
多源数据驱动的防突预警指标自适应技术研究
2022-10-07 11:06朱墨然王麒翔张庆华
煤炭科学技术 2022年8期
朱墨然,王麒翔,张庆华
(1.瓦斯灾害监控与应急技术国家重点实验室,重庆 400037;2.中煤科工集团重庆研究院有限公司,重庆 400037)
0 引 言
煤与瓦斯突出事故仍然是煤矿造成伤亡人数最多的事故,对煤与瓦斯突出事故的预测预警是降低事故发生的重要手段之一[1-2]。目前对煤与瓦斯突出的预测,主要通过两个"四位一体"综合防突措施进行,这种主要以钻探方式预测突出危险性的方法优点是探测直接、数据准确,但也存在预测数据不连续、数据测试时间长、钻孔空白带等问题。随着煤矿监测监控系统的完善和煤矿信息化的推进,一种非接触式连续预测的防突预警技术逐步成熟[3-4],成为与传统防突预测的补充,这种预警是在本地通过工业环网采集安全监控系统瓦斯传感器等数据,通过应用瓦斯含量反演模型[5]、专家知识库[6]、机器学习[7-8]等方法,计算出预警指标然后与预警临界值进行比较,确定突出危险性的大小,这种预警技术数据来源单一,缺少预警模型效果验证,且预警临界值的设置不够灵活精确[9-10],在不同煤矿或不同煤层进行预警时又要重新考察临界值,工作量较大[11-12]。
基于此,有必要研究一种能够解决上述问题的多源数据驱动防突预警指标自适应技术,通过将煤矿各类生产数据格式化后进行上传,建立多源数据驱动的预警模型,将预警结果与现有防突预测数据进行匹配,对预警模型的有效性进行定量评价;建立预警临界值的自适应训练模型,使预警临界值自适应煤矿生产条件,避免同一预警临界值应用于多种生产条件的情况,提高预警的准确率,降低误报率。
1 防突信息数据特征
煤矿在执行《防治煤与瓦斯突出细则》两个“四位一体”综合防突措施过程中,会产生大量防突信息数据,主要包括防突预测过程中的预测指标数据、打钻动力现象、钻孔布置等数据;生产过程中产生的瓦斯涌出、进尺、产量、地质构造等数据;管理过程中产生的审批等数据。随着煤矿生产的推进,数据不断累积,这些数据具有如下特征:
1)多源异构。由于防突信息涉及的设备和部门较多,防突信息呈现出来源分布广泛、结构各异的特征。如瓦斯涌出数据来源于瓦斯体积分数传感器、局部预测指标来源于WTC、风量数据由人工测风获得等,此外数据的采集频率和特征也不相同,由于各类数据的结构字段不一致,造成数据结构多元化特征,为方便计算和分析,需要将数据进行预处理,统一数据格式。
2)体量庞大且数字化程度低。煤矿每天都会产生大量的防突相关数据,随时间的积累数据体量非常庞大,并且大量数据只有纸质记录,数字化程度较低,不利于数据的查找和分析计算。
