
融合空间掩膜预测与点云投影的多目标跟踪
2022-10-02 09:26:22陆康亮陶重犇
光电工程 2022年9期
陆康亮,薛 俊,陶重犇,2*
1苏州科技大学电子与信息工程学院,江苏 苏州 215009;2清华大学苏州汽车研究院,江苏 苏州 215134
1 引言
在计算机视觉领域中,目标跟踪在自动驾驶中扮演着关键角色[1-2]。点云中的三维目标跟踪应用更是至关重要[2-4]。现有大多数三维目标跟踪算法都是直接处理点云信息[3],然而,点云的稀疏性和无序性给这项任务带来了巨大的挑战,对于点云精确度的严重依赖也使得计算成本大幅度提高。本文将注意点从直接处理点云转移至利用二维数据处理三维数据。
随着视频处理能力取得巨大的进步,视频目标跟踪任务成为了新热点,国内外对目标跟踪进行了深入的研究[5-7]。在相关跟踪的方法中,如Jiang 等[8]提出的方法是一种基于注意力模型的分层多模式融合全卷积神经网络构建的RGB-D 跟踪算法,能够通过深度图形获得更丰富的语义感知;Muller 等[9]提出的方法从一系列RGB-D 帧中检测每个帧中的目标并学习预测目标的几何形状以及到规范空间的密集对应映射,为每帧中的目标导出6DoF 姿势和目标在帧之间的对应关系,从而在RGB-D 序列中提供稳健的目标跟踪。上述算法都依赖于RGB-D 数据,对于点云精度依赖性不高,因此计算成本低。此外,He 等[10]提出了一种可学习图匹配方法的多目标跟踪,图匹配方法着重于轨迹和检测之间的关系。然而这些算法仍存在光照遮挡等问题导致的目标丢失情况,因此本文将注重优化跟踪任务中的目标丢失问题。
为了从数据中挖掘信息,国内外研究人员引入了自监督方法[11-12]。许多新的跟踪方法通过多模态融合来估计运动,例如Luo 等[13]通过利用来自点云的免监督信号和成对的相机图像来通过自监督纯粹地估计运动。研究人员还探索了利用视频的空间信息来进行学习的方法,如Han 等[14]通过对原始视频进行自监督的对比学习,强化视频目标的表示,从而进行动作识别;Wang 等[15]采用自监督学习的方法来训练局部相关性模块,使得模型对相似物体的判别能力更强。然而,上述算法运算量大,并且无法满足目标跟踪所需的实时性要求。因此,本文将结合自监督优化方法设计一种跟踪器,并用于优化跟踪任务中的实时性。
针对上述问题,本文提出了一种基于融合空间掩膜预测与点云投影的多目标跟踪算法。算法模型主要在时序跟踪器前增加第一层掩膜输入以提高目标初始位置的准确性。其次,使用卷积神经网络为主导的跟踪器进行跟踪,优化每帧的单独实例分割,以提高跟踪器的速度,从而提高实时性效果。与之前的自监督方法类似,跟踪器对目标掩膜的空间特征学习,预测目标在后续帧的具体位置,从而获得整个视频序列对于目标的跟踪掩膜,因此减少遮挡对跟踪目标的丢失情况。还设置了一个验证层,将抽取样例掩膜输出与跟踪器对应图片输出进行比较验证,以减少检测不细致导致的跟踪丢失。最后,将二维视频处理后获得的掩膜数据,用点云投影的办法与三维雷达中的点云进行匹配,投影至三维点云中以获得三维目标跟踪。
创新点如下:1) 以卷积神经网络目标检测模块为基层模块,不直接使用实例分割模块进行跟踪,减少掩膜提取量。2) 增加了一个预测模块梯度损失函数,以增加算法对于预测掩膜精准度的把控,提高了算法对于预测出现差错所拥有的修正能力。3) 通过将二维跟踪到的目标掩膜数据投影到对应的点云图像上,不需要对于点云图像进行进一步处理。
2 理论推导
