明显有误的车型排除,最后筛选出了以下6个车型:“云度π1”、“小鹏汽车 G3”、“蔚来汽车 ES8”、“比亚迪唐EV”、“广汽埃安Aion S”、“蔚来汽车ES6”。就查看其六个车型的历史销量数据特点来看,该六个车型的销量数据都比较小,每个月的销售数据基本上都没有超过1万;新浪汽车网的销量精度为 (万辆/月),导致新能源汽车销量的力度较低;并且新能源汽车的销售时间维度的长度都普遍较短。
(二)数据采集和预处理
1、汽车销售数据
数据获取与预处理是建模分析的基础,高质量的数据以及精准的预处理可以显著提高模型精度,提高预测效果。该六个车型覆盖的品牌比较多,车型比较丰富,基本上可以迎合消费者的消费习惯,且生产周期相对较长,数据量比较充足,适合作为研究对象。
本文对该六个车型的汽车各自进行销量预测,将 “搜狐汽车网”作为汽车销售的历史数据的来源,通过Python语言编写爬虫脚本,对搜狐汽车网上的这六个新能源汽车的车型和其每个月的汽车销量进行抓取。图3为该六个车型的月度汽车销量,从图中可以看出其数据具有很强的季节性,在不同的季节,销量波动比较相似;并且在2019年前后,受疫情的影响,销量波动比较显著。
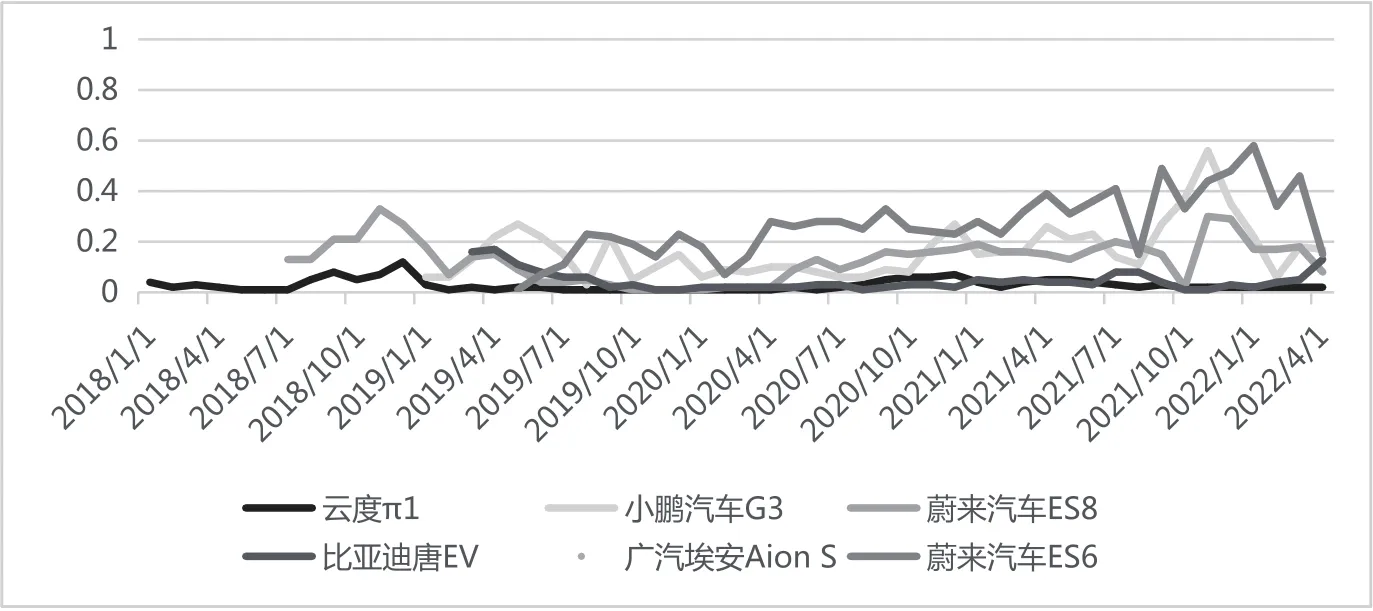
图3:六个新能源车型月度销量图 (万辆/月)
2、数据集的划分
在将数据带入到模型中进行拟合之前,需要对数据集进划分。因为LSTM模型对数据进行训练时,数据集的设定有一定的规范,考虑到消费者在进行购车消费之前的决策时间较长,本文将初始的基础序列长度设置为12月,对接下来的1月进行预测的模型对历史销售数据集进行重构。以汽车 “云度Π1”为例,其全部历史销量数据为52条一维数据,对数据集按照滑动窗口的方式进行重构之后,数据集变成了41条由13组一维数据组成的数据集。之后再对每个数据集进行拆分,将20%的数据集作为测试集和验证集,剩余的80%作为训练集。当然,在进行数据集划分之前需要对全部六个车型的历史销量数据进行空缺值填充,本文采用8邻域的K-means填充,使数据更接近于原始数据。
