
基于边缘增强的遥感图像弱监督语义分割方法
2022-10-17 11:07栾晓梅刘恩海武鹏飞
计算机工程与应用 2022年20期
栾晓梅,刘恩海,武鹏飞,张 军
1.河北工业大学 人工智能与数据科学学院,天津 300401
2.北京仿真中心 航天系统仿真重点实验室,北京 100854
遥感图像因其丰富的地物信息,已成为对地观测的重要数据来源。遥感图像语义分割可实现为图像中的每一个像素点分配一个语义类别,被广泛应用于测绘、精准农业、土地观测等领域。随着全卷积神经网络(fully convolutional neural network,FCN)[1]及其改进网络U-Net[2]、SegNet[3]、Deeplab[4]等被用于语义分割[5],分割精度得到大大提升。马宇等人[6]基于U-Net网络采用空洞卷积的方式提升了交通标志中小目标分割的精确度。王鑫等人[7]则加入了激活层与Dropout层,实现对耕地、河流、建筑的快速检测分割。DeepLab网络中的空间金字塔池化虽然能够增加网络的感受野,初步达到上下文结合的效果,但是,该方法学习到的是分布在图像平面空间距离上的信息。为此,Yan等人[8]采用关联非本地语境的方法,提出了一种结合自注意力机制和RNN实现上下文相关性的方法。
上述基于深度学习的全监督语义分割方法在训练过程需要依靠大量的带有像素级标签的数据,但这些数据人工标注成本很高。近年来许多研究者致力于通过图像类别、边界框、涂鸦等更易获取的标注数据进行语义分割,大大降低了数据成本。同时,遥感图像地物信息复杂、目标尺寸不一的特点,为遥感图像弱监督语义分割带来了巨大挑战。
目前,使用图像级标签的弱监督语义分割方法大多是基于可视化的两阶段方法[8-9]。首先,训练分类网络,通过初始定位获得伪像素级掩码;其次,利用生成的伪掩码单独训练语义分割网络。在分类网络中获得的初始可视化激活区域很大程度上决定了伪分割掩码的质量,进一步决定了最终语义分割网络的分割质量。因此,目前弱监督语义分割方法的注意力主要集中在生成一个质量较好的伪像素级掩码上。
Zhou等人[10]利用类激活图生成一个粗略的特征映射来定位物体的空间位置。原方法中CAM只能覆盖目标最具有判别性的部分,存在着过激活或欠激活的问题。为此,多层次特征融合方法[11-13]通过不同方式融合多层次的特征实现遥感图像中不同尺寸目标的激活。Ma等人[14]和Chen等人[15]更是在多层次特则融合的基础上加入超像素池化为网络提供低层特征,以提升目标激活的完整性。基于激活区域获得的初始伪分割掩码是极粗糙的,为了进一步提高伪分割掩码的质量,条件随机场(conditional random field,CRF)[16]被广泛用作映射函数。左宗成等人[17]、熊昌镇等人[18]提出将条件随机场与可变形卷积融合,进一步对遥感图像的激活区域进行细化。但是,遥感图像地物信息复杂,通过CRF的颜色约束对激活区域的轮廓进行微调是有限的。为了更准确地分割遥感图像,陈琴等人[19]将边缘信息和网络的多尺度特征图进行组合,提高了遥感图像分割的准确性和完整性。