首先,本文利用空间位置预测模块来保存跟踪实例的位置信息,将序列视频信息输入算法跟踪层,以获得简单的跟踪目标信息。然后,通过基于FCOS[16]的EmbedMask[17]算法的掩膜分类分支来预测检测到的边界框,并且生成实例特定的空间系数。在空间掩膜预测模块中,针对边界盒内的每个子区域的空间进行单独的掩膜边界框预测,并通过每项单独的映射预测组合来获得最终实例掩膜预测。最后,通过确定信息的实例掩膜数据与雷达点云的关联特征相对应,利用二维掩膜覆盖确定三维点云中的目标位置,算法框架图如图1 所示。
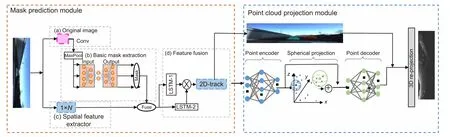
图1 算法框架图Fig.1 Algorithm frame diagram
2.1 掩膜预测模块
掩膜预测模块对同一物体不同帧的掩膜信息进行标定,从而获得每帧之间对于同一目标的跟踪定位。本模块对第一帧图像掩膜进行提取工作,后续帧的掩膜信息通过预测形式进行提取,这减少了提取图像每帧掩膜信息和跟踪对比所浪费的大量算力。同时,通过预测掩膜与验证帧掩膜的对比验证,这样既保证了掩膜预测正确,也节省了算力并提高运行速度,掩膜预测模型如图2 所示。
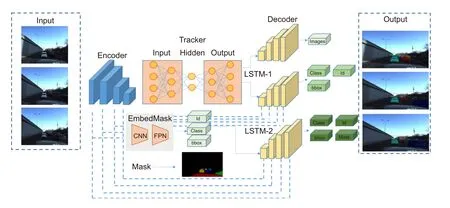
图2 掩膜预测模块Fig.2 Mask prediction module
2.1.1 基掩膜提取
目标检测的任务是找出图像中所有感兴趣的目标,并确定其位置和大小,这是机器视觉领域的核心问题之一[18]。随着深度学习的不断发展,实例分割算法开始出现,其目的是指定一个像素级的掩膜来对图像中的每个目标进行定位和分类。传统的目标检测仅提供盒级定位信息,然而实例分割提供目标轮廓级信息,从而能够更好地提供目标准确的位置信息。目标跟踪器需要对于目标捕捉拥有一定的实时性要求,然而Mask RCNN[19]算法存在无法保留精细掩膜和识别速度缓慢的弱点,难以做到实时准确的目标识别。因此,采用可高速运行并制作高分辨率掩膜的EmbedMask算法,这一优化能够快速地预处理图像序列,从而提高每秒输出帧数(frames per second,fps)。此外,由于选取EmbedMask 算法提供目标跟踪所需求的目标位置信息,单阶段方法减少了计算成本,从而能够给予后续跟踪器充足时间进行帧与帧对比分析以做到实时化处理。
EmbedMask 算法是使用多任务丢失的端到端优化,其损失函数被联合优化为
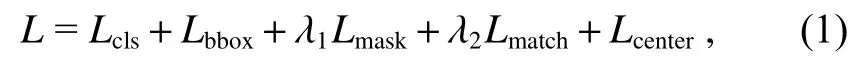
其中:除了FCOS 中原有的分类损失Lcls和盒回归损失Lbbox之外,还引入了额外的损失用于掩膜预测的Lmask和Lmatch。
2.1.2 掩膜预测模块
掩膜预测模块对序列图像后续掩膜进行预测,使用一种特殊的循环神经网 络Long-Short Term Memory (LSTM)[20]的门控制去预测获得最终的掩膜覆盖。LSTM 的特点在于单个循环结构内部有四个状态,循环结构之间将保持一个持久的单元状态不断传递下去,用于决定要遗忘或继续传递下去的信息。通过各种状态门之间的转化,判断该层是否选择输出或者跳转到下一层。通过阀门的控制,使得LSTM 框架解决在训练过程中数据量过大而造成的梯度爆炸问题,这种算法很好地应用到序列图像中的目标数据关联计算。
当建立多目标跟踪外观模型时,可以认为ct代表目标外观的存储模板,通过外观的数据变化量,决定是否将门ot输出之前存储的外观ct-1,以决定当前输出ht。LSTM 使用以下规则运行:

其中:◦ 表示哈达玛积(Hadamard product)。
基于LSTM 的空间掩膜预测模块如图3 所示。在给定输入的序列图像的情况下,预测模块以边界框、基掩膜和空间系数为输入,预测最终的掩膜。首先,通过基掩膜和空间系数定义模型中的外观输入ct并存储第一帧的外观输入ot+1,同时与第二帧的外观输入对比。然后,结合外观数据的变化量决定是否将门ot输出预测外观ot+2。最后,将新获得的外观输出和第三帧输入的外观数据进行比较获得一个新的Lcenter值以表达空间预测模块的梯度下降性能。

图3 预测帧模块Fig.3 Prediction module
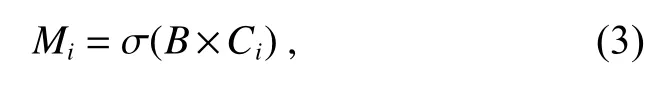
其中:σ 为掩膜输入的规范化表示,B是整个图像所拥有的m个基掩膜输入,Ci表示每张图片所获得的外观输入。Mi表示所有边界框的映射,已获得最终掩膜所拥有的边界框形状和位置信息。将预测边界框映射中心点与同帧边界框输入中心点信息对比,获得对于空间位置信息的变化梯度增加变量Lcenter如式(4),以确保边界框预测合理。
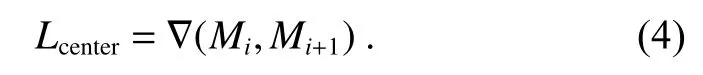
2.1.3 二维目标跟踪器
本文采用EmbedMask 算法进行序列图像的边界框及基掩膜特征提取,只使用基掩膜和目标的边界框判定,减少了实例分割模块对于每一帧图像中每一个目标的掩膜分割。不使用每帧的掩膜覆盖输出作为跟踪器的输入,避免了输入数据量过大而导致的梯度爆炸问题,同时也减少了输入量递增所产生的检测速度极度下降的情况。其次,将输入的序列图像边界框判定以及基掩膜作为外观总特征,输入空间掩膜预测模型中,通过LSTM 模型对于每帧图像外观特征的变化进行一定量约束,以门类型的决策进行输出判断。然后,对后续图像的掩膜输出进行预测,以获得最终的掩膜输出,从而实现多目标跟踪器。最后,通过验证帧的掩膜输入作为判据,以确保输出的掩膜帧跟踪目标的鲁棒性。通过这种优化减少一定量的特征输入并确保算法不失准确性,为提高实时速率提供了保障。
本算法采用实例分割检测模块与LSTM 空间掩膜预测模块融合的多目标跟踪器。通过将不同帧的视频信息作为输入Σpi,最终获得的掩膜 Σyi为输出,得出以下算法:

2.2 点云投影
三维点云数据存在处理数据量大和处理难度高的问题,然而二维图像处理技术较为成熟,并且可以通过提升硬件性能来提高处理速度。因此,本文通过对二维相机数据与三维雷达点云数据的对比匹配,将二维图像的跟踪数据投影到三维点云中。点云投影的方法不仅能够让自动驾驶车辆对于道路情况拥有更好的信息感知能力,还可以减少点云计算并提高算法的实时性,点云投影模块如图4 所示。

图4 点云投影Fig.4 Point cloud projection
2.2.1 三维雷达与长焦相机的联合标定
激光雷达和单目相机之间的标定是传感器所必需的,需要获取相机与激光雷达外参,将点云三维坐标系下的点投影到相机三维坐标系下。还需要通过相机标定获得相机内参,将相机三维坐标系下的点投影到成像平面。通过调整标定板的角度可以将三维激光雷达数据与相机数据相转换,以确定雷达与相机内参统一,标定板效果如图5 所示。

图5 标定板效果Fig.5 Calibration board effect
在联合标定时,会使用基于投影的方法估计激光雷达点云和相机图像平面中的一组目标特征。可以通过以下方式对应,找到激光雷达到相机的变换:

其中:Xi是雷达特征的(均匀)坐标,Yi是摄像机特征的坐标,P为“投影图”,是雷达框架的带有旋转矩阵和平移的摄像机帧变换,ddist是距离或误差的度量。
在一个确定目标顶点的新方法中,令Pr表示目标的雷达点云,并将三维点的集合设为Xi,使Pr={Xi}Ni=1,其中N是目标上的点数。对于外部校准问题,需要估计雷达框架中的目标顶点。
对于a>0 和 λ ∈R有:
秀丽隐杆线虫是一种重要的模式生物,以大肠杆菌OP50为食。它具有结构简单、身体透明、易于观察、生命周期短、子代数目多等生物学特征[4],并与人类脂肪代谢路径相似,各关键步骤的酶相似度较高[5]。通过线虫的生理生化研究,有助于阐明并揭示食品中功能活性成分对健康的影响及作用机制。L-阿拉伯糖作为一种食品中重要的代糖来源,目前在模式生物线虫中的研究较少。因此,本试验拟通过研究 L-阿拉伯糖对秀丽隐杆线虫生长发育和脂肪合成能力的影响,为进一步探索开发其功能活性,并揭示其健康作用机制提供理论和试验基础。

