
联合神经协同过滤与短期偏好的课程推荐模型
2022-10-15 09:03:00罗琨杰孙华志
天津师范大学学报(自然科学版) 2022年5期
罗琨杰,张 珑,杨 波,孙华志
(天津师范大学计算机与信息工程学院,天津 300387)
随着互联网的发展,在线资源极易出现信息过载,相关领域通过逐渐完善个性化推荐算法解决该问题[1].在教育领域,随着教育信息化和素质教育的提出,实现智能“因材施教”形态下的个性化课程资源推荐越来越重要.课程推荐属于典型的数据挖掘项目,旨在挖掘出学习者潜在的个性化学习兴趣[2],然后提出下一步的学习建议.课程推荐常用的算法通常是从其他类型的推荐模型中迁移过来的(如电影、音乐、电子商品等的推荐).一个通用的课程推荐模型包括基于学习者的协同过滤[3-4]、基于课程的协同过滤以及利用矩阵分解[5-6]和内容感知[7]来捕获学习者的个性化潜在学习兴趣的方法.由于课程学习时间长(几周甚至更长)且具有学习顺序,因此这种长期学习行为导致课程推荐的数据形成了区别于电影、音乐等数据的独有特点,表现出的数据稀疏性程度更深.因此,大多数研究者在设计课程推荐系统时常利用许多其他辅助信息[8]进行主题建模[9]以弥补学习行为的不足.考虑到学习顺序的问题,文献[10]提出一种计算课程先验关系的推荐算法,用以构建更好的课程学习推荐顺序.为更好地获得课程的先验关系,文献[11]引入其他辅助信息用于计算先验关系:在一种混合的学习环境下设计一种基于关联规则的课程推荐系统.这些方法虽然在推荐性能上有一定提升,但需要大量额外的辅助信息数据和资源.
近年来,越来越多的推荐算法基于深度学习[12-13]设计模型.文献[14]提出的分解课程相似度模型(factored item similarity model,FISM)将学习者的历史学习行为表示为嵌入向量,再利用学习者两两嵌入向量之间的内积来建模学习者的相似度.而在学习者的课程学习中,想从每门课程中获得的知识是不同的,学习行为的权重也不同,而FISM在目标课程与历史课程的计算中将所有的历史行为看作同等重要,将其迁移到课程资源推荐上会限制模型的表达能力,也不利于个性化学习兴趣的获取.为解决该问题,文献[15]提出一种基于神经注意力项目相似的推荐模型(neural attentive item similarity model,NAIS).该模型是融合注意力机制的神经协同过滤推荐算法,通过区分学习者每个历史行为的重要性,给每个历史行为都赋予注意力系数[16-18]作为历史行为的贡献度来进行学习者的偏好计算,NAIS可以看作是FISM的一种增强模型.而学习者的学习兴趣可能会随着时间的推移而改变,采用以上算法获得的结果是一种当时时刻的历史贡献值,而不是学习者动态兴趣变化赋能的动态兴趣偏好贡献.模型将各时刻的历史行为都视为静态的,无法平衡学习者历史行为静态偏好和近期动态化偏好间的关系,只能获得静态化的历史学习行为贡献值,致使最终的推荐性能欠佳.
本文提出一种联合神经协同过滤与短期偏好的课程推荐模型,利用短期偏好嵌入与历史行为嵌入获得动态兴趣赋能的历史行为嵌入的新表示,利用新嵌入表示更新计算学习者历史行为的动态化贡献度,重构个性化动态学习兴趣,以提高推荐性能.
1 模型构建
本文模型的主要思想是通过利用学习者短期学习行为的动态偏好,将其与学习者各时刻的历史行为嵌入融合,形成重构的个性化历史行为嵌入表示,构建动态兴趣赋能的历史行为的新贡献度,最后利用算法融合后的损失函数对模型进行训练,获得更准确的历史新贡献度和个性化偏好来进行课程推荐.本文推荐模型的整体流程如图1所示.

