
基于图文注意力融合的主题标签推荐
2022-10-08 09:03:32冯皓楠何智勇马良荔
郑州大学学报(工学版) 2022年6期
冯皓楠, 何智勇, 马良荔
(中国人民解放军海军工程大学 电子工程学院, 湖北 武汉 430000)
0 引言
社交媒体平台(如Twitter)上提供了大量的文本、图片及视频数据,这些数据的爆发式增长已经远远超过了人们的接收理解能力。如何消化大量嘈杂的社交媒体数据,提取其中的重要内容,为用户推荐其所需的快速访问信息已经成为一个新的挑战。用户在社交媒体平台发布文本、图片和视频数据时,会使用一种特定形式的元数据标签(hashtag),它是一串以符号#为前缀的字符,一般可以用来描述帖子中的关键词或主题。
表1展示了一个用户在Twitter上为帖子内容配上标签的示例。通过帖子文本及其配套图片的耦合效应指示帖子的主题内容并且推荐一系列能反映帖子的主要关注点的标签是目前研究的热点。然而,前人的研究主要集中在文本特征的使用上[1],但社交媒体的语言风格本质上是非正式的、碎片化的,为了丰富语境,本文分析利用了帖子中配套的图片内容。

表1 Twitter数据集中的一个真实帖子示例Table 1 A real post example from Twitter dataset
现有的研究主要是针对单模态的标签推荐或关于多模态标签推荐的分类算法的研究,但从实际应用的角度出发,生成数据集标签空间中不存在的标签至关重要。因此,本文进行了多模态标签序列生成模型(GEN-CO-ATT)的研究,并进一步提出了多模态标签推荐算法的分类方法和生成方法的统一模型(UNIFIED-CO-ATT)。
本文旨在为新型社交平台设计一种完整而有效的标签推荐方法,采用共注意力机制对多模态内容进行建模融合,并采用Seq2Seq框架生成新的标签序列(GEN-CO-ATT);同时,针对分类方法和生成方法的特点,采用复制机制的扩展方法将分类模型的结果聚合到序列生成模型的输出中,并通过2个模块端到端的联合训练得到一个统一的标签推荐模型(UNIFIED-CO-ATT)。
1 相关工作
早期的研究工作中,通常仅将多模态内容各自建模使用,例如,Vinyals等[2]提出先对文本和图片建模,提取高层图片特征,再将其输入LSTM中对图片生成字幕;何伟成[3]提出基于图卷积神经网络的个性化标签推荐算法,借助图卷积网络的表示、学习能力进行标签推荐;Yang等[4]使用注意力机制多次查询图片,逐步推断推荐结果。但是,这些工作并没有考虑图片对文本特征提取的指导意义和二者之间的关联。