Nivaggioli等人[20]改进自然场景中的像素间亲和力方法[21],通过学习像素间的语义关系对激活区域进行修正,有效提升了遥感图像伪分割掩码质量。此外,为获得额外的监督信息,自监督学习理念[22]被用于弱监督语义分割。Wang等人[23]利用理想分割函数的等方差设计自监督的辅助任务,以寻求额外的监督来缩小差距;Shimoda等人[24]通过加强对分割映射函数结果的自监督,从差异区域中学习有用信息,进一步细化伪分割掩码的边缘。两者都是通过从输出域生成受监控的监督信息,作为网络的优化方向。
但是,上述方法都是基于可视化的两阶段方法,模型训练繁琐。刘雨溪等人[25]基于生成对抗网络设计的端到端弱监督语义分割网络仅使用少量样本标签,在ISPRS 2D数据集上实现较好的分割。但生成对抗网络往往需要源域、目标域两个域的数据集,且这两个域要求有一定的相似性。
针对上述问题,本文结合遥感图像的特点,设计了一个基于边缘增强算法的端到端弱监督语义分割方法,仅使用图像级标签实现遥感图像的多类别语义分割。为验证本文方法的有效性,本文还将特征空间边缘增强模块扩展到两阶段方法中,并在ISPRS的Postdam和Vaihingen两个城市数据集上进行了实验。
本文主要创新包括以下几个方面:
(1)为准确激活出遥感图像中的小目标,本文提出了特征空间边缘增强模块,以自监督的方式在激活出小目标的同时提升伪分割掩码质量。
(2)为提升分割结果的语义完整性,本文利用特征空间边缘增强模块生成的伪分割掩码为输出空间提供边缘信息。
(3)为降低模型训练的繁琐度,本文提出联合细化损失配合交叉熵损失优化训练过程,设计了一个新的端到端弱监督语义分割网络。
1 网络整体结构
本文网络整体结构如图1所示,主要由两个平行模块构成,两个模块共享相同的主干网络,在训练过程中同时更新整个网络。
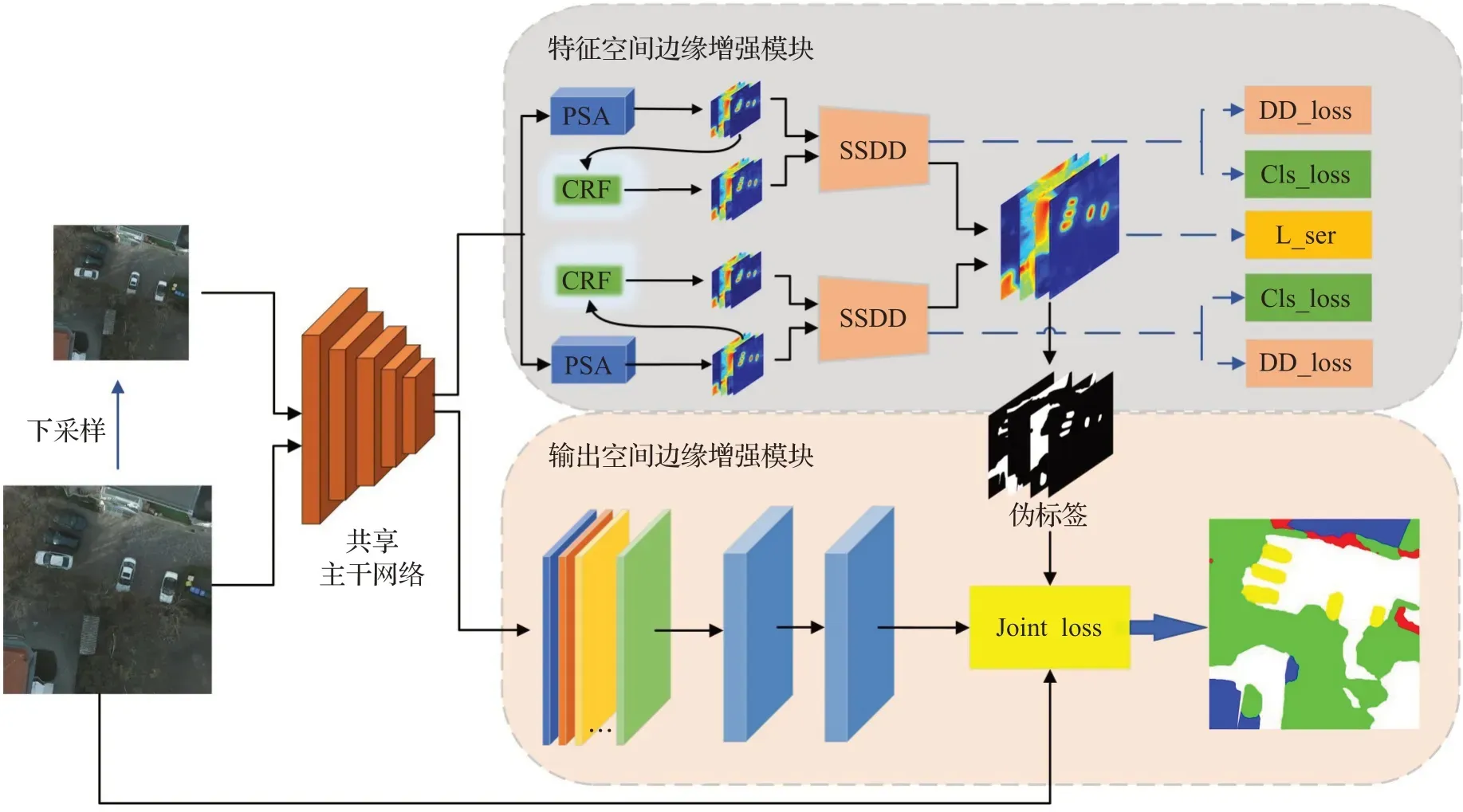
图1 遥感图像弱监督语义分割网络整体结构Fig.1 Overall structure of remote sensing image weakly-supervised semantic segmentation network
1.1 特征空间边缘增强模块
整个特征空间边缘增强模块利用自监督的方式将小目标激活与边缘降噪进行联合,最终生成可靠的伪标签。其主要从两个方面来提升伪像素级掩码的质量。在原图及下采样后的图通过共享主干网络得到不同大小的特征图后,本文首先利用尺度等变正则化保证原图及下采样图之间CAM激活映射的一致性,以激活出遥感图像中的小目标;其次,本文在不同尺度的激活区域基础上,分别利用随机游走PSA和CRF得到效果不同的特征图,通过等变差异检测模块从差异区域中学习有用信息,进行边缘特征增强。
1.1.1 尺度等变正则化
理想状态下基于CNN的非线性映射函数可表示为Fσ(x)=y,y表示输入图像x的分割掩码,σ表示网络参数。用C表示图片中包含的目标类别数量,具体类别用c表示,弱监督语义分割网络在CNN网络基础上附加额外的全局平均池化函数P()解决分类任务,分类任务可以表示为P(Fω(x))=c,ω表示此时的网络参数,用c表示图像x对应的类别标签。通常情况下弱监督语义分割方法假设其分类网络与全监督分割网络的最优参数满足σ=ω。但是每个样本在训练前都会进行数据增强,显然这种做法是不正确的。本文算法将对原图进行的尺度改变操作视为数据增强的一种,其仿射变换矩阵用A表示,则弱监督任务的映射不变性为P(Fω(Ax))=c。其中分类不变性任务主要是由池化函数P()实现的,但是对于映射函数Fω()没有明确的不变性约束,无法实现分割函数的相同目标。
