
针对无人潜航器的反潜策略研究
2022-10-10 08:14张鸿强李厚朴
系统工程与电子技术 2022年10期
曾 斌,张鸿强,李厚朴
(1.海军工程大学管理工程与装备经济系,湖北 武汉 430033;2.海军工程大学导航工程系,湖北 武汉 430033)
0 引 言
无人潜航器(unmanned underwater vehicles,UUV)具有长期水下自主航行能力,经常用于在水下执行搜集舰艇声纹、侦察与监视、反潜警戒、探测海底地势和资源等各类任务[1-2]。近年来,在很多重要海域经常发现UUV的出没,疑似用于搜集我方舰艇信息、海上实验数据以及重要海域的水文情报[3],甚至日本在2018年12月新版的《防卫计划大纲》中公开宣布计划在钓鱼岛等海区部署新型UUV,这些对我国海洋国土安全构成极大威胁[4],因此针对敌方UUV入侵的反潜方法研究日益重要。
UUV入侵与潜艇入侵相比有几点不同:体积小,噪声低,隐蔽性更强;经常多艘同时入侵;可用于长时间自主监测,且具有一定反搜索能力;具有军民难分的特点,法律地位模糊[3-4]。这就导致针对UUV入侵的反潜作战更为困难。针对潜艇的常规反潜行动需要通过派遣反潜巡逻机或直升机等手段搜潜,判断出潜艇的初始位置,然后在一个预估范围内展开搜索[5-6]。而UUV隐蔽性更强,许多情况下只是根据不确定的情报线索,例如渔民报告或声纳网络的疑似预警,怀疑有不明水下装置在我方利益区域(例如海上试验区、关键航道或油气田区)活动,由于缺少明确定位,起始搜索范围较大。同时针对多艘UUV情况,我方搜潜平台还需要协同工作,这更加大了反潜难度。另外,利用反潜巡逻机和直升机进行UUV搜潜的费效比也较低,而利用UUV侦搜UUV更加可行,这就要求反潜UUV能够自主探测、协同并跟踪敌方UUV。
从公开文献看,除了一些非正式的网上相关报道,尚未查找到专门针对UUV的反潜研究学术性论文,但针对潜艇的反潜研究一直是研究热点。例如,上下文感知的反潜任务决策支持方法[7]利用隐马尔可夫模型对反潜资源分配和搜索路径规划问题进行了数学建模,并采用进化算法对数学模型求解。随机反潜巡逻算法[8]认为利用现有技术难以在开放海域侦搜潜艇,为此提出在被岛屿等地形限制潜艇行动的海域进行巡逻监测的路径规划算法。反潜资源优化部署算法[9]把反潜任务看作有限时间范围内的零和博弈,并利用线性规划算法求解出优化策略。反潜规划辅助工具[10]针对分布在多海域的多个反潜任务,利用线性规划对不同类型的反潜装备分配问题进行了建模和求解。文献[11]对文献[10]的线性规划模型进行了扩展,加入了时限参数。但以上反潜研究都是以数学规划模型作为理论基础,适用于只有单个水下目标(一个潜艇)的确定性环境。
另外,近年来博弈论、深度强化学习等方法在国土安全的资源调度领域日益得到重视。例如,文献[12]基于博弈论建立了攻防资源分配模型。文献[13]针对海岸安全巡逻问题,基于量子反应模型对敌方目标进行行为建模,利用攻防Stackelberg博弈模型设计了海岸巡逻调度算法。文献[14]把强化学习引入到多人博弈中,并提出了软团队(actor-critic,AC)算法求解团队协作问题。文献[15-16]提出了深度虚拟博弈算法求解环保领域的资源分配问题。尽管这些研究更多的是关注陆地上安保资源的分配及巡逻问题,与反潜规划有较大差异,但从中可以看出机器学习、多智能体学习等新兴技术在博弈论领域能够解决某些传统线性规划算法难以计算的问题。