为了分析多模态内容之间的语义关联性,张素威[5]提出了一个基于异质注意力的图文融合的标签推荐模型,既强化了跨模态的共性信息,也考虑了不同模态差异信息之间的互补性。由于共注意力机制[6]可以同时考虑文本与图片对推荐结果的影响,Zhang等[7]采用共注意力机制对文本和图片的关联建模,通过分类的方法研究了基于多模态内容的标签推荐问题。
在关键词预测方面,大部分工作是直接从源输入中提取序列[8]或从预定义的候选列表中进行分类[9],这样不会产生数据集标签空间中不存在的关键词。受到在科学文章中生成关键词方法的启发,Wang等[10]采用Seq2Seq框架实现了在社交媒体平台上生成关键词;Chen等[11]也采用了分离检索的方法来生成关键字;Wang等[12]基于复制机制将分类方法的结果与生成方法的结果进行聚合。首先,本文应用共注意力机制对多模态内容进行建模与融合;其次,建立基于多模态内容的标签分类模型和标签序列生成模型,允许端到端的联合训练,以更好地捕捉2种模型的多样化结果,并通过一种聚合策略将分类方法的输出结果聚合到生成的标签序列中;最后,得到2种方法的统一推荐模型。
2 统一的多模态标签推荐模型
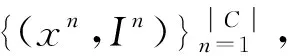
图1为所提出的多模态标签推荐模型的总体框架。该模型是从下往上运行的:首先,将帖子中的文本和图片编码为文本表示和图片表示,使用共注意力机制捕捉它们复杂的语义交互;其次,将学习到的多模态表示向量cfuse用于标签的分类模型或序列生成模型,使用一种聚合策略来组合它们的输出;最后,上述整个框架可以通过多任务学习的方式联合训练为一个整体的模型。
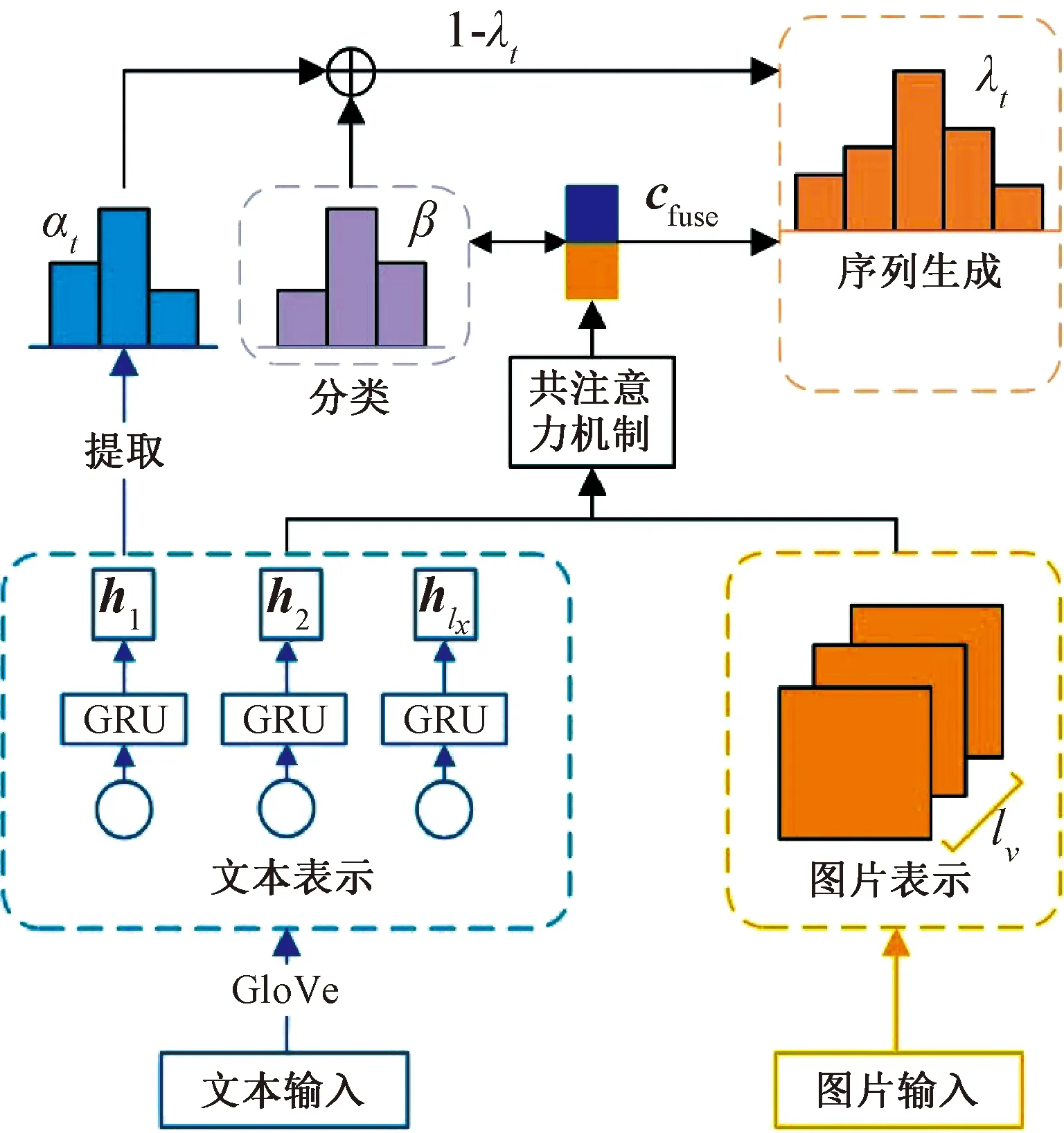
图1 基于多模态内容的标签推荐统一模型Figure 1 Unified model of hashtag recommendation based on multi-modal content
2.1 多模态编码
(1)学习文本表示。通过数据集预训练的查找表将文本输入序列中的每个单词xi嵌入到一个高维向量中,使用双向门控循环单元(BiGRU)对嵌入后的单词e(xi)进行编码,表达式为
(1)
(2)
(2)学习图片表示。采用在大规模图片库ImageNet上预训练后的VGG-16网络[14]对每个图片I提取49个卷积特征图,每个特征图通过一个线性投影层转化为一个新的向量vi,然后存储到一个图片向量库Mvis={v1,v2,…,vlν}∈Rlν×d中,其中lν为图片区域的个数。
