
小儿川崎病并发冠状动脉损伤的危险因素分析
2022-10-13 03:22姚小飞潘晓明
蚌埠医学院学报 2022年9期
姚小飞,潘晓明,王 丽
川崎病是一种以急性、热性出疹,累及全身中小血管的非特异性炎症性疾病,好发于儿童群体,其中病情严重时可合并冠状动脉损伤(coronary artery lesion,CAL) ,具体表现为冠状动脉炎性浸润型损伤导致血管平滑肌坏死、血管弹性下降,并逐步引发冠状动脉瘤或冠脉狭窄,最终引发后天获得性心脏病,严重影响患儿预后,故早期发现并干预小儿川崎病的CAL对于改善其预后而言至关重要[1-2]。近年来,临床上对川崎病的诊断和治疗愈发重视,川崎病患儿的诊断率明显提高,如何提高预测川崎病患儿合并CAL的风险评估正成为业内关注的热点。基于文献分析可知,25羟基维生素D缺乏[3]、心电图QT间期变化[4]、降钙素升高[5]、白细胞计数升高[6]等是诱发小儿川崎病合并CAL的危险因素,但不同研究报道的危险因素不尽相同,且缺少基于危险因素预测模型的分析和对比研究。本研究将基于现有研究对川崎病合并CAL的危险因素进行深入研究,同时采用多种预测模型对模型进行优化、改进和横向对比,旨在为小儿川崎病并发CAL的临床早期预防和干预提供指导。
1 对象与方法
1.1 研究对象 收集2017年1月至2021年7月我院小儿内科收治的82例川崎病患儿的临床资料,其中完全川崎病患儿62例和非完全川崎病患儿20例;合并有CAL者纳入观察组30例,未合并有CAL者纳入对照组52例。观察组中冠状动脉扩张共19例(63.33%),冠状动脉瘤11例(36.67%)。
1.2 诊断标准 川崎病诊断标准:符合2017年美国心脏协会(AHA)发布的川崎病诊治指南[7],包括:(1)草莓舌,口唇口腔黏膜及咽部黏膜弥漫性充血;(2)双眼球结膜充血,但无分泌物;(3)四肢末端出现四掌跖红斑或表现为“袜套样”脱皮;(4)存在多形红斑;(5)早期出现颈部单侧淋巴结肿大,直径多超过1.5 cm。满足上述任意4项即可明确诊断。
CAL诊断标准[8]:0~3岁患儿冠状动脉内径>2.5 mm,3~9岁患儿冠状动脉内径>3.0 mm,>9岁患儿冠状动脉内径>3.5 mm,或冠状动脉内径超过紧邻1.5 倍以上。符合上述任意一条即可诊断为川崎病合并CAL。
CAL分级:轻度扩张,明确处在冠脉病变,且冠状动脉内径≤4.0 mm;中度扩张,明确存在冠脉病变,且冠脉内径在4.0~8.0 mm之间;巨大冠脉瘤,冠状动脉内径超过8.0 mm。
1.3 纳入与排除标准 纳入标准:符合川崎病合并CAL 病变的诊断标准;已排除渗出性结膜炎、渗出性咽炎溃疡性口腔炎、大疱性或水疱性皮疹、全身淋巴结肿大或脾肿大;实验室、化验室指标支持川崎病诊断。排除标准:合并有其他疾病者;实验室检查或临床病历资料不全者。
1.4 资料收集以及变量定义 (1)人口学因素:性别、年龄;(2)实验室指标:C反应蛋白、白细胞计数、血小板计数、血红蛋白、血沉、血钠、血清白蛋白;(3)临床症状:发热持续时间。根据《川崎病诊断指南第6次修订版》[9]及我院病史资料数据收集情况,将年龄、性别、发热持续时间、C反应蛋白、白细胞计数、血小板计数、血红蛋白、血沉、血钠、血清白蛋白共10项自变量进行了分组定义用于统计研究。
1.5 分析模型
