
融合上下文信息的混合神经网络序列推荐模型
2022-10-15 01:00冼海锋
小型微型计算机系统 2022年10期
冼海锋,沈 韬,曾 凯
(昆明理工大学 信息工程与自动化学院,昆明 650500)
(昆明理工大学 云南省计算机技术应用重点实验室,昆明 650500)
E-mail:xianhaifeng@stu.kust.edu.cn
1 引 言
现如今无论是与我们生活密切相关的电商应用,还是当下正大热的短视频应用,他们流行的背后是运用了推荐系统.目前用户在使用这些应用时产生大量的隐反馈[1]行为(例如浏览、点击、收藏、加入购物车、分享等行为),但传统协同过滤[2,3]算法利用这些数据存在缺陷,所以序列推荐就成为使得这些数据价值最大化的关键技术.
序列推荐为了捕获用户的动态偏好,通常做法是对过去一段时间内用户与项目交互的序列进行建模.如传统序列推荐中的马尔科夫链模型就是其中的典型应用.马尔科夫链将从序列建模中所捕获到的信息用于下一交互预测,但是马尔科夫链模型[4]存在一个明显的弊端,即是它认为当前的交互喜好仅仅与用户最近的一个或者几个交互行为有关.其中一阶马尔科夫链模型认为用户当前的偏好仅仅与用户最后一次的序列行为有关,而高阶马尔科夫链模型[5]假设用户当前的交互偏好与用户最近几次的序列行为相关.只能捕捉用户近期偏好,而忽略了用户长期偏好是低阶马尔科夫链和高阶马尔科夫链模型的共同问题.另一种比较常用的序列推荐模型就是基于分解机[6]的方法,它主要是把用户-项目之间的交互编码成两个对应的低维度矩阵.此外Wang等人[7,8]的工作也是利用了概率矩阵分解推荐算法,解决了传统矩阵分解存在的数据稀疏问题.贝叶斯个性化排序(BPR-MF)[9]模型方法通过随机梯度下降来优化pairwise目标函数,很好地捕获到了用户的偏好.最具代表性的基准算法FPMC[10]可以很好地为下一物品实现推荐预测,因为其兼具了马尔科夫链模型与基于矩阵分解模型的优点.基于矩阵分解的算法模型存在的弊端是它们往往是针对低阶的用户-项目交互进行建模的,并没有考虑捕获高阶交互的转换模式.
随后在推荐系统领域,深度学习技术得到研究者们的大力追捧,无论在工业界还是学术界都占据了极为重要的地位.循环神经网络(RNN)是最早被应用于序列推荐系统的深度学习技术之一.相比于传统的序列推荐技术,基于RNN的序列推荐在处理一个会话内的序列数据时,精准建模交互序列的项目间依赖关系,Hidasi等人[11]的工作就是其中的典型.由于传统序列推荐模型和基于循环神经网络的序列推荐技术存在只能建模用户-项目交互序列当中的点依赖关系问题,为此Tang等人[12]率先在序列推荐领域引用卷积神经网络来建模用户-项目交互序列中的跳过关系以及项目间的联合关系.另外一个在序列推荐中比较热门的深度学习技术是注意力机制,它可以在一定程度上解决传统序列推荐、基于CNN的序列推荐存在的交互序列有噪音的情况.
当前,传统序列推荐方法和基于深度学习的序列推荐方法存在着以下两点问题:
1)已有方法中大多只考虑项目ID的影响,而忽略了其他特征的影响,如用户与项目上下文信息特征,即还没有考虑到用户行为上下文信息或者项目上下文信息.
2)现有一些研究方法在建模时通常是假设相邻之间的项目存在关系,但是交互序列中相邻的项目不一定存在关系,从而存在着不能建模非相邻项目之间关系问题.