3、LSTM模型的构建和训练
LSTM模型在输入层方面和其他的神经网络模型一样是输入数据集组成的特征向量矩阵,通过模型内部的 “输入门”,“遗忘门”,“输出门”,通过多层的循环,对数据进行拟合,最终通过优化函数不断地调整参数,使最终模型的损失降到最低。本文对该模型采用的损失函数为平均绝对误差 (MAE),本文通过调整LSTM模型的可控参数,目的是将误差值将到最低。
(1)初始模型
目前,基于LSTM的汽车销量预测模型,众多学者也都没有比较泛用的模型,而且在模型的参数的设定上也没有统一的规定,一般都基于研究者的经验判断。由于新能源车型的历史销量数据量都比较少,过高的循环和更深的神经网络层数会导致数据更快地过拟合,不易被发现,而简单的循环层数和深度会导致训练次数过多,给机器造成比较大压力且耗时较多。所以本文就将所有车型的初始模型设定为单层的神经网络层,输入层节点为16,训练完后直接进行单值输出,编译模型的优化函数为Adam,采用MAE(平均绝对误差)作为模型的损失函数,模型进行训练是每次训练的数据量为32,总共训练120轮,用测试集进行数据的验证。
(2)模型训练
对六个车型用初始模型进行训练拟合后的预测值Αt与真实值Ft进行计算MAPE如表1。众多有关时间序列的研究对模型的评判标准为MAPE(平均绝对百分比误差),其公式如(18)。从几次训练的结果可以看见少数几个车型如 “广汽埃安Aion S”,“蔚来汽车ES6”等车型的预测结果还行,其余车型的预测值和真实值的差值比较大,所以需要对这些车型的预测模型进行参数的调整。
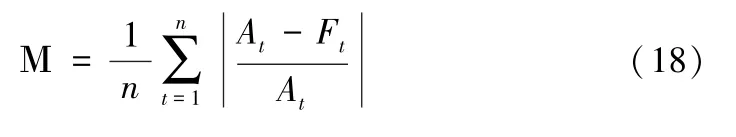

表1:各车型的初始模型预测的误差表