为此,Wang等人[23]在弱监督前提下,集成额外的尺度等变正则化(SER),使用自监督标签以缩小分类和语义分割最优解的差距:

基于对遥感图像尺度多变性的考虑,本文利用尺度等变正则化方法,采用权重共享的网络,将原图及下采样后的图分别送入网络,通过主干网络分别获得C-1通道的特征图(不包含背景类)。
类别c的CAM图可表示为:

其中,ωc表示类别c的分类权重,fcamu表示全局平均池化前获得的像素u处的特征向量。考虑到原图与下采样后得到的激活图尺度不一致,通过双线性差值对原图得到的CAM输出进行下采样,通过自监督的方式保证CAM在不同尺度下的激活映射一致。此外,本文分别校验了上采样和下采样对遥感图像CAM激活映射的影响,如图2所示。通过自监督尺度等变正则化处理后,本文方法获得的目标类激活图效果更好。
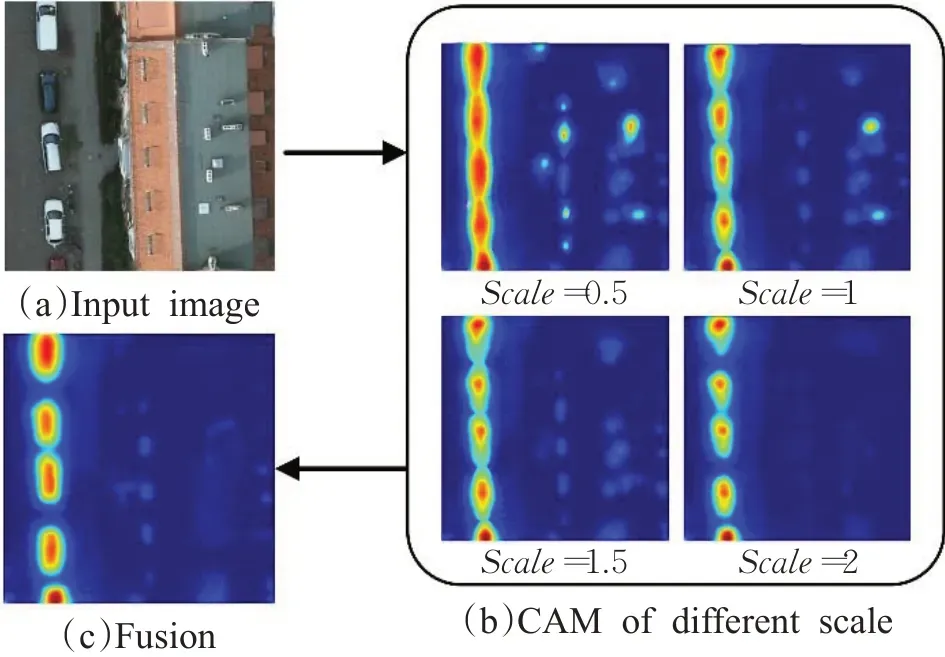
图2 不同尺度输入图像生成的CAM图对比Fig.2 Comparisons of CAMs generated by different scale input images
1.1.2 等变差异检测
Wang等人[23]直接将激活区域可视化作为语义分割的伪分割掩码,但是这些伪掩码的边缘粗糙。为此,考虑到1.1.1小节的尺度等变正则化只对映射函数F进行了仿射变换的监督,本小节从将可视化结果转换为语义分割的映射函数G入手,假设分割映射函数G的结果含有噪点,通过消除噪点来提高映射函数的精度,从而达到细化分割掩码边缘的目的。
映射函数G的输入和输出分别定义为:mknowledge(简写为mK)、madvice(简写为mA)。映射函数G的输出结果mA中含有正确和不正确的信息,本文将其视为包含噪声的监督,为函数G提供监督信息。根据两者之间的差异区域,从mA(含有噪点)中获取有用信息,并更正已有的分割掩码。差异区域DK,A定义为:

其中,u∈{1,2,…,n}表示像素的位置,n是像素的数量。差异检测模块结构如图3所示。
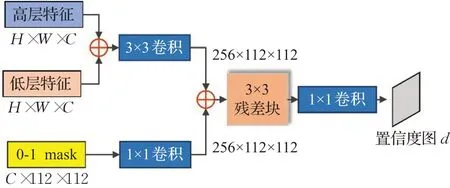
图3 差异检测结构图Fig.3 Difference detection module
它由三个卷积层和一个残差模块组成,本文将原始掩码、后处理的掩码以及与目标具有相同通道数的0-1向量输入该模块,输出得到差异掩码的置信度图d。该模块的损失为:
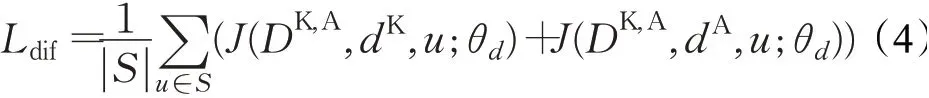
式中,S是输入空间的一组像素,函数J()返回二值交叉熵的损失,θd表示其参数。
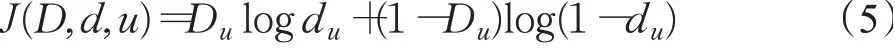
因为原始掩码对差异检测模块影响较大,本文未对主干网络的输出特征直接使用全局平均池化,而是利用像素亲和力矩阵(PSA)[21]分别将不同尺度下的初始定位激活传播到属于同一语义目标的附近区域。本文用PK0=PSA(x;θpsa)表示由PSA获得的概率图,其CRF结果表示为PA0。本文假设从概率映射(pK0,pA0)中获得初始的分割掩码为(mK0,mA0)。然后把两者输入到SSDD模块中分别得到置信度图dK0、dA0。本文通过dK0如何接近dA0的角度来计算mA0的置信分数ϑ:

其中,biasu是差异检测用于选择阈值的超参数。通过置信分数ϑu进一步获得细化掩码mD0:

此时,差异检测模块的损失为:
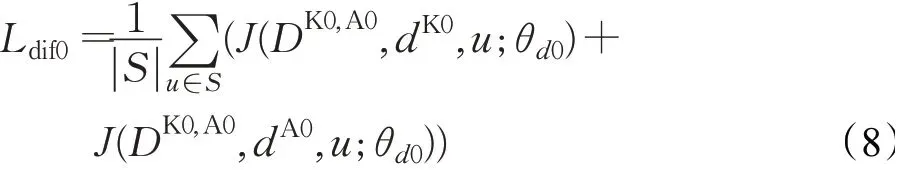
通过差异检测得到大小不同的细化掩码mD0、mD0d(这里,对原图及下采样图差异检测的处理方式一样,便不再赘述)。由于原图及下采样的图分别经过差异检测模块后的概率图尺寸不一致,边缘特征增强模块最终对细化掩码mD0、mD0d进行尺度等变监督,其损失函数Lser为:
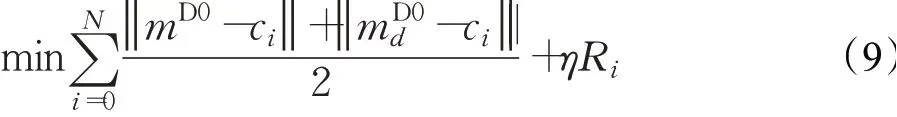
式中,i表示样本索引,η控制正则化的影响参数,在本文将其设置为1,不需要再对其进行调整。在1.1.1节中对原图进行下采样获得新的大小概率图,这里A表示1/2下采样的双线性差值矩阵。
1.2 输出空间边缘增强模块
特征空间边缘增强模块获得的伪分割掩码质量得到大幅提高,以此训练的分割网络其分割性能也被大大提升。但上述研究均是建立在多阶段的基础上,并没有实现端到端的训练分割。此外,在CAM生成过程中,全局平均池化层(global average pooling,GAP)使得特征图中所有的像素点参与到目标类识别中,增加了分类器对上下文的依赖,无法保证目标的语义完整性。
因此,本节利用特征空间边缘增强模块(第1.1节)获得的可靠的伪分割掩码作为伪标签,为输出空间边缘细化模块增加额外的语义信息,从而达到掩码边缘细化的目的。与其他利用伪标签单独训练语义分割网络的两阶段方法不同,本文网络的两大特征增强模块共享相同的主干网络。
为融合特征空间边缘增强模块中伪分割掩码的语义信息,本文首先用1×1卷积替代了CAM生成过程中的全局平均池化层。虽然两者计算效果是一样的,但是,GAP是将所有的像素点进行了目标分类计算,这会降低网络对小目标的定位能力,而1×1卷积则可以避免这个问题。其次,本文通过1×1卷积获得的特征预测分数图与伪分割掩码进行相应分类分数的相对加权,共同生成类分数。类别c的类分数可表示为:

给定特征x:,:,:本文首先预测每个像素大小为C×H×W的分类分数y:,:,:。然后,添加一个背景通道,以获得具有置信值的遮罩m:,:,:。
本文方法使用的分类损失是多标签分类损失函数(multi-label soft margin loss):
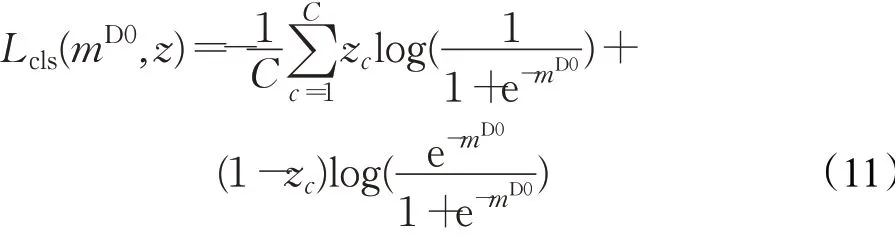
式中,mD0是模型预测向量,z是地面真值标签的二进制向量,C={c0,c1,…,cN}表示包含背景类c0的类别数。但是,交叉熵损失Lcls主要利用了伪标签中的标记数据,并没有考虑未标记数据。为了同时考虑标记数据和未标记数据,本文利用PCA学习像素级亲和力的思想,充分利用RGB颜色和像素空间位置,设计了一个新的浅层损失,即语义细化损失Lthinning。本文采用像素相邻标签的组合来迭代地更新融合特征空间伪分割掩码后获得的伪标签mD0。
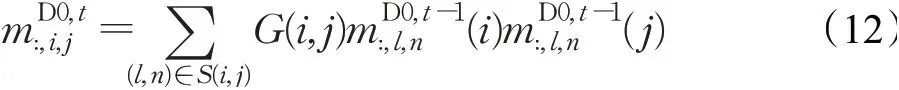
式中,mD0,t即为迭代细化后的像素级掩码。G(i,j)表示由高斯函数获得的像素级亲和力。
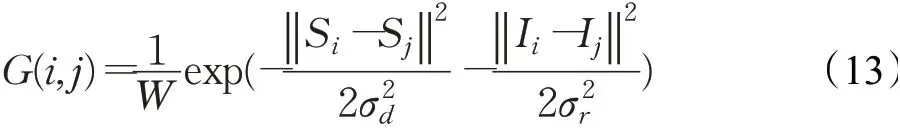