3)数据利用率低。煤矿拥有丰富宝贵的原始生产数据,但数据的处理方式通常只是简单的观察数据是否超标,缺乏有效的数据分析手段,造成数据利用程度低。如钻屑瓦斯解吸指标或瓦斯体积分数,只关注最大值是否过临界值,而没有分析数据的变化趋势和时空关系,更没有将多源数据结合起来分析。
2 多源数据驱动融合的防突智能预警结构设计
多源数据驱动融合防突智能预警系统是利用煤矿生产过程中产生的多源数据,打通数据传输通道、建立预警模型算法、分析并发布计算结果,以此来实现防突预警的目的[13-14]。系统设计在智能化煤矿设计原则指导下,应用数据驱动和辅助智能决策思维,结合煤矿生产条件进行设计。多源数据驱动融合的防突智能预警结构设计如图1所示,结构包括基础数据层、数据传输层和决策应用层。

图1 多源数据驱动防突预警结构设计Fig.1 Design drawing of multi-source data-driven outburst prevention early warning structure
2.1 基础数据层
基础数据为系统结构的前端,基础数据中包含了大量工作面的突出危险性特征,为防突预警模型的建立奠定基础。基础数据分为结构性数据和非结构性数据。结构性数据可通过自动采集程序对数据进行采集,如监控系统中的传感器数据,防突预测指标数据的自动上传;非结构性数据则可以通过客户端人工录入并上传,如地质构造信息,动力现象等。
2.2 数据传输层
数据传输层是整个结构的枢纽。基础数据可通过煤矿工业环网进行传输,本地客户端保存的数据通过因特网上传到云服务器。将所有数据上云,可以方便数据的移动查询浏览,更有利于预警信息的发布。
2.3 决策应用层
决策应用层主要功能是将云服务器中的各类数据进行建模分析处理,根据煤与瓦斯突出特征建立相应的预警模型,建立算法对预警模型的有效性进行定量化验证,并通过建立预警指标数据库,根据大量预警结果不断训练预警临界值模型。当预警指标超过临界值时,通过互联网将信息推送给管理人员,方便及时作出决策消除事故隐患。
3 数据驱动防突预警技术
数据驱动的防突预警技术是根据多源数据特征,通过预警模型计算预警指标,当预警指标超过临界值时进行预警信息发布,及时采取相应措施预防事故的发生。该技术由预警模型的建立、预警模型的优选和预警临界值自适应训练3部分组成。
3.1 防突预警模型的建立
在整个数据驱动防突预警技术中,防突预警模型的建立是核心。防突预警模型的建立是根据煤与瓦斯突出发生发展机理,结合综合作用假说理论,通过对煤与瓦斯突出的主要影响因素进行反演,捕捉突出发生的前兆特征[15-18]。根据目前煤与瓦斯突出的预测手段,突出预警模型的建立主要通过多源数据反演煤体的瓦斯含量、煤体结构及地应力等特征,其中瓦斯含量是重点。煤体瓦斯含量是煤体瓦斯涌出潜能的直接表现,煤体瓦斯涌出量的多少最终取决于煤体本身拥有的瓦斯含量或者瓦斯潜能的多少[19-20]。通过对煤与瓦斯突出的影响因素和工作面瓦斯涌出的主控因素分析,建立了瓦斯量特征、解吸特征、波动特征和趋势特征的四大类预警模型,如图2所示。