2.2 共注意力机制
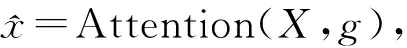
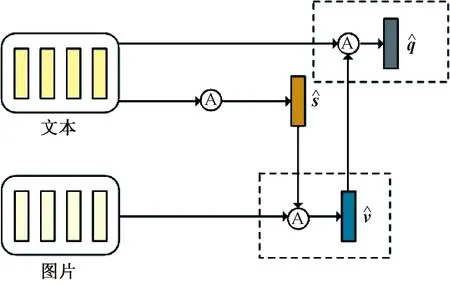
图2 共注意力机制结构Figure 2 Co-attention mechanism structure
H=tanh(WxX+Wgg);
(3)
(4)
(5)
式中:Wx、Wg∈Rk×d,ωhx∈Rk均为特征矩阵;αx为特征X的注意力权重。
考虑社交媒体数据的噪声特性,采用最大/平均池化层为每个模态获取一个整体的查询向量,将所有共注意力层的输出通过一个线性多模态融合层表示为上下文向量cfuse∈Rd,并输入标签分类模型和标签序列生成模型中进行标签推荐。
2.3 统一的多模态标签推荐模型
结合不同方法的特点,采用一种聚合策略将多模态标签推荐的分类方法和生成方法结合为一个统一的推荐模型。
步骤1 标签分类。由于每个标签y通常只由几个单词组成,因此可以将单词视为整体标签的离散部分,并通过推荐单词来推荐标签。在分类方法中,直接将多模态上下文向量cfuse传递到一个双层的多层感知器MLP中,然后将它映射到标签分类词汇表Vcls的分布中:
Pcls(y)=softmax(MLPcls(cfuse))。
(6)
步骤2 标签序列生成。在标签序列生成方面,使用Seq2Seq框架来生成新的标签序列y=
(7)
采用一个单向的门控循环单元GRU解码器对生成建模过程,具体来说,解码器释放的隐藏状态st=GRU(st-1,ut)∈Rd是基于前一个隐藏状态st-1和嵌入式解码器的输入ut,st由文本编码器的最后一个隐藏状态hlx初始化。采用共注意力机制获取文本的上下文语境向量ctext:
(8)
αt,i=softmax(S(st,hi));
(9)
(10)
式中:S(st,hi)为得分函数,用来衡量第t个被解码的单词和文本编码器的第i个单词之间的兼容性;Wα∈Rd×2d,Bα、vα∈Rd均为可训练权值。
接下来结合静态多模态向量cfuse来构建丰富的上下文表示:
ct=[ut;st;ctext+cfuse]。
(11)
在此基础上,采用另一个带有softmax函数的MLP将ct映射到生成词汇表Vgen的单词分布中:
Pgen(yt)=softmax(MLPgen(ct))。
(12)
为了使解码器更好地从源输入帖子中复制单词,应用复制机制[15]设置一个带有sigmoid激活函数的MLP软开关λt∈[0,1],它决定了模型是从词汇表Vgen中生成单词序列还是从源输入序列中提取单词,其中提取源输入序列的概率分布由文本注意力权重αt,i决定。
