
基于数据增强和神经网络的小样本图像分类
2022-10-15 15:54严家金
现代信息科技 2022年15期
严家金
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.安徽理工大学 环境友好材料与职业健康研究院(芜湖),安徽 芜湖 241003)
0 引 言
目前,深度学习已得到了广泛的研究和应用,深度学习的引入使图像数据集上的分类准确率得到了极大的提高,而这些模型大部分是基于卷积神经网络并且需要大规模的数据集,但在实际应用中存在着很大的局限性,例如在疾病诊断、害虫分辨、工业故障检测等方面都没有足够数量的样本去训练,这就是所谓的小样本学习。
小样本学习是从人类能够运用少量数据快速学习中得到的启发。当训练数据不足时,如何实现以及怎样获得一个具有良好性能和泛化能力的学习模型,是小样本学习的最终目的。小样本图像分类的学习模型基于卷积神经网络模型,一般分为两种:元学习和度量学习。基于元学习的小样本学习有两种:基于数据增强的小样本学习,基于模型优化的小样本学习。
对于小样本问题,多采用对抗生成网络(Generative Adversarial Nets, GAN)进行数据增强。虽然GAN能使用现有数据来缓解数据量不足的问题,但是标准数据扩充只能产生有限的替代数据。基于GAN改进的DAGAN模型可以从数据集中获取数据,并推衍生成同类数据项,是一种有效的数据增强模型。卷积神经网络VGG是牛津大学计算机视觉组和Google DeepMind公司一起研发的,不仅在ILSVRC分类和定位任务上取得极高的准确性,而且还适用于其他类型的图像识别。但在训练样本较少的情况下,单纯的VGG模型很难取得理想的分类结果。使用注意力机制能够使网络模型更加关注重要信息并且适当过滤那些与目标任务无关的信息,使模型能够在有限的样本下提取到更多的有效信息。
综合上述分析,本文为了解决样本数量不足的问题采用了DAGAN网络,在网络中输入图片能够按类生成多张图片以此来扩充样本。为了取得更好的分类效果,本文在VGG19中引入了注意力机制,在每个卷积层之后加入SE模块以提高分类准确率,最后对主动学习进行改进并结合DAGAN提出了主动数据增强学习(Active Data Augmentation Learning)策略,通过主动数据增强学习策略找到最利于分类的样本集大小,这样不但可以减少不必要的训练,而且还可以在有限的时间和资源的条件下,进一步提高分类的效率和准确率。
1 相关工作
1.1 数据增强对抗生成网络(DAGAN)
在DAGAN中生成网络模型由一个编码器组成,该编码器获取输入图像(class C),将其向下投影到低维空间。对随机向量(z)进行变换并与该向量连接;它们都将被传送到解码器网络,再由解码器网络生成增强图像。对抗网络模型经过训练,能够区分来自真实分布和虚假分布的样本。这样的对抗博弈训练能够使模型从旧图像生成同类但看起来完全不同的样本,能有效地扩大训练集,从而很好地解决训练样本数量不足的问题。
1.2 VGG
VGG在AlexNet的基础上进行了改进,在VGG中使用3个3×3卷积核代替7×7卷积核,使用2个3×3卷积核代替5×5卷积核。这是因为使用3×3卷积核在感受野不变的情况下可使参数和层数变得更深,并使用三个全连接层。同时验证了通过适当地加深网络结构能够提升性能。VGG结构图如图1所示。

图1 VGG结构图
1.3 注意力机制
注意力机制可以用人的视觉机制来直观地解释。例如,人类的视觉系统往往把注意力集中在图像中的某些重要信息上,从而会忽略一些不重要的信息。所以注意力机制也可以理解成在输入上不同的部分施加不同的注意力,去影响某个时刻的输出,这里的注意力就是权重。同时通过反向传播算法,使网络能够自适应地学习到最合适的权重参数。
2 主动数据增强学习和VGG-SE
2.1 VGG-SE和主动数据增强学习模型
在现实世界中,某些方面的某些类别只有少量的样本数据,但深度学习模型在很大程度上依赖大量的训练数据。那么在疾病诊断、人脸识别、临床实验、手写字体识别等在现实中只能得到较少样本的领域,深度学习模型的准确率是比较低的。因此,本文为了提高深度学习模型的分类准确率,同时缓解训练过程中样本数量不足的问题,提出了VGG-SE和主动数据增强学习。VGG-SE和主动数据增强学习模型结构如图2所示。

