
基于多核CPU的多源异构数据库信息快速同步研究
2022-10-13 05:13杨波邓欣王鑫章萧阳彭程刘绪清
中国信息化 2022年9期
文|杨波 邓欣 王鑫章 萧阳 彭程 刘绪清
多源异构数据库之间的信息同步对实现网络数据实时共享具有重要的意义,但是由于多源异构数据库信息量庞大,导致数据同步处理流程较长,数据整合度不高,多源异构数据库信息同步速度较慢,针对该问题我们研究了基于多核CPU的多源异构数据库信息快速同步方法。以多核CPU并行执行任务的模式为基础,控制处理数据的流程和时间。整合多源异构数据,设计快速同步触发模块,优化信息同步速度,以此实现多源异构数据库信息快速同步。测试结果表明,此次研究的数据库信息同步方法所用的平均时间与传统同步方法相比缩短了7.33s,达到了本次研究的预期。
互联网技术的飞速发展及云平台的普及为社会大众的日常工作和生活带来了一定的便利,与此同时大量的网络用户行为产生海量的信息,并且信息的形态和来源也日渐丰富,导致单一的数据模式已经不足以全面精确地概括用户特征。多源异构数据库的应用,能够使不同的信息应用系统之间建立密切联系,一定程度上缓解了因信息孤岛问题对互联网数据处理系统造成的压力。但由于多源异构数据本身性质差异较大且载体类型较为多样,数据处理过程中融合难度较高,因此在进行数据库信息同步时速度较慢,整体效果不理想,很难在较短时间内实现不同系统和设备间的数据移动及共享。为了提高多源异构数据库信息同步的速度,业界学者及相关人员研究了不同类型的信息同步方法,但是其应用效果均不理想。此次研究在现存的多源异构数据库信息同步方法的基础上,针对传统方法存在的问题引入多核CPU的处理方法,以期进一步提升多源异构数据库信息同步速度。
一、基于多核CPU并行处理数据
多核CPU,即多核处理器,通过在同一块芯片中植入多个处理器实现数据处理系统的高度并行,以此提高处理数据的能力和速度。多核CPU的大致架构如图1所示。
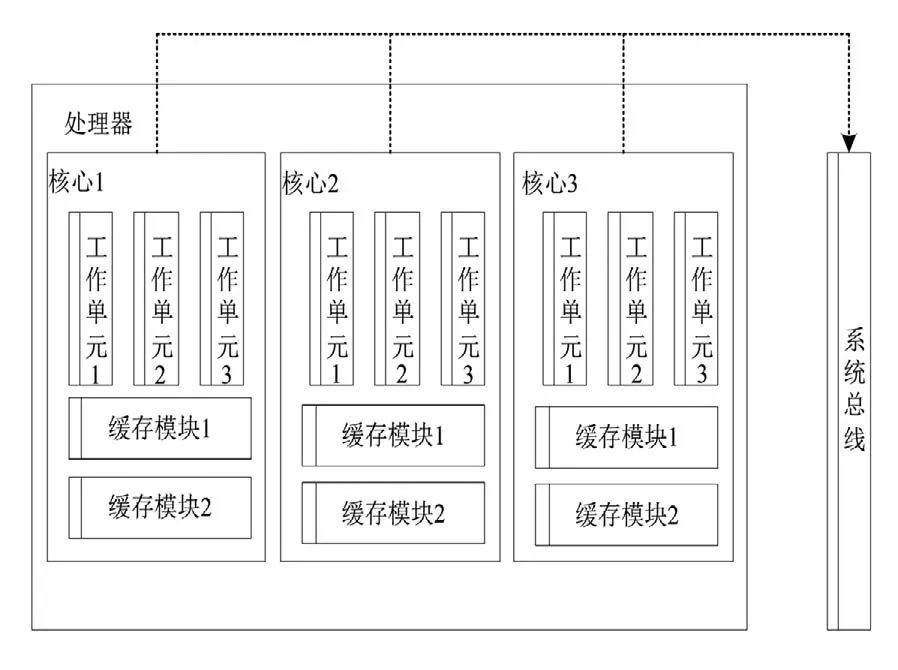
图1 多核CPU并行运行架构图