为解决以上问题,本文提出一种并行结构的混合神经网络模型,其并行结构由卷积神经网络与自注意力机制构成.主要贡献如下:
1)本文提出了融合项目与用户上下文信息的混合神经网络模型,该网络模型包含了以下模块,分别为嵌入编码层、卷积神经网络模块和自注意力机制模块.本文方法实现了同时建模用户动态偏好以及用户与项目交互的上下文信息,解决了当前已有研究方法忽略了上下文信息特征影响的问题.
2)本文方法中卷积神经网络模块结合pairse编码方法,该方法将用户与项目交互序列中的任意两个项目成对编码成张量.最后提取张量特征的工作由卷积神经网络完成.所以本文方法可以学习到交互序列的项目之间关系,这解决了现存研究方法不能建模交互序列中非相邻项目的问题.
3)在Movielens-1m与Tmall数据集上,本文分别建立了实验.结果表明本文方法比基准方法Caser[12]、CosRec[13]在Prec@5、Recall@5、MAP、NDCG@5、HR@5等推荐评价指标上都要好.本文方法在Movielens-1m数据集上MAP获得了6.5%的提升,Precision@5提高了3.5%,Recall@5提升了7.8%,F1@5提升了7.1%.Tmall数据集上,本文方法在MAP提高了3.2%,Precision@5提高了2.8%,Recall@5提升了3.3%,F1@5提升了3.1%.
2 相关工作
2.1 基于卷积神经网络的序列推荐
卷积神经网络将用户与项目交互序列当作“图像”,通过卷积层提取这些“图像”的特征.这些学习到的局部特征再被用于后续的序列推荐.与循环神经网络相比,卷积神经网络的优势在于其不需要像基于循环神经网络序列推荐中的交互序列相邻物品必须相互独立的假设.但基于卷积神经网络的序列推荐缺点是不能学习到用户的长期偏好,这是由卷积滤波器大小限制决定的.
Tang等人的研究工作在基于卷积神经网络序列推荐中开启了一个新的研究点.他们的创新点是将用户近期的行为序列视作“图像”,然后采用垂直和水平卷积层提取其特征.这在一定程度上解决了Top-N序列推荐模型问题.Yuan等人[14]针对Tang等人研究工作还因卷积网络结构简单存在着不能建模复杂关系与长期依赖问题,引入了一种简单但十分有效的卷积生成网络模型.该模型是由带1D膨胀卷积的掩码滤波器和剩余块组成的,能够同时从短期和长期项目依赖中学习高阶表征.此外Yan等人也针对Tang等人的研究工作进行了更进一步的研究,提出了基于2D卷积神经网络序列推荐模型.这个模型框架的工作大体流程是先把项目的序列编码成一个三维张量,通过2D卷积从张量中学习局部特征,最后再以前向传播的方式汇聚成高阶交互.
2.2 基于注意力机制的序列推荐
由于注意力机制具有学习不同东西之间权重的特点,因而在序列推荐中被用于学习交互序列中不同项目对用户的重要程度关系,从而实现更切合实际的下一可能交互项目推荐.而Kang和McAuley等人[15]为了解决马尔科夫链模型存在的在密集数据集性能不太好和RNN模型在稀疏数据集推荐性能不好的问题,提出了一个在稀疏数据集和密集数据集表现性能都不错的自注意力序列推荐模型.该模型可以在每个时间步中对之前的项目自适应地分配权重,通过这样的方式自注意力序列推荐模型一方面可以像RNN那样从整个序列行为中捕获序列信息的长期依赖.同时另一方面也可以像MC那样只是根据之前的一小部分项目行为来生成预测.简而言之,自注意力序列推荐模型同时兼具了RNN和MC的优点.但有些研究工作仅考虑了项目级别上转换模式,忽略了项目特征级别转换模式的影响.因此Zhang等人[16]在他们的研究工作基础上,提出项目特征级别的深层注意力网络(FDSA)模型.具体来说,FDSA这个改进模型先是通过香草注意机制用不同的权重把项目的各种异构特征整合到一个特征空间.在这之后,FDSA分别对项目级别序列和特征级别的序列应用自注意力机制.这一步主要是为了捕获项目级别和特征级别的转换模式.最后将上述两个级别的输出输入到全连接层用于生成推荐.