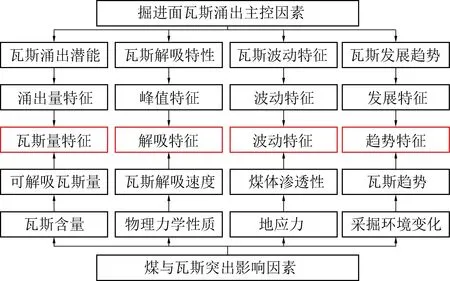
图2 瓦斯涌出特征与突出影响因素关系Fig.2 Relationship between gas emission characteristics and outburst influencing factors
3.2 预警模型的优选
预警模型建立后,由于预警模型较多,预警模型计算结果能否有效反映工作面的突出危险性,需要对预警模型进行优选,筛选出预警效果较好的预警模型。预警模型的优选方法有对比分析、相关性分析等方法。
1)对比分析法。对比分析法是将预警模型计算结果和实际防突预测数据绘制成曲线图,对比2者之间的关联性和有效性,当2者变化趋势一致时,认为预警模型能够反演实际防突预测信息,预警效果较好,反之则代表该预警模型有效性较弱。
在防突预测作业中,钻屑瓦斯解吸指标K1、瓦斯含量、瓦斯压力P等均能反映煤层的突出危险性。为验证预警模型的有效性,可以根据K1-P关系,通过K1值反演瓦斯压力和瓦斯含量,对预警模型的有效性进行多指标交叉验证。此外还可以根据煤矿生产过程中观测到的煤层赋存变化、打钻动力现象等信息,对预警模型的预警效果进行考察,分析预警模型对井下实际观测到的异常信息是否有响应。
2)相关性分析法。对比分析法只能对预警指标和防突预测指标进行一个定性的分析,不能对预警模型进行定量的评价,分析2者之间的差异。为定量评价2者之间的相关性,可以采用计算两条曲线波动特征的方法,衡量2者之间的相关性大小,以避免因人为主观因素导致预警模型的选取失误。定义波动特征为
(1)
其中:Wi为波动特征,i=1,2,…,n-1;Di为第i个数据,i=1,2,…,n。
通过比较预警模型和实测防突预测数据的波动特征,可以得出各预警模型有效性的强弱。
3.3 预警临界值自适应
预警模型确定后还需要对预警临界值进行考察,以提高预警的准确率。由于各个煤矿存在不同的煤层瓦斯赋存条件,使得各个煤层甚至不同采区发生煤与瓦斯突出的临界值不同。为避免同一临界值用于所有条件带来的预警准确率较低的情况,降低人工考察跟踪预警临界值的工作量,应用数据驱动思维,建立预警临界值自适应训练模型,随着采掘活动的进行,产生的新数据持续不断的对预警临界值进行修正,最终使预警临界值适应当前的采掘状况,实现预警临界值的自适应。
预警临界值的自适应是通过建立预警模型数据与实测防突数据之间的关系,根据该关系计算出当实测值处于临界值时预警模型的数值。例如可以通过建立预警模型数据与实测瓦斯含量、瓦斯压力、钻屑瓦斯解吸指标K1的线性关系,计算当实测指标瓦斯含量为8 m3/t、瓦斯压力为0.74 MPa或K1值为0.5的时候对应预警模型的数值即为预警临界值。
