
基于一维卷积神经网络的实时道岔故障诊断
2022-10-17 11:15:26陈光武
计算机工程与应用 2022年20期
池 毅,陈光武
1.兰州交通大学 自动化与电气工程学院,兰州 730070
2.兰州交通大学 自动控制研究所,兰州 730070
3.甘肃省高原交通信息工程及控制重点实验室,兰州 730073
S700k电动转辙机作为高速铁路重要组成设备之一,是保证列车安全通过道岔的转辙设备。而当前我国主要是采用铁路信号集中监测系统(CMS)采集电流曲线或功率曲线进行监测,以工作人员的定期修和故障修两种方式相结合,这种道岔故障诊断方式已经不适用于当前高速铁路自动化、智能化发展方向。
传统的故障诊断方法分为以下三个步骤,首先以专业的先验知识对原始动作功率曲线数据进行信号处理,提取特征数据,主要有时域、频域(小波分解(WT)[1])、时频域(集合经验模态分解(EEMD)[2])的信号处理方法;然后对提取的特征数据进行降维,使用主成分分析(PCA)[1,3]、Fisher准则[3]等方法;最后使用分类器对降维后的特征数据分类,使用反向传播神经网络(BPNN)[1,4-5]、支持向量机(SVM)[5-6]、灰关联[4]、隐马尔可夫模型(HMM)[3]等方法,其中对分类器参数的优化,通常使用粒子群优化算法(PSO)[5]、遗传算法(GA)[3]等算法,至此完成整个故障诊断。这种对信号进行多样化处理和分类算法改进的分层诊断框架,很难进行联合优化,而将两者融合的方法目前研究较少。
深度学习在机器健康监控中的应用非常广泛[7],常使用的是卷积神经网络和长短期记忆网络。二维卷积神经网络(2D-CNN)主要应用在二维图像识别领域,然而将2D-CNN用于时间序列数据时,除了需要将数据从1D转换到2D外,通常还需要大规模的数据集,所以本文采用直接处理一维时间序列数据更优的一维卷积神经网络,如应用在心电图信号检测[8]、轴承振动信号故障诊断[9-10]、加速度计采集时间序列信号的人类活动识别研究[11],电力系统的电压、功率和相角的时间序列稳定评估[12]等。长短期记忆网络用于轨道电路的电流信号的故障诊断[13]、电机电流信号的实时故障诊断[14]等。
人工提取数据特征倾向于追求正确率而降低实际运用的整体泛化能力,降维后构建的特征工程则可能会丢失重要信息,故需要在特征完整度和诊断准确率上进行联动,寻求两者之间的平衡。本文采用的一维卷积神经网络可以直接应用于原始信号(例如,电流、电压、振动等),却无需进行大量数据的预处理(例如特征提取、选择、降维、去噪等)。直接对原始数据自适应提取特征,有效地消除传统人工特征提取与选择所带来的复杂性和不确定性;将特征提取与分类融合为一体,然后对整体进行优化,选择最优的结构,从而提升故障检测正确率,并提高泛化能力,能更好地用于实际的检测故障。对于这种线性1D卷积局部连接和参数共享机制,大大减少了模型的训练参数和训练时间,能实现实时诊断和在低成本的硬件上实现。
1 S700k转辙机动作过程分析
在分析S700k交流式转辙机动作的故障时,主要分析转辙机的动作功率曲线和动作电流曲线,转辙机的工作状态可以由其输出工作拉力的具体变化情况表现,而动作功率曲线的大小能反映转辙机输出拉力的变化,所以本文使用动作功率曲线进行研究。
1.1 转辙机正常工作状态
S700k转辙机正常工作的动作功率曲线如图1所示,主要包括5个阶段,分别是启动、解锁、转换、锁闭、表示。转辙机的功率动作曲线在0~0.3 s之间,处于启动阶段时,功率值较大,随即进入解锁、转换阶段,功率曲线值维持在0.5 kW左右,在功率曲线出现小幅下降时,处于锁闭阶段,之后进入表示阶段,功率曲线降至0 kW。
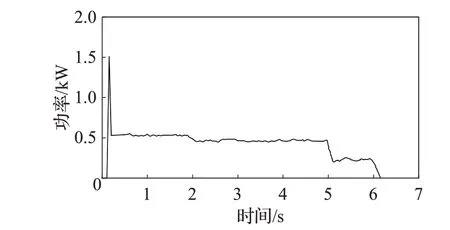
图1 S700k转辙机正常功率曲线Fig.1 Normal power curve of S700k switch machine
1.2 转辙机故障工作状态
通过现场调研和相关资料,当前道岔主要有8种常见的故障模式,具体的故障现象及故障原因如表1所示,与其对应的S700k转辙机的动作功率曲线如图2所示。
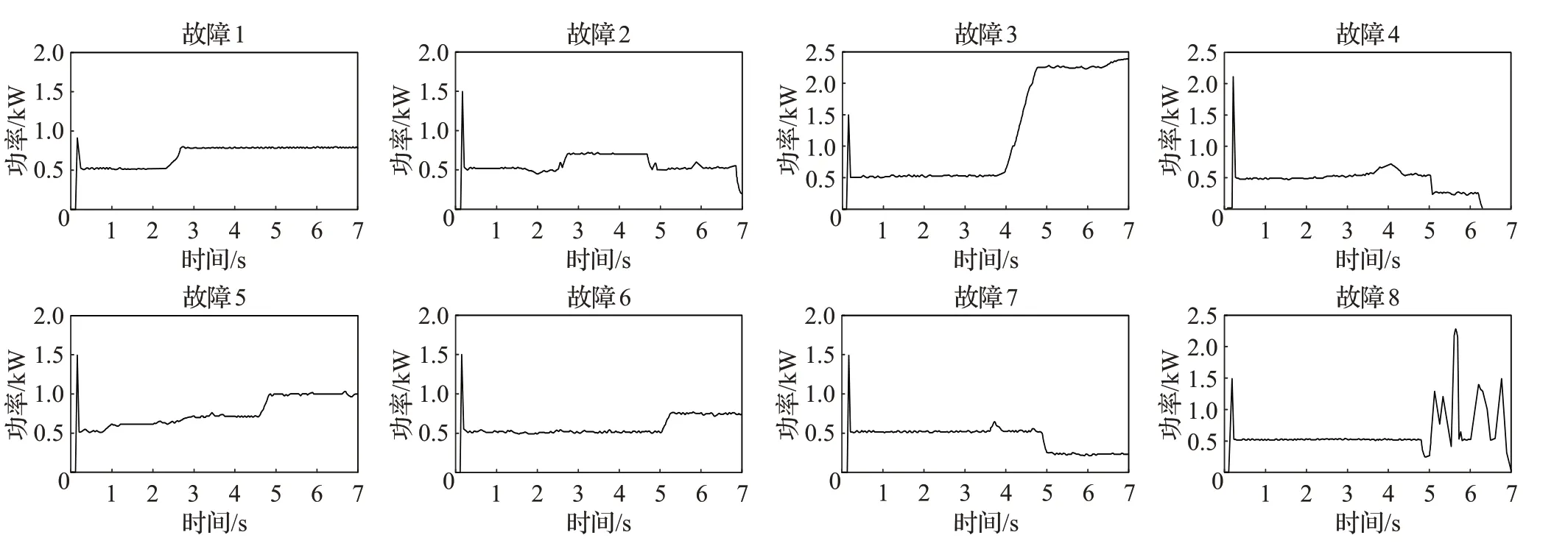
图2 常见的8种道岔故障所对应的动作功率曲线Fig.2 Action power curve corresponding to eight common turnout faults