因为整体数据并不复杂且数据量较小,本文对于LSTM模型的主要参数如:输入层节点数、模型的层数、进行拟合时的每次训练的数据量的大小 (batch_size)和每轮训练的拟合次数 (epochs)等进行调整。通过实验的不断调整,本文发现模型的节点数、模型的层数和每轮训练的拟合次数基本呈负相关,模型的节点数和层数决定了模型的复杂程度,更复杂的模型对数据的拟合越快越准,但是对于较小、较简单的数据来说会导致拟合情况不易被察觉,相应的拟合次数需要降低,以车型蔚来汽车ES8为例,测试实验结果如表2。而每次训练数据量的大小很大程度上决定了拟合数据的平滑度,越大会使误差降低的比较平缓,但对于少量数据而言,取过大的数据量会导致训练时根本取不到响应的数据量而使拟合结果变差,对其调整的结果如图4。
表2:参数改变和拟合状态的关系测试情况表

图4:不同数据量大小的预测图像
结合以上经验,本文对所有的车型分别调整参数重新进行了训练,寻找最优的预测模型,通过实验得知,增加模型的层数对于本实验数据并不能提高模型的预测效果,所以将所有的预测模型设为单层并进行测试,各车型的训练结果如表3,对测试集用该模型进行预测所得预测值于真实值对照画散点图如图5。
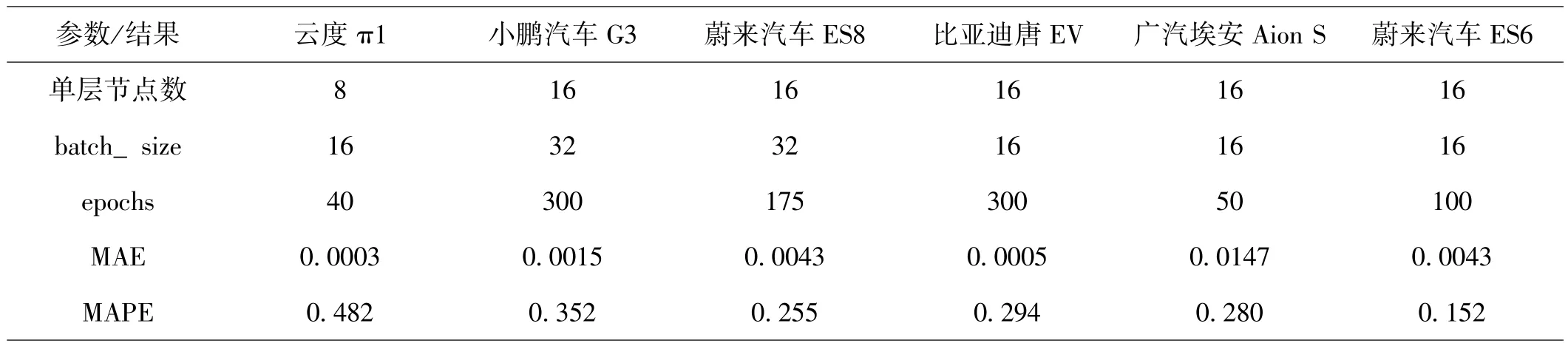
表3:六个车型的预测模型参数与预测误差表
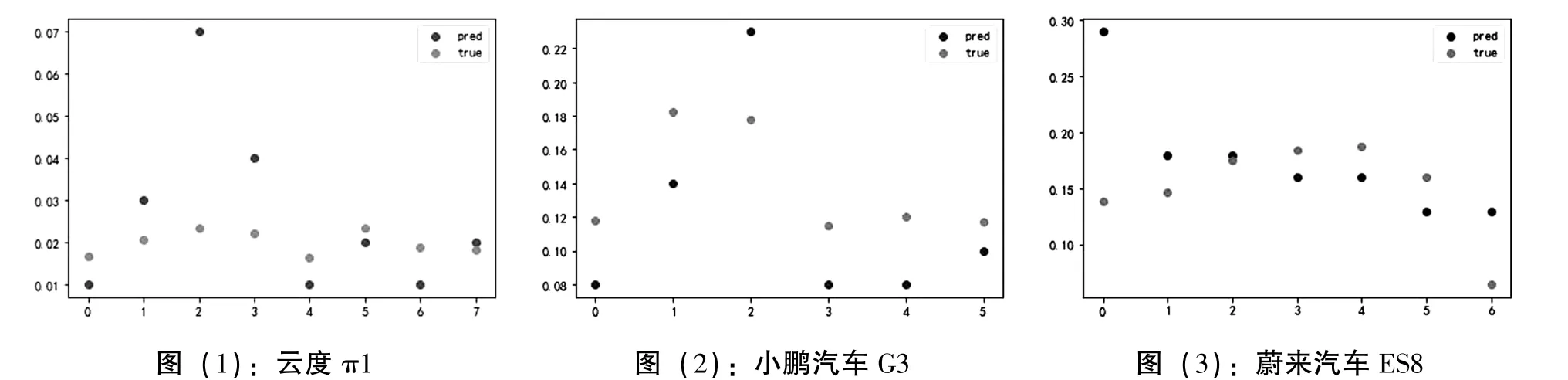

图5:六个车型的预测值与真实值的散点图对比
通过上述实验,本文通过调整参数确定了六个车型的较优预测模型,对比初始模型MAPE有比较明显的下降,大部分车型的MAPE基本都下降了10%~30%。接下来需要对数据集的划分进行优化,在众多学者的预测模型中,很大部分学者都将基础序列长度设置为短期、中长期和长期等时间段对数据进行预测,但大多都为经验所致。本文将以上述模型带入循环中,将基础序列长度设为4月到24月,测试各个车型的预测结果和设置的基础序列长度的关系,寻找最优的基础序列长度。
本文分别对4到24月进行模型的拟合,每次进行3轮,共5次,最后取均值,查看最终的MAPE的大小来判断该模型对该基础序列长度的预测程度的好坏,实验数据如表4。