图1 推荐模型流程Fig.1 Flow of recommended model
将学习者表示为集合U={u1,u2,…,um},将课程集合表示为C={c1,c2,…,cn},学习者的课程学习注册行为表示为矩阵Rm×n,rij∈{0,1},学习者ui对课程cj的注册行为视为学习者的历史行为,标记为rij=1,反之标记rij=0.令x1,x2,…,xt为学习者对课程注册的历史行为序列,其中xt为学习者在时刻t的注册行为.推荐系统的最终目标是要给学习者推荐时刻t+1的目标课程ci,而该目标课程ci来自于学习者未注册过的课程序列候选集.
1.1 神经协同过滤历史贡献计算模块
该模块以历史行为序列x1,x2,…,xt和目标课程ci作为输入,采用基于学习者注册过的历史课程与未注册过的目标课程的相似度计算的协同过滤算法来拟合数据.利用模块融入的注意力机制将输入值输入到注意力网络计算学习者的历史行为的权重值,以获得不同学习者不同历史学习行为的历史贡献度.该过程需要将输入序列处理为嵌入的形式,具体处理方法是将历史行为序列表示为Multi-hot的编码方式,在获得基础的历史行为表示后输入线性嵌入层,获得最终的历史行为的嵌入序列q1,q2,…,qt.将目标课程利用One-hot的编码方式得到目标课程的稀疏向量表示,再输入到线性嵌入层后降维得到稠密向量pi,表示目标课程的嵌入[19].最后利用学习者的各个行为特征嵌入与学习者的目标课程嵌入作为注意力网络的输入,获得学习者每个历史行为的一个标量值作为输出,表示贡献度.该模块涉及不同历史行为的权重问题,因此引入softmax函数归一化权重计算神经注意力相似度,获取历史行为的贡献值[15].基于课程的历史行为的贡献值aij表示为
其中:f为使用一个多层感知机(multilayer perceptron,MLP)进行计算的函数,且以Relu为激活函数;R+u为学习者曾经注册过的课程集合;β为针对某些过度活跃的学习者获得过度惩罚的softmax分母的平滑系数,β∈[0,1],当β=0.5时的推荐效果最佳.上述利用神经协同过滤历史贡献计算的整体框架结构如图2所示.

图2 神经协同过滤历史贡献计算框架Fig.2 Neural collaborative filtering framework for computing historical contributions
1.2 学习者短期偏好计算模块
本文基于双向长短时记忆网络(BI-LSTM)[20]构建短期偏好模型,模型结构如图3所示.

图3 捕获短期偏好的模型结构Fig.3 Model structure for capture short-term preference
该模型网络以历史行为序列作为输入,为了获得近期的动态性兴趣,选用最近的部分历史行为序列,下文的实验部分中说明了选取最近3次的历史行为序列(xt-2,xt-1,xt)获得的性能最佳.隐藏向量的特征状态为

BI-LSTM包含左右序列上下文的2个子序列,分别表示前向网络和后向网络所获得的高层次特征状态,因此学习者在时刻t的历史行为序列产生的包含上下文信息的隐藏向量的特征状态ht表示为
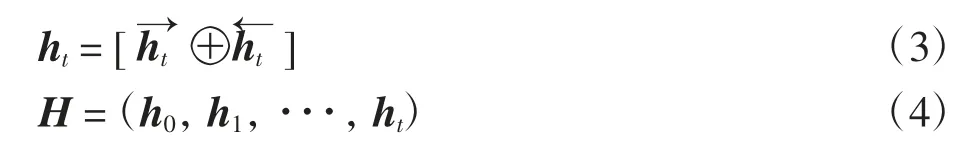
其中:ht∈Rd,H∈Rd×t,d为学习者历史行为嵌入的维度.之后,利用自注意力机制来学习短期偏好S,其过程为

其中:tanh为特征状态的激活函数;w为训练获得的超级参数矩阵;α为由自注意力机制获得的每个状态特征的权重向量.
1.3 模型的整体结构
为更好地平衡各时刻历史行为与近期动态性偏好,本文建构了一种融合短期偏好的动态性偏好行为的新表示,用以重构近期动态性偏好变化赋能的历史行为的新贡献度.模型结构如图4所示,通过γ控制融入的短期偏好S的比例后,分别与学习者在时刻1到t注册过的第j个课程的嵌入qj相乘,重构得到学习者动态兴趣赋能的新嵌入表示qsj,将其与目标课程嵌入输入到注意力机制模块中,建构学习者历史行为的新贡献度aisj.将该新贡献度作为学习者历史行为的权重值,重新量化不同历史学习行为的重要性,其形式为
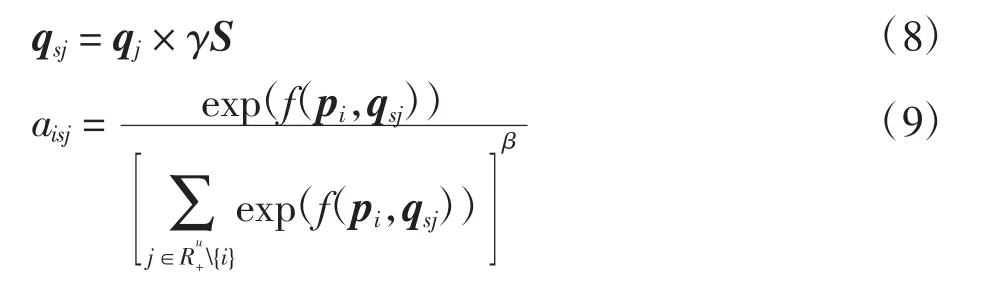