步骤3 聚合策略。使用复制机制的扩展方法将分类模型的输出结果聚合到标签序列生成结果中:①从分类模型中检索前K个预测结果,并将其转换为单词序列w=
步骤4 统一模型的标签推荐。根据聚合后的结果得到统一的标签推荐模型。
(13)
式中:a、b为超参数,a+b=1,用于决定模型是从输入序列中提取单词还是从分类输出中提取单词。为了稳定分类输出结果的聚合,设置a为1,b为0,输入分类器进行训练,实验完成几个批次后,将两者都设置为0.5以进行更进一步的训练。
2.4 联合训练目标
本文采用标准的负对数似然损失函数来定义整个模型的训练目标。似然损失函数由多任务学习的标签分类损失和单词级序列生成损失的线性组合构成:
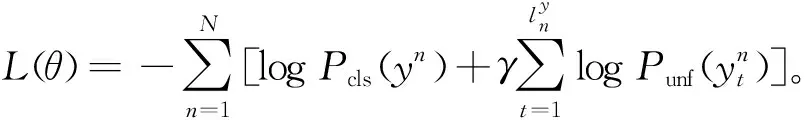
(14)
式中:N为训练文本-图片对的大小;γ为平衡这2个损失的超参数,设为1;θ表示整个框架共享的可训练参数。从式(14)可以看出,联合训练标签分类模型有助于统一的标签推荐,不仅隐式地提供了更好的参数学习,还明确提供了更精确的输出,以供聚合策略组合到标签生成模型中。
3 实验与结果分析
本文的实验设置为Ubuntu20.04、CPU i9-10900X、64 GB内存、NVIDIA GeForce RTX 2090,实验环境为python3.6、pytorch1.5。
3.1 数据收集和统计
由于缺少社交媒体平台基于多模态内容的帖子及标签的公开数据集,因此本文使用了文献[12]中公开的数据集。该数据集使用了Twitter高级搜索API查询2019年1月至2019年6月期间包含文本、图片和标签的英文帖子,并获得53 701条推文。本文将数据按8∶1∶1随机划分为训练集、验证集和测试集。数据集的数据分割和统计信息如表2所示。
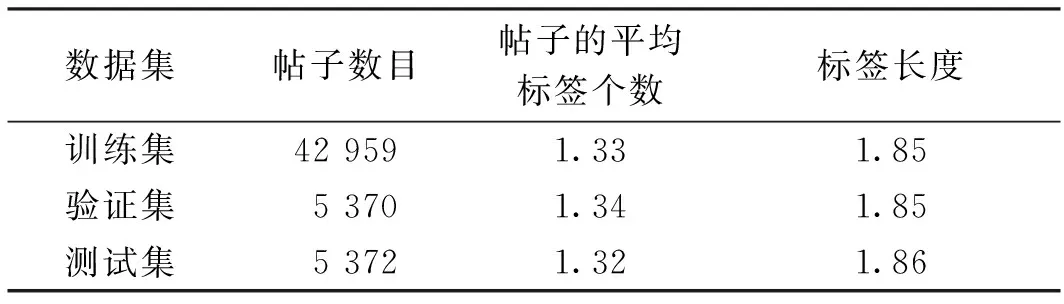
表2 数据集的数据分割和统计Table 2 Data segmentation and statistics of dataset
3.2 实验设置
3.2.1 评价指标
本文采用信息检索指标宏平均F1值来评估本文模型,选取推荐概率排名前K的主题标签计算评价指标,例如:F1@K表示推荐概率排名前K的标签计算出的F1值,其中K=1,3,5。F1@K值越大表示模型性能越好。为了进一步测量标签的推荐顺序,本文对推荐概率排名前5的标签采用平均精度指标MAP(mean average precision)[16]进行评价。指标得分越高表示模型性能越好。
