
基于GPR 和深度强化学习的分层人机协作控制
2022-09-30 12:44金哲豪刘安东
自动化学报 2022年9期
金哲豪 刘安东 俞 立
近年来,随着机器人技术的高速发展,机器人在工业生产中替代了大量的人力资源.然而,对于一些复杂的任务,机器人往往无法和人类一样灵活的操作与控制.人机协作(Human-robot collaboration,HRC)研究如何利用人的灵活性与机器人的高效性,使机器人与人协同高效、精准地完成复杂任务,因此受到了国内外学者的广泛关注[1].
人机协作按机器人在协作过程中的角色可分为人主-机器人从、机器人主-人从、人机平等3 类.第1 类人机协作中机器人接收人发出的命令并执行,主要完成一些负重类的任务.如文献[2]中人与机器人共同搬运一个物体,其中人决定了运动轨迹,而机器人作为跟随者负责轨迹跟随并承担重物.在这一类人机协作任务中的一大难点是如何将人的想法正确的传递给机器人.文献[3-4]研究了在人与机器人共同操作一个对象时,如何消除传递给机器人旋转与平移命令之间歧义的方法.第2 类人机协作的研究相对较少,文献[5]将人建模为一个被动的旋转关节模型,并且用实验证明了在机器人主导的情况下如何使用该模型将物体维持水平.以上两类人机协作方法虽然能一定程度上结合人与机器人自身的优点,但过于注重单方面的性能,如人类的灵活性或机器人的高效性,从而导致协作的整体效率不高.
人机平等形式的人机协作考虑人与机器人以平等的关系完成复杂任务,这要求协作双方对对方的操作规律有一定的了解.由于人的智能性,对于人而言这种能力可以很方便地获得,但机器人无法自然获取这种能力,因此如何为机器人建立有关人的运动规律模型是非常重要的.其中较为常用的方法假设是人的运动规律满足最小抖动模型[6],并根据该模型预测人的运动轨迹.文献[7]在人与机器人协作抬一根长杆的场景中,使用加权最小二乘实时估计最小抖动模型中的参数,并利用变种阻抗控制器使机器人跟踪最小抖动模型的预测值,从而达到使机器人主动跟随人运动的效果.文献[8]利用扩展卡尔曼滤波估计最小抖动模型中的参数,并在一维的点到点运动中证明该方法的有效性.文献[7-8]均证明了在人机协作中使用以上基于最小抖动模型的方法能在一定程度提升人的舒适度.然而,基于最小抖动模型生成人的运动轨迹需要事先了解人运动轨迹起止时间与起止位置,这在一些任务中过于苛刻.文献[9]表明最小抖动模型在一些特别的协作任务中会失效,如一些协作任务中人的轨迹存在大量的干扰与抖动,或者人在协作过程中多次决定改变其运动轨迹.文献[10-11]假设人在运动过程中其加速度变化较小,利用卡尔曼滤波器预测人下一时刻的位置,并根据预测精度加权融合机器人主被动控制器,从而提高机器人协作时的主动性以及协作的鲁棒性.该方法在人机协作抬桌子的场景中得到了验证.文献[12]使用基于与文献[10-11]相同的运动模型的扩展卡尔曼滤波预测人下一时刻的位置,但是其使用基于强化学习的方法设计机器人的速度控制律,并且利用扩展卡尔曼滤波的预测值减小强化学习算法搜索的动作空间范围,提升了机器人的协调能力,同时加强了机器人在协作任务中的主动性.也有一些工作[13-14]将人的控制量作扰动处理.
以上方法均属于较为经典的人运动轨迹建模方法,有较强的可解释性.然而一些复杂的人机协作任务中,人的运动轨迹往往很不规律,如人手在3 维空间中到达某些不同目标位置时形成的轨迹[15]、人在完成装配任务时的运动轨迹[16]等.此时用概率分布去建模这些轨迹显然更加合适,因此一些基于学习和统计的轨迹建模方法往往更加有效.文献[15]利用高斯混合模型(Gaussian mixture model,GMM)与高斯混合回归(Gaussian mixture regression,GMR)建立人手到达不同目标位置所形成的轨迹概率分布模型,该模型被用来提升人机协作过程中的安全性以及机器人的自主性.文献[16]通过人拖动机器人完成装配任务的方式将人的运动轨迹转化为机器人末端的轨迹,并利用GMM/GMR建立机器人末端的轨迹概率分布模型以达到示教学习的目的.文献[17]利用高斯过程回归(Gaussian process regression,GPR)拟合包含人在内的球杆系统的前向传播模型,并利用基于模型的RL 算法设计次优控制律,极大地提升了对数据的利用率.文献[18]使用卷积神经网络学习人在完成零件装配任务时的动作与意图.文献[19]使用触觉数据作为输入,利用基于隐马尔科夫模型的高层控制器估计人的意图并生成相应的机器人参考轨迹,并在机器人与人握手的场景中验证了该方法的有效性.另外,部分可观马尔科夫模型[20]以及贝叶斯神经网络[21]也被用来预测人下一时刻的行为.
然而,上述方法几乎都是对人在一段时间内的运动轨迹进行建模,很少有文献直接对人的控制策略建模.与人运动轨迹建模不同,针对人体控制策略建模主要为了预测人在遇到某个状态时可能执行的动作,从而为机器人对人的控制行为建立更加直观的认知模型.本文提出了一种基于GPR 与深度强化学习(Deep reinforcement learning,DRL)的两层人机协作控制方法,不仅设计了一种次优的非线性控制律,还对人体控制策略建模,从而降低了人为不确定因素的不利影响,增强了协作系统的稳定性,并解决了传统主从式人机协作中效率较低的问题.本文以人机协作控制球杆系统为例验证该方法的可行性.首先,针对顶层期望控制律的设计问题,利用深度确定性策略梯度算法(Deep deterministic policy gradients,DDPG)[22]得到了一种次优的非线性控制器.其次,本文使用GPR 建立球杆系统的人体控制策略模型,解决了协作过程中由人为不确定因素所导致的系统不稳定问题.然后,根据期望控制律和人体控制策略模型设计机器人的控制律以提升人机协作的效率.最后,通过实验验证了该方法的可行性与有效性.