图4 模型的整体结构Fig.4 Overall structure of the model
当学习者的历史行为处于负面状态时(学习兴趣已改变),通过融合短期偏好后获得的qsj向量会变得稀疏,弱化了新贡献度aisj的计算,故短期偏好的引入对各时刻历史行为与近期兴趣起到平衡作用;当处于理想状态时(学习兴趣未改变),通过融合短期偏好后获得的qsj向量会变得更加稠密,强化了新贡献度aisj的计算,此时短期偏好将起到辅助作用.这2种情况下模型都能获得近期动态兴趣赋能的偏好.
获得新贡献度后,利用基于课程的协同过滤进行课程推荐.

1.4 模型学习
为获得更好的推荐性能,需要在融合后的模型中选择特定的目标函数优化模型.整个推荐问题中的隐式反馈被视为二分类问题,故选用二元交叉熵函数作为损失函数的一部分.同时,为更好地匹配模型中引入的短期偏好,加入负对数似然函数,联合训练整个模型.训练中将学习者的历史行为序列看作正样本,从该学习者未注册的样例中随机采样99个作为负样本,因此最小正则化日志损失函数定义为

其中:N为训练实例总数;σ为激活函数;ti为One-hot表示的一个正确标记数据;R+、R-分别为正、负样本集合;λ为L2正则项的权重参数,用于防止过拟合.
2 实验与分析
2.1 数据集及参数设置
选用来自学堂在线真实的MOOC数据集进行实验.选择学习者在2016年10月至2018年3月之间的历史注册课程的有效行为作为学习行为的历史记录,数据集中用户数为82 535,课程数为1 302,互动数为458 454,数据集稀疏度为99.57%.
由于实验引入了短期偏好并且数据集的稀疏度高达99.57%,因此对数据集进行清洗过滤处理,将历史行为长度低于3的记录过滤.考虑到行为序列相对较少的情况,按照时间线对数据集进行划分,2016年10月至2017年12月的数据作为训练集,2018年1月至3月的数据作为测试集.
采用top-K推荐中广泛使用的评估方法,即以基于召回的命中率(hit ratio,HR)和基于位置预测的归一化折损增益(normalized discounted cumulative gain,NDCG)作为性能评估指标.
采用Python3和TensorFlow框架实现模型构建并在Linux系统下运行实验.模型训练参考已有的相关文献[15,20]对部分参数进行设置,设置学习率为0.5~0.000 1;嵌入维度为64、32、16、8,依次取值实验;迭代次数为15;丢弃率为0.75;Batch_size为128;γ为0.2.
2.2 实验结果与分析
为验证所设计模型的推荐性能,将本文模型与常用模型FISM[14]、MLP、NeuMF(neural matrix factorization)和NAIS[15]进行比较.MLP模型利用多层感知机对学习者和课程学习行为数据进行处理,从中获得评分函数以学习相关课程被选择的概率,从而进行课程推荐[21].NeuMF模型通过融合矩阵分解和多层感知机,建模复合矩阵分解与多层膜耦合课程排序,属于神经协同过滤推荐模型,是神经协同过滤算法中使用最为广泛的模型之一[21].
在相同的环境下进行实验,5种模型的HR和NDCG实验结果见表1.由表1可见,本文模型与另外4种模型相比,2个评价指标都有不同的增长,推荐性能得到一定提升.