3.2.2 参数设置
本文使用了一个有45 000单词的生成词汇表Vgen和4 262个标签的关键短语分类词汇表Vcls,采用200维的Twitter GloVe嵌入[17]来编码文本输入。采用两层的BiGRU作为编码器,一层的GRU作为解码器,隐藏大小设置为300。对于图片,本文使用VGG-16提取49个特征图和512维的特征。在训练中,本文设置损失系数γ=1,采用Adam优化器,学习率为0.001。如果验证损失没有下降,则采用最大梯度范数为5的梯度裁剪方法将其衰减0.5,通过监测验证损失的变化,采用了提前停止方法。
3.2.3 对比模型
选择2种对比模型TAKG[10]和COA[6]。TAKG模型是针对社交媒体平台的主题感知关键词生成模型,只使用了帖子中的文本模态信息推荐关键字;COA模型是针对社交媒体平台的基于多模态内容的主题标签推荐模型,此模型使用共注意力机制对多模态特征建模,并使用多类分类的方法进行标签推荐。
3.3 实验结果
表3为本文模型与其他模型的实验结果对比。分析表3可得如下结论。
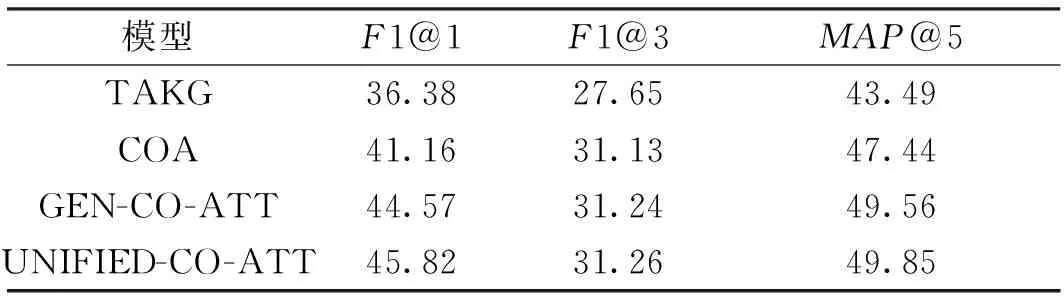
表3 各模型的实验结果对比Table 3 Experimental results of models %
(1)多模态方法比单模态方法更具优势。所提统一推荐模型UNIFIED-CO-ATT的F1值比仅使用单模态的对比模型TAKG高9.44百分点;所提标签序列生成模型GEN-CO-ATT相比于TAKG模型在F1@1、F1@3、MAP@5上分别提升8.19百分点、3.59百分点、6.07百分点。可以看出,考虑多模态内容的模型比只考虑文本模态内容的模型有更好的表现,这说明基于Seq2Seq框架的标签序列生成模型能够很好地利用社交媒体平台上多模态信息的特殊性,且图片模态提供了许多文本模态中未包含的额外信息。
(2)生成新标签序列的方法也优于传统的分类方法。所提GEN-CO-ATT模型比基于多模态内容的多类分类方法进行主题标签推荐的模型COA在F1@1、F1@3、MAP@5上分别提升3.41百分点、0.11百分点、2.12百分点。这说明基于多模态内容进行主题标签推荐的问题中,能够生成出标签空间中不存在的主题标签是非常重要的,分类方法只能推荐出在标签空间中预定义的主题标签,有一定局限性。