Wang等人[17]提出的双重最相关注意网络也是分成了项目级别和特征级别.不过他们先是把连续的时间特征信号编码成离散特征,然后分别实现项目级别注意和特征级别自注意.他们是通过项目级别注意把不相关的项目过滤掉,从而减小序列大小.而通过特征级别的自注意力网络可以学习到项目不同特征的权重,这对精准建模用户偏好起了至关重要的作用.当然自注意力网络的作用远不止于此,如有些研究工作[18]提出的多阶注意排序模型.该模型同时把单个级别的和联合级别的项目交互整合到偏好引用,这可以把通用的和序列模式联合起来生成推荐.还有一些研究工作[19]也是利用自注意力网络,但他们主张将用户交互序列视为有不同时间间隔的序列,而且不同时间间隔对于预测下一项目的影响是不一样的.因此他们展开了基于时间感知自注意力机制的推荐模型研究工作.该研究工作不仅考虑到了自注意力网络序列推荐模型中项目的绝对位置,还兼顾了项目之间的相对时间间隔,这就很好地用来预测用户后续可能的交互项目.
但是以上提及的这些模型方法都存在着问题.
首先现有工作在构建模型并没有考虑到项目与用户行为上下文信息的影响.
其次现有方法大多存在着没有充分利用用户与项目交互序列中非相邻项目之间的关系问题.
最后为了解决现存工作所存在的问题,本文提出了一种融合上下文信息的混合神经网络推荐模型.该模型同时利用了卷积神经网络和自注意力机制的优势,其中卷积神经网络被用来建模用户的近期偏好、自注意力机制则被用来建模项目上下文信息或者用户行为上下文信息.
3 本文方法
本文模型方法的框架结构如图1所示.其中Item1、Item2、…、ItemL表示为任一用户所有历史交互的项目嵌入序列,而Context1、Context2、…、ContextN表示为用户交互历史项目对应项目与用户上下文信息.模型主要有以下几部分组成,即嵌入层模块、卷积神经网络处理模块、自注意力机制模块、全连接层模块.整个模型的流程如下:1)在嵌入层模块中把用户数据编码成向量、用户-项目交互历史项目数据编码成项目序列向量、将交互项目种类数据编码成矩阵;2)卷积神经网络(CNN)负责处理用户嵌入、用户-项目交互序列信息,解决用户的短期偏好问题;3)自注意力机制负责处理用户交互项目中上下文信息的种类序列数据,聚合得到上下文信息对偏好的权重;4)结合建模得到的所有偏好与上下文信息权重,实现用户在交互序列中下一可能交互项目推荐.
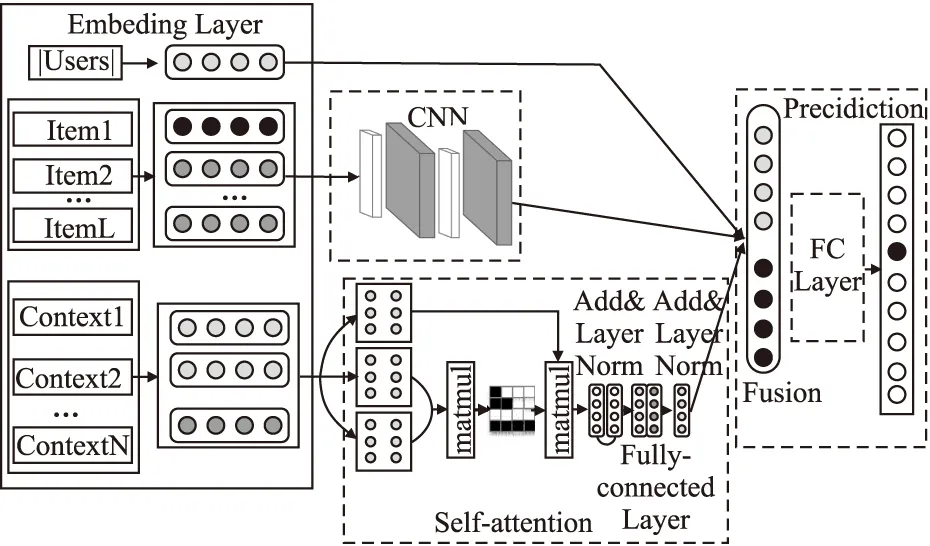
图1 本文模型的框架结构图Fig.1 Frame structure of the model
本文将U表示成所有的用户集,U={u1,u2,…,u|U|},|U|是用户的数量.全部项目的集合用I代表,I={i1,i2,…,i|I|},项目的全部数量为|I|.将S表示用户与项目交互的集合,S={s1,s2,…,s|s|},这里的Si∈I.本文将通过训练用户交互的前n个序列S,预测用户u的下一交互项目.在本部分,将通过嵌入编码层、卷积神经网络模块、自注意力网络模块、全连接层以及预测层对本文提出的方法进行详细的介绍.