为此,本文设计了一个两阶段反潜规划算法。提出了基于强化学习AC算法(actor-critic,AC)的鲁棒性部署策略学习算法,用以计算不确定环境下的资源部署问题;提出了基于多智能体强化学习的搜潜策略学习算法,用以计算团队攻防环境下的搜潜路径规划问题。针对敌方目标噪声低和具有自主行为模式的特点,在强化学习的马尔可夫决策模型中加入了综合反映声纳探测概率和海区重要度的奖励值设计;针对不确定的敌方目标分布情况,在强化学习中引入参数扰动机制提高算法的鲁棒性。由于本文反潜算法不仅适用于UUV,同样也能用于常规潜艇,所以后文敌方目标通称为水下探测器。
1 反潜问题的指标设计
假设反潜海域划分为I个网格区域或分区,每个网格可看作一个包含深度的长方体,符号i={1,2,…,I}表示反潜分区的计数下标,反潜指挥人员可以按照优先级定义每个反潜区域的重要性,用ui表示。反潜博弈过程包括J+K个运动物体,其中包含J个敌方水下目标和K个我方搜潜平台,符号j={1,2,…,J}表示水下目标的下标,k={1,2,…,K}表示我方搜潜平台的计数下标,敌方水下目标和我方搜潜平台作为多智能体运行。反潜的目标是:通过我方搜潜平台智能体的分工协作,在降低我方重要反潜海域威胁度的同时,提高对敌方水下目标的检测率。
首先定义威胁度指标,表示j号敌方目标对i号分区的威胁程度,用TIij表示。设Dist(i,j)表示j号目标与i号分区之间距离,则当Dist(i,j)越大且i号分区重要性u i越小时,威胁度越低,所以TIij定义如下:
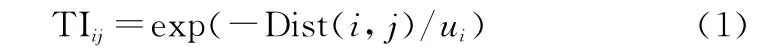
第2个指标为目标探测率。复杂多变的海洋环境会产生水下声波传播的功率损耗,其中回波、环境噪声等都会极大地影响搜潜平台声纳系统的传感性能[17]。搜潜常用的主动声纳的声信号流程为:换能器阵发出声波,通过海水传播至目标,在目标物产生散射/反射,经过海水传至接收换能器阵,其探测方程如下:
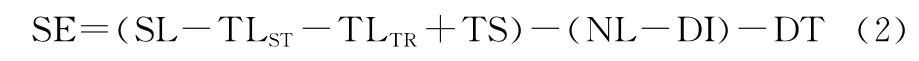
式中:SE(以dB为单位)表示信号余量,作为声纳探测性能的指标;SL为声纳级别,表示声纳发射器发出的声波量;TLST和TLTR分别表示从声源(搜潜声纳)至水下目标和从水下目标至声源之间的传输损耗;TS为目标强度,表示目标物反射/散射的能力;NL表示周围海洋环境的噪声级别;DI和DT分别表示方向性增益和检测阈值。
在此基础上,为了反映声纳探测的不确定性,本文利用概率模型计算搜潜声纳探测水下目标的能力。该模型同样适用于被动声纳方程。
当第k个搜潜平台获得的第j个水下目标的回波信号余量为SEjk时,定义第k个搜潜平台对第j个水下目标的探测概率为

式中:Φ是正态分布概率函数;σ为标准差,一般取3~9 dB之间[7]。当不考虑声纳、环境和目标的随机性时,P jk仅为j号敌方目标和k号搜索平台之间距离的函数。
2 部署策略的学习
