
基于文本信息的图书馆读者流失分析模型
2022-10-15 08:39徐根祺曹宁谢国坤董三锋张正勃
微型电脑应用 2022年9期
徐根祺,曹宁,谢国坤,董三锋,张正勃
(西安交通工程学院,1.机械与电气工程学院,2.土木工程学院, 陕西,西安 710300)
0 引言
图书馆传播知识的对象是读者,而读者又是图书馆资源中最根本的资源,图书馆价值的体现(如经济效益和社会效益)很大程度上是建立在读者资源这个平台上的,读者数量的稳定以及开发的深、广度在根本上影响着图书馆的生存与发展。因此,如何能够留住读者,防止读者流失逐渐引起决策者和管理者的重视,这也是检验图书馆是否成熟的一个重要标志[1]。
然而,当云计算风起云涌之际,大数据又风靡云蒸,在物联网、移动互联、云计算等技术的推动下,全球化大数据时代已如日方升[2]。随着人们获取知识的方式多样化,传统图书馆受到了极大的冲击,读者流失严重。探究读者流失的原因、提升图书馆的服务质量、增加现有读者的满意度、吸引潜在读者到图书馆借阅图书、减少读者流失的可能性,对比充分发挥图书馆知识服务的作用更显得尤为重要[3]。目前,国内外研究大多集中于对图书馆读者流失原因的剖析,而对于读者流失预测的研究则凤毛麟角,且预测效果也并不理想,面对读者们各种需求的纷至沓来,为了最大程度减少读者流失,可以采用数据挖掘算法根据读者和图书馆的历史数据建立以读者信息和图书馆信息为输入,读者流失概率为输出的模型,探求这些数据之间的内在联系,据此来预测读者流失的可能性。若读者流失概率过高,则通过改善服务、为读者推荐图书等方式来提高读者的忠诚度以预防读者流失[4],这就改变了过去图书馆在读者注册后无法预估读者流失和无法有效实现对读者关怀的情况[5]。
本研究根据读者的属性信息、读者的借阅行为信息和图书馆的属性信息等文本信息[6]结合卷积神经网络(convolutional neural network, CNN)[7],建立了图书馆读者流失概率预测模型TEXT-CNN,利用这个模型对读者的流失概率做出分析。
1 准备工作
造成图书馆读者流失的原因有多种,众多研究表明,常见的包括读者和图书馆两方面原因[8-10]。
1.1 读者属性
1.1.1 读者固有属性
年龄、性别、职业、学历、是否结婚等均属于读者固有属性信息,这些因素均从不同程度上对读者进入图书馆阅读的行为产生影响[11]。随着读者年龄的增长、学历的提升、职业的转变以及婚姻状况的改变等,造成其远离或转移图书馆的行为。