表1 S700k转辙机常见故障现象和故障原因Table 1 Common fault phenomena and causes of S700k switch machine
2 一维卷积神经网络结构
1D-CNN和2D-CNN结构类似,其基本的结构由输入层、卷积层、池化层、全连接层、输出层组成,其基本结构如图3所示,本文使用一维卷积神经网络进行序列到序列的学习,将原始功信号的时间序列作为输入,输出一系列的标签预测。卷积层和池化层用于提取数据特征,通常需要堆叠多组卷积层和池化层,从而提取更深层次的特征序列,提高神经网络的性能,全连接层用于对提取的特征进行分类。如图4中结构图所示,是1DCNN的三个连续隐藏CNN层,其中包括两个卷积层一个池化层。1D-CNN的卷积核是一个权值矩阵,卷积核以一定步长依次对输入信号的局部区域进行卷积运算以生成相应的一维特征图,不同的卷积核分别从输入信号中提取不同的特征,且在同一输入信号上实现权值共享,局部连接和权重共享的这一特征能有效地降低网络的复杂性和减少训练参数的数量。完成卷积操作之后,需要使用激活函数实现非线性变换,使用在CNN中应用广泛的Relu激活函数,它能使模型更好收敛和有稀疏表示,防止梯度消失。一维卷积层的运算公式如下所示:kk
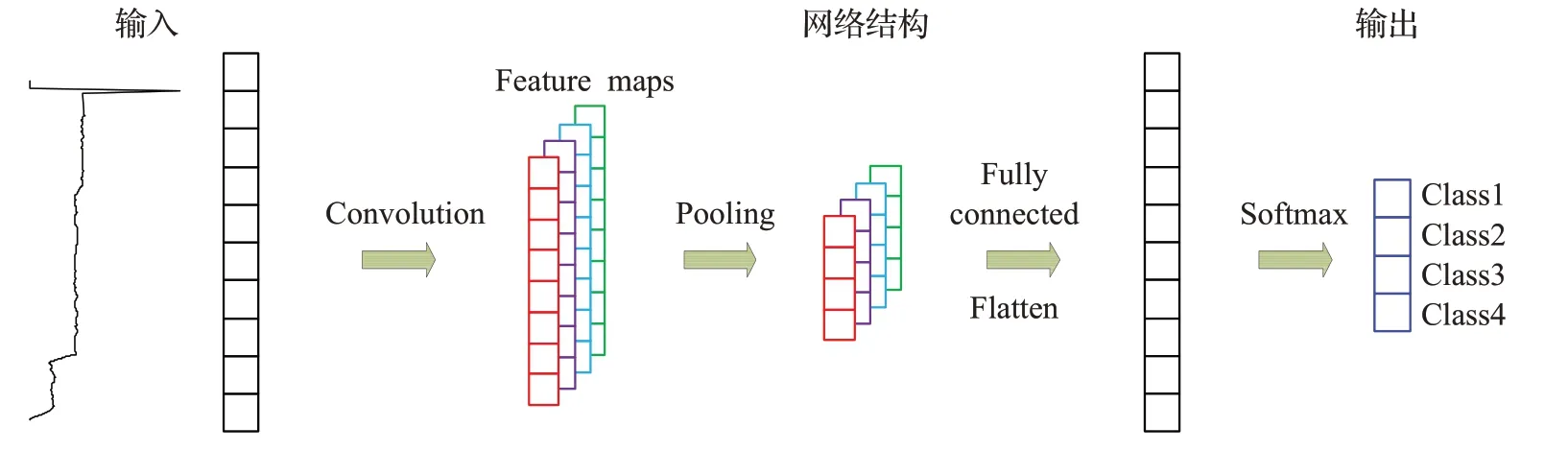
图3 1D-CNN网络结构图Fig.3 1D-CNN network structure diagram convolution operation