1.5.1 logistic回归模型 对2组川崎病患儿的一般资料、临床资料进行单因素对比分析,随后将有统计学差异的单因素纳入logistic多因素回归模型明确独立危险因素,并验证logistic回归分析模型的诊断效能。
1.5.2 随机森林模型 利用R语言中的randomForest包实现随机森林,并计算得到各指标的平均最小基尼指数,随后根据指数权重大小判断变量的重要性,并根据模型受试者工作特征(ROC)曲线下AUC面积最终决定所纳入的具体危险因素。
1.5.3 XGboot模型 XGBoost是eXtreme Gradient Boosting的缩写称呼,其是一个非常强大的Boosting算法工具包,在计算效率、缺失值处理、控制过拟合、预测泛化能力方面表现优秀,具体流程为:(1)训练集与测试集划分。每组患儿按照7∶3的比例随机分为训练集和测试集。(2)模型改进。为确保模型稳定,本研究采用10倍的交叉验证来评估模型的预测能力。训练组被随机分成10组。在每次10倍交叉验证的迭代中,随机选择9组进行训练,剩下的组作为测试集。这意味着每个小组依次被选作测试集,以确保评估结果不是偶然的。然后对10个评估结果进行平均,以减少由于测试集中不合理的选择所造成的误差。为了获得XGB模型中的总体最优值,我们采用学习曲线法来寻找最优参数。其中横坐标轴代表树木数量和不同的学习率,纵坐标轴代表10倍交叉验证的平均AUC。最优参数组合为:树的数量( "n tree" ) = 92,学习率("eta") = 0.3,从根节点到叶节点的最大长度( "max depth" )= 3 ,最小叶节点样本权重之和( "min childweight" )= 1,L2正则化参数( " reg lambda" )= 120。所有其他参数都被选为默认值进行计算。(3)模型性能评价。使用受试者工作特征(ROC)曲线分析对模型判别进行量化,并用ROC曲线得到的AUC对其预测精度进行评估。
1.6 统计学方法 采用χ2检验和logistic回归分析,采用R语言进行随机森林模型和XGB模型研究。
2 结果
2.1 基于logistic回归分析的小儿川崎病合并CAL危险因素分析 单因素分析结果显示,不同组别患儿的性别、发热持续时间、C反应蛋白、白细胞计数、血小板计数、血沉、血钠、血清白蛋白比较,差异均有统计学意义(P<0.05~P<0.01)(见表1)。

表1 川崎病合并CAL高危因素单因素分析
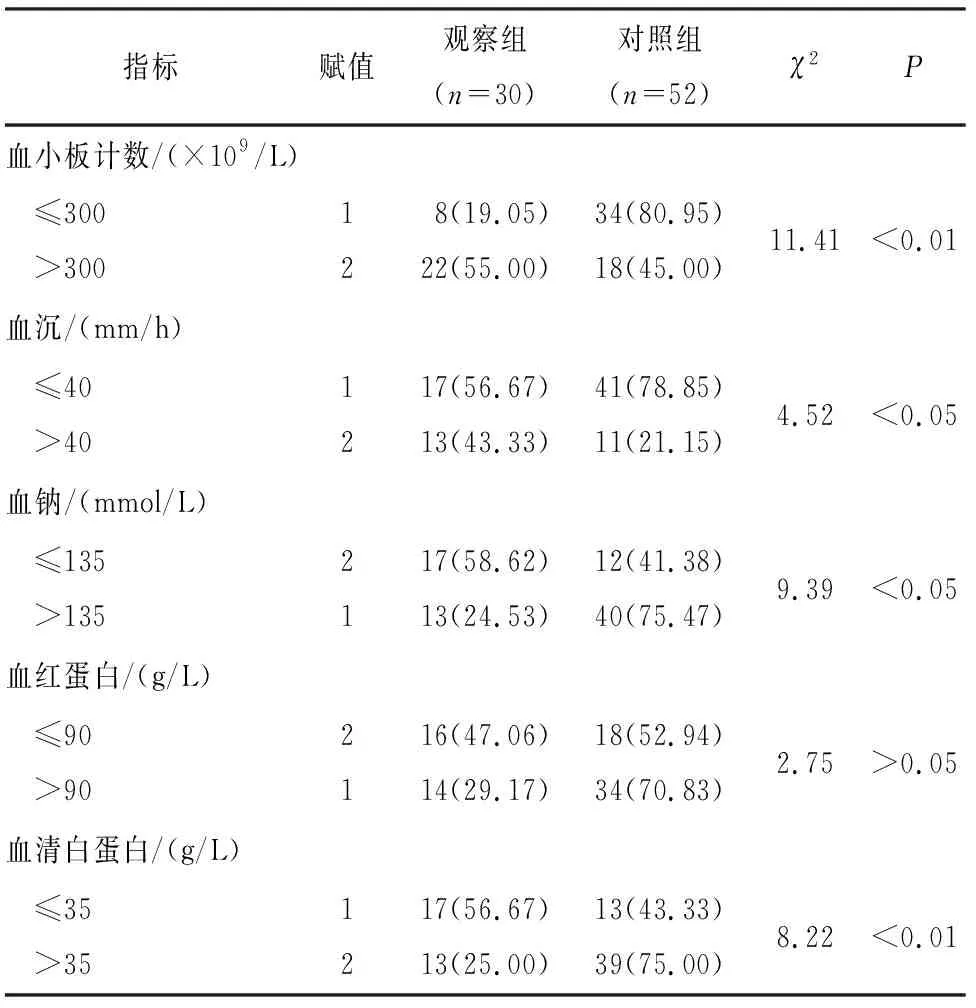
续表1
将小儿川崎病是否合并CAL作为因变量,将上述有统计学差异的因素作为自变量纳入条件logstic回归模型分析,结果显示发热持续时间、血小板计数、白细胞计数、C反应蛋白、血钠是川崎病患儿发生CAL的独立危险因素(P<0.05~P<0.01)(见表2)。
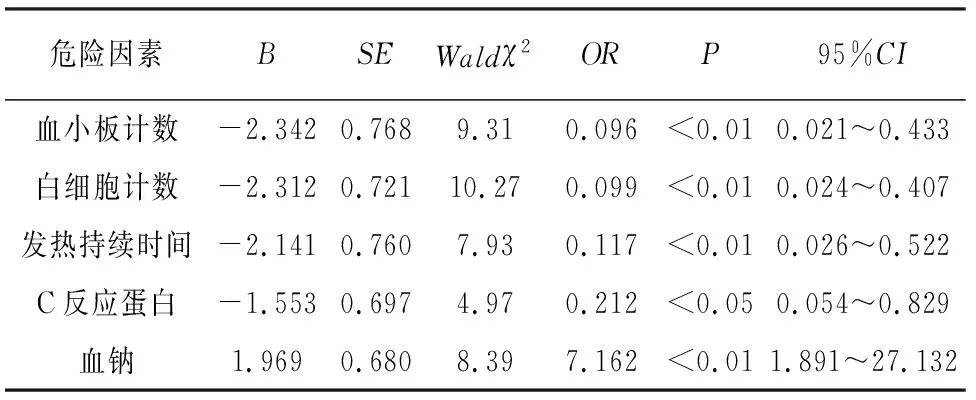
表2 小儿川崎病合并CAL的多因素logistic分析
2.2 基于随机森林模型回归分析的川崎病合并CAL危险因素分析 随机森林模型因其抽象概念的限制,无法呈现出可视化的结构图,具体通过R语言实现,通过建模和数据分析发现不同影响因素的影响权重因素从高到低排序依次为白细胞计数、C反应蛋白、血小板计数、血清白蛋白和血钠(见图1)。