其中:d由(正方形)目标的大小确定,唯一的调整参数ϵ >0(即理想目标的厚度)。并定义估计的目标顶点为
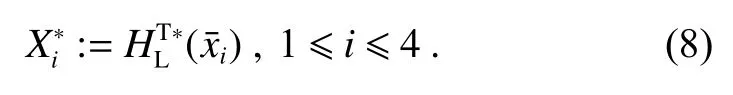
首先通过三维雷达和相机的联合标定,获取了估计的目标顶点。有了对应关系后,下一步就是将雷达目标的顶点[xi yi zi1 ]T=Xi匹配到图像坐标中。
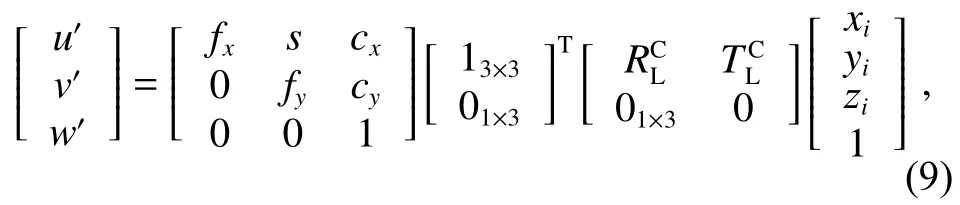
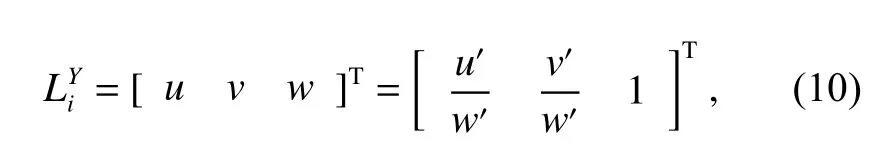
2.2.2 点云投影算法
假设已确定目标在雷达和相机图像平面中的顶点及其对应关系,用最小化相应角的欧几里得距离来表示外在变换的优化。同时,将对应投影多边形的并集和交集最大化。其中是摄像机角点公式

最后,通过“交叉验证”的形式评估了此对应关系式。以循环方式使用一个或多个场景中的数据估算外在变换,然后评估剩下的场景。
当获得相机与雷达点云的对应关系后,将识别所得掩膜数据投影到雷达点云之中,通过球投影算法,将雷达中目标所对应点云数据进行渲染标注。以投影雷达点云的方式获得目标在三维点云图像中位置信息,投影关系如图6 所示。

图6 掩膜投影到点云中Fig.6 Mask projection
3 实验与分析
3.1 二维跟踪器训练及分析
本文基于百度阿波罗数据进行实验模型训练。在训练模型中输入如图7 的一组序列的视频数据和相对应的掩膜数据进行训练,最终获得跟踪器的权重文件。将阿波罗数据集的实例分割样本分为进行了训练、测试和验证三部分,对训练集进行了培训,并且在测试集和验证集中进行了训练结果的分析,再对边界框使用空间掩膜预测训练线性组合获得最终掩码,从而完善跟踪器。

图7 向模型中输入序列RGB 和掩膜数据。(a)原始序列RGB 数据;(b)对应序列掩膜数据Fig.7 Input sequence RGB and mask data into the model.(a) Original sequence RGB data;(b) Corresponding sequence mask data
在训练模型中输入所需数据,通过不断迭代和训练获得loss 曲线如图8 所示。其中图8(a)显示了算法定义的四个不同loss 值所产生的曲线下降,图8(b)显示了四个loss 值总和所展现的曲线梯度下降。通过曲线可以看出梯度下降在一开始表现得非常迅速,到后期逐渐趋于平缓。本算法通过四个loss 值展示训练效果,最后将其总结成最终的loss 值。