图4 1D-CNN的三个连续隐藏CNN层Fig.4 Three consecutive hidden CNN layers of 1D-CNN

在卷积操作后,提取的特征序列的数量增加,导致数据的维数扩大,提高了计算复杂度,通过池化(pooling)操作特征序列进行降采样DS(down sampling),降低特征序列数据的维度,最大池化(max pooling)是对设定窗口内的最大参数作为输出值。池化的计算公式如下所示:

经过多层的卷积和池化操作后,将提取的多列深层次特征序列在扁平层(flatten)整合为一列,经全连接层继续提取时序特征,全连接层和传统的神经网络(ANN)结构一致,是由多层的隐含层组成。在输出层,采用softmax函数进行分类,如下所示:

式中,P(j)表示输出层输出的第j类的概率值,值范围在[0,1],k表示需要分类的数量。
损失函数用于度量模型的质量,通过模型的输出结果与实际目标结果之间的接近度来描述,针对多分类问题,采用交叉熵损失函数,如下所示:


在模型的训练过程中极易出现的过拟合问题,采用正则化增强模型的泛化能力,在全连接层中加入随机丢弃神经元(Dropout)的方法,防止神经元对训练数据的适应过度,Dropout只针对模型训练过程,丢弃的神经元在梯度BP时不更新权值,这就使得网络以不完美的方式学习,达到了提高泛化能力的目的,也增加了模型的鲁棒性。
3 一维卷积模型的实验设计
3.1 构建实验数据
S700k转辙机的动作功率曲线是一维时间序列数据,正常的道岔动作时间为6~7 s,铁路信号微机监测系统中采集一个数据的时间间隔为0.04 s,所以总计取150~175个点,而一些故障的动作时间会超过7 s,为了统一模型的输入张量,所以将时间序列数据的长度固定,取动作功率曲线7 s的时间序列,总计175个点集,当动作功率曲线时间少于7 s时,未到7 s的序列以0补充。在输入模型训练之前,将数据进行归一化,其公式如下所示:

3.2 基于1D-CNN故障诊断流程
本文建立的基于一维卷积神经网络的道岔故障智能诊断流程图如图5所示,具体步骤如下:
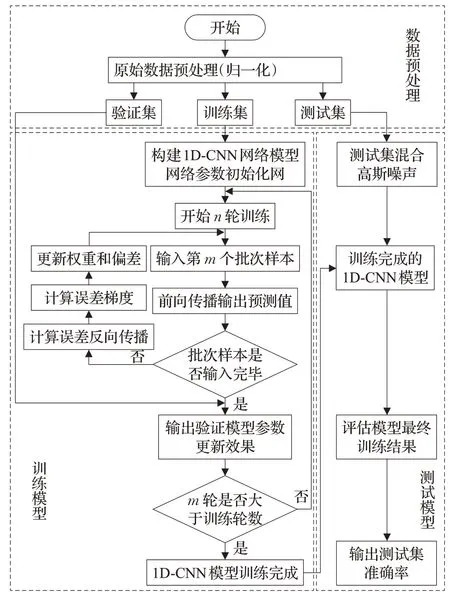
图5 1D-CNN训练流程图Fig.5 1D-CNN training flow chart
(1)将不同状态的所有功率序列数据集进行归一化,再将数据集的标签进行独热编码(one-hot vector),然后将数据集打乱,分为训练集、验证集、测试集,并在测试集中加入高斯白噪声。
(2)建立1D-CNN模型并确定模型的超参数(迭代次数、批次数和学习率等),初始化模型的权值和偏差。
(3)输入训练集,根据迭代次数和批次数训练模型,通过前向传播得出模型的输出值与期望值的误差,然后进行反向传播,求得误差梯度,更新模型的权重和偏差。在每轮训练过程中,使用验证集对模型进行验证。
(4)重复执行步骤(3),直至训练集完成所有的迭代次数后,得到1D-CNN模型。
(5)将测试集用于已经训练好的模型,根据模型的输出准确率判断模型是否符合实际诊断要求,保存模型。
1D-CNN模型在Python3.6的环境下,采用Keras深度学习框架搭建,模型采用随机梯度下降(SGD)算法更新权值,设置学习率为0.001,采用小批量训练法,批量大小为15。本文选择3层卷积层,3层池化层,使得模型对故障诊断的准确率达到要求,而且模型的计算复杂度不是很高,模型具体结构与相应的参数,如表2所示。
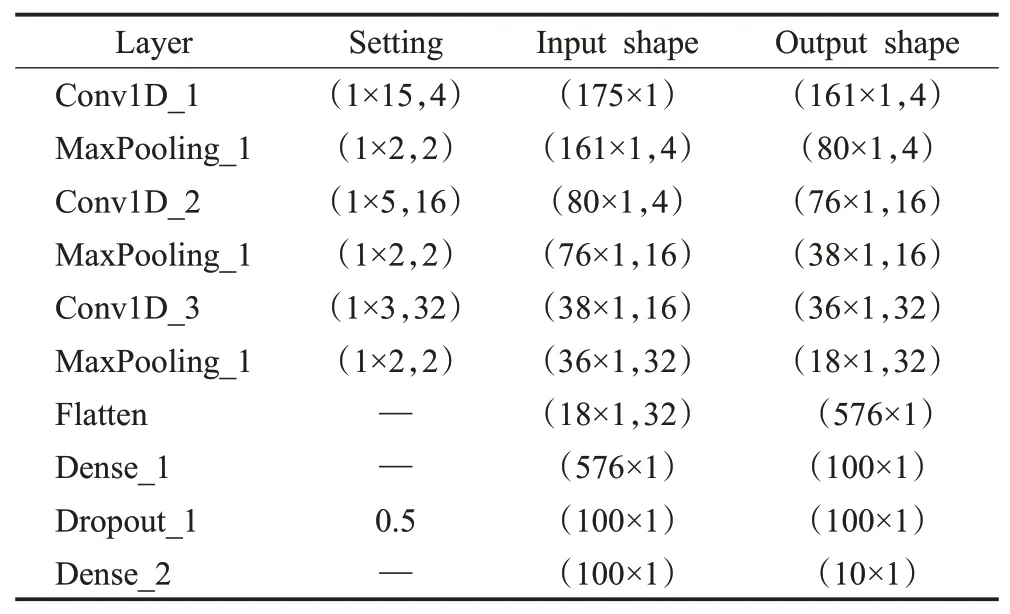
表2 1D-CNN参数分布Table 2 1D-CNN parameter distribution
4 实验结果和分析
由于在现场采集的正常和故障数据失衡,故障数据的数量相较正常数据少,通过Matlab中的rand函数,对已有的故障数据加入不同程度的波动,仿真模拟出一部分故障数据,总共900组数据,其中训练集有630组数据,取训练集中的20%作为验证集,测试集有270组数据,然后在测试集继续加入高斯白噪声,验证训练的模型的泛化能力,鲁棒性。
针对卷积核的多尺度对模型准确率的影响进行测试,以确定卷积核尺寸,具体结果如表3所示,从表中可以看出,第一层卷积层使用大卷积核,对模型的准确率有一定的提高,因为大卷积核能使原始数据中的噪声对模型的准确率影响降低,而后两层采用小卷积核,因为小卷积核能更有效地提取出原始数据中的深层次特征,对模型的准确率有着至关重要的作用。