从图1中可以看出,在多核CPU的运行过程中,多个数据处理核心之间具有并列执行的关系,CPU先将接收到的任务指令进行解析并向每个独立的核心分配任务,核心中的工作单元负责具体执行,并反馈执行结果。在此基础上可以计算使用多核CPU并行处理数据与传统的串行处理模式之间的加速比:

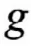
二、 整合多源异构数据
多源异构数据库拥有丰富的数据源,其数据结构也包含数字、图像、影像等多种形式。在对多源异构数据库信息进行同步时,庞大且杂乱的信息内容极有可能成为降低信息同步速度的主要原因,因此在进行信息同步操作之前,利用去噪算法对数据库中的操作对象进行整合,通过删减噪声数据精简需要同步的多源异构数据,从而加快信息同步的速度。利用聚类算法对数据对象进行分类和筛选,具体方法如下式:
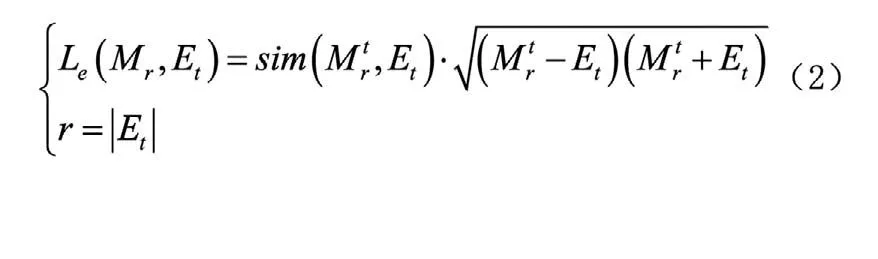
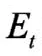


三、设计快速同步触发模块
设计快速同步触发模块的核心是在数据库中设置触发器,当触发器接收到指令时会即刻根据指令内容执行操作,并将每一次执行的操作指令的数据对象写入触发器中的日志表,当多源异构信息发生变动时,日志表也会触发更改操作,避免同步信息中进行更改指令的重复操作,以节省多源异构数据库信息同步所需的时间。触发模块的运行流程如图2所示。
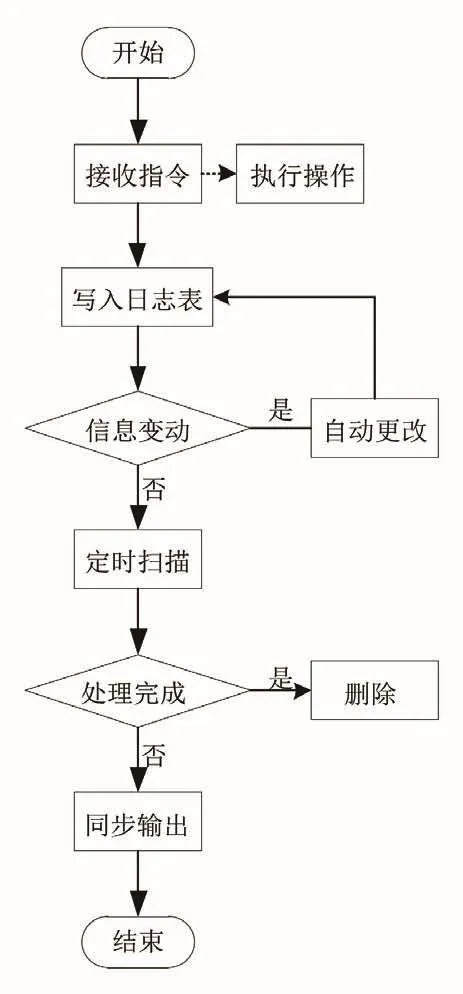
图2 快速同步触发模块运行流程
本次研究目标是加快触发模块运行速度,在其运行流程中加入对数据的定时处理程序,定期对日志表进行扫描,删除已经完成同步的信息,减少因重复同步日志表中的信息内容而浪费的时间,进而实现多源异构数据库信息的快速同步。
四、 应用研究
(一) 实验准备
为测试此次本文所提出的多源异构数据库信息快速同步方法在实际应用中的效果,选取某数据库K作为实验对象,利用本次研究的信息同步方法对数据库K中不同类型的信息进行同步操作,对所用的时间进行记录,对照组为传统同步方法所用时间,通过两者对比判断本文研究的多源异构数据库信息快速同步方法是否具有可行性。
