
基于电价远程下装成功率及时效性预警模型分析
2022-10-15 08:39侯昝宇周良柱
微型电脑应用 2022年9期
侯昝宇,周良柱
(国网辽宁省电力有限公司, 辽宁, 沈阳 110006)
0 引言
电价远程下装是智能电表实现实时费控的重要技术途径,且在2010年开始在国内部分城市实现智能电表实时费控试点工作以来,至今国内绝大部分城市的城乡家用电表均实现了电价下装工作。但是,因为电价下装增加了抄核收系统的复杂性,容易带来诸多计费偏差,如故障计费产生零电费、叠加计费导致电费重复计算等。但绝大多数地市级供电公司均需要提供数十万甚至上百万家用电表计费服务,如果采用人工审计排查,很难在有效时间发现故障个案问题,所以在全面电价远程下装环境下,通过人工智能实现对电价远程下装后的计费问题进行时效性预警,成为当前电力大营销中抄核收大数据审计技术提升的重要研究创新点。
因为电价下装可采用费率下装和阶梯下装等不同技术路径,且多数供电公司在早期实验性操作中在不同阶段尝试了不同的技术路径,在并网运行过程中,如果存在个别区域未能做出及时技术调整的问题,则可能产生系统兼容性问题。系统兼容性问题容易造成电价下装的大面积故障,但也合并个别电表重置或其他故障、远程抄表数据干扰等个别故障问题。所以,该研究的核心创新点是采用同一套电费大数据审计系统实现对电价下装问题的全面审计并作出预警。
1 基于差值离群分析算法的传统电费审计方案
基于“电费=费率×当期电量”的基本电费计算规则,如果费率一致,则当期电量与电费之间是严格的正比关系。电价下装后,因为要计算尖时、峰时、平时、谷时的不同费率条件下的分时电价,且供电公司辖区内的城市用电、乡村用电、重点区域用电、小规模工业用电、商业用电、特殊行业商户用电等均有不同的分时电价费率,所以采用传统差值离群分析算法时,需要将所有用户根据其执行费率不同而进行严格划分。这一审计方案反而进一步增加了电费管理的复杂度,带来额外计费问题隐患。
此时对差值离群算法的工作流进行分析,见图1。
图1中,分别对不同用户类型的所有用户分别重新验算其计费情况,将不同分时分段的电费量与用电量求取比值,得到费率,考察费率是否与该用户所属的费率相符。该算法在理论上只要计算机系统算力可以达到要求,即可在规定时间内精准选择出问题用户。但此算法有诸多问题无法解决:

图1 差值离群审计算法工作流图
1) 用电用户的类型需要手动归类,或从客户信息管理系统中读取用户类型,该类型在客户信息管理系统中也为手动输入,其用户类型的信度存疑;
2) 用户的计费分时策略并非一成不变,部分城市的尖时计量区间仅在夏季和冬季用电高峰期有效,其他时间并入峰时管理。在用电策略变更过程中,是电费下装问题出现的高峰期。
综上,该电费审计方案的可靠性与电费下装工作的可靠性存在同步性,问题是存在同源性,对电费下装过程可能出现的问题发现能力受到工作流的先天不足影响,较难发挥电费大数据审计的效能。
在电费大数据审计过程中建立一种脱离电费下装基础数据的工作模式,此时引入卷积神经网络的机器学习技术,实现无视下装基础数据的电费大数据审计工作模式,是该研究的创新点。
2 电费下装成功率大数据审计预警系统设计
2.1 可用数据资源及数据输入输出模式
电费大数据审计的核心数据资源,为各电能表的各期电量数据和各期电费计量结果数据,通过此两项数据,可以计算出特定用户的分时电价计费标准,传统模式下,直接使用k-means算法可以提取离群数据进行分析,但在机器学习视角下,可以直接跳过k-means分析阶段,直接对此两项数据进行卷积,将问题数据进行分类。
该输入输出模式如图2。