本文把搜潜攻防过程划分为两个阶段。第1个阶段为资源分配,在这个阶段我方把搜潜平台部署到不同的网格分区,这也代表了搜潜开始时的起始位置。对应地,敌方也在这个阶段部署不同数量的水下探测器至对自己占优的网格海区。第2个阶段为搜潜阶段,在这个阶段敌方水下探测器在我方反潜海域活动,试图探测甚至攻击我方重要设施,而我方搜潜平台则需要在保护我方重要海域的同时搜索破坏敌方水下探测器目标。
本节描述部署阶段敌我双方攻防博弈采用的分配策略。
2.1 资源分配模型
分配模型基于不确定性马尔可夫决策过程[18]建立,利用四元组[S d,A d,T d,R d]表示。状态S d=[a t-1,u t-1],a t-1表示我方在t-1时间段的动作,为资源分配方案矢量,表示每一个反潜分区内指派的搜潜平台数量,总数量小于等于我方搜潜平台资源总量,例如a=(2,1,2,0,0)表示在第1~第3号反潜分区指派搜潜平台数量分别为2、1、2,其他分区没有分配资源。u t-1表示t-1时间段的各个反潜分区重要性,该状态分量用于描述我方保护目标位置变化的场景。A d表示敌我双方的博弈动作空间,由资源分配方案矢量构成。状态迁移T d:S d→与敌方目标的位置参数相关,设l为敌方水下探测器的出现位置和数量,为不确定参数,敌方部署的混合策略πl将会生成状态迁移T d上的一次概率分布,例如假设有两个敌方目标可能出现的位置和数量矢量,l1=(3,2,1,0,0)和l2=(2,3,0,1,0),表达方式同资源分配矢量,本文称之为目标分布矢量,如果πl=(0.6,0.4),表示l1有0.6的概率出现,l2有0.4的概率出现,状态迁移的混合策略分布是不确定性马尔可夫决策过程的主要特征。
在具体实现时,为了提高强化学习的效率,本文把方案矢量或分布矢量映射为[0,1]之间的小数,在应用时通过Lambda函数把连续小数还原为数量。另外,为了表达搜潜平台以及探测器的不同类型,可以把方案矢量以及分布矢量扩展为2维矩阵,第1维为反潜分区,第2维为装备类型。
奖励R d表示执行动作的奖励,由第1节介绍的反潜指标构成,我方k号搜潜平台的奖励r k定义如下:
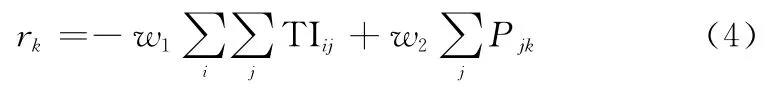
敌方j号探测器奖励r j定义如下:
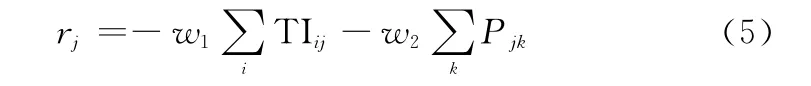
式(4)和式(5)中w1和w2表示组合指标权重。
2.2 鲁棒性部署策略学习算法总体设计
敌方分布矢量l为不确定参数,我方对其分布也缺乏先验知识,为此需要我方的部署策略πa对于不确定参数l具有一定鲁棒性。本文采用了鲁棒性决策理论中的最小最大后悔值方法[19]来设计鲁棒性部署算法。设r(πa,l)为在敌方不确定性参数l影响下,我方采用策略πa所获得的期望奖励,则我方采用策略πa的后悔值定义如下:

因此,部署算法的目标是计算得到我方部署策略πa,能够最小化不确定参数l下的最大可能后悔值,利用式(6)可推导出该问题的规划模型为
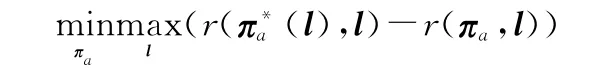
该规划模型可以看作是敌我双方的博弈问题,针对敌方选择最坏情况下的参数值l,我方需要学习优化策略πa,最小化最大的后悔值,该博弈问题中,我方的收益为-regret,敌方收益为regret。借鉴double oracle算法、博弈论和深度学习思想,部署策略学习算法设计如下。