(二) 实验结果反馈
本次实验将分别选取数据库K中的字符数据及图像数据进行同步操作测试,以规避数据结构类型不同对实验结果产生的影响。实验阶段将对选取的多源异构数据进行十次同步测试,分别记录实验组和对照组所用的时间,其具体结果如表1所示。
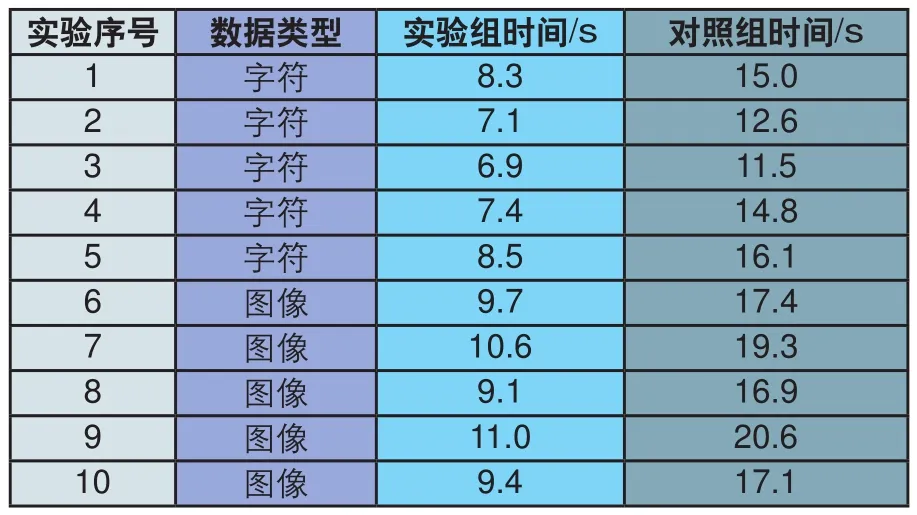
表1 数据库信息快速同步测试结果
观察表1中的实验数据可以发现,对于字符数据的同步,实验组所用时间均少于9s,对照组时间均大于10s;对图像数据进行信息同步时,实验组所用时间均不超过11s,对照组时间均超过17s。通过计算得出,在对多源异构数据库K进行信息同步实验测试中,实验组所用的平均时间为8.8s,对照组所用的平均时间为16.13s,实验组的平均同步时间较对照组缩短了7.33s,证明本次研究方法的有效性。
五、结束语
本次研究在明确传统信息同步方法现存问题的基础上,有针对性地引入多核CPU并行处理数据的技术和模式,为多源异构数据库信息快速同步提供了新的可行方法和途径。然而,对多源异构数据进行整合主要依靠去噪处理过程与触发模块,因其数据差异性较大,此过程容易出现误差,从而对数据库信息同步的准确性产生负面影响。今后可以优化去噪处理过程与触发模块,对多源异构数据进行更为精确的分类和整合,确保其过程准确性的同时,进一步加快多源异构数据库信息同步的速度。
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
当代体育(2021年7期)2021-09-10
福建基础教育研究(2019年12期)2019-05-28
福建基础教育研究(2019年11期)2019-05-28
现代养生·下半月(2018年7期)2018-09-12
师道·教研(2017年4期)2017-04-22
财经(2017年2期)2017-03-10
中学生物学(2016年11期)2016-12-13
财经(2016年15期)2016-06-03