2.3 XGB模型危险因素分析 基于XGB模型分析可知,影响川崎病患儿发生CAL的独立危险因素包括血小板计数、血钠、血清白蛋白、白细胞计数及发热持续时间,各因素的影响权重大小见图2。

2.4 模型性能评价 基于logistic回归模型分析所得的独立危险因素预测小儿川崎病合并CAL的敏感性为86.50%,特异性为80.00%,约登指数为0.665,AUC面积为0.895;基于随机森林模型分析所得的危险因素预测小儿川崎病合并CAL的敏感性为86.70%,特异性为73.10%,约登指数为0.598,AUC面积为0.841;基于XGB模型分析所得的危险因素预测小儿川崎病合并CAL的敏感性为100%,特异性为80.00%,约登指数为0.800,AUC为0.963,XGB模型的预测效能优于logistic回归模型和随机森林模型(见表3)。

表3 3种危险因素分析方法效能ROC分析
3 讨论
小儿川崎病多发于5岁以内的婴幼儿,且以男孩为主,其首发临床表现多为全身血管炎[10],而CAL则是川崎病发病过程中一种较为严重的并发症,具体机制可能与川崎病引发血管炎症反应后激活细胞因子联级反应,导致血管通透性增加有关[11]。目前,临床上已经十分重视小儿川崎病合并CAL的预防和治疗,对小儿川崎病合并CAL的危险因素进行深入分析,对于早期预防和干预而言意义重大。基于文献分析可知,不同研究所论证的小儿川崎病合并CAL的危险因素不一,这一方面考虑与儿童病例的来源、病例特征、临床表现可能存在一定差异,另一方面考虑与危险因素的分析方法不同有关。不同研究病例的均一性并无法很好平衡,但对比不同危险因素分析方法则有助于进一步深化小儿川崎病合并CAL危险因素,为今后预测模型的研究创造良好的条件。传统的危险因素分析方法为logistic回归分析方法,这一分析方法较为成熟,在临床中的应用十分广泛,但分析所得的危险因素之间可能存在共线性的问题,继而导致基于logistic回归分析构建的预测模型、列线图模型的预测效能并不十分理想。机器学习和数据分析技术的快速兴起令临床影响因素研究有了更多的选择,其中随机森林模型和XGB模型是近几年来热门的临床预测模型研究工具,蓝潞杭等[12]基于随机森林模型预测了预测急性心肌梗死后急性肾损伤的风险,王铭等[13]基于XGB模型建立了COVID-19病人重症风险早期预测模型,而目前现有关于logistic回归模型、随机森林模型、XGB模型的横向对比研究,故本研究以此为切入点进行了回顾性分析研究。
单因素分析结果显示,结果显示发热持续时间、血小板计数、白细胞计数、C反应蛋白、血钠是川崎病患儿发生CAL的独立危险因素,与陈秋阳等[14]报道结果基本一致。川崎病患儿出现低钠血症者多同时合并血清白蛋白的降低和C反应蛋白的异常升高,而这些因素均为川崎病合并CAL的高危风险,其中低钠血症对川崎病病情的影响可能与血管内皮细胞通透性改变有关,且多与发热持续时间相对应,发热持续时间越长,发生低钠血症的风险越高[15]。此外,血清白蛋白的降低提示川崎病患儿存在低蛋白血症,这会导致患儿对静脉用免疫球蛋白(IVIG)的治疗效果大打折扣。ANDERSON等[16]研究表明川崎病合并CAL的危险因素包括:男性、婴儿、 白细胞计数>12×109/L、C反应蛋白强阳性、红细胞压积<0.35、白蛋白<35g/L、血小板计数>450×109/L、热程大于10 d 等,这与本研究结果存在一定的差异。