如果对敌方探测器的分布情况有历史数据作为启发线索,可以在算法输入时作为参数集L输入,否则可以随机生成L。算法1中,第1行~第4行为初始化。从第5行开始进入敌我双方博弈的外循环,第6行和第7行敌我双方根据对手的方案集和策略,生成自己的最佳反应方案,第8行扩充现有方案集并计算双方收益矩阵pm。如果不考虑扰动机制,最后利用收益矩阵计算纳什均衡下的混合策略。
本文出于以下两个原因引入了参数扰动机制:一是由于水下复杂环境的影响,我方声纳难以精确获取敌方水下目标的分布情况;第二个原因与强化学习的精度有关,对于一个给定的敌方分布,我方强化学习机并不能保证一定得到最佳反应策略。因此,受奖励值随机扰动处理不确定参数的思路启发,本文加入分布参数l的不同扰动值,便于我方学习机搜索优化策略(l)以及最佳反应方案。
另外,算法中博弈树规模与反潜分区数量相关,计算复杂性属于多项式范围,能够利用线性规划(本文利用Nashpy库函数[20]进行计算)求解出纳什均衡解。所以,尽管参数扰动机制增加了更多的候选方案,但是只扩大了收益矩阵的大小,计算复杂性的增加幅度并不大。
下面为收益矩阵计算函数UpdatePayoffs的伪代码。

下面描述敌我双方最佳反应策略的学习算法。
2.3 最佳反应策略学习算法设计
我方最佳反应策略的学习算法为DefendPlanBR,在给定的敌方分布集S l和策略πl的情况下,学习我方部署优化策略πa,使得我方部署方案能够最大化奖励值。该算法直接采用了强化学习的深度确定性策略梯度(deep deterministic policy gradient,DDPG)架构[21]来获取优化的部署策略。DDPG架构可以看作AC架构[22]和深度Q网络(deep Q network,DQN)[23]的综合,能够解决连续性动作问题。
敌方最佳反应策略的学习算法为Enemy Plan BR,与我方学习算法DefendPlanBR类似,也是采用了DDPG算法架构,但因为需要同时计算敌方水下探测器的分布策略πl和不确定参数l,所以算法更加复杂。
最为直接的方法是采用两套学习机(AC神经网络)分别训练πl和l,但是由于不确定参数l和策略πl强相关,这种分离式训练方法只能得到次优结果,因此本文采用唤醒-休眠机制,利用1套AC神经网络同时优化πl和l,不仅能够简化算法复杂性,而且提高了训练速度,算法伪代码如下。

EnemyPlanBR伪代码中,为了提高算法鲁棒性,第3行利用随机抽样生成新的部署策略,第5行~第7行在实现时可以利用Tensor Flow或Py Torch的选择性权重梯度求解接口实现,第8行需要利用第3节搜索训练好的敌我双方攻防策略计算下一步时间段的奖励和状态结果,第10行调用了DDPG网络的更新算法,为了伪代码的表达清晰,省略了DDPG网络的经验回放和目标网络更新等步骤。
3 搜潜策略的学习
3.1 搜潜模型的建立
