
结合遥感卫星及深度神经决策树的夜间海雾识别
2022-10-02 09:26:16符冉迪尹曹谦
光电工程 2022年9期
李 涛,金 炜,符冉迪,李 纲,尹曹谦
宁波大学信息科学与工程学院,浙江 宁波 315211
1 引言
海雾是受海洋影响发生在海上或沿海地区低层大气中的凝结现象,通常会使大气水平能见度小于1 km[1]。海雾不仅对海上交通运输、渔业捕捞等活动产生很大安全隐患,而且对沿海地区的交通、农业、电力、空气质量也具有一定影响,严重威胁人民的生命财产安全。因此,监测或跟踪海雾的生消变化,能为有关部门实施科学调控和管理应对提供依据,对海上防灾减灾具有重要现实意义。
由于海上只有少数的观测站点,缺乏实地观测资料,且天气和环境生态系统变化迅速,因此海雾无法像陆地雾一样使用常规监测方式进行大范围、长时间的连续监测。卫星遥感具有快速、覆盖范围广、可连续观测等优势,已成为海雾监测中不可或缺的重要技术手段。利用遥感数据对海雾的监测始于上世纪70年代,经过多年的研究,已趋于成熟。研究人员通过分析不同类型云雾在卫星多通道光谱信息上的差异,建立阈值或者机器学习模型用于大雾的监测。Shin等[2]在海洋和气象卫星(communication,ocean and meteorological satellite,COMS)数据的基础上引入海表亮温数据,并根据海雾红外通道亮温差与海表云顶亮温差的特性建立无监督算法来学习优化数据的显著特征,自动设置最佳阈值,完成了对夜间海雾的检测。Kim 等[3]基于地球静止海洋彩色成像仪和葵花8 号(Himawari-8)双卫星观测数据,通过分析海雾的光学和空间特性,建立了决策树算法实现了海雾的动态监测。郝姝馨等[4]基于新一代静止气象卫星Himawari-8 高时空分辨率多通道数据,对2018-2019 年黄、渤海海雾事件的多通道红外亮温辐射特性进行了分析,通过设置海雾、晴空水体和一般云系分离指数,建立多指数概率分布算法,完成了对夜间海雾的监测。
近年来,深度学习快速发展,在医学分割、云检测与云图生成等领域取得不错的成绩[5-9]。目前,已有研究人员成功地将深度学习技术迁移到海雾监测任务上。Jeon 等[10]基于GOCI 的红外亮温和可见光反射率数据,对卫星云图进行分析标注,建立了雾分类数据集,并在此基础上,采用迁移学习的方法,将在自然图像数据集上预训练过的卷积神经网络迁移到海雾数据集上,开展了不同波段组合对海雾识别精度影响的研究。Xu 等[11]借助无监督域自适应的方法,将丰富的标注陆地雾样本和未标注海雾样本有效结合进行海雾检测,提高了海雾识别准确率。文献[12-14]将基于深度学习的分割技术推广到海雾识别,使用融合空间信息的图像级别检测代替传统单像元检测,解决了传统海雾检测缺乏空间语义信息的问题,实现了雾区的精细化反演。虽然深度学习方法能够表征数据语义信息,具有特征学习能力强、预测精度高等优点,但其通常以“端到端”模式进行训练和推理,具有“黑盒子”特性,即难以解释其推理过程。另外,深度学习模型通常需要大量有标签的样本进行训练,而上述基于深度学习的海雾监测研究大多针对于日间场景。通过结合云图分析专家对可见光与红外波段数据分析后的建议,对海雾样本进行手工标注。由于夜间缺乏可见光波段数据,因此难以快速准确地对样本进行标注,这也导致深度学习方法在夜间海雾识别中应用难度更大。
针对上述问题,本文首先借助能够穿透云层,获取大气剖面信息的星载激光雷达对样本进行标注。相比手工标注,该方法更加便捷准确,能够获取海量的云、雾及下垫面标注数据,可以满足深度学习对训练数据量的要求。然后基于葵花8 号气象卫星多通道数据提取标注样本的亮温、纹理特征,建立夜间海雾监测数据集。最后根据海雾监测的需求,抽象出对应的推理决策树,并将其嵌入到卷积神经网络中,建立深度神经决策树模型,在高精度识别海雾的同时具备较强的可解释性,实现对夜间海雾的有效监测。