图2 VGG-SE主动数据增强网络模型
由图2可以看出,本文模型包含两个部分:引入注意力机制的分类网络(VGG-SE)和基于DAGAN的主动数据增强学习。VGG-SE用于样本的识别和分类,而主动数据增强学习则用来缓解样本数量不足的问题。
2.2 VGG-SE
为了提升VGG的性能,在VGG中引入注意力机制(即VGG-SE)来提高整体网络模型的分类准确率。由Momenta公司设计的SENET(Squeeze-and-Excitation Networks)在2017年ImageNET中荣获分类比赛的冠军,其提出的SE模块结构简单、易于实现,可以十分方便地加载到现有的网络模型中。SE模块能够根据不同特征通道的重要程度对通道进行排序,以此增强重要的通道,减弱不重要的通道。SE模块结构图如图3所示。

图3 SE模块结构
对输入特征图Z进行Squeeze操作,将它的每一个二维通道都变成一个具有全局感受野的实数,再使其变成1×1×C向量;再对这个向量进行Excitation操作,为每个特征通道生成权重;最后通过Scale操作,将计算得出的各通道权重和输入特征图Z相对应通道的二维矩阵相乘就可以得到输出特征图Z。
本文将SE模块加在VGG每一个卷积层的后面,以便在每次卷积之后都能对所获得特征图的每个通道进行加权处理,从而在每次训练过程中都能有效地提升有用的特征并抑制不重要的特征,如此进行良性循环达到更为准确的分类结果。改进的模型结构如图4所示。
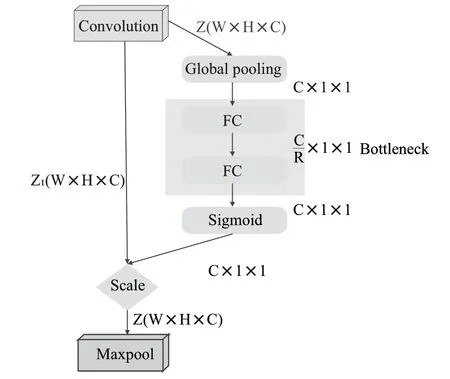
图4 VGG-SE模型结构
使 用Global pooling作 为Squeeze操 作,两 个Fully Connected层构成一个Bottleneck结构就可以去建模通道间的相关性,且输出与输入特征相同数目的权重。首先将特征维度降低到输入的1/(是经过训练后得到的参数),再经过ReLu函数激活后通过Fully Connected 层回到之前的维度,通过Sigmoid函数获得0~1之间归一化的权重,最后对归一化后的权重进行Scale操作加权到每一个通道的特征上。
2.3 主动数据增强学习
事实证明深度神经网络学习存在着训练时间过长、计算量过大、过拟合、欠拟合等各种问题。为了适当缓解这些问题,本文对主动学习进行改进,提出了主动数据增强学习策略。
学习策略主要包括两大部分:
(1)让各个类别的少量样本构成初始训练集(),用经过训练DAGAN的每50轮生成的样本数据集作扩充训练集(,,),再用初始训练集去训练网络模型VGGSE,按类别计算模型输出的loss,当某类别的loss大于预先设定的阈值时,则向该类别加入扩充训练集,在该类别输出的loss小于预先设定的阈值时则停止扩充。
(2)对每个类别进行标号(分别为1,2…),每个初始训练集为,…X,,…I为其对应的扩充训练集,L为每个类别输出的loss值,设计一个分段阈值=0.2、=0.1、=0.05。训练总共分为2轮,前轮时L与比较,中间/2轮时L与比较,后/2轮时L与比较轮时比较;当L大于阈值时则向该类别加入扩充训练集,若小于阈值则不用加入。
主动数据增强学习结构示意图如图5所示。

图5 主动数据增强学习结构示意图
3 实验和分析
3.1 数据集描述
为了测试所提出改进模型的有效性,采用MiniImageNet和Omniglot两个数据集。MiniImageNet数据集包含100个类,每100个类都有600张图片,每张图片的大小为84×84。Omniglot数据集包含50个不同的字母及其1 623个不同的手写字符,每个字符都有20张图片,通过将图片进行90°、180°、270°旋转来扩充训练集。
MiniImageNet数据集信息描述如表1所示。