图2 机器学习模块输入输出模式示意图
图2中对特定用户(以电表号计)当月分时电量数据和分时电费数据作为输入数据,最终输出4个二值化数据。输出数据包括电费下装问题标志(接近0.000时认为正常,接近1.000时发出预警),计量兼容下装问题标志、电表设备故障问题标志、其他问题标志(以上3种标志均为接近0.000时认为正常,接近1.000时发出预警),此时,后3个预警标志需要在第1个预警标志为真值时有效,且第1个预警标志出现时,后3个预警标志需要有且只有1个为真时有效。其输出结构如表1。

表1 预警输出结果含义表
表1中,4个二值化输出变量共有4种有效表达,而其可能输出结果包括16种,包括下装问题标志为1时的1000、1110、1011、1101表达均为无效表达,下装问题表达为0时,所有不为0000的表达均为无效表达。数据训练过程中,可通过判断无效表达出现概率对神经网络的收敛程度进行判断。
数据输入过程中,因为电费数据和电量数据存在量纲异构特征,所以需要对其进行重投影去量纲计算,采用Z-score法进行数据整理,整理数据集为该月输入的4个电量数据和4个电费数据分别进行Z-score计算,计算函数如式(1):
(1)

(2)
式中,N为该列输入量最大下标,此处N=4。σ为4个输入量的标准偏差率,如式(3):
(3)
2.2 多列卷积神经网络模块细化设计
经过Z-score初步处理的2组各4个输入项,组成8个输入项输入到多列卷积神经网络中,形成相对独立的4个卷积+二值化模块,最终通过输出模块将二值化数据治理成逻辑数据,该数据流详见图3。
图3中,每个卷积模块均等价读入8个输入变量,输出1个双精度浮点型变量进入二值化模块,经过二值化输出的1个双精度浮点变量经过输出模块治理后形成预警标志,4个预警标志按照前文的解释方式进行解释形成最终预警结果。
4个卷积模块结构相同,但在训练中的收敛方向不同。其统计学意义在于将8个双精度浮点变量卷积为1个双精度浮点变量,其间的数据信息量损失较小,所以可以采用3层隐藏层(7节点、5节点、3节点)进行节点设计,节点函数采用细节放大率较高的对数回归函数进行节点设计。其基函数可写作式(4):

图3 多列卷积神经网络数据流图
(4)
式中,Xi为第i个输入项,Y为节点输出项,e为自然常数,A、B为待回归系数;
4个二值化模块结构相同,但在训练中的收敛方向不同。其统计学意义是将卷积模块输出的1个双精度浮点变量进行二值化处理,使其投影位置更贴近1.000或0.000。所以用经典二值化函数作为节点函数,隐藏层3层,分别为3节点、7节点、3节点。其基函数可写作式(5):

(5)
4个输出模块结构相同,且不含有神经网络计算,其本质是根据二值化输出模块的输出数据进行数据强制转化,形成逻辑输出变量。其逻辑转化过程可写作式(6):
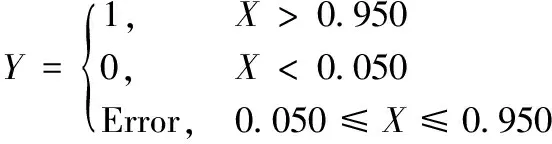
(6)
输出模块仅在输出结果大于0.950和小于0.050时输出逻辑型结果,当其落点在0.050和0.950之间时,系统报错。与上述输出解释模块的报错机制相同,该报错也可以作为神经网络充分训练收敛的标志。
3 电价下装问题预警系统性能仿真测试
在电力CAE(computer aided engineering,CAE)系统中加载SimuWorks组件,构建2组随机电费数据,每组数据共设计20万组,其中A组设置1 000组问题数据,并将问题原因进行标注,作为神经网络的训练数据,B组设置200组问题数据,并将问题原因进行标注,作为神经网络的验证数据。在上述试验平台和试验数据支持下,对该预警系统进行训练,测试其数据训练量与收敛程度的关系。收敛程度按照每万次系统报错次数进行标定,当万次测试数据运行报错次数为0时,认为神经网络充分收敛。其实际训练过程如图4所示。
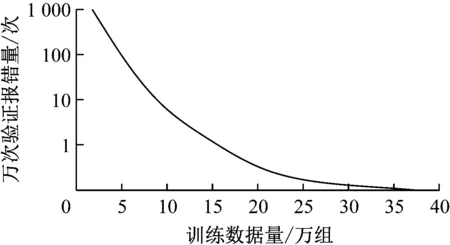
图4 神经网络训练收敛效率
图4中,当训练量达到10万次之前,系统迅速收敛,训练至17万次之后,万次验证报错率稳定到0,标志着该系统针对电价下装的评价任务,具有较强的收敛特性,可以进行后续评价效率验证试验。
在上述验证用B组数据下,使用传统的差值离群分析算法和该研究革新的神经网络算法进行比较分析,验证其敏感性和特异性,分析其综合准确率,可以得到表2。

