
基于多线程技术的ONNX音频分离模型并发推理的设计与优化
2022-10-15 13:17陈家乐董雪莲方慧桧谭静元
现代信息科技 2022年14期
陈家乐,董雪莲,方慧桧,谭静元
(南华大学,湖南 衡阳 421001)
0 引 言
线程则离不开进程。首先进程是一个正在执行中的程序,每一个进程执行都有一个执行顺序,该顺序是一个执行路径,或者叫一个控制单元;线程就是进程中的一个独立控制单元,线程在控制着进程的执行。一个进程中至少有一个进程。多线程:一个进程中不只有一个线程。
使用多线程,可以更好的利用CPU 的资源,如果只有一个线程,则第二个任务必须等到第一个任务结束后才能进行,如果使用多线程则在主线程执行任务的同时可以执行其他任务,而不需要等待;进程之间不能共享数据,线程可以;系统创建进程需要为该进程重新分配系统资源,创建线程代价比较小;Java 语言内置了多线程功能支持,简化了java 多线程编程。
传统的C++(C++98)中并没有引入线程这个概念。Linux和Unix 操作系统的设计采用的是多进程,进程间的通信十分方便,同时进程之间互相有着独立的空间,不会污染其他进程的数据,天然的隔离性给程序的稳定性带来了很大的保障。而线程一直都不是Linux 和Unix 推崇的技术,为了使得C++更符合现代语言的特性,在C++11 中引入了多线程与并发技术。
1 问题描述
随着深度学习的发展,近些年来音频算法在智能医疗、语音识别、声源定位等领域的应用非常火热,其效能和速度也不断得到精进。从过去的云端服务,逐步脱离并发展到PC 端边缘运算,到这几年再往移动端运算发展。尽管硬件的运算能力越来越强大,但是模型轻量化仍是算法设计所追求的核心之一。唯有如此,AI 算法才可以随时随地调用,发挥它们强大的作用。
语音识别是音频深度学习的重要研究课题,被广泛应用到各个领域,比如语音文字转换,可以快速把说话人的信息以文字的形式保存下来,又比如人声背景声分离,可以减弱背景声对人声的干扰,加强语音识别能力。
语音识别中的音频多人声分离算法,主要针对多人发声的场景下,可以把分离之后的音轨和特定的说话人物对应起来。此种方式为其后的语音识别领域提供了许多的可能性。譬如,音频多人声分离算法未来可能会应用于视频通话降噪、提升波束成形的质量和目标人识别等领域,并为传统的语音识别带来一个比较大的突破。
其中算法性能指标为在 interli7CPU 处理一个时长2 分钟的音频 时间不超过10 秒。
2 方案设计
通过对wav 进行数据读取以后,使用需要上下采样的参数(如16 000,8 000)构造好Kaiser Window,此后将wav数据数组传入到Kaiser Window 的FIR 滤波器中,通过位移纠偏,即可得到下采样以后的符合模型推理的8 kHz 的音频数组。此外,当模型推理完成后,将所得的数据再次输入Kaiser窗口的FIR 滤波器中进行上采样,即8 kHz 上采样到16 kHz。而后将上采样结果输出到wav 文件中。过程如图1所示。
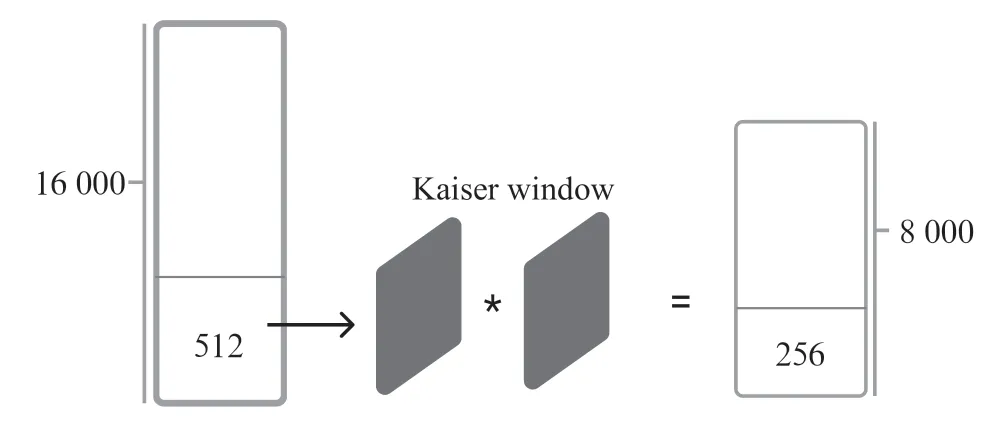
图1 Kaiserwindow 运行过程
由于目前大部分的电脑设备已经达到了6 核、8 核甚至10 核,因此在本项目中使用多线程并行化模型推理可以极大地加速推理,压缩推理时间。具体流程如图2所示。
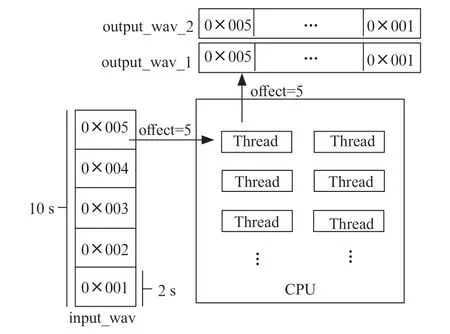
图2 并行推理流程
首先核心程序将wav 音频数据载入到verctor(内存)中,而后对wav 数据进行分割,使之大小符合模型的输入的规定。而后对分割出来的每组小音频数据数组进行偏移标记,如第一组标记偏移量为0,第二组标记偏移量为16 000。对每组数据,分别送入不同的线程进行推理。各线程完成推理后,按照偏移量将推理完成数据存放至所对应的位置。最终程序再将所有的数据加载到新建的三个wav 文件中一同输出到指定的位置。最终实现在10 s 的长音频中推理时间仅需0.48 s。
使用Microsoft Visual Studio 2019 进行开发,主要使用了Microsoft 所自研开发的ONNX 模型推理框架ONNXRunTime,并且使用C++多线程进行并行化推理优化、FIR 低通滤波进行上下采样、最终实现推理加速,VS 编程界面如图3所示。