2 数据与方法
2.1 葵花8 号卫星
本文基于葵花8 号静止卫星数据进行研究。葵花8 号静止气象卫星是日本气象厅运营的第三代地球静止气象卫星,2014 年10 月7 日发射上空,2015年7 月投入使用,现位于赤道上方东经140.7°。其搭载的高级葵花成像仪(advanced Himawari imager,AHI),覆盖了可见光与红外共16 个波段,空间分辨力为0.5 km~2 km,时间分辨力为6 次/小时。相比于上代静止气象卫星,葵花8 号静止气象卫星在波段数量、空间与时间分辨力上均得到了大幅度提升。因此,本文使用葵花8 号气象卫星数据进行海雾的监测与识别研究。
2.2 结合星载激光雷达的样本标签提取
云-气溶胶激光雷达和红外探测者卫星(Cloud-Aerosol LiDAR and Infrared Pathfinder Satellite Observations,CALIPSO)由美国国家航天局与法国国家航天中心合作研制,于2006 年4 月28 日成功发射,在太阳同步轨道上运行,距地高度705 km,倾角98.2°。其携带的探测器星载激光雷达(cloud-aerosol LiDAR with orthogonal polarization,CALIOP)是第一个可以测量全球大气状态的星载偏振激光雷达,能够持续不断发射和接收激光脉冲,穿透云层及气溶胶,获取大气垂直剖面结构信息。
目前CALIOP 的公开数据分为一级(Level 1)、二级(Level 2)和三级(Level 3)产品(下载地址:https://subset.larc.nasa.gov/calipso/login.php)。其中二级垂直特征掩模产品(vertical feature mask,VFM)提供了背向散射的连续大气区域的类别信息,如云、气溶胶、晴空等。VFM 产品虽没有雾这一类别,但是雾实际上就是贴地的云,当产品中识别为水云且云贴地时即认为是雾。除此之外,由于海雾的云底高度非常低,接近于海平面,在CALIOP 数据反演无法计算海雾的底层高度信息时,就把海雾归为同样无法计算底层高度信息的海水一类中,即出现海表误判[15]。吴东等[16]统计了大气低层云雾和气溶胶的衰减后向散射系数,给出了海表误判区剔除气溶胶的阈值。综上,本文获取海雾标签的方法为:在VFM 产品数据中,当分类结果为云,且云底距海表不超过一个测量单元时,认为是海雾;当分类结果是海表,并且超出水平高度两个及以上的测量单元也判为海雾;此外,为了消除气溶胶的影响,在上述判断的基础上,需要同时满足1064 nm 衰减后向散射系数且532 nm 总衰减后向散射系数本文利用CALIOP 数据,将样本标记为中高云、低云、海雾与晴空海表四类。
2.3 基于Himawari-8 的样本特征构建
提取丰富的特征是准确识别海雾的基础。受太阳光照的影响,Himawari-8 卫星在夜间场景下可见光波段与近红外波段数据缺失,只有红外波段数据可用。因此,本文基于Himawari-8 红外波段通道进行了特征提取。为了增强对空间信息的挖掘,本文选取以样本中心大小3×3 的局部窗口作为样本的亮温特征。由于低云和海雾的组成相似,海雾抬升成为低云,低云下沉变为海雾,因此两者在物理和光学性质上都表现出一致性。虽然难以从物理和光学性质上辨别,但可以利用纹理特征对其进行区分。通常海雾是在稳定大气条件下由暖湿空气平流到冷的表面上形成的,其纹理一般比较均匀,在图像上表现为顶部光滑且边缘整齐清晰,易受地表的影响,雾区像素的亮温值波动更加稳定[1]。因此,纹理特征能加大海雾与低云的可区分性,提高模型识别海雾的精度。