图8 损失函数曲线。(a) 四种定义损失;(b) 总算法损失Fig.8 Loss function curve.(a) Four definitions of loss;(b) Total algorithm loss
在掩膜提取部分,本文算法与主流实例分割算法进行对比,结果如表1 所示。可以看出本文掩膜提取算法在识别精确度方面和主流的算法Mask R-CNN 相近,并且实时速度提升显著,与主流算法YOLACT相近。通过上述实验分析,可以体现出本算法在保证精度稳定情况下,提高了算法的实时性。
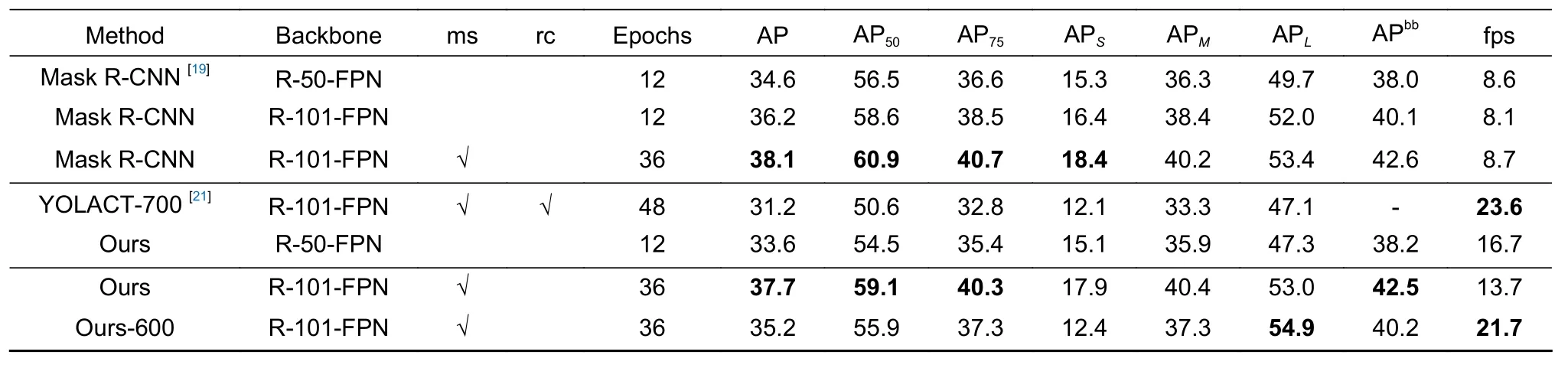
表1 本文与其他算法对比Table 1 This algorithm is compared with other algorithms
利用PR 曲线验证分类状况,并与Yolo-V3[22]、Faster-RCNN[23],MS-RCNN[24]进行比较,PR 曲线如图9 所示。其中Precision 能够体现模型分类为正样本的数量中分类正确的比例,其计算方法为在设定某一阈值的情况下,正样本的预测数除以被预测为正样本的数量(包含错误预测为正样本的负样本)。Recall作为召回率,计算方法为在设定某一阈值的情况下,分类正确的样本除以所有正样本的数量。因此,不同的阈值会得到不同的Precision 和Recall 的值,由此绘制PR 曲线。可以看出,本算法相较于这些成熟的目标检测算法具有良好的收敛性。在不同阈值下,本方法能够更好地兼顾精确率和召回率,且比其他方法收敛地更慢。

图9 PR 曲线对比Fig.9 PR curve comparison
本文主要解决的是遮挡以及光度变化所导致的跟踪目标丢失而引起的跟踪器失灵的问题,因此本算法与其他算法在不同的距离、遮挡度、光度以及模糊度下进行对比实验。结果如图10 所示,从图像看出,对于完全遮挡和完全图像损失,所有算法都完全丢失目标无法获得跟踪。然而,对于图像一般变化时,本文跟踪器的精确度明显高于另外两种跟踪器。特别对于遮挡情况,本算法能够在完全遮挡情况下,通过预测帧与帧的关联提供目标跟踪功能。这可以体现出本算法的鲁棒性强,对于遮挡问题的解决较为明显。