部署阶段考虑的是敌我双方两个指挥机构之间的零和博弈,而搜潜阶段需要考虑多个智能体(多个我方搜潜平台和多个敌方水下探测器)之间的协作与攻防关系,为此在搜潜阶段采用了基于多智能体的部分可观察马尔可夫决策 过 程[24](partially observable Markov decision processes,POMDP)来建立攻防模型。设系统内共有N个智能体(下标为n),环境的部分可观察状态空间定义为O={O1,O2,…,O N},动作空间定义为A={A1,A2,…,A N},对于我方搜潜平台和敌方探测器,考虑到搜潜仿真软件中探测概率的计算需要(见第1节),选取3个自由度方向的动力为动作,即动作a n为包含3个实数分量的矢量,水面舰船深度方向动力为0。在搜潜阶段,假设敌我双方只能感知自己传感距离之内的环境和物体,我方搜潜平台具有通信能力,且每个智能体按时间步长移动。对于我方搜潜平台智能体,其状态包括:搜潜网格分区中我方各个搜潜平台的位置、深度、类型,搜潜平台上声纳传感器的观测结果,某一个分区内是否检测到敌方目标,搜潜平台的通知消息、各个网格分区的重要性(如果保护对象为编队等移动对象)以及每一个分区的经过次数等。敌方探测器的状态包括:观测范围内我方和敌方UUV的位置信息。
奖励函数R的定义与第2.1节资源分配模型相同。对于状态转移函数,每一个智能体包含一套AC网络,其中actor网络输入矢量为局部观察状态On,每一个时间步长t,智能体n根据AC网络中参数化的策略πl,选择动作a n,并获得奖励rn,每一个智能体的目标是最大化其期望奖励,其中γt为t时段的折扣率,为第n个智能体在时段t收集到的奖励。
3.2 搜潜策略学习算法的设计
本文提出了一个基于多智能体DDPG[25](multi-agent DDPG,MADDPG)的搜潜算法,用以学习我方搜潜策略,MADDPG是DDPG架构在多智能体学习方面的扩展,采用的是集中式训练 -分布式执行学习模式[26],这种模式特别适用于POMDP,由于搜潜过程中单个智能体都无法获取整个环境的完整状态信息,所以在训练时给智能体的critic网络以集中训练形式提供额外信息,这样可以帮助智能体学习到更好的动作策略。
设搜潜环境中包括K个搜潜平台,策略空间πD={π1,π2,…,πK},对应K个搜潜平台智能体的actor神经网络参数θ={θ1,θ2,…,θK},另外设有J个敌方水下探测器,策略空间τE={τ1,τ2,…,τJ},对应的actor神经网络参数ψ={ψ1,ψ2,…,ψK},则我方第k个搜潜平台智能体的actor网络参数的梯度更新公式如下:
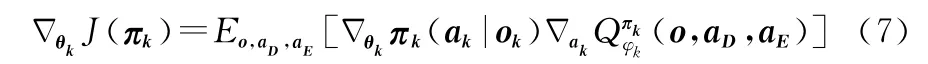
同样,敌方第j个探测器智能体的actor网络参数的梯度更新公式如下:
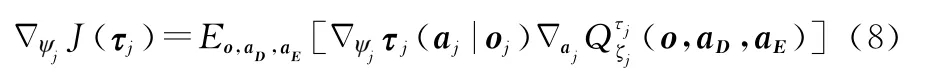
式(7)和式(8)中o={o1,o2,…,o K+J}表示敌我双方的可观测状态;ak表示我方第k个搜潜平台的动作,a D={a k}表示我方所有搜潜平台的动作;a j表示敌方第j个搜潜平台的动作;a E={a j}表示敌方所有探测器的动作,Q函数表示提供了所有环境信息(o,a D,a E)的集中动作 价值函数,它用于计算智能体的Q值,其中φk和ξj分别为我方和敌方智能体Critic网络的权重参数。
我方第k个搜潜平台智能体的Critic网络参数的梯度更新公式如下:
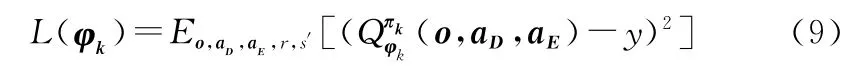
敌方第j个探测器智能体的Critic网络参数的梯度更新公式如下:
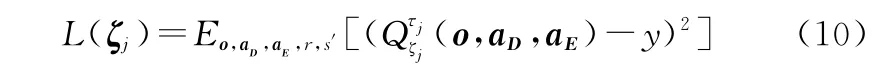