本文首先提取了局部二值模式(local binary patterns,LBP)特征。LBP 通过比较中心像素与3×3邻域像素的灰度值进行阈值运算,并按照指定的编码规则生成编码,最终的编码值能够体现中心像素和3×3 邻域像素灰度值的大小关系。由于LBP 仅采样局部3×3 邻域,不能体现更大范围的纹理分布情况,为提取更大邻域的纹理特征,本文选取以样本为中心的7× 7 大小矩阵计算了灰度共生矩阵(gray-level cooccurrence matrix,GLCM),灰度游程矩阵(gray-level run length matrix,GLRLM)与灰度区域大小矩阵(graylevel size zone matrix,GLSZM)三种纹理特征并以此作为样本的纹理特征。其中GLCM 保存了邻域内所有灰度组合在定义的距离和方向条件下“共生”的频数。GLRLM 保存了邻域内具有相同灰度值的连续像素的长度和个数信息。GLSZM 保存了邻域内具有相同灰度强度的连通域大小和个数信息。
最终,本文基于Himawari-8 红外波段通道提取了亮温特征与纹理特征共128 维的向量作为构造的样本特征,以进行夜间海雾识别研究。
2.4 基于深度神经决策树的海雾识别
2.4.1 网络整体结构设计
传统海雾监测算法通常借助云雾对于卫星不同通道的反照率或者亮温分布差异,建立单通道或者多通道模型来逐步分离晴空海表、中高云、低云,最终达到识别海雾的目的。虽然此方法简单高效、可解释强,但其海雾识别精度通常较低,且易受季节、区域等因素影响。卷积神经网络作为深度学习的主要方法,具有特征学习能力强、预测精度高等优点,被广泛应用于云图相关领域。虽然目前已有不少研究将卷积神经网络迁移到海雾监测任务上,但都局限于日间海雾监测。相较于日间监测场景,夜间缺乏可见光波段数据,海雾识别的精度较低,有必要借助卷积神经网络来提升夜间海雾识别的精度。尽管卷积神经网络能够提高海雾识别的精度,但其通常以“端到端”模式进行训练和推理,具有“黑盒子”特性,即难以对其推理过程进行解释。
为使得模型高精度识别海雾的同时具备合理的解释性,本文通过分析传统海雾识别方法,抽象出了符合海雾监测需求的决策树,并将此决策树嵌入卷积神经网络中,建立对应的深度神经决策树模型,对海雾进行识别研究。本文方法如图1 所示。
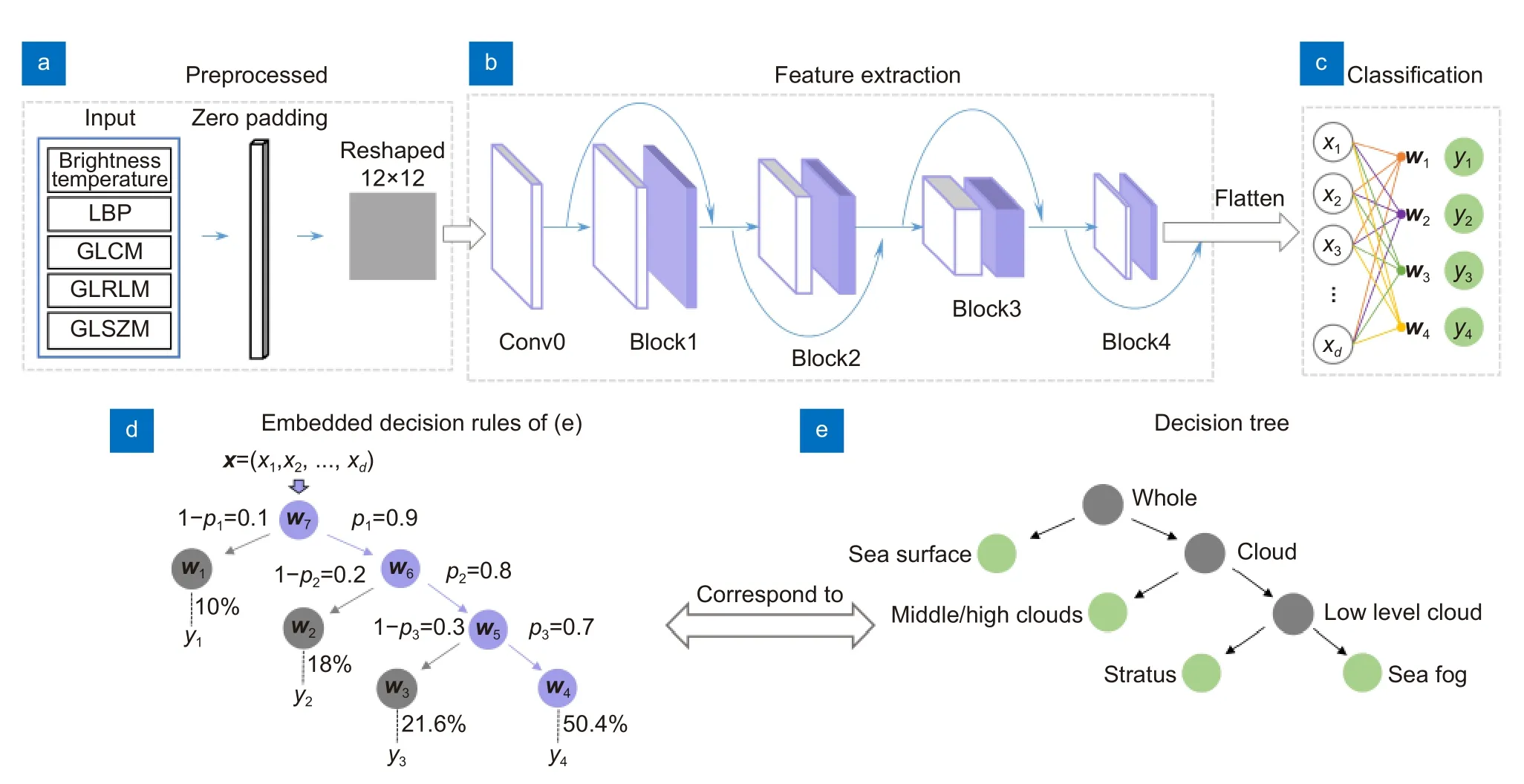
图1 算法流程图Fig.1 Overall algorithm flow chart
首先对云图中提取的128 维的特征进行预处理,如图1(a)所示。使用零填充的方式将其填充为144 维的特征向量,并对填充后的特征向量进行变换,转换成大小为12×12 的特征矩阵,以满足卷积网络的输入需求。之后将此特征矩阵输入卷积网络,如图1(b)所示。特征矩阵输入卷积网络后首先经过conv0进行处理,conv0 包含了一层卷积与批次归一化(BatchNorm)[18]操作。随后输入4 组级联的卷积块block 进行特征变换与学习。每个卷积块block 都包含两组卷积、批次归一化以及ReLU 函数激活操作。卷积块之间使用跳跃连接的方式进行连接,以输入的残差为学习的目标,有助于梯度的反向传播,加速网络的学习。