3.1 嵌入编码层
每个用户u所交互的项目数量不一样是很常见的,所以本文将用户与项目交互的序列长度全部固定为指定的长度n.对于用户u交互的序列长度少于长度n的序列,在用户交互序列的左边进行零填充处理.对于那些超出指定长度n的用户u历史行为序列,只保留用户最近交互过的n个项目.本文采用pairse编码方法将用户编码成用户嵌入矩阵EU∈R|U|×d,同时将项目编码成项目嵌入矩阵EI∈R|I|×d.
3.2 卷积神经网络模块
计算机视觉和自然语言处理领域在卷积神经网络应用方面取得了巨大进展,故本文为能捕获到用户与项目交互的高阶序列关系也采取了CNN.
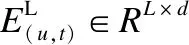
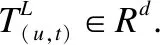
3.3 自注意力网络模块
由于自注意力网络模块需要处理的是带有时间先后顺序关系的序列输入矩阵Ec∈Rn×d,而自注意力网络不像循环神经网络以及卷积神经网络可以获取到之前交互过项目的位置信息,故而需要自注意力网络模块在序列输入矩阵再加上位置编码矩阵P∈Rn×d.最终的自注意力网络输入矩阵如下所示:
(1)
文献[20]中的缩放点积注意力(scaled dot-product attention)公式定义如下:
(2)
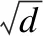
Fh=SA(Fc×WQ,Fc×WK,Fc×WV)
(3)
这里WQ,WK,WV∈Rd×d的映射矩阵.由于多头注意力具有用不同位置表示子空间信息的优势,所以其比缩放点积注意力更为灵活,实现效果更好.故本文自注意力网络模块应用了多头注意力,多头注意力定义如下所示:
(4)
(5)
Mh=LayerNorm(Mh+Fc)
(6)
OTf=ReLU((MhW1+b1)W2+b2)
(7)
OTf=LayerNorm(Mh+OTf)
(8)
其中W*,b*为模型的参数.为了简便起见,本文定义自注意力网络块如下所示:
OTf=SAB(Fc)
(9)
在经过第1个自注意力网络块之后,OTf把用户u之前交互过的所有特征信息汇聚起来.在基于Fc的另一个自注意力网络块之后对于学习复杂的序列变换会更有帮助,具体定义如下:
(10)
当p=0时,OTf=Fc.
3.4 全连接层
全连接层为了可以同时捕获用户交互序列中的项目特征以及品牌信息、用户交互行为等上下文信息特征,将卷积神经网络模块的输出和注意力网络模块的输出拼接起来.
(11)
其中W∈R3d×d,b∈Rd.我们将用户嵌入Pu与Ocf拼接起来的目的是获取用户u长期偏好,然后映射到|I|个节点的输出层.
(12)
其中W′∈R|I|×2d,b′∈R|I|分别为输出层的权重矩阵和偏置项.将输出层的y(u,t)表示用户u在时间戳t与项目i交互的概率.