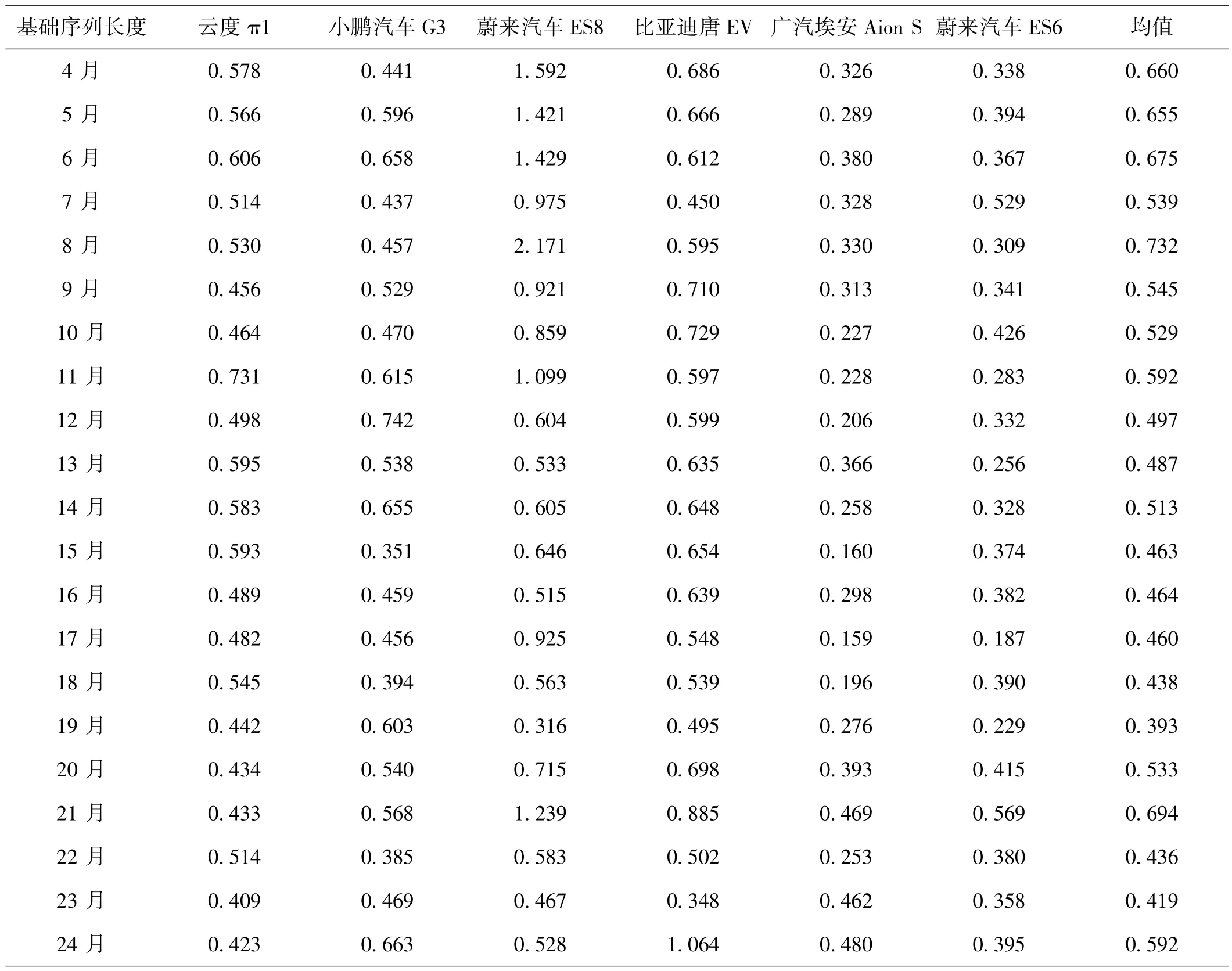
表4:六个车型在不同基础序列长度下预测下一个月的MAPE表
经过测试可以看出每个车型的历史销量数据所匹配的基础序列长度大不相同,但基本上都是基础序列长度越长,模型的预测精度越高。结合均值,当基础序列长度为19月时,上述六个车型的预测模型相对精准。
综上所述,可以得到用LSTM模型分别对六个车型的近四个月销售量进行预测的较优预测结果如表5。
表5:LSTM模型对六个车型近四个月预测结果的MAPE表
五、基于SARIMA模型的汽车销量模型的构建
对于已经处理好的六个纯电新能源车型的历史销量数据很容易建立相应的预测模型,本文构建的基于SARIMA模型的汽车销量模型的模型图如下,其主要步骤为SARIMA模型的训练和预测结果的分析,如图6所示。

图6:基于SARIMA的汽车销量预测模型
(一)数据处理
在构建SARIMA模型之前,最重要的就是检验数据是否平稳且是否为白噪声[14]。该步骤决定了处理的数据是否可以进行SARIMA模型的构建。对每个车型的销售数据进行单位根检验和纯随机数检验,将数据均转换为平稳序列且非随机数序列,各车型销量数据的检验结果如表6。为简化表格,将六种车型 “云度π1”、“小鹏汽车G3”、“蔚来汽车ES8”、“比亚迪唐EV”、“广汽埃安Aion S”、“蔚来汽车ES6”依次编为车型一到六。
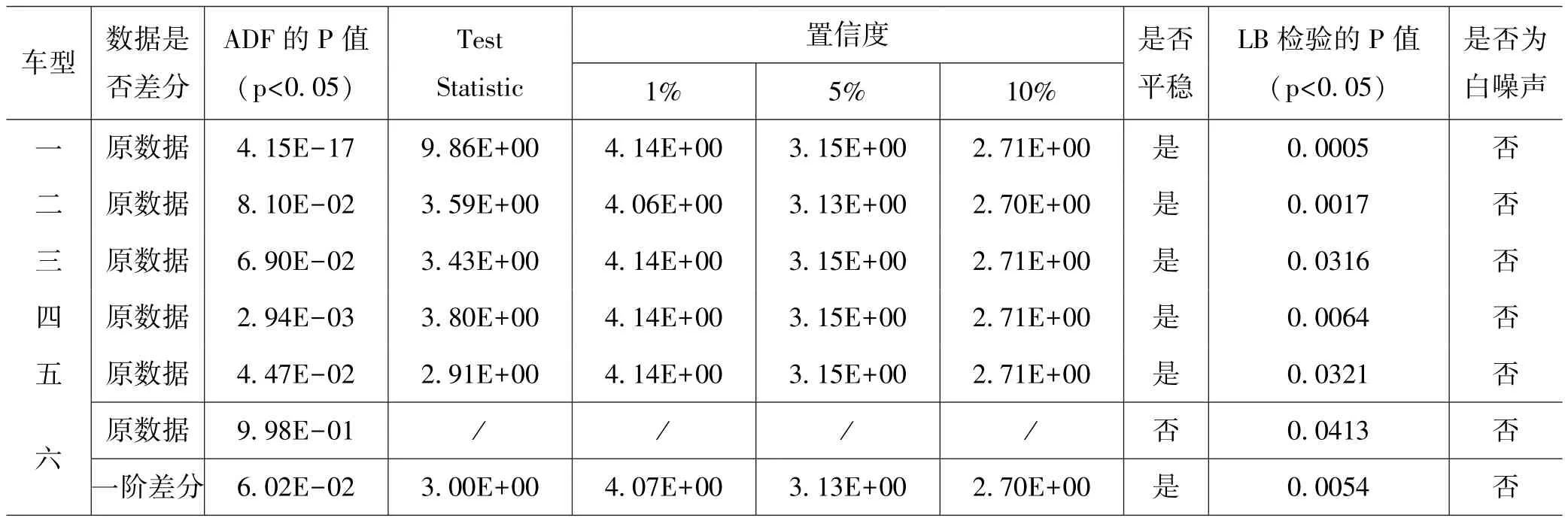
表6:不同车型销量数据的检验结果表
(二)模式识别
建模需要的平稳非随机数据处理好之后的重要步骤就是确定模型的滞后期。主要有两种方法,图示法和数值法。本文选择的方法就是直接通过数值法来确定模型的滞后期,去除主观因素对实验准确度对实验造成的影响。通过循环p、q值的大小,通过信息准则找出最优模型组合。
(三)预测
