
差分隐私软大间隔聚类
2022-10-06 04:18谢云轩
计算技术与自动化 2022年3期
谢云轩
(南京航空航天大学,江苏 南京 210000)
如今,AI技术几乎在每个行业都显示出其独特的优势。优势之一便来自大数据驱动。虽然对大数据的挖掘用于研究与决策可极大地改善社会体系,但是数据的共享同时也伴随隐私的泄露。因此必须保护那些提供个人身份信息等各种机密数据的用户的隐私。比如当研究机构使用这些信息进行模型训练并将模型公开时,隐私信息可能会泄露。因此,有必要在模型训练过程中增加隐私保护技术。
在数据挖掘的众多方法中聚类(Clustering)是一种较流行的无监督学习手段,其将数据集划分为多个由相似示例组成的簇,使得同一簇内的任何两个示例的相似性大于不同一簇的任意两个示例的相似性。然而,对于大规模数据或分布式存储数据,一般的单机聚类算法无法满足对其聚类的训练需求,即使可行,训练的时间代价也过于高昂。因此,对单机聚类算法进行分布式改造,减少对大规模数据或分布式存储数据训练的时间成本,是提高其伸缩性的有效途径。
在分布式计算中,不同节点通过在迭代更新中解决本地子问题并上传解,从而求得全局闭式解,达到整个模型的收敛。但是,不同节点的通信过程会带来隐私泄露的风险。因此,在迭代通信中,需要引入隐私保护技术确保隐私没有泄露的风险。
因而近年隐私保护理念持续受到人们的关注,其在数据挖掘、机器学习和深度学习等许多领域都得到广泛的应用。其中差分隐私通过混淆查询响应来防止对手获得关于隐私数据的信息,可以为个体隐私提供严格的保证而得到广泛研究。具体而言,差分隐私将随机噪声加入待通讯的数据,从而避免攻击者执行攻击来推测数据集的若干敏感信息。
尽管学界已提出了极其丰硕的高性能聚类算法,比如DeepClustering等,但对大量现有聚类算法不做选择地改造并不实际。因此本文将隐私保护改造局限于相对简单但又有代表性的聚类算法,目的不是提出新的单机聚类算法,而是示范如何让相对简单但又有代表性的聚类算法适应联邦学习环境,使之发挥更大的潜能。
软大间隔聚类(Soft Large Margin Clustering, SLMC)性能相对认可又简单,直接将数据映射到预定的个输出标记实现聚类。除了不同于FCM(Fuzzy C-Means)在数据空间内的聚类之外,其作为判别型算法在标记空间进行聚类产生的良好性能和一定程度的可解释性,并受到后续关注。因此本文选择将其进行隐私保护优化。当面对潜在的隐私泄露风险时,分布式软大间隔聚类(Distributed Sparse SLMC, DS-SLMC)与其他分布式聚类算法一样,遭遇了类似的瓶颈。因此引入隐私保护改造是一个自然选择。然而,改造的挑战是如何在保持原有聚类算法收敛速度和准确度的同时,降低隐私泄露的风险。需要对改造后的算法进行理论证明,看其是否符合差分隐私准则,并利用实验进行验证。
本文为了提高SLMC的隐私保护能力,发展出差分隐私软大间隔聚类(Differentially Private SLMC, DP-SLMC)。具体来说,在DS-SLMC迭代的过程中加入随机高斯噪声,为个体隐私提供严格的保证。同时通过-zCDP给出严格的隐私分析,证明本文提出的模型满足差分隐私准则。
本文的具体贡献如下:
1)将软大间隔聚类与联邦学习进行结合,通过引入随机高斯噪声减少不同节点间通讯导致隐私泄露的风险,从而解决不同节点进行分布式机器学习中的隐私问题。
2) 我们通过(,)-DP与-zCDP之间的关系进行理论证明,得到DP-SLMC算法的隐私保证。确保DP-SLMC算法满足差分隐私准则。
