
基于特征提取与聚类的医院档案数据分类方法
2022-10-15 08:39张宁
微型电脑应用 2022年9期
张宁
(石家庄市第五医院, 河北,石家庄 050000)
0 引言
随着医疗卫生事业的蓬勃发展,海量的医院档案数据也被记录和积累下来,如何有效地对这些海量数据进行分类对于充分发挥档案资源以史鉴今的作用至关重要。而现有的医院档案数据分类方法主要为人工分类[1]以及传统的数据库技术[2]。前者过于依赖人工经验并且耗时耗力;后者虽然可以满意一般数据规模下的档案分类,但是也难以适应突发公共卫生事件中医疗救治定点医院的档案管理[3]。
王红等[4]利用注意力机制与双向门控循环单元方法提取民航突发事件领域本体的关系,为获取民航本体关系提供了新的方法。何喜军等[5]提出基于语义相似聚类的技术需求分级方法,并在新能源领域得到了应用和推广。TANG等[6]利用贝叶斯方法框架为每一个类别选择确定的特征,并在多个真实的数据集中验证了所提的文本分类方法的有效性。陈果等[7]提出融合领域元知识实体关系分类,并以心血管数据为例进行仿真实验。近期,白亦霆[8]设计了一种医院档案信息化管理系统解决了传统的档案管理系统中缺少有效的管理数据库问题。
本文利用改进的LDA模型结合GMM算法对医院文档数据进行特征提取和聚类,实现医院档案数据的准确和智能分类。主要贡献如下。
(1) 加权的LDA模型(WLDA)不但可以提取文档数据的特征,而且可以消除多种主题内相关度词语之间的影响。
(2) 将提取的特征作为GMM模型的输入并依关联性的大小进行聚类,用已有的档案数据训练Naive Bayes模型,实现档案数据的智能分类。