图3 VS 编程界面
3 详细代码
下文给出详细代码:




4 实验结果
面对整个模型推理的程序工程化问题,我们使用了分而治之的思路。根据所要达到的目标(模型大小、性能、以及推理速度),我们分成了两个主要的工程进行问题的解决,分别是算法的实现以及模型工程优化。在本项目中,我们总共使用了3对模型进行训练、3个技术点对模型推理进行优化,从而提升整个模型的泛化能力以及推理的速度。最终项目实现了模型大小仅19.2 MB(FP32),推理速度0.48 s,参数量4.9 M,计算量(flops)为32.9 G,整个程序运行的思路为:
首先对wav 文件进行读取,产生一个verctor
根据sample rate,创建好Kaiser Window,而后将wav数据传入其中进行上下采样。
根据模型需要的大小,将音频进行切割成合适的片段,并传入到ONNXRunTime 框架中使用训练好的onnx 模型进行推理。每一个片段进行推理时都使用并行化的方法,最终10s 的音频分离速度可达0.48 s。
对推理完成的wav 数据数组,根据步骤2 的进行反向操作,构建Kaiser Window,并重新传入Kaiser Windows 进行上采样。使用原音频对分离出来的两条音轨进行滤波,产生最后的噪音音轨。将所得的三条wav 数据进行输出wav。整个过程的流程图如图4所示。
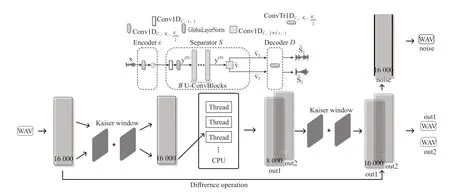
图4 软件执行逻辑图
最终可以实现在Windows 平台上面运行,提供了cmd命令行的方式对音频进行分离,其cmd 命令程序无需安装,仅需解压即可使用。真正做到了随解压随用,程序运行效果如图5、图6所示。
图5 核心推理程序运行压缩包内容

图6 核心推理程序使用界面
5 结 论
本系统在音频多人声分离功能的模型训练中处理了114 000 个(约合424 小时)Libri-mix,wsj0 和wham 噪音音频数据集,使用Libri-mix 噪声训练集以及wsj0 纯声训练集交替训练,在纯人声分离环境中达到17.5 dB SI-SDRi 的测试集性能指标,噪音环境中达到13.5 dB SI-SDRi 的测试集性能指标。最终获得模型大小仅为19.2 MB,训练时长约合1个月20 天,执行24 小时不间断训练。
此外,本项目结合数字信号处理课程以及综合软件工程思想,使用KaiserWindow 对音频进行上下采样,并且对推理过程进行了并行化优化,使得核心推理程序每推理10 s 的音频最快仅需0.48 s(i7-11800H 平台)。同时结合QT 进行开发的图形化界面,可以使得音频工作者处理音频更方便快捷,更好地解决了其需求。
猜你喜欢
现代电子技术(2022年12期)2022-06-14
数码世界(2019年6期)2019-09-09
电脑爱好者(2018年15期)2018-08-23
电脑爱好者(2018年6期)2018-04-23
艺术评鉴(2017年10期)2017-07-05
民主(2017年3期)2017-05-12
中学政史地·初中(2016年6期)2016-05-14
科技资讯(2016年7期)2016-05-14
计算机教育(2006年4期)2006-04-19