3) 利用数据集进行了广泛的实验并对其非隐私版本进行比较,证明所提出算法的有效性。
1 相关工作
1.1 差分隐私
差分隐私定义如定义1-3所述。
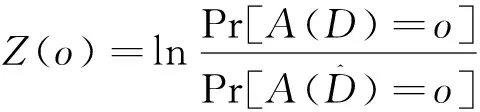
(1)
其中Z()的上界为的可能性至少为1-。
(敏感度) 查询函数()对输入的敏感度为:
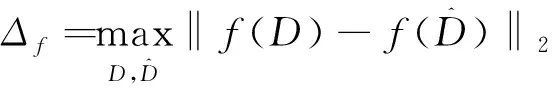
(2)
(高斯机制).对于函数而言, 高斯机制A定义为:
(,,)=()+
(3)
其中为从N(0,)的高斯分布中采样的噪声。高斯机制需要将其加入函数的输出中。当满足式(4)时,高斯机制A满足(,)-DP。
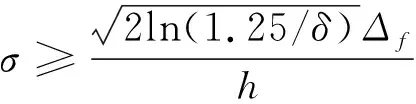
(4)
零集中差分隐私(zero concentrated differential privacy,-zCDP)是一个差分隐私的松弛版本,利用Rényi散度来度量随机函数在相邻数据集上的分布差异。-zCDP 如定义4所述。
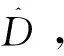
下文的引理1-3显示了-zCDP 与(,)-DP 的关系以及-zCDP的合成定理.
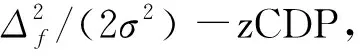
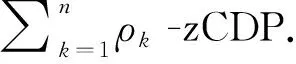
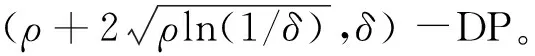
1.2 ADMM方法
在现有的分布式优化方式中,交替方向乘子法(Alternating Direction Method of Multipliers, ADMM)是一种比较流行的策略。ADMM将全局问题分解为多个局部子问题,通过协调子问题的解最终得到全局问题的最终解。ADMM对输入不敏感,还具有方法简单、可解释性高与收敛性易证明的优点。
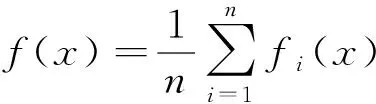
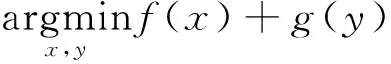
s.t.+=
(5)
通过优化这个目标函数,算法最终会收敛到某一个全局最优化或近似最优结果,从而解决了分布式中的一致性优化问题。
然而,满足差分隐私的ADMM算法大多数都是去中心化的。比如动态zCDP(dynamic zero concentrated differential privacy)在每次迭代中引入具有线性衰减方差的高斯噪声,在加速训练的同时保持隐私保护的效能。K-Fed算法将联邦学习与one-shot学习结合,只需一轮通讯即可完成K-Means算法的训练。L-FGADMM将节点分为头尾两组,以确保每个节点只与其相邻的两个节点进行通信。此外,通过对神经网络的每一层选择不同的通信周期,L-FGADMM也减小了模型的通信负载。
1.3 分布式软大间隔聚类
软大间隔聚类(SLMC)由Chen于2013年提出。该模型将大间隔聚类(Maximum Margin Clustering, MMC)与软聚类结合,在输出空间进行聚类,而不是在数据空间中寻找一组聚类中心。具体来说,SLMC将簇中心锚定为个输出标记的预定义编码,计算决策函数和输出空间中数据的软隶属度。它兼有大间隔聚类和软聚类的优点,一方面具有寻求簇间最大间隔的决策函数,另一方面通过引入软学习原理,使每个实例都属于具有相应软隶属度的多个簇/聚类,并可通过软隶属度反映属于单个簇的程度,从而具有较强的聚类能力。
