
融合业务拓扑的电力计量全链路关键业务异常定位研究
2022-10-15 08:39石云辉
微型电脑应用 2022年9期
石云辉
(贵州电网有限责任公司计量中心, 贵州,贵阳 550000)
0 引言
南方电网大力推进“数字化”转型,融合新一代数字技术在新型经济生态中的价值延伸。用大数据分析和数学模型,构建智能化运维体系。计量采集链路上的异常数量日益激增,根源的异常是运维实际中很迫切需要解决的问题[1],但是计量采集是基于链路架构,单点异常处理缺乏找到根源原因的办法[2]。近年来,关于异常定位的研究一直受到国内外学者的重视[3-4]。当前,针对计量单环节的异常分析,以及通过关联分析找异常根源的算法比较多,具有成熟的研究成果[5-9]。由于缺少从链路的整体上定位异常根源,造成待处理的异常较多、根本问题得不到解决等问题。因此,本文引入异常预处理与全链路异常定位算法,按权重面积排序,提供全链路异常定位依据,既提升了运维的智能化水平又从业务前后环节的整体角度对异常进行监控,提升电力计量运维效率。
1 电计量主站运维异常排查现状与问题
目前运维工作主要通过人工巡检,通过经验排查运行中链路和采集装置的异常原因。存在以下问题:第一,排查单个环节异常,运维工作中主要通过人工与系统自动统计方式进行运维,以解决一个环节的异常为目的;第二,缺乏链路整体定位,电力计量主站运维存在很多离散的监控点;第三,整体智能程度不高,异常点存在误报、漏报现象,大部分需要人工经验排查。
2 计量主站全链路异常定位模型
2.1 计量主站全链路异常定位建模流程
异常定位模型包含信息预处理、异常定位及定位路径与规则固化三方面。模型构建过程如图1所示。