表1 课程推荐性能比较Tab.1 Performance comparison of course recommendation
5种模型的HR和NDCG随迭代次数变化的情况见图5.由图5可见,5种模型的HR和NDCG随迭代次数的增加都呈先上升后下降再稳定的趋势,本文模型的指标在后期迭代中一直处于稳定的状态,而NAIS和FISM的2个指标都有一段明显的下降趋势,这是因为在迭代后期,由于MOOC数据集的稀疏性使得模型收敛较快,且神经网络中的权重和参数更新次数增多造成了过拟合,这说明本文模型的鲁棒性较强.NeuMF和MLP在迭代后期较NAIS和FISM稳定,但性能整体上低于本文模型.因此本文模型更适合于具有高度稀疏性的数据集的推荐任务.

图5 5种模型2个指标随迭代次数的变化Fig.5 Changes of two indicators of five models with the number of iterations
实验对比了使用LSTM和BI-LSTM的模型性能,HR和NDCG见图6.由图6可见,在迭代前期,LSTM和BI-LSTM的HR基本一致,LSTM的NDCG低于BI-LSTM,但相对稳定,随着迭代的增加,LSTM的2个指标呈现下降趋势.说明LSTM虽然在一定程度上能提升推荐性能,但在面对具有高度稀疏性的数据集时,稳定性低于BI-LSTM,因此,使用BI-LSTM在课程推荐中捕获学习者的短期偏好后融入贡献度计算模型更加适合.

图6 使用LSTM和BI-LSTM 2个指标随迭代次数的变化Fig.6 Changes of two indicators using LSTM and BI-LSTM with the number of iterations
由于模型使用BI-LSTM来获取短期偏好以重构学习者个性化学习偏好,因此选取的历史长度也对模型性能有一定影响.选取历史长度为1,2,…,6,本文模型和NAIS的HR和NDCG见图7.由图7可见,本文模型的HR和NDCG随历史长度增加呈先上升后下降的趋势.历史长度为3时的推荐性能最佳,这是因为融入的短期偏好起到平衡和辅助的作用,历史长度过小不利于短期偏好的捕获且构造的损失函数也不利于模型训练,历史长度过大又会引入其他噪声信息,也不利于模型的训练.

图7 历史长度对2个指标的影响Fig.7 Influences of history length on two indicators
本文模型旨在重构个性化学习偏好以平衡时刻偏好来更新计算历史贡献度,但时刻偏好不是完全片面、不可利用的偏好,将短期偏好融入神经协同过滤历史贡献度计算中时,需要选择合适的比例才能获得更好的推荐结果.选择γ为0.1,0.2,…,0.9,本文模型和NAIS的HR和NDCG见图8.由图8可见,本文模型的2个指标随γ的增大呈现波动趋势.当γ=0.2时的实验结果最好,这是因为针对数据集本身的特点,只需取相对较小比例即可获得较好的性能,取值过大反而会限制模型的表达能力且弱化短期偏好的平衡和辅助作用.

图8 融入短期偏好的权重比例对2个指标的影响Fig.8 Influences of weight proportion with short-term preference on two indicators
3 结语
获取历史行为的贡献度是课程资源推荐的一种重要应用方式.本文模型通过捕获学习者近期的动态兴趣偏好,不仅可以平衡兴趣发生变化时历史行为的静态偏好问题,还能在兴趣未改变时辅助计算偏好,获得学习者更准确的个性化学习偏好表示,建构出计算动态兴趣赋能的历史行为的新贡献度,能够增强课程推荐模型的鲁棒性,使推荐结果相对稳定.实验结果表明,本文模型相比其他方法,在MOOC数据集上获得了一定比例的性能提升.在未来工作中将尝试利用强化学习、知识图谱等技术以获得各时刻偏好与个性化动态学习偏好的映射关系,以进一步提升推荐性能.
猜你喜欢
学生天地(2020年15期)2020-08-25 09:22:02
文苑(2020年4期)2020-05-30 12:35:12
意林·少年版(2020年2期)2020-02-18 11:14:52
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27 01:33:48
中国生物医学工程学报(2019年4期)2019-07-16 08:04:10
新闻传播(2018年12期)2018-09-19 06:27:10
海外华文教育(2016年4期)2017-01-20 08:22:24
汽车与新动力(2016年6期)2017-01-04 10:50:48
电力自动化设备(2015年4期)2015-09-28 02:42:54
中国卫生(2015年1期)2015-01-22 17:20:15