4 应用分析
本技术在贵州盘州地区某煤矿进行应用,通过对预警模型的定量评价,优选出了预警A指标和预警S指标,并通过临界值自适应方法优化了预警临界值范围。在考察期间对一次煤层厚度变化现象提前进行了预警,在采取相应措施后安全通过煤层厚度异常变化区域,通过现场应用验证了本技术在预警指标优选和临界值自适应方面的有效性。
4.1 工作面概况
该煤矿主采17号煤层为突出煤层,瓦斯含量高,开采过程中瓦斯涌出量大。该煤矿生产过程中产生的结构类数据,通过定制开发的数据自动采集程序进行传输,获取监控系统中各传感器数据,非结构类数据可通过客户端录入上传。
4.2 预警模型的优选
根据煤与瓦斯突出影响因素,建立了四大类预警模型,预警模型建立后,通过对比分析和相关性分析对预警模型进行优选。在本次预警模型的优选过程中,实测防突预测数据选择的是钻屑瓦斯解吸指标K1。
选取该煤矿12171里段运输巷在2020-09-01—2020-10-10的数据,对4个典型预警指标A、B、S、D(预警指标释义见表1)进行对比分析和相关性分析。通过绘制预警指标与实测防突预测数据K1的趋势线进行对比分析(图3)。
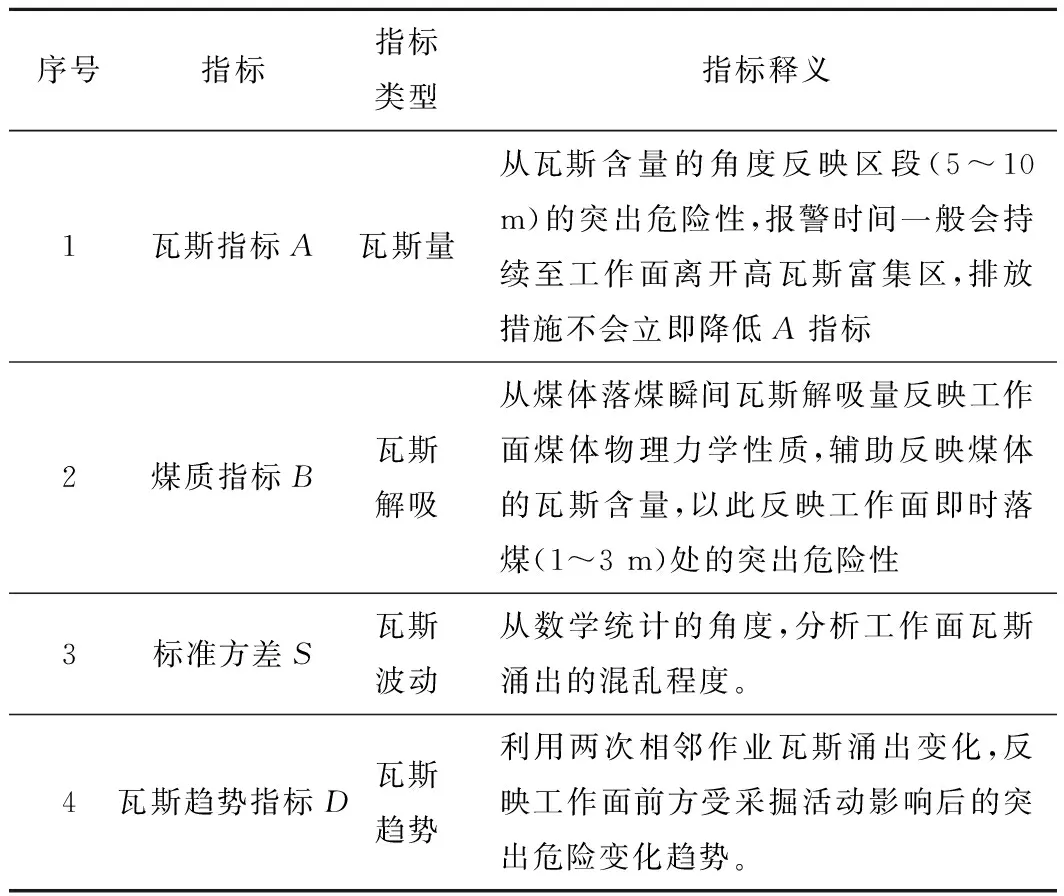
表1 预警模型释义Table 1 Explanation of early warning model
通过图3可以定性的考察预警模型数据与实测防突预测数据之间的相关性。为定量分析各预警指标的有效性,按照式(1)的方法分别计算各个预警指标的波动特征,以此来衡量各预警指标与实测防突预测数据之间的相关性,波动特征计算结果见表2。

表2 数据波动特征Table 2 Data fluctuation characteristics
由表2可知,各预警指标当中,与K1值波动率最接近的是预警A指标和预警S指标,由图中也同样可以看出预警A指标和预警S指标对K1值的跟踪性较好,能够反映煤与瓦斯突出的危险性大小,因此将预警A指标和预警S指标作为该煤矿的预警指标。
4.3 预警临界值自适应训练
对该煤矿12171里段运输巷2020-09-01—2020-10-10期间实测值K1和对应的预警A指标数据进行处理,通过回归分析,计算各时间段内2者之间的关系,如图4所示。
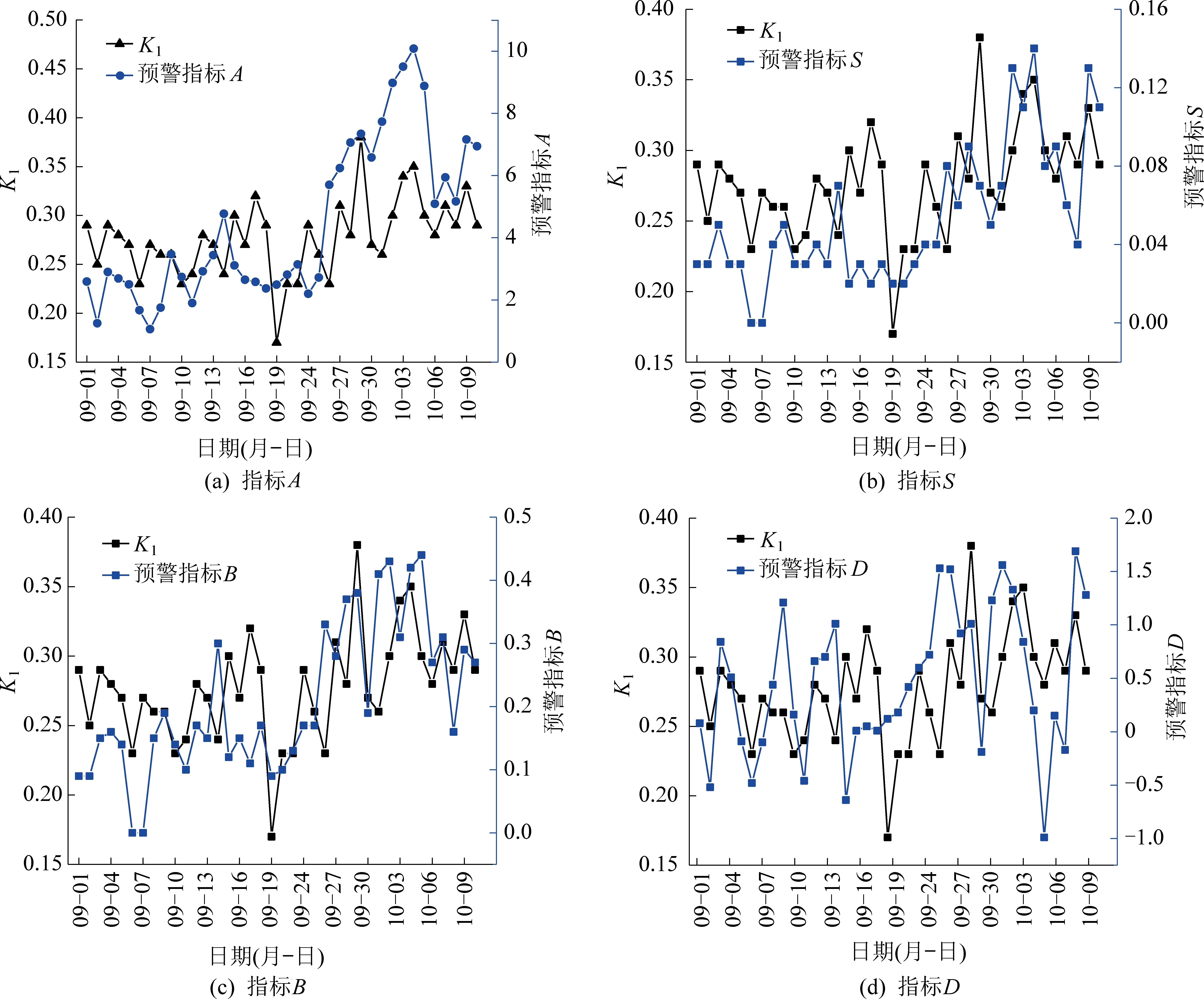
图4 4个预警模型有效性分析Fig.4 Effectiveness analysis of four early warning models