1.1.2 读者行为属性
读者在图书馆进行的借阅行为也属于读者属性,借阅行为数据主要包括在借数据、历史数据和统计数据。
(1) 在借数据收集的是读者正在借阅的书籍信息。
(2) 历史数据收集的是读者过去半年内的借阅信息。
(3) 统计数据又分为借阅频率和阅读程度。借阅频率表示读者某时间段内借阅图书的平均次数;阅读程度表示读者对所借阅书籍认真阅读的程度,用续借次数和借阅天数之积表征。
1.2 图书馆属性
图书馆属性包括自身的“硬”属性和“软”属性。馆藏图书数量与种类、开放时间和馆内图书更新速度等均属于图书馆能否留住读者的“硬”属性,多伦多大学的Heather V. Cunningham和Susanne Tabur根据Maslow需求层次理论提出图书馆四大空间学习属性,可将其归纳为地理位置便捷性、易于读者活动性、便于建立社交性和学习空间舒适性,这些也可列入“硬”属性范畴[12];而图书馆举办的讲座与活动、工作人员的服务态度与服务质量等则属于图书馆能否留住读者的“软”属性。读者流失正是由于图书馆的各种属性无法满足读者相应的需求所导致的。
2 相关理论
2.1 卷积神经网络(CNN)
CNN本质上就是从输入到输出的某种映射关系,且输入与输出之间并不需要精确的数学表达式就可以从学习海量输入与输出数据得到映射关系[7]。为了建立卷积神经网络的输入、输出之间的映射关系,需要用已设定好的模式对网络进行训练。Fukushima在神经认知机中提出了第一个卷积神经网络计算模型。Lecun等提出的卷积神经网络是第一个真正的多层结构学习算法。图1给出了CNN的一般网络结构,从左至右依次为输入层、卷积层、池化层(子采样层)、全连接层和输出层。
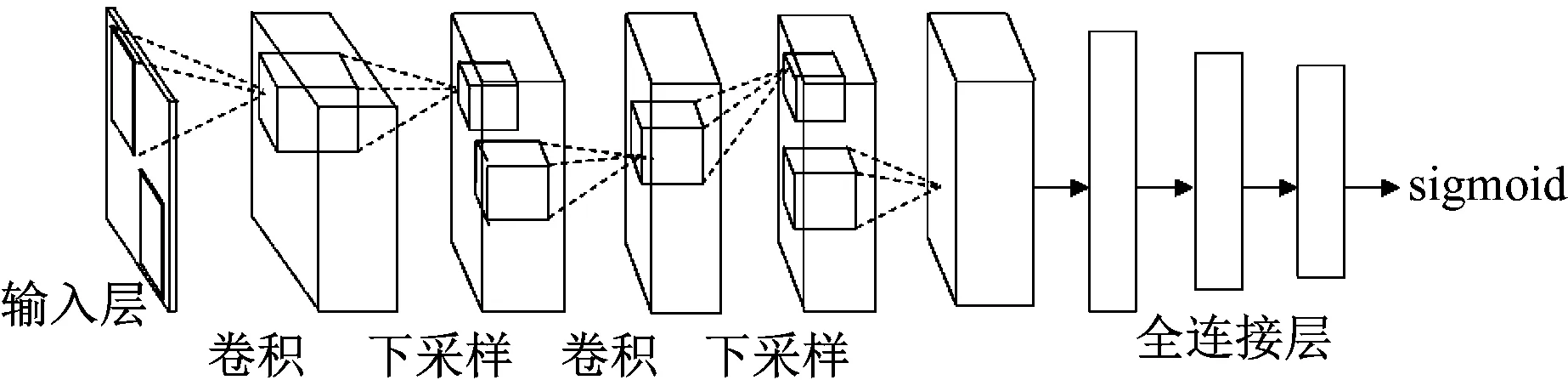
图1 卷积神经网络结构图
(1) 输入层
CNN的输入层可直接以原始数据作为输入,也可以先通过矩阵变换得到特征向量,再将其输入到网络中。由于CNN通常都有全连接层,而全连接层的输入要求是大小相同,因此卷积神经网络的输入一般大小都一样。
(2) 卷积层