(3) 快速有效地应用现有档案资料指导医疗救治、院感防控等工作的开展,充分发挥档案资源的参考作用。
1 所提方法
1.1 LDA模型
LDA模型是在PLSA模型基础上改进得到的,其主要结构如图1所示。
图1中,α和β分别表示文档和词语的超参数,z和w为主题和词语级的参数。LDA模型的联合概率可表示为
p(θ,z,w,φ|α,β)=Πp(θ|α)p(zn|θ)p(φ|β)p(wn|θ)
(1)
经过N次循环之后,整个语料N的生成概率为
p(N|α,β)=Πp(wn|α,β)
(2)

图1 LDA模型流程图
1.2 WLDA模型
医院档案数据中主题内部之间的相关性较高,主题间相关性和词语相关性如下:

(3)
其中,w为词语,sim为词语之间的相似性,得到主题权重w′:
w′=2δ(S-S′)
(4)
其中,S′是S的均值,δ为平衡参数,用于调节S′和S对w′大小影响的程度。图2给出了当δ=1时,w′、S′以及S间的关系。
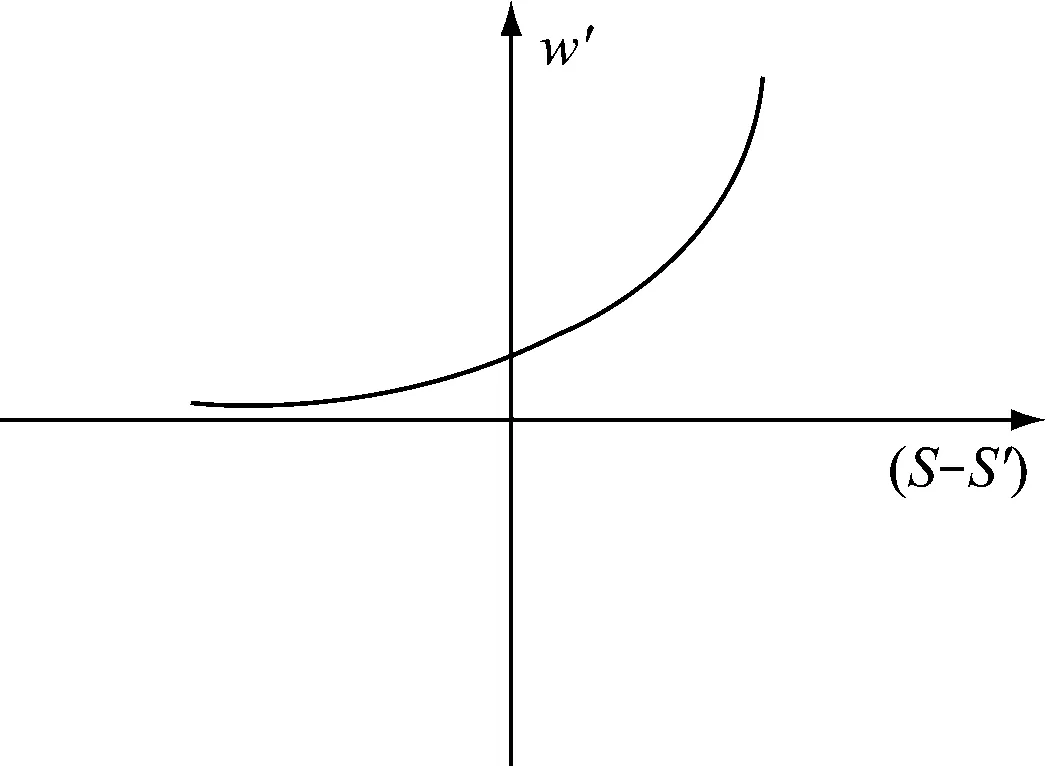
图2 权重w′、S′以及S之间的关系
1.3 GMM模型
GMM算法假设类别标签服从多项分布,并对给定的标签样本满足多值高斯分布:
(xi|zi=j)~N(μj,Σj)
(5)
进而得到联合分布:
P(xi,zi)=P(xi|zi)P(zi)
(6)
1.4 Naive Bayes模型
假设Naive Bayes模型的后验概率为P(y,x),由贝叶斯公式可知:
(7)
其中,x=x1,x2…为联合事件。
2 基于特征提取与聚类的档案数据分类方法流程
此算法的具体步骤介绍如下。
离线建模:
(1) 将原始档案数据输入到LWDA模型中;
(2) 利用GMM模型对LWDA提取的特征依相关性进行聚类;