2.2 全链路异常信息预处理
电力计量业务通常被设计为网状的业务拓扑结构,需要先将网状拓扑结构进行降维处理,同时过滤冗余异常,使有效异常叠加至链路环节之上,此过程是对异常信息的预处理。计量主站业务主要分为数据采集与指令下发2类业务链路,如图2所示。
业务拓扑图中的业务逻辑、节点间的相互关联是交叉往复且带有复杂的逻辑判断关系。通过对链路各环节间数据流转、指令调用等关系的分析,将网状链路处理成具有独立调用的关系链路,最后形成不同的链路结构。将业务拓扑图降为单一指令流与数据流的多条链路,如图3所示。
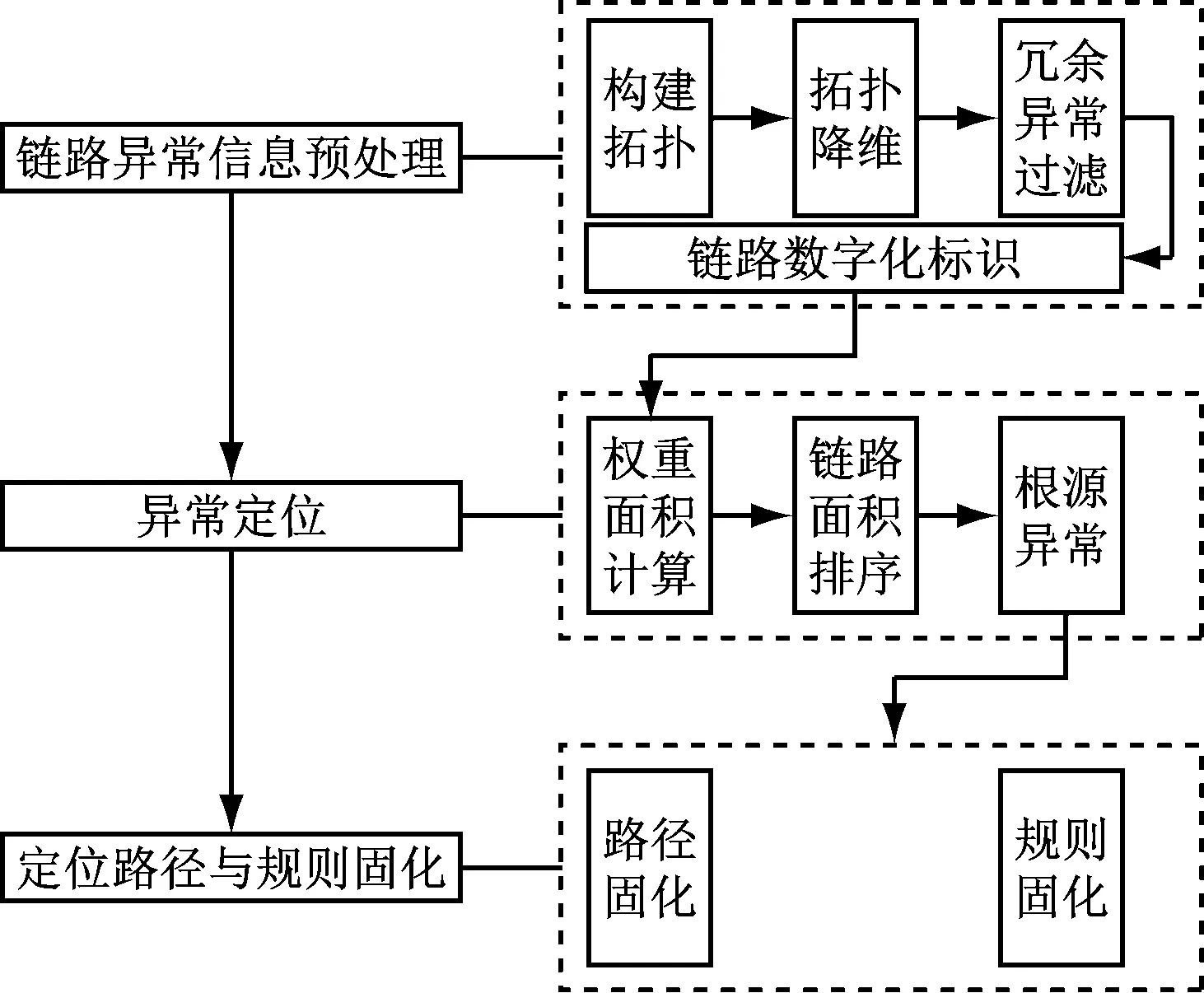
图1 计量全链路异常定位建模流程图
处理后的链路中节点与节点间的关系直观,都将降维拆解出一条独立的链,形成从业务起点到终点的业务链路。
为实现对非关注异常的有效过滤,从而提高异常定位的精准度,需要设置时间序列,对异常信息进行切割,锁定异常定位范围。计量关键业务异常项获取如图4所示。
(1) 同一时间片内节点异常重复处理。节点异常内容包括时间完全相同,只按第一次判定的异常节点进行异常链标记,其余节点异常判定为不参与异常链标记。
(2) 按时间序列划归异常项。确定需定位异常点前后需划分的时间范围,设置t为前后时间范围。设置e为划归间隔时间,链路数量m=t/e(t时间范围以实际情况配置,e间隔时间以实际情况配置)。
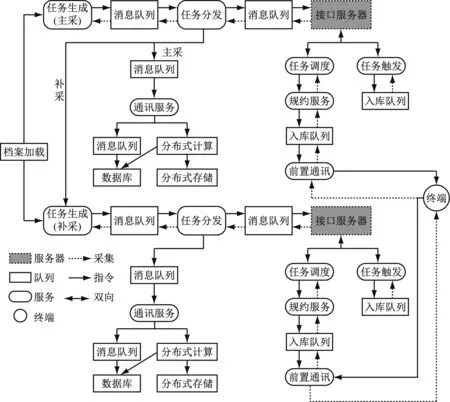
图2 计量全链路关键业务拓扑图