卷积网络最终输出特征图被展平为d维的特征向量x=(x1,x2,...,xd)。此时传统的深度网络通常直接使用全连接层将特征向量x映射到输出类别空间中,如图1(c)所示。虽然这种方式简单直接,但丧失了可解释性,使得我们无法了解模型的推理过程。为使深度网络在高精度的同时具备更加清晰的决策过程,符合海雾监测的常规流程,本文根据海雾识别的需求建立了二叉决策树,并将其转换为对应的推理规则嵌入到深度网络中进行训练,使得网络能够按照预先建立的规则进行推理。
2.4.2 海雾识别决策树
本文建立的海雾识别二叉决策树如图1(e)所示。由图可知,此决策树符合常规的海雾监测思想,图中绿色标注的节点为决策树叶子节点,对应数据集中具体类别,分别为晴空海表(sea surface)、中高云(middle/high clouds)、低云(stratus)和海雾(sea fog)四类。灰色标注的节点是非叶子节点,为虚拟节点,即数据集中并不存在对应的具体类别,分别为整体(whole)、云(cloud)和低层云(low level cloud)。决策树中父节点所对应的类别与子节点所对应的类别在逻辑上为父子关系。如海雾和低云的父节点为低层云,则表示低层云包含海雾和低云。通过此决策树对输入样本进行逐级判断后,输入样本将归属到某叶子节点,即晴空海表、中高云、低云和海雾中的一类。综上,所建立的决策树能够从逻辑上完成海雾识别任务,输入样本从决策树根节点转移至叶子节点即完成分类。
2.4.3 深度推理规则
为使得网络能够按照决策树指定的规则进行训练与推理,需在卷积网络与决策树之间建立联系。本文基于卷积网络的全连接层权重与目标决策树建立了可嵌入学习的推理规则来显式约束网络。推理规则是与目标决策树相对应的树形结构,不同之处在于推理规则的节点与卷积网络的参数相关联,如图1(d)所示。设y1,y2,...,y4分别表示晴空海表、中高云、低云和海雾四类。推理规则的叶子节点分别为w1,w2,...,w4,对应图1(c)全连接层y1,y2,...,y4的参数,为d维的权重向量。推理规则的非叶子节点在全连接层中无对应参数,使用以非叶子节点为根节子树的所有叶子节点的均值进行填充[19],即w5=(w3+w4)/2,w6=(w2+w3+w4)/3,w7=(w1+w2+w3+w4)/4。推理规则可代替决策树进行推理,其叶节点与决策树的节点一一对应,表示不同类别,并且节点权重与卷积网络相关联,能够对网络起到约束。从推理规则根节点转移到叶节点即可完成推理,计算方式如下:
设输入样本经卷积网络处理后的特征为x=(x1,x2,...,xd),非叶节点i的子结点集合C(i)={C(i)1,C(i)2,...,C(i)n},则输入样本从父节点i转移到子节点C(i)j,j=1,2,...,n的概率为
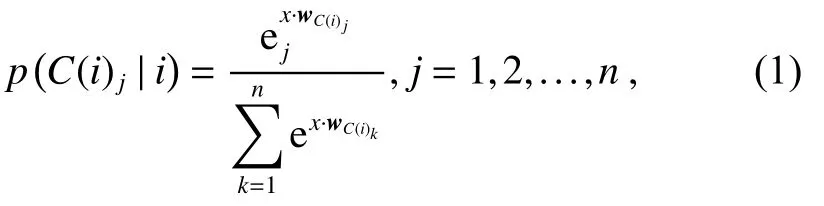
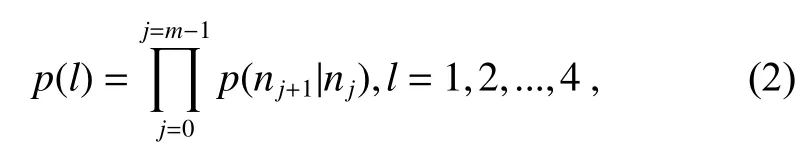
其中:p(nj+1|nj)表示从父节点nj转移至子节点nj+1的概率,m为根节点到叶节点的路径长度,p(l)表示样本从根节点转移到叶节点l的概率,即样本归属叶节点l对应类别的概率。从根节点转移至所有叶节点的概率计算完成后,选择概率最大的作为网络最终预测的类别:
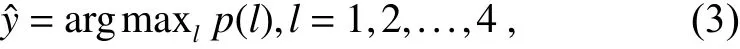
其中:yˆ 表示网络最终预测的类别,p(l)为从推理规则根节点转移至叶节点l的概率,即样本属于类别l的概率。如图1(d)展示了输入的样本为海雾时推理规则推理的过程,图中标注为紫色的部分即为输入样本的转移路径,节点旁数字表示从对应的父节点转移至子节点的概率。由图可知,最终y4对应的叶节点的概率为p1×p2×p3=50.4%,大于其它叶节点概率,因此海雾为网络预测的类别。