式中,1/W是标准化权重,S同公式(4)中一样,表示像素的空间位置,I则表示RGB颜色。σd和σr是控制高斯函数核大小的超参数。高斯核的大小决定了公式(13)迭代更新伪标签的次数。
通常情况下,交叉熵损失认定标签信息是100%正确的,但是这与事实不符。通过边缘降噪模块得到的所有像素标签都不是100%可靠的,这意味着交叉熵损失可能会引入一些错误。本文的语义细化损失为减轻这一问题,为像素i添加了滤波器D(i):
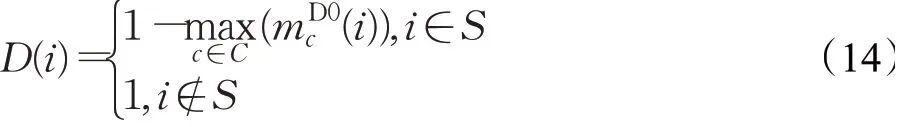
最终,本文的语义细化损失可以表示为:
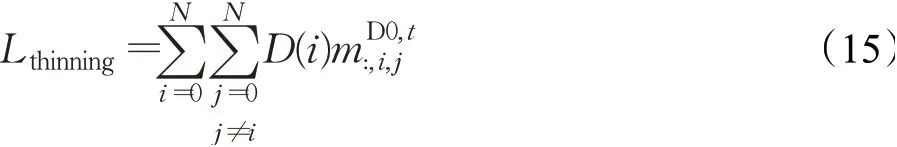
通过不断迭代,伪分割掩码不断得到细化,为分割提供良好的自我监督信息。
本文方法通过自监督的训练策略,利用训练集中的图像级信息和细化后的CAM图得到更加良好的伪标签,进而训练得到良好的网络结构参数,使得整个网络训练过程中通过一个标准的反向传播算法进行了端到端的优化,从而在预测过程中获得更好的分割结果。
本文网络最终的损失函数L为:

网络整体算法如算法1所示。
算法1端到端弱监督语义分割算法流程


2 实验
2.1 数据集介绍
为验证本文方法对遥感图像的分割效果,在ISPRS 2D语义分割数据集[26]上进行验证,其包含Postdam和Vaihingen两个城市图像数据。两个数据集都包含6类,即Impervious surface、Building、Low vegetation、Tree、Car、Clutter。为了更直观地展现最终的多分类语义分割效果,将Low vegetation和Tree合并为一类,即Plant。受硬件条件限制,本文方法将原始数据及标签都进行了随机切割,切割为500×500像素大小的图像。
2.2 评估指标
为了评估语义分割效果,本文通过平均交并比(mean intersection over union,MIoU)、重叠度(intersection over union,IoU)及总体精度(overall accuracy,OA)等评估指标进行了比较。其中IoU用于评估每个类别的精确度,并通过MIoU及(OA)来评估模型的整体性能。
一般来说,根据预测的像素值和地面真值,像素分割结果可分为四种情况:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。IoU可以计算真实值和预测值两个集合的相似性,并由以下等式定义:

MIoU是所有类别IoU的平均值,其等式可写作:
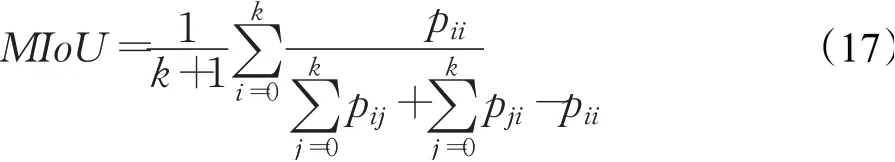
其中,i表示真值,j表示预测值,pij表示i被预测为j。OA是具有正确标记的像素与总像素之比。

2.3 实验设置
实验主要基于Linux系统的Pytorch环境下完成,Python版本为3.6.10,使用GPU加速,服务器处理器为Intel Xeon®CPU E5-2620 0@2.00 GHz。本文采用具有38个卷积层的ResNet38模型[27]作为主干网络,删除了原始网络的平均池化层和全连接层。下采样分支经过多次实验验证下采样率为0.5时效果最好,因此训练时,将原图的下采样率设置为0.5,同时将网络学习率设置为1E-4,批大小设置为8。