表3 多尺度卷积核的模型诊断结果分析Table 3 Analysis of model diagnosis results based on multiscale convolution kernel
模型训练过程中的正确率如图6所示,Train代表训练集的准确率,validation代表验证集的准确率,由实验结果看出,模型在迭代25轮之后,训练集上的准确率为97%左右,而在模型迭代9轮之后,验证集上的准确率为100%,验证集的准确率高于训练集,导致出现这样的结果,主要是因为使用了正则化Dropout。如图7所示,模型在迭代25轮之后,训练集和验证集的交叉熵损失也接近0。

图6 训练过程的准确率曲线Fig.6 Accuracy curve of training process

图7 训练过程的损失曲线Fig.7 Loss curve of training proces
为了验证一维卷积神经网络模型中卷积层对原始输入信号的自适应提取特征的能力,采用了可视化t分布随机近邻嵌入(t-distribution stochastic neighbor embedding,t-SNE)方法[15],它是一种将高维数据降维可视化的分析方法,其思想是在低维度空间构建一个t分布,使其与高维空间构造概率分布一致。将卷积层提取的特征进行可视化分析呈现,具体结果如图8所示,展示了模型中三层卷积层提取特征的t-SNE可视化的映射视图,如图可知,在第一层卷积层提取特征之后,具有一定的雏形,明显看到各种类型有一定的聚集,但是仍然有大量的散点,分类效果非常不好;在第二层卷积层提取特征之后,各种类型能有效地聚集在一块,但是相对有一些分散;在第三层卷积层提取特征之后,各种类型基本都能很紧密地聚集在一块,且各种类型的距离更大,足以区分各种道岔的故障状态,这也说明了卷积层对提取道岔动作功率曲线时间序列的深层特征有很明显的效果,所以1D-CNN可以从含噪声信号中学习有效的特征,并实现准确的故障诊断。