本研究并未发现性别因素对小儿川崎病合并CAL存在显著影响,但在单因素分析中的确证实了性别因素为相关影响因素,笔者分析认为性别因素仅为小儿川崎病合并CAL的相关因素,但其影响权重并不高,其原因与川崎病的发病特征、发病特点有关,该病的临床表现并无显著的性别差异,且临床特征与遗传因素无关,故在疾病发展、发展过程中性别因素的影响被逐步弱化。
基于随机森林模型结果可知,不同影响因素对小儿川崎病合并CAL的影响权重不一,基于模型内部逻辑和推算可知影响权重因素从高到低排序依次为白细胞计数、血清白蛋白、血钠、C反应蛋白和血小板计数,白细胞计数的临床参考价值较高,这与川崎病的发病机制相契合,且刘芳等[17]报道指出,小儿川崎病合并CAL病人多伴有IL-6、IL-10、TNF-α的异常升高,而这些因素均与机体炎症反应的发生、发展密切相关。横向对比显示,随机森林模型所推算的危险因素与logistic回归模型所推算的共同危险因素包括血小板计数、白细胞计数、血钠及C反应蛋白,区别在于logistic回归模型还纳入了发热时间,随机森林模型则纳入了血清白蛋白。从疾病发生、发展角度分析,发热时间可反映疾病的进展阶段,但这一指标并不特异,且体温升高程度不同对疾病发展的提示作用不同,而血清白蛋白作为评价肝功能和机体营养状态的客观指标,其临床参考价值可能更高,且特异性更高。从AUC面积对比可知,logistic回归模型与随机森林模型之间并无显著差异,模型预测效能均较理想,说明这两种分析方法的可信度均较高。
在本研究中纳入了XGB模型,这一模型在计算机领域、教育学领域、管理学领域中的研究较为成熟,其优势性已经得到了充分证实,且该模型内嵌有决策树模型,可分析出关键影响因素并按照权重大小进行排序,且危险因素的预测精度十分理想(AUC=0.963),且与随机森林模型和logistic回归模型相比优势明显,这提示基于XGB模型分析得到了小儿川崎病合并CAL的影响因素可信度极高,基于上述因素构建的临床预测模型的效能十分良好,在今后后续研究中可通过外部数据对该模型进行进一步验证。本文的不足之处在于样本量相对偏低,82例川崎病患儿中包含有完全川崎病患儿和非完全川崎病患儿,2组病例数相差较差,在进行合并CAL的风险组间数据对比时可能会出现较大偏倚,希望今后可以继续收集相关病例,增加研究样本量,进一步探究比完全川崎病患儿与非完全川崎病患儿合并CAL的风险因素并制定相应的风险预测模型。
综上所述,logistic回归分析、随机森林模型、XGB模型均可用于小儿川崎病合并CAL危险因素研究,其中XGB模型的预测效能最为良好,所演算出的影响因素按照权重大小依次排序为血小板计数、血钠、血清白蛋白、白细胞计数和发热持续时间。
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
爱你·健康读本(2020年4期)2020-04-30
数学大王·低年级(2019年8期)2019-08-27
健康人生(2018年8期)2018-05-14
家庭医学(2017年8期)2017-09-06
祝您健康(2014年9期)2014-11-10
中华养生保健(2013年8期)2013-09-17