1 问题描述
本文以球杆系统为例设计分层人机协作控制方法,考虑如图1 所示的人机协作球杆系统.
图1 中,人与机械臂各执长杆一端以控制长杆倾角,使小球快速,平稳地到达并停留在目标位置(虚线小球位置).在人机协作环境下,由于长杆的倾角变化幅度较大,使得在平衡点附近线性化模型后设计相应控制器的方法效果不佳.因此,如何针对该球杆系统设计一种有效的非线性控制器是本文的一大难点.然而,常规的非线性控制方法对模型精度依赖较高,而一些复杂协作任务往往很难精确建模,甚至无法建模.因此,本文基于DRL 算法设计球杆系统的控制器.DRL 算法不依赖环境模型,其通过不断与环境交互,以寻找一种使累积奖励最大化的控制策略.由于DRL 利用神经网络设计控制器,并通过迭代的方式更新参数,易陷入局部最优.因此,基于DRL 的非线性控制器是一种次优控制器.

图1 人机协作控制球杆系统示意图Fig.1 Schematic diagram of the human-robot collaboration task
使用DRL 设计控制器需要先将球杆系统建立成马尔科夫决策模型.马尔科夫决策模型由5 元组(S,A,P,r,γ)表示.其中S表示状态空间,是对环境状况的一种数学描述;A表示动作空间,是智能体影响环境的手段;P表示状态转移概率,表示在当前状态受到某个动作后下一个状态的概率分布,也可以理解为环境模型;r表示奖励函数,是环境对当前状态施加某个动作后的一个奖惩反馈;γ表示折扣因子,是调节智能体关注长远利益程度的参数.
控制器的设计问题可以转化为解马尔科夫决策模型问题,即设计一个最优策略π*:使智能体获得的累积奖励最大化.对于任意的s∈S,π*(s)满足:
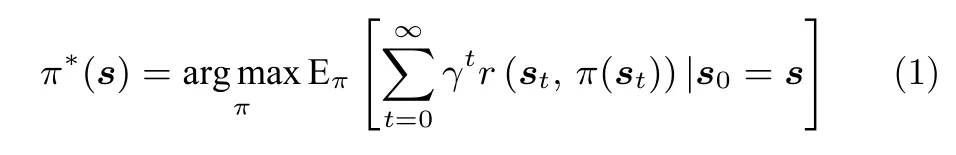
式中,π*可以通过强化学习算法设计.由于球杆系统状态空间连续的特性,使得处理离散状态空间马尔科夫决策模型的传统强化学习算法无法为其设计最优策略.因此,对于这类状态空间连续的马尔科夫决策模型常常使用基于估计的强化学习算法(如DRL).为了取得更好的控制效果,本文考虑连续的动作空间,这使处理离散动作空间的基于值函数的DRL 方法[23-24]失效.本文使用的DDPG 算法利用Actor-Critic 结构,能在连续的动作空间中寻找一种次优控制策略.
另外,在主从式协作中,从方往往不做决策,只承担跟随或执行主导方发出的命令的任务.因此,该模式的协作效率往往较低,即系统进入稳态所需的控制时间较长.本文考虑人机平等的协作方式,即人与机器人均为完成任务作出控制决策,而人的高随机性行为将为机器人控制器设计带来极大的不确定性.因此,如何为机器人建立人体控制策略预测模型,增强机器人在协作过程中的主动性,从而提高协作效率与协作鲁棒性是本文的第2 个难点.考虑到人体控制策略的随机性(即使同一个人面对相同状态,其采取的控制行为也可能不同,本文假设该行为服从高斯分布),本文利用GPR 拟合人体控制策略.与传统回归算法不同的是,对于一个特定的输入,GPR 模型的输出并不是一个固定的值,而是一个高斯分布,即(s)~N(a,δ).并且,GPR是一种非参数估计方法,因此不会有过拟合的风险.
由于协作过程中只有机械臂的行为是可控的,本文的目标是为机械臂设计合适的末端速度控制律以使小球在人机协同控制下快速,平稳地到达并停留在指定位置.本文以基于DRL 的次优非线性控制策略为期望控制策略,以拟合的人体控制策略预测模型作为机器人对人控制行为的认知模型,设计机器人的控制律,从而使人机协作的整体控制效果趋向于期望控制策略的控制效果.