表1 MiniImageNet信息描述
Omniglot数据集信息描述如表2所示。

表2 Omniglot信息描述
3.2 实验结果与分析
改进模型在两块Tesla P100 16 GB的显卡上进行训练和测试。本文改进的模型使用VGG19作为主干网络,输出层采用Sigmoid激活函数,其他层均采用Relu激活函数。
在实验中,改进模型的训练初始学习率设置为0.001,训练总轮数为2轮,前轮时loss值与主动数据增强学习中的阈值比较,中间/2轮时loss值与比较,后/2轮时loss值与比较;当loss值大于设定的阈值时则向该类别加入扩充训练集,若小于阈值则不用加入,学习率每次下降百分之零点一,在本次实验中使用MiniImageNet数据集的运行轮数为400轮,使用Omniglo数据集的运行轮数为200轮。通道数从3通道扩充到64,从64扩充到128,从128扩充到256,再从256扩充到512,在每一层扩充通道的时候加上SENet对通道追加注意力机制,在对通道进行注意力操作时,首先对通道进行压缩,在通过Sigmoid激活函数学习训练权重后,对通道进行还原。实验结果如表3、表4所示。

表3 在MiniImageNet数据集上的实验结果
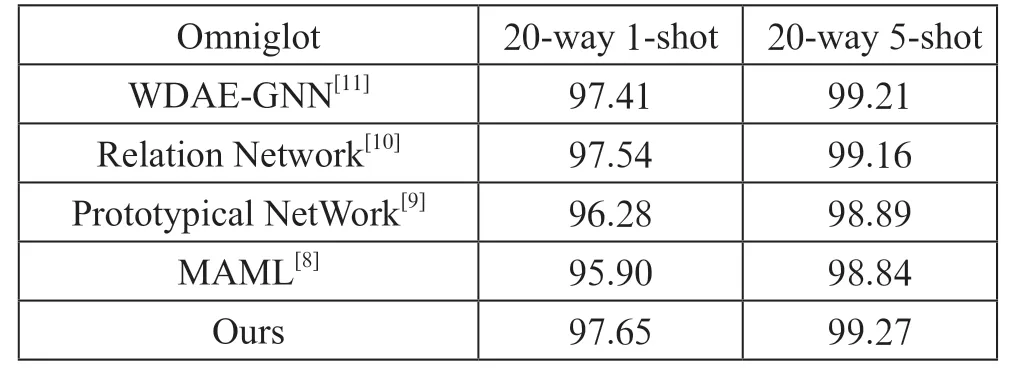
表4 在Omniglot数据集上的实验结果
由表3和表4可以看出,在MiniImageNet数据集中,本文提出的方法在5-way 1-shot方式中的测试准确率比其他实验模型平均高2.98%,在5-way 5-shot方式中的测试准确率比其他实验模型平均高2.67%;在Omniglot数据集中,本文提出的方法在20-way 1-shot方式中的测试准确率比其他实验模型平均高0.86%,在20-way 5-shot方式中的测试准确率比其他实验模型平均高0.24%。这是因为本文通过设置阈值对loss值的时刻关注,在避免网络过拟合的同时,在不同阶段加入新的训练样本,使网络的鲁棒性更好。实验中对通道进行压缩可以适当降低学习成本。在每经过一个大的特征提取层时,网络就能学习到更多抽象的高维特征,紧接着通过对通道注意力机制的关注,使网络能够轻松捕捉到各个类别间的差异,从而使得在样本数量越少、类别数量越少时,本文模型可以取得较好的分类结果。
4 结 论
本文提出了主动数据增强学习,并在已有的网络VGG上引入了注意力机制。主动数据增强学习能够有效地缓解在小样本分类中样本数量不足的问题,用DAGAN进行数据增强能生成大量的同类型样本,再通过主动数据增强学习合理使用训练集的样本量防止过拟合或欠拟合。在VGG中引入注意力机制能通过不同的通道去提升重要的特征或抑制不重要的特征从而提高网络的分类效果。实验证明,本文提出的方法在MiniImageNet数据集和Omniglot数据集上都取得了比基准模型更好的效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年11期)2022-06-14
计算技术与自动化(2022年1期)2022-04-15
科技研究(2021年15期)2021-09-10
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
分析化学(2017年12期)2017-12-25