表2 算法效能比较结果表
表2中,真阳性指下装问题电表中被判断为问题电表的数量,假阳性为无问题电表被判断为问题电表的数量,真阴性为无问题电表被认定为无问题电表的数量,假阴性为问题电表中被认定为无问题电表的数量,敏感性为判断为问题电表的总量中确实为问题电表的比例,特异性为判断为无问题电表中确实为无问题电表的比例,准确率为问题电表中被判断为问题电表的比例。对上述7个判断结果使用SPSS24.0进行双样本t校验,当t<10.000时认为数据存在统计学差异,同时读取其log值,作为信度标志P值,当P<0.05时认为结果在信度空间内,当P<0.01时认为结果存在显著的统计学意义。
表2数据表明,受到样本中阴性数据总量与阳性数据总量的比值影响,该结果数据的特异性并无统计学差异(t>10.000,P<0.05),但革新方法敏感性达到传统方法的1.86倍,且具有显著的统计学差异(t<10.000,P<0.01),革新方法准确率也显著超过传统方法(t<10.000,P<0.01)。所以可以认为,采用多列卷积神经网络对电价下装成功率进行评价,其算法效能显著超过传统大数据审计方法。
另外,革新技术还存在以下优势:
第一,革新技术条件下,完全排除了传统方法下因为数据同源性导致大数据审计过程和电费核算过程出现相同错误的可能性,这是其敏感性大幅度提升的重要原因;
第二,革新技术可以直接精确给出电价下装的常见问题类型,该研究中已经给出最常见的电表故障问题和电价下装设置问题,且将其他问题也给出标记,在传统方案下仅可发现电价下装问题,而无法在审计过程中给出下装问题原因;
第三,本技术通过基于多列卷积神经网络的电费审计方法,较传统电费审计方法,复杂度显著降低,算法更加精准。
4 总结
综上分析,电价下装问题一般为系统兼容性问题,在进行电费大数据审计师,也可能因为审计工作的数据来源兼容性问题导致无法发现电价下装的相应问题,该研究产生的革新成果,抛开原始配置数据,直接对电费计量结果数据进行大数据审计,从而实现更高的判断敏感性和更高的判断准确率,同时给出电价下装问题的常见原因判断结果。当然,该研究成果虽然准确率达到了99.9%,但其实际敏感度仅有95.7%,说明其在特异性方面仍有提升空间,即其存在一定比例的假阴性结果。所以,在后续研究中,应从增加神经网络复杂度和卷积程度等方面进行持续革新研究,以提供更高敏感度的电费大数据审计算法。
猜你喜欢
意林·少年版(2020年1期)2020-02-18
现代营销·理论(2019年5期)2019-09-10
数学大王·低年级(2018年5期)2018-11-01
环球时报(2018-09-11)2018-09-11
科学与财富(2016年32期)2017-03-04
新作文·小学低年级版(2016年12期)2016-09-10
共产党员·上(2014年11期)2014-11-26
数理化学习·高三版(2009年1期)2009-03-19