2 人机协作控制
本节将设计基于GPR 与DRL 的分层人机协作控制方法,具体分为顶层与底层的设计.其结构如图2 所示:
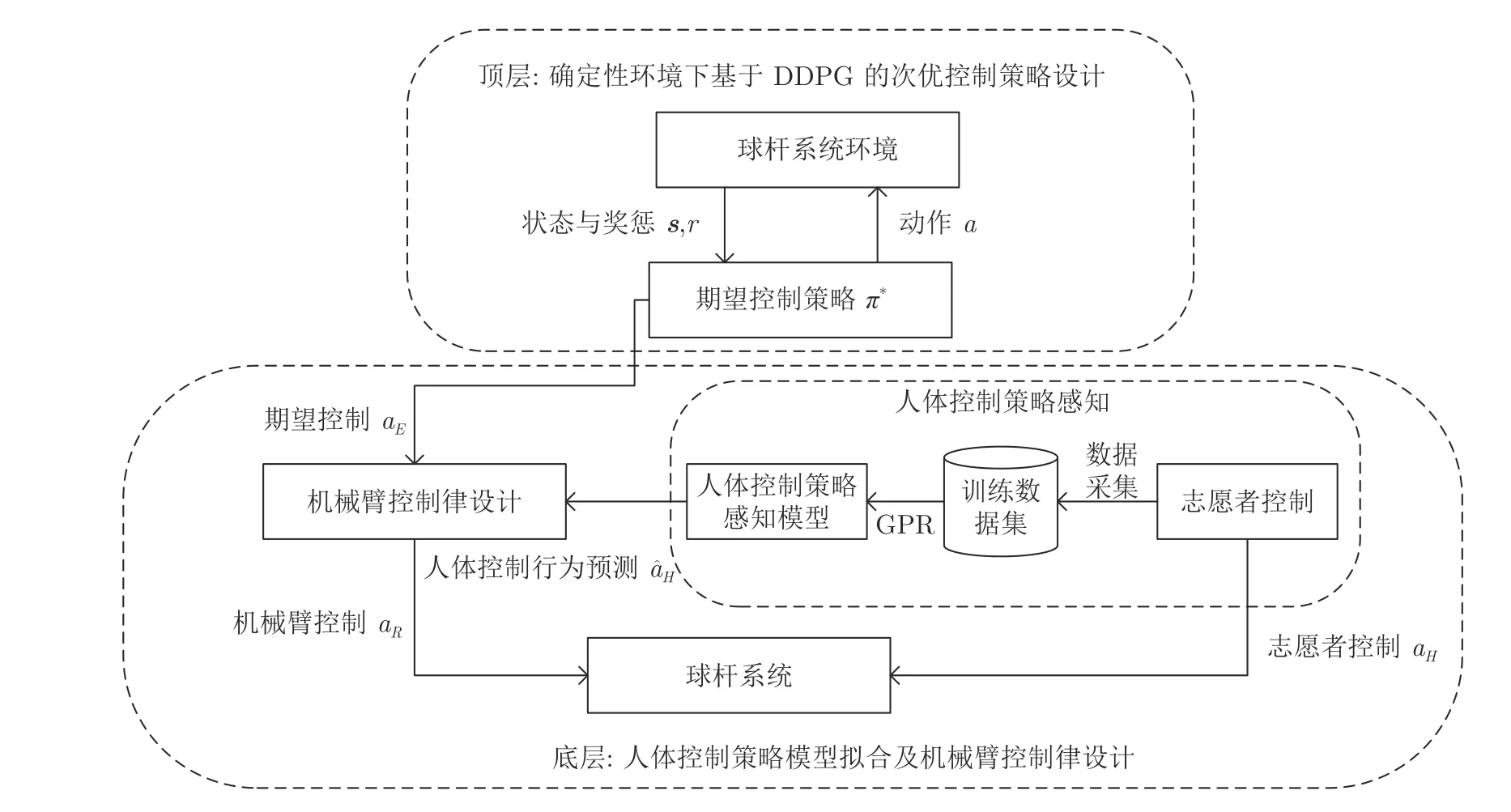
图2 分层人机协作球杆结构示意图Fig.2 Schematic diagram of hierarchical human-robot collaboration
顶层利用DDPG 算法为非线性球杆系统设计一种次优的高效控制律,并作为人机协作过程中的期望控制策略.底层主要分为两部分: 1)基于GPR拟合人体控制策略,为机械臂建立人控制行为的认知模型;2)根据期望控制策略以及认知模型设计机械臂的末端速度控制律,从而使人机协作下的控制行为趋向于期望控制策略的控制行为.
2.1 顶层设计
本节主要介绍如何利用DDPG 设计球杆系统的期望控制策略.在此之前,必须先将球杆系统建立成马尔科夫决策模型,主要包括状态空间、动作空间和奖励函数的设计.
1)状态空间: 球杆系统的控制目的是使小球快速,稳定地到达指定位置,因此位置误差信号e被用来构建状态.另外,据经验可知,人在控制球杆的时候还会关注小球的速度以及长杆的倾角θ.同时,为了不使小球离开长杆,小球的位置x也被用来构建状态.因此,马尔科夫决策模型状态被定义为s=[e x]T.
2)动作空间: 本文以长杆的旋转角速度作为控制量,因此,动作被定义为a=.
3)奖励函数: 为了使小球快速,稳定地到达指定位置,本文设计的损失函数为,其中Wc为权重矩阵,令奖励函数r=-c.另外,小球离开长杆被认为是控制失败,因此,一但检测到小球离开长杆,环境将给予一个幅值较大的损失函数并重新开始实验.