卷积层属于特征抽取层。对输入进行卷积,便可得到特征图。为了减少网络结构中连接权的数量,CNN要求同一卷积层中不同神经元与前一层中不同位置相连的权值相等(一个卷积核提取前一层输出中不同位置的特征),即一个卷积核对前一层网络的输出进行卷积从而得到一种特征。对于不同的卷积核,每个卷积核都能分别进行卷积,这样就能够提取出不同的特征。
(3) 池化层
池化层(也称下采样层)是特征映射层。在池化层中,使用非线性降采样法将输入划分为多个局部感受域,用这些局部感受域中的平均值(或最大值)来表示降维后的特征值。每一个与前一层的输出局部感受域相连接的权值都被设定为固定值,在整个网络训练的过程中不再改变。这一层通过对前一层网络的输出进行下采样,进一步降低了网络参数规模。
(4) 全连接层
全连接层是采用全连接方式的人工神经网络,对卷积层所提取特征的总结变换,将所有的特征映射至一维列向量。
(5) 输出层
全连接层的下游为CNN的输出层,与传统前馈神经网络的输出层相比,其原理和结构完全相同。此处选用sigmoid函数作为输出层激活函数。
2.2 文本数据的处理
首先,文本信息必须转换为某种数字输入,因此先要进行预处理,然后准备文档,使每个术语都进行一次热编码。文本数据需要转换为代表维空间中文本信息的维数字向量,连续的维向量表示可以随机地使用预训练的向量来初始化,这些词嵌入可以像其他模型参数一样在训练期间进行更新,也可以保持不变。其次,可以从CNN卷积层的嵌入向量中计算出新的特征。本文使用复杂层术语,其中将卷积层定义为3个阶段,即卷积阶段、检测器阶段和合并阶段。
卷积可以提高网络的计算效率。首先,将卷积阶段的单元组织在特征图中,并通过一组连接权值连接到上一层特征图中的局部补丁。其次,特征图中的所有单位共享相同的连接权值或滤波器组,这一过程称为参数共享。卷积是线性运算,因此将局部加权和的结果通过激活函数传递给检测器阶段的非线性模型,该激活功能将有关神经元输出是否被激活的信息传递给外部连接。
分类需要将在卷积层中创建的特征组合到一个分类器中,通常使用一个或多个全连接(或密集)层。全连接层需要一维输入,因此将最后一层中的列连接为单个向量x,变换Z定义为Z=xTW,它是权值矩阵W和某些非线性激活函数的内积。输出层中使用softmax函数作为激活函数。
CNN的训练需要使用损失函数,该函数间接优化了真实目标,其定义为Loss=-Σ{yilogpi+(1-yi)log(1-pi)},其中yi表示真实的类别标签,pi表示读者i的预测结果。当对读者的预测越来越接近实际值时,损失也越来越少,因此可以通过减少损失来提高目标。