3.5 模型训练及参数设置
本文采取了二值交叉熵损失函数作为目标函数:
(13)
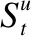
本文模型在训练过程中使用的操作系统为Ubuntu 18.04,CPU为Intel(R) Xeon(R) Gold 5120 CPU @2.2GHz,GPU为Tesla V100,开发语言为Python3.7.9,深度学习框架为Pytorch1.7.0.本文模型是由4层卷积神经网络与1层自注意力机制网络组成,其训练序列长度可取5、7、9、11等.一般来说序列长度取值较大时包含的信息相应也会较多,故该参数一开始增大会促进模型性能,但是逐渐会趋于稳定.模型其他超参数具体设置如表1所示.
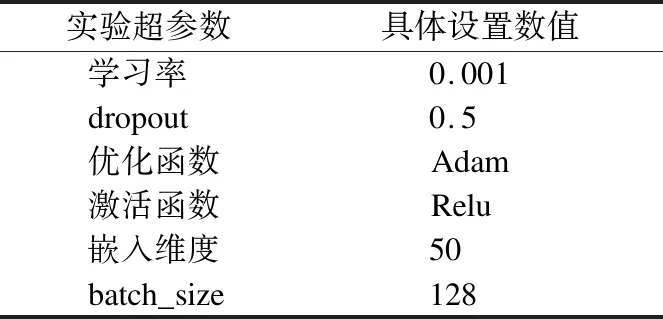
表1 超参数设置情况Table 1 Situation of setting hyperparameter
4 实验结果与分析
4.1 数据集
本文使用Tmall和Movielens-1m作为实验的数据集,这两个数据集是推荐系统领域常用的公开数据集.Tmall是用户在天猫商城特定时间内的行为数据集,该数据集囊括了21960个用户的记录.这个数据集在众多电商中最具代表性的,使得本文提出的研究算法可以很好地与应用场景对接起来.另外Movielens-1m数据集也是推荐系统中经常用到的数据集,它主要是提供了6000多个用户对3000多部电影评分的记录,以及电影种类的信息.本文对以上数据集特性进行了总结,具体如表2所示.
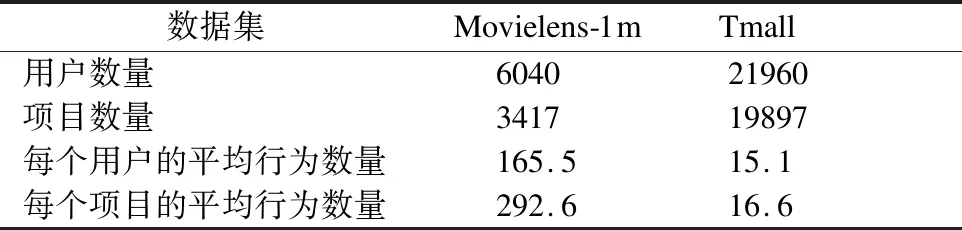
表2 数据集特性Table 2 Characteristic of dataset
参考Yan与Zhang等人研究工作的做法,本文将对以上两个数据集进行以下的处理.首先对于Tmall数据集,本文对数据集中那些被少于15个用户交互的商品进行了移除操作,即数据集只保留至少被15个以上用户交互过的商品.同时对于数据集中那些交互商品数量少于30个的用户也会被移除掉.本文在处理Movielens-1m数据集时只保留那些观看5部电影以上的用户以及被不少于5个用户观看过的电影.本文进行这些数据预处理是为了尽可能地使得本文提出的算法不被推荐系统中常见的冷启动问题所影响.在以上处理完成之后,本文将数据集划分为训练集、验证集、测试集.训练集以及验证集将由数据集中前80%的用户与商品或者用户与电影的交互行为组成,而测试集将由剩下的20%用户交互行为构成.其中训练集以及验证集用于训练本文提出的算法模型和找出本文算法模型最合适的模型超参数.测试集的功能则是用于检验提出模型的性能.