DDPG 算法可以用来为状态以及动作空间连续的马尔科夫决策模型寻找次优策略,主要包含Actor、Actor 目标网络、Critic、Critic目标网络4个神经网络.记这4 个神经网络的参数分别为Critic神经网络用来估计动作值函数Q(s,a),即对于马尔科夫决策模型在状态s执行动作a的价值,并利用Bellman 方程来构建其损失函数:
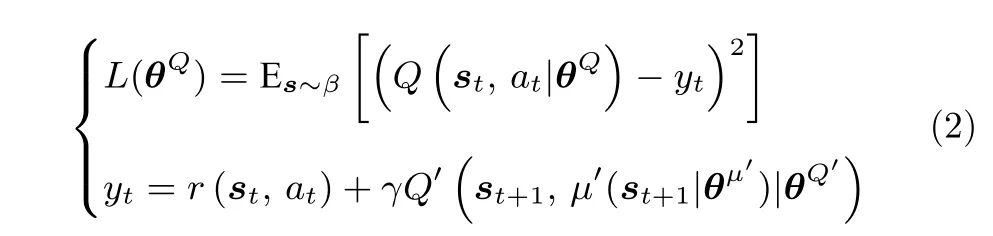
式中,β是一种随机策略,用来探索未知环境.Actor 神经网络以s作为输入,以a作为输出,负责学习控制策略,其参数更新规则较为复杂.根据文献[25]给出的确定性策略梯度理论,Actor 网络在策略µ下,目标函数对θµ的梯度为:

设立目标网络是为了促进神经网络收敛,目标网络与原网络之间采用软更新原则:
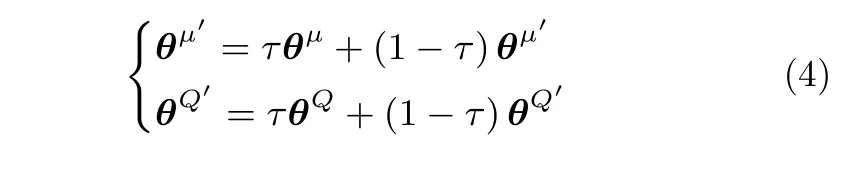
另外,受到深度Q 网络(Deep Q network,DQN)的启发,DDPG 还设立的回放缓冲区M储存过去的数据,并从中随机抽样训练Actor 与Critic 神经网络.使用DDPG 设计球杆系统期望控制策略的算法如下所示:

2.2 底层设计
本节介绍如何利用GPR 拟合人体控制策略以及如何根据期望控制策略和人体控制策略模型设计机械臂的控制律.
2.2.1 人体控制策略感知

2.2.2 机械臂控制
本节在期望控制策略与人体控制策略预测模型的基础上,设计机械臂末端速度的控制律.
机械臂的控制目标是使长杆在机器人末端速度vR与人控制端速度vH的作用下,其旋转角速度趋向于期望值其中可由顶层Actor 网络前向传播得到,vH的估计值可由人体控制策略预测模型预测得到,本文使用高

3 仿真与实验
本节通过仿真与实验验证了所设计的人机协作控制方法的有效性,共分为3 个部分: 1)介绍DDPG 中各神经网络的架构及超参数的设计,并在仿真环境中训练各神经网络以得到顶层期望控制策略.同时,通过与基于值函数的DRL 算法对比,证明了在实际控制任务中使用基于策略的DRL 算法(如本文使用的DDPG 算法)来设计顶层期望控制策略的必要性.2)通过相机采集人控制球杆系统的实验数据以构建训练集,介绍并分析了利用GPR 拟合人体控制策略预测模型的结果.基于得到的期望控制策略与人体控制策略预测模型.3)在实际场景中通过人机协作控制球杆系统与人单独控制球杆系统的控制效果作对比,证明了所提控制方法确实能提升效率与控制精度.
3.1 基于DDPG 的期望控制策略设计
本节分析DDPG 学习期望控制策略的过程与结果.首先介绍DDPG 中神经网络的架构与超参设置.DDPG 共包含4 个神经网络,由于球杆系统的复杂程度相对较低,本文将Actor 与Actor 目标网络设置成3 层全连接网络,隐藏层单元个数为30;将Critic 与Critic 目标网络设置为4 层全连接网络,隐藏层单元个数分别为30 和40.Actor与Critic 网络的学习率均为0.001.回放缓冲区大小为10 000对 [sk ak rk sk+1],每次训练采样64 对数据.目标网络软更新参数为τ=0.01.损失函数中的权重矩阵Wc取对角阵,对角元分别为{5,0.1,0.001}.神经网络优化器使用Adam 优化器.
仿真环境中忽略球杆系统摩擦力,具体模型参考文献[26],控制周期设置为0.033 s (与第3.2 节中通过相机采样志愿者控制数据的采样周期保持一致),每次试验最长为200 步.DDPG 的训练过程如图3 所示.
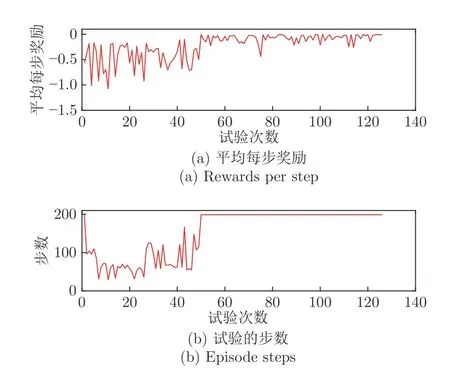
图3 DDPG 训练过程曲线图Fig.3 Training process curves of DDPG
由于环境在每一步给智能体的奖励均为负值,而球杆系统需要长久的运行,因此每一次试验累积的奖励值所代表的意义不鲜明.故本文统计了每次试验在每一步的平均奖励值随训练时间的变化情况.另外,本文还统计了每次试验运行的时间(步数)以监测球杆系统在训练过程中的稳定性变化情况.由图3(a)可见,平均每一步所累积的奖励值随着训练时间的增长逐渐增加,这说明以本文设置的奖励函数为评价标准,控制器的表现越来越好.最终,平均每一步所获得的奖励值收敛于一个接近0 的负值,这是由奖励信号的设计方式所导致的.图3(b)说明了随训练时间的增加,球杆系统从开始的控制失败(步数较少,因为小球离开长杆)逐渐变得更加稳定(后期每次球杆系统控制时长都达到了最大值).由图3 可以猜测,DDPG似乎习得了一个合适的控制器.