为了保证相同的感受野,本文算法将最后三个残差块进行扩张卷积(残差块是具有相同大小的残留单元)。倒数第三层的扩张率为2,最后两层扩张率为4。随后将获取的特征图利用PSA及CRF进行处理,采用作者提供的训练参数,并设置了最佳超参数。随后将PSA最后的上采样率设置为2,分别获得大小为512×112×112和128×112×112的特征图。将其作为等变差异检测机制的高级特征及低级特征。对于输出空间边缘增强模块,本文在主干网络之后增加了两层相同配置的空洞卷积,其卷积核大小为3,扩张率为12,填充率为12。密集能量损失中的参数分别设置为5和10,对背景和前景分别计算交叉熵损失。
在训练期间,这两个主要并行模块都会更新该主干网络,在测试过程中,本文仅使用等变差异检测机制中的原图分支获取最终的分割结果,只需使用输出空间分支来进行预测。
2.4 实验结果及分析
2.4.1 特征空间有效性验证
为验证特征空间边缘增强模块中各部分方法对于伪分割掩码边缘质量提升的作用,本文分别比较了不同方法获得的伪分割掩码质量。表1给出了Potsdam和Vaihingen两个城市数据集上不同方法获得的伪标签质量结果。为更明显地体现特征空间边缘增强模块的有效性,本小节对类激活图进行了可视化展示,如图4所示。
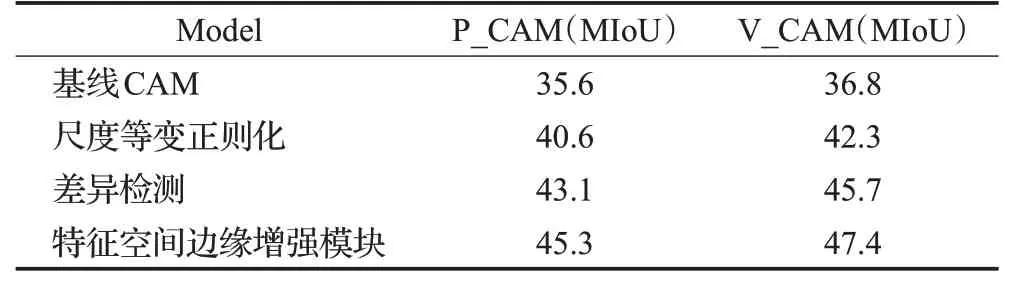
表1 伪分割掩码质量Table 1 Quality of pseudo-segmentation mask单位:%

图4 Potsdam数据集伪分割掩码对比Fig.4 Comparisons of pseudo segmentation mask on Potsdam datasets
(1)定量分析
通过表1的定量对比,本文提出的尺度等变正则化方法在两个数据集上对于伪分割掩码质量的提升均起到正向作用,其中在Vaihingen上较基线CAM方法提升5.5个百分点。此外,仅使用差异检测方法获得的伪分割掩码效果比尺度等变正则化方法的结果更好,原因是它能更好地保证类激活图边缘的完整性。当两者结合后,伪分割掩码质量达到最佳,在Potsdam和Vaihingen数据集上的MIoU分数分别为45.3%和47.4%,大大超过了基线CAM方法。
(2)定性分析
图4展示了Vaihingen数据集中“汽车”类的类激活图,如(c)中红框所示,尺度等变正则化方法采用自监督的策略,比基线传统的CAM方法能够更加准确地激活出遥感图像中的小目标;单独使用差异检测方法获得的类激活图(d)也较好地保证了目标的完整性;两者结合后,类激活图的效果达到最好,如(e)所示。
2.4.2 输出空间有效性验证
本小节实验主要是验证了融合伪分割掩码中的语义信息对伪标签精度提升的有效性,以及语义细化损失对于原始粗糙掩码质量的提升作用。
(1)融合语义信息
表2展示了在Potsdam数据集上融合不同质量的伪分割掩码对最终分割精度的影响。

表2 融合语义信息对比分析Table 2 Contrastive analysis of fusion semantic information 单位:%
通过表2可知,当输出空间融合任意伪分割掩码的语义信息后获得的伪标签均比传统的CAM获得的伪分割掩码质量要高。
(2)语义细化损失
为了验证语义细化损失中高斯核大小(迭代次数)对掩码细化的作用,本文在Potsdam数据集上进行了实验对比,具体实验数据如图5所示。