对SLMC结合ADMM进行分布式改造之后,优化问题表示如下。
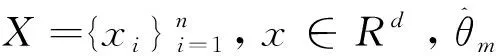
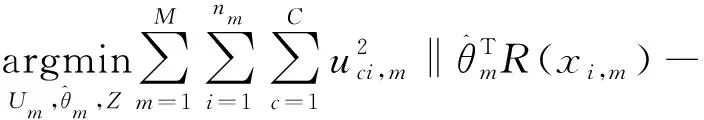
‖+‖‖
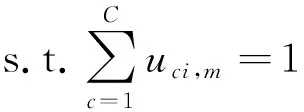
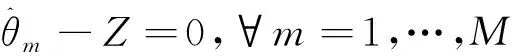
0≤,≤1,∀=1,…,,=1,…,,
=1,…,
(6)
其中决策函数为:
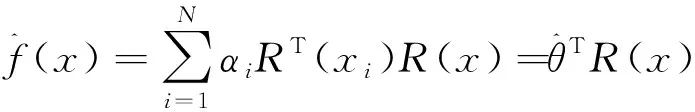
(7)
该算法通过引入RBF核的显式特征映射近似,在不降低精度的前提下降低了时间复杂度。具体而言,该算法用傅立叶变换的蒙特卡罗逼近RBF核的特征映射。特征映射的方式如式(8)所述。
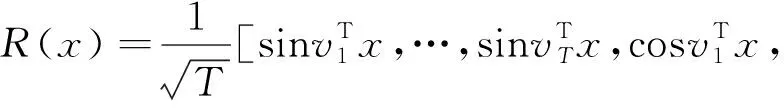
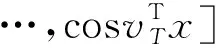
(8)
为RBF核对应高斯分布中随机抽样的向量。显然,这种近似的精度会随着样本数量的增加而增加。在训练中,将会根据具体场景考虑精度与复杂度的权衡来选择一个适当的。
对其增广拉格朗日优化格式实现采用交替迭代策略求解,可得迭代更新式:
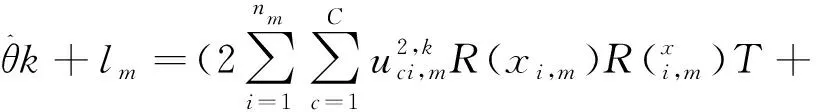
)-1

(9)
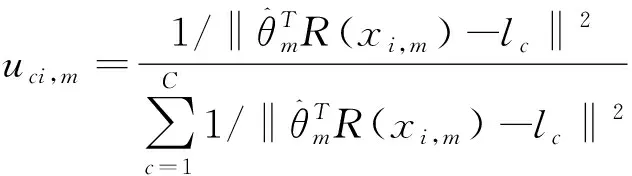
(10)
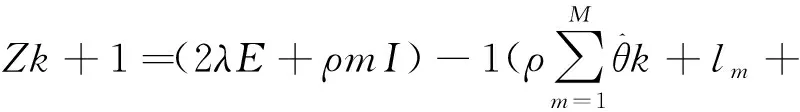
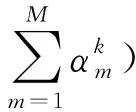
(11)
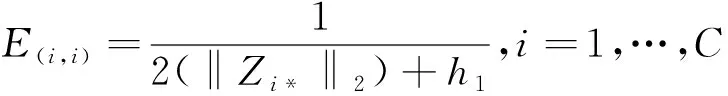
(12)
为了防止分母为0,故在分母处添加非负小量数。
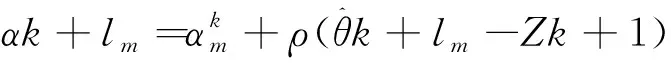
(13)
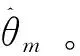
然而,目前还没有关于差分隐私中心化SLMC算法的研究工作。因此,本文重点关注中心化差分隐私ADMM算法并提出了具有隐私保证的差分隐私软大间隔聚类算法。
2 差分隐私软大间隔聚类
2.1 差分隐私软大间隔聚类
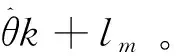

算法1 隐私保护软大间隔聚类算法输入:λ、ρ,停止参数εs、εr,,节点数M、映射特征维度D、输入数据X;输出:软隶属度矩阵Um;Each learner constructs random feature map Rm(x) with the same seed.Initialize Um by FCM,k=0.Upload Um+ξk+1mto the central server where ξk+1m~N(0,σ2Im+1D).Update Zk+1 in the central server by (11).Update θ^k+lm in parallel by (9).Update Uk+lm in parallel by (10).Update αk+lm in parallel by (13).k=k+1.If not obtaining convergence then go 3.10. Output Um at each learner.