图3 基于所提方法的医院档案数据智能分类框架
(3)将测试样本的聚类结果保存。
在线分类:
(1) 将新采集的医院档案数据按照离线步骤1~2进行依特征的聚类;
(2) 计算相应的样本概率P(xi,zi);
(3) 将样本概率作为Naive Bayes模型的输入,并计算得到相应的分类结果。
3 实验结果分析
利用石家庄市第五医院的真实档案数据进行实验,由于涉及病人的隐私,文档数据用编号表示。该训练集有8 425个档案文档,测试集6 896个档案文档,共包含16种文本数据。
3.1 WLDA+GMM聚类结果
本文只选择其中的8种类别(C1~C8)进行聚类,如表1所示。

表1 8类档案数据
通过准确率、F1值、召回率等来刻画所提的WLDA+GMM模型在医院数据聚类方面的可靠性。首先利用WLDA对档案数据进行特征提取,得到与文本数据对应的维度为16的文档特征向量,并利用GMM模型对这些特征进行聚类。由表1可知,所选择的8种档案数据具有类别不平衡性,所以加权平均的定量指标更能体现算法的聚类性能,具体实验结果如表2所示。
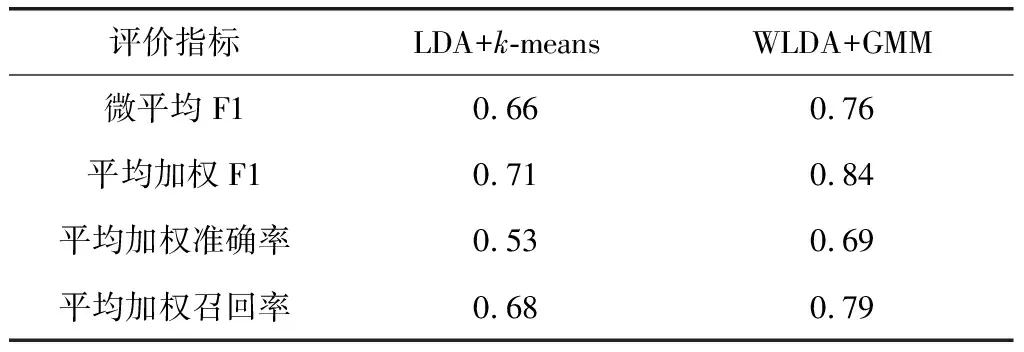
表2 不同聚类算法的F1值比较
从表2中可以看出,由于本文所提的WLDA+GMM算法考虑了不同特征之间的关联性并以概率的形式进行聚类准则,所以比传统的LDA+k-means取得了更好的聚类效果。WLDA+GMM在表2中的四种评价指标上都比LDA+k-means方法有一定程度上的提升(最低10%,最高16%),说明本文方法能够更好地对医院文档数据进行聚类。
3.2 档案数据分类结果