确定了每个车型的最优模型之后,本文用每个车型的最优模型对最近四个月进行预测,求出每个月的MAPE来查看模型对该月销售量的预测精度的好坏,如表7所示,可以看出模型对总体的预测水平比较好,MAPE水平都比较低除了个别车型的个别月份的拟合效果不太理想。该模型对云度π1、蔚来汽车ES8和广汽埃安Aion S这三种车型的预测精度较高,对于其他的的车型的预测对于真实值的损失比较大。
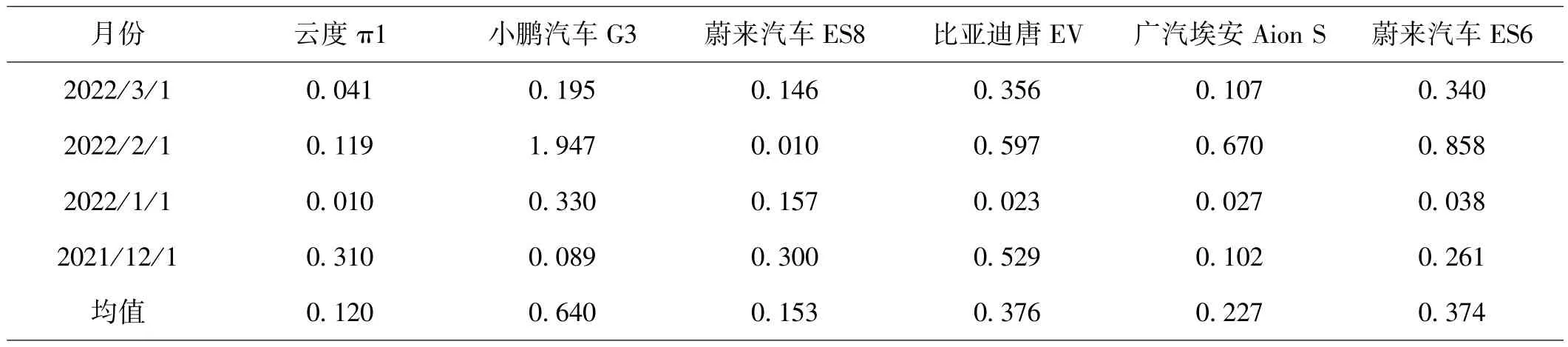
表7:SARIMA模型对六个车型近四个月预测结果的MAPE表
六、迁移学习
综合上述实验,对各个车型单独建模形成的模型都大不相同,并且不能推广到一般情况。所以,在上述实验的基础上,结合迁移学习的思想,本文提出一个基于迁移学习的LSTM模型[15],模型图如图7所示,其主要步骤为数据处理、泛化模型的构建、特化模型的训练和预测结果分析。

图7:基于迁移学习的LSTM汽车销量预测模型
(一)泛化模型的构建
迁移学习主要是指将已知的或易知的领域推广到未知的或比较困难的领域的一种重要的学习思想[15]。目前应用的场景很多,例如在机器学习领域,多数学者在实际研究过程中会把一些已知的模型推广应用于不能或者难于构建模型的问题[16]。
本文将全部车型的数据集连接进行第一次训练,通过LSTM的模型构建方法,设置初始模型,带入数据集进行参数的一系列调整和训练,最终确定了最优的LSTM模型为单层模型,基础序列长度为19月,预测下 1月,输入层 8节点,batch_size为256,epochs为150次,训练出来的最终预测结果:MAE:0.043,MAPE:0.313。预测值与真实值构成的散点图如图8。

图8:全部车型LSTM模型的预测值与真实值散点图
(二)特化模型的训练及预测
接着将上述模型保存,再分别对每个车型的销量数据进行单独训练优化,使模型可以对每个车型具有针对性。用经过再次优化后的模型对近四个月进行预测得表8。对照上述表5可知,使用迁移学习的LSTM模型和对每个车型分别建模的LSTM模型两者的精度差别不大,但是迁移学习的LSTM模型更具有广泛性,可以对其他数据量较小的新纯电新能源汽车的销售量进行预测。