2.4.4 损失函数
为显式约束卷积网络遵从决策规则的方式进行推理,使用决策树损失对网络进行约束。另外,卷积网络原始分类损失表征模型预测类别与样本真实类别之间的误差大小,能够引导模型参数进行优化,因此在决策树损失的基础上引入分类损失对网络训练过程进行监督[19]。综上,网络损失函数如下所示:
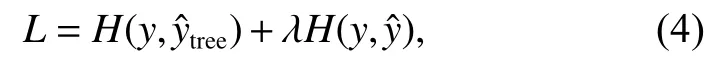
其中:y为真实标签,为推理规则预测的类别概率,yˆ 为原始网络的预测类别概率,λ为超参数,用于控制模型原始分类损失与决策树损失的比重。H(·,·)为交叉熵损失,如式(5)所示:
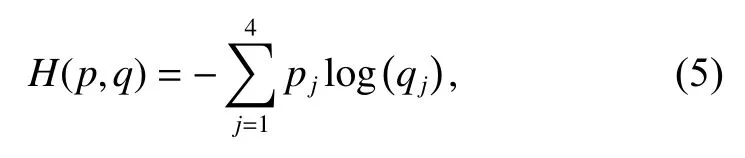
其中:p是样本标签,q为模型的预测结果。
3 实验结果与分析
3.1 实验环境及网络参数设置
本文实验环境为64 位版本的Ubuntu16.04 操作系统,CPU 为Intel Core i7-11700k,显存为12 G 的NVIDIA GTX 3080Ti 显卡。使用的编程语言为Python,采用了Pytorch,Sklearn 等框架。在模型的训练过程中,使用随机值初始化权重,将批量大小设置为256,学习率设置为0.001,损失权重 λ设置为1[19],并使用Adam 作为优化器进行训练。为了测试本文模型在海雾识别中的有效性,将数据集按照8:2的比例随机划分为训练集和测试集,使用训练集对模型进行训练并验证模型在测试集的性能,其中训练集包含16693 个样本,测试集包含4173 个样本。
为了定量评价本文方法是否能正确识别海雾区域,本文使用了命中率(probability of detection,POD,用Pd表示),误判率(false alarm ratio,FAR,用Fr表示)和临界成功指数(critical success index,CSI,用Cs表示)三种指标对模型进行了评价,如下所示。
1) 命中率,模型正确识别正样本数量与真实正样本数量的比值,其值越大则模型错误地将正样本识别为负样本的比例越小,即漏检数量越少。

2) 误判率,模型错误识别的正样本数量占所有识别为正样本的比例,其值越小,模型错误地将负样本识别为正样本的比例越小,即误检数量越少。
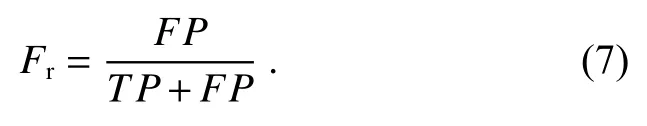
3) 临界成功指数,综合了命中率和误判率的结果,其值越高说明模型的综合性能越好。
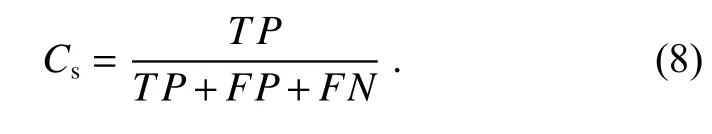
上述公式中,真阳性(true positive,TP)表示模型正确检测到的正样本数量,假阳性(false positive,FP)表示模型错误检测到的正样本数量,假阴性(false negative,FN)表示模型错误检测到负样本数量。
3.2 网络结构分析
为了确定卷积网络的深度,对网络中block 的组数进行实验。本文以3 组block 模块为初始,依次增加,实验结果如表1 所示。
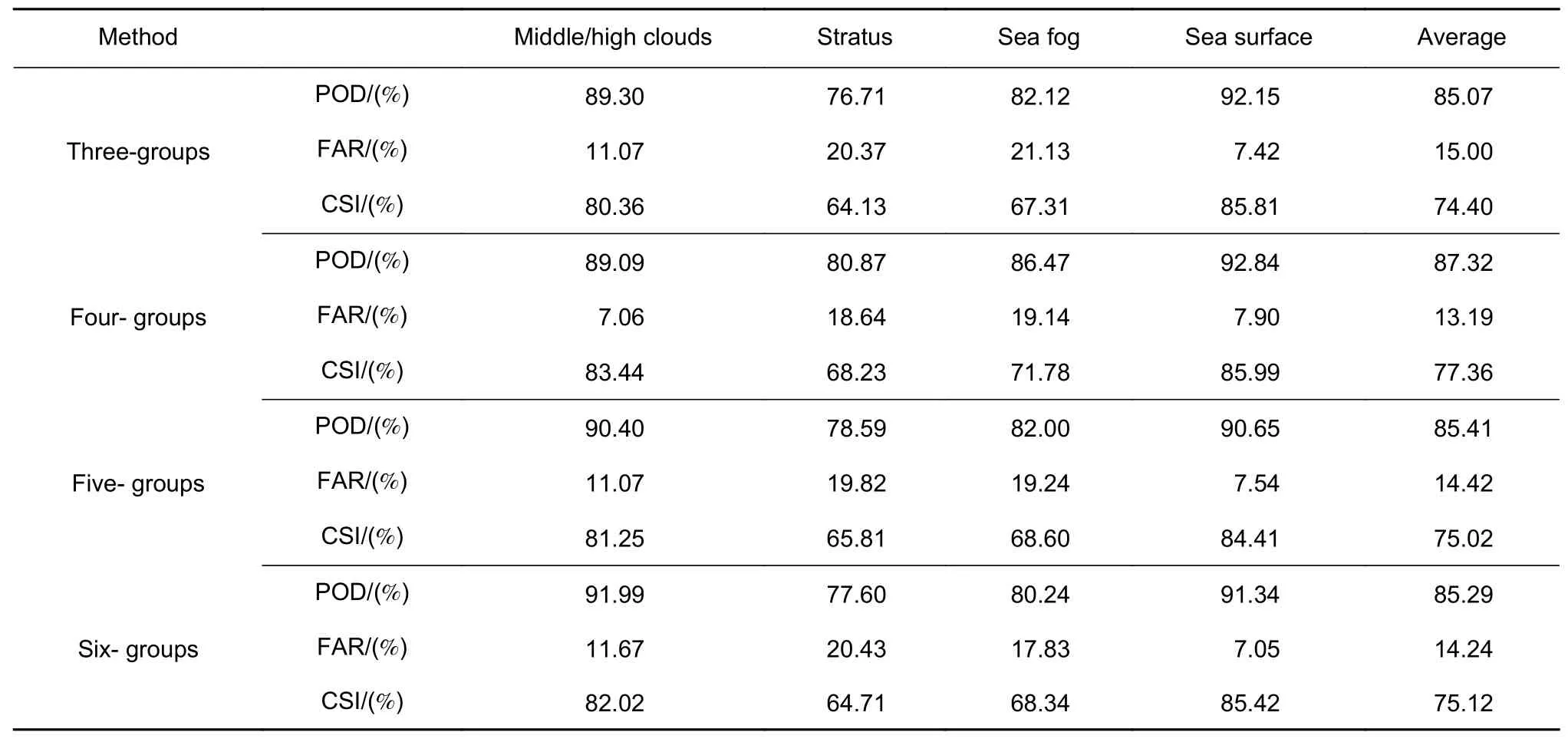
表1 不同网络层数实验结果Table 1 Experimental results of different network layers
由表可知,6 组block 网络的中高云命中率最高,为91.99%,但其误判率较高为11.67%,对于其它类别,4 组block 网络命中率相对较高。从平均评价指标来看,4 组block 网络最高,平均临界成功指数为77.36%。综合考虑识别精度与效率,选择4 组block网络为训练模型。