图10 三种算法对于不同距离、遮挡度、光度以及模糊度的精确度Fig.10 The accuracy of the three algorithms for different distance,occlusion,luminosity and ambiguity
本文算法在传统的目标跟踪框架基础上,优化了遮挡导致的目标丢失问题。与其他算法在MOT 数据集检测,结果如图11 所示,在图中可以看出本算法的跟踪性能不输于其他传统方法,尤其在KITTI 数据集中,本算法效果明显优于其他算法。
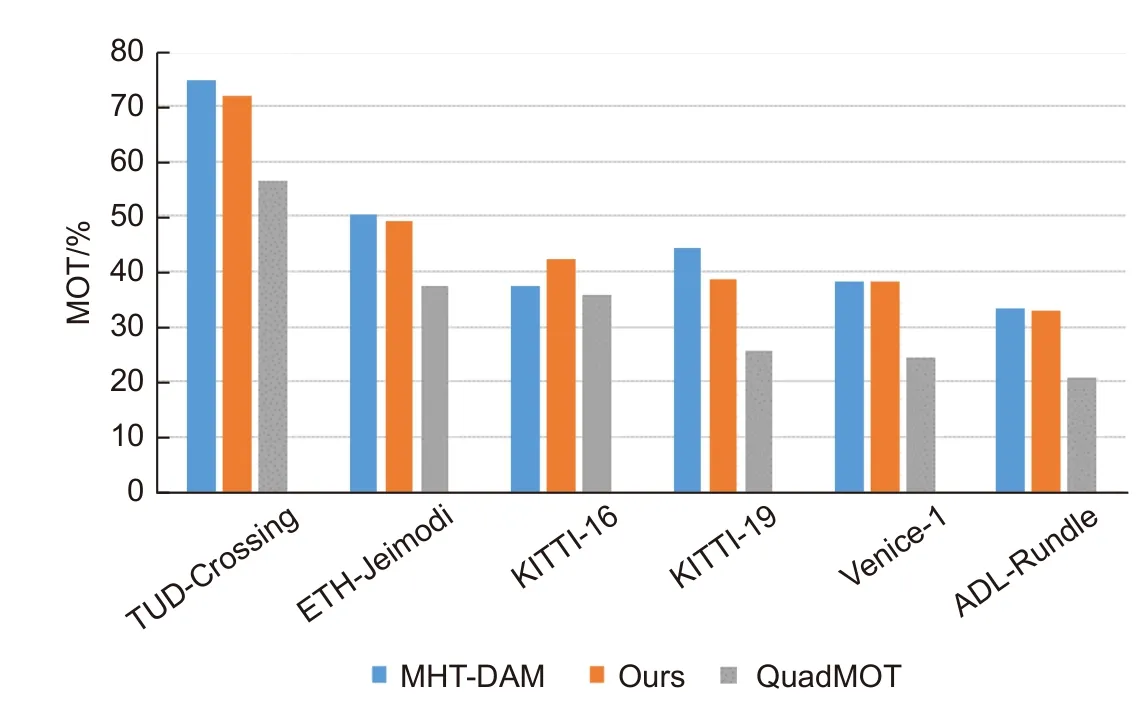
图11 多种目标跟踪算法在MOT 上的性能Fig.11 Performance of multiple target tracking algorithms on MOT
本算法与一些主流的多目标跟踪算法做了对比,结果如表2 所示。在针对车辆的KITTI 多目标跟踪数据集中,本算法的分割准确度优于其他所示算法。在针对行人的KITTI 多目标跟踪数据集中,本算法效果与其他算法相近。由于本算法主要针对目标车辆进行跟踪,行人的外形变化可能会导致一定丢失目标,使得准确度略低于现有多目标跟踪算法。由于本算法采用空间掩摸预测模型对目标进行跟踪,在跟踪精确度方面略低于其他算法,然而本文的主要目标是提高算法对被遮挡目标的跟踪准确度,略微的跟踪精度下降不影响跟踪器效果体现。
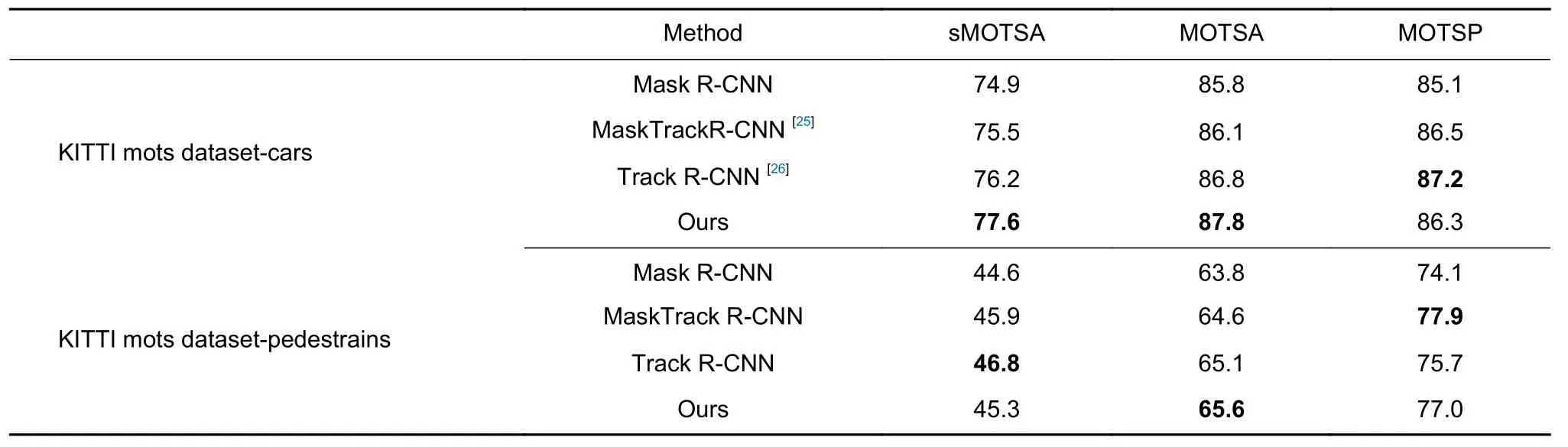
表2 性能指标Table 2 Performance index
在阿波罗数据集中测试结果如图12 所示,对于目标的重叠等问题显示了良好的解决效果,所获得的跟踪目标准确并且掩膜覆盖得完整良好。