2.2 隐私保护分析
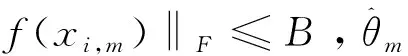
证明:根据式(6)可得:
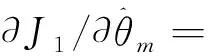
(14)
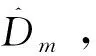
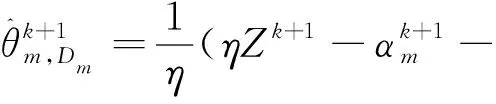
(15)
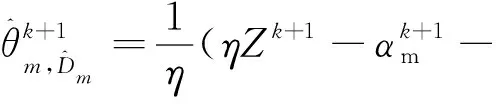
(16)
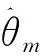
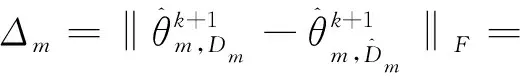
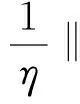
(17)
DP-SLMC的隐私保护效用如定理1所示。
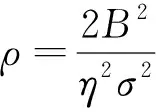
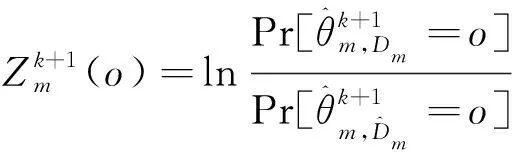
(18)
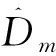
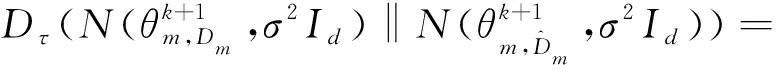
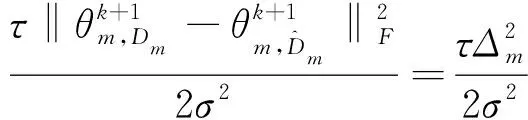
(19)
可得:
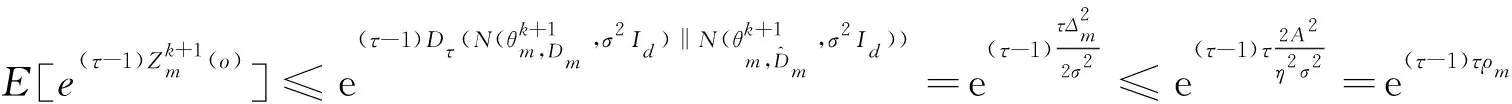