3 图书馆读者流失预测模型搭建
3.1 CNN读者流失预测模型
读者预测模型流程如下:
(1) 将结构化处理后的读者和图书馆的数据作为预测模型的输入;
(2) 对数据进行数据抽取、数据清理和数据转换等预处理过程;
(3) 将准备好的数据集输入CNN网络,预测出读者流失的数量。
预测模型结构图如图2所示。

图2 CNN读者流失预测模型
3.2 将文本信息纳入CNN
由于非结构化文本数据和结构化数据的数据类型之间存在巨大差异,因此第一阶段将它们分开处理,该阶段仅将文本数据纳入基于结构化数据的预测模型中。第二阶段将预处理的结构化信息和文本信息进行组合来构建预测模型,如图3所示,将文本数据与卷积神经网络进行合并。
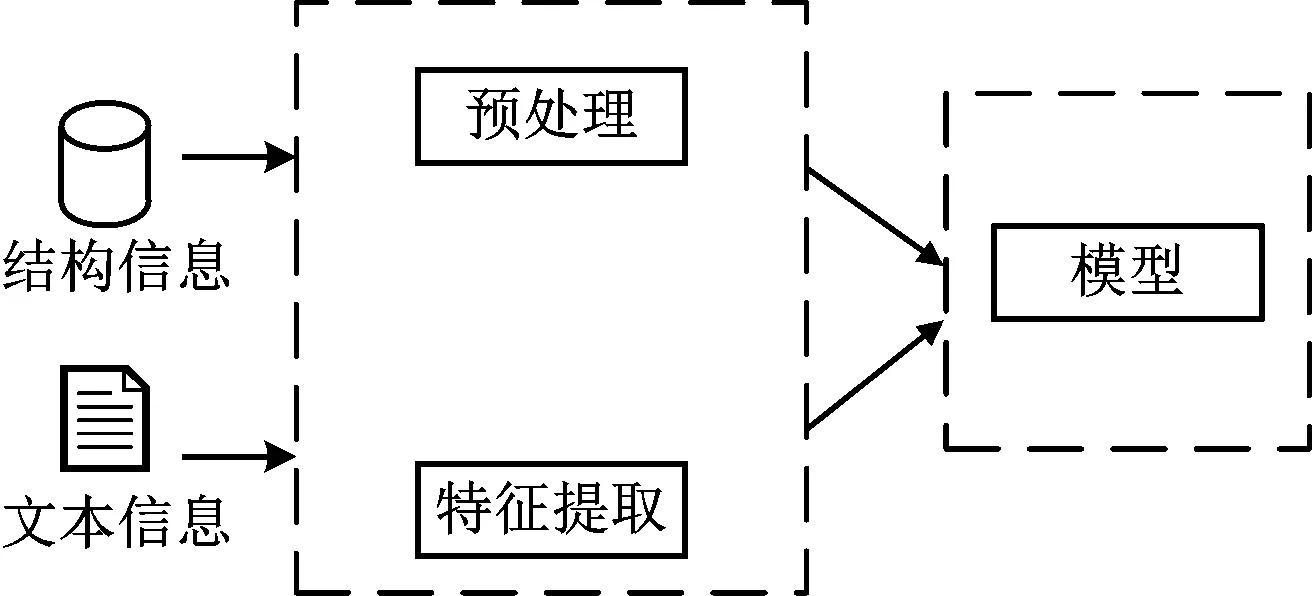
图3 基于文本信息的CNN读者流失预测模型
本节构造了一个非静态的CNN来处理文本数据,嵌入层之后是一维卷积层和最大池化层,将这些层的输出合并在一起作为全连接层的输入。最后一层使用sigmoid激活函数,该函数对每个读者可生成其流失概率。基于先前的研究经验,本文CNN的参数设置如表1所示。

表1 CNN模型参数
4 实验与仿真
4.1 数据来源
模型搭建过程中需要建立模型的目标变量,这些变量包括读者属性信息、读者借阅行为信息和图书馆属性信息。本文选取西安市某图书馆2018年1月~2018年12月共3 300组数据,将其分为两部分对模型进行训练和验证,其中2018年1月~2018年11月的3 000组数据用于训练模型,2018年12月的300组数据用于对模型进行验证。
4.2 仿真验证
根据所选取的数据进行读者流失的预测,输入为某图书馆 2018年1月至2018年11月的读者数据,目标变量为2018年12月的读者流失数据,并将本研究中所用模型TEXT-CNN与遗传算法优化的BP神经网络(GA-BP)模型、支持向量机(SVM)模型以及逻辑回归(Logistic)模型的预测结果进行比较,各模型的预测误差如图4所示。
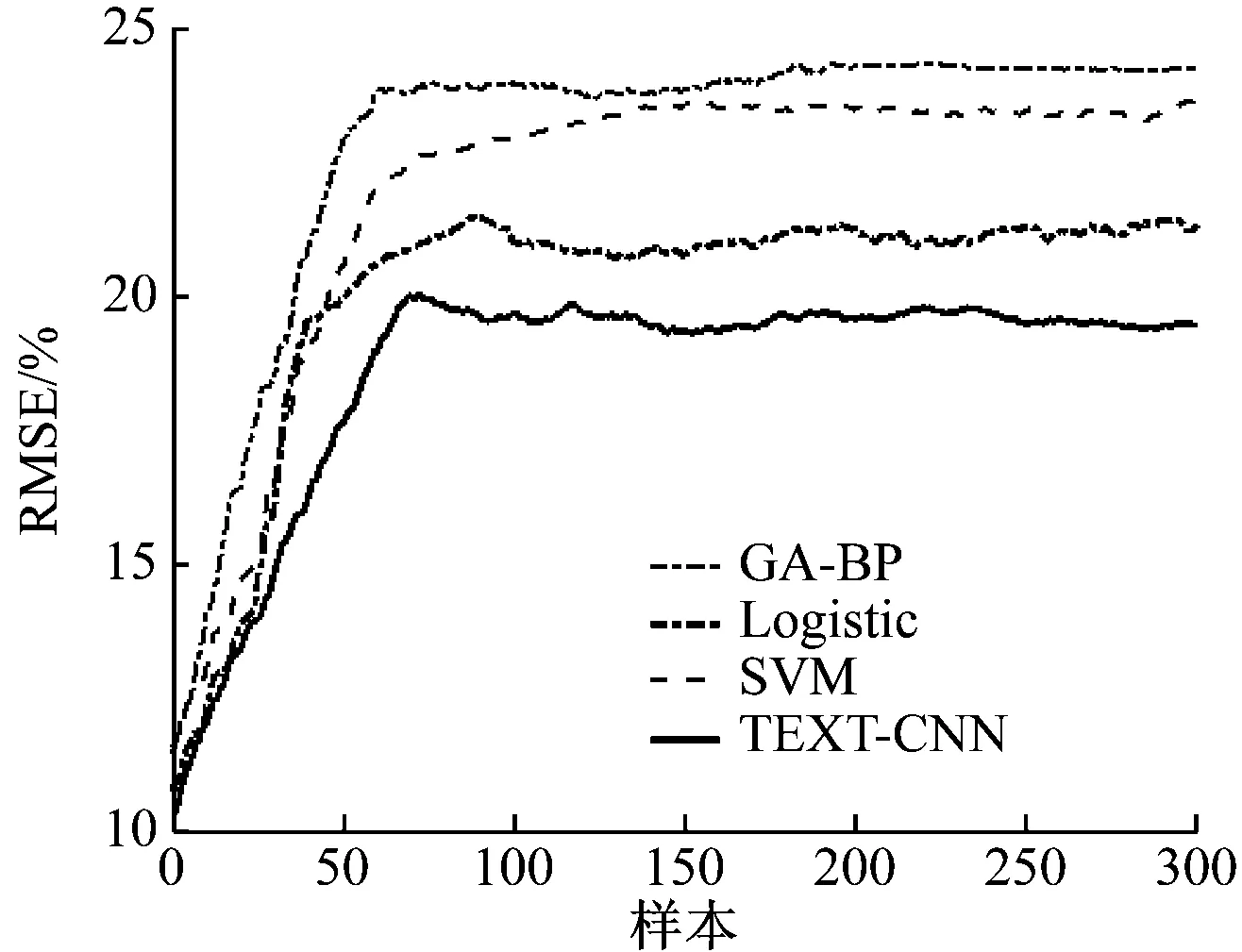
图4 4种模型预测误差对比