为了验证所提算法的医院档案数据分类精度,选择其中的5种类别(C1~C5)共2 969个样本进行仿真实验,将所提取的特征作为输入来训练Naive Bayes模型,并以SVM作为对比算法,2种方法的分类结果分别如表3和表4所示。
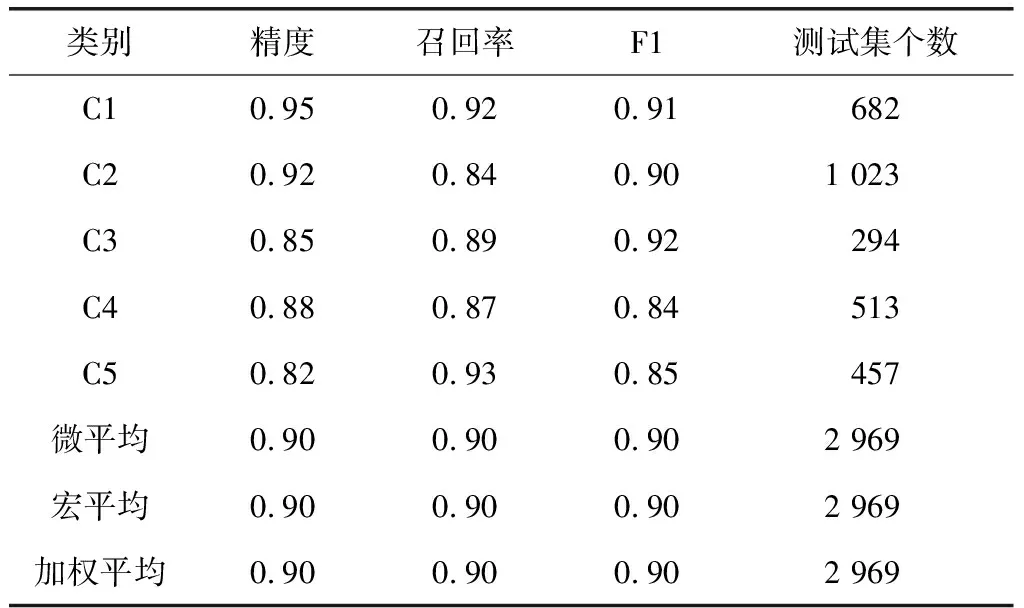
表3 SVM模型分类结果

表4 Naive Bayes模型分类结果
由表3可知,SVM算法的宏平均、微平均和加权平均为90%,并且最高的指标为95%(C5的召回率和C3的F1),最低的定量指标只有82%(C5的精度),说明SVM模型在测试集中总体表现较差。由表4可知,所提方法取得了较好的分类结果,基本可以替代基于人工的医院档案分类。
为了更加直观地展示所提方法的分类优势,以F1指标为例来进行说明,结果如图4所示。从图4中可以看出,所提方法的分类精度在5个类别上的F1值都高于SVM,并且最高的F1值已经达到100%。
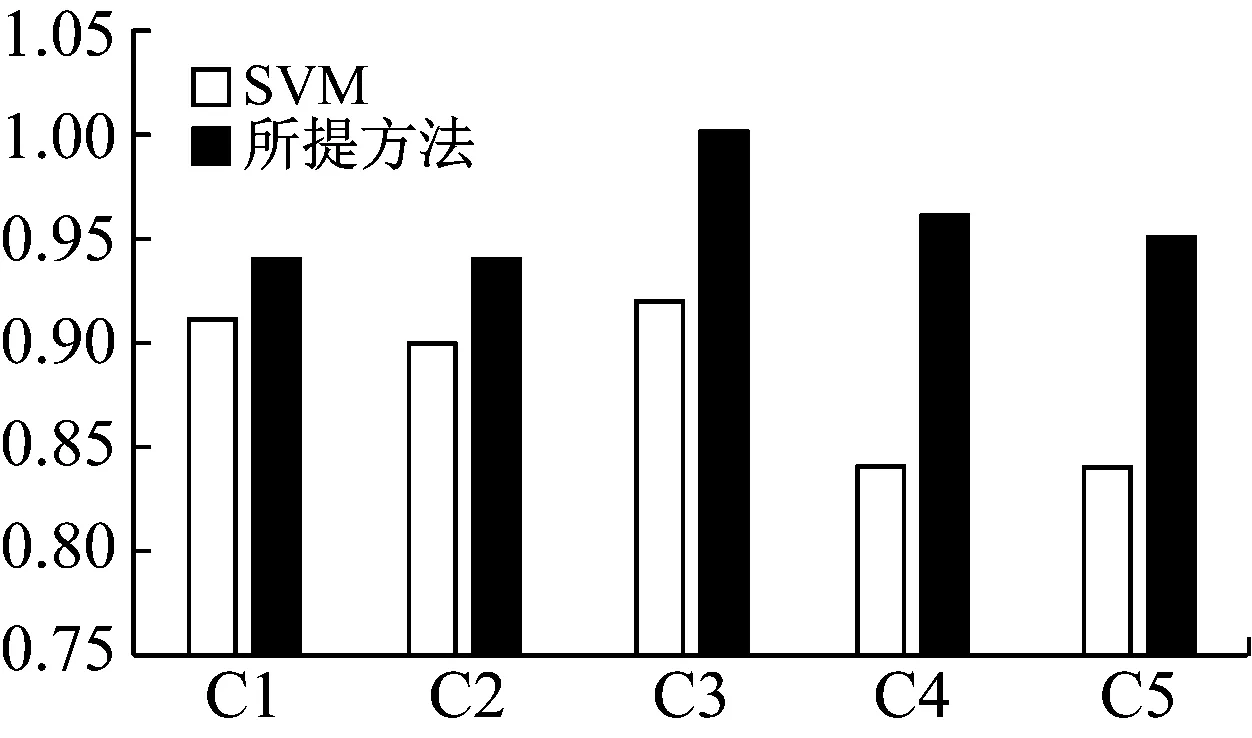
图4 2种方法在5种类别上的F1值
4 总结
本文提出一种新的医院档案数据的智能分类方法,可以进行档案数据的智能分类,并在石家庄市第五医院的档案数据集中验证了本文方法的有效性。但是针对医院丰富图片和声音数据档案还未有涉及,这将是未来研究的重点方向之一。
猜你喜欢
客联(2022年3期)2022-05-31
汽车实用技术(2022年4期)2022-03-07
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
电脑爱好者(2017年7期)2017-05-06
电子技术与软件工程(2016年23期)2017-03-06