图12 阿波罗数据集测试效果Fig.12 Effect of Apollo dataset test
为了验证训练模型的鲁棒性,使用阿波罗数据中训练所获得的模型去测试KITTI 数据集。如图13所示,对于不同情况的道路车辆状况,本算法具有一定的兼容性,这也为实时性开发奠定了良好的效果基础。对于KITTI 数据集图像分辨率问题,采用了数据集匹配模型的方法进行了测试,后续将优化跟踪器模型对于不同相机的兼容性,以获得更好的实际使用效果。

图13 KITTI 数据集测试效果Fig.13 Effect of KITTI dataset test
在BDD100K 数据集的多种经典无人驾驶子数据集中进行效果测试,可以更好地检测出算法对于复杂多变的交通环境的跟踪适应能力。在图14 的表现中可以看出,本算法兼容性良好,对于不同的相机拍摄环境因素都拥有很好的稳定性,能够准确地检测出所要求的多目标跟踪车辆。

图14 BDD100K 数据集测试效果Fig.14 Effect of BDD100K dataset test
3.2 三维点云实验
本文通过联合标定的方法,将每帧获取的RGB目标跟踪掩膜与三维点云相匹配。以二维跟踪掩膜获取三维跟踪目标点云,从而获得三维目标跟踪图像。通过深度位置关系,可以使得自动驾驶车辆获得最为准确的目标信息,从而做出更好的决策。三维点云图像如图15 所示,可以看到算法拥有较为良好的匹配。