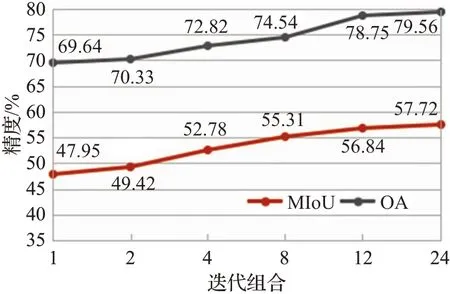
图5 语义细化损失迭代次数对比Fig.5 Comparison of semantic refinement loss iterations
通过图5数据可知,在本文的自监督模型中,语义细化损失是一个至关重要的组件,因为未使用语义细化损失时,分割的MIoU准确率从57.72%显著下降到47.95%,OA更是下降9.8个百分点。此外,内核的大小也会影响精度,随着迭代次数增加,掩码精度不断提升,当达到24时,增长趋势出现缓和现象,因此,本文实验最终选取迭代次数为24。因为小的感受野不足以修正与物体边界存在较大偏差的粗糙掩模的边界。
2.4.3 模型有效性验证
伪分割掩码不能代表最终的语义分割结果,因此,本文分别在Potsdam和Vaihingen两个城市数据集上进行了大量的语义分割实验,通过最终的语义分割结果对比来证明,本文主要从两个方面进行了横向对比实验,实验数据如表3、4所示。此外,图6和图7分别展示了在Potsdam和Vaihingen数据集上本文方法与SSENet[23]、DDNet[24]与本文方法对其中两张遥感图像的语义分割结果对比。在图6和图7中,(a)表示原始图像,(b)表示原始的语义标签,(c)和(d)分别为SSENet和DDNet的语义分割结果,(e)表示本文方法的语义分割结果。
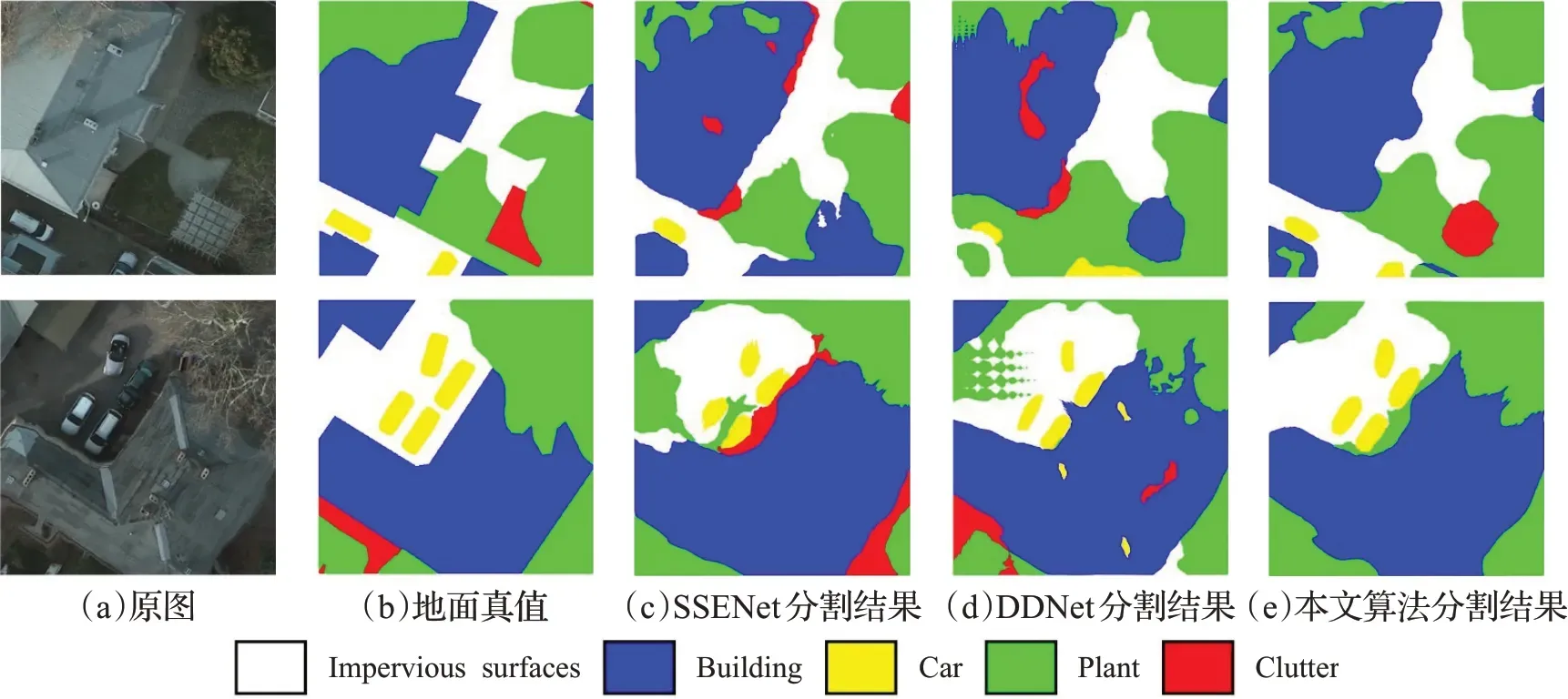
图6 Potsdam数据集语义分割结果对比Fig.6 Comparisons of semantic segmentation results on Potsdam datasets
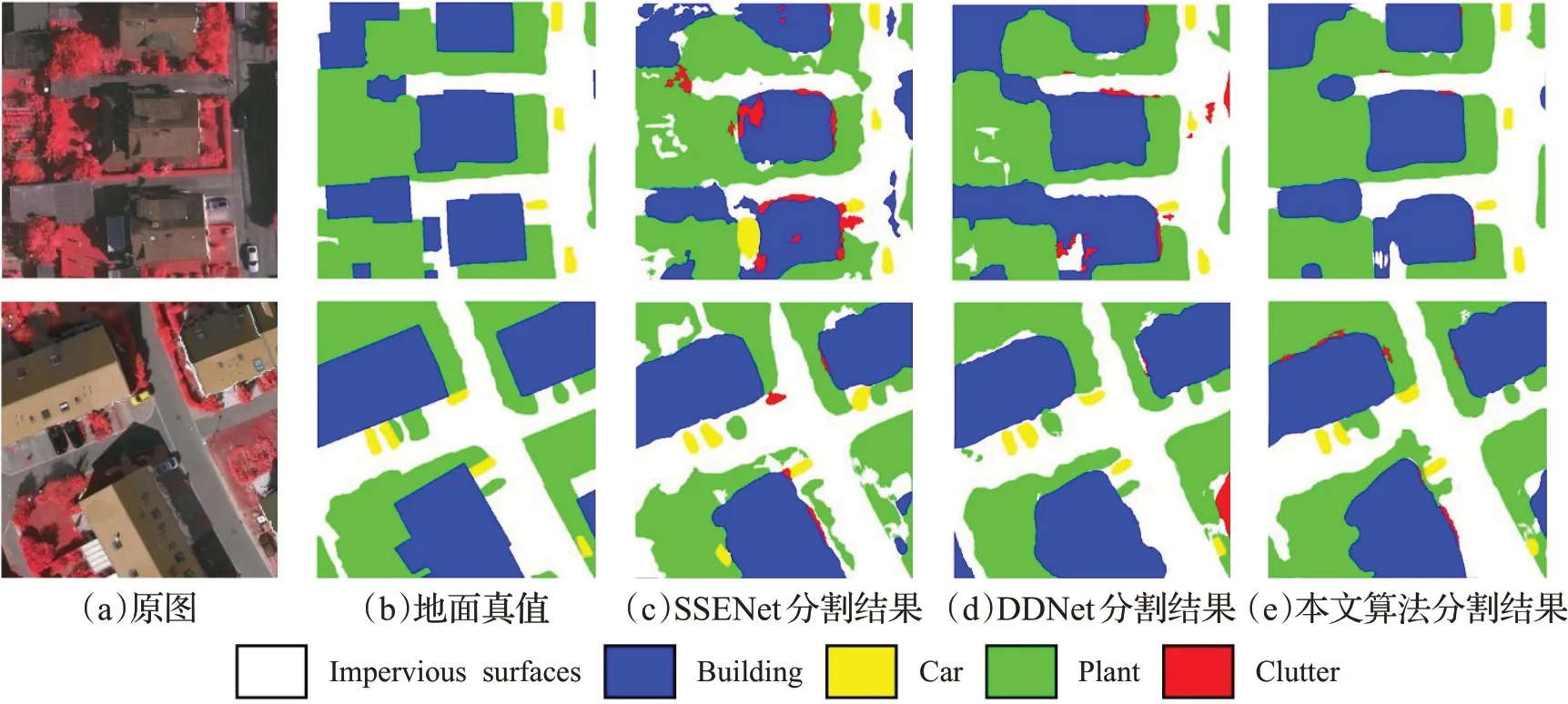
图7 Vaihingen数据集语义分割结果对比Fig.7 Comparisons of semantic segmentation results on Vaihingen datasets
(1)消融实验
为验证特征空间边缘增强模块的伪分割掩码对最终分割精度提升的作用,本文利用输出空间边缘增强模块生成的伪分割掩码训练了Deeplab-v2(使用ResNet-101主干),扩展了两阶段框架(EEA-two),进行了消融实验对比。
通过表3、4中本文单阶段WS-EEA及两阶段的EEA-two消融对比可以看出,在Potsdam数据集上本文方法比基于相同伪掩码的两阶段方法(EEA-two)的MIoU分数提升了0.85个百分点,OA精度提升了1.65个百分点;在Vaihingen数据集上MIoU提升了1.06个百分点,OA精度提升了2.08个百分点。通过纵向对比实验可以证明本文提出的输出空间边缘细化模块不仅可以降低网络的繁琐度,对于最终分割精度的提升也是有效的。

表3 Potsdam数据集各算法分割结果Table 3 Several methods’quantitative evaluation of semantic segmentation results on Potsdam datasets单位:%
(2对比实验
为证明本文端到端弱监督语义分割方法可以在降低网络训练繁琐度的同时,仍然保持较高分割精度,本文与当前较好的弱监督语义分割方法[27]进行了对比。