4.2 评价指标
本文通过推荐系统当下比较流行的几个性能指标来测试模型性能.这些指标是MAP、Prec@K、Recall@K、Hit@K、NDCG@K.目前主流算法K值一般是取1,5,10,由于数据集特性的关系,本文取了K为5作为主要比较依据.
4.3 比较方法
本文提出的模型将会跟Tang等人提出的Caser模型进行比较、Kang等人提出的CosRec模型等进行比较.
Caser:此基准利用了卷积操作来捕获高阶的序列依赖关系,在一定程度上解决了传统的低阶马尔科夫链模型算法存在的问题.该算法将用户与项目交互矩阵视作“图像”,从而通过垂直卷积与水平卷积获取交互序列变换模式.
CosRec:在Caser基准模型的基础上引入了pairwise编码方法,使得模型可以捕获用户与项目交互序列中联合模式.该算法不同于Caser模型,它将用户与项目交互的序列打成三维张量,更有利于后续使用灵活的卷积操作.
本文模型与待比较基准模型的实验结果已由表3所记录.通过表3的数据可以清晰地发现在Movielens-1m数据集上CosRec模型在评价指标Prec@5,Recall@5,F1@5以及MAP上均比Caser模型好.而我们提出的模型则是在Movielens-1m所有上述评价指标均取得了最好的性能效果.本文模型在Prec@5提升了3.5%,Recall@5提高了7.8%,F1@5提高了7.1%,MAP提高了6.5%.在Tmall数据集上的数据显示CosRec模型同样在各个评价指标上比Caser模型有所提升,但是在模型性能表现方面仍然是本文模型最好.本文模型与CosRec模型相比在Prec@5提升了2.8%,Recall@5提升了3.3%,F1@5提高了3.1%,MAP提升了3.2%.

表3 本文模型和基准模型的实验结果.其中每一列中的值越大代表模型性能结果越好,其中黑体为该列最大值Table 3 Experimental results of our model and benchmark.The larger value in each column is,the better the performance of the model is,and bold is the maximum value of the column
表4记录了本文模型在Tmall数据集取用户行为上下文信息、项目相关上下文信息以及时间上下文信息时的推荐性能,表4中的数据粗体加黑是最大值,数据越大表明本文模型在建模对应上下文信息时的性能最好.表4的数据表明在上下文信息为brand_id时,本文提出的模型性能提升最小.而当上下文信息取merchant_id时,本文提出模型的推荐性能得到最大的提升.在这些数据当中,其次较好的推荐性能是当上下文信息取action_type时的,这其实与现实生活中的事实是相符合的.因为用户在平时的购物过程中,相对于衣服品牌而言,用户会更偏好于收藏商家店铺.再就是用户在购物的时候,往往会产生不同行为类型,而这些行为类型可以很好的反应用户的偏好.例如用户点击商品、把商品加入购物车、点了收藏物品、购买物品完全表示了用户不同偏好程度.
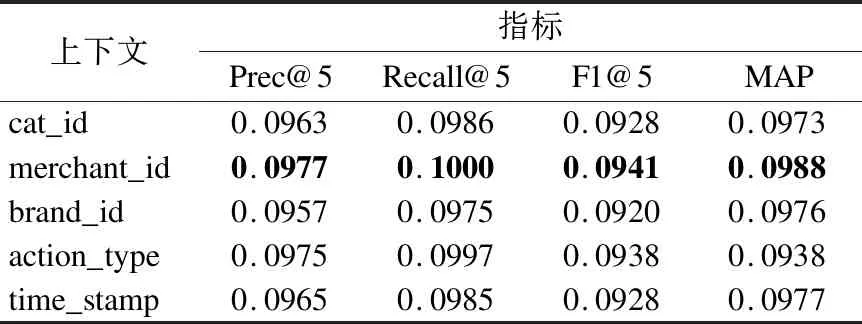
表4 Tmall数据集下本文模型取不同上下文信息时的性能比较Table 4 Performance comparison of our model with different context information in Tmall dataset
由表5的数据可以得知,本文方法在Movielens-1m数据集上采用Sigm激活函数几乎取得了最好的推荐性能.但是Relu激活函数的推荐性能与Sigm激活函数的性能相差无几.这与Relu激活函数在计算量比较大、网络深度比较深的特性是相符合的.由于Tmall数据集的数据比较大,所以本文综合分析之后,决定还是取Relu激活函数作为本文提出模型的激活函数.