式(10)和式(11)中y的定义为
算法4为搜潜算法伪代码,为简洁起见,伪代码只考虑了敌我双方各拥有一种类型的装备,如果需要考虑多种装备,只需在算法中添加新类型装备的智能体训练流程即可。


算法分3个部分,第1部分从第4行到第14行,第6行从当前策略中随机生成敌我双方所有智能体的动作,数据类型为矩阵,并在第7行把这些动作输入给搜潜过程仿真软件,以矩阵形式返回下一时间步的各自状态和奖励,并在第8行至第13行把敌我双方的当前状态、下一步状态、动作以及奖励存入回放缓存。第1部分运行MAX_EP_STEPS个循环,得到一批可用于强化学习的数据集。
第2部分从第15行至第21行,主要用于我方所有搜潜平台智能体搜潜策略的学习。第16行从回放缓存中采样一批大小为N s的训练样本,17行~18行按式(11)生成y,第19行更新critic神经网络权重,损失值计算是式(9)的具体实现,第20行更新actor神经网络权重,梯度下降更新是式(7)的具体实现。
第3部分用于敌方所有水下探测器智能体入侵策略的学习,与第2部分类似。这里为了简洁起见,省略了诸如固定目标网络的赋值等细节。
4 仿真实验结果分析
本文实验程序利用Python开发,强化学习二次开发平台为Tensor Flow[27]。由于在策略学习过程中需要调用反潜仿真软件获取训练数据,为了与现有强化学习开发模式兼容,对现有反潜仿真软件的接口进行了封装,参照Open AI Gym工具库的规范,实现了仿真过程的reset和step2个关键接口。
4.1 实验采用的神经网络结构
首先描述搜潜策略学习算法中智能体的神经网络结构。actor网络第1层和第2层为卷积层,卷积层之间采用非线性Re Lu函数激活。输入层为卷积层结构,包括10个3×3的卷积核,步长为1×1;第2层也采用卷积层,包括20个3×3的卷积核,步长为1×1;第3层为包括128个隐藏节点的全连接层;第4层为包括64个隐藏节点的全连接层;第5层同样为全连接层,包括3个单元,表示动作空间的3个维度;各层之间采用ReLu函数激活;最后为lambda层,通过tanh函数把动作范围映射到对应的量纲。
搜潜策略学习算法中智能体critic网络有2个输入层,由于本文采用集中学习模式,其分别用于输入敌我双方的状态和动作;第2层利用Concat函数连接状态输入和动作输入;第3层和第4层是激活函数为ReLu的全连接层,都包括128个隐藏节点;第5层为包含1个输出节点的全连接层,输出Q值。敌方智能体结构只在输入状态层有所不同,不再冗述。
部署策略学习算法包括两个采用DDPG架构的智能体,分别表示敌我双方的布局策略,这里只描述我方神经网络结构,敌方结构与我方类似。actor网络输入层节点数量等于状态维度,即为2×反潜网格分区数量(特征分别为分配矢量和重要性矢量);第2层和第3层为全连接层,节点数量分别为16和32,其通过非线性的ReLu函数激活;第4层为Softmax层,把动作策略映射为(0,1)之间的概率值。critic网络输入层对应状态输入和动作输入,第2层节点数量为状态数量与动作维数量之和,即为3×反潜网格分区数量,连接状态和动作;第3层和第4层为全连接层,节点数量分别为16和32,其通过非线性的ReLu函数激活;第5层输出层为全连接层,节点数量为1,输出Q值;第3层到第5层之间通过ReLu函数激活。