通过表3、表4的定量对比可以得出,与多阶段弱监督语义分割方法的比较,本文算法在Potsdam和Vaihingen两个数据集上均优于SSENet,其中Potsdam数据集上MIoU及OA分别提升了4.18、2.71个百分点,在Vaihingen数据集上分别提高了4.2、5个百分点。在Potsdam城市数据集上,虽然本文方法的MIoU分值比DD-Net网络低了0.95个百分点,但是本文的OA精度高于DD-Net,且DD-Net需要三个训练步骤,模型繁琐。

表4 Vaihingen数据集各算法分割结果Table 4 Several methods’quantitative evaluation of semantic segmentation results on Vaihingen datasets单位:%
与单阶段语义分割方法的对比中,本文方法与全监督方法还是有一定的差距。但是,在Potsdam和Vaihingen两个数据集上本文算法比单阶段的弱监督语义分割方法TransferNet均有提升,其中MIoU及OA分数在Potsdam数据集上分别提升了1.77、4.35个百分点,在Vaihingen数据集上分别提升了1.49、1.39个百分点。
此外通过图6、图7的定性分析对比可以看出,本文方法可以很好地分割出遥感图像中的小目标,例如小汽车及小的建筑物。对于较大的目标,分割也较为准确,并不存在大面积的过分割问题,每个目标分割出的结果较为连续完整。
综上,通过以上定量分析及定性分析,本文算法对于伪标签质量的提升,及单阶段弱监督语义分割结果精度的提升都达到了不错的效果。
3 结束语
本文针对遥感图像地物复杂、目标尺寸不一的特点,打破传统弱监督语义分割方法的多阶段训练步骤,提出一种端到端的遥感图像弱监督语义分割方法,主要结论如下:
(1)在ISPRS两个城市数据集上的实验结果表明,本文方法相较于多阶段方法及最新的单阶段方法在MIoU、OA提取指标上均表现优异,可以很好地分割出遥感图像中的小目标,达到多类别分割效果,性能显著。
(2)相较于基于CAM的多阶段弱监督语义分割方法,本文模型简单易用,大大降低了训练的繁琐度,且不会产生过大的GPU占用,为解决端到端弱监督语义分割问题提供了新的研究思路。
(3)本文特征空间特征增强模块进一步扩展到两阶段方法中,对于伪分割掩码质量的提升也具有促进作用。
本文方法在对比实验中表现优异,但特征空间边缘强模块扩展到两阶段方法的分割结果仍然有上升空间,且与全监督方法相比仍然有较大差距。考虑到弱监督本身监督信息不足,本研究未来会考虑从底层网络入手,在CAM的初始获得过程中提升浅层信息可靠性,即考虑特征图中的每个空间位置信息。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
计算机研究与发展(2022年1期)2022-01-19
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
文苑(2015年9期)2015-09-10
长江学术(2015年1期)2015-02-27
新课程学习·中(2013年3期)2013-06-14
中学数学研究(2008年3期)2008-12-09
数码影像时代(2006年5期)2006-05-29