表8:LSTM迁移模型对六个车型近四个月预测结果的MAPE表
七、模型的对比与应用
(一)模型的对比
本文通过对消费者的购车行为进行分析,提出了基于LSTM模型、基于SARIMA模型和基于迁移学习的LSTM的三种汽车销量预测模型,经过一系列调整与训练,将三模型最优的MAPE进行比较得表9。从表中可以看出六个车型用三种模型进行预测的精度相差不大,分车型的LSTM模型和迁移学习的LSTM模型两模型的预测精度差别也相近,除了小鹏汽车G3一种车型的MAPE差值达到60%,其余的几种车型在两种模型中的MAPE波动在10%~20%之间,属于正常范围。

表9:三种模型预测结果的MAPE表
对比上述三个模型对近四个月的预测结果的MAPE均值表10如下。在总体的汽车销量预测上SARIMA模型比LSTM模型较好,但差距并不大。对比使用迁移学习的LSTM模型进行预测的结果精度与单独对每个车型用LSTM模型进行预测的结果精度,两者的精度相近,无差别,说明在电动新能源汽车的这几个车型中,它们的数据结构具有一定的相似性,对于历史数据的波动也具有一定的相关性。但在上述实验中,三个模型对小鹏汽车G3 2022年2月的预测精度都发生了突变,考虑到其他的可能因素,本文将该车型去除重新计算均值发现三种模型的预测精度都差不多,同表10。

表10:三种模型预测误差表
所以,通过该实验为新能源汽车的销量预测提供了一个可靠的模型。在对新能源汽车销售数据进行预测,当车型的数据有所缺失或数据量较小时可以用相类似的新能源汽车进行训练建模,再对该车型进行建模预测,同样可以得到高精度的预测结果。
(二)应用
本文应用迁移学习模型对近来占据新能源汽车销售榜头的车型 “五菱宏光MINIEV”的销量进行建模预测。其历史销售数据截至2022年3月止只有21条,数据量不足两年,用常规建模方法很难对其进行精准预测。对比常规的LSTM模型和用迁移学习的LSTM模型的预测结果得表 11。发现迁移学习的LSTM模型有较好的预测精度,且MAPE值比较稳定,而用常规的LSTM模型对其进行预测,MAPE值不稳定。