(20)
由于在整个迭代过程中每一轮都在更新与上传系数矩阵,因此需要计算迭代过程中隐私损失的总和。
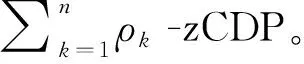
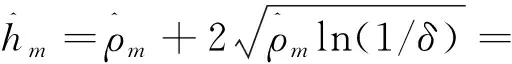
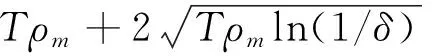
(21)
对于所有节点, DP-SLMC被(,)-DP限制的总隐私损失为:
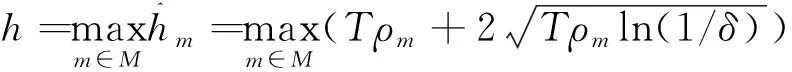
(22)
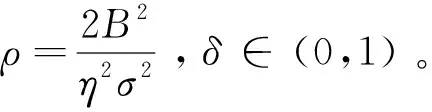
3 实验部分
本节将会通过 UCI 数据集来对本文提出的算法进行实验,探究其性能。第3.1节中说明实验相关设置。第3.2节引入本次实验的对比指标。最后进行实验并对实验结果进行分析,验证该方法的有效性。
3.1 实验设置
本节将与未做隐私保护的分布式SLMC进行对比分析,进行性能比较。
我们对待对比的算法执行了20次独立实验,在每次实验中使用最优的核与参数设置,并最终记录这些实验结果的平均值。所有的实验都是在一台具有英特尔(R)核心(TM)四核处理器(i7CPU@3.6GHz)和16.0GB内存的64位机器上进行的。表2描述了实验数据集的属性。
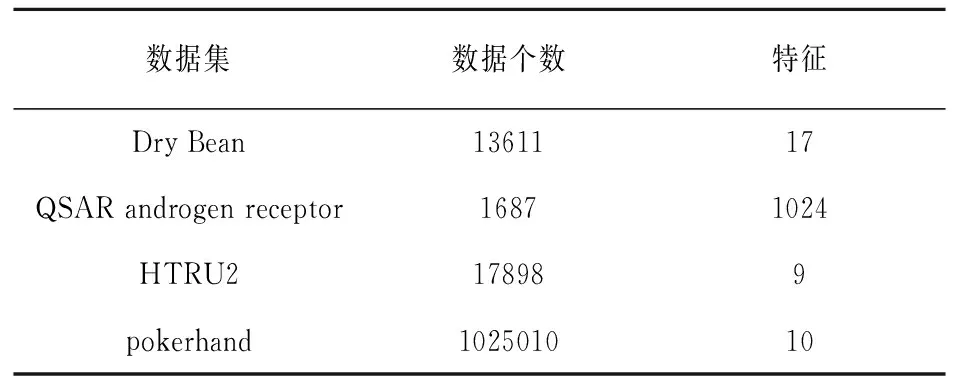