(3) 同一环节持续或闪退的异常判定处理。对长时间存在的异常,或者在短期内自行消除的异常进行标记,通过规则分析,判断为冗余的,k天内不再参与异常智能诊断(k设置天数以实际情况配置)。
2.3 异常链路权重面积算法
2.3.1 异常链路数字化处理
结合业务信息与时间信息的异常链,将调序后的异常链进行抽象化处理,删减多余的业务信息和时间信息,用1代表异常节点,0代表非异常节点,得到抽象后的01异常链,如图5所示。
2.3.2 特殊倍率赋值
为进一步提高异常链路的计算准确性,需对异常权重算法进行调整,其规则如下。
(1) 全链仅存在单个异常节点的单节点异常链:乘因c=1+异常节点序/总节点数。
(2) 存在单个异常密集段且在链最后的后置异常链:乘因c=整体异常权重放大10倍。
(3) 全链各节点都异常的全异常链:乘因c=整体异常权重放大10倍。
2.3.3 异常链路权重面积计算
通过链路环节上的异常数量和异常密集程度计算链路异常关联程度,为异常定位提供参考,具体算法如下。
(1) 异常数量以宽度表示:如链路异常节点数N=1,则宽度a=1。如链路异常节点数N>1,则宽度a=max(相连异常节点数)。
(2) 异常密集程度以长度表示:如链路异常节点数N=1,则长度b=1+告警节点所在链路的序号/链路总节点数。如链路异常节点数N>1,则长度为
(1)
(3) 异常权重面积公式:S=a×b×100×c。
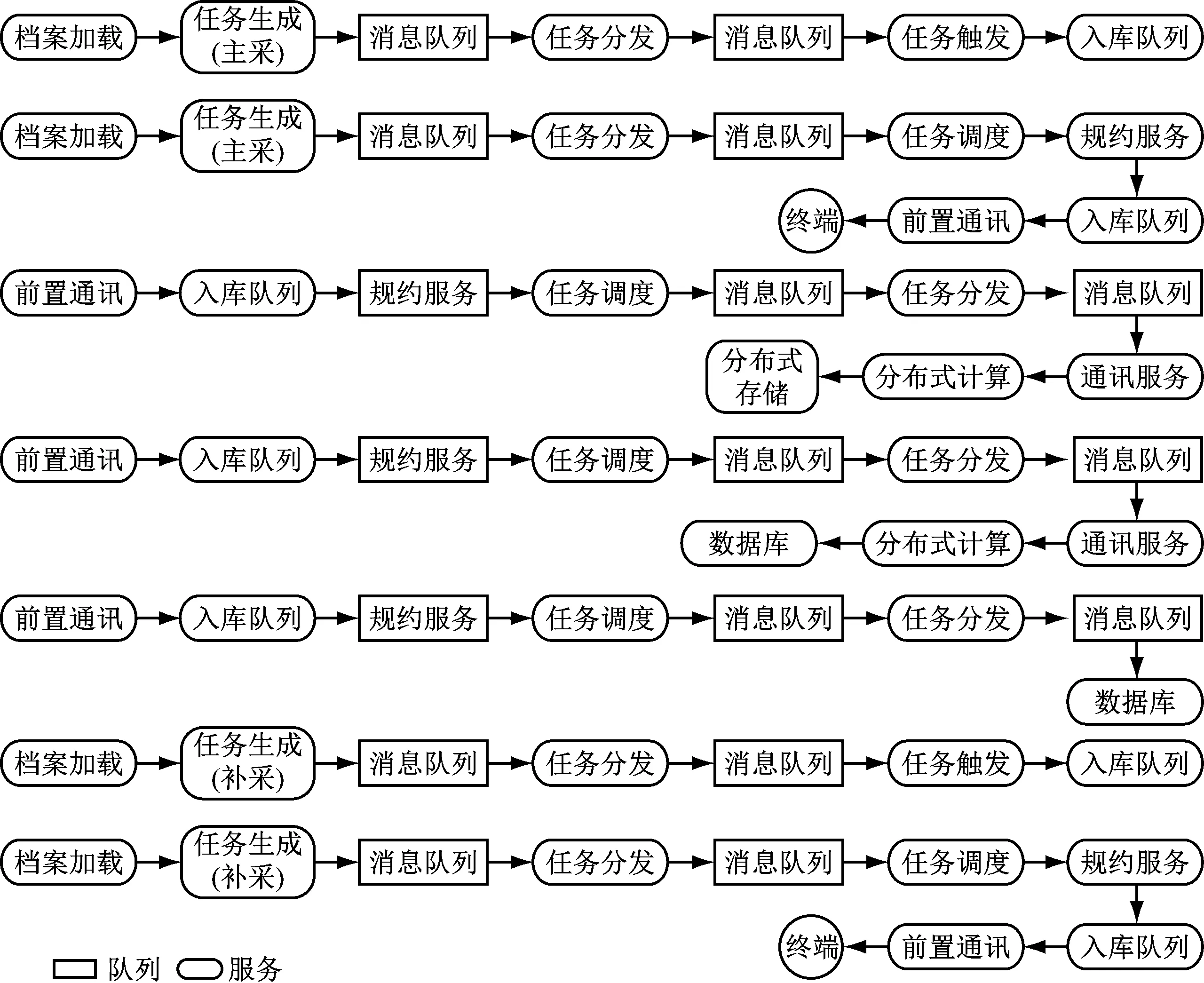
图3 计量关键业务降维链路图
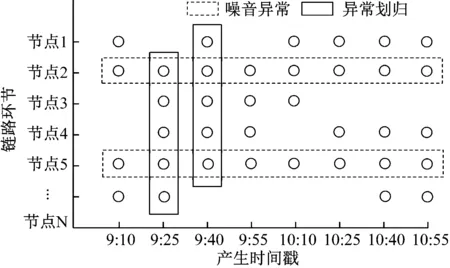
图4 计量链路冗余异常处理架构