为了探讨不同形式卷积网络对模型识别海雾的影响,分别使用二维卷积网络(CNN_2D)与一维卷积网络(CNN_1D)构建深度决策树进行对比。一维卷积网络除了将二维卷积替换为一维卷积外,其余结构与二维卷积网络相同。不同卷积网络识别结果如表2所示。
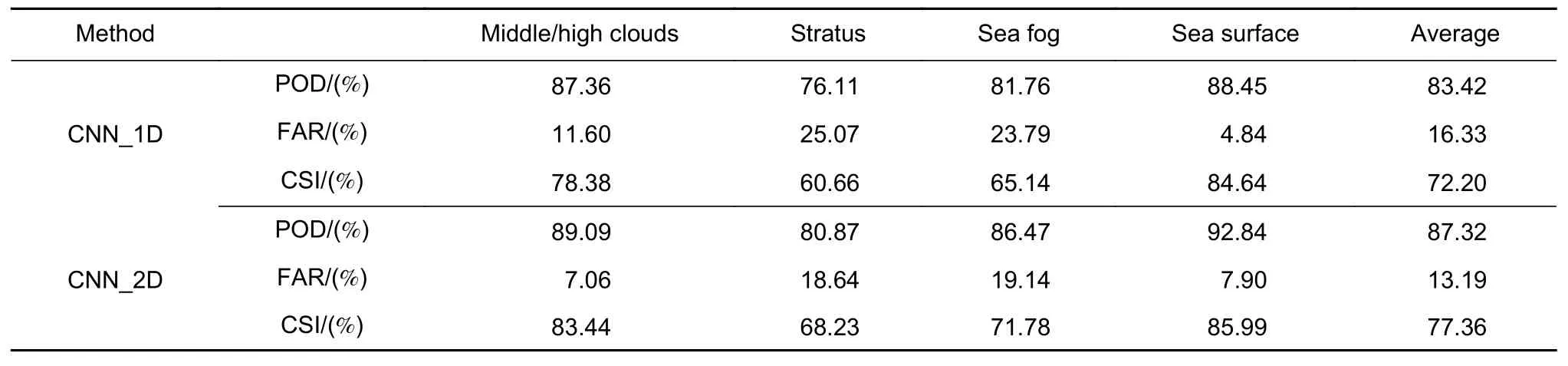
表2 不同卷积网络结果对比Table 2 Comparison of results of different convolution networks
由表可知,一维卷积网络的平均命中率为83.42%,平均误判率为16.33%,平均临界成功指数为72.20%,二维卷积网络的平均命中率为87.32%,平均误判率为13.19%,平均临界成功指数为77.36%。二维卷积网络在识别精度上相比于一维卷积网络有较大的提升。这表明二维卷积网络能够学习更有效的特征组合模式,增强了不同类别样本的特征区分度,因此提高了对应模型的识别精度。
3.3 模型有效性分析
为了验证纹理特征以及决策树监督损失对模型识别海雾的影响,分别对深度决策树的纹理特征与决策树损失进行消融实验,结果如表3 所示。

表3 消融结果对比Table 3 Comparison of ablation results
表中,ATF 表示消融纹理特征后的模型(ablationtexture features,ATF),ATL 表示消融决策树损失后的模型(ablation tree loss,ATL),WOA 表示未进行消融的模型(without ablation,WOA)。由表可知,消融纹理特征后模型的平均命中率为81.24%,平均误判率为19.03%,平均临界成功指数为68.65%,引入纹理特征后模型的性能得到了提升,平均命中率为87.32%,平均误判率为13.19%,平均临界成功指数为77.36%。上述现象表明纹理特征能够有效区分不同类别的样本,提升模型的识别精度。对比表中ATL 与WOA 两种方法可知,引入决策树损失后模型的精度得到了一定的提升,平均命中率提升1.98%,平均误判率下降1.47%,平均临界成功指数提升2.58%,不同类别的识别精度也得到了提升。这不仅表明引入决策树损失能够有效地监督模型,也间接说明本文所建立的决策树具有区分不同类别样本的能力。
为了客观地评价本文方法在海雾监测中的应用潜力,使用测试集对该模型进行了测试,并展示了测试结果的混淆矩阵,如表4 所示。

表4 模型分类混淆矩阵Table 4 Confusion matrix of model
由表可知,本文模型对于中高云和晴空海表具有较强的区分能力,这与云图影像中所展示的迹象相一致。中高云和晴空海表的图像特征通常比低层云雾更明显。由于海雾和低云在组成成分、光学特征和物理性质十分接近,海雾上升演变为低云,低云下降成为海雾,因此识别低层云雾相比其它类别更加困难。本文模型在区分低云和海雾的能力上有一定的改进空间。对于这种差异,下一步可以考虑结合不同区域、时间段样本以及多卫星观测资料,充分挖掘海雾的空间特征,来提高模型的鉴别能力。
为了验证本文方法对海雾识别的决策过程具备可解释性,对2020 年6 月2 日出现在黄渤海区域的海雾进行了识别,并可视化了模型识别海雾的推理过程,如图2 所示。