为了检验习得的期望控制策略的有效性,在仿真环境中用该控制策略控制球杆系统(随机选择了4 个初始状态),结果如图4 所示.其中分别表示在期望控制策略的控制下第i次仿真小球位置误差,小球速度以及长干角度的变化轨迹.可以发现,从任意的初始状态出发,基于DDPG 的期望控制策略都能高效,稳定的完成控制任务.另外,该期望控制策略并没有将小球准确无误的停在目标位置,而是存在着2 cm 左右的误差,这可能是DRL 算法在学习过程中没有完美的把握 “利用与探索之间的平衡”导致的.当然,这也是DRL 中公认的一大难点.但是,总体来说,该期望控制策略作为一种基于神经网络的非线性控制器,在本文设计的奖励指标上具有次优性.
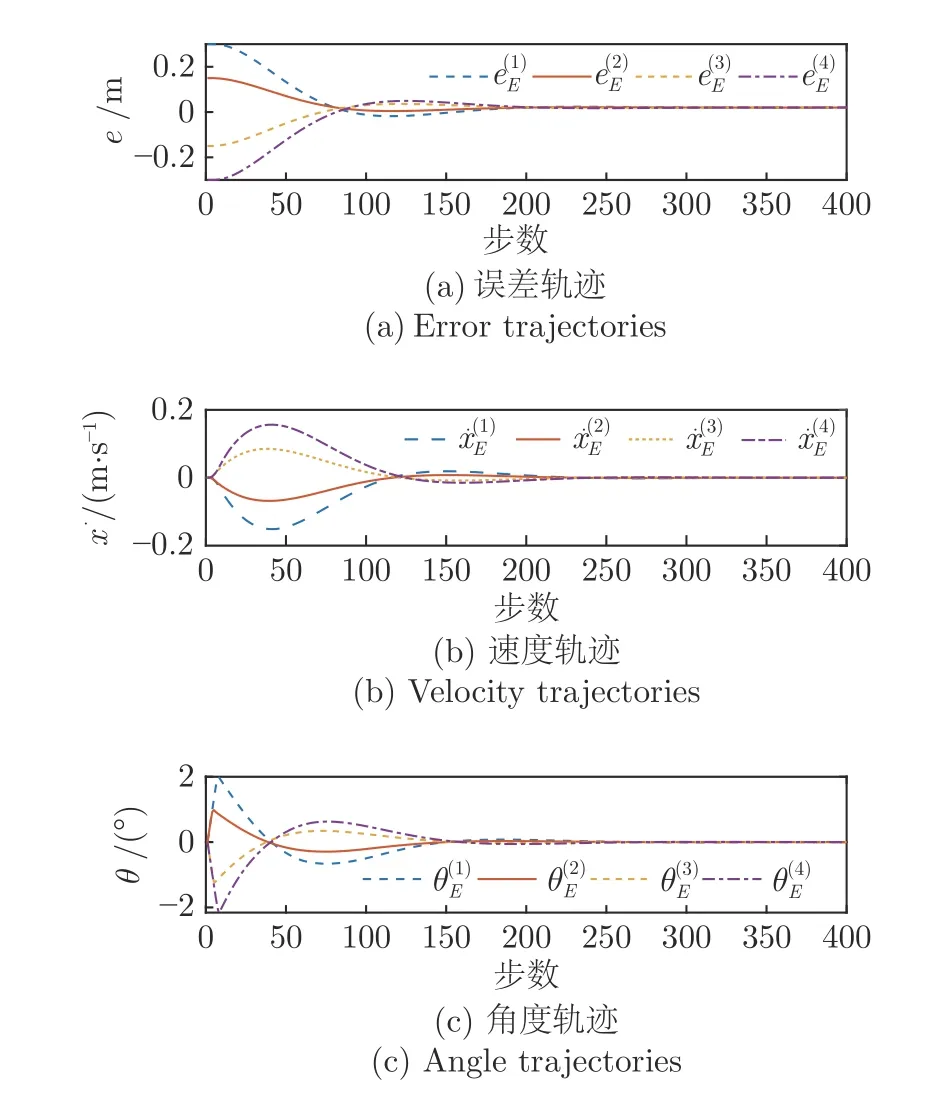
图4 DDPG 控制效果图Fig.4 The control result of DDPG
另外,本文在仿真中对比了基于DDPG 的控制策略与基于DQN 的控制策略的控制效果,结果如图5 所示.DQN算法是一种经典的基于值函数的DRL算法,其控制量是离散的.本次仿真中DQN的控制量属于可以发现,由于控制量是离散且其个数是有限的,如DQN 这种基于值函数的DRL 方法往往很难解决实际的控制问题.因此,使用基于策略的DRL 方法设计期望控制策略是必要的.
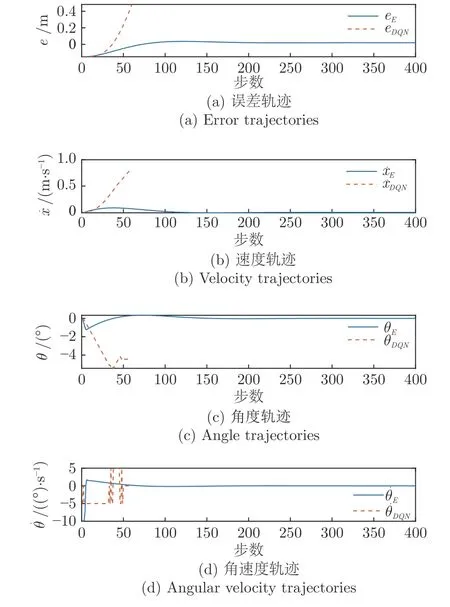
图5 DDPG 与DQN 的控制效果对比图Fig.5 The comparison of control effects between DDPG and DQN
3.2 基于GPR 的人体控制策略感知
本节分析利用GPR 学习人体控制策略预测模型的结果.本文通过相机检测人机协作球杆系统的状态,具体检测环境如图6 所示.相机通过检测长杆两端的特征点(分别记人端和机器人端的特征点为p1 与p2)与小球的位置(记为p3),以确定球杆系统的实时状态.