图15 点云投影效果Fig.15 Effect of point cloud projection
3.3 道路测试
本文使用一辆搭载了多传感器的自动驾驶汽车进行实验。实验平台如图16,汽车拥有一个集合了短焦相机的32 线三维激光雷达、一个长焦相机、两个RTK 定位装置和车头的毫米波雷达。主要使用三维激光雷达以及长焦相机进行配合,对点云目标进行跟踪处理。
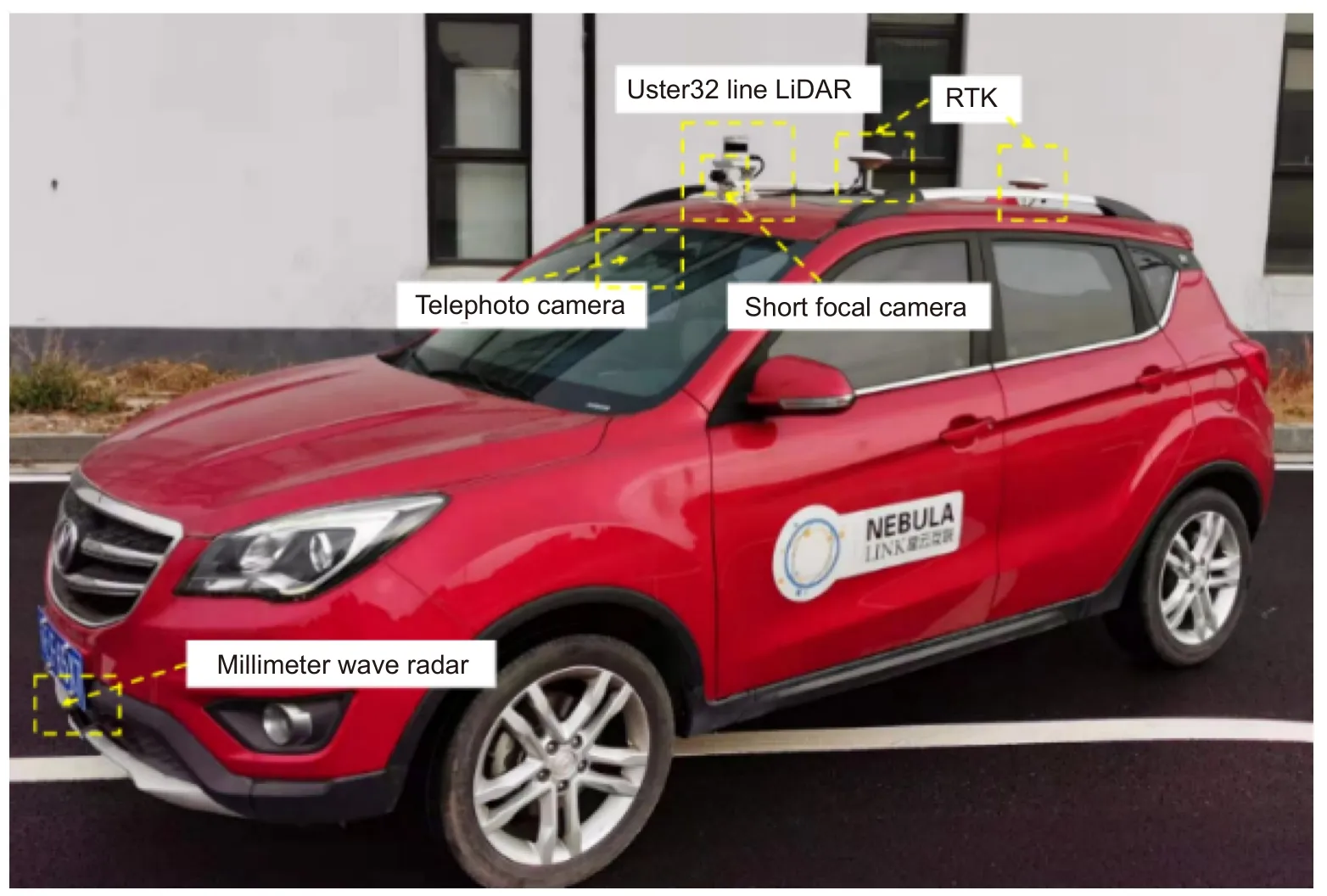
图16 实验平台Fig.16 Experimental platform
实际道路测试在清华大学苏州汽车研究院的试验场地道路上进行,结果如图17 所示。首先在ROS 系统中录制实时道路数据,然后使用本算法对数据进行目标跟踪,最后可视化输出最终结果。本文构建的数据集输入模型得到的检测结果显示,整个算法在实验平台上运行时间为32 ms,对于车辆跟踪的平均精度达到81.63%。从可视化结果也可以看出,本算法对中远距离的车辆检测效果良好,而对于近处的车辆,由于角度偏差较大存在丢失情况,需要进一步修正。上述实验表明,该算法计算效率高,可以满足实际路况下的实时检测需求。

图17 实际道路测试效果Fig.17 Effect of actual road experiment
4 结论
本文提出基于掩摸预测与点云投影融合的多目标跟踪算法,很好地解决了目标跟踪中车辆重叠导致的目标丢失问题。在目标跟踪算法基础上,融合了空间掩摸预测来优化算法对于目标的跟踪效果,同时增加点云投影算法,将获取二维数据投影到三维点云中,能够更好地获取所跟踪的三维目标信息。结果表明,算法很好地解决了车辆遮挡导致的目标丢失问题。本文在多种数据集中进行跟踪器验证,能够很好地对多目标车辆进行跟踪。同时,算法在实际道路上进行测试,有效地满足了实际路况下的实时目标跟踪需求。后续将进一步增高算法对多辆车、拐弯、变道及车的形状突然变化情况处理的实时性和精准度,并通过传感器的边缘计算以更好地辅助决策系统判断。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
太阳能(2022年3期)2022-03-29 05:15:50
中国体视学与图像分析(2021年3期)2021-11-24 02:20:44
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
太阳能(2020年3期)2020-04-08 03:27:10
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
当代工人·精品C(2019年2期)2019-05-10 00:13:22
学生天地(2019年15期)2019-05-05 06:28:28
制造技术与机床(2017年10期)2017-11-28 05:20:18