(4) 异常链路权重面积计算:评价计算与日志记录的异常项对应到链路的环节之上,并且通过时间戳进行显示。将异常信息数字化成0和1表示的标准链,通过权重面积算法得出每一条链的面积,以此表示不同链的异常优先级,以实现辅助运维异常排查的目的。
(5) 计量全链路根源异常定位:设置链路优先级,在优先级范围内依据时间戳顺序确定根源异常。
2.4 全链路异常定位规则固化
将异常置于优先级高的链路中寻找链路上的异常根源,并保留全链路径。同时,从验证中提取匹配的异常定位规则,形成规则库。
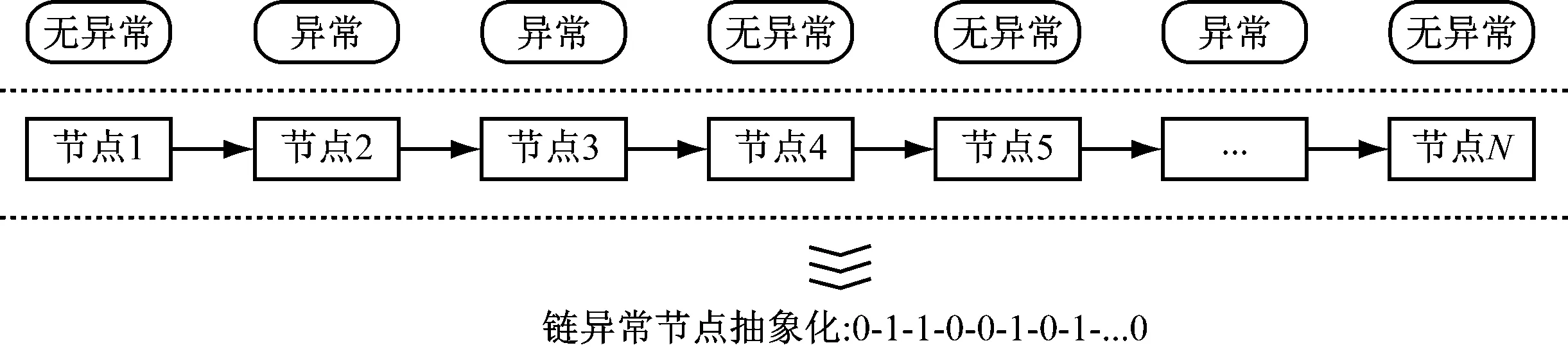
图5 计量链路异常节点抽象化
3 实例分析
以贵州电网公司计量主站2020年4月10日至2020年4月18日期间8条关键数据采集上行链路为例,环节分别为前置通讯、规约服务、消息队列、任务触发、任务分发、消息队列和入库队列,对环节异常信息进行标识与时间戳,如表1所示。
通过权重面积算法得出每一条链的面积,以此表示不同链的异常优先级,进而对面积进行排序,得到优先级高的链路,以实现辅助运维异常排查的目的,如表2所示。
为验证计量全链路关键业务异常定位的准确性,以2020年4月10日至2020年4月24日的5.32万条数据作为训练样本集,建立计量全链路关键业务异常定位验证数据库,将其与已排查运维工单数据进行比较验证,具体流程如图6所示。
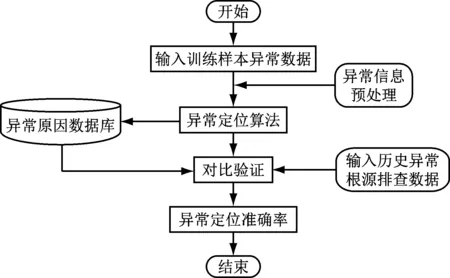
图6 验证流程图
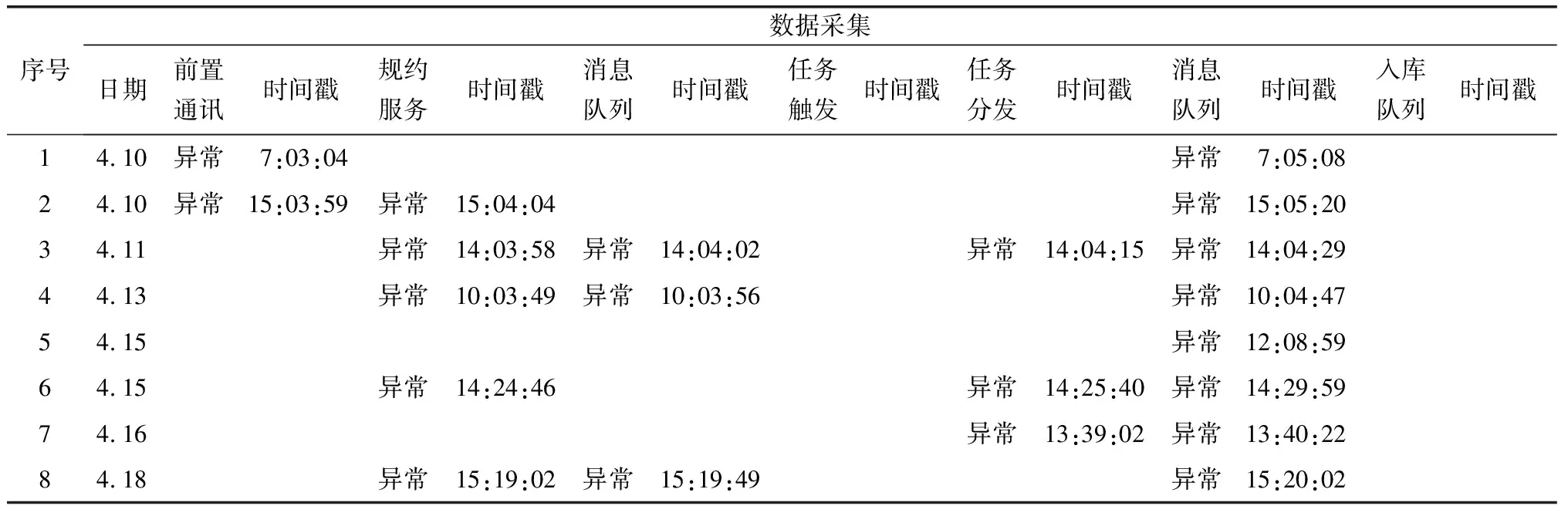
表1 数据采集业务异常链路信息

表2 数据采集业务异常链路权重面积计算