由图5可知,随着工作面的推进,实测数据和预警指标数据不断丰富,预警临界值模型动态更新以更好的反映预警指标A与K1值之间的关系。计算得出2者的关系模型,得出当K1=0.5时,对应预警A指标大小即为预警临界值,计算结果见表3。

表3 预警临界值计算结果Table 3 Calculation result of early warning critical value

图5 预警临界值随时间变化趋势Fig.5 The warning threshold changes over time
由表3可知,随着时间的推移,预警临界值随之动态变化,应用前40 d的临界值模型计算出该工作面当K1=0.5时,A指标临界值为9.99。当指标超过9.99时认为突出危险性较高。
临界值模型刚开始应用时数值变化较大,初始阶段可以使用默认预警临界值,随着采掘作业的进行,预警临界值自适应后可采用训练后的临界值进行预警。为加快预警临界值的优化过程,可将同一地质单元或采区的数据进行保存,用于下一个工作面掘进时继承迭代更新。
4.4 预警典型案例
该煤矿12173里段运输巷在掘进期间瓦斯涌出量大,煤与瓦斯突出危险较高,应用该技术体系,对掘进过程进行持续监控。2020-08-10晚班,预警系统的预警A指标超过临界值,并及时向该煤矿通风部发送了预警短信。2020-08-11早班掘进作业时瓦斯体积分数继续攀升,预警A指标达到11.42,随即前往工作面查看,经现场确认该工作面掘进工作面顶板附近煤厚异常,煤层厚度由4.5 m增大到了6 m,使得瓦斯涌出异常升高。在采取相应措施后安全穿过煤层厚度异常增大区域,随后瓦斯体积分数水平逐步回落,预警指标也逐渐回归正常。
5 结 论
1)研究了多源数据驱动防突预警指标自适应技术,通过多源数据采集、建立预警模型、模型的有优选和预警临界值自适应训练,提高了预警指标的有效性和精确性。
2)研究了预警模型优选方法,实现对预警模型的有效性定量评价,克服传统人工定性筛选所存在的随机性偏差问题。
3)研究了预警指标临界值自适应方法,使预警临界值能够自适应煤矿开采条件,有效缩小预警临界值范围,提高预警准确率。
4)该技术体系在贵州盘州地区某煤矿应用过程中,提前捕捉到煤层厚度异常导致的瓦斯涌出异常现象,具有良好的预警效果。
猜你喜欢
中原商报·科教研究(2022年1期)2022-05-13
电子乐园·上旬刊(2022年5期)2022-04-09
散文(2022年2期)2022-04-01
科学与生活(2021年25期)2021-12-02
意林原创版(2021年7期)2021-08-03
知识文库(2018年2期)2018-05-14
大陆桥视野·下(2016年5期)2016-07-05
科技与创新(2016年3期)2016-03-15
三联生活周刊(2015年52期)2015-12-25
科技与企业(2015年18期)2015-10-21