由图4可知,TEXT-CNN的预测误差明显低于其他模型的预测误差,采用将文本信息纳入卷积神经网络的结果要比实际读者流失的变动曲线拟合效果更好。利用均方根误差(root mean square error,RMSE)和均方误差(mean square error,MSE)2个指标进行衡量并对比分析(结果如表2所示),由表2可以看出,TEXT-CNN模型的预测结果相对应的RMSE和MSE均为最小,同时相对其他3种模型可靠性也最高。
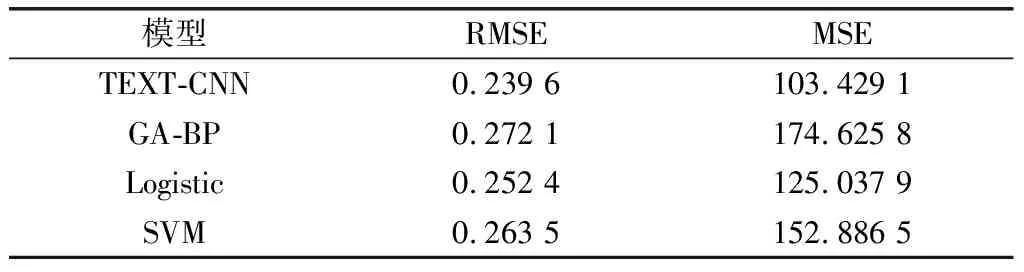
表2 4种模型的RMSE和MSE数值表
为了进一步分析各模型的性能,本节对各模型的精准率、准确率、F1值和召回率进行比较,结果如表3所示。

表3 4种模型预测结果
由表3可知,本文所用的TEXT-CNN神经网络的精准率为85.21%,F1值为77.33%,均比其他3种模型略高;准确率为95.19%,比Logistic、SVM和GA-BP模型分别高2.51%、3.58%和6.72%;召回率为72.01%,分别高出Logistic模型7.65%、SVM模型9.26%和GA-BP模型10.92%。该结果表明TEXT-CNN模型相比于其他3种模型能够更有效地对读者流失情况进行预测。
根据模型输入的目标变量数据,生成读者流失概率的信息列表,如表4所示。
由表4可知,模型的预测结果与图书馆的日常借阅情况相符,可用于图书馆读者流失的预测,具有较强的实用性。根据预测结果,图书馆管理人员针对可能流失的原因进行分
析,对不同的读者群体采取相应的措施。
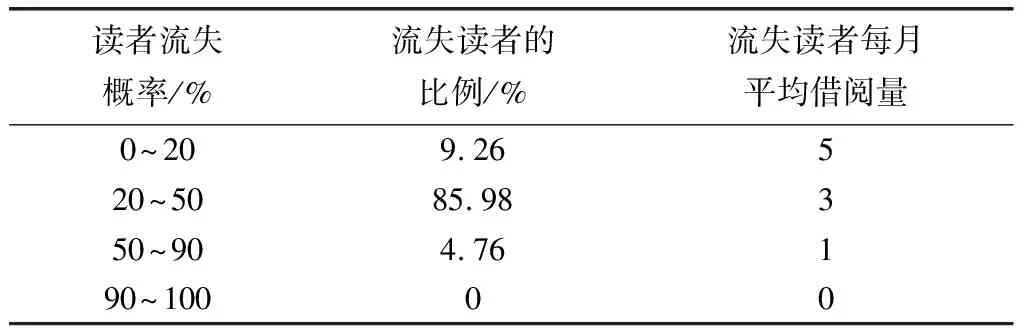
表4 读者信息列表
5 总结
通过对图书馆用户流失原因的深入剖析,基于图书馆属性和读者属性的文本信息结合卷积神经网络构建了TEXT-CNN预测模型,并通过西安市某图书馆的实际样本数据,分别将TEXT-CNN模型和Logistic模型、SVM模型及GA-BP模型的预测结果进行了比较,结果显示,本文提出的模型在精准率、准确率、F1值和召回率方面均高于其他3种模型,预测结果与流失的读者信息也基本一致。该模型能够帮助图书馆准确分析读者流失的实际情况,为全面有效地开展图书馆管理工作提供更好的决策支持。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
软件(2017年6期)2017-09-23
金点子生意(2014年4期)2014-04-10