表11:两种模型对五菱宏光MINIEV预测的MAPE均值对比表
八、结语
本文对纯电新能源汽车的销量预测提出了三种模型,针对每个车型的LSTM模型和SARIMA模型和基于迁移学习的LSTM模型。前两个模型对于不同的车型,两模型预测结果的好坏不一致,不能确定哪个模型更优,且两模型都过特殊只能对单个车型进行精准预测;而第三种基于迁移学习的LSTM模型具有泛用性可以对大部分纯电新能源汽车进行销量预测,且其预测结果与对车型单独进行预测的结果的MAPE值并无差别,根据表10的 MAPE值可知,迁移学习的 LSTM模型的MAPE值为0.26,精度达到74%。
本文虽然提出了迁移学习的汽车销量预测模型,对汽车销量预测的研究有一定的作用,但对于本次实验仍有很多不足:一是由于实验设备算力有限,并不能将所有的所涉及到的所有参数进行统一调整,未进行更多参数的选择进而改进模型;二是本文并没有将更多的因素,如:政策因素、疫情因素、网络搜索数据、网络评论情感等包含到模型预测当中。
猜你喜欢
车迷(2022年1期)2022-03-29 00:50:20
当代水产(2021年7期)2021-11-04 08:17:32
中国交通信息化(2020年11期)2021-01-14 03:30:30
汽车与安全(2020年8期)2020-11-13 09:41:24
汽车与安全(2020年7期)2020-10-09 11:13:01
汽车与安全(2020年5期)2020-08-28 11:13:49
汽车与安全(2020年4期)2020-06-23 09:37:16
汽车观察(2019年2期)2019-03-15 06:00:12
家用汽车(2016年4期)2016-02-28 02:23:37
汽车与安全(2015年12期)2015-09-10 06:12:36