其中图2(a) 为模型识别结果,识别出的海雾标记为绿色,图2(b) 为模型对经纬度为120.4°E,38.4°N的样本点A 的推理过程,节点旁边文字代表节点的类别,数字代表样本点A 归属本节点类别的概率。图中标记为紫色路径的节点为模型对样本A 的推理路径,即A 以91%的概率归属云(cloud),然后以98%的概率归属低层云(low level cloud),最后以99%的概率归属海雾(sea fog)类别。样本A 最终归属海雾类别的概率为推理路径上所有概率的乘积,即91%×98%×99%=88%。模型预测A 为海雾节点的概率大于其它三个叶子节点的概率,因此样本A 最终的类别为海雾。上述现象表明深度决策树模型对海雾进行识别时能够按照预先建立的决策规则对样本进行逐层判断,符合常规的海雾识别监测流程,具有较好的可解释性。

图2 模型推理示例Fig.2 An example of the model inference process
3.4 不同算法海雾识别结果对比分析
为了验证算法的有效性,本文进行了对比实验。对比模型包括支持向量机(support vector machine,SVM)、决策树(decision tree,DT)与卷积神经网络ResNet[20]。将上述模型的识别结果与本文模型进行比较,分析不同模型在海雾识别中的有效性。不同模型使用POD、FAR 和CSI 进行评估,结果如表5 所示。
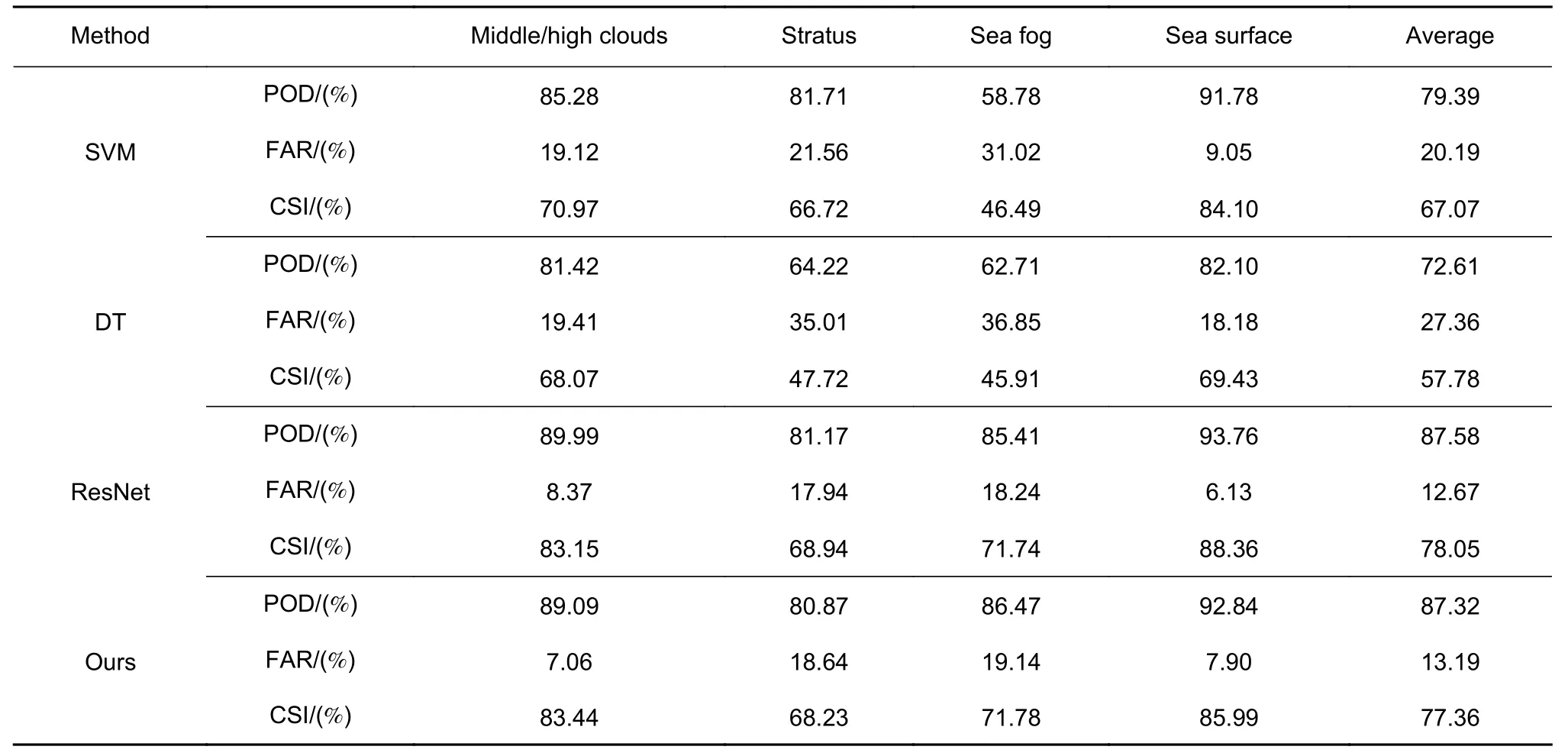
表5 不同海雾识别方法分类结果对比Table 5 Classification accuracy of different sea fog recognition methods
从单类别的角度来看,对于中高云,不同模型均具有相对较高的临界成功指数,其中决策树最低为68.07%,本文方法最高为83.44%。对于晴空海表,ResNet 的临界成功指数最高为88.36%,其次是本文方法为85.99%,决策树最低为69.43%。海雾和低云相比于中高云、晴空海表来说,模型的识别精度较低。本文方法对低云和海雾的临界成功指数分别为68.23%和71.78%,ResNet 的临界成功指数分别为68.94%、71.74%,基于传统机器学习模型的方法相对较差。从不同方法类型来看,对于机器学习方法,支持向量机相比于决策树具有更好的性能,平均命中率为79.39%,平均误判率为20.19%,平均临界成功指数为67.07%。深度学习方法相比于传统机器学习方法具有较大的提高。对于深度学习方法,本文方法对中高云和海雾的临界成功指数分别为83.44%、71.78%,识别效果优于ResNet,而对于低云和晴空海表的识别效果相对较差。ResNet 的平均命中率为87.58%,平均误判率为12.67%,平均临界成功指数为78.05%,整体的性能最优。本文方法的平均命中率为87.32%,平均误判率为13.19%,平均临界成功指数为77.36%,略低于ResNet。上述现象表明,相比其它类别,海雾与低云的识别难度较高,传统机器学习模型难以有效地对它们进行区分,本文将显式的决策规则引入卷积网络中,建立的深度决策树模型能够有效地对海雾进行识别,整体识别精度能够达到常规深度学习方法的水平,并且具有较好的可解释性。
为了更加直观地比较模型,本文选取了2020 年6 月5 日出现在黄渤海区域的海雾天气进行分析。使用不同模型对UTC 18:20 时刻的卫星云图进行海雾识别,结果如图3 所示。

图3 黄渤海区域2020 年6 月5 日UTC 18:20 时刻的海雾识别图Fig.3 Sea fog identification result at UTC 18:20 on June 5,2020 in the Yellow Sea and Bohai Sea