图6 人机协作实验环境图Fig.6 The environment of the human-robot collaboration task
据经验可知,人控制球杆系统时主要根据状态s=[e x]T来决定旋转长杆的速度vH.为了获取训练数据,本文邀请了10 位志愿者控制球杆系统,并利用相机记录了他们在控制过程中的控制策略数据 (s,vH).由于相机检测的是位置级信息,通过差分算法得到速度级信息时不可避免的引入高频噪声,因此本文使用低通滤波器对数据进行滤波,效果如图7 所示(本文只给出p1 点检测信息,另外2 点的滤波效果相似).其中p1x,O、p1y,O、p1x,F和p1y,F分别表示p1 在滤波前后的横纵像素坐标,v1x,O、v1y,O、v1x,F分别表示p1 在滤波前后的横纵像素速度.虽然经过滤波后的数据在位置级信息中有轻微的相位落后,但是速度级数据中的高频噪声被大幅抑制了.因此,利用滤波后3 点的位置数据可以较好得到数据集 (s,vH).图8 可视化了一部分基于滤波后3 点构建的志愿者控制球杆系统的状态轨迹.
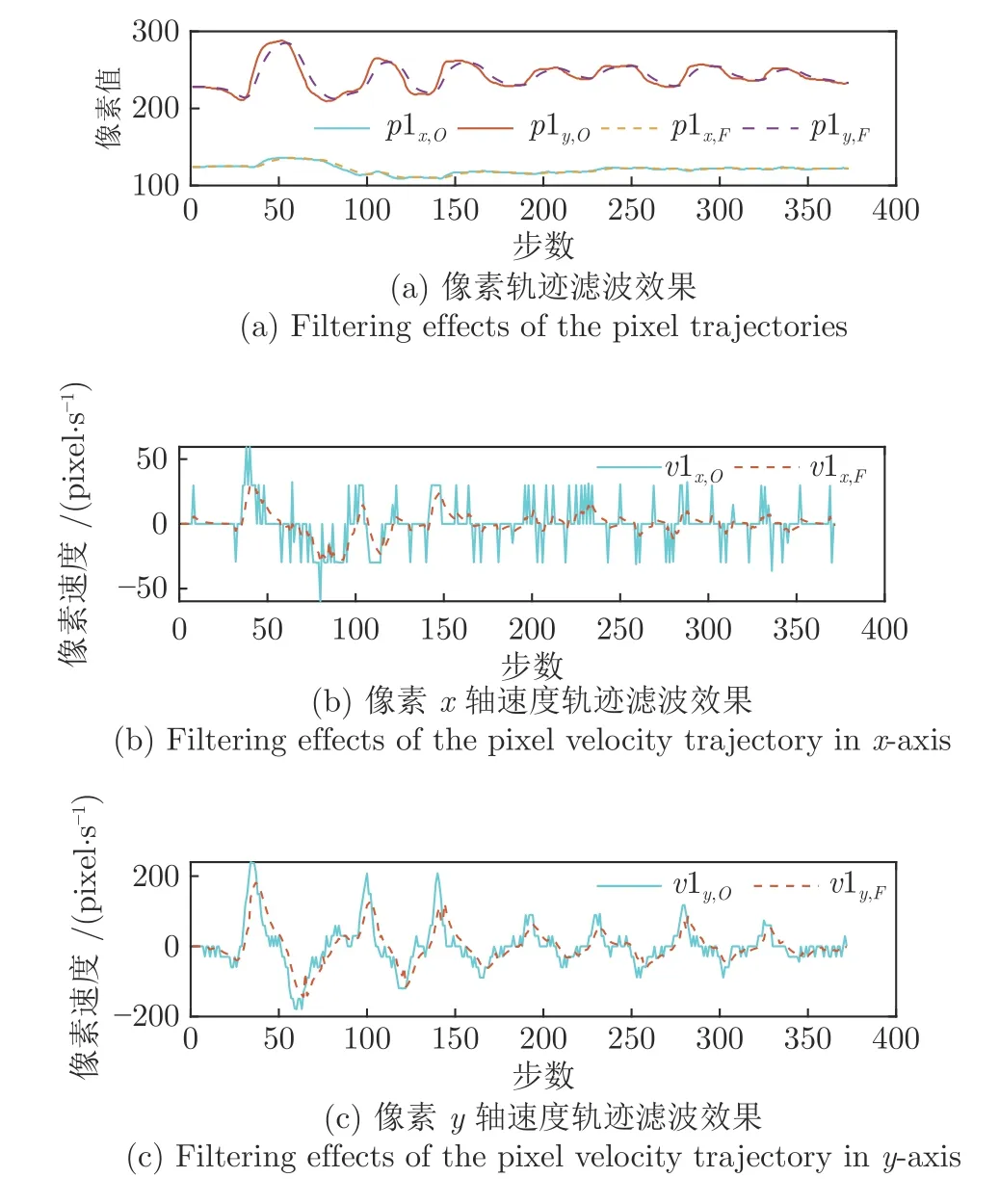
图7 志愿者控制过程中产生数据的滤波结果图Fig.7 Filtering results of the data generated by volunteers' control process
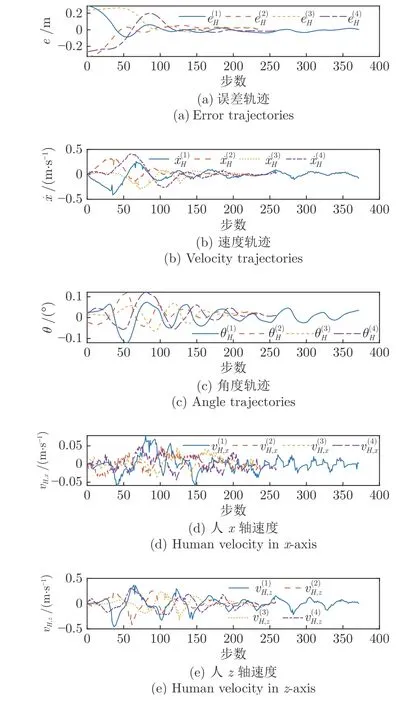
图8 志愿者控制过程中产生的部分轨迹图Fig.8 Some trajectories generated by the volunteers' control process
图8 中的下标H表示这些数据是由人的控制策略产生的.可以发现,志愿者在控制球杆系统时并不会使小球最终严格地停在目标位置处,而是在目标位置附近徘徊.并且,人在控制球杆系统时往往伴随较大的超调与一定程度的振荡.本文认为这种现象是很自然的,人的控制策略较为灵活与智能,这也是人相较于机器人最大的优点.然而,人往往很难像数字控制器一样做到高精度,高效率的控制.另外,进一步发现人的速度分量vH,x相对于分量vH,z幅值较小,无明显规律,更像是志愿者自己引入的随机噪声.本文利用GPR 在训练数据上拟合人体控制策略预测模型,即.结果图9 所示.图9 中阴影部分表示预测置信度为68.2%的区域(GPR 的输出是1 个高斯分布),第1 行的2 幅子图分别表示在训练集中1 条轨迹上的vH,x与vH,z的预测情况(上标Tr表示).