选取15天5类链路环节中重要程度较高的报错作为异常信息,对异常信息前后10 min内的异常信息,每间隔2 min获取一次,最终对异常关联度优先级设置为排名前3的链路进行分析,如表3所示。

表3 异常定位与运维排查准确率对比表
经过实际对比验证,本文提出的权重面积较大链路的异常定位准确率较高,此类链路范围覆盖根源异常的比例均超过50%,其中5类关键异常的定位准确性高于75%,验证了本文提出的电力计量全链路关键业务异常定位规则的准确性和有效性。
4 总结
本文采用融合业务拓扑的电力计量全链路关键业务异常定位,为标准化异常信息,绘制计量关键业务拓扑图,并通过数字化将异常信息进行预处理,引入异常权重面积算法来确定链路异常关联程度,通过对链路异常关联程度高的链路进行异常定位,提高了运维排查并解决链路异常的效率,保障电网稳定运行。但是计量链路异常根源很多,其中非链路异常也是主要原因,本文提到的异常定位方法无法完全满足定位要求。因此,下一步将从链路与单点异常定位两个角度入手,提高异常根源定位能力。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
计算机系统应用(2022年8期)2022-08-25
汽车实用技术(2022年12期)2022-07-05
心理学报(2022年5期)2022-05-16
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
高中生·天天向上(2018年2期)2018-04-14
科技创新导报(2016年27期)2017-03-14
吉林农业·下半月(2016年6期)2016-10-21