4.2 实验场景及比对算法
在本文给出的实验想定场景中,反潜海区划分为30×30个网格分区。我方配置为:2艘护卫舰,4艘反潜UUV;敌方水下探测UUV数量为1艘(单目标)或3艘(多目标),其中护卫舰速度约为敌方UUV的3倍,我方UUV速度约为敌方UUV的1.2倍,出于数据安全考虑,这里没有列出装备的具体参数。另外,本文演示的实验场景规模、敌我双方兵力的数量不大,这主要因为随着场景和智能体数量增加,强化学习的算力需求和训练时间也快速增加,为了找出不同敌方目标数量和反潜海域下我方兵力的优化数量,需要通过实验设计(design of experiment,DOE)进行大量实验取得数据,而本文当前主要从技术思路上进行论证研究。
为了检验保护目标的分布情况对算法性能的影响,本文对划分海区各个网格的设置分为两种情况:一是各网格分区重要性指标随机分布;另一种是规律分布,基于某真实海区的水下资源分布情况,与重要网格分区越远,重要性越低,另外海区边缘的重要性最低。这主要检验算法对不同海区的适应能力。敌方目标数量和反潜分区重要性分布是影响算法性能的两个重要指标,为此本文采用交叉实验,分别针对单目标随机分布、单目标规律分布、多目标随机分布、多目标规律分布进行了仿真实验,在不同场景下验证算法性能。
为了能够检测算法性能,本文设置了3种比对算法。因为在搜索阶段,当缺少先验知识时,如果时间充足,采用穷举搜索;如果时间比较紧张,一般采用随机搜索。这两种搜索方法缺乏可比性,所以除了第3种比对算法,本文都采用第3节方法训练好的搜索策略(部署阶段为随机分配资源),变化主要在部署方法上,说明如下:
(1)智能搜索:为本文提出的2阶段反潜规划算法,第1阶段训练的部署策略和第2阶段的搜索策略,部署策略为第2阶段的搜潜服务,在海区分配反潜资源。
(2)随机部署:部署阶段在反潜分区随机分配搜潜平台;
(3)策略梯度:采用策略梯度更新算法学习最佳反应策略,并采用经典的虚拟博弈[28-29]训练框架使博弈双方收敛至纳什均衡;
(4)数学规划:由于文献[7]只考虑1个敌方探测器的情况,所以在单目标时使用该文献提出的规划算法。多目标时,部署阶段由人工选择资源分配方案。
4.3 仿真结果
首先在不同场景下,对本文提出的智能反潜算法与3种比对算法进行性能比较,为了能够清楚表示演示图形,每200个训练轮次的样本取一次均值,训练曲线如图1所示。
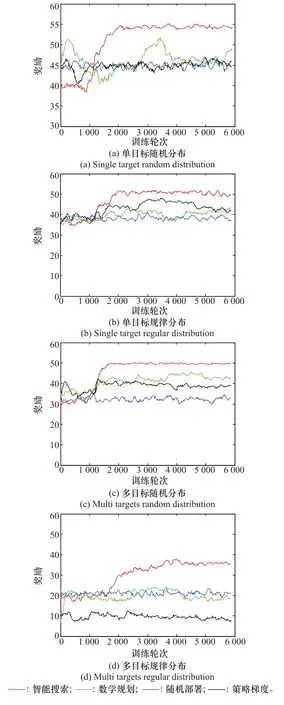
图1 不同场景下的训练曲线Fig.1 Training curves of different scenarios
从图1可以看出,从收敛速度和奖励效用性能指标方面,智能反潜算法都远超比对算法。而且智能反潜算法的曲线变化幅度也比其他算法更小,说明其反潜策略具有更强的鲁棒性。
第2个实验检验算法的鲁棒性。本文引入了两个不确定参数表示反潜过程的不确定性,第1个参数为资源部署阶段的敌方分布矢量l(第3.2节),表示对敌方水下探测器初始分布的不确定性,实验时修改l的间隔范围,即l的最大值与l的最小值之差作为调节参数;第2个不确定参数为影响探测概率的标准差((第2节式(3))。图2和图3演示了场景为多目标规律分布下的实验结果,以8 000轮训练轮次计算得到平均奖励值,按式(6)得到的最大后悔值作为性能指标,由于随机部署无法处理不确定情况,所以没有把它作为比对。图2为不确定参数l的间隔范围变化时针对单目标随机分布的最大后悔值变化情况,从图中可以看出当其他算法最大后悔值显著增加时,智能搜索算法的增加幅度较小。