第2~ 4 行表示测试集中各速度分量的预测情况(上标Te表示).由图9 可以看出,无论是在训练集还是测试集中,vH,x的预测均较差,说明GPR 方法较难从训练数据中寻得一种普遍规律,这也证实了vH,x可能是志愿者自身引入的一种随机噪声的猜测.而对于速度分量vH,z,预测模型较为准确地预测了变化趋势.由于人控制策略的高随机性与灵活性,精确的预测其具体的幅值是不现实的.本文得到的人体控制策略预测模型的预测值无论是在训练集还是测试集中,其预测幅值误差均较小,故该预测模型可使机器人在一定程度上了解人的控制规律.
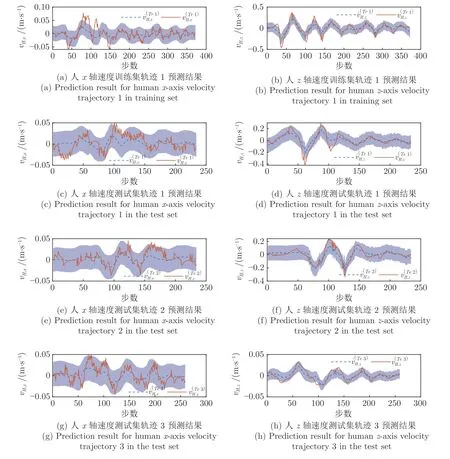
图9 人体控制策略预测模型拟合结果图Fig.9 The fitting results of human-control policy prediction model
3.3 人机协作控制实验
本节在图6 所示的平台上对基于GPR 与DRL的分层人机协作控制方法进行实验验证.
首先验证顶层期望控制策略.由于顶层期望控制策略是只针对非线性球杆系统设计的,未考虑人引入的随机因素.因此,在该部分实验中保持p1 点固定不动,以期望控制策略控制机器人,即vR,x=0,vR,z=-θ˙L.其中θ˙ 由期望控制策略即Actor 网络输出得到.实验结果如图10 所示.
由图10 可以发现,无论小球从何初始位置出发,该期望控制策略均能高效的完成控制任务(每一步时间为0.033 s,故期望控制策略约在6 s 内完成控制任务).另外,可以发现该实验结果与图4 中的仿真结果非常相似,更进一步的验证了该期望控制策略的有效性.
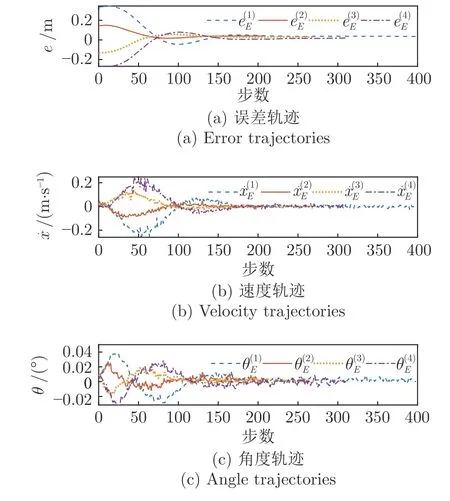
图10 期望控制策略的实验验证Fig.10 The experimental validation of the expected control policy
然而在实际人机协作任务中,人也参与到球杆系统的控制过程中.若仍以期望控制策略直接控制机器人,协作任务很可能在人与机器人协同的总控制量下失败(如人的过激控制量加上机器人的期望控制量,使长杆的旋转速度过快,从而使小球滚落长杆).故本文考虑使机器人与人的总控制量趋向于期望控制策略的控制量,即按第2.2.2 节所述设计机器人末端速度控制律.为了进一步突出该方法的有效性,本文将人机协同控制的控制效果与期望控制策略和人单独控制球杆系统的控制效果作对比.其实验效果如图11 所示.