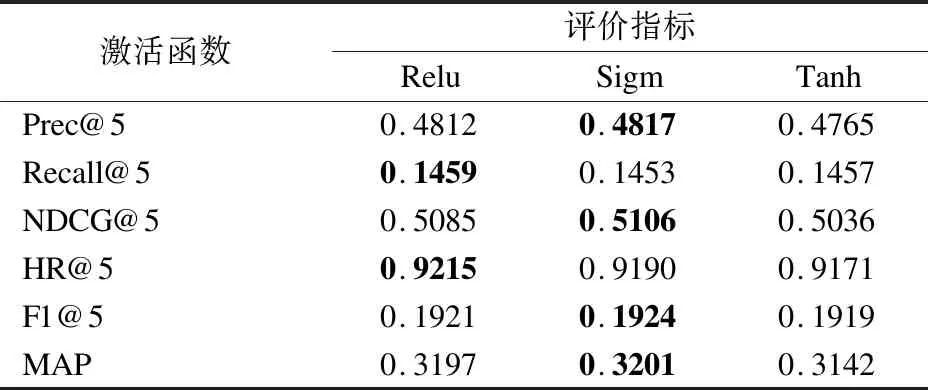
表5 Movielens-1m数据集中不同激活函数下的模型性能比较
本文还在Tmall和Movielens-1m两个数据集做了不同嵌入维度大小对模型性能影响的对比实验,具体结果如图2和图3所示.
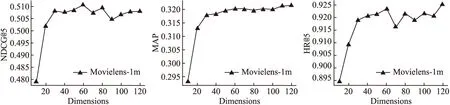
图2 本文方法在Movielens-1m数据集下不同模型维度大小的影响Fig.2 Influence of different dimension sizes on our method in Movielens-1m dataset
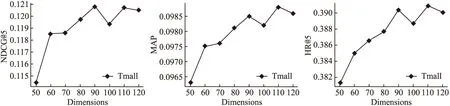
图3 在Tmall数据集下不同模型维度大小对本文方法的影响Fig.3 Influence of different dimension sizes on our method in Tmall dataset
根据图2的曲线数据特性,我们可以发现模型在Movielens-1m数据集上的推荐性能中的MAP一开始是随着嵌入维度Dimensions增大而提升的,但是当嵌入维度大于50之后,模型的性能提升速度就逐步変缓,趋于稳定.这说明在嵌入维度增大一定情况之后,模型就已经得到充分的训练了.
从图2在Movielens-1m数据集的实验数据可知,模型维度大小为50起时取得的推荐性能较好,故在Tmall数据集上的实验就直接从维度为50时开始.从图3能发现在Tmall数据集上一开始随着嵌入维度Dimensions增大,模型的推荐性能也是逐步提升,但是当Dimensions超过90之后,性能有点下降,接着再略微提升一点.这说明训练过拟合对于模型性能的提升有限,后面模型性能会逐渐趋于平稳.
5 结 论
本文提出了融合项目与用户上下文信息的混合神经网络推荐模型,该模型采用卷积神经网络模块提取用户与项目交互的序列特征,同时通过自注意力机制建模用户序列中的上下文信息特征.在与现实生活密切相关的两个数据集上进行实验,证明了我们提出的模型方法比基准模型更进一步促进了推荐性能的提升,取得了最好的推荐性能.
在后续工作,我们将进一步对项目与用户上下文信息组合起来对序列推荐的影响和用户的长期偏好问题进行研究.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
数理化解题研究·综合版(2021年11期)2021-12-22
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小学教学研究(2021年5期)2021-09-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