图中3(a)、3(b)、3(c)、3(d)分别为通过SVM 模型、决策树、ResNet 以及深度决策树进行预测的海雾识别图。图中黑色实线表示星载激光雷达在该时间段的运行轨迹线,轨迹线标记为青色的部分是通过星载激光雷达资料判定为海雾样本的像元。图中绿色部分为模型识别为海雾的区域。由图可知,相比深度学习模型,传统机器学习模型海雾识别效果较差。支持向量机与决策树模型都产生了不同程度的漏检,错误识别星载激光雷达轨迹线上标记的海雾样本。ResNet 与深度决策树基本完全识别出星载激光雷达轨迹线上的海雾样本,效果较优。上述现象说明基于深度决策树模型进行海雾识别具有较好的性能。
3.5 海雾识别个例分析
国家气象中心发布了海雾预报:2020 年6 月5日夜间到6 日白天,由于偏南暖湿气流加强,导致黄海中部和南部海域、山东南部和江苏东部沿岸海域能见度小于1 km,出现了海雾天气,影响了我国北方海域。本文利用深度决策树模型对此次海雾过程进行了分析。图4 给出了基于深度决策树对2020 年6 月5 日UTC 15:00~20:00 整点时刻的海雾监测结果。由海雾监测结果可知,在15:00 时刻海雾出现在黄海西部沿岸区域,主体呈三角状,少量散布于渤海沿岸;15:00~20:00 之间,海雾处于发展期,主体逐渐向南、东、北方向进行蔓延;到20:00 时刻,海雾主体扩张到最大,南至33°N,北至37°N,东至125°E 附近。海雾主体接壤山东半岛,跨越黄海中部,延伸至朝鲜半岛西部。监测结果清晰地展现了本次海雾动态发展、稳定的过程。
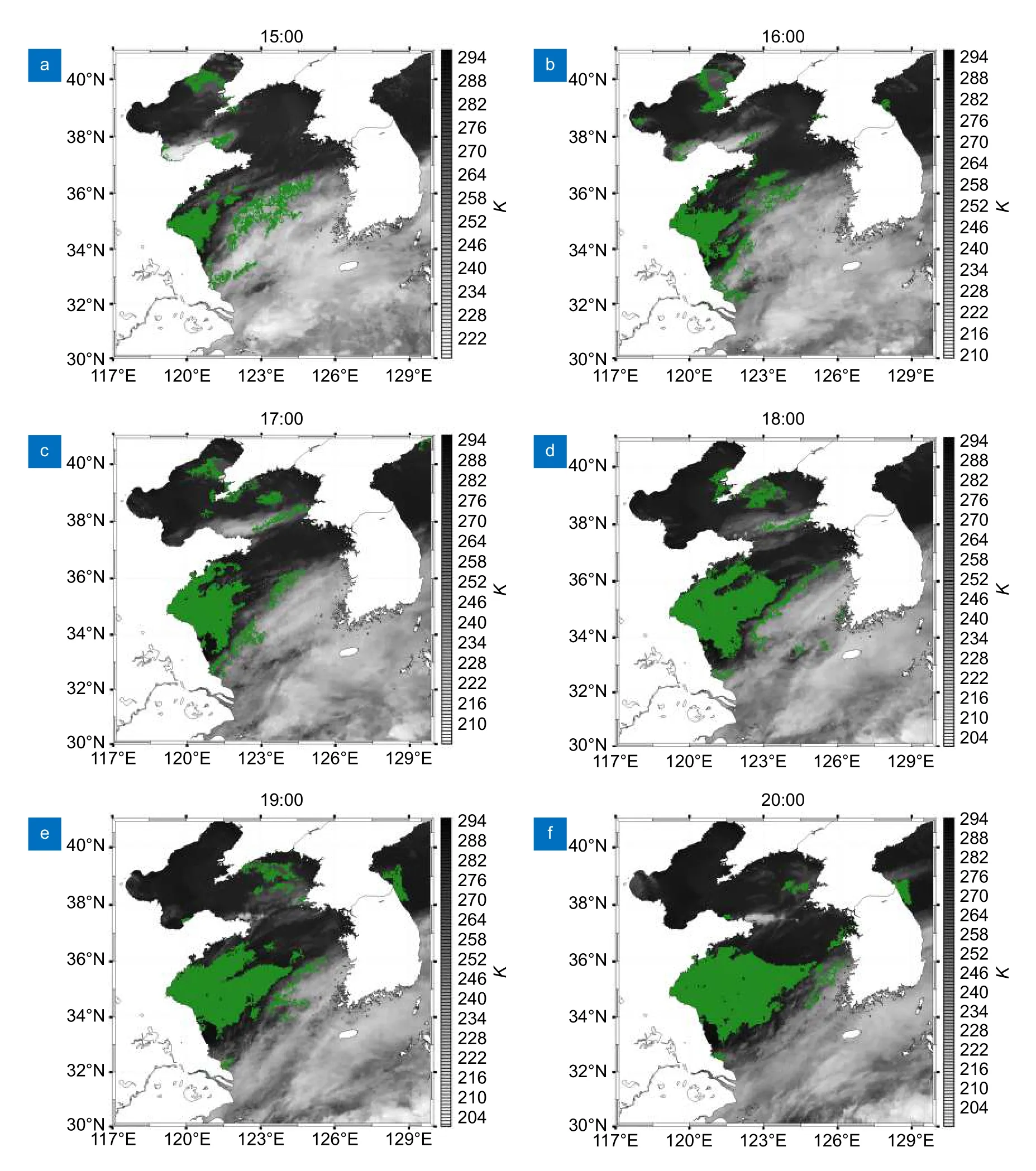
图4 黄渤海区域2020 年6 月5 日UTC 15:00~20:00 海雾监测图Fig.4 The monitoring results of sea fog in the Yellow Sea and Bohai Sea from 15:00 to 20:00 UTC on June 5,2020
4 结论
海雾因其恶劣的能见度而对海上及沿岸地区的交通运输、海洋捕捞和海洋开发工程以及军事活动等造成不良影响,因此对于海雾的实时监测和预报就显得尤为重要。目前,越来越多的研究人员开始借助深度学习方法来进行海雾的识别,但深度学习通常对标签具有较高要求,需要专业的云图分析专家对海雾进行标注,是一项艰巨而繁琐的工作,而且难以对深度学习方法进行合理解释。为了解决这些问题,本文利用Himawari-8 静止卫星与星载激光雷达对海雾进行标注,提取其亮温特征和纹理特征,并构建深度决策树模型对夜间海雾进行自动识别。通过实验对模型有效性进行了分析并与不同模型进行了对比,结果表明,该方法在较高精度识别海雾的同时具备可解释性,可作为实践中进行识别海雾的辅助工具。当然,该方法也还存在一些不足之处,区分海雾和低云的能力还有提升空间,未来可进一步研究海雾与低云的物理性质差异、结合多卫星观测数据提取更具辨别度的特征,以及借助生成对抗网络生成夜间伪可见光数据等方式,提升模型识别海雾的能力。
猜你喜欢
海洋预报(2023年6期)2024-01-05 09:24:16
科技资讯(2023年21期)2023-11-22 08:35:46
海峡科学(2022年8期)2022-10-14 02:55:42
东坡赤壁诗词(2021年1期)2021-03-24 18:25:35
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
海洋气象学报(2017年4期)2017-12-04 08:41:46
疯狂英语·新读写(2017年9期)2017-09-25 01:23:29
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