图8 模型中三层卷积层提取特征的t-SNE可视化Fig.8 T-SNE visualization of features extracted from three-layer convolution layer in models
LSTM模型是由两层LSTM单元组成,然后用Dropout方法提高模型的鲁棒性,最后采用softmax函数分类,迭代次数为50次;自编码器模型是先训练4层编码,4层解码,然后将提取的特征输入给softmax函数,实现故障诊断,迭代次数为30次;两模型均采用SGD算法更新权值,设置学习率为0.001,采用小批量训练法,批量大小为15。
图9是一维卷积神经网络模型在测试集上分类的混淆矩阵,图10是长短期记忆网络(LSTM)模型和自编码器(AutoEnconder)模型在测试集上分类的混淆矩阵。从图9中看出,出现了一例误判,将故障4预判为故障7,从图2中可以看到,故障4和故障7的整体功率动作曲线有很大的相似性,这是出现误判的主要原因。
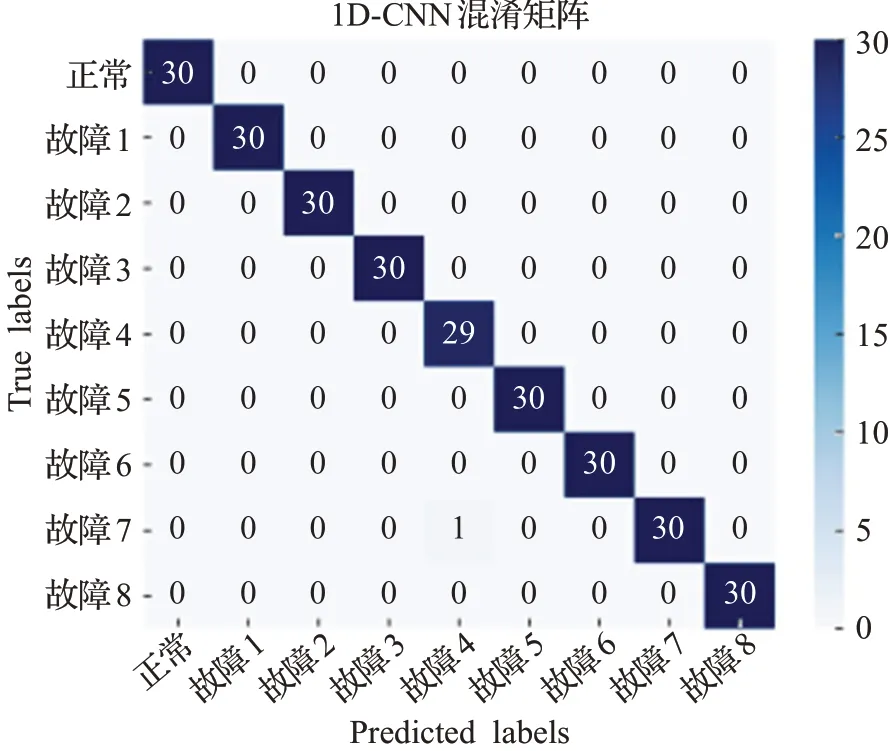
图9 1D-CNN的混淆矩阵Fig.9 Confusion matrix of 1D-CNN
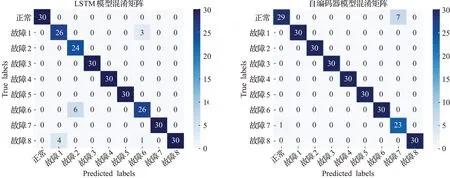
图10 LSTM和AutoEnconder的混淆矩阵Fig.10 Confusion matrix of LSTM and AutoEnconder
分别对表4中的5种模型进行10次训练测试,随机选择一组测试结果,分别得到模型的预测正确率和以分钟为单位训练时间,1D-CNN模型在道岔各种状态的预测正确率相比其他的模型最高,达到了99.63%,在多次测试中有时也能达到100%;在训练时间上,1D-CNN模型相比LSTM和AutoEncoder两种深度学习模型更短,也能说明1D-CNN模型的计算复杂度低,1D-CNN模型相比SVM和BP两种传统机器学习的分类器,在训练时间上相差不多,但是在测试集上的准确率有很大的提高。

表4 1D-CNN故障诊断模型和其他方法的对比Table 4 Comparison between 1D-CNN fault diagnosis model and other methods
5 结论
本文采用的一维卷积神经网络是首次应用于道岔故障诊断,根据实验结果可以得出如下结论:
(1)1D-CNN模型相比于传统机器学习方法,不需要专业的先验知识去手工提取原始功率信号的相应特征,所以不会破坏原始功率信号的时空信息,从原始功率信号的整体上直接学习更有代表性、更深层次的特征,突破了浅层学习的瓶颈,提高了诊断的准确性。
(2)所提出的方法能将特征提取与分类操作融合到一个机器学习体中,能更好地进行二者的联合优化。
(3)对于单个原始功率曲线输入模型,只需要0.37 ms即可实现诊断分类,可以满足道岔转换实时的监测。
(4)实现了端对端的自适应学习,直接输入道岔原始的功率曲线时间序列,输出道岔相应的状态类型,模型有很强的泛化能力,有很好的鲁棒性,并且在准确率上平均能达到99%以上,能很好地应用于铁路现场的实时道岔故障检测。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
铁道通信信号(2020年3期)2020-09-21 09:13:16
铁道通信信号(2020年1期)2020-09-21 08:55:00
铁道通信信号(2020年10期)2020-02-07 01:01:02
铁道通信信号(2019年3期)2019-04-25 03:00:40
铁道通信信号(2018年10期)2018-12-06 09:34:48
铁道通信信号(2018年10期)2018-12-06 09:34:48
中国交通信息化(2018年5期)2018-08-21 03:37:40