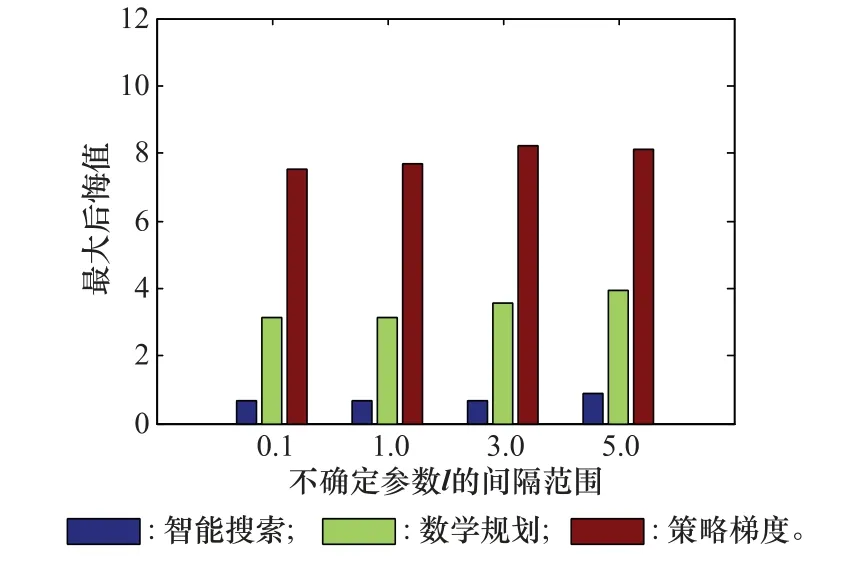
图2 敌方分布不确定下的性能比较Fig.2 Performance of uncertain enemy distribution
图3进一步针对不同场景和不确定参数进行了交叉实验设计,x坐标的S[1,3]表示单目标规律分布场景下l=1,σ=3时不同算法的最大后悔值;M[1,3]对应多目标规律分布场景下l=1,σ=3时各算法的最大后悔值;其他标记与此类似,其中原数学规划算法只支持单个目标,难以在多目标场景下对其加入不确定参数的扩展模块,所以没有在图3的多目标场景下显示。
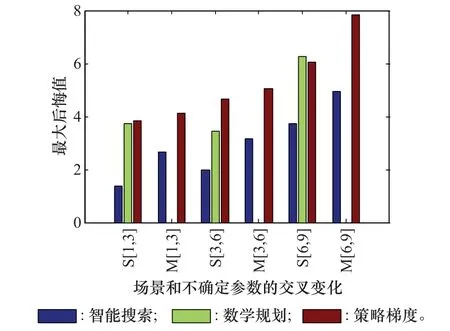
图3 场景和不确定参数交叉变化的性能比较Fig.3 Performance comparison of cross changing of scenarios and uncertain parameters
图4为不同场景和不确定探测概率下智能搜索算法奖励值的变化情况,从中可以看出对应不同场景和探测概率,本算法的可扩展性能也较好。
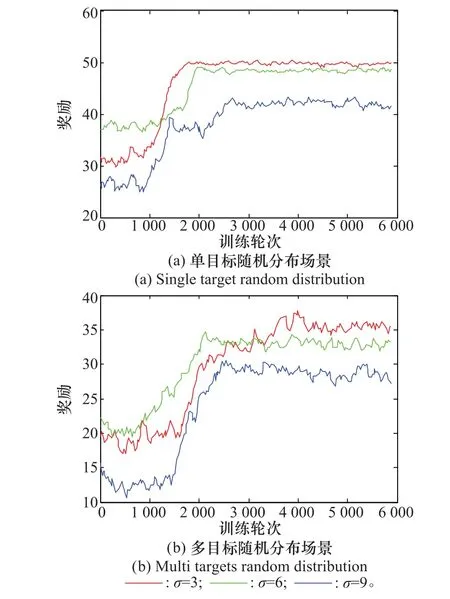
图4 不同探测概率标准差σ下的训练曲线Fig.4 Training curves with different detection probabilitiesσ
5 结束语
本文提出了一个基于多智能体强化学习的两阶段反潜策略学习方法,能够在环境信息感知不确定情况下,辅助决策反潜资源的部署、巡逻、搜潜以及各资源之间的协同工作。主要优点包括:与传统的基于数学规划的反潜规划方法不同的是,多智能体强化学习方法不需要事先指定敌方目标的行为模型,而是在对抗仿真中逐步增强敌我双方的行为策略,因此本文算法不仅支持常规战术演练,而且能生成新的反潜战术,或者对新战术进行性能评估。过去潜艇仿真平台主要用于潜艇和反潜装备性能的评估,由于缺乏战例或想定数据,对于实战过程中战术推演支持不够,而积累战术数据需要花费大量人力物力反复推演或情报收集,而基于多智能体强化学习的策略学习算法与Alpha Zero类似,可以自我学习和生成方案。下一步工作主要集中在反潜海域以及参战兵力规模扩大后的算法可扩展性研究。
猜你喜欢
少林与太极(2022年6期)2022-09-14
舰船科学技术(2022年10期)2022-06-17
小哥白尼(军事科学)(2022年1期)2022-04-26
当代陕西(2020年13期)2020-08-24
非公有制企业党建(2020年5期)2020-06-16
海峡姐妹(2019年3期)2019-06-18
儿童时代·快乐苗苗(2018年7期)2018-09-03
少林与太极(2016年6期)2016-08-05
少林与太极(2015年5期)2015-11-14
中国高新技术企业(2009年12期)2009-09-23