表2 数据集属性
3.2 评估指标
虽然本文提出的是无监督分布式聚类算法,但在训练时可通过带类别标签的数据集进行训练。具体来说,在训练时将类别信息剔除,然后将聚类的结果与真实标签相比较。因此可采用聚类准确度(Clustering Accuracy, CA)来对算法进行性能评价。
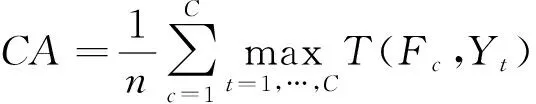
(23)
代表第聚类标签,而代表真实标签。(,)则代表属于真实类别而被预测为类别的数据个数。我们通过比较预测聚类的标签与真实标签的方式,来确定聚类的准确度。显然这个数值是越大越好。
此外,由于本文提出的是联邦聚类算法,因此也将与未进行隐私保护的分布式软大间隔聚类(DS-SLMC)进行收敛速度的对比。
3.3 实验分析
图1显示了DP-SLMC算法与DS-SLMC算法目标函数值的对比。DP-SLMC与DS-SLMC的收敛曲线基本吻合,证明二者收敛速度并无太大差异。这个符合我们的直觉,即对交换变量加入符合差分隐私要求的噪声对收敛过程与函数值影响较小。这个实验证明即使加入噪声,只要控制噪声的大小,噪声本身对模型的收敛无法造成较大的干扰。
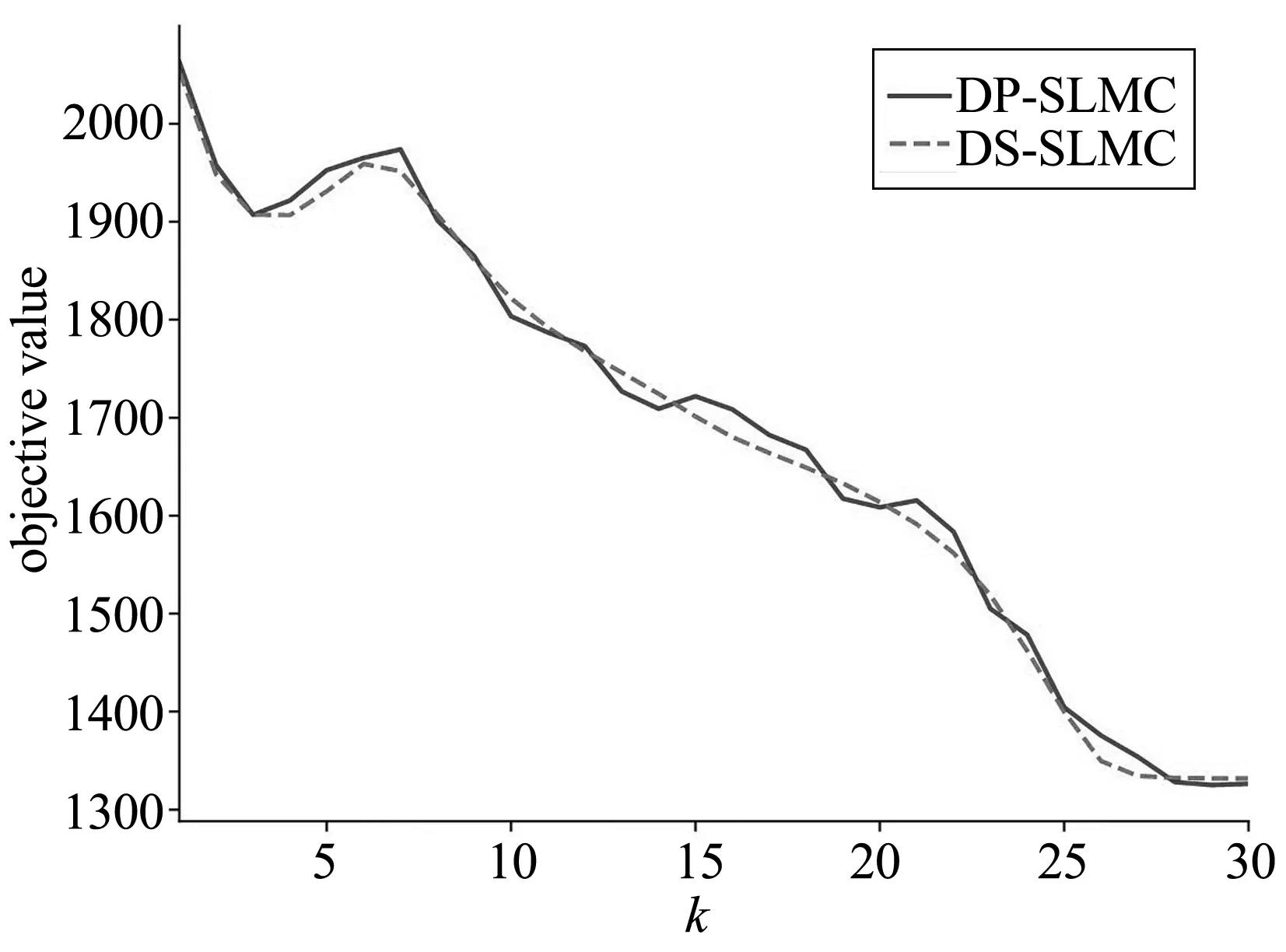
(a) Dry Bean