(3)本文统一标签推荐模型UNIFIED-CO-ATT比仅使用生成方法的GEN-CO-ATT模型在F1@1、F1@3、MAP@5上分别提升1.25百分点、0.02百分点、0.29百分点,即统一的标签推荐模型比仅使用分类方法的模型表现更好。这说明本文先联合训练分类模型和生成模型,再将分类结果聚合于生成方法中进行优化的聚合策略有效果。这种聚合策略使模型同时具有准确性和新颖性的特点。
图3为4种模型在K=1,3,5时的精确度和召回率。由图3可以看出,模型GEN-CO-ATT和UNIFIED-CO-ATT在精确度和召回率方面也优于对比模型TAKG和COA。由于测试集中每个帖子中已有的标签的平均数量为1.32(见表2),因此所有模型在K从1到3的性能比K从3到5的性能表现更好,同时性能也下降更快;在K>3时,模型的性能都逐渐平稳。这可能是由于在本文使用的嘈杂的社交媒体数据集中,关键词数量大但是缺位率高的原因。
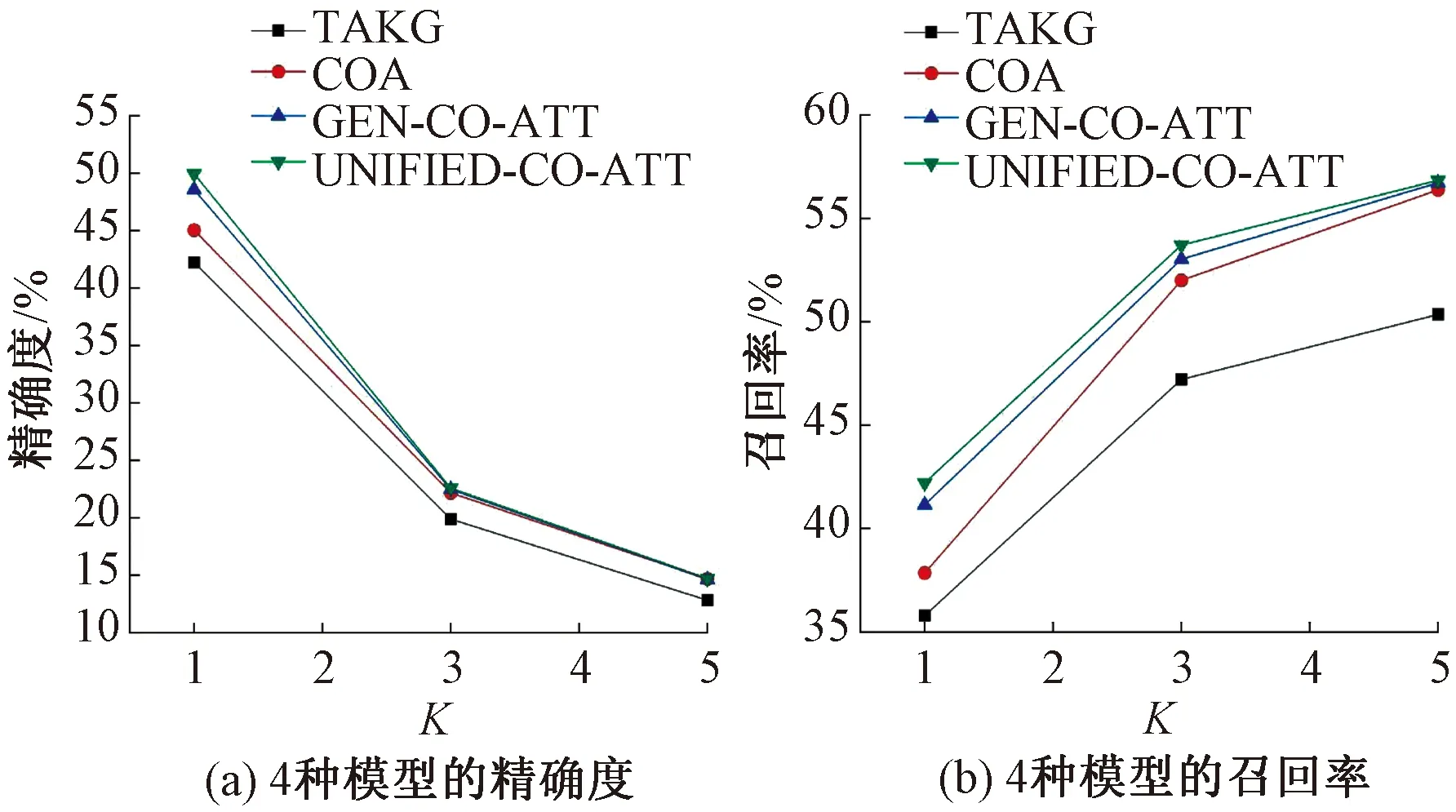
图3 4种模型在K=1,3,5时的精确度和召回率Figure 3 Accuracy and recall rate of 4 models with K=1,3,5
4 结束语
本文围绕社交媒体平台上的基于多模态内容的标签推荐问题,研究了标签序列生成模型在此问题中的性能表现,进一步提出了一个统一的标签推荐模型,将序列生成模型和分类模型的优势结合起来。此外,本文使用的先联合训练单个模型,再将分类模型结果聚合到生成模型结果中的聚合策略是有效的。在大规模数据集上的实验结果表明,本文的模型明显优于只使用文本内容生成标签的模型和仅使用分类方法推荐标签的模型。
猜你喜欢
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
车迷(2018年11期)2018-08-30 03:20:32
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
海峡姐妹(2018年3期)2018-05-09 08:21:02
意林(绘英语)(2017年5期)2017-05-15 02:17:23
公民与法治(2016年10期)2016-05-17 04:12:58
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
计算机工程(2015年8期)2015-07-03 12:20:27
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