考虑到传统的主从式人机协作多为人主-机器人从模式,即在协作任务中控制策略完全由人产生,机器人多承担负重任务.因此本文考虑固定机器人端(即p2 点),由人单独控制球杆系统来代表人主-机器人从的协作模式.单独由人产生控制球杆系统的策略往往会带来较大幅度的振荡,延长了整体控制时间,降低了控制效率.本实验的控制效率由使系统进入稳态区域的控制时间ts体现,稳态区域为稳定值正负3 cm 所在的范围(图11 中的阴影部分).如图11 所示,人单独控制策略下的球杆系统在ts,H=9.57 s时进入稳态区域.与顶层期望控制策略相比,其效率明显更低,并且最终较难精确地使小球停在目标位置处.从振荡的角度看,由于人在控制起始阶段往往采取过激的控制量以达到快速降低误差的目的,其并没有考虑长远的系统变化.而基于DDPG 的顶层期望控制策略的目标如式(1)所示,是使长远的累计奖励最大化,其考虑到了系统的长远变化,并在快速性与稳定性之间做出权衡,使系统不会有过大超调.另外,如第3.2 节所述,人的控制精度相对于数字控制器较低是很自然的.因此,用人机协作来提高协作任务的控制效率与精度是有必要的.可以发现,虽然人机协作的控制效果与期望控制策略的控制效果并不是理想情况下的完全一致,但是两者的小球位置误差与速度轨迹相差不大.单独由人作控制决策相比,人机协作明显提升了控制效率(ts,HRC=1.914 s),验证了本文方法的高效性.

图11 人机协作控制效果的实验验证Fig.11 The experimental validation of the HRC control
进一步对比人机协作与期望控制策略之间的控制曲线可以发现,人机协作的控制曲线存在一定的抖动,这在长杆的倾角变化轨迹中尤为明显.显然,这是人体控制策略预测模型的预测误差造成的.如图12 所示,可以发现虽然预测模型能较为准确地预测vH,z的变化趋势,但是对于其幅值的预测存在一定的误差,使得机器人并未完全补偿人的控制量,从而使人机协作的总控制量中仍然包含残留着的人的控制量,因此造成了长杆倾角抖动.然而,长杆倾角的抖动对球杆系统的控制目的(使小球停在目标位置处)并未造成较大的影响.
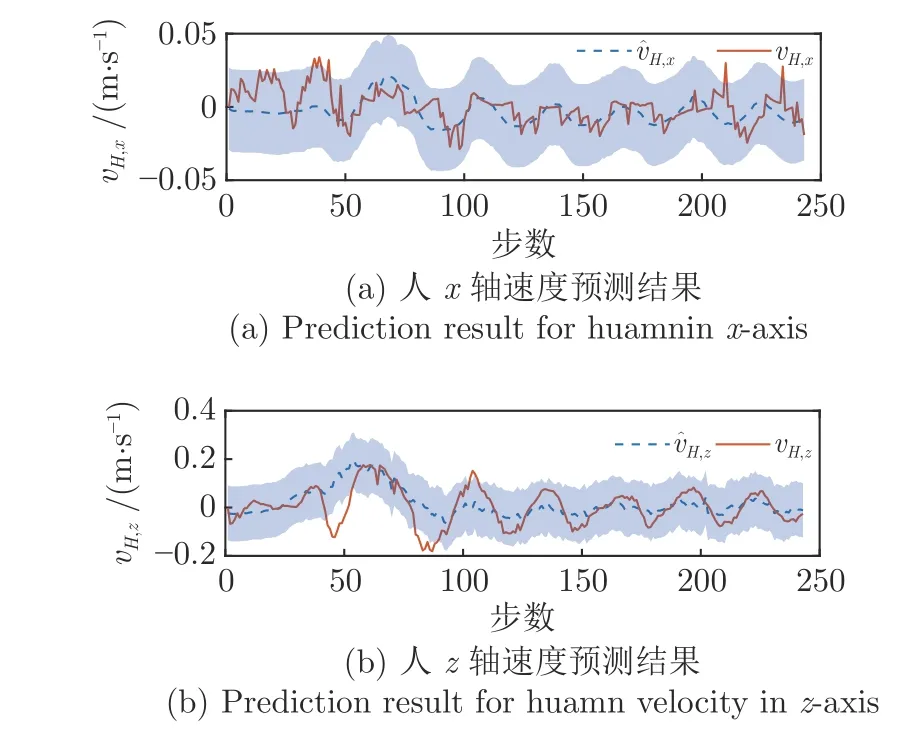
图12 人体控制策略预测模型预测结果Fig.12 The prediction result of the human-control policy prediction model
4 结束语
本文针对主从式人机协作效率较低的问题设计了一种基于GPR 和DRL 的分层人机协作控制方法.顶层使用DRL 算法在模型未知的情况下设计了一种有效的次优非线性控制策略,并将其作为期望控制策略以引导人机协作控制过程.底层使用GPR 方法拟合人体控制策略预测模型,为机器人建立人体行为认知模型,从而提升机器人在协作过程中过的主动性,提高协作效率同时降低人未知随机行为带来的不利影响.进而,基于期望控制策略与认知模型设计机器人的末端速度控制律.最后由实验对比发现,本文所提的人机协作控制方法较人主-机器人从协作控制具有更高的协作效率,体现了本文方法的高效性.
本文用GPR 拟合人体控制策略之后只使用了输出的均值来构建机械臂的控制律,未利用协方差信息.如何利用协方差信息来构建构更加具有鲁棒性的机械臂控制律是未来的一个研究要点.另外,如何提升在人体控制策略预测模型的预测精度也将是未来的工作之一.
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-08-31
能源工程(2022年2期)2022-05-23
现代电力(2022年2期)2022-05-23
南都周刊(2021年3期)2021-04-22
灌篮(2019年16期)2019-11-25
消费导刊(2018年10期)2018-08-20
山东工业技术(2016年15期)2016-12-01
海外星云(2016年7期)2016-12-01
太空探索(2016年5期)2016-07-12
首都体育学院学报(2016年3期)2016-05-30