DP-SLMC在不同隐私预算下的目标函数值与准确度对比如图2所示。在隐私预算较小的情况下,由于加入的噪声过多,DP-SLMC的目标函数值与准确度相比,DS-SLMC算法表现不佳。但随着隐私预算的增加,加入的噪声逐渐减少,DP-SLMC的目标函数值与准确度越来越接近DS-SLMC算法。这个实验说明,保证差分隐私的前提下,只要给予足量的隐私预算,噪声本身对算法的准确度无法造成较大的干扰。在实际应用场景中,可通过准确率与隐私保护需求的权衡来决定隐私预算的大小,从而让算法最大限度地满足需求。
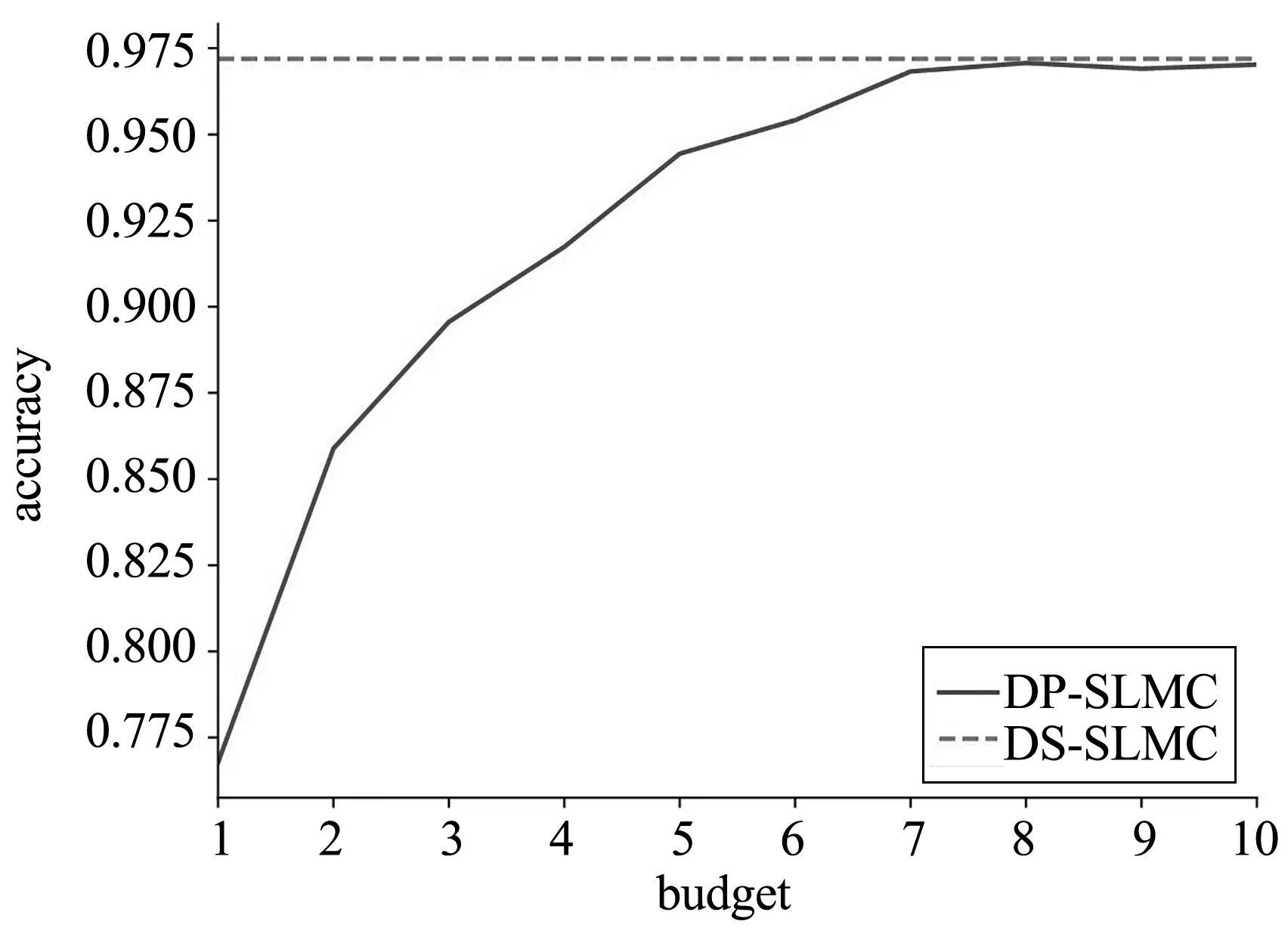
(a) Dry Bean
4 结 论
提出了一种联邦软大间隔聚类算法,将原聚类算法与隐私保护进行结合。为了实现这个目标,我们将原始的聚类问题中容易发生隐私泄露的通信环节加噪,使其满足差分隐私准则,从而达到隐私保护效果。而实验结果也表明本文提出的算法在降低隐私泄漏风险的前提下,依旧有贴近原聚类算法的性能与较快的收敛速度。此外,我们也通过实验验证DP-SLMC在不同数据集上都拥有良好的聚类性能。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
上海师范大学学报·自然科学版(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
电子技术与软件工程(2016年23期)2017-03-06
新东方英语(2016年4期)2016-04-06
读写算·小学低年级(2014年4期)2014-07-24
小雪花·成长指南(2009年10期)2009-12-